

Clustering-Verfahren aus dem Bereich des unüberwachten Lernens sortieren Daten in Gruppen und erlauben so eine nützliche Segmentierung komplexer Datensätze.
Beim überwachten Lernen sollen die Algorithmen einen funktionalen Zusammenhang zwischen Features und Labels erkennen. Diesen Zusammenhang erlernen die Algorithmen anhand von Trainingsdaten mithilfe statistischer Modelle. Beim unüberwachten Lernen dagegen liegen nur Features vor, die keine Labels besitzen. Hier kann und soll also kein funktionaler Zusammenhang gefunden werden. Stattdessen hat das unüberwachte Lernen je nach Anwendungsbereich verschiedene Aufgaben. Grundsätzlich gibt es drei verschiedene Hauptaufgaben des unüberwachten Lernens: das Clustering, die Dimensionsreduktion und die Anomalieerkennung.
Die Cluster-Bildung stellt beim unüberwachten Lernen eine häufige Aufgabe dar. Dabei ordnet ein Algorithmus ähnliche Datenpunkte aufgrund ihrer Merkmale oder Eigenschaften in Cluster oder Gruppen ein. Dieses Clustering hilft dabei, Muster und Strukturen in den Daten zu erkennen. Ein gutes Beispiel aus dem E-Commerce-Bereich wäre die Gruppierung von Kunden in Segmente auf Basis ihres Kaufverhaltens.
Eine weitere wichtige Aufgabe im unüberwachten Lernen ist die Dimensionsreduktion. Bei dieser Aufgabe versucht der Algorithmus, die Anzahl der Datenmerkmale (die Dimensionen) zu reduzieren, während er gleichzeitig so viel relevante Information wie möglich erhält. Das hilft, die Daten zu vereinfachen und gleichzeitig die nützlichen Informationen beizubehalten.
Man kann unüberwachtes Lernen auch zur Anomalieerkennung einsetzen. In diesem Fall versucht der Algorithmus, abnormes Verhalten oder Ausreißer in den Daten zu identifizieren, ohne dass explizite Informationen über diese Ausreißer vorhanden sind. Das spielt in vielen Anwendungsfällen eine Rolle, beispielsweise bei der Erkennung von betrügerischen Transaktionen in Finanzdaten oder bei der Identifizierung von fehlerhaften Produkten in der Qualitätskontrolle.
Arten des Clusterings
Eine der wichtigsten Aufgaben des unüberwachten Lernens liegt im Erkennen von Mustern und Strukturen in Daten anhand von Clustering-Verfahren. Dazu kommen verschiedene Arten von Clustering-Algorithmen zum Einsatz. Am weitesten verbreitet sind dabei zentroidbasiertes, dichtebasiertes und hierarchiebasiertes Clustering.
Zentroidbasiertes Clustering ist eines der bekanntesten Verfahren. Man verwendet dabei Zentroiden (Cluster-Zentren), um Cluster zu bilden. Dazu platziert man mehrere Zentroiden in den Datenpunkten und ordnet jeden Datenpunkt dem nächstgelegenen Zentroiden zu. Das ist die am häufigsten verwendete Methode des Clusterings und eignet sich für viele Anwendungen.
Beim dichtebasierten Clustering gruppiert man Datenpunkte, indem man im Feature-Raum Bereiche hoher Datenpunktdichte sucht, die von Bereichen niedriger Dichte umgeben sind. Ein hierarchiebasiertes Clustering erfolgt in der Regel auf hierarchisch strukturierten Daten. Der Algorithmus erstellt dazu eine Baumstruktur von Clustern, was die Hierarchie von oben nach unten organisiert.
Jede dieser Cluster-Arten hat ihre eigenen Vor- und Nachteile und eignet sich für verschiedene Arten von Daten und Anwendungen. Die Wahl des richtigen Clustering-Algorithmus hängt von den spezifischen Anforderungen und der Beschaffenheit der Daten ab.
Zentroidbasiertes Clustering
Das zentroidbasierte Clustering-Problem lässt sich recht einfach formulieren: Gegeben seien N Datenpunkte in einem D-dimensionalen Feature-Raum. Diese Datenpunkte sollen durch das Clustering in k Gruppen (Partitionen) eingeteilt werden. Dabei gilt es, die Aufteilung in die Gruppen derart zu wählen, dass das Clustering Objective minimiert wird. Diese Zielfunktion erreicht ein Minimum, wenn die gebildeten Gruppen (Cluster) maximal homogen sind:
![]()
Hier ist S=(C,U) die Menge der Partitionen C mit einzelnen Partitionen ci und der Menge der Zentren der Partitionen U mit einzelnen Zentren µi. Der Abstand wird über die euklidische Entfernung … gemessen. Ziel des Clustering-Algorithmus ist es, die Menge S zu finden, die die Doppelsumme minimiert. Eine Idee, dieses Problem zu lösen, besteht darin, alle möglichen Partitionen und Zentren auszuprobieren. Das Problem ist allerdings die Zeitkomplexität dieses Ansatzes. Sie beläuft sich auf:
![]()
Dieses Verhalten hat zur Folge, dass man den Algorithmus nicht für größere Datenmengen verwenden kann, da er mit steigendem N immer langsamer wird. Aus diesem Grund gibt es andere Techniken, die das Cluster Objective zwar nicht global minimieren, aber ein lokales Minimum dieser Zielfunktion finden können. Oft genügt dieses lokale Minimum für die Anwendung.
