

Das Texterkennungswerkzeug OCRmyPDF schreibt den Inhalt eines Briefs in das eingescannte Dokument. Mit dem Scanner Button Daemon und dem richtigen Scanner klappt das auf Knopfdruck.
Trotz allen Fortschritts bleibt die Bürokratie noch immer meilenweit von kompletter Digitalisierung entfernt. Jeden Tag trudeln üblicherweise mehrere Rechnungen, Angebote und sonstiger Schriftverkehr in Papierform per Brief ins Haus – nicht nur im geschäftlichen Umfeld, sondern nach wie vor auch zu Hause. Um der Papierflut Herr zu werden, nutzen viele Anwender inzwischen spezielle Anwendungen wie Paperwork [1] oder gar Apps auf dem Handy, die Briefe “einscannen” und mit Cloud-gestützter OCR sogar den Text in das resultierende PDF einfügen.
Fortschritte sieht man beispielsweise bei den von 1&1 betriebenen E-Mail-Portalen Web.de und GMX: Sie bieten inzwischen in Kooperation mit der Deutschen Post eine Briefankündigung per E-Mail an. Der Nutzer erhält auf Wunsch eine E-Mail mit einem Bild des Briefumschlags und weiß, was demnächst im Briefkasten eintrudelt [2]. Optional legen die Anbieter zudem eine “digitale Kopie” des Briefs ins E-Mail-Postfach, zumindest dann, wenn der Absender den Brief digital bei der Post eingeliefert hat. Große Unternehmen wie Banken oder Versicherungen nutzen diesen Service.
Digitaler Briefkasten
Bei allen Ansätzen, bis auf die auf dem eigenen Rechner zu installierende Anwendung Paperwork, trübt ein Blick auf das Thema Datenschutz und Privatsphäre das Bild. Es erscheint nicht unbedingt als beste Idee, vertrauliche Post der Cloud zur Texterkennung zu übergeben oder Briefpost an notorisch unverschlüsselte E-Mails anzuhängen. Wer den Posteingang digitalisieren möchte, sollte daher auf lokale und unter eigener Regie betriebene Systeme setzen.
Dafür braucht es keine teuren Einzugsscanner oder besondere Software. Ein alter Flachbettscanner und ein einfacher Rechner – im Artikel nutzen wir einen Raspberry Pi der dritten Generation – erfüllen die Anforderungen mehr als genug. Das Ziel ist ein System, das es einem Haushalt oder einem kleinen Büro erlaubt, die eingehende Briefpost zu digitalisieren, ohne selbst ein Scanprogramm oder eine Texterkennung aufrufen zu müssen (Abbildung 1).

Abbildung 1: Der über 20 Jahre alte Canon Canonscan N650U liest Briefe oder Artikel noch problemlos ein. Ein Knopfdruck genügt: Scanbd startet den Scan und aktiviert danach OCRmyPDF.
Oldies but Goldies
Als Scanner kommt in unserem Fall ein Canon Canonscan N650U zum Einsatz. Für das über 20 Jahre alte Gerät gibt es für aktuelle Windows-Varianten schon lange keine offiziellen Treiber mehr. Unter Linux müssen Sie den Scanner nur anstecken, er funktioniert ohne Komplikationen. Der Linux-Kernel enthält bereits alle nötigen Treiber. Der Scanner verfügt über einen Knopf, über den sich der Scanvorgang starten lässt. Andere Varianten besitzen noch Schalter für andere Funktionen, wie E-Mail oder Kopieren.
Die Steuerung und Texterkennung übernimmt ein Raspberry Pi 3 mit 1 GByte Arbeitsspeicher unter einem aktuellen Raspberry Pi OS. Die Rechengeschwindigkeit genügt, um den Text eines Geschäftsbriefs innerhalb weniger Sekunden per OCR zu digitalisieren. Möchten Sie stattdessen einen PC verwenden, lässt sich unser Konstrukt ohne Anpassungen auf ein Ubuntu-System übertragen. Aufgrund des robusten und stromsparenden Aufbaus des Raspberry Pi empfiehlt sich allerdings der Mini-Rechner: Über die Stromkosten müssen Sie sich hier keine großen Gedanken machen.
Ausgehend von einem frisch aufgesetzten Raspberry Pi OS stecken Sie den Scanner an den RasPi an und rufen ein Terminal auf oder loggen sich via SSH ein. Den grafischen Desktop benötigen Sie nicht zwingend, Sie können also auch zur Lite-Variante von PiOS greifen. Um zu kontrollieren, ob das System mit dem Scanner zurechtkommt, führen Sie die Kommandos aus Listing 1 aus. Der erste Befehl zeigt an, ob das System den Scanner erkennt, der zweite listet am Ende die unterstützten Knöpfe des Scanners auf. Der dritte Befehl startet einen Scan-Vorgang, der das Testbild im Home-Verzeichnis ablegt (Abbildung 2). Kennt das System das Kommando scanimage nicht, fehlt das Paket sane-utils.
Listing 1
Funktionsprüfung
$ scanimage -L device 'plustek:libusb:001:004' is a Canon CanoScan N650U/N656U flatbed scanner $ scanimage -A | awk '/Buttons/,0' Output format is not set, using pnm as a default. Buttons: --button 0[=(yes|no)] [no] [hardware] This option reflects the status of the scanner buttons. --button 1[=(yes|no)] [inactive] This option reflects the status of the scanner buttons. --button 2[=(yes|no)] [inactive] This option reflects the status of the scanner buttons. --button 3[=(yes|no)] [inactive] This option reflects the status of the scanner buttons. --button 4[=(yes|no)] [inactive] This option reflects the status of the scanner buttons. $ scanimage --format tiff --mode Gray --resolution 300 -x 210 -y 297 > ~/scanbd.tiff

