

Ohne Regexe kann man sich den Alltag als Benutzer, Entwickler, Autor oder Systembetreuer kaum vorstellen. Das clevere Konzept vereinfacht repetitive Schritte enorm, speziell in Texteditoren wie Vim und Emacs.
Reguläre Ausdrücke – nach ihrer englischsprachigen Bezeichnung “regular expressions” kurz auch als Regex, Regexp oder RE bezeichnet – sind ein fundamentales, durchdachtes Konzept, das jeder IT-Benutzer, Entwickler, Systemadministrator und Autor kennen und zumindest grundlegend beherrschen sollte. Nicht ohne Grund sind Regexe fester Bestandteil der beiden Prüfungen LPIC-1 und CompTIA Linux+.
In der Vergangenheit erschienen in LinuxUser bereits mehrere Artikel zu diesem Thema, beispielsweise zu den Grundlagen regulärer Ausdrücke [1] oder dem automatischen Erzeugen von REs [2]. Der vorliegende Artikel konzentriert sich auf die praktische Anwendung von REs in der täglichen Arbeit mit den Texteditoren Vim und Emacs. Wir loten dabei aus, wie es um die Verfügbarkeit, Nutzbarkeit und praktische Anwendbarkeit regulärer Ausdrücke bei der Erstellung und Modifikation von Text und Programmcode bestellt ist.
Die meisten Anwender kennen sowohl Regexe als solche als auch die Navigation in einem Texteditor als separate Vorgehensweisen. Nach Beobachtung der Autoren wird jedoch die Anwendung regulärer Ausdrücke in Texteditoren oder integrierten Entwicklungsumgebungen (IDEs) nicht gelehrt – dieser Punkt verbleibt bei Ihnen als Anwender auf der Aufgabenliste. Dabei sind Texteditoren essenziell, da Sie damit programmieren und Textdaten erstellen beziehungsweise redigieren. Erst die Kombination aus beiden Vorgehensweisen erlaubt es Ihnen, alle Joker auszuspielen, die Ihnen zur Verfügung stehen.
Historie
Vim und Emacs sind grundlegende, freie und verlässliche Werkzeuge zur Textbearbeitung, die sich seit Längerem einen Stammplatz auf unixoiden Systemen gesichert haben. Die Beherrschung von wenigstens einem der beiden Tools ebnet Ihnen glaubhaft den Weg in den Hacker-Olymp. Alles andere gilt in Fachkreisen häufig als neumodischer Kram für Möchtegerntastendrücker und Mausschubser, die auf Kilometergeld aus sind.
Falls es bei einem Linux-Event Schneeball- oder Wasserschlachten zwischen beiden Lagern gibt, hilft es, vorab zu wissen, in welchem der beiden Teams Sie mitspielen möchten. Atom und Co. bringen selten genügend Mitglieder für eine eigene Mannschaft zustande. Die Präferenzen der Autoren bei der Teamwahl sind da jedoch ganz eindeutig: Gerold gehört seit Jahrzehnten zur Emacs-Fraktion und hat sein Wissen bei Richard Stallman abgeschaut. Frank nutzt hingegen begeistert Vim, dessen Benutzung ihm Sven Guckes (1967–2022) auf seine unverwechselbare Art nahebrachte.
Unterstützte Regex-Dialekte
Listet ein Werkzeug stolz die Unterstützung regulärer Ausdrücke im Funktionsumfang auf, klingt das erst einmal super. Es bedarf aber eines genaueren Blicks darauf, was damit konkret gemeint ist.
Erstens gibt es mehrere Regex-Dialekte und -Implementierungen, die sich in der Schreibweise, im Funktionsumfang und in der Interpretation von Regex teils deutlich voneinander unterscheiden. Zweitens geht aus der Dokumentation des Werkzeugs nicht immer ganz klar hervor, welcher Regex-Dialekt davon als Standardeinstellung des Werkzeugs fungiert. Drittens gilt es, herauszufinden, welche Dialekte bereits vollständig im Werkzeug implementiert wurden und ob die Entwickler für den Dialekt unübliche Erweiterungen hinzugefügt haben, weil es beispielsweise für die Anwendung passte. Mitunter ist auch geplant, den bisher implementierten Umfang in Zukunft noch zu vervollständigen.
Diese Gemengelage erschwert die eindeutige Zuordnung eines Werkzeugs zu einer bestimmten Regex-Kategorie erheblich. Eine Ableitung, welche regulären Ausdrücke Sie überhaupt formulieren und mit dem Werkzeug verwenden können, gerät ohne das Lesen der Dokumentation und intensivem Ausprobieren zum Glücksspiel. Selbst ein Studium des Themas mithilfe Jeffrey Friedls exzellentem Meisterwerk “Mastering Regular Expressions” [3] macht die Situation nicht unbedingt leichter.
Wie Sie sicher bereits ahnen, birgt allein diese Ebene genügend Potenzial für hitzige, häufig religiös geprägte Diskussionen um die Überlegenheit und Brauchbarkeit eines Dialekts oder Werkzeugs. Je nach Regex-Dialekt schreiben Sie bestimmte Muster leichter oder auch umständlicher, das heißt mit Abkürzungen oder zusätzlichen Zeichen. Im Kasten “Regex-Dialekte” finden Sie einen kurzen Abriss zu den häufig genutzten Regex-Dialekten, damit Sie in der Diskussion mithalten können.
Bevor wir genauer auf die verwendeten Dialekte eingehen, beleuchten wir kurz, wo, wie und wozu Sie REs in den beiden Texteditoren benutzen. Hier kommen recht konträre Bedienkonzepte ans Tageslicht, was die Angelegenheit aber auch ungemein spannend macht. Erst besprechen wir Vim, Emacs folgt danach.
