

Ein Teilbereich des überwachten maschinellen Lernens ist die Klassifikation. Dazu kommen häufig Entscheidungsbäume zum Einsatz.
Ein typisches Beispiel für eine binäre Klassifikation ist das Erkennen von Spam-Mails. Dabei gibt es mit “Spam” und “Kein Spam” nur zwei Klassen. Will man dagegen beispielsweise handgeschriebene Ziffern erkennen, hat man es mit einem Multiklassenproblem mit zehn verschiedenen Klassen (einer pro Ziffer) zu tun.
In jedem Fall aber hat der Anwender das Ziel, sein Klassifikationsmodell anhand von vorhandenen, beschrifteten Trainingsdaten so zu trainieren, dass es auch bisher nicht gesehene und nicht im Trainingsset enthaltene Daten verlässlich der richtigen Klasse zuordnet. Es gibt eine große Zahl verschiedener Klassifikationsmodelle, angefangen bei einfachen linearen Modellen bis hin zu komplexen neuronalen Netzwerken, die anspruchsvolle Aufgaben bewältigen können.
Entscheidungsbäume
Eines der einfachsten Verfahren zur Klassifikation von Daten, das aber trotzdem leistungsfähig ist, nutzt Entscheidungsbäume. Die haben unter anderem den Vorteil, dass sie sich einfach nachvollziehen und selbst für Daten mit hochdimensionalen Feature-Räumen effizient konstruieren lassen.
Wie der Name andeutet, modellieren Entscheidungsbäume die Beziehung zwischen Features und Labels (Klassen) mithilfe einer Baumstruktur. Das Ziel besteht darin, anhand der Features die Zugehörigkeit zu einer Klasse vorherzusagen. Durch das Aufteilen der Daten anhand der Features entstehen möglichst homogene Gruppen, die man wiederum in weitere möglichst homogene Gruppen unterteilt. Entscheidungsbäume starten dabei mit einem Wurzelknoten, der alle Daten enthält. In weiteren Schritten werden die Daten weiter an internen Knoten verteilt, indem man bestimmte Features untersucht. Die Teilung wird so lange fortgeführt, bis ein Blattknoten des Baums erreicht ist. Das in diesem Blattknoten enthaltene Label ist dann die Klassifikationsvorhersage des Baums.
Diese zunächst etwas abstrakt anmutende Arbeitsweise lässt sich anhand eines einfachen Beispiels veranschaulichen: Ein Entscheidungsbaum soll anhand der Breite und Länge einer Frucht herausfinden, ob es sich dabei um einen Apfel oder um eine Birne handelt. Äpfel neigen dazu, kurz und rundlich zu sein, Birnen sind normalerweise größer und schlanker. Man kann nun einen Entscheidungsbaum darauf trainieren, anhand der Länge und Breite Äpfel von Birnen zu unterscheiden. Dieser Baum könnte beispielsweise wie in Abbildung 1 aussehen.
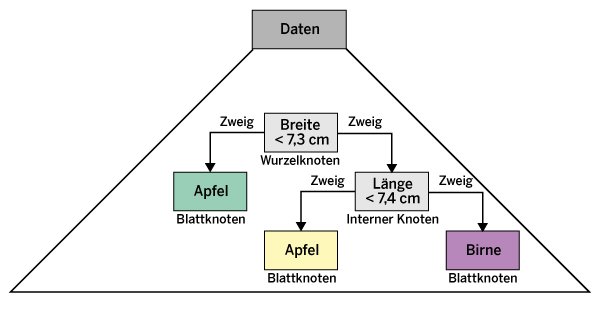
Abbildung 1: Das Modell eines Entscheidungsbaums, der Apfel und Birnen anhand ihrer Länge und Breite klassifiziert.
