

Beim Standard-Befehl Grep gab es lange keine wesentlichen Neuerungen mehr. Ugrep bringt nun Schwung in die Angelegenheit.
Grep gehört mit zu den ältesten Unix-Befehlen überhaupt. Das Kürzel Grep steht für Global/Regular Expression/Print oder Global search for a Regular Expression and Print out matched lines. Sie greift die Syntax des ursprünglichen Unix-Editors Qed auf, der mittels g/re/p Muster in Textdateien suchte. Neben festen Suchwörtern kann es dabei auch Muster mit Joker-Zeichen suchen. Unter Linux wird normalerweise die GNU-Variante von Grep installiert. Sie erweitert die Eigenschaften des ursprünglichen Grep an einigen Stellen, wie beispielsweise bei der rekursiven Suche in Verzeichnissen.
Eine andere Variante von Grep, Agrep (approximatives Grep [1]), erweitert die Textsuche um eine unscharfe Suche. Sie findet auch Beinahe-Treffer, sofern die Unterschiede unter einer vorgegebenen Schwelle liegen, dem sogenannten Wortabstand. Der errechnet sich aus den notwendigen Vertauschungen, Löschungen und Hinzufügungen von Buchstaben, die das Suchmuster in das tatsächliche Datum umwandeln.
Zusätzlich gibt es einige Varianten von Grep, die Suchmuster auch in bestimmten Archivtypen finden, beispielsweise in ZIP-Dateien. Diese Programme arbeiten relativ langsam, da sie zunächst das Archiv entpacken müssen. Alle unter Linux verwendeten Grep-Varianten können zur Suche in Archiven aber auch Daten aus Pipes via Standardeingabekanal lesen und die Ergebnisse in den Standardausgabekanal schreiben (Listing 1).
Listing 1
Archivsuche
$ zcat Archiv.gz | grep Muster
Ugrep
All das, und noch einiges mehr, kann Ugrep [2], und zwar ohne das explizite Entpacken der Datenströme. Zusätzlich zeichnet sich das Programm durch eine ausgesprochen hohe Bearbeitungsgeschwindigkeit aus. Um die Suche zu beschleunigen, verwendet es bei Bedarf mehrere Threads.
Ugrep wird seit einigen Jahren in der Sprache C++ entwickelt und steht nicht nur unter Linux zur Verfügung, sondern auch für andere Betriebssysteme. Suchmuster, die man als reguläre Ausdrücke angibt, dürfen sich auch über aufeinanderfolgende Zeilen erstrecken, was viele andere Grep-Varianten nicht beherrschen. Voreingestellt nimmt Ugrep für die durchsuchten Daten Unicode als Kodierung an.
Ugrep installieren
Unter Debian und Arch Linux gestaltet sich das Einrichten von Ugrep einfach. Ersteres führt das Tool in seinen Repositories, bei Letzterem weichen Sie auf das AUR aus. Bei allen anderen Distributionen müssen Sie Ugrep aus den Quellen installieren [4]. Die dazu nötigen Kommandos zeigt Listing 2.
Listing 2
Ugrep installieren
$ git clone https://github.com/Genivia/ugrep $ cd ugrep && ./build.sh $ sudo make install
Als Archivtypen unterstützt Ugrep Formate wie CPIO, JAR, PAX, TAR und ZIP, komprimiert mit allen gängigen Verfahren (BZIP, GZ, LZ, XZ). Zusätzlich gibt es mit sogenannten Filtern eine Möglichkeit, Daten in speziellen Formaten vorab aufzubereiten. Beispielsweise lassen sich PDF-Dokumente mit einem Filter in Text umwandeln, den Ugrep dann durchsucht.