Regex-Dialekte
Regexe als solche gehen auf das Jahr 1951 und den Mathematiker Stephen Cole Kleene (1909–1994) zurück. Damals entwickelte er eine mathematisch exakte Beschreibungssprache namens regular events.
Etliche Implementierungs- und Standardisierungsrunden später zeigt sich heute immer noch eine Vielfalt an Regex-Varianten, die nicht leicht auseinanderzuhalten ist. Die wichtigsten Varianten samt ausgewählter Anwendungen unter GNU/Linux zeigt die Tabelle “Übersicht: Regex-Dialekte (Auswahl)”. Manche Anwendungen und Programmiersprachen unterstützen mehrere Dialekte, die Sie dann mittels Schalter oder durch Auswahl der entsprechenden Funktion benutzen [16]. Zu den typischen Vertretern zählen GNU Grep/Egrep (GNU BRE und GNU ERE) sowie die Programmiersprache PHP, die sowohl POSIX ERE, GNU ERE als auch PCRE anbietet.
Mehr Dialekte sowie eine ausführlichere Beschreibung samt der nicht oder auch zusätzlich zum Standard unterstützten Zeichenklassen sowie weiteren Besonderheiten bietet ein Regex-Feature-Vergleich [17]. Detailinformationen zu weiteren Werkzeugen mit deren Regex-Dialekt(en) stellt die Webseite Regular-Expressions.info [18] bereit.
|
Dialekt |
Abkürzung |
Beschreibung |
Anwendung |
|---|---|---|---|
|
POSIX Basic Regular Expressions |
POSIX BRE |
Grundlegende Ausdrücke gemäß IEEE-POSIX-Standard 1003.2 |
R |
|
POSIX Extended Regular Expressions |
POSIX ERE |
Erweiterte Ausdrücke gemäß IEEE-POSIX-Standard 1003.2 |
MySQL, Oracle Database 10g, PHP, PostgreSQL bis Version 7.4, R |
|
GNU Basic Regular Expressions |
GNU BRE |
POSIX BRE mit GNU-Erweiterungen |
GNU Grep, GNU sed |
|
GNU Extended Regular Expressions |
GNU ERE |
POSIX ERE mit GNU-Erweiterungen |
GNU Egrep, GNU Awk, GNU Sed, PHP, GNU Emacs |
|
Perl Compatible Regular Expressions |
PCRE |
Regexe, die in der Programmiersprache Perl benutzt werden |
PHP, Perl, R, Emacs mit Pcre2el-Erweiterung, Apache Webserver, Exim, Postfix, Nmap |
|
Tcl Advanced Regular Expressions |
Tcl ARE |
Regex-Kommandos von Tcl 8.2 und 8.4 |
TCL, PostgreSQL ab Version 7.4 |
|
European Computer Manufacturers Association |
ECMA 262 |
Regex-Implementierung für Webbrowser |
Javascript |
Bedienkonzepte: Vim
In Vim benutzen Sie Regexe im Kommandomodus. Sie drücken also im Einfügemodus zunächst [Esc] und geben danach einen Schrägstrich ([Umschalt]+[**7]) gefolgt vom Suchmuster ein. Eine Rückwärtssuche beginnt hingegen mit einem Rückstrich [Umschalt]+[ß], wieder gefolgt vom Suchmuster. Eine einfache Angabe von s/Suchmuster im Kommandomodus löscht alle Vorkommen des Suchmusters im Text (Ersetzung des Suchmusters durch nichts). Das Zeichen g steht als Abkürzung für global und wendet eine Aktion auf jeden Suchtreffer im Text an. Das vollständige Schema dazu zeigt die Tabelle “Schema für Suchen und Ersetzen in Vim”. Falls Sie sich jetzt fragen, ob der Editor Suchen und Ersetzen auch rückwärts beherrscht: Nein, das kann Vim nicht.
|
Kommandofolge |
Bedeutung |
|---|---|
|
|
Vorwärtssuche ab aktueller Cursor-Position. |
|
|
Rückwärtssuche ab aktueller Cursor-Position. |
|
|
Alle Vorkommen des Suchmusters löschen. |
|
|
Suchen und Ersetzen im benannten Bereich. |
|
|
Vim-Kommando im benannten Bereich auf Zeilen anwenden, die das Suchmuster enthalten. |
Als Trennzeichen zwischen den einzelnen Komponenten der Kommandofolge dient üblicherweise ein Schrägstrich (/), Sie dürfen aber auch ein anderes Trennzeichen verwenden. Details dazu liefert der Kasten “Alternative Trennzeichen in Vim”.
Alternative Trennzeichen in Vim
Vim benutzt als Trennzeichen zwischen den einzelnen Komponenten der Kommandofolge einen Schrägstrich. Zulässig ist aber auch jedes andere Zeichen, das die Komponenten sauber und eindeutig voneinander trennt, beispielsweise ein Doppelpunkt. Das ist dann hilfreich, wenn Ihr Suchmuster oder Ihr Ersatztext viele Schrägstriche enthält, beispielsweise bei Pfadangaben, die Sie ansonsten jeweils vielfach escapen müssten. Im Beispiel aus Listing 1 ersetzen wir die Pfadangabe /var/log/dtafile durch /var/log/datafile (erste Zeile). Mit dem Doppelpunkt als Trennzeichen fällt die Kommandofolge deutlich lesbarer aus (zweite Zeile).