Der Wurzelknoten inspiziert hier zunächst die Breite. Ist sie geringer als 7,3 Zentimeter, endet der Baum direkt in einem Blattknoten mit einer Entscheidung für Apfel. Bei einer größeren Breite muss man zusätzlich noch die Länge durch einen weiteren internen Knoten inspizieren. Die entsprechende Entscheidung führt dann ebenfalls wieder in einen Blattknoten. Das hier gewählte Beispiel ist einfach, da die Daten nur zwei Features besitzen (Breite und Länge) und der resultierende Baum klein ausfällt. Allerdings lassen sich auf dieselbe Weise auch Daten mit deutlich höherdimensionalen Feature-Räumen konstruieren. Die Bäume können dann signifikant größer sein und sehr viele Zweige und interne Knoten enthalten.
Eine wichtige Frage klärt dieses Beispiel allerdings noch nicht: Warum sind die Knoten und Zweige exakt so gewählt, wie gezeigt? Warum untersucht der Wurzelknoten beispielsweise die Breite und nicht erst die Länge? Idealerweise sollte bei jeder Aufteilung in einem Knoten ein Feature der Daten untersucht werden, und nach der Aufteilung sollten die Daten in den darunterliegenden Knoten möglichst homogen ausfallen. Auf jeden Fall sollten die Daten der Kindknoten homogener sein als vor der Aufteilung in den Elternknoten. Das Ziel besteht also darin, dass die Knoten beim Abstieg im Baum immer reiner werden. Es gilt also, die Features für die Aufteilung so zu wählen, dass dieser Anstieg der Knotenreinheit maximiert wird. Das ist das Optimierungskriterium von Entscheidungsbäumen.
An dieser Stelle steht man vor der Frage, wie man diese (Un-)Reinheit mathematisch erfassen kann und wie man basierend darauf die Features und deren Werte zur Aufteilung im Knoten wählt. Dazu dienen hauptsächlich zwei verschiedene Methoden: die Gini- und die Entropie-Unreinheit. Die Gini-Unreinheit misst man auf einer Skala von 0 bis 1, wobei 0 für perfekte Reinheit steht (alle Datenpunkte gehören derselben Klasse an) und 1 für maximale Unreinheit (die Klassen sind gleichmäßig gemischt).
Bekannt ist der Gini-Index übrigens dafür, dass ihn Ökonomen verwenden, um die Ungleichverteilung der Einkommen innerhalb der Bevölkerung eines Landes zu messen. Diese Statistik führt Südafrika mit einem Gini-Koeffizienten von 0,63 an. In der entsprechenden Top-Ten-Liste finden sich viele weitere Staaten Afrikas. Das bedeutet, dass dort wenige sehr gut verdienende, reiche Menschen vielen anderen gegenüberstehen, die kaum ein Einkommen haben und sehr arm sind. Die Einkommensverteilung ist also sehr ungleich.
Mathematisch ist die Gini-Unreinheit durch folgende Gleichung über den Anteil der Datenpunkten in den entsprechenden Klassen im Knoten definiert:
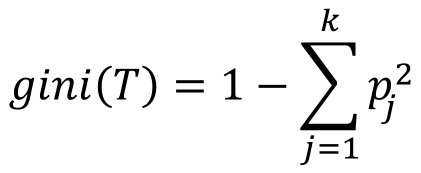
pj ist hier der Anteil der Datenpunkte im Knoten, die zur Klasse j gehören. Um die Gini-Unreinheit zu berechnen, muss man also die relativen Häufigkeiten der einzelnen Klassen in der Datenmenge ermitteln und dann die Summe der Quadrate dieser relativen Häufigkeiten von 1 subtrahieren.
