

Regressionsmodelle sollen eine mathematische Funktion so modellieren, dass sie sich bestmöglich an Trainingsdaten anpasst. Dann lässt sich mit ihrer Hilfe eine Vorhersage für neue Werte berechnen, bei denen man das Ergebnis noch nicht kennt.
Algorithmen des überwachten, maschinellen Lernens basieren auf beschrifteten Trainingsdaten, denen jeweils sowohl Features (Eigenschaften) als auch Labels (Benennungen) zugeordnet sind. Das Ziel des überwachten Lernens besteht darin, einen Zusammenhang zwischen den Features und den Labels zu erlernen. Dazu wird ein mathematisches Modell basierend auf den Trainingsdaten optimiert, um dann die Labels neuer Datensätze vorhersagen zu können, sobald deren Features bekannt sind. Es gibt zwei Arten des überwachten Lernens: die Regression und die Klassifikation.
Bei der Regression trainiert man einen Algorithmus darauf, einen Wert aus einem kontinuierlichen Bereich möglicher Werte vorherzusagen. Das ist der Unterschied zur Klassifikation: Dort bestehen die Labels nicht aus kontinuierlichen Daten, sondern aus Klassen. Ein Beispiel für ein Regressionsproblem ist die Vorhersage von Immobilienpreisen (Labels) basierend auf Eigenschaften der Immobilie (Features). Ein solches Regressionsmodell würde mithilfe einer Immobiliendatenbank trainiert und ließe sich dann für die Bewertung von Immobilien verwenden.
Konkret könnte das Modell durch Angabe von Eigenschaften (Features) der Immobilie wie Lage, Baujahr, Fläche, Ausstattung und so weiter dann den Preis (Label) vorhersagen. In diesem Beispiel hängt das Label von mehreren Features ab. Der Feature-Raum ist also multidimensional. In einfachen Anwendungen können die Labels von nur einem Feature abhängen. Man spricht dann von einem eindimensionalen Feature-Raum.
Alle Regressionsmodelle haben gemeinsam, dass das Modell den Zusammenhang zwischen Features und kontinuierlichen Labels erlernt. Es handelt sich um mathematische Modelle, die einen funktionalen Zusammenhang zwischen den Features und Labels beschreiben. Die Vielfalt an Regressionsmodellen beruht auf den verschiedenen mathematischen Methoden und Funktionen, die man zur Darstellung dieses Zusammenhangs heranziehen kann. Die Modelle hängen von verschiedenen Parametern ab, die man dann während des Lernprozesses so optimiert, dass das Modell die Trainingsdaten möglichst gut beschreibt.
Lineare Regression
Lineare Regression ist das einfachste mathematische Modell [1]. Es versucht, die Trainingsdaten durch eine lineare Gleichung zu beschreiben, die die Korrelation zwischen den Features und Labels am besten repräsentiert.
Abbildung 1 zeigt ein schematisches Beispiel. Die x-Achse stellt hier das Feature der Daten dar. Prinzipiell kann es auch mehrere Features geben. Im Immobilienbeispiel wären das der Zustand des Hauses, das Baujahr und so weiter. Die y-Achse stellt das Label dar. Im Fall der Immobilien wäre dies deren Preis. Die Trainingsdaten erscheinen in diesem Graphen als Symbole und folgen einem linearen Trend.
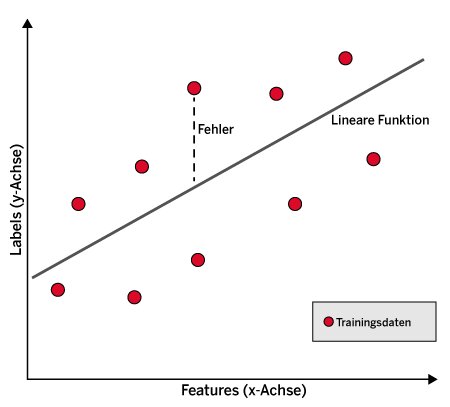
Abbildung 1: Bei der linearen Regression repräsentiert eine Gerade den Zusammenhang zwischen Labels und Features.
