
Erfahrene Linux-Nutzer schwören auf flexible Kommandozeilentools, mit denen sie manche Aufgabe schneller bewältigen als in grafischen Programmen. Wir stellen interessante Anwendungen und Aufrufparameter vor, um auch Einsteiger zu einem Ausflug in die Shell zu ermutigen.
Tipp: Mutt: Mehr Komfort dank Tab-Completion
In der letzten Ausgabe der Shell-Tipps haben wir die Tab-Completion für die Bash vorgestellt [1]. Dank dieses Features kürzen Sie viele Befehlseingaben ab, denn die Tabulatortaste vervollständigt nicht nur Datei- und Verzeichnisnamen, sondern auch Kommandos und sogar deren Aufrufparameter. Auch der Mailclient Mutt nutzt [Tab], um Kommandos, Adressen, Foldernamen und mehr zu vervollständigen. Im Pager, also in der Mailübersicht, verwenden Sie die Taste, um zur nächsten ungelesenen Mail zu springen. Haben Sie die letzte Nachricht erreicht und drücken [Tab], geht’s wieder von vorne mit der ersten ungelesenen los. In die andere Richtung wandern Sie mit [Esc]+[Tab] und erreichen so jeweils die vorige ungelesene Mail.
Wenn Sie eine neue Nachricht verfassen, drücken Sie [M], und Mutt zeigt am unteren Rand in der Statuszeile To: – jetzt geben Sie entweder die Mailadresse von Hand ein oder einen Kurznamen aus Ihrem Adressbuch. Auch hier kürzt die Tab-Taste das Ganze ab, und sobald der Name eindeutig ist, vervollständigt Mutt ihn. Drücken Sie direkt [Tab], sehen Sie ihr komplettes Adressbuch. Beim Folderwechsel, den Sie mit [C] anstoßen, blendet Mutt in der Voreinstellung den nächsten Ordner mit ungelesener Post ein. Betätigen Sie insgesamt dreimal die Tab-Taste, um eine Liste aller Folder anzuzeigen. Die Ordner mit neuen Nachrichten erkennen Sie am vorangestellten N (Abbildung 1). Die Tab-Taste vervollständigt weiterhin Namen von Foldern, wenn Sie Ihre Post sortieren und per [S] in einem Ordner speichern möchten. Auch wenn Sie einen Mailanhang aussuchen, funktioniert die Abkürzung.
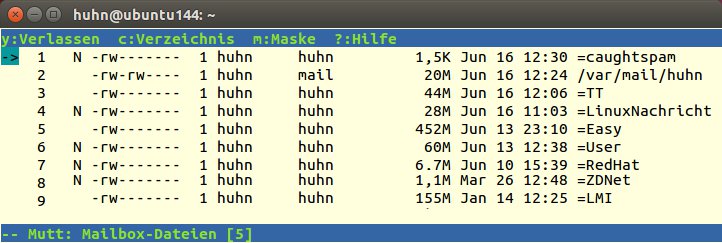
Tab, und Mutt zeigt alle Folder an. Ein vorangestelltes "N" bedeutet, dass hier neue Nachrichten warten.” width=”300″ height=”101″ />
Abbildung 1: DreimalTab, und Mutt zeigt alle Folder an. Ein vorangestelltes “N” bedeutet, dass hier neue Nachrichten warten.Tipp: Mutt: Standard für Betreffzeilen (Re, Fwd)
Der Betreff einer Mail (auch Subject genannt) stellt im Idealfall einen Bezug zum Inhalt der Nachricht her. Er sollte kurz und aussagekräftig sein, damit Empfänger auf einen Blick erkennen können, worum es im Schreiben geht. Beim Beantworten oder Weiterleiten fügen die meisten Mailprogramm automatisch ein Kürzel vor den Betreff ein. So sehen Adressaten sofort, um was es geht. RFC 5322 beschreibt in Abschnitt 3.6.5 [2], dass RE: oder Re: (Lateinisch “res” = “die (betreffende) Sache”) vor einer beantworteten Mail steht. Als Zeichen für weitergeleitete Mails hat sich FWD: bzw. Fwd: als Standard etabliert. Einige Mailclients ignorieren diese Konventionen. So haben sich die Entwickler von Microsoft Outlook einen besonderen “Service” ausgedacht, der eingedeutschte Varianten wie AW: (“Antwort”) oder WG: (“weitergeleitet”) verwendet.
