Texte diktieren, statt sie zu tippen – davon konnten Linux-Anwender bislang nur träumen. Dank der vom ChatGPT-Hersteller OpenAI entwickelten, kaum beachteten Texterkennungssoftware Whisper hat sich das geändert.
Audio-Memos sind oft die praktikabelste Methode, um im Alltag mit dem Smartphone Notizen festzuhalten. Die seit Ende 2022 verfügbare freie Spracherkennungssoftware Whisper von OpenAI [1] erspart es sogar, die Stimmaufnahmen abzutippen. Auch längere Texte lassen sich so bei hervorragender Erkennungsgenauigkeit komfortabel diktieren.
Es gibt zwar keine OpenSuse-Pakete für diese Software, doch das Kompilieren aus dem Quellcode gelingt schnell und zuverlässig: Es handelt sich um C/C++-Code ohne externe Abhängigkeiten, was die Fehleranfälligkeit des Kompiliervorgangs begrenzt und den Aufwand auf einen Aufruf von Make reduziert (Abbildung 1).
Abbildung 1: Eine einfach zu kompilierende Version von Whisper findet sich im Quellcode unter der MIT-Lizenz auf Github.
Whisper ist kein klassisches Diktierprogramm wie das kommerzielle Dragon NaturallySpeaking [2] des US-Unternehmens Nuance. Diese weitverbreitete Software gibt es allerdings gar nicht für Linux, und da Microsoft den Hersteller 2021 aufgekauft hat, dürfte es auch in Zukunft dabei bleiben.
Anders als NaturallySpeaking untersucht Whisper stets gesprochene Abschnitte von 30 Sekunden Dauer. Bei einer Erkennungsgeschwindigkeit von etwa der halben Aufnahmedauer auf aktuellen PCs braucht die hier vorgestellte C++-Spielart des Programms also um die 15 Sekunden, bis sie den transkribierten Text liefert. Das gilt auch dann, wenn die Audioaufnahme nur aus einem Wort besteht. Zwar enthält Whisper ein Tool, das sich direkt mit dem Mikrofon verbindet [3], aber auch das liefert erst nach rund 15 Sekunden Ergebnisse. Wegen dieser (offenbar willkürlichen) Segmentierung ließen sich damit im Test keine besonders guten Ergebnisse erzielen.
Langer Rede kurzer Sinn: Whisper (Abbildung 2) verarbeitet in der Praxis stets vorher aufgenommene Wave-Dateien. Dabei kann es sich um ganze, in einem Stück aufgenommene Schriftstücke handeln. Audacity gestattet es, in solchen längeren Passagen Versprecher oder Teilabschnitte bei Bedarf zu überschreiben. Entspricht das eher Ihrem Arbeitsfluss, dann können Sie stattdessen nur einzelne Absätze diktieren, sie dann der Texterkennung unterziehen, und erst dann weitersprechen, wenn der vorausgehende Text in lesbarer Form vorliegt. In diesem Fall bietet es sich an, sich mittels eines Bash-Skripts die Aufrufe von Whisper auf der Kommandozeile zu ersparen.
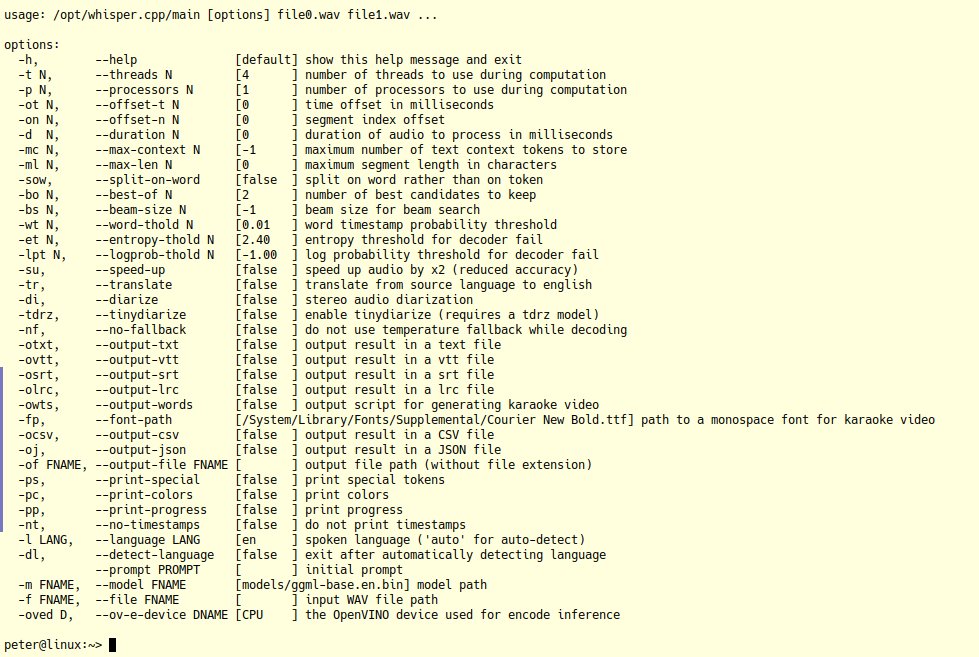
Abbildung 2: Das Kommandozeilenprogramm von Whisper bietet eine ausgezeichnete Erkennungsleistung. Ein Skript, das Aufnahmen automatisch einer Texterkennung unterzieht, gestattet ablenkungsfreies Diktieren.
