
Bloggen in der Konsole mit Bashblog, Verzeichnisse vergleichen mit Difftree 0.5.9, Daten restlos löschen mit Open Shredder 0.0.3, Prozesse parallelisieren mit Splitjob 2.0.
Meinungsmacher
Das schlanke Bashblog erlaubt es, neue Beiträge für eine Webseite schnell aus der Shell heraus zu veröffentlichen.
An Blog-Lösungen besteht unter Linux kein Mangel, wobei die meisten dynamische Inhalte unterstützen und dazu PHP-basierte Frameworks und einen leistungsfähigen Web-Server voraussetzen. Wer auf beides verzichten kann oder muss, der greift zum handlichen Bashblog, einem Shell-Skript, mit dem Sie das Blog verwalten. Im Quellarchiv befinden sich lediglich das Skript bb.sh, das alle Funktionen bereitstellt, sowie eine Anleitung. Nach dem Entpacken des Archivs ist Bashblog sofort einsatzbereit, wobei es auf Tools wie Awk, Grep oder Iconv zurückgreift. Da das Skript vollständig in der Konsole arbeitet, können Sie damit ein Blog auch via SSH verwalten, falls Sie einen Editor wie Nano, Vim oder Emacs verwenden.
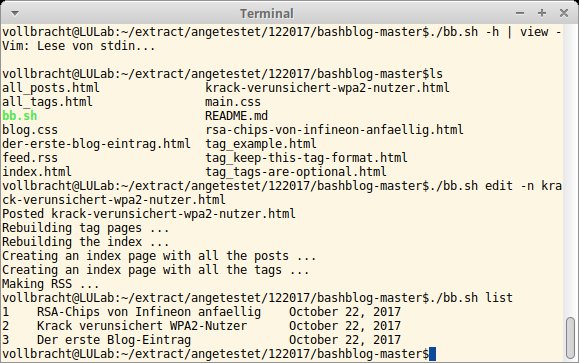
Für die Konfiguration setzen Sie die Umgebungsvariable $EDITOR und legen entweder in einem Verzeichnis die Datei .config an oder ändern die jeweiligen Parameter direkt im Skript. In dessen Funktion global_variables liegen Parameter wie der Name des Blogs, die URL, der Autor sowie dessen Mailadresse. Darüber hinaus finden Sie hier Einstellungen zum Zeitformat sowie den Kopf- und Fußzeilen der jeweiligen HTML-Dateien. Über den Aufrufparameter --help erhalten Sie eine rudimentäre Hilfe, die alle wichtigen Befehle ausweist. Für einen neuen Eintrag rufen Sie die Software mit dem Parameter post auf. Bashblog öffnet dann den Editor mit einer Beispiel-Vorlage, deren Inhalt Sie nach Belieben formatieren dürfen. Beim Beenden des Editors entscheiden Sie, ob Sie den Eintrag direkt online stellen wollen oder ihn weiterbearbeiten beziehungsweise als Entwurf ablegen möchten.
Bashblog legt alle Beiträge samt der zugehörigen CSS-Dateien im Hauptverzeichnis an, Entwürfe landen im Unterverzeichnis draft/. Das Tool legt die jeweilige Verzeichnisstruktur mit dem veröffentlichten Beitrag an. Als Format zum Speichern stehen wahlweise Markup oder HTML bereit. Eine Liste aller veröffentlichten Beiträge erhalten Sie mit list, mit edit bearbeiten Sie bereits veröffentlichte Postings. Neben einer Datei index.html für den Webserver legt das Programm eine feed.rss an, sodass Leser den Inhalt des Blogs via Feed-Reader verfolgen können.
Buchhalter
Mithilfe von Difftree 0.5.9 vergleichen Sie schnell ein oder mehrere Verzeichnisse und überwachen deren Status.