K-Means Clustering
Eines dieser Verfahren ist die k-Means-Clustering-Methode. In einem ersten Schritt (Abbildung 1) bestimmt man dabei zunächst k Cluster-Zentren. Dabei können zufällig ausgewählte Datenpunkte als Cluster-Zentren dienen. Anschließend legt man die Zugehörigkeit aller Datenpunkte zu je einem der Cluster fest. Dazu weist der Algorithmus jeden Datenpunkt dem Cluster zu, dessen Zentrum ihm am nächsten liegt. Das erfolgt in der Regel durch die Berechnung des euklidischen Abstands zwischen jedem Datenpunkt und den Zentren.
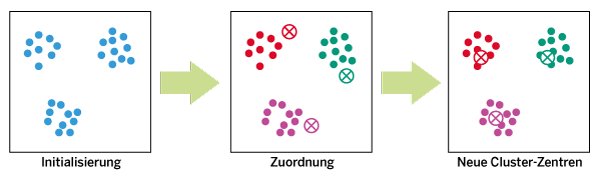
Abbildung 1: Die ersten Schritte beim k-Means-Clustering, der letzte wird im Bedarfsfall wiederholt.
Danach werden neue Cluster-Zentren derart berechnet, dass das neue Zentrum den Schwerpunkt (Durchschnitt) aller Datenpunkte in jedem Cluster bildet. Anschließend ordnet der Algorithmus die Datenpunkte den nun neuen Zentren nach Maßgabe der Nähe zum Zentrum erneut zu, wobei einzelne Punkte ihre Cluster wechseln können. Nach der wiederholten Berechnung der Zentren wird jedes Mal geprüft, ob die Rechnung konvergiert. Das ist der Fall, wenn sich die Cluster-Zentren im Vergleich zur vorherigen Iteration nicht ändern. In diesem Fall ist der k-Means-Algorithmus zum Ende gekommen. Liegt noch keine Konvergenz vor, erfolgt eine nächste Iteration, bis das Konvergenzkriterium erfüllt ist.
Da k-Means-Clustering lediglich ein lokales Minimum des Clustering Objective auffinden kann, hängt das Ergebnis des Algorithmus von den zufälligen Cluster-Zentren während der Initialisierung ab. Normalerweise initialisiert man k-Means-Clustering deshalb mit verschiedenen Clustering-Zentren, bis man eine möglichst gute Zuordnung der Datenpunkte erzielt. Die Qualität des Clusterings lässt sich anhand des Clustering Objective beurteilen. Die Zeitkomplexität dieses Verfahrens steigt linear mit den Datenpunkten und liegt bei O(T k N d), wobei T die maximale Anzahl von Iterationen bezeichnet, bis der Algorithmus konvergiert. Das bedeutet, dass sich das k-Means-Verfahren auch auf große Datensätze effizient anwenden lässt.
Den Hyperparameter k, die Zahl der Cluster, muss der Anwender des k-Means-Clustering-Verfahrens selbst bestimmen. Dafür eignet sich das sogenannte Elbow-Verfahren (Abbildung 2). Dabei lässt man den k-Means-Algorithmus mit verschiedenen k-Werten laufen. Für jeden k-Wert wird der Wert des Clustering Objective bestimmt. Trägt man nun das Clustering Objective als Funktion von k auf, so nimmt es zunächst ab und verläuft dann ab einem bestimmten k-Wert flach. Die Form des Graphen erinnert an die Form eines Ellenbogens, daher auch der Name. Der Wert am Knickpunkt des Ellenbogens stellt den k-Wert dar, der die optimale Anzahl Cluster angibt.
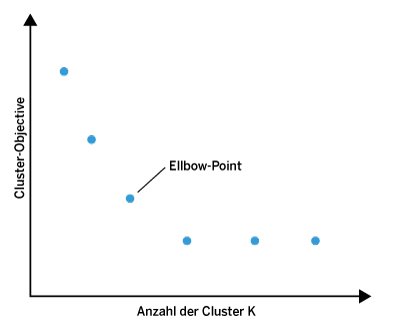
Abbildung 2: Das Elbow-Verfahren bestimmt die optimale Anzahl an Clustern.