Eigenbau
Um die C++-Version von OpenAI Whisper [4] aus dem Quellcode in eine startbare Programmdatei umzuwandeln, installieren Sie auf Ihrem Rechner zunächst das Paket gcc-c++. Um den Quellcode von der Hosting-Plattform Github zu beziehen, benötigen Sie außerdem die Versionsverwaltungssoftware Git (Paket git).
Haben Sie diese beiden Programmpakete installiert, öffnen Sie ein Konsolenfenster (Abbildung 3) und laden darin per Git den Whisper-Quellcode aus dem Online-Repository auf Ihren Computer herunter. Das entsprechende Kommando aus der ersten Zeile von Listing 1 legt ihn in einem Ordner namens whisper.cpp/ in dem Verzeichnis ab, aus dem heraus Sie den Befehl aufgerufen haben. Nun wechseln Sie in diesen Ordner (Zeile 2) und starten dort die Übersetzung des Quellcodes durch einen Make-Aufruf (Zeile 3). Nach Abschluss des Kompiliervorgangs liegt das schlicht main genannte Texterkennungsprogramm ausführbar im Ordner.
Abbildung 3: Mehr als je einen Aufruf von git clone und make braucht es nicht, um das Whisper-Binary aus dem Quellcode zu bauen.
Listing 1
Whisper bauen
$ git clone https://github.com/ggerganov/whisper.cpp.git $ cd whisper.cpp $ make -j $ make medium
Zum Transkribieren von Audioaufnahmen fehlt noch das AI-Trainingsdatenmodell, also der komplexe Regelsatz, anhand derer das lediglich 875 KByte große Programm main die Audiodaten in Text verwandelt. Es gibt fünf unterschiedlich große Varianten des Modells, von tiny, base und small über medium bis hin zu large. Die Dateigrößen reichen von 75 MByte bis 2,9 GByte. Sie laden die Erkennungsmodelle mit dem Aufruf von make Modell aus dem Verzeichnis whisper.cpp/ heraus in das Unterverzeichnis models/ herunter (Zeile 4).
Der RAM-Bedarf während des Einsatzes der Modelle bewegt sich zwischen 125 MByte und 3,3 GByte [5]. Da die größeren Modelle eine bessere Erkennungsgenauigkeit liefern, empfiehlt sich auf dem PC der Einsatz der Modelle large oder medium (1,5 GByte Download, 1,7 GByte RAM-Belegung). Die für die Texterkennung benötigte Rechenzeit fällt beim Modell large doppelt so lang aus wie bei medium. Bei tiny dagegen liegt sie um den Faktor 32 niedriger [6].
Um Ordnung im Home-Verzeichnis zu schaffen, ist es sinnvoll, den Ordner whisper.cpp/ in das Verzeichnis /opt zu verschieben, an den unter Linux für selbst kompilierte Programme vorgesehenen Ort. Das erledigen Sie als Root. Damit Sie das Programm auf der Kommandozeile mit whisper ohne vorangestellten Pfad aufrufen können, wechseln Sie als Root auf der Konsole in das Verzeichnis /usr/local/bin/. Dort erstellen Sie dann einen Link auf das main-Programm (Listing 2, erste zwei Zeilen).