Zur Entscheidung für ein Feature und einen Wert zur Aufteilung geht der Algorithmus dann wie folgt vor: Er wählt ein zufälliges Feature und einen Wert dafür basierend auf den Daten aus. Dann bestimmt er zunächst im aufzuteilenden Knoten und dann in allen darunterliegenden Knoten die Gini-Unreinheit. Diese verschiedenen Gini-Unreinheiten der Kindknoten fasst der Algorithmus dann zu einem gewichteten Mittelwert zusammen und vergleicht ihn mit der Gini-Unreinheit des Elternknotens. Das Feature und den Wert zur Aufteilung variiert man dann so lange, bis ein minimaler Wert für die Unreinheit in den Kindknoten gefunden wurde. Nach diesem Feature und Wert wird der Elternknoten dann aufgeteilt. Dasselbe passiert dann mit allen weiteren Knoten.
Das Vorgehen bei der Entropie-Unreinheit ist analog. Sie erreicht ihren minimalen Wert von 0 ebenfalls, wenn alle Datenpunkte im Knoten derselben Klasse angehören und damit maximale Reinheit vorliegt:
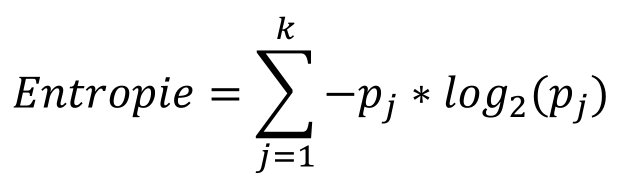
Das Konstruktionsverfahren des Entscheidungsbaums mit der Entropie-Unreinheit folgt demselben Schema wie das der Gini-Unreinheit: Sowohl bei der Gini- als auch bei der Entropie-Unreinheit wird die Datenunreinheit verwendet, um die beste Aufteilung der Daten in Untergruppen zu ermitteln, um möglichst homogene Klassen in den resultierenden Knoten zu erhalten. Ein niedriger Gini- oder Entropie-Wert deutet auf eine bessere Trennung der Klassen hin und wird daher bei der Baumkonstruktion bevorzugt. Beide Unreinheitsmaße lassen sich in der Entscheidungsbaum-basierten Klassifikation verwenden, und die Wahl zwischen Gini-Unreinheit und Entropie-Unreinheit hängt oft von den spezifischen Anforderungen des Problems und der Art der Daten ab. In der Praxis erzeugen sie jedoch oft ähnliche Entscheidungsbäume.
Nachdem ein Entscheidungsbaum mit einer dieser Methoden trainiert wurde, kann er präzise Vorhersagen zu der Klasse der Daten machen.
Zufallswald
Ein Problem der Entscheidungsbäume ist allerdings, dass die genaue Struktur eines Baums sehr stark von den Trainingsdaten abhängt. Ändern sich die Trainingsdaten geringfügig, können komplett andere Bäume entstehen. Das führt dann auch dazu, dass sich die Vorhersagen der Bäume ändern – ein Problem, da ein Klassifikationsmodell ja stabile Vorhersagen zur Klasse machen soll. Diese Stabilität kann man durch sogenannte Zufallswald-Modelle erreichen.
Ein Zufallswald nutzt die Ergebnisse einer Vielzahl verschiedener Entscheidungsbäume, um bestmögliche Entscheidungen oder Vorhersagen zu treffen. Die Entscheidungsbäume werden dabei nach einem Zufallsprinzip unkorreliert erstellt. Jeder Baum trifft für sich eine einzelne Entscheidung. Indem er die Einzelentscheidungen verrechnet, kann der Algorithmus dann eine endgültige Entscheidung liefern. Das Zufallswald-Verfahren gehört zu den Ensemble-Methoden, da es auf einem Ensemble von Bäumen beruht, die zusammen eine Entscheidung treffen.
Der Zufallswald bietet gegenüber anderen Algorithmen zur Klassifikation zahlreiche Vorteile. Im Gegensatz zu anderen Modellen und Verfahren des maschinellen Lernens, die beispielsweise auf neuronalen Netzen basieren, bleiben die Entscheidungen eines Zufallswalds nachvollziehbar. Warum eine bestimmte Entscheidung getroffen wurde, geht nicht wie in einem neuronalen Netz in einer Art Blackbox unter. Die Anforderungen, die der Zufallswald-Algorithmus an die Hardware und deren Rechenleistung stellt, sind ebenfalls geringer als beispielsweise bei neuronalen Netzen.