Die lokalisierten Kürzel sind vor allem in der Geschäftswelt weit verbreitet. Sie verursachen erst dann Probleme, wenn Outlook-Benutzer Mails mit standardkonform arbeitenten Programmen wie z. B. Thunderbird und auch Mutt austauschen. Mailen Sie als Mutt-Nutzer oft mit Outlook-Fans, dann kommt es bei der Kommunikation zu unschönen Rattenschwänzen in der Betreffzeile. Das liegt daran, dass Ihr Mailclient das AW: ignoriert und dem Subject ein standardkonformes Re: voranstellt. Outlook wiederum beachtet das Kürzel nicht, setzt wieder AW: davor, und mit jeder Antwort wächst die Reihe, bis am Ende so unschöne Konstruktionen wie Re: AW: Re: AW: Ihre Mail im Betreff stehen.
Um das zu verhindern, können Sie natürlich auf den RFC verweisen und versuchen, alle Outlook-Anwender zu überreden, auf standardkonforme Präfixe umzuschalten. Schneller und leichter lösen Sie das Problem jedoch, wenn Sie Mutt damit beauftragen, die Betreffzeilen zu reparieren. Dazu bearbeiten Sie die persönliche Konfiguration ~/.muttrc in einem Texteditor und fügen die folgende Zeile hinzu:
set reply_regexp="^((re([\[^-][0-9]+\]?)*|aw|antwort|antw|wg):[ \t]*)+"
Der reguläre Ausdruck ersetzt alle Kürzel der Form aw, antwort, antw und wg durch re. Sollten in Ihrer Mailbox weitere nicht standardkonforme Varianten auftauchen, können Sie diese Liste ergänzen. Fügen Sie einfach hinter wg ein weiteres Pipe-Zeichen als Trenner und dann das Kürzel ein.
Tipp: Schnelle Suche in PDF-Dateien
Sie arbeiten auf der Shell gerne mit grep[3], um Zeichenketten in Textdateien zu suchen? Sie wünschen sich ein ähnliches Tool für PDF-Dateien? Gibt es. Das Tool pdfgrep[4] liegt in den Paketquellen der von EasyLinux unterstützten Distributionen, und Sie spielen das gleichnamige Paket über den Paketmanager ein. Die Funktionsweise gleicht der von grep: Zuerst folgt das Kommando, dann optionale Parameter, dann die gesuchte Zeichenkette und dann eine oder mehrere Dateinamen. Um beispielsweise in einer Datei namens audacity-handbuch.pdf nach dem Begriff Ogg zu suchen, tippen Sie Folgendes:
$ pdfgrep Ogg audacity-handbuch.pdf ... Exportieren als MP3 oder Ogg als MP3 oder als Ogg-Vorbis-Datei. MP3 und Ogg Vorbis ist eine freie Alternative zu Ogg-Vorbis-Format lesen und schreiben. ...
Die Ergebnisse landen direkt auf der Standardausgabe im Terminal. In der Voreinstellung hebt das Tool die gesuchte Zeichenkette in Rot hervor.
Auch die Aufrufparameter sind wie bei grep. So ignoriert das Programm beispielsweise mit -i die Groß- und Kleinschreibung, und -r durchsucht Verzeichnisse rekursiv bis in den letzten Winkel. Wenn Sie pdfgrep auf mehrere Dateien loslassen, sehen Sie in der Ausgabe zusätzlich den Dateinamen vor dem Treffer in seinem Kontext. Ist das nicht gewünscht, schalten Sie das Verhalten mit -h ab. Praktisch ist auch die Option -n, die zusätzlich die Seitennummer für die Treffer ausgibt. Der Vergleich mit einem PDF-Betrachter zeigt: Die Seitenzahlen stimmen überein (Abbildung 2).