Listing 1
Trennzeichen
s/\/var\/log\/dtafile/\/var\/log\/datafile/g s:/var/log/dtafile:/var/log/datafile/g
Als Bereich versteht Vim den Wirkungskreis, in dem ihre Kommandofolge Anwendung findet (siehe Tabelle “Bereichsangaben im Vim”). Spezifizieren Sie keinen Bereich, umfasst der Wirkungskreis lediglich die aktuelle Zeile. Die Modifikatoren aus der Tabelle erlauben das Suchen und Ersetzen einzelner oder mehrerer Worte sowie ganzer Zeilen und Absätze im Text, die das Suchmuster enthalten (oder nicht enthalten). Die Bereichsangabe mit Zeilennummern erlaubt die Ergänzung um + und -, damit Sie “nach der Zeile mit dem Suchtreffer” beziehungsweise “vor der Zeile mit dem Suchtreffer” ausdrücken können. Mittels / und ? geben Sie mehrere Suchtreffer an.
|
Bereich |
Zeichen, Beispiel und Erklärung |
|---|---|
|
Bestimmte Zeilennummer |
d – |
|
Bereichsangabe mit Zeilennummern |
d,d – |
|
Aktuelle Zeile |
|
|
Letzte Zeile |
|
|
Ganzer Text |
|
|
Beginne ab Markierung |
|
|
Ab nächster Zeile mit neuem Suchmuster |
|
|
Ab vorheriger Zeile mit neuem Suchmuster |
|
|
Ab nächster Zeile mit bisherigem Suchmuster |
|
|
Ab vorheriger Zeile mit bisherigem Suchtreffer |
|
|
Ab nächster Zeile mit dem bisherigen Ersatztext |
|
Einen Treffer ersetzt Vim durch den Ersatztext. Bei einer globalen Aktion löst Vim dagegen das von Ihnen genannte Vim-Kommando aus (siehe Tabelle “Vim-Kommandos bei globalen Aktionen”). Wie und wann das erfolgt, steuern Sie über eines oder mehrere zusätzliche Aktions-Flags. Die Tabelle “Vim-Aktionen bei Suchtreffern” listet diese Flags auf. Sie lassen sich bei Bedarf kombinieren. Geben Sie beispielsweise beim Suchen und Ersetzen ein g als Aktions-Flag an, berücksichtigt Vim alle Treffer, ansonsten nur den ersten.
|
Kommando |
Beschreibung |
|---|---|
|
|
Suchtreffer ausgeben (“print”) |
|
|
Suchtreffer ersetzen (“search and replace”) |
|
|
Suchtreffer in Puffer kopieren (“copy”) |
|
|
Zeile mit dem Suchtreffer löschen (“delete”) |
|
|
Zeile mit dem Suchtreffer in Puffer kopieren (“yank”) |
|
|
Ergebnis schreiben (“write”) |
|
Aktions-Flag |
Beschreibung |
|---|---|
|
|
Bestätige jede Ersetzung (“confirm”) |
|
|
Ersetze alle Suchtreffer (“global”) |
|
|
Ignoriere Groß- und Kleinschreibung (“ignore”) |
|
|
Berücksichtige Groß- und Kleinschreibung (“not ignore”) |
Im Folgenden wollen wir das anhand einiger Beispiele verdeutlichen. Die erste Zeile von Listing 2 zeigt das Kommando, mit dem Sie ab der aktuellen Cursor-Position alle exakten Vorkommen der Zeichenfolge “Windows” im Text finden. Die zweite Zeile sucht dasselbe, jedoch von der aktuellen Cursor-Position zum Anfang des Texts. In der dritten Zeile sehen Sie das Kommando, um in den Zeilen 10 bis 20 alle Vorkommen von “Windows” jeweils durch die Zeichenkette “Linux” zu ersetzen. Möchten Sie das unabhängig von Groß- und Kleinschreibung vollziehen, ergänzen Sie noch ein i am Ende des Ausdrucks (letzte Zeile).
Listing 2
Vim: Ersetzen
/Windows ?Windows :10,20 s/Windows/Linux/g :10,20 s/Windows/Linux/gi
Möchten Sie die Aktion auf den gesamten Text anwenden, bieten sich die in Listing 3 gezeigten Möglichkeiten an. Die erste Zeile nutzt den %-Operator für den gesamten Text und wendet darauf den Suchen-und-Ersetzen-Ausdruck an. In der zweiten Zeile kommt zunächst eine globale Aktion zum Einsatz, die alle Zeilen heraussucht, die den Suchbegriff “Windows” enthalten. Mit der Angabe /norm schaltet Vim zunächst in den Normalmodus [4] zurück und wendet danach auf die jeweils gefundene Zeile ein globales Suchen und Ersetzen an.
Listing 3
Vim – global ersetzen
:% s/Windows/Linux/g :g/Windows/norm s/Windows/Linux/g
Vim kann nicht nur mit einzelnen Worten umgehen, sondern auch mit ganzen Zeilen und Absätzen. Ein Absatz beginnt beziehungsweise endet mit einer Leerzeile. Mit dem Kommando aus Listing 4 suchen Sie zunächst nach allen Zeilen, in denen die Zahlen 201 bis 205 vorkommen – eine Ziffer 2, gefolgt von einer 0 und einer Ziffer aus dem Bereich 1 bis 5. Mit dem Vim-Kommando dap für “delete actual paragraph” löschen Sie den entsprechenden Absatz aus dem Text.