Listing 2
Whisper starten
# cd /usr/local/bin # ln -s /opt/whisper.cpp/main whisper # whisper -t Zahl_CPU-Cores -m /opt/whisper.cpp/models/ggml-medium.bin -l de -otxt -of Ausgabe.txt Audioaufnahme.wav
Nun lässt sich das main-Programm unter dem Namen whisper auf der Kommandozeile aufrufen. Im Kommando aus der letzten Zeile von Listing 2 sorgt die Option -t dafür, dass die Texterkennung alle CPU-Kerne im Rechner nutzt. -m wählt die Modelldatei, hier die Spielart medium. Hinter -l geben Sie die Sprache an, also zum Beispiel de für Deutsch oder en für Englisch [5]. Der Schalter -otxt weist das Programm an, den erkannten Text als reine Textdatei zu speichern, hinter -of steht der Dateinamen für die Ausgabe.
Mitschnitt
Wie bereits erwähnt, gestattet Whisper ohnehin keine Echtzeiterkennung während des Diktierens. Daher empfiehlt es sich, das größte Datenmodell zu wählen, für das der Rechner genügend Arbeitsspeicher bietet und bei dem die Wartezeit für die Erkennung erträglich ausfällt. Zudem empfiehlt sich der Einsatz eines Aufnahmeprogramms, das während der Aufnahme zurückspulen und Versprecher überschreiben kann.
Unter Linux kommt hier nur das eher sperrige Audacity (Abbildung 4) infrage. Die erwähnten Funktionen bietet erst Audacity 3. OpenSuse Leap liefert immer noch die Uraltversion*2.2.2 mit, Tumbleweed ist auf einem aktuellen Stand. Leap-Anwender sollten daher die Version aus dem Repository home:Sauerland:mixx installieren, das nach der Suche nach Audacity unter https://software.opensuse.org und einem Klick auf den Button Community-Pakete anzeigen sichtbar wird (Abbildung 5).
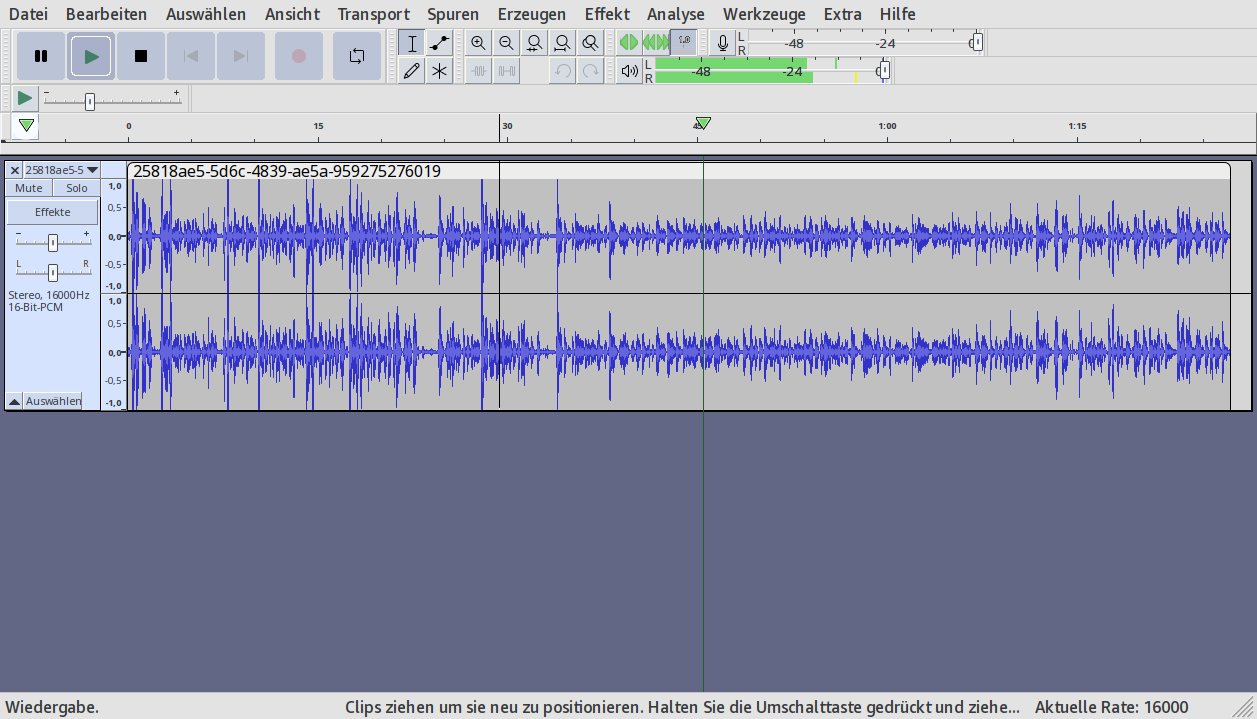
Abbildung 4: Das Aufnahmeprogramm Audacity 3.x bietet mit Funktionen wie Punch and Roll (anreißen und weiterspielen) und Scrub (Spulen mit hörbarem Sound) eine optimale Umgebung zum Diktieren.