Wie alle Grep-Varianten wird das Programm maßgeblich durch Optionen gesteuert. Für die meisten Optionen gibt es wie üblich eine Kurz- (-O) und eine Langform (--Option). Die Tabelle “Ugrep: Wichtige Optionen” fasst die wichtigsten Optionen zusammen.
|
|
Daten als Text interpretieren |
|
|
Treffer zählen |
|
|
Suchmuster definieren (kann mehrfach angegeben werden) |
|
|
Suchmuster als erweiterte reguläre Ausdrücke interpretieren (voreingestellt) |
|
|
Kodierung der Daten festlegen |
|
|
Suchmuster aus angegebener Datei laden |
|
|
Suchmuster als Zeichenkette interpretieren (Sonderzeichen werden als Text angesehen) |
|
|
|
|
|
Suchmuster als einfache reguläre Ausdrücke interpretieren |
|
|
Groß-/Kleinschreibung im Muster ignorieren |
|
|
negatives Suchmuster definieren |
|
|
alle folgenden Suchmuster als Ausschlussmuster interpretieren |
|
|
nur Dateien mit der angegebenen Extension bearbeiten |
|
|
Suchmuster als Perl-Ausdrücke interpretieren |
|
|
Pager für die Terminal-Ausgabe festlegen |
|
|
inkrementelle Suche mit optionaler Verzögerung |
|
|
rekursive Suche |
|
|
Wortsuche |
|
|
Ausgabe in hexadezimaler Form |
|
|
komprimierte Datenströme vorab entpacken |
|
|
unscharfe Suche mit max. Wortabstand |
Daneben schlägt der Entwickler eine Reihe von Alias-Konstrukten für die .bashrc vor, um unter anderem die Kompatibilität zu GNU Grep zu gewährleisten (Tabelle “Vorgeschlagene Alias-Konstrukte”). Einige dieser Kurzformen setzen auf die Befehlsvariante ug. In dieser Form liest Ugrep eine Konfigurationsdatei ein (voreingestellt $HOME/.ugrep), die spezielle Einstellungen enthalten kann. Das erlaubt, wichtige Voreinstellungen implizit anzuwenden, ohne sie jedes Mal in der Befehlszeile angeben zu müssen.
|
Alias |
Funktion |
|---|---|
|
|
interaktive, inkrementelle Suche |
|
|
binäre Suche |
|
|
Suche in (komprimierten) Archiven |
|
|
Grep für Git |
|
Kompatibilität zu klassischen Varianten |
|
|
|
Suche mit einfachen regulären Ausdrücken |
|
|
Suche mit erweiterten regulären Ausdrücken |
|
|
Suche ohne reguläre Ausdrücke |
|
|
Suche mit regulären Perl-Ausdrücken |
|
Suchen in komprimierten Daten |
|
|
|
Archivsuche mit einfachen regulären Ausdrücken |
|
|
Archivsuche mit erweiterten regulären Ausdrücken |
|
|
Archivsuche nach Zeichenketten |
|
|
Archivsuche mit regulären Perl-Ausdrücken |
Bei den Suchmustern unterstützt Ugrep mehrere Varianten, die Sie durch entsprechende Optionen aktivieren (siehe Kasten “Muster”). Neben einfachen und erweiterten regulären Ausdrücken, wie sie auch GNU Grep kennt, unterstützt Ugrep auch Perl-Regexe und Wortmuster. Zusätzlich zu diesen Standardmustern, die immer Positiv-Muster definieren, kann Ugrep auch negative Muster (Ausschlussmuster) verwenden. Diese erlauben es beispielsweise, Treffer zu ignorieren, wenn sie in Kommentaren auftreten. Auch Dateien, deren Namen einem bestimmten Muster entsprechen, lassen sich von der Suche ausschließen. Die Option --not wirkt speziell: Alle rechts von ihr stehenden Muster verwendet Ugrep als Ausschlussmuster.
Muster
Der Begriff “Muster” taucht bei Suchprogrammen wie Ugrep normalerweise in mehreren Kontexten mit unterschiedlichen Bedeutungen auf. Muster in Dateinamen legen fest, welche Dateien das Programm bearbeitet. Bei den Mustern für die Dateiinhalte handelt es sich um die eigentlichen Suchmuster, nach denen es die bearbeiteten Dateien durchsucht. Bei Ugrep dürfen diese auch zeilenübergreifend sein. Ugrep und einige andere Suchprogramme kennen außerdem negative Muster. Sie dienen dazu, Dateien auszuschließen oder entsprechende Treffer nicht anzuzeigen. Tatsächlich führt Ugrep dieses Verfahren recht weit: In der Dokumentation des Programms gibt es einen eigenen Abschnitt Search this but not that with -v, -e, -N, –not, -f, -L, -w, -x, der sich mit den Feinheiten zu diesem Thema beschäftigt.
