

Um viele Fälle gleichzeitig abzudecken gestalten sich reguläre Ausdrücke mitunter recht komplex. Einige Tools helfen dabei, die Muster zu berechnen.
Der Begriff reguläre Ausdrücke (regular expressions) umfasst die Beschreibung komplexer Muster aus alphanumerischen Zeichen, Klammern und weitere Sonderzeichen zum Beschreiben von Zeichenketten [1]. Diese Technik erlaubt etwa ein zeitsparendes Suchen und Ersetzen in Texten jeglicher Form, etwa bei Strings in Programmiersprachen, in Ergebnissen von Datenbankabfragen oder Dokumenten.
Sie helfen darüber hinaus beim effektiven Einsatz von Werkzeugen wie Grep [2], Xmlgrep [3] und Ugrep [4]. Wie gut Ihnen diese Tools im Alltag helfen, hängt häufig von der verwendeten Musterbeschreibung ab. Je mehr Erfahrung Sie im Schreiben von regulären Ausdrücken mitbringen, desto präziser fällt das Suchergebnis aus.
Um einen regulären Ausdruck zu formulieren, braucht es gerade am Anfang etwas Zeit. Die Mühe lohnt sich aber, um in Folge schneller zu Ergebnissen zu kommen. Beim Erlernen helfen Ihnen Webseiten wie Regular-Expressions.info [5], RegExDB [6] oder das Buch “Mastering Regular Expressions” von Jeffrey Friedl aus dem O’Reilly-Verlag [7]. Alle drei erklären die Konzepte anschaulich und zeigen anhand einer Unmenge von Beispielen den Einsatz im Alltag.
In Abbildung 1 sehen Sie einen regulären Ausdruck für Nummern auf Kreditkarten von Visa: die Ziffer 4 gefolgt von drei beliebigen Ziffern, danach Trennzeichen (entweder nichts oder ein Leerzeichen oder ein Bindestrich), gefolgt von bis zu drei Blöcken aus beliebigen vier Ziffern, auf die wieder obiges Trennzeichen folgen kann.
Damit testen Sie die Korrektheit der Form der übermittelten Daten. Eine Aussage über die Gültigkeit der Karte treffen Sie damit jedoch nicht. Unvollständige Nummern filtern Sie damit jedoch bereits zuverlässig heraus und erkennen Tippfehler, etwa aus Eingabefeldern von Formularen auf Webseiten.
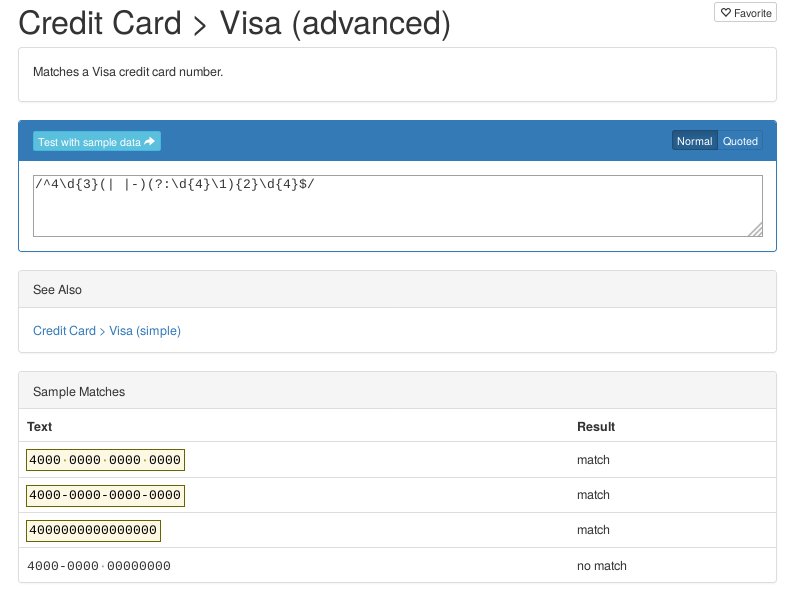
Abbildung 1: Mit regulären Ausdrücken validieren Sie den korrekten Aufbau einer Visa-Kartennummer relativ leicht.