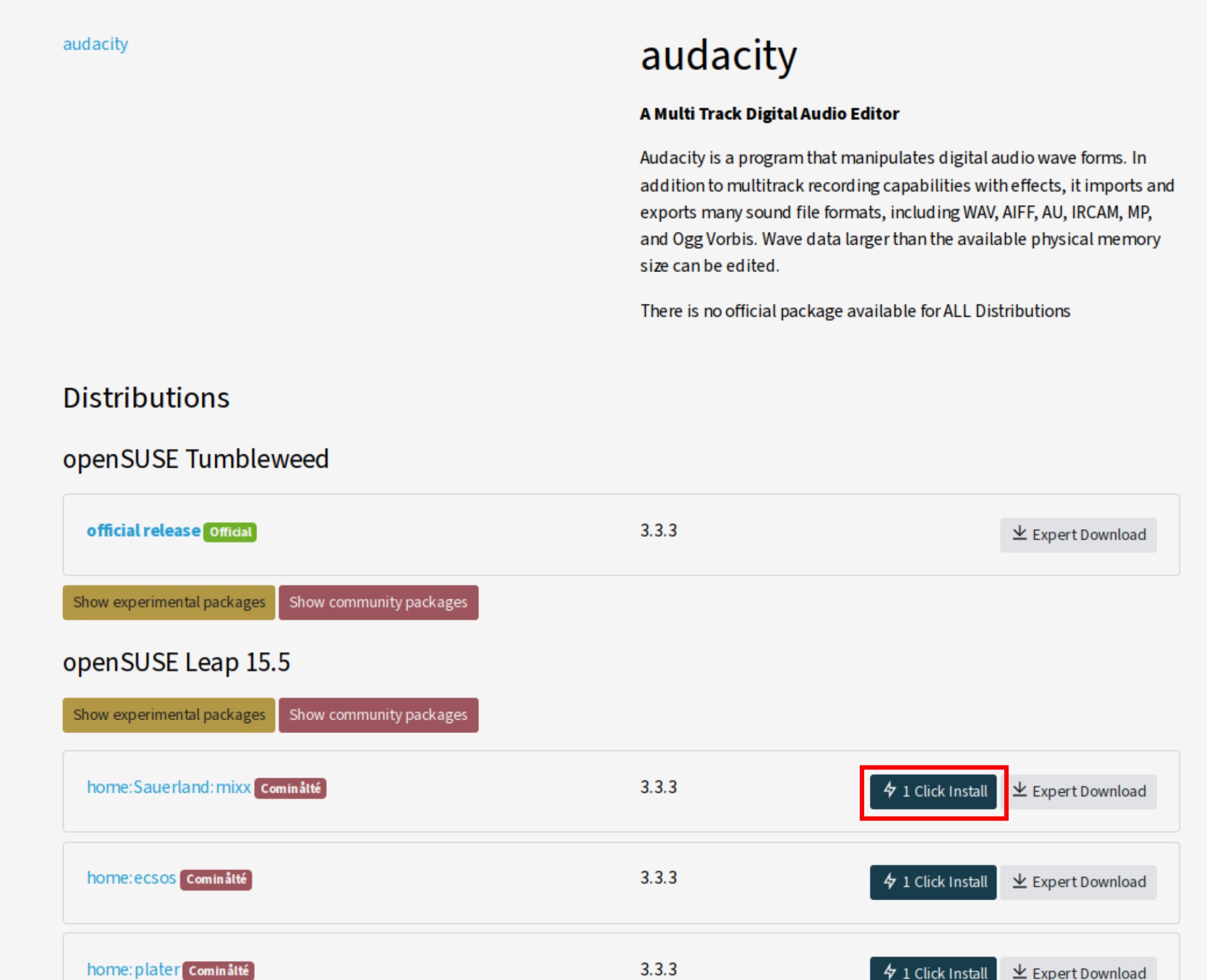
Abbildung 5: Mit etwas Nachhilfe lässt sich Audacity 3.3.3 in Leap aus dem Repository home:Sauerland:mixx installieren.