Erweiterungen
An vielen Stellen erweitert Ugrep die anderen, klassischen Programmversionen. Besonders interessant sind dabei die neuen Features bei den Mustern in den Dateinamen (“Globbing”). So steht **/ für beliebig viele – auch null – Verzeichnisse. Am Ende einer Pfaddefinition steht /** analog für beliebig viele Dateien. Der Spezialfall \\? adressiert null oder ein Zeichen. In der Manpage fasst der Abschnitt GLOBBING diese Features zusammen und führt auch zahlreiche Beispiele an.
Spezielle Umgebungsvariablen erlauben, das Verhalten von Ugrep zusätzlich zu steuern. $GREP_PATH vereinfacht den Zugriff auf sogenannte Pattern Files, also Dateien, die Suchmuster definieren; die Option -f aktiviert dieses Feature. Muster in externen Dateien sind ein gutes Mittel, um komplexe Suchmuster dauerhaft vorzuhalten.
Einige Optionen, insbesondere -Q, können einen externen Editor aktivieren, den die Tastenkombination [Strg]+[Y] startet. Ist die Umgebungsvariable $GREP_EDIT gesetzt, verwendet Ugrep den dort festgelegten Editor, ansonsten den in $EDITOR definierten.
In den Umgebungsvariablen $GREP_COLOR und $GREP_COLORS legen Sie bei Bedarf fest, wann und wie Ugrep bei Verwendung der Option --color Treffer farbig hervorhebt. Näheres dazu beschreibt der Abschnitt GREP_COLORS in der Manpage.
Als wirklich herausragende Erweiterung von Ugrep stechen aber die inkrementelle Suche beziehungsweise das sogenannte User Interface ins Auge.
User Interface
Grep-Programme setzt man normalerweise interaktiv in Befehlszeilen, Skripten oder Pipes ein; in vielen Fällen dienen die Ergebnisse dann als Eingaben für weitere Befehle. Das klappt so auch uneingeschränkt mit Ugrep. Zusätzlich legt der Entwickler aber auch ein großes Augenmerk auf eine erweiterte interaktive Nutzbarkeit. So stellt die inkrementelle Suche derzeit ein absolutes Alleinstellungsmerkmal von Ugrep dar. Das dafür eingesetzte User Interface wurde Editoren wie Emacs nachempfunden und ist normalerweise GUI-Programmen vorbehalten.
Bei dieser Form der Suche verfeinert jeder zusätzlich angegebene Buchstabe die Suche weiter und reduziert die Anzahl der Treffer. Als Treffer erscheinen dann alle Zeilen, die mit den bisherigen Angaben übereinstimmen. Für diese Form der Suche stellt Ugrep eine spezielle Schnittstelle bereit, die Sie über die Option -Q aktivieren. Als Argument von -Q können Sie eine kleine Zeitspanne angeben, die Ugrep wartet, bevor es die Eingaben auswertet.
In der linken oberen Ecke des Terminals erscheint nun der Prompt Q>. Alles, was Sie eintippen, interpretiert Ugrep als Suchmuster, jeder zusätzlich Tastendruck verfeinert die Suche. Dabei lassen sich sogar Tippfehler mit der Rückschritttaste korrigieren. Im Beispiel aus Abbildung 1 haben wir Ugrep mit den Optionen -ZQ (unscharf, interaktiv) aufgerufen und nach “alles” gesucht. Aufgrund der unscharfen Suche findet Ugrep dabei auch “alpes”, “alls”, “ales” und so weiter.
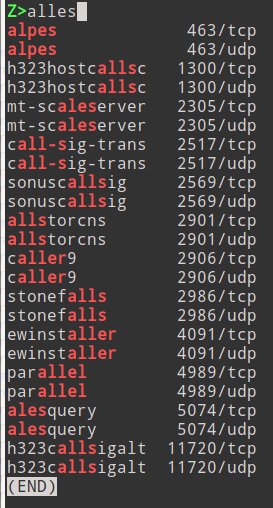
Abbildung 1: Das Universaltalent Ugrep ermöglicht interaktive, unscharfe und inkrementelle Suchen.