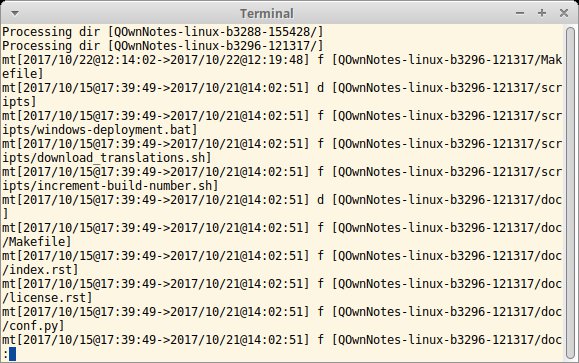
Um den Inhalt zweier Dateien zu vergleichen, greifen versierte Nutzer zum Tool Diff. Ähnlich effizient ermittelt Difftree die Unterschiede zwischen Verzeichnissen. Die Entwickler haben das Programm im Vergleich zu Konkurrenten wie Tripwire vor allem auf Geschwindigkeit optimiert. Außerdem bringt das Tool eine Reihe interessanter Funktionen mit: So kann es in einem Durchlauf mehrere Verzeichnisse vergleichen, deren URIs Sie dazu beim Aufruf durch Leerzeichen getrennt übergeben. Difftree vergleicht jedoch nicht alle Verzeichnisse direkt miteinander, sondern jedes mit seinem Vorgänger in der Parameterliste. Die Reihenfolge, in der Sie die Verzeichnisse angeben, ist also beim Auswerten entscheidend.
Für den Vergleich zweier Einträge zieht Difftree neben dem Namen auch Eintragstyp, Zugriffs- und Eigentumsrechte, alle Zeitstempel sowie die Dateigröße in Betracht. Falls das nicht genügt, berechnet es auf Wunsch auch MD5- oder SHA256-Prüfsummen. Bei großen Verzeichnisbäumen braucht das Tool jedoch länger für ein Ergebnis. Für Ungeduldige gibt es deshalb den Quick-Modus (Parameter -q), in dem Difftree nur Änderungen bei der Dateigröße sowie entfernte oder neue Dateien berücksichtigt. Starten Sie die Software mit dem Parameter -w, schreibt sie den Inhalt eines Verzeichnisses in eine Textdatei. Die lässt sich bei späteren Vergleichen als Referenz nutzen, um zu erkennen, was sich verändert hat. In Kombination mit dem Scheduler Cron richten Sie so ein rudimentäres Monitoring ein.
Reißwolf
Das Java-Tool Open Shredder 0.0.3 löscht Dateien unwiederbringlich, muss jedoch bei SSDs passen.
Der Inhalt “gelöschter” Dateien liegt bekanntlich weiter auf der Festplatte, bis er von anderen Inhalten überschrieben wird. Um Daten nachhaltig zu vernichten, brauchen Sie ein Tool wie Open Shredder. Das Java-Programm unterstützt Sie mit einer eingängigen Benutzeroberfläche beim Entfernen einzelner Dateien oder ganzer Verzeichnisse. Open Shredder löscht einzelne Dateien durch mehrmaliges Überschreiben der entsprechenden Blöcke. Soll es schnell gehen, überschreibt es die Inhalte mit Nullen. Daneben bietet es mit der Methode DoD ein komplexeres Muster zum Überschreiben an. Hier überschreibt die Software alle Inhalte einer Datei in drei Schritten. Im ersten Durchlauf nullt es alle Blöcke, beim zweiten Durchlauf belegt es alle mit dem Wert 1. Im abschließenden dritten Durchlauf überschreibt es jeden Block mit zufälligen Werten. Der Preis für das gründliche Löschen ist eine deutlich längere Laufzeit.