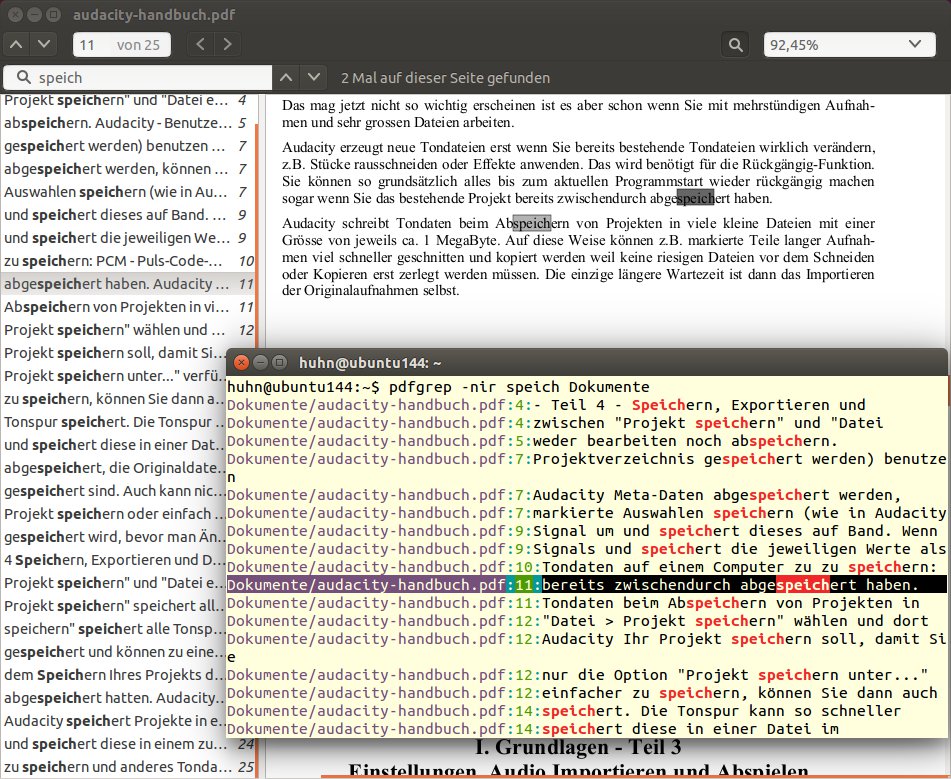
Abbildung 2: Mit “pdfgrep” durchsuchen Sie PDF-Dokumente nach Zeichenketten. Hier sehen Sie im Vergleich Evince und das Shell-Tool.
Tipp: Große Dateien mit “split” aufteilen
Auf der Shell gibt es eine sehr einfache Methode, eine große Datei in mehrere kleine aufzuteilen. Das Programm split gehört bei allen gängigen Distributionen zum Standardumfang. Geben Sie hinter dem gleichnamigen Befehl einfach einen Dateinamen an, teilt split diese auf und setzt jeweils eine Schnittmarke nach 1?000 Zeilen. Die einzelnen Häppchen nennt das Tool xaa, xab, xac und so weiter. Mit Aufrufparametern steuern Sie das Verhalten von split. Um eine andere Größe für die Teilstücke einzustellen, verwenden Sie -b und geben dahinter das Maß an. Sollen die Teile beispielsweise 100*KByte groß sein, lautet die Option -b 100K; für 100*MByte schreiben Sie entsprechend -b 100M, für 100*GByte -b 100G usw.
Außerdem können Sie bestimmen, wie die Fragmente heißen. Geben Sie den Namen dazu hinter der Datei an, die Sie aufteilen möchten:
split -b 100M film.avi teil-film.
Die einzelnen Stücke sind danach 100*MByte groß und heißen teil-film.aa, teil-film.ab, teil-film.ac usw. Achten Sie auf den Punkt hinter dem Kommando. Er sorgt dafür, dass die Suffixe aa, ab usw. sauber abgetrennt werden. Finden Sie die Buchstaben in dem Zusammenhang verwirrend, können Sie die Teile auch einfach durchnummerieren. Setzen Sie dazu den Parameter -d vor die Größenangabe (Abbildung 3).