Listing 4
Vim – Zeilen löschen
:g/20[1-5]/norm dap
Geht es darum, die Zeilen zwischen zwei Suchtreffern zu entfernen, lässt Vim Sie ebenfalls nicht im Stich. Listing 5 zeigt, wie Sie alle Zeilen zwischen den zwei Überschriften “Kapitel 1” und “Kapitel 2” aus einem Dokument entfernen, das reStructuredText (reST [5]) als Format benutzt. Nach der Angabe des ersten Suchmusters /= Kapitel 1/ folgt ein +, um die Zeile als Begrenzung auszuwählen, die auf die Zeile mit dem Suchtreffer folgt. Das darauffolgende Komma versteht Vim als Bindeglied zum zweiten Suchmuster /= Kapitel 2/. Das wird um ein - ergänzt, um die Zeile als Begrenzung auszuwählen, die sich vor der Zeile mit dem zweiten Suchtreffer befindet. Am Ende steht das Vim-Kommando d für “delete”, das die betreffenden Zeilen entfernt. Das umfasst auch Leerzeilen und Zeilen, in denen nur Leerzeichen stehen.
Listing 5
Vim – Bereich löschen
:/= Kapitel 1/+,/= Kapitel 2/-d
Bedienkonzepte: Emacs
Bevor Sie zu einer Reise aufbrechen, hilft der Blick auf eine Landkarte. Bei Emacs ist es ähnlich. Auf der GNU-Webseite stehen eine Reihe von Referenzkarten [6] für unterschiedliche Sprachen bereit, die die häufig benutzten Tastenkombinationen von Emacs 28 beinhalten.
Emacs verwendet ein etwas anderes Bedienkonzept als Vim. Der Editor kennt keine Bedienmodi, sondern agiert konsequent im Einfügemodus. Außerdem benutzt er komplexere Tastenkombinationen und Schlüsselworte (siehe Tabelle “Emacs-Aktionen mit Regex”), um weitere Aktionen auszulösen. Diese gehen mit einer zusätzlichen Benutzerinteraktion (Abbildung 1) in einem kleinen Zusatzfenster oder Minipuffer (Abbildung 2) einher.
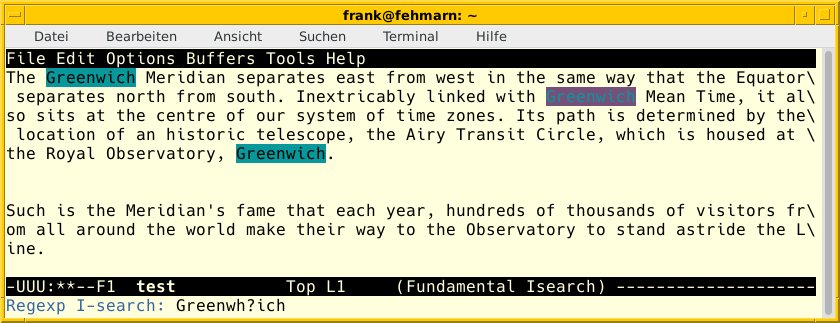
Abbildung 1: Emacs bei der Recherche nach den Suchbegriffen “Greenwich” und “Greenwhich”.
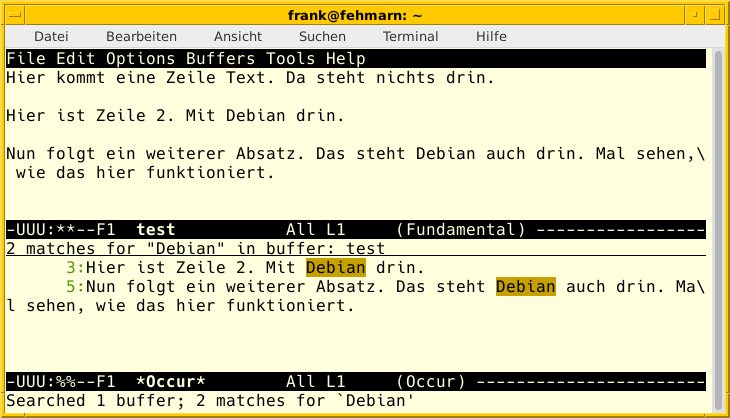
Abbildung 2: Emacs nach der Ausführung des occur-Kommandos.
|
Schlüsselwort |
Beschreibung |
|---|---|
|
|
Vorwärtssuche mit Regex über [Strg]+[Alt]+[S]. Das |
|
|
Rückwärtssuche mit Regex über [Strg]+[Alt]+[R]. |
|
|
Suchen und Ersetzen ohne vorherige Rückfrage. |
|
|
Suchen und Ersetzen mit vorheriger Rückfrage über [Strg]+[Alt]+[Umschalt]+[**5]. |
|
|
Zeichenketten ausrichten anhand von REs als Begrenzern. |
|
|
Zeichenketten finden und hervorheben auf der Basis von REs. |
|
|
Zeilen mit einem Suchtreffer anzeigen. |
|
|
Zeilen in allen Puffern mit einem Suchtreffer anzeigen. |
|
|
Zähle alle Suchtreffer basierend auf dem Regex. |
|
|
Lösche alle Zeilen außer denen mit Suchtreffern. |
|
|
Lösche alle Zeilen mit Suchtreffern. |
|
|
Rufe Grep auf und speichere das Ergebnis in einem Puffer. |
|
|
Benutzerfreundliche Schnittstelle zu Grep. |
|
|
Rekursives Grep. |
|
|
Kopiere die Dateien mit einem Dateinamen, auf den der Regex passt. |
|
|
Benenne alle Dateien um, auf die der Regex passt. |
|
|
Zeige alle Dateien an, die Regex-Treffer auf der Basis von Dired enthalten [19]. |
Emacs: Andere Tasten
Die in der Tabelle “Emacs-Aktionen mit Regex” genannten Tastenkombinationen funktionieren nicht immer, da manche Emacs-Pakete sie neu zuweisen. Versuchen Sie in diesem Fall ersatzweise die Tastenkombination [Alt]+[X], tippen Sie dann den ersten Buchstaben des gewünschten Befehls ein, und drücken Sie [Pfeil-oben]. Tippen Sie dann einen weiteren Buchstaben und drücken Sie den Tabulator, bis der gesamte gewünschte Befehl im Minipuffer am unteren Rand des Bildschirms oder Fensters steht.