Damit der Zufallswald gute Ergebnisse liefert, dürfen die einzelnen Entscheidungsbäume nicht zu stark miteinander korreliert sein. Hierzu wird unter anderem das Bagging-Verfahren (Bootstrap Aggregation) herangezogen. Dieses Verfahren trainiert die verschiedenen Entscheidungsbäume des Walds basierend auf unterschiedlichen Subsets der Trainingsdaten. Dadurch hat jeder Baum des Walds eine etwas andere Struktur, was die Korrelation zwischen den verschiedenen Bäumen minimiert.
Jeder Baum wird auf einem Trainingsdatensatz mit der ursprünglichen Länge trainiert, obwohl mit der Probe nur ein Teil des Datensatzes entnommen wurde. Das klappt, indem man das kürzere Sample mit vorhandenen Werten auf die ursprüngliche Länge auffüllt. Angenommen, die Trainingsdaten sind die Liste [1,2,3,4,5,6]+ mit der Länge 6. Ein mögliches Sample daraus ist [1,2,4,6]+, das man um die 2 und die 6 erweitert, sodass wieder eine Liste der Länge 6 entsteht: [1,2,2,4,6,6]. Mit dieser Methode trainiert man ein Ensemble von Entscheidungsbäumen, die dann zusammen den Zufallswald bilden (Abbildung 2, links).
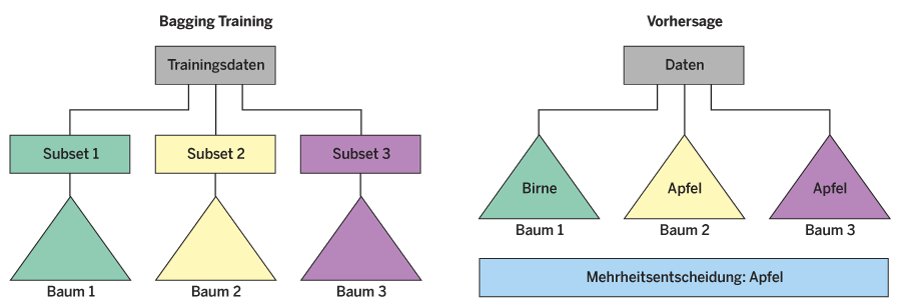
Abbildung 2: So arbeitet ein Zufallswald: Zuerst klassifizieren mehrere Entscheidungsbäume dasselbe Objekt parallel, dann entscheidet die Mehrheit.
Ist der Zufallswald entsprechend trainiert, kann er neue Daten klassifizieren. Dabei trifft jeder Entscheidungsbaum des Zufallswalds eine Entscheidung bezüglich der Klasse der neuen und bisher noch nicht gesehenen Eingabedaten. Anschließend werden alle Entscheidungen der Bäume betrachtet und die Klasse mit den meisten Stimmen als Vorhersage des Zufallswalds ausgewählt (Abbildung 2, rechts). Aufgrund der großen Zahl an Entscheidungsbäumen sind die Vorhersagen des Zufallswalds deutlich verlässlicher und stabiler als die einzelner Entscheidungsbäume.
Fazit
Es gibt verschiedene Modelle, mit denen sich Daten klassifizieren lassen. Obwohl es sich bei den Entscheidungsbäumen und Zufallswald-Modellen um recht einfache Verfahren handelt, haben sie zahlreiche Vorteile. Insbesondere können sie effizient konstruiert werden und erlauben es, die Entscheidungen nachzuvollziehen. Gerade der letzte Punkt ist ein großer Vorteil gegenüber anderen Verfahren wie neuronalen Netzen, deren Vorhersagen sich praktisch nicht nachvollziehen lassen. (jcb/jlu)