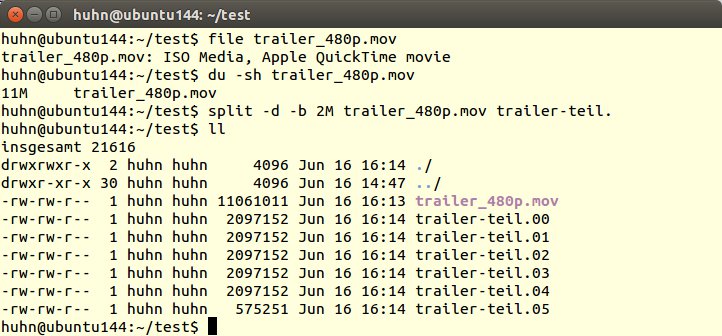
Abbildung 3: Mit “split” teilen Sie eine große Datei schnell in mehrere Teile auf und nummerieren diese optional durch.
Tipp: Zerlegte Dateien mit “cat” zusammensetzen
Um mit split zerlegte Teilstücke wieder zu einer einzigen Datei zusammenzufügen, können Sie den Befehl cat verwenden. Zum Einsatz kommt weiterhin der Umleitungsoperator >, der die Ausgabe eines Kommandos nicht ins Terminal oder auf die Konsole schreibt, sondern in eine Datei umlenkt [5]:
cat teil-film* > film.avi
Der Befehl führt alle Dateien, deren Name mit teil-film beginnt, zusammen – und zwar in der richtigen Reihenfolge. Dabei spielt es keine Rolle, ob Sie die split-Endungen aa, ab usw. oder fortlaufende Nummern vergeben haben.
Tipp: Spalten aus Textdateien extrahieren
Schauen Sie sich Dateien wie /etc/passwd oder /etc/group an, dann sehen Sie, dass diese mehrere Zeilen enthalten. Die Zeilen sind jeweils in Spalten unterteilt, z. B.:
huhn:x:1000:1000:Heike Jurzik,,,:/home/huhn:/bin/bash
In der ersten Spalte steht der Benutzername (huhn), dann folgt ein x, das anzeigt, dass das System so genannte Shadow-Passwörter verwendet. Stünde hier ein *, wäre kein Login möglich, und wäre das Feld leer, dürfte sich der Benutzer ohne Kennwort anmelden. Es folgen zwei weitere Spalten, welche die UID (User-Identification-Nummer, eindeutig) und die die GID der Standardgruppe (Group-Identification-Nummer) anzeigen. Im Feld dahinter ist Platz für weitere Informationen zum Account. Meist steht hier der Vor- und Zuname o. Ä. Es folgen das Home-Verzeichnis (/home/huhn) und die Standard-Shell (/bin/bash).
Um nun eine Spalte gezielt anzuzeigen, um beispielsweise alle Benutzernamen aufzulisten, können Sie das Kommando cut zu Hilfe nehmen:
$ cut -d: -f1 /etc/passwd root ... huhn petronella
Zunächst geben Sie hinter -d das Trennzeichen an, in diesem Fall den Doppelpunkt. Danach definieren Sie hinter -f die Nummer des Feldes. Da der Benutzername in der ersten Spalte steht, tippen Sie also -f1. Hinter letztgenannter Option können Sie auch mehr als eine Spalte notieren. Um zusätzlich zum Benutzernamen die UID, also die dritte Spalte, zu erfassen, geben Sie also cut -d: -f1,3 /etc/passwd ein.
Tipp: Informationen zur CPU auslesen
Ist die CPU Ihres Rechners für ein 64-Bit-Linux geeignet? Wie viele Kerne hat der Prozessor? Bevor Sie lange nach dem Handbuch kramen, im Netz suchen oder einen grafischen Gerätemanager starten, befragen Sie doch einfach Ihren Computer auf der Shell. Das kleine Tool lscpu aus dem Paket util-linux gibt kurz und bündig Auskunft (Abbildung 4). Die erste Zeile zeigt die Betriebssystem-Architektur an, und direkt darunter lesen Sie, dass Sie auf einem Computer mit dieser CPU sowohl eine 32- als auch eine 64-Bit-Version der Distribution installieren können. Auch die Frage nach den Kernen ist schnell beantwortet. Hier ist nur einer vorhanden. Falls Sie die 0 hinter On-line CPU(s) list verwirrt: Die Zählung derEinzelkerne beginnt nicht bei 1, sondern bei 0.