Eine Anwendung dieser Art von Regression ist nur sinnvoll, wenn tatsächlich ein solcher linearer Trend vorliegt. Das Ziel der linearen Regression besteht nun darin, anhand der Trainingsdaten eine Gerade (eine lineare Funktion) zu finden, die möglichst nahe an den Daten liegt. Eine solche Gerade wird bei nur einem Feature durch die folgende lineare Funktion beschrieben:
y = w * x + b
In dieser Gleichung beschreibt w die Steigung der Geraden und b den y-Achsenabschnitt. Der Algorithmus versucht die beiden Parameter so zu wählen, dass sie die Trainingsdaten möglichst gut beschreiben, dass also die Gerade einen möglichst kleinen Abstand zu allen Datenpunkten hat.
Um zu bestimmen, wie gut die gewählte lineare Funktion die Trainingsdaten beschreibt, bestimmt man eine sogenannte Kostenfunktion. Sie besteht aus der Summe der Quadrate der Differenz zwischen den Datenpunkten und der linearen Funktion (dem Fehler). Je kleiner diese Differenzen ausfallen, umso besser beschreibt die lineare Funktion die Trainingsdaten. Ziel des maschinellen Lernens bei der linearen Regression ist es, diese Kostenfunktion zu minimieren.
Das Optimierungsproblem tritt bei zahlreichen Verfahren des maschinellen Lernens auf und lässt sich mit dem sogenannten Gradientenabstiegsverfahren lösen. Dabei handelt es sich um eine allgemeine Methode der Numerik, um mathematische Optimierungsprobleme zu lösen. Die Idee besteht darin, die Parameter des Modells entlang der Richtung der negativen Ableitung (Gradienten) iterativ zu variieren (Abbildung 2).
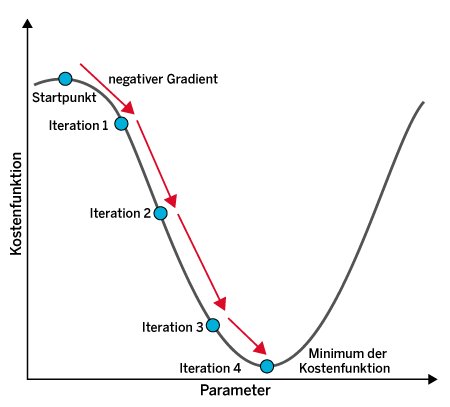
Abbildung 2: Das Gradientenabstiegsverfahren variiert die Parameter des Modells iterativ entlang der Richtung der negativen Ableitung.
Bei der linearen Regression dient das Gradientenabstiegsverfahren dazu, die Kostenfunktion zu minimieren. Dabei bestimmt man den Gradienten bezüglich der beiden Parameter w und b des Modells. Das Iterationsverfahren stoppt, wenn sich die Parameter mit jeder weiteren Iteration nicht mehr stark ändern, also das Verfahren konvergiert. Die so erhaltenen Parameter w und b bestimmen dann die optimale lineare Funktion, um die Trainingsdaten zu beschreiben.
Die einzelnen Schritte des Gradientenabstiegsverfahrens lassen sich wie folgt zusammenfassen:
- Man wählt zunächst zufällige Werte für die Modellparameter (hier für w und b).
- An diesem Punkt bildet man die Ableitung der Kostenfunktion und ermittelt die steilste Steigung (also den Gradienten).
- Es erfolgt eine Aktualisierung der Parameter in Richtung der negativen Ableitung (negativer Gradient). Dabei bestimmt eine Lernrate die Größe der Schritte. Bei der Lernrate handelt es sich um eine kleine Zahl, die man als Vorfaktor vor den Gradienten schreibt.
- Der zweite und dritte Schritt wiederholen sich so lange, bis sich die Parameter w und b durch die Iteration nicht mehr ändern.
Die auf diese Weise erhaltenen Parameter w und b lassen sich dann für Vorhersagen des Modells verwenden.