Verwenden Sie Gnome, gilt es, noch ein kleines Hindernis aus dem Weg zu räumen: Im Auslieferungszustand fängt Gnome die Tastenkombination [Strg]+[Alt]+[S] ab, um darüber zwischen unterschiedlichen Bildschirmauflösungen umzuschalten. Passen Sie diesen Shortcut über die Aktivitätseinstellungen an und legen Sie eine andere Tastenkombination fest, ansonsten gelingt Ihnen keine Suche in Emacs.
Bei regulären Ausdrücken gehören das Einfügen von Text sowie das Kopieren und Rückgängigmachen zum Alltag. Die beliebten Tastenkombinationen [Strg]+[V][Strg]+[C] und [Strg]+[Z] aktivieren Sie, indem Sie in Emacs entweder [Alt]+[X],cua-mode eingeben oder ein = in Ihrer Emacs-Konfigurationsdatei ergänzen. In der GUI vom Emacs finden Sie diese Auswahl im Menü Optionen.
Deutlicher wird das Ganze anhand von Beispielen aus der Praxis. In der ersten Zeile von Listing 6 finden Sie die Tastenfolgen für die interaktive Vorwärtssuche nach den beiden Suchbegriffen “Greenwich” und “Greenwhich” (Abbildung 1) und in Zeile 2 die dazugehörige Rückwärtssuche. Zeile 3 demonstriert das Ersetzen der beiden Suchbegriffe “Windows” und “windows” durch “Linux” sowie das Zählen der Treffer für den Suchbegriff “Linux” (Zeile 4). Der Aufruf in Zeile 5 zeigt nur noch jene Zeilen des Texts in einem Unterfenster an, die den Suchbegriff “Debian” enthalten (Abbildung 2). Um das Gegenteil zu erreichen und alle Zeilen aus dem Text zu entfernen, die den Suchbegriff “Debian” enthalten, benutzen Sie den Aufruf aus Zeile 6.
Listing 6
Emacs – Ersetzen
[Strg]+[Alt]+[S]isearch-forward-regexp[Eingabe]Greenwh?ich [Strg]+[Alt]+[R]isearch-backward-regexp[Eingabe]Greenwh?ich [Esc],[X]query-replace-regexp[Eingabe][Ww]indows[Eingabe]Linux[Eingabe][Esc],[X]how-many[Eingabe]Linux[Eingabe][Esc],[X]occur[Eingabe]Debian[Eingabe][Esc],[X]flush-lines[Eingabe]Debian[Eingabe]
Emacs beachtet – zumindest bei der interaktiven Suche mittels query-replace-regexp – Groß- und Kleinschreibung, sobald auch Großbuchstaben im Suchmuster vorkommen, ansonsten nicht. Eine Suche nach “t” findet also sowohl t als auch T, eine Suche nach “T” dagegen nur T.
Unterstützte Dialekte
Hinsichtlich der unterstützten Regex-Dialekte machen sowohl Vim [7], als auch Emacs [8] ihr eigenes Ding. Sie benutzen beide eine RE-Variante, die sich nicht eindeutig den in der Tabelle “Übersicht: Regex-Dialekte (Auswahl)” genannten Kategorien zuordnen lässt.
In Bezug auf die Funktions- und Schreibweise orientiert sich Vim [9] an Perl und GNU Grep. Kurz gesagt steht Ihnen somit in Vim eine Basismenge aus GNU BRE, GNU ERE und PCRE zur Verfügung, die um spezifische Erweiterungen (siehe Tabelle “Wer kann was?”) ergänzt wurde. Allerdings ist die Regex-Engine in Vim nicht vollständig PCRE-kompatibel, was gelegentlich Perl-Benutzer zur Verzweiflung treibt. Zudem besteht keine Möglichkeit, Vim mitzuteilen, ob es einen Regex als BRE, ERE oder PCRE interpretieren soll.
Die GNU-Implementierung von Emacs hingegen positioniert sich klar und deutlich: Sie benutzt GNU ERE mit Ausnahme der Klassen, Sortierungen und Gleichwertigkeiten (“collations and equivalences”) von POSIX. Mithilfe der Erweiterung Pcre2el [10] wandeln Sie reguläre Ausdrücke zwischen PCRE, dem Emacs-Dialekt und Rx um. Bei Rx handelt es sich um baumartige Ausdrücke aus der Programmiersprache Lisp.
