

Maschinelles Lernen ist eine revolutionäre Technologie, die unser tägliches Leben und verschiedene Branchen einschneidend verändert. Es ermöglicht Computern, aus Daten zu lernen und Vorhersagen zu treffen, ohne dass man sie dafür explizit programmieren muss.
Das maschinelle Lernen ist ein Teilgebiet der künstlichen Intelligenz. Es beschäftigt sich mit der Entwicklung von Algorithmen und Modellen, die es Computern ermöglichen, aus Daten zu lernen und sich dann zu entscheiden oder Vorhersagen zu treffen, ohne für das jeweilige Problem explizit programmiert worden zu sein. Maschinelles Lernen basiert auf statistischen Methoden und ermöglicht es Computern, Muster und Zusammenhänge in großen Datenmengen zu erkennen.
Der Hauptvorteil des maschinellen Lernens gegenüber der traditionellen Programmierung besteht darin, dass es mit Eingabedaten flexibler umgeht. Abstrakt gesprochen stellt jedes Computerprogramm eine Funktion oder Abbildung dar, die eine Eingabe in eine Ausgabe umwandelt. Traditionelle Programme verwenden Regeln und Vorschriften, um die Eingabedaten in die Ausgabedaten zu überführen. Bei komplexen Aufgaben, wie Sprach- oder Bilderkennung, geraten diese regelbasierten Ansätze aber an ihre Grenzen, da sie nicht flexibel genug sind, um all die verschiedenen Eingabedaten zu verarbeiten.
Maschinelles Lernen, in diesem Fall sogenanntes überwachtes maschinelles Lernen, hilft hier weiter: Statt anhand in Code gegossener Algorithmen lernen diese Systeme die Regeln selbst. Dazu nutzen sie vorgegebene Eingabe-Ausgabe-Paare, die Trainingsdaten. Kein Entwickler muss sie programmieren (Abbildung 1).

Abbildung 1: Eine schematische Darstellung der Transformation von Ein- in Ausgabedaten bei klassischer Programmierung und KI.
ML-Varianten
Das maschinelle Lernen (ML) lässt sich in drei Hauptkategorien unterteilen (Abbildung 2): überwachtes, unüberwachtes und verstärkendes Lernen.
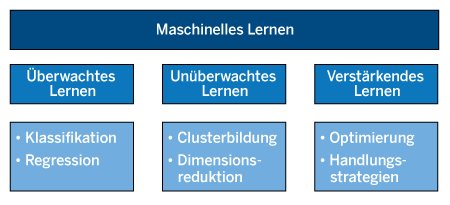
Abbildung 2: Die hauptsächlichen Kategorien beim maschinellen Lernen.
Beim überwachten Lernen nutzt der Algorithmus beschriftete Trainingsdaten, um Vorhersagen für neue, unbekannte Daten zu treffen. Beschriftet bedeutet in diesem Kontext, dass zu vorgegebenen Eingaben (Features) auch die Ausgaben (Labels) vorliegen. Der Algorithmus versucht dann, Regeln zu finden, um die Eingaben mit den Ausgaben zu verknüpfen.
Klassifikation und Regression sind beim überwachten Lernen gängige Aufgaben. Die Klassifikation hat das Ziel, Daten in bestimmte Klassen einzuteilen. Beim Erkennen von Spam-Mails handelt es sich beispielsweise um ein binäres Klassifikationsproblem: Liegt eine Spam-Mail vor oder nicht? Bei der Regression sollen hingegen konkrete Werte vorhergesagt werden. Die Vorhersage von Aktienkursen stellt beispielsweise ein Regressionsproblem dar.
Allgemein ist es beim überwachten Lernen wichtig, dass der Algorithmus aus den Trainingsdaten den allgemeinen Zusammenhang zwischen den Features und den Labels erlernt. ML zielt also nicht darauf ab, einfach nur perfekt die Trainingsdaten zu reproduzieren, sondern auch darauf, weitere Testdaten korrekt zu behandeln. Ist der Algorithmus dazu nicht in der Lage, kann das ein Problem der sogenannten Überanpassung sein, die es zu vermeiden gilt.
Unüberwachtes Lernen verzichtet auf beschriftete Daten. Es liegen also nur Features vor, aber keine Labels. In diesem Fall dient der Algorithmus nicht dazu, einen Zusammenhang zwischen Features und Labels zu finden – Letztere gibt es ja hier gar nicht. Vielmehr versucht er, Einsichten über die Features selbst zu erlangen. Methoden des unüberwachten Lernens erkennen beispielsweise eigenständig Muster und Strukturen in den Daten, zum Beispiel durch Cluster-Bildung.
Bei hochdimensionalen und komplexen Daten können Methoden des unüberwachten Lernens auch die Dimensionalität der Daten reduzieren und so die weitere Verarbeitung vereinfachen. Das unüberwachte Lernen eignet sich also gut für die Entdeckung von verborgenen Mustern und das Erkunden von Datensätzen. Ein typisches Beispiel aus dem Bereich des Marketings ist die Segmentierung von Kundendaten, um zu erkennen, ob bestimmte Kundengruppen sich speziell für bestimmte Produkte interessieren.