Dass im Moment nicht einmal die seit Langem gewohnte 1-Klick-Installation reibungslos funktioniert, ist symptomatisch für den Pflegezustand von OpenSuse Leap. Nach einem Klick auf den entsprechenden Schalter startet keineswegs die Installation: Der Browser lädt lediglich die Datei audacity.ymp herunter. Erst ein Klick darauf in der Downloads-Liste des Webbrowsers startet den YaST-1-Klick-Handler. Außerdem bietet der sich öffnende Assistent viele Repositories an, die offensichtlich gar nicht mehr existieren. Klicken Sie daher im zweiten Screen auf Anpassen und deaktivieren Sie alle zusätzlichen Softwarerepositorys außer home:Sauerland:mixx.
Whisper verarbeitet ausschließlich Dateien mit einer Sampling-Frequenz von 16 KHz. Im Menü Bearbeiten | Einstellungen lässt sich in der ersten Rubrik Audio-Einstellungen die Standard-Abtastrate festlegen, mit der Audacity startet. Dasselbe gilt für die Projekt-Abtastrate für die aktuell geöffnete Aufnahme.
Das Tastenkürzel [R]+ stößt die Aufnahme an, ein Druck auf die Leertaste beendet sie. Möchten Sie die letzten paar Sekunden der Aufnahme überspielen, dann stoppen Sie die Aufzeichnung mit der Leertaste und drücken [Ende], um die Wiedergabemarke ans Ende der Aufnahme zu setzen. Sie sollte dort als dünne schwarze Linie in der Zeitleiste oberhalb der Audio-Tracks erscheinen (Abbildung 6). Tut sie das nicht, dann klicken Sie mit der Maus auf eine beliebige Stelle der Audiospuren, um ihnen den Fokus zu geben, und versuchen es erneut.
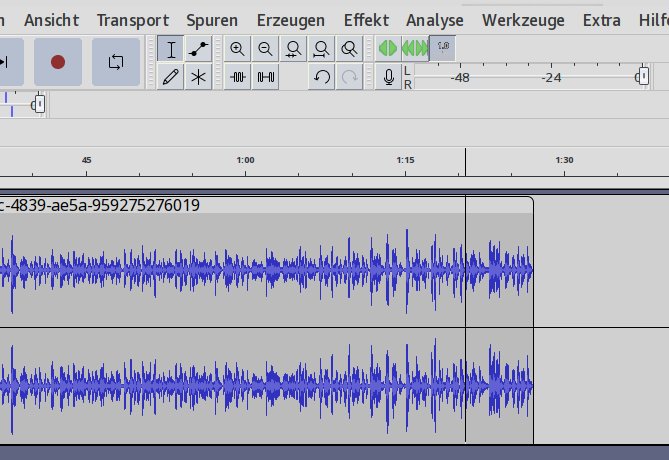
Abbildung 6: Lässt sich die schwarze vertikale Aufnahmemarke in Audacity nicht setzen oder bewegen, dann liegt der Eingabefokus nicht auf den Spuren. Ein entsprechender Mausklick sorgt für Abhilfe.
Nun können Sie den Wiedergabecursor stumm mit den Pfeiltasten verschieben. Dagegen spielen [I]+ und [U] während des Vor- oder Zurückspulens den Track wie auf einem Tonbandgerät ab. Die Spulgeschwindigkeit hängt dabei vom Zoom-Level der Track-Anzeige ab, das Sie mit [Strg]+[ 3] und [Strg]+[ 2] erhöhen respektive verringern. Vor allem beim Vorspulen hilft der hinterlegte Sound, die richtige Stelle zu finden.
Steht der Cursor an der Stelle, ab der Sie die Aufnahme überschreiben möchten, dann starten Sie mit [Umschalt]+[D] die sogenannte Punch-and-Roll-Aufnahme. Dabei spielt Audacity eine einstellbare Zeitspanne vor dem Cursor ab und schaltet erst dann in den Aufnahmemodus. Voreingestellt sind hier fünf Sekunden. Für zügigere Korrekturen von Sprachaufnahmen legen Sie in den Einstellungen unter Aufnahme unten im Dialog einen Vorlauf von ein bis zwei Sekunden fest. Die in der Voreinstellung nicht unbedingt intuitiven Tastaturkürzel lassen sich in der Einstellungsrubrik Tastatur verändern.
Audacity 3 ermöglicht einen handlichen Workflow für Sprachaufnahmen. Manche Anwender diktieren auf diese Weise einen ganzen Text am Stück und redigieren, sofern nötig, direkt in der Audioaufnahme. Ein Druck auf [Entf] löscht mit der Maus markierte Bereiche.