|
Zeichen oder Aktion |
Vim |
Emacs |
|---|---|---|
|
Angabe von Wortgrenzen (“word boundaries”) |
|
|
|
Keine Wortgrenze (“no word boundary”) |
|
– |
|
Zeilenanfang |
|
|
|
Zeilenende |
|
|
|
Wortklassen (hier von “a” bis “z”) |
|
|
|
Jedes Zeichen zwischen eckigen Klammern |
|
– |
|
Kein Zeichen zwischen eckigen Klammern |
|
– |
|
Gruppen |
|
|
|
Back References |
|
|
|
Mehrfachmuster (“oder”) |
|
|
|
Metazeichen |
||
|
Jedes Zeichen außer Zeilenumbruch |
|
|
|
Leerzeichen und Tabulator (“whitespace”) |
|
|
|
Leerzeichen, Tabulator, Zeilenumbruch |
|
– |
|
Kein Leerzeichen oder Tabulator (“non whitespace”) |
|
|
|
Ziffer (0 bis 9) |
|
|
|
Keine Ziffer, alles außer 0 bis 9 |
|
– |
|
Hexadezimalwert |
|
|
|
Alles außer Hexadezimalwert |
|
– |
|
Oktalwert |
|
Bei |
|
Alles außer Oktalwert |
|
– |
|
Zeichen für den Wortanfang (a bis z, A bis Z und _) |
|
– |
|
Zeichen für keinen Wortanfang (alles außer a bis z, A bis Z und _) |
|
– |
|
Druckbares Zeichen |
|
|
|
Druckbares Zeichen mit Leerzeichen |
|
– |
|
Druckbares Zeichen außer Ziffern |
|
– |
|
Steuerzeichen |
|
– |
|
Ganzes Wort |
|
|
|
Kein ganzes Wort |
|
|
|
Buchstabe des Alphabets |
|
|
|
Kein Buchstabe des Alphabets |
|
|
|
Lateinischer Buchstabe des Alphabets |
|
– |
|
Griechischer Buchstabe des Alphabets |
|
– |
|
Kleinbuchstabe |
|
|
|
Kein Kleinbuchstabe |
|
– |
|
Großbuchstabe |
|
|
|
Kein Großbuchstabe |
|
– |
|
Zeichen in c-Schreibweise |
|
– |
|
Kein Zeichen in c-Schreibweise |
|
– |
|
Zeilen und Spalten |
||
|
Spalte 23 |
|
[Alt]+[G][Alt]+[G][**2]+[**3] oder [Alt]+[G][G]+[**2]+[**3] |
|
vor Spalte 23 |
|
– |
|
nach Spalte 23 |
|
– |
|
Zeile 23 |
|
– |
|
Cursor-Position |
|
– |
|
Gierige Mengenangaben (“Greedy quantifiers”) (n,m>0) |
||
|
0 oder mehr des vorhergehenden Zeichens, Bereichs oder Metazeichens |
|
|
|
Alles inklusive Leerzeile |
|
|
|
Mindestens ein vorhergehendes Zeichen, Bereich oder Metazeichen |
|
|
|
0 oder ein vorhergehendes Zeichen, Bereich oder Metazeichen |
|
|
|
Mindestens n und maximal m vorhergehende Zeichen, Bereiche oder Metazeichen |
|
|
|
Exakt n vorhergehende Zeichen, Bereiche oder Metazeichen |
|
|
|
Von 0 bis maximal m vorhergehende Zeichen, Bereiche oder Metazeichen |
|
|
|
Mindestens n vorhergehende Zeichen, Bereiche oder Metazeichen |
|
|
|
Nicht-gierige Mengenangaben (“Non-greedy quantifiers”) (n,m>0) |
||
|
0 oder mehr vorherige Zeichen, Bereiche, oder Metazeichen, so wenig wie möglich |
|
– |
|
Mindestens n und maximal m vorherige Zeichen, Bereiche, oder Metazeichen, so wenig wie möglich |
|
– |
|
Mindestens n vorherige Zeichen, Bereiche, oder Metazeichen, so wenig wie möglich |
|
– |
|
Von 0 bis maximal m vorherige Zeichen, Bereiche, oder Metazeichen, so wenig wie möglich |
|
– |
TIPP
Um Zeichenketten zu finden, die sich vollständig in einer einzigen Zeile befinden, verwenden Sie die Zeichen für Zeilenanfang (^) und Zeilenende ($).
Beispiele aus der Praxis
Um die Verwendung regulärer Ausdrücke in Vim und Emacs zu verdeutlichen, haben wir mehrere, unterschiedlich komplexe Beispiele zusammengestellt. Das erste umfasst das Auffinden im Text und Prüfen auf formale Korrektheit einer deutschen und Schweizer IBAN. Allerdings kann eine reine Regex-Lösung keine Gültigkeitsprüfung der IBAN vornehmen. Jede IBAN umfasst eine Prüfsumme, die separat berechnet werden muss, was Regex jedoch nicht beherrscht. Im zweiten Beispiel versehen wir eine Zahl mit Tausendertrennzeichen in deutscher und britisch-englischer Schreibweise (Suchen und Ersetzen).
Betrachten wir das erste Beispiel. Gemäß der Beschreibung der Deutschen Bundesbank setzt sich die IBAN eines deutschen Bankkontos aus den beiden Buchstaben “DE”, zwei Prüfziffern, der Bankleitzahl aus 8 Ziffern sowie der Kontonummer aus 10 Ziffern zusammen. Zur besseren Lesbarkeit gruppiert man im Alltag 4 Ziffern und trennt diese Gruppen mit einem Leerzeichen voneinander, sodass Angaben der Form “DE22 1001 0050 1234 5678 90” entstehen.
Beim Auffinden einer passenden Zeichenkette müssen wir stets davon ausgehen, dass sie Tippfehler enthält, und daher den Regex entsprechend fehlertolerant auslegen. Die drei Ausdrücke in Listing 7 gelten für Vim und beschreiben ein einzelnes Wort, das eine Zeichenfolge aus den beiden Zeichen “D” und “E” als Groß- oder Kleinbuchstabe repräsentiert, auf die unmittelbar zwei Ziffern aus dem Bereich 0 bis 9 folgen. Die erste Zeile passt auf eine Zeichenkette mit oder ohne ein Leerzeichen als Trenner zwischen Ziffern, die zweite hingegen mit beliebig vielen Leerzeichen zwischen zwei Ziffern. Die letzte Zeile vereinfacht den Ausdruck, indem sie lediglich nach den beiden Buchstaben gefolgt von 20 Ziffern sucht, vor denen wiederum jeweils beliebig viele Leerzeichen stehen können. Abbildung 3 zeigt das Suchergebnis in Vim, bei dem wir im Text nach passenden IBANs fahndeten.