Zum Testen regulärer Ausdrücke erwarb sich RegEx101 [8] einen sehr guten Ruf. Es unterstützt nicht nur unterschiedliche Regex-Dialekte, sondern zeigt neben einer Erklärung an, welche Muster übereinstimmen. Abbildung 2 zeigt das für Datumsangaben, in denen die einzelnen Komponenten, Tag, Monat und Jahr, als Dezimalwerte angegeben und mit einem Bindestrich voneinander getrennt sind.
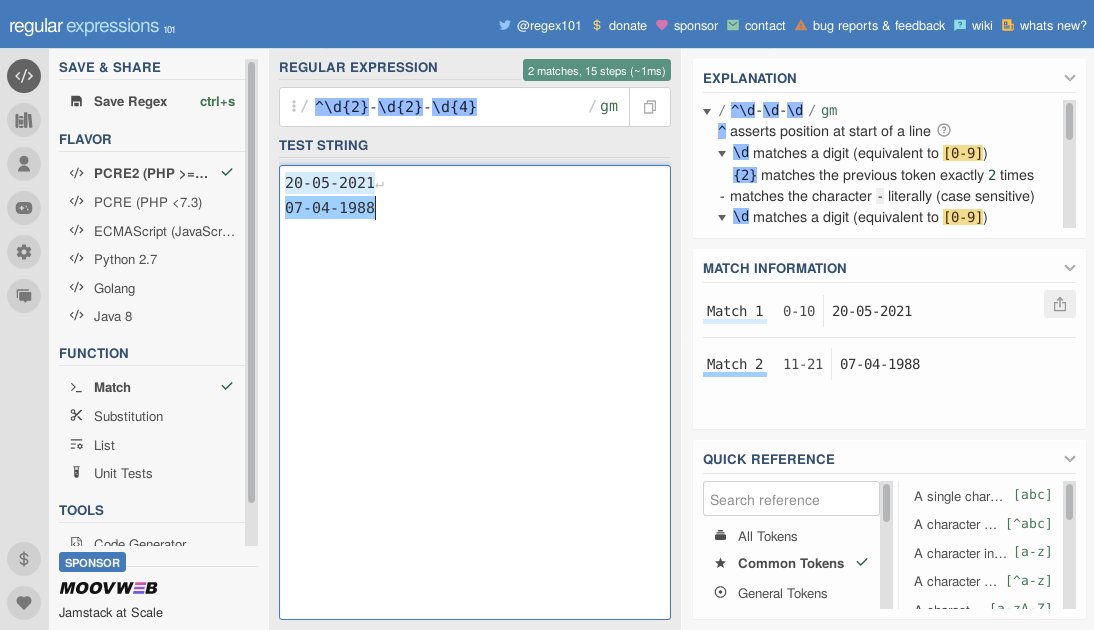
Abbildung 2: Im Beispiel überprüft RegEx101 Datumsangaben.
Regex-Generatoren
Wie Sie vielleicht aus eigener Erfahrung wissen, fällt das Formulieren eines regulären Ausdrucks nicht immer leicht. Es gibt mehrere Projekte, die diesen Schritt automatisieren möchten: eine Text-/Zeichenfolge zu nehmen und daraus einen passenden regulären Ausdruck abzuleiten.
Beachten Sie, dass die Werkzeuge mit einer sehr unterschiedlichen Präzision arbeiten. Die Bandbreite reicht von “Regex für genau diesen Ausdruck” (Fall 1: maximale Präzision) bis hin zu “einem Regex für eine Menge ähnlicher Ausdrücke” (Fall 2: minimale Präzision). Die Wahl der Mittel hängt in erster Linie vom konkreten Anwendungsfall ab. Mit Fall 1 finden Sie genau ein Muster, mit Fall 2 zusätzlich diejenigen, die eine ähnliche Struktur aufweisen.
Regex Generator
Bei Regex Generator handelt es sich um eine private Webseite von Olaf Neumann [9], der das Projekt in Kotlin und Javascript umsetzt. Auf der Webseite gibt es mehrere Formularfelder. Zuerst geben Sie den Text ein, nach dem Sie konkret suchen. Als Beispiel dient ein typischer Log-Eintrag, der aus einem Datum und einer Nachricht besteht, beide mit einem Leerzeichen voneinander getrennt.

Abbildung 3: Nach der Eingabe eines Texts und der Auswahl der Komponenten im Regex Online Generator von Olaf Neumann erhalten Sie den passenden Ausdruck.