Polynominale Regression
In der Praxis kann die Beziehung zwischen den Features und Labels nichtlinear ausfallen. Der Versuch, eine lineare Regression zu verwenden, führt dann zu einem schlecht passenden Modell. Eine polynominale Regression bietet die Möglichkeit, eine nichtlineare Beziehung zwischen den Features und den Labels zu berücksichtigen:
y = w0 + w1 * x1 + … + wM * xM
In dieser Gleichung bezeichnet M den Grad des Polynoms. Dabei entspricht M=1 der linearen Regression. Polynome höheren Grades berücksichtigen auch Terme mit x2, x3, x4 und so weiter, die über eine lineare Funktion hinausgehen.
Bei der polynominalen Regression stellt sich die Frage, wie genau man den Grad M des Polynoms wählen soll, um ein gutes Modell für die zugrunde liegenden Trainingsdaten zu erhalten. Je höher M, umso besser kann sich das Modell an nichtlineare Beziehungen zwischen den Features und Labels anpassen. Allerdings sollte man M auch nicht zu groß wählen, da das Modell sonst zu flexibel arbeitet und es dann die Daten überangepasst hat.
Dieses als Overfitting (Überanpassung) bezeichnete Phänomen gilt es stets zu vermeiden, um sinnvolle Modelle zur Beschreibung der Daten zu erhalten. Overfitting ist ein allgemeines Problem zu komplexer Modelle. In der Statistik bedeutet Überanpassung die Spezifizierung eines Modells, das zu viele Parameter zur Beschreibung der Daten enthält. So hat ein Polynom mit großem Grad M zu viele Parameter in Form der Koeffizienten w0, w1, w2 und so fort.
Im Kontext des maschinellen Lernens führt Overfitting dazu, dass das Modell zwar die Trainingsdaten exzellent beschreibt, nicht aber andere Testdaten. Das Modell generalisiert also nicht gut und ist damit unbrauchbar. Auf der anderen Seite sollte das Modell auch nicht zu einfach ausfallen. Beispielsweise führt die Wahl von M=1 (lineare Regression) zu einem schlechten Modell für nichtlineare Daten.
Die Wahl eines zu einfachen Modells zur Beschreibung von Trainingsdaten bezeichnet man als Underfitting (Unteranpassung). Es gilt also, den Grad des Polynoms so zu wählen, dass man sowohl Under- als auch Overfitting vermeidet.
Modelle für komplexe Daten
Oft fallen die vorliegenden Trainingsdaten derart komplex aus, dass selbst die polynominale Regression keine guten Ergebnisse liefert. Bereits das oben genannte Immobilienbeispiel lässt sich nicht vernünftig durch lineare oder polynominale Regression darstellen. In diesem Fall muss man ein Modell wählen, das genügend flexibel ist, um auch komplexere Zusammenhänge zwischen Features und Labels zu beschreiben.
Hier spielen neuronale Netzwerke eine entscheidende Rolle, die praktisch jeden funktionalen Zusammenhang zwischen Features und Labels darstellen können. Es gibt sogar ein mathematisches Theorem, das sogenannte Universal-Approximation-Theorem [2], das besagt, dass ein geeignet gewähltes neuronales Netzwerk fast jede mathematische Funktion beliebig gut annähern kann. Diese theoretische Aussage garantiert also, dass egal, wie komplex der Zusammenhang zwischen Features und Labels auch ausfällt, es immer ein neuronales Netzwerk gibt, das den Zusammenhang zu beschreiben vermag.
Fazit
Regressionsprobleme im Rahmen des überwachten Lernens lassen sich mit zahlreichen verschiedenen Regressionsmodellen angehen, die sich in ihrer mathematischen Form unterschieden. Nicht jedes Modell kann man auf beliebige Trainingsdaten anwenden. Lineare Regression setzt beispielsweise voraus, dass die vorliegenden Daten intrinsisch einen entsprechenden Zusammenhang vorweisen. Neuronale Netzwerke stellen die leistungsfähigsten Modelle dar, um komplexe funktionale Zusammenhänge zu beschreiben. (jlu)
Infos
-
Lineare Regression: https://de.wikipedia.org/wiki/Lineare_Regression
-
Universal-Approximation-Theorem: https://en.wikipedia.org/wiki/Universal_approximation_theorem