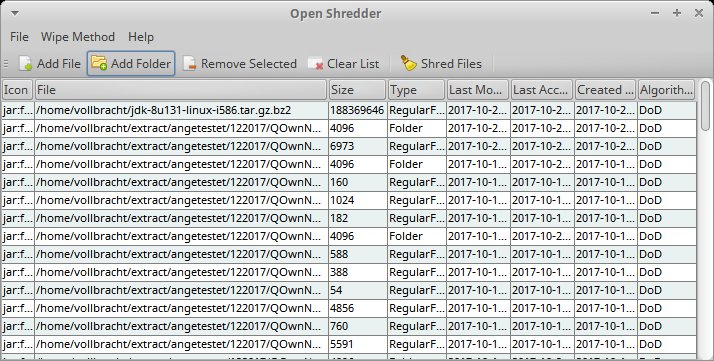
In Sachen Bedienoberfläche beschränkt sich Shredder auf das Wesentliche; alle wichtigen Funktionen stehen via Symbolleiste bereit. Über die Symbole Add File und Add Folder nehmen Sie ganze Dateien oder einzelne Verzeichnisse in die Liste auf. Um einen oder mehrere Einträge wieder aus der Liste zu entfernen, wählen Sie Remove Selected. Mit Shred files leiten Sie das Löschen ein. Das Programm öffnet eine Ansicht mit einem Fortschrittsbalken und fordert Sie auf, das Löschen mit dem Startknopf explizit anzustoßen. Das ermöglicht es, in letzter Sekunde noch einen Rückzieher zu machen. Die Methode zum Löschen wählen Sie über das Ausklappfeld Wipe Method aus, wobei das gründliche Verfahren als Standard dient. Während frühere Versionen von Open Shredder das Löschen ganzer Partitionen unterstützten, konzentriert sich das aktuelle Release ganz auf das nachhaltige Vernichten von Dateien.
Beschleuniger
Auf Multi-Core-Systemen beschleunigt Splitjob 2.0 durch Parallelisierung das Verarbeiten großer Datenmengen mit einfachen Programmen.
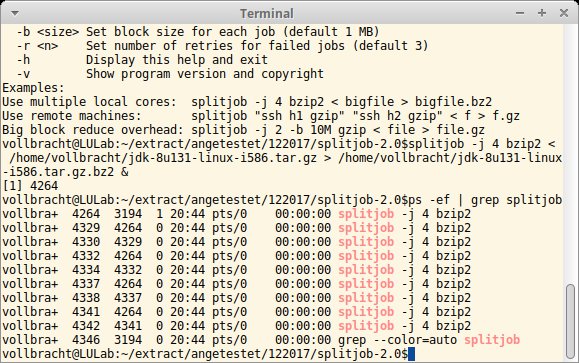
Die meisten PCs und Embedded-Systeme bringen heute Multi-Core-CPUs mit. Mangels entsprechender Programmierung reizen jedoch viele kleinere Programme und Tools die Möglichkeiten des parallelen Verarbeitens auf diesen Prozessoren nicht aus. Hier springt Splitjob in die Bresche: Mit dessen Hilfe starten Sie ein Programm mehrfach, wobei das Tool den zu verarbeitenden Datenstrom auf die einzelnen Kerne verteilt und das Ergebnis wieder zusammenfügt. Dazu teilt Splitjob Eingabedaten auf mehrere Queues auf und übergibt diese via Standardeingabe an den jeweiligen Instanz des verarbeitenden Programms. Da Splitjob die einzelnen Prozesse selbst startet, behält es dabei stets den Überblick.
Die Konfiguration erfolgt über einige wenige Parameter auf der Kommandozeile. Mit -j legen Sie die Anzahl der Prozesse fest. Fehlt diese Angabe, startet Splitjob nur einen Prozess des jeweiligen Tools. Standardmäßig teilt es die Eingabedaten in 1 MByte große Blöcke auf und reicht diese an die Prozesse durch. Wollen Sie diese Größe anpassen, nutzen Sie den Parameter -b. Schlägt das Verarbeiten eines Blocks in einem Job fehl, startet Splitjob drei weitere Versuche und bricht dann ab, um mit dem nächsten Block weiterzumachen. Mit -r schrauben Sie gegebenenfalls die Anzahl der erneuten Versuche hoch.
Als letzten Parameter übergeben Sie das zu parallelisierende Programm. Dabei beschränkt sich der Einsatz von Splitjob auf einfache Konsolenwerkzeuge, die keine weiteren Parameter benötigen. Programme mit grafischer Oberfläche arbeiten mit Splitjob nicht zusammen. Auf der Webseite finden Sie eine Reihe von Beispielen, die unter anderem zeigen, wie Sie das Komprimieren von Daten parallelisieren. (agr)