Daraus leitet die Software die einzelnen Bestandteile ab, die sie unterschiedlich einfärbt. In Feld 2 wählen Sie mit einem Mausklick auf die jeweilige Farbe beziehungsweise Komponente den für Sie relevanten Bestandteil aus. Dieser färbt sich dann grau. Aus Ihrer Auswahl generiert das Online-Tool dann den passenden regulären Ausdruck und zeigt ihn danach in Feld 3 an (Abbildung 3).
Anschließend wählen Sie aus, in welcher Programmiersprache Sie den regulären Ausdruck verwenden wollen. Zur Auswahl stehen derzeit unter anderem PHP, Ruby und Javascript (Abbildung 4).
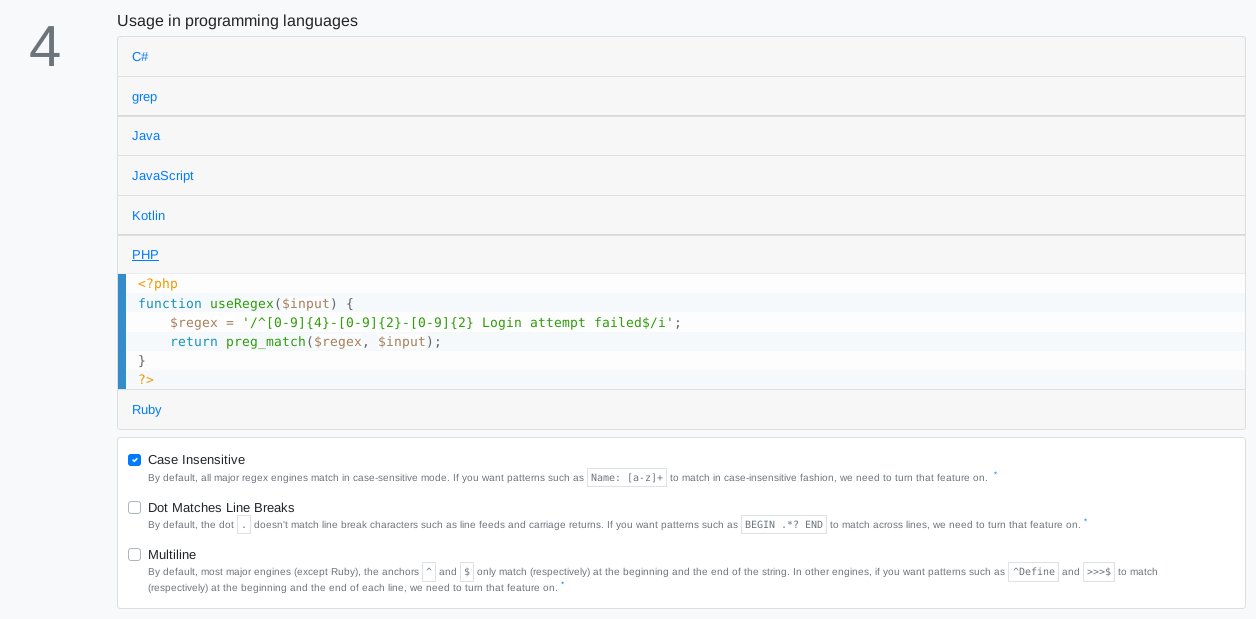
Abbildung 4: Nach Anwahl der gewünschten Programmiersprache erscheint ein regulärer Ausdruck, im Beispiel als PHP-Funktion.
Die Präzision entsprechend liegt der generierte reguläre Ausdruck im Mittelfeld. Das Datum passt auf beliebige Daten, der Text hingegen nur auf die Fehlermeldung Login attempt failed in Groß- und Kleinschreibung dank des Parameters /i am Ende des regulären Ausdrucks. Er genügt aber, um zum Beispiel nach fehlgeschlagenen Logins für beliebige Zeitpunkte zu suchen.
Rgxg
Was im Webbrowser geht, funktioniert genauso gut auf der Kommandozeile. Der erste Kandidat heißt Rgxg [11] (Abbildung 5), eine Abkürzung für Regular Expression Generator. In Debian, Ubuntu und Linux Mint gehört er zu den Paketen im Repository, daher installieren Sie ihn am besten mit den bekannten Bordmitteln. Zur besseren Lesbarkeit der Ausgabe benutzen Sie Rgxg am besten in einem Terminalfenster mit dunklem Hintergrund.