Dieses Feature ist so leistungsfähig, dass Ugrep in diesem Modus manchmal sogar einen Pager zur Anzeige der Ausgaben ersetzen kann. So zeigt etwa man ugrep | ugrep -Q die Manpage von Ugrep an und erlaubt, ganz genau einzuschränken, welchen Suchbegriff es darstellen soll. Mit den Pfeiltasten lässt sich die Ausgabe dabei noch vertikal verschieben; [Esc] beendet den Modus wieder.
Obendrein lässt sich diese Option noch mit anderen kombinieren. Für den Fall, dass es nicht genügt, nur die Zeile mit dem Treffer zu sehen, fügen Sie der Ausgabe durch -C2 zwei sogenannte Kontextzeilen vor und nach dem Treffer hinzu. In dieser Form ist Ugrep als Alias (alias q2='ug -C2 -G '), Shell-Funktion oder Skript extrem nützlich.
Ähnliches gilt für die Möglichkeit, Archive zu durchsuchen. Viele moderne Dokumente liegen in komplexen Formaten wie EPUB, ODF etc. vor. Dort wirken die Optionen normalerweise nur auf Metadaten, die die Dokumenten-Container – oft ZIP-Archive – enthalten. Um in den eigentlichen Inhalten zu suchen, muss man diese Archive entpacken, was entweder ein Filter erledigt (dazu später mehr) oder die Option -z, oft gekoppelt mit -r für rekursiv.
Eine unscharfe Suche unterstützt Ugrep mit der Option -Z, optional gefolgt von einer ohne Leerzeichen direkt angehängten Zahl. Letztere bestimmt den Grad der Unschärfe, also die zulässige Anzahl der Fehler (ausgelassene, hinzugefügte, vertauschte Zeichen). Voreingestellt ist 1. Größere Werte führen schnell zu vielen zusätzlichen Treffern, was die Ergebnisse aber manchmal unbrauchbar macht.
Allerdings lässt sich die Art der zulässigen Fehler festlegen: Mit einem Vorzeichen + oder - bezieht sich die Angabe nur noch auf Hinzufügungen beziehungsweise Auslassungen. Die Tilde ~ fasst mehrere Fehler zusammen. Bei -Z~-2 sind bis zu zwei Auslassungen oder Vertauschungen zulässig. Die Option --sort=best sortiert die Ausgaben so, dass die Files mit den besten Treffern zuerst erscheinen.
Einige Funktionstasten nutzt Ugrep im interaktiven Modus für besondere Aufgaben. So aktiviert [F1]+ eine Online-Hilfe (Abbildung 2), in der Ugrep die aktuellen Tastenbindungen anzeigt. Sie können zusätzliche Optionen aktivieren, indem Sie sie in diesem Modus aufrufen. So aktiviert beispielsweise nach dem Drücken von [F1] die Tastenkombination [Alt-links]+[Umschalt]+[Z] die unscharfe Suche.
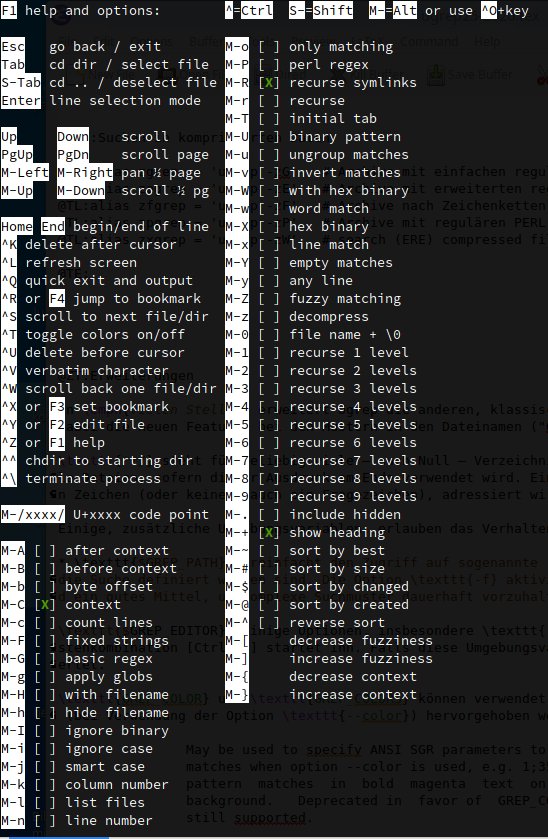
Abbildung 2: Die Ugrep-Hilfe bringt praktischerweise einen eingebauten Konfigurationsmodus mit.