Listing 7
Vim – DE-IBAN finden
/\<[dD][eE][0-9]\{2\}\(\s\?[0-9]\{2\}\)\{9\}\>
/\<[dD][eE][0-9]\{2\}\(\(\s\+\)\?[0-9]\{2\}\)\{9\}\>
/\<[dD][eE]\(\(\s\+\)\?[0-9]\)\{20\}\>

Abbildung 3: Vim mit hervorgehobenen Suchtreffern.
Im Vergleich zu einer deutschen IBAN fällt die schweizerische Variante etwas kürzer aus. Sie beginnt mit den beiden Buchstaben “C” und “H” (Confoederatio Helvetica, Schweizerische Eidgenossenschaft). Darauf folgen zwei Prüfziffern, die Bankleitzahl aus 5 Ziffern sowie die Kontonummer aus 12 Zeichen – sowohl Ziffern als auch Groß- und Kleinbuchstaben. Listing 8 zeigt das Suchmuster, das in Emacs passende IBANs im Text aufstöbert – einmal vollständig ausgeschrieben und darunter mit der passenden Abkürzung (Abbildung 4).
Listing 8
Emacs – CH-IBAN finden
[Strg]+[Alt]+[S]\b[cC][hH][0-9]\{2\}[[:space:]]*\([0-9a-zA-Z]\{4\}[[:space:]]*\)\{4\}[[0-9a-zA-Z]]\b[Eingabe]
[Strg]+[Alt]+[S]\b[cC][hH][0-9]\{2\}[[:space:]]*\([:alnum:]\{4\}[[:space:]]*\)\{4\}[[:alnum:]]\b[Eingabe]

Abbildung 4: Suche nach einer Schweizer IBAN in Emacs.
Es findet Zeichenketten aus “C” und “H” gefolgt von zwei Prüfziffern, keinem oder mehreren Leerzeichen, vier Gruppen aus 4 Ziffern und Buchstaben, gefolgt von keinem oder mehreren Leerzeichen sowie am Ende einer Ziffer oder einem Buchstaben. So stöbert der Regex beispielsweise “CH41 1000 0FSF 2023 1234 5” für ein Konto auf, das der Free Software Foundation (FSF) gehören könnte. Die IBAN ist in unserem Fall zudem in einen Wortbegrenzer (\b) eingeschlossen. Allerdings haben wir den Sonderfall nicht berücksichtigt, dass alle Zeichen 0 oder 9 sind – dann ist die Kontoangabe ungültig.
Im zweiten Beispiel befassen wir uns mit der Vergabe von Tausendertrennzeichen. Während man dafür im deutschen Sprachraum einen Punkt nutzt, verwenden Angelsachsen ein Komma. Bei der Trennung zwischen Ganzzahl und Nachkommastelle ist es genau umgekehrt.
Listing 9 zeigt unsere Kommandofolge für den Vim, mit der wir jedoch nicht voll und ganz zufrieden sind. Sie funktioniert zwar, aber wir müssen das Vim-Kommando mehrfach anwenden – unabhängig davon, ob wir das g am Ende des Suchausdrucks angeben oder nicht. Es findet stets nur eine Ersetzung pro Zeile statt. Eine versuchte Umsetzung mittels Regex Lookahead beziehungsweise Regex Lookbehind führte nicht zum Erfolg [11]. Abbildung 5 zeigt den vorletzten Schritt, bevor alle Zahlen ein Komma als Tausendertrennzeichen erhalten.
Listing 9
Vim – Tausendertrenner
:% s/\([0-9]\)\(\([0-9][0-9][0-9]\)\+$\)/\1,\2/g
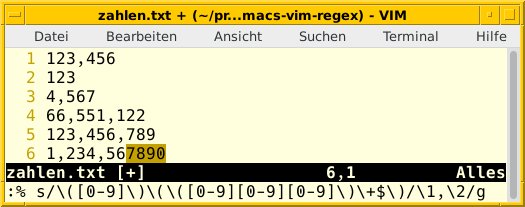
Abbildung 5: Ergänzen der Zahl durch Tausendertrennzeichen.
Farben und Hervorhebung
Vim arbeitet üblicherweise ohne Hervorhebung der Suchtreffer – dieses Feature schalten Sie selbst ein und aus. Vim kennt dazu die beiden Schalter hlsearch (“highlight search”) und nohlsearch (“no highlight search”) [12] für das Kommando set. Sie tippen also :set hlsearch, um die Hervorhebung einzuschalten.
Möchten Sie das Feature dauerhaft aktivieren, gelingt das über die Konfiguration in der Datei .vimrc. In Listing 10 schaltet Zeile 2 die Hervorhebung der Suchtreffer ein, die Zeilen 4 und 6 stellen zusätzlich die gewünschte Farbkombination der Hervorhebung ein. Zeile 4 definiert als Hintergrundfarbe ein helles Gelb, Zeile 6 als Vordergrundfarbe ein Feuerwehrrot. Der Kasten “Farben in Vim” führt alle Farbangaben auf, die Vim akzeptiert. Wie diese dann tatsächlich dargestellt werden, hängt von dem Terminal ab, in dem Sie Vim benutzen.