Direkt in die Lücke hinein wieder aufzunehmen, beherrscht Audacity nicht. Es macht jedoch nicht viel Aufwand, mit [Umschalt]+[R] eine Aufnahme in eine neue Spur zu starten und den entsprechenden Block per Zwischenablage in die Lücke zu kopieren. [Strg]+[B] setzt an der Cursor-Position eine Marke, was das spätere Platzieren von neuem Material erleichtert. Ein alternatives Vorgehen beim Diktieren besteht darin, kleine Abschnitte aufzunehmen und gleich der Texterkennung zu unterziehen, um sie dann beim weiteren Diktieren bereits als Text vor Augen zu haben.
Beim Speichern mit [Strg]+[S] legt Audacity die Daten in einem nur für das Programm selbst lesbaren Format ab. Um eine für Whisper verwendbare Wave-Datei zu erhalten, exportieren Sie die Aufnahme per [Umschalt]+[Strg]+[E]. In der Voreinstellung nutzt Audacity dabei die passende Encodierung (Signed 16-bit PCM) und unten im Dialogfeld das korrekte Dateiformat WAV (Microsoft).
Stapelverarbeitung
Auf Dauer nervt es ein wenig, in kurzen Abständen exportierte Audiodaten jedes Mal händisch per Kommandozeilenaufruf der Spracherkennung zu übergeben. Es steigert den Arbeitskomfort deutlich, per Bash-Skript den Ordner mit den Aufnahmen zu überwachen, alle dort abgelegten Dateien automatisch zu verarbeiten und den erkannten Text an den bisherigen anzuhängen (Abbildung 7). Sie brauchen dann nur noch in Audacity die jeweils neu aufgenommenen Abschnitte zu exportieren.
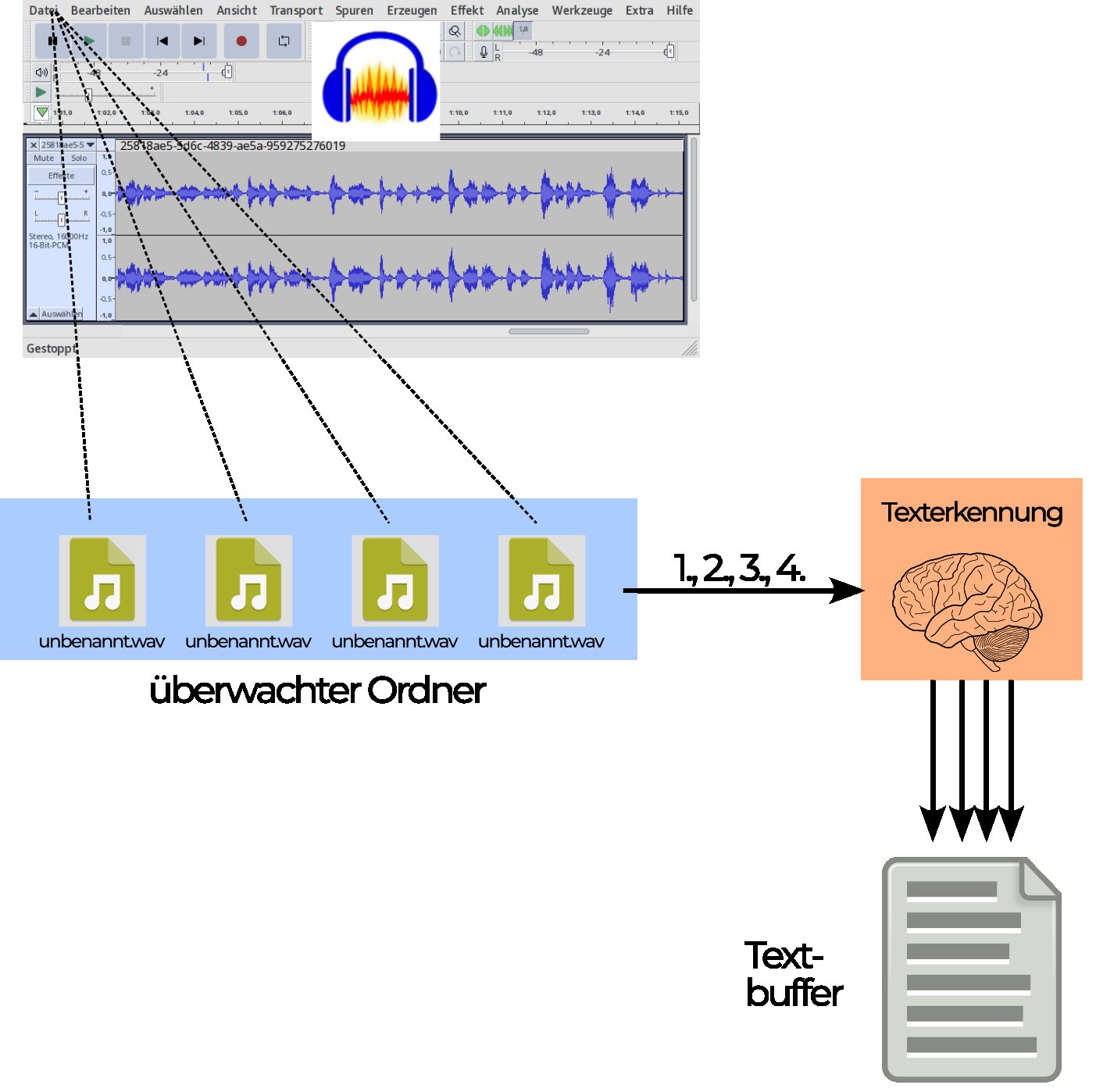
Abbildung 7: Das Skript aus Listing 1 ruft die Texterkennung mit unterschiedlichen Versionen des von Audacity vorgeschlagenen Dateinamens unbenannt.wav auf und fügt das Ergebnis einem Textpuffer hinzu.