Mit der Option --save-config aufgerufen, erzeugt das Programm die Konfigurationsdatei $HOME/.ugrep. Bei Bedarf erzeugen Sie mit --save-config=/Pfad/Datei) eine andere Datei. Analog arbeitet --config beim Einlesen von Konfigurationsdateien. Der Aufruf von Ugrep als ug liest die Konfiguration automatisch ein.
Da die Konfigurationsdateien ein mächtiges Mittel zum Steuern von Ugrep darstellen, gibt es auch noch die Kurzform ---Datei für das Laden. Konfigurationsdateien mit bestimmten voreingestellten Optionen erzeugen Sie mit folgendem Befehl:
$ ugrep -Option [...] --save-config
Die Konfigurationsdateien sind gut kommentiert und lassen sich bei Bedarf mit einem Texteditor leicht anpassen.
Filter
Ugrep versucht, den Typ einer untersuchten Datei anhand der enthaltenen Daten, der Dateinamenserweiterung und der Signatur (dem “magic byte”) zu bestimmen. So lässt sich die Suche für bestimmte Dateitypen speziell vorbereiten, also quasi filtern.
Dabei extrahiert der Filter die Textbestandteile aus den Datenströmen. Diese Filter führen einen Befehl, ein Skript beziehungsweise eine bestimmte Funktion aus, gegebenenfalls mit Pipes. Sie werden dem Suchprozess über die Option --filter=Filter oder --filter-magic=Label:MagicByte vorgeschaltet.
In der Form --filter=Filter besteht der Filter aus einem Ausdruck der Form Ext:Befehlszeile. Bei Ext handelt es sich um eine durch Kommas getrennte Liste von Dateinamenserweiterungen, für die der Filter gelten soll, etwa .doc,.docx,.xls. Einen Sonderfall stellt * dar, das auf alle Dateien wirkt, insbesondere auf solche, für die es keine anderen Filter gibt.
Die Befehlszeile muss so konstruiert sein, dass sie Eingaben via Standardeingabekanal liest und die Ergebnisse in den Standardausgabekanal schreibt. Zu den typischen Befehlen zählen cat (alles weiterreichen) und head (die ersten Textzeilen weiterreichen), aber auch Werkzeuge wie exiftool (Metadaten extrahieren und weitergeben) oder pdftotext (Text aus PDFs extrahieren) lassen sich so einbinden. Manche Befehle, wie pdftotext, benötigen Optionen um korrekt zu arbeiten – in diesem Fall pdftotext % -. Leerzeichen in den Befehlszeilen müssen Sie dann durch Hochkommas schützen:
--filter='pdf:pdftotext % -'
Die Option --filter-magic-label=Label:Magic erlaubt, den Filtermechanismus auf Datenströme zu erweitern, die Ugrep dann via Magic Byte klassifiziert. Details dazu verrät die Manpage [3].
Mehrere Filter lassen sich durch Kommas getrennt angeben. Eine kombinierte Definition für PDF- und Office-Dokumente könnte so aussehen wie in Listing 3 gezeigt.
Listing 3
Kombinierte Filterdefinition
--filter="pdf:pdftotext % -,odt,doc,docx,rtf,xls,xlsx,ppt,pptx:soffice --headless --cat %"
Fazit
Ugrep gehört auf jeden Rechner. Es ersetzt und ergänzt die Standardbefehle in ganz hervorragender Weise, und jeder, der sich mit der Textsuche auseinandersetzen muss, sollte sich damit vertraut machen. Allein die inkrementelle Suche ist schon so nützlich, dass sie die minimale Einarbeitungszeit mehr als rechtfertigt. (jlu)
Infos
-
Agrep: Agrep: Karsten Günther, “Besser finden”, LU 01/2016, S. 70, https://www.linux-community.de/35929
-
Filtern von Datenströmen: https://github.com/Genivia/ugrep#using-filter-utilities-to-search-documents-with—filter
-
Installation: https://github.com/Genivia/ugrep