Neben dem überwachten und unüberwachten Lernen gibt es noch das verstärkende Lernen, das sich grundsätzlich von den beiden anderen Arten des maschinellen Lernens unterscheidet. Beim verstärkenden Lernen interagiert ein Algorithmus mit einer Umgebung und wird für bestimmte Aktionen belohnt oder bestraft. Das Ziel besteht darin, eine optimale Handlungsstrategie zu entwickeln. Der Algorithmus lernt durch Ausprobieren verschiedener Aktionen. Er optimiert dabei seine Strategie so, dass er möglichst viele Belohnungen erhält. Verstärkendes Lernen kommt häufig in der Robotik, bei autonomen Systemen und für die Planung von Spielen zum Einsatz.
Die bisher genannten Methoden des maschinellen Lernens gehören zu den prädiktiven Methoden. Sie erlauben, Vorhersagen oder Aussagen über Daten zu treffen. Im Gegensatz dazu zielt generatives maschinelles Lernen darauf ab, neue Daten zu erzeugen, die den Trainingsdaten ähneln. Anstatt eine bestimmte Vorhersage zu treffen, lernt das Modell die Verteilung der Trainingsdaten und kann dann neue, bisher ungesehene Daten generieren, die ähnliche Merkmale aufweisen. Diese Modelle werden oft in der Bild- und Textgenerierung eingesetzt. Anwendungen wie ChatGPT verwenden ebenfalls solche generativen Methoden, um die Antworten auf eine Eingabe des Anwenders zu erzeugen.
ML-Anwendungen
Maschinelles Lernen kommt in zahlreichen Anwendungen zum Einsatz. Die Verwendungsgebiete sind heute praktisch unbegrenzt. Die folgende Aufzählung gibt einen Überblick über einige aktuelle Einsatzgebiete.
- Bild- und Spracherkennung: Maschinelles Lernen ermöglicht Computerprogrammen, Bilder zu identifizieren und Sprache zu verstehen. Das umfasst Bereiche wie Gesichtserkennung, automatisches Übersetzen und Chatbots. Durch den Einsatz von neuronalen Netzwerken und Deep Learning haben sich die Leistungsfähigkeit und Genauigkeit dieser Systeme erheblich verbessert.
- Empfehlungssysteme: Unternehmen wie Netflix und Amazon nutzen maschinelles Lernen, um personalisierte Empfehlungen zu generieren, die auf den individuellen Vorlieben und Verhaltensweisen der Nutzer basieren. Diese Empfehlungssysteme analysieren das Nutzerverhalten, um Vorlieben und Interessen zu verstehen und darauf aufbauend passende Produkte, Filme, Musik oder andere Inhalte vorzuschlagen.
- Medizin und Gesundheitswesen: In der Medizin unterstützt maschinelles Lernen Ärzte bei der Diagnostik, dem Entdecken von Mustern in medizinischen Daten und der Entwicklung personalisierter Behandlungspläne. Durch die Analyse von medizinischen Bildern, genetischen Daten und klinischen Informationen können Algorithmen helfen, Krankheiten frühzeitig zu erkennen und die Behandlung zu optimieren.
- Finanzwesen: Maschinelles Lernen wird im Finanzwesen eingesetzt, um Finanzmärkte zu analysieren, Betrugsfälle zu erkennen und Risikobewertungen zu erstellen. Algorithmen können große Mengen von Finanzdaten analysieren und Muster detektieren, die menschliche Analysten möglicherweise übersehen würden. So lassen sich fundierte Entscheidungen treffen und Risiken minimieren.
Das sind nur einige wenige Beispiele für Anwendungen des maschinellen Lernens. Gerade das Aufkommen generativer Methoden wird in naher Zukunft dazu führen, dass maschinelles Lernen immer mehr kreative Aufgaben unterstützt oder gar übernimmt.
Fazit und Ausblick
Maschinelles Lernen ist eine revolutionäre Technologie, die unser tägliches Leben und verschiedene Branchen einschneidend verändert. Es ermöglicht Computern, aus Daten zu lernen und Vorhersagen zu treffen, ohne dass man sie dafür explizit programmieren muss.
Allerdings gibt es auch Herausforderungen im Umgang mit maschinellem Lernen. Die Qualität und Verfügbarkeit von Daten spielt eine entscheidende Rolle, da schlechte Daten zu fehlerhaften Ergebnissen führen können. Zudem müssen Entscheidungen von Algorithmen nachvollziehbar und erklärbar sein, insbesondere bei ethisch sensiblen Anwendungen.
Regressionsmodelle helfen beim maschinellen Lernen: Sie sollen eine mathematische Funktion so modellieren, dass sie sich bestmöglich an Trainingsdaten anpasst. Dann lässt sich mit ihrer Hilfe eine Vorhersage für neue Werte berechnen, bei denen man das Ergebnis noch nicht kennt. Das sehen wir uns in der nächsten Folge dieser Reihe näher an. (jlu)