Rgxg erwartet einen Aufruf mit unterschiedlichen Unterkommandos. Die Tabelle “Rgxg steuern” listet die verschiedenen Möglichkeiten auf.
|
Unterkommando |
Beschreibung |
Kommando |
Ergebnis |
|---|---|---|---|
|
|
Ausdruck erzeugen, der auf jedes der angegebenen Muster passt |
|
|
|
|
Ausdruck erzeugen, der auf alle Adressen eines CIDR-Blocks passt (IPv4) |
|
|
|
|
String in Escape-Zeichen setzen |
|
|
|
|
Ausdruck erzeugen, der auf den angegebenen Bereich passt |
|
|

Abbildung 5: Generierte reguläre Ausdrücke des Kommandozeilenprogramms Rgxg.
Darüber hinaus bietet das Tool noch eine ganze Reihe von Parametern an, um die generierten Ausdrücke weiter zu verfeinern (siehe Tabelle “Parameter Rgxg”).
|
Parameter |
Bedeutung |
Kommando |
Ausdruck |
|---|---|---|---|
|
|
Keine äußeren Klammern |
|
|
|
|
Nur Ziffern mit führenden Nullen |
|
|
|
|
Nur Ziffern mit einer bestimmten Anzahl führender Nullen |
|
|
Von der Genauigkeit her hat der generierte reguläre Ausdruck maximale Präzision. Mithilfe der vielen Parameter erzeugen Sie einen regulären Ausdruck, der exakt auf das vorgegebene Muster passt.
Txt2regex
Beim zweiten Kandidaten handelt es sich um das Shell-Skript Txt2regex mit Menüsteuerung über die Tastatur [12]. Wie Rgxg finden Sie es im Repository aktueller Distributionen, etwa Debian oder Fedora. Unter MacOS installieren Sie es via Fink [13].
Aufgrund der Farbwahl der Bedienoberfläche benutzen Sie die Software am besten in einem Terminal mit dunklem Hintergrund. Alternativ schalten Sie mit dem Parameter --nocolor die Farbe ab oder über --whitebg auf eine passende Anzeige für einen hellen Hintergrund um. Im laufenden Programm bewirkt [Umschalt]+[+] (der Stern) dieses Umschalten.
Txt2regex nimmt Sie beim Erzeugen der regulären Ausdrücke an die Hand, indem es Fragen dazu stellt, welche und wie viele Zeichen aufeinander folgen. Es baut aufgrund der Eingaben den Ausdruck für verschiedene Werkzeuge zusammen, beispielsweise Awk, Find, Grep, PHP und PostgreSQL.
Die vollständige Liste erreichen Sie über [Umschalt]+[ 7] (Schrägstrich) (Abbildung 6). Daraus wählen Sie über den entsprechenden Buchstaben den Dialekt aus, für den Sie mit dem Skript die regulären Ausdrücke erzeugen wollen (Abbildung 7).
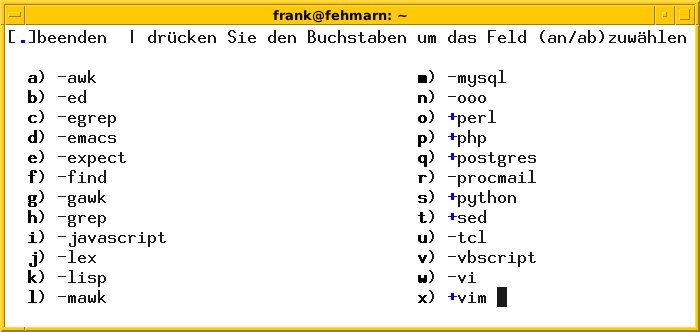
Abbildung 6: Txt2regex unterstützt eine Vielzahl an Dialekten für reguläre Ausdrücke.