K-Means++
Das k-Means-Verfahren liefert oft schon brauchbare Clustering-Ergebnisse, hat allerdings auch einige Schwächen. Um diese zu adressieren, wurde k-Means++ als Verbesserung des klassischen Algorithmus entwickelt.
Der ursprüngliche k-Means-Algorithmus hängt unter anderem stark von der zufälligen Auswahl der anfänglichen Cluster-Zentren ab. Je nachdem, welche Punkte man als anfängliche Zentren auswählt, kann der Algorithmus in verschiedene lokale Minima des Clustering Objective konvergieren und unterschiedliche Ergebnisse liefern. Deshalb führt k-Means++ eine verbesserte Initialisierung ein, die die Wahrscheinlichkeit schlechter Ausgangszentren reduziert. Dazu initialisiert es die Cluster-Zentren so, dass sie weiter auseinander liegen, sodass sie in der Regel schneller konvergieren.
Zunächst wählt k-Means++ zufällig einen Datenpunkt als erstes Cluster-Zentrum aus. Dann berechnet der Algorithmus für jeden Datenpunkt dessen Abstand zum nächstgelegenen zuvor gewählten Zentrum. Danach wählt er das nächste Zentrum so aus den Datenpunkten aus, dass der Punkt mit dem größten Abstand zum nächsten Zentrum am wahrscheinlichsten als Nächstes an die Reihe kommt. Diese Schritte wiederholen sich, bis alle k-Zentren ausgewählt sind. Diese Art der Initialisierung vermeidet die Schwachstellen des k-Means-Verfahrens.
Hierarchiebasiertes Clustering
Das hierarchiebasierte Clustering kommt ohne Cluster-Zentren aus. Es beruht darauf, naheliegende Datenpunkte in einem Cluster zusammenzufassen. Im ersten Schritt betrachtet es dazu jeden Datenpunkt als eigenen Cluster. Danach identifiziert es die beiden Cluster, deren Zentren den geringsten Abstand zueinander haben, und fasst sie zusammen. Diese Schritte werden wiederholt, bis alle Datenpunkte zu einem Cluster zusammengefasst sind. Das ergibt eine Hierarchie von Clustern, deren grafische Darstellung man als Dendrogramm bezeichnet. Dabei handelt es sich um ein Baumdiagramm, das die Schritt-für-Schritt-Fusion der Cluster zeigt.
Abbildung 3 zeigt ein Beispiel für die sechs Datenpunkte A bis F. Zuerst fasst der Algorithmus die Datenpunkte A und B sowie (E und F) zusammen, danach fusioniert er den Cluster (E,F) mit dem Datenpunkt D zu einem Cluster. Der so entstandene Cluster wird im nächsten Schritt mit Datenpunkt C in einem neuen Cluster zusammengeführt. In einem letzten Schritt fließt dieser Cluster dann mit dem Cluster (A,B) zusammen. Auf diese Weise entsteht das abgebildete Dendrogramm.
Am oberen Ende des Dendrogramms sind alle Datenpunkte in einem Cluster zusammengefasst. Man schneidet das Dendrogramm dann in einer bestimmten Höhe ab, um die gewünschte Anzahl von Clustern zu erhalten. Dieser Schritt wird oft als Schwellwertfestlegung oder Cut-off-Punkt bezeichnet. Die gewünschte Anzahl von Clustern und die Einteilung in Cluster ergibt sich aus der Festsetzung eines entsprechenden Schwellwerts.
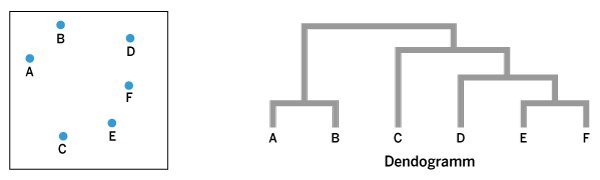
Abbildung 3: Das Dendrogramm entsteht beim hierarchischen Clustern aus der Gruppierung der jeweils zueinander nächstgelegenen Datenpunkte.
Fazit
Clustering-Verfahren sind vielseitige Werkzeuge zur Identifizierung von Mustern in Daten. Sie kommen bei der Kundensegmentierung im Marketing, der medizinischen Diagnose, der Textanalyse, der Optimierung von Finanzportfolios, der Verkehrsflussanalyse und vielen anderen Anwendungen zum Einsatz. Zum Beispiel helfen sie Unternehmen, Kundenpräferenzen zu verstehen, unterstützen Ärzte bei der Diagnosestellung, helfen News-Aggregatoren bei der Organisation von Inhalten und erleichtern Investoren die Portfolioverwaltung. Clustering trägt dazu bei, versteckte Strukturen in Daten zu enthüllen und datengesteuerte Entscheidungen zu treffen. Zentroidbasierte Clustering-Verfahren gehören zu den am häufigsten eingesetzten Methoden des Clusterings. (jcb/jlu)