Das in Listing 3 vorgestellte Skript sieht dafür das Unterverzeichnis new_files/ in einem zu Beginn (Zeile 3) definierten Ordner vor. In dem Verzeichnis müssen Sie vor dem Aufruf des Skripts die Unterordner output/, processed/, new_files/ und tmp/ erstellen. Wie wir sehen werden, entfernt das Skript verarbeitete Dateien aus new_files/. Sie können daher immer wieder den von Audacity vorgeschlagenen Dateinamen unbenannt.wav verwenden, ohne eine Überschreibwarnung wegklicken zu müssen. Das Skript benötigt das Paket inotify-tools.
Listing 3
Aufnahmen verarbeiten
#!/bin/bash
verz=/Pfad/zum/Ordner/whisper
inotifywait -m $verz/new_files -e close_write |
while read filename eventlist eventfile; do
cp $verz/new_files/$eventfile $verz/tmp/current.wav
whisper -m /opt/whisper.cpp/models/ggml-medium.bin \
-t 16 -l de -otxt -nt -of $verz/tmp/whisper_out \
$verz/new_files/$eventfile &> /dev/null
mv $verz/new_files/$eventfile $verz/processed/$(uuidgen).wav
cat $verz/tmp/whisper_out.txt >> $verz/output/recognized.txt
done
Der Export per [Umschalt]+[Strg]+[E] in Audacity speichert die gesamte vorliegende Aufnahme. Um immer wieder neue, kurze Abschnitte zu diktieren, löschen Sie den bisherigen Inhalt mit [Strg]+[A][Entf]. Das Skript archiviert alle im Ordner new_files/ abgelegten Audiodaten in den Unterordner processed/, damit sie für ein späteres Korrekturlesen erhalten bleiben.
Als Erstes startet das Bash-Skript aus Listing 1 in Zeile 3 dafür das Werkzeug Inotifywait. Es empfängt direkt vom Linux-Kernel eine Meldung, wenn in dem als Parameter -m übergebenen Verzeichnis ein Schreibvorgang stattfindet. Das erspart ein regelmäßiges Nachsehen und die damit verbundene Festplattenaktivität. Der read-Befehl in Zeile 4 wartet untätig, bis Inotifywait ihm via Pipe (|) Daten übermittelt.
Der Parameter -e close_write sorgt dafür, dass das erst geschieht, wenn eine zum Schreiben geöffnete Datei wieder geschlossen wird, also nach Beendigung des Speichervorgangs. Dann führt die Shell den Code zwischen do und done aus. Der Ordner new_files/ sollte übrigens nach dem Start des Skripts nicht im KDE-Dateimanager geöffnet bleiben, da dessen Vorschaufunktion das Skript ebenfalls triggert.
Zeile 5 kopiert die neu hinzugekommene Datei als current.wav in das Unterverzeichnis tmp/ von $verz. Dann startet der Aufruf whisper in Zeile 6 das Programm main aus dem Ordner /opt/whisper.cpp/. Dabei kommt das Modell ggml-medium.bin zum Einsatz. Es speichert in Zeile 7 den erkannten Text zunächst in der Datei tmp/whisper_out, wobei Whisper die Endung .txt anhängt.