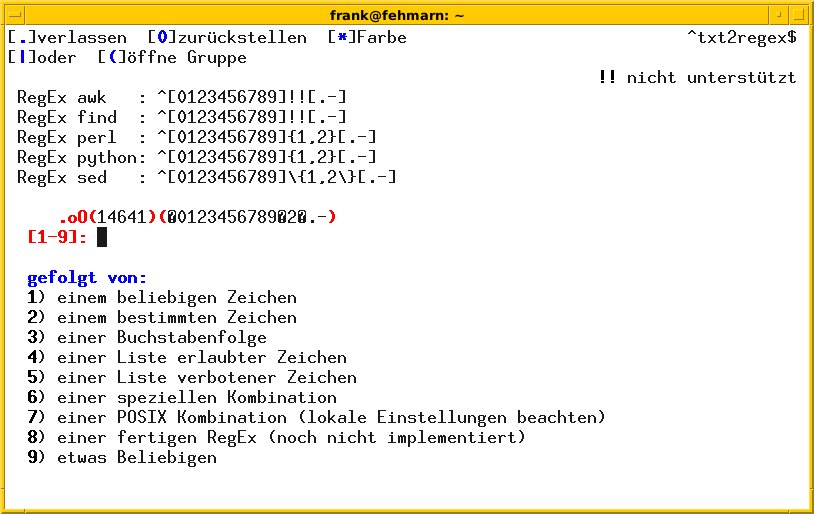
Abbildung 7: Hier erzeugt Txt2regex die passenden Muster für Awk, Find, Perl, Python und Sed. Es handelt sich um einen Zwischenschritt bei der Abfrage nach dem gewünschten String.
Das Programm erfordert Präzision, wodurch Sie beim Bedienen lernen, die Musterfolge genau zu spezifizieren. Als Ergebnis zeigt die Software eine Übersicht, wie Sie den regulären Ausdruck im jeweiligen Werkzeug angeben müssen, damit es das Muster erkennt. Das hilft, da diverse Implementationen und Dialekte im Linux-Alltag vorkommen: reguläre Ausdrücke, erweiterte reguläre Ausdrücke und Perl-kompatible reguläre Ausdrücke (PCRE).
Die Genauigkeit betreffend rangiert es in der gleichen Klasse wie Rgxg und formuliert den regulären Ausdruck maximal präzise. Hier helfen die vielen Parameter, den Ausdruck auf das von Ihnen vorgegebene Muster anzupassen.
Bibliotheken zum Selbstbau
Für Bibliotheken, die ähnlich zu den bereits vorgestellten Werkzeugen arbeiten, fiel die Ausbeute bei der Recherche für diesen Artikel mager aus: Exemplarisch sei für Python der Regex Generator [16], die dazugehörige Regex Generator Lib [17], der Regex Builder namens Rex aus dem Python-Paket Test-Driven Data Analysis (TDDA) [18] sowie der Regextractor [19] genannt.
Für den Regex-Generator zeigt Listing 1 ein kurzes Skript. Es ermittelt einen regulären Ausdruck aus der Zeichenkette 415-5553-7676. Speichern Sie es unter rg.py ab und führen es aus (Listing 2).
Listing 1
Regex-Generator-Skript rp.py
from RegexGenerator import RegexGenerator
myRegexGenerator = RegexGenerator("415-5553-7676")
print(myRegexGenerator.get_regex())
Listing 2
Ausgabe rg.py
$ python3 rg.py
\d{3}[-]\d{4}[-]\d{4}
Das Ergebnis passt durchaus: ein Muster, welches aus drei Ziffern, gefolgt von einem Minuszeichen, vier Ziffern, einem weiteren Minuszeichen und wiederum vier Ziffern besteht. Exakter wäre jedoch ^415[-]5{3}3[-](76){2}$ als Ergebnis. Die drei Ziffern 415 gefolgt von einem Minuszeichen, drei Mal die Ziffer 5 und danach eine 3, wiederum ein Minuszeichen und danach zwei Mal die Ziffernfolge 76 inklusive Zeichen für den Zeilenanfang (^) und das Zeilenende ($).
Der vom RegexGenerator errechnete reguläre Ausdruck passt nicht nur ausschließlich auf obige Zeichenfolge, sondern auch auf andere, etwa 123-4567-8901 oder bla-123-5553-7676-fasel. Laut regulärem Ausdruck dürfen die Ziffern beliebig sein und das Muster weitere Zeichen einschließen, da er etwa keine Begrenzungszeichen wie \b für Wortgrenze, ^ für Zeilenanfang und $ für Zeilenende verwendet.