Listing 10
Vim-Konfiguration
# Suchtreffer hervorheben set hlsearch # Hintergrundfarbe hi Search ctermbg=LightYellow # Vordergrundfarbe hi Search ctermfg=Red
Farben in Vim
Vim versteht folgende Farben zur Auswahl der Vorder- und Hintergrundfarbe: Black, DarkBlue, DarkGreen, DarkCyan, DarkRed, DarkMagenta, Brown, DarkYellow LightGray, LightGrey, Gray, Grey, DarkGray, DarkGrey, Blue, LightBlue, Green, LightGreen, Cyan, LightCyan, Red, LightRed, Magenta, LightMagenta, Yellow, LightYellow, White.
Das Pendant zu Vims hlsearch beziehungsweise nohlsearch sind in Emacs die beiden internen Variablen search-highlight für die normale Suche und highlight-regexp für die Suche auf der Basis von REs [13]. Setzen Sie beide auf den Wert nil, schaltet das die Hervorhebung vollständig ab, ansonsten ist sie jeweils aktiviert [14]. In Emacs stellen Sie das über das Menü Optionen ein, Abbildung 6 zeigt das für Emacs 27.
Abbildung 6: Sie können Emacs an die eigenen Bedürfnisse anpassen.
Abkürzungen erstellen
Benötigen Sie einen regulären Ausdruck häufiger, bieten Abkürzungen ein probates Mittel, um Zeit zu sparen. In Vim helfen Ihnen dabei Makros, in Emacs heißt das Konzept Macroscript. Über beide Varianten speichern Sie Aktionen und Tastendrücke unter einem eigenen Namen ab und greifen bei Bedarf wieder darauf zurück. Die jeweiligen Konzepte genauer vorzustellen, würde den Rahmen dieses Artikels sprengen. Wir gehen in einem Folgebeitrag ausführlicher darauf ein.
Fazit
Das Wissen um reguläre Ausdrücke vereinfacht Ihnen das Umsetzen komplexer Vorgänge rund um die Themen Suchen und Ersetzen in Textdaten. Sowohl Vim als auch Emacs unterstützen das Konzept in umfangreicher Form, gehen dabei jedoch sowohl in der Formulierung als auch in der Ausführung unterschiedliche Wege.
Beim Erlernen und Ausprobieren von regulären Ausdrücken (PCRE) hilft Ihnen die Webseite Regexr [15] weiter. Diese äußerst nützliche Spielwiese sollten Sie unbedingt einmal ausprobieren. (jlu)
Danksagung
Die Autoren bedanken sich bei Axel Beckert und Veit Schiele für deren Anregungen beim Erstellen dieses Artikels. Gerold bedankt sich bei Ben Forta, mit dessen Buch “Teach Yourself Regular Expressions in 10 Minutes” [20] er in die Welt der regulären Ausdrücke eintauchte.
Die Autoren
Frank Hofmann arbeitet zumeist von unterwegs aus als Entwickler, Trainer und Autor, bevorzugt in Berlin, Genf und Kapstadt. Er gehört zu den Verfassern des Debian-Paketmanagement-Buchs. Der gebürtige Kanadier Gerold Rupprecht wohnt seit 30 Jahren in Genf und hat sich auf Finanzsoftware sowie die Evaluierung und die Optimierung IT-bezogener Prozessabläufe spezialisiert. Seit 2000 unterstützt er das GNUstep-Projekt.
Glossar
-
escapen
-
Aufheben der besonderen Bedeutung eines Zeichens durch Voranstellen eines anderen speziellen Zeichens. In Regexen müssen Sie beispielsweise Schrägstriche durch einen vorangestellten Rückstrich escapen.
Infos
-
Reguläre Ausdrücke: Frank Hofmann, “Schnipseljagd”, LU 09/2011, S. 84, https://www.linux-community.de/24091
-
Regex-Generatoren: Frank Hofmann, “Muster finden”, LU 08/2021, S. 82, https://www.linux-community.de/46467
-
“Mastering Regular Expressions”: http://regex.info/book.html
-
Modi im Vim: https://www.warp.dev/terminus/vim-modes
-
reStructuredText: https://docutils.sourceforge.io/rst.html
-
Emacs-Referenzkarte: https://www.gnu.org/software/emacs/refcards/
-
“The Vim Regular Expression Dialect”: https://medium.com/usevim/the-vim-regular-expression-dialect-7fd0b07d2a6a
-
REs im EmacsWiki: https://www.emacswiki.org/emacs/RegularExpression
-
Vimregex: http://vimregex.com
-
“Pcre2el: convert between PCRE, Emacs and rx regexp syntax”: https://github.com/joddie/pcre2el
-
“Regex lookahead and lookbehind”: https://vim.fandom.com/wiki/Regex_lookahead_and_lookbehind
-
“Highlight all search pattern matches”: https://vim.fandom.com/wiki/Highlight_all_search_pattern_matches
-
“Highlighting by Word, Line and Regexp”: https://www.masteringemacs.org/article/highlighting-by-word-line-regexp
-
“Tailoring Search to Your Needs”: https://www.gnu.org/software/emacs/manual/html_node/emacs/Search-Customizations.html
-
Regexr: https://regexr.com
-
“Comparing regular expressions in Perl, Python, and Emacs”: https://www.johndcook.com/blog/regex-perl-python-emacs/
-
Regular Expression Engine Comparison Chart: https://gist.github.com/CMCDragonkai/6c933f4a7d713ef712145c5eb94a1816
-
“Specialized Tools and Utilities for Working with Regular Expressions”: https://www.regular-expressions.info/tools.html
-
“Find and Dired”: https://www.gnu.org/software/emacs/manual/html_node/emacs/Dired-and-Find.html
-
“Teach Yourself Regular Expressions in 10 Minutes”: https://www.oreilly.com/library/view/sams-teach-yourself/0672325667/