Zeile 9 verschiebt die abgearbeitete Sound-Datei unter einem mit dem Tool Uuidgen erzeugten eindeutigen Dateinamen in das Verzeichnis processed/. Der Ordner new_files/ ist nach der Texterkennung wieder leer.
Zeile 10 hängt schließlich den erkannten Text an den bestehenden Inhalt der Datei output/recognized.txt an. Diese Datei halten Sie während des Diktierens in einem Editor geöffnet.
Workflow
Allerdings ist es gar nicht so einfach, einen Editor zu finden, der eine Textdatei bei Veränderung ohne eine störende Nachfrage neu lädt. Hier empfiehlt sich das KDE-Plasma-Widget Command Output [7], das schon in den vorangegangenen OpenSuse-Tipps zur Anzeige einer Textdatei auf dem Desktop diente (Abbildung 8). Als Command, dessen Rückgabe das Widget anzeigen soll, geben Sie cat /Pfad/zu/Whisper/output/recognized.txt ein.

Abbildung 8: Anders als die meisten Texteditoren lädt das KDE-Widget Command Output veränderte Textdateien ohne Nachfrage neu.
Damit ist die Umgebung zum Diktieren von Text mit OpenAI Whisper vollständig: Ein Bash-Skript startet die Texterkennung für jeden neuen Aufnahmeblock und fügt den erkannten Text einer bestehenden Textdatei hinzu. Das KDE-Desktop-Widget lädt diese automatisch neu, sodass Sie beim Diktieren alle bereits konvertierten Abschnitte vor sich sehen.
Sie können das Skript manuell in einem Konsolenfenster starten. Da es aber nicht regelmäßig im überwachten Verzeichnis nach neuen Aufnahmen sucht, sondern lediglich auf eine Nachricht des Linux-Kernels wartet, bindet es so wenige Systemressourcen, dass Sie es auch problemlos für den Autostart mit Ihrer Desktop-Umgebung eintragen können. Unter KDE finden Sie dazu in den Systemeinstellungen unter der Rubrik Starten und Beenden den Punkt Autostart. Nach einem Klick auf Hinzufügen tragen Sie im Texteingabefeld oberhalb der Anwendungsliste den Dateipfad zum Skript ein oder benutzen den Dateiwähler, den ein Klick auf das Pfeil-nach-oben-Icon hinter dem Eingabefeld öffnet.
Unter Gnome suchen Sie zunächst nach der Anwendung Menübearbeitung und installieren Sie, sofern noch nicht geschehen. Erstellen Sie dann zum Beispiel im Menü Sonstige mit dem kleinen Plus-Icon rechts in der Titelleiste über Starter hinzufügen einen neuen Anwendungsstarter, bei dem Sie als Befehl das Skript eintragen. Diesen neuen Eintrag im Anwendungsmenü fügen Sie dann in der Anwendung Optimierungen unter Startup Programme hinzu.
Der automatische Start bietet sich insbesondere dann an, wenn Sie die Texterkennung dazu nutzen möchten, vom Smartphone synchronisierte Audio-Memos zu verarbeiten. So nehmen Sie unterwegs Sprachnotizen auf, ohne den Blick auf die Bildschirmtastatur des Mobiltelefons zu richten. Auf dem heimischen Rechner erscheinen die Notizen dann trotzdem als lesbarer Text.
Fazit
Die freie Software Whisper [1] ist kein Diktierprogramm im klassischen Sinn. Dennoch lässt sie sich unter OpenSuse Leap und Tumbleweed (oder auch anderen Distributionen) nutzen, um Texte absatzweise zu diktieren und automatisiert zu erkennen, während man sich schon dem nächsten Absatz zuwendet. Whisper leistet sich bei der Erkennung von deutschen oder noch besser englischen Texten kaum Fehler, selbst wenn man das Mikrofon nicht optimal in Mundnähe positionieren kann. (uba/jlu)
Infos
-
Whisper: https://openai.com/research/whisper
-
Dragon NaturallySpeaking: https://www.nuance.com/de-de/dragon.html
-
Real-Time-Audio-Beispiel: https://github.com/ggerganov/whisper.cpp/#real-time-audio-input-example
-
C++-Port von Whisper: https://github.com/ggerganov/whisper.cpp
-
RAM-Belegung: https://github.com/ggerganov/whisper.cpp#memory-usage
-
Erkennungsgeschwindigkeit: https://github.com/openai/whisper#available-models-and-languages
-
Plasma-Widget Command Output: https://store.kde.org/p/1166510