Rex aus TDDA
Setzen Sie das Werkzeug Rex aus dem Paket TDDA ein, ergibt sich ein sehr schöner, praxisnaher Anwendungsfall. Nachfolgendes Beispiel aus Listing 3 ermittelt den regulären Ausdruck zum Benennen von Bilddateien. Alle Dateinamen beginnen mit den drei Buchstaben DSC, gefolgt von fünf Ziffern, einem Punkt und den drei Buchstaben JPG.
Listing 3
Rex aus TDDA
$ ls bilder/*.JPG DSC06743.JPG DSC06745.JPG DSC06751.JPG DSC06754.JPG $ ls bilder/*.JPG | python3 tdda/rexpy/rexpy.py ^DSC\d{5}\.JPG$
Der reguläre Ausdruck stimmt soweit und enthält auch die beiden zusätzlichen Begrenzungszeichen ^ für Zeilenanfang und $ für Zeilenende. Falsche Positive schließt der Ausdruck aus, sofern das Muster aus den drei Großbuchstaben DSC gefolgt von fünf beliebigen Ziffern und der Zeichenfolgen .JPG besteht.
Der präzisere reguläre Ausdruck wäre DSC067((4[35])|(5[14]))\.JPG. Somit landet das Ergebnis der Python-Bibliothek die Präzision betreffend im Mittelfeld, da es einen Teil sauber liefert, aber die Ziffernfolge zu ungenau beschreibt.
Regextractor
Der Regextractor musste seine Fähigkeiten mit zufälligen deutschen Fahrzeugkennzeichen unter Beweis stellen. Listing 4 gibt zunächst die Kennzeichen und danach den regulären Ausdruck aus, der für alle Kennzeichen passt.
Listing 4
Regextractor
$ python main.py
Kennzeichen:
A-BC 1234
CB-LN 5246E
FR-CG 1554
TUT-R 712
AA-LN 5E
Regex dazu:
[A-Z][A-Z]{0,2}\-[A-Z][A-Z]?\ [0-9][0-9A-Z]{1,4}
Beim Ergebnis handelt es sich nicht um einen korrekten, regulären Ausdruck. Nicht einverstanden sind wir mit dem letzten Teilmuster über [0-9][0-9A-Z]{1,4}, was eine beliebige Ziffer gefolgt von einer beliebigen Mischung aus einem, zwei, drei und vier Großbuchstaben und Ziffern erlaubt.
Exakter wäre der Teilausdruck [0-9]{1,4}E+ für ein bis vier Ziffern, auf das lediglich noch der Großbuchstabe “E” für Elektroautos folgt. Bei unseren Tests trat das wiederholt auf. Deswegen ist der Regextractor nur bedingt zu empfehlen.
Außenseiter
Im Test kamen dem Autor Projekte unter, die zwar einen guten Ansatz zeigen, aber aus verschiedenen Gründen im Test zu keinem brauchbaren Ergebnis führten.
Die private Webseite Txt2re [10] des Entwicklers Mark arbeitet ähnlich wie der Regex Generator. Der Ursprung des Projekts liegt in der Ablehnung des Entwicklers gegenüber regulären Ausdrücken, die ihn dazu bewogen hat, den Schritt so weit wie nur irgend möglich zu automatisieren.
Txt2re funktioniert ähnlich zum Regex Generator, aber derzeit nur mit dem voreingestellten Textstring 20:Apr:2016 This is an Example!. Im Gegensatz zu früher eignet sich das Werkzeug entsprechend nur für Demonstrationszwecke. Es bleibt unklar, ob die eingeschränkte Funktionalität am Webbrowser oder dem verwendeten Javascript liegt.
Vom nächsten Kandidaten namens Grex steht derzeit Version 1.2 auf der Github-Projektseite zum Herunterladen bereit [14]. Fertige Pakete suchen Sie in den Repositories der großen Distributionen aber bislang vergeblich.
Grex basiert auf der Programmiersprache Rust aus dem Mozilla-Projekt und dem Javascript-basierten Werkzeug Regexgen [15]. Der Versuch, Grex unter Debian 11 aus den Quellen zu kompilieren, schlug fehl.