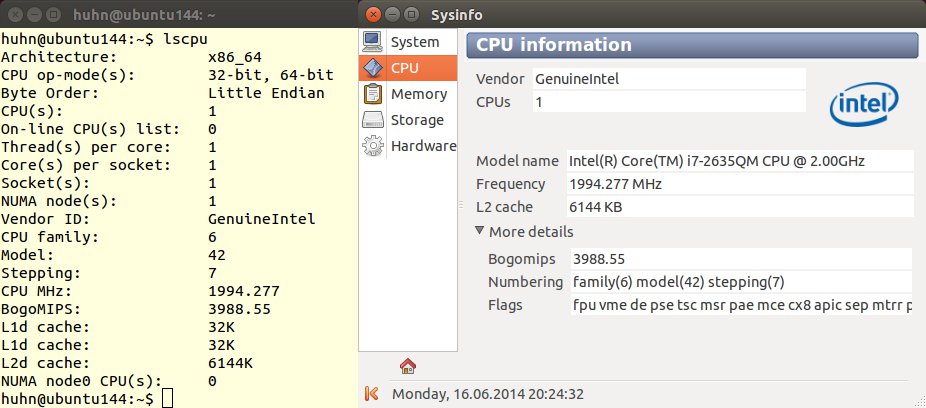
Abbildung 4: “lscpu” ist deutlich informativer als das grafische Programm Sysinfo – schnell getippt ist das Kommando obendrein.
Tipp: Den Rechner zeitgesteuert herunterfahren
Falls Sie nicht die Schaltflächen der Desktopumgebungen oder Anmeldemanager zum Ausschalten des Rechners nutzen, ist Ihnen sicherlich schon einmal der shutdown-Befehl begegnet. Er benötigt Root-Rechte und eine Zeitangabe. Um einen Rechner sofort auszuschalten, tippen Sie Folgendes:
sudo shutdown -h now
Auf Aufforderung geben Sie Ihr eigenes Passwort ein, und der Rechner fährt sofort im Anschluss herunter (“now” = “jetzt”). Auf ähnliche Weise veranlassen Sie einen Reboot; ersetzen Sie dazu -h im Aufruf durch -r.
Anstelle der Zeitangabe now können Sie dem Kommando auch mitteilen, dass es den Rechner in genau 120 Minuten (also in zwei Stunden) abschalten soll:
sudo shutdown -h +120
Wenn Sie möchten, definieren Sie auch eine genaue Uhrzeit. Um den Computer beispielsweise um 20:59 Uhr neu zu starten, tippen Sie:
sudo shutdown -h 20:59
In allen Terminals und auf der Konsole erhalten nun alle Benutzer eine Meldung darüber, etwa “The system is going down for halt in 27 minutes!” Auf Deutsch heißt das so viel wie: “Das System wird sich in 27 Minuten abschalten!” Haben Sie den Timer einmal gestartet, und überlegen Sie es sich anders, halten Sie den Vorgang so an:
sudo shutdown -c
Dabei spielt es keine Rolle, ob Sie den Befehl im selben Terminal oder auf einer der virtuellen Konsolen absetzen – er funktioniert überall.
Glossar
-
RFC
-
Die Requests for Comments (dt. “Bitte um Kommentare”) sind durchnummerierte, (hauptsächlich) technische Dokumente, welche die IETF (Internet Engineering Task Force) herausgibt. Sie beschreiben Internetstandards, wie Protokolle, Methoden, Programme und Konzepte.
Infos
[1] Shell-Tipps, unter anderem zu “Tab-Completion auf der Bash”: Heike Jurzik, “Know-how für die Kommandozeile”, EasyLinux 02/2012, S. 103 ff.
[2] RFC 5322, Abschnitt 3.6.5: http://tools.ietf.org/html/rfc5322#section-3.6.5
[3] Artikel zu grep: Elisabeth Bauer, “Text fischen”, EasyLinux 10/2004, S. 74 ff., http://www.easylinux.de/2003/10/074-grep/
[4] pdfgrep-Homepage: http://pdfgrep.sourceforge.net/
[5] Artikel zu Umleitungsoperatoren: Heike Jurzik, “Genial gelenkig”, EasyLinux 09/2005, S. 84 ff., http://www.easylinux.de/2005/09/084-umleitungen