Fazit
Die clevere Idee, reguläre Ausdrücke auf der Basis bestehender Textfragmente und Muster abzuleiten hilft, Gemeinsamkeiten in komplexeren Mustern zu analysieren und zu erkennen. Die untersuchten Werkzeuge arbeiten gut, aber nicht immer fehlerfrei. Die generierten regulären Ausdrücke fallen zum Teil allgemeiner aus, als sie tatsächlich auf der Basis der Textfragmente sein dürften.
In Folge heißt das, dass die Suche mithilfe der darüber generierten Muster mehr Treffer liefert, als erlaubt. Dabei beziehen sie insbesondere solche ein, die nicht zu den Suchmustern passen. Daraus resultieren falsche positive Ergebnisse und eine gewisse Unschärfe.
Reguläre Ausdrücke sind komplex und es liegt in deren Natur, ein Fragment und Muster unterschiedlich abzubilden. Die Leistung, die die Werkzeuge bislang erbrachten, verdient angesichts der komplizierten Analyse Anerkennung. Wünschenswert wäre es, die Exaktheit beim Erzeugen der Muster zu erhöhen, um das Einsatzgebiet der Werkzeuge zu vergrößern. (tle)
Danksagung
Der Autor bedankt sich bei Axel Beckert und Arne Wichmann für deren Hilfe und kritische Anmerkungen während der Erstellung des Artikels.
Über den Autor
Frank Hofmann arbeitet zumeist von unterwegs aus als Entwickler, Trainer und Autor. Bevorzugte Arbeitsorte sind Berlin, Genf und Kapstadt. Er gehört zu den Verfassern des Debian-Paketmanagement-Buchs.
Infos
-
Reguläre Ausdrücke: Frank Hofmann, “Schnipseljagd”, LU 09/2011, S. 84, https://www.linux-community.de/24091
-
Grep-Varianten: Axel Beckert, Frank Hofmann, “Mit Struktur”, LU 06/2012, S. 82, https://www.linux-community.de/25404
-
Grep-Varianten: Axel Beckert, Frank Hofmann, “Durchgekämmt”, LU 07/2012, S. 84, https://www.linux-community.de/25972
-
Ugrep: Karsten Günther, “Aufgespürt”, LU 01/2021, S. 14, https://www.linux-community.de/45289
-
Regular Expressions: http://www.regular-expressions.info/
-
RegEx DB: https://rgxdb.com/
-
Jeffrey Friedly: Mastering Regular Expressions: http://regex.info/book.html
-
RegEx101: https://regex101.com/
-
Regex Generator von Olaf Neumann: https://regex-generator.olafneumann.org/
-
Rgxg: https://rgxg.github.io/
-
Txt2regex: https://aurelio.net/projects/txt2regex/
-
Regexgen: https://github.com/devongovett/regexgen
-
Regex Generator: https://github.com/dbuhlbrown/Regex-Generator
-
Regex Generator Lib (Python): https://pypi.org/project/regex-generator-lib/
-
TDDA: http://www.tdda.info/
-
Regextractor: https://github.com/iuliux/RegExTractor





Über’s Ziel hinaus geschossen Regex-Generator-Script: Aus dem vorgegebenen String von Listing 1 “415-5553-7676” wird fast perfekt das zu erwartende Suchmuster generiert \d{3}[-]\d{4}[-]\d{4} Eine Nyance besser und zwei Zeichen kürzer wäre \d{3}\-\d{4}\-\d{4} , weil das Minuszeichen für sich keine Klasse darstellt, wird es mit dem Backslash maskiert und so seiner Sonderfunktion entbunden. Mit RegEx geht es doch darum, nicht exakt den genannten Ausdruck zu suchen, sondern Zeichenketten, die diesem Typ entsprechen, also 3 Ziffern, 4 Ziffern und noch einmal 4 Ziffern mit dem Minuszeichen dazwischen. Wenn ich genau den String von Listing 1 “415-5553-7676” finden möchte, dann so: 415\-5553\-7676 Für diese… Mehr »
Hallo ak,
Vielen Dank für dein Feedback zum Artikel — deine Variante des Strings aus Listing 1 ist einfacher zu lesen.
Rgxg schweigt sich in seiner Dokumentation aus, welche Dialekte es derzeit unterstützt. Ein guter Anlass, dazu beim Autor nachzufragen :)
Beste Grüße,
Frank Hofmann