Abbildung 2: Im ersten Schritt testen Sie, ob das Linux-Scanner-Backend Sane die Hardware unterstützt und zuverlässig im Schwarzweißmodus scannt.
Scannen auf Kommando
Ein erfolgreicher Testlauf bestätigt, dass die grundlegenden Funktionen vorliegen, doch das Gerät soll am Ende automatisch funktionieren. Die Automatik übernimmt der Scanner Button Daemon Scanbd [3]. Das Programm erkennt es, wenn Sie einen Knopf am Scanner drücken, und löst daraufhin eine zugeordnete Funktion aus.
Mit dem ersten Befehl aus Listing 2 installieren Sie das Programm sowie die später benötigten Pakete zur Texterkennung. Mit dem zweiten Kommando testen Sie, ob Scanbd auf einen Tastendruck am Scanner reagiert. Die Ausgabe scanbd: checking option button 0 [...] signalisiert, dass alles klappt; die entsprechende Taste registriert Scanbd als button 0.
Listing 2
Scanbd einrichten und testen
$ sudo apt install scanbd libtiff-tools ocrmypdf tesseract-ocr-deu $ scanbd -f -d7 ### Buttons am Scanner drücken [...] scanbd: checking option button 0 number 40 (1) for device plustek:libusb:002:004: value: 1 scanbd: value trigger: numerical scanbd: trigger action for button 0 for device plustek:libusb:002:004 with script test.script scanbd: get_sane_option_value scanbd: Value of mode as string (len 5, hash 217719332): Color scanbd: setting env: SCANBD_FUNCTION_MODE=Color scanbd: setting env: PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/snap/bin scanbd: setting env: PWD=/home/test scanbd: setting env: USER=test scanbd: setting env: HOME=/home/test scanbd: setting env: SCANBD_DEVICE=plustek:libusb:002:004 scanbd: setting env: SCANBD_ACTION=send [...]
In der unter /etc/scanbd/scanbd.conf gespeicherten Standardkonfiguration führt Scanbd bei einem beliebigen Tastendruck das unter /etc/scanbd/scripts/ gespeicherte Skript test.script aus. Direkt nach der Installation des Diensts existieren weder das Verzeichnis noch die Skriptdatei. Mit den Kommandos aus Listing 3 legen Sie das Verzeichnis an und öffnen dann den Texteditor Nano (Zeile 1 und 2). Dort tippen Sie den Inhalt aus Listing 4 ein und speichern die Änderung mit [Strg]+[O]; mit [Strg]+[X] kehren Sie zurück auf die Kommandozeile. Das Kommando aus der dritten Zeile macht die Datei dann noch ausführbar. Nach der Änderung starten Sie den Dienst mit dem Befehl einmal neu (Zeile 4).
Listing 3
Scanbd konfigurieren
$ sudo mkdir -p /etc/scanbd/scripts $ sudo nano /etc/scanbd/scripts/test.script $ sudo chmod +x /etc/scanbd/scripts/test.script $ sudo systemctl restart scanbd.service
Listing 4
test.script
#!/bin/bash ### Variablen export LANG=C.UTF-8 export LC_ALL=C.UTF-8 zeitstempel=$(date +"%Y-%m-%d-%H%M") ordner=/home/shares/scans #### Scan-Vorgang scanimage --format tiff --mode Gray --resolution 300 -l 0 -t 0 -x 210mm -y 297mm > /tmp/scanbd-$zeitstempel.tiff tiff2pdf -o /tmp/scanbd-$zeitstempel.pdf /tmp/scanbd-$zeitstempel.tiff ocrmypdf --quiet --rotate-pages --rotate-pages-threshold 8 --deskew --sidecar --pdf-renderer sandwich -l deu /tmp/scanbd-$zeitstempel.pdf /tmp/scanbd-$zeitstempel-OCR.pdf ### obsolete Dateien entfernen rm /tmp/scanbd-$zeitstempel.tiff mv /tmp/scanbd-$zeitstempel*.pdf $ordner mv /tmp/scanbd-$zeitstempel*.txt $ordner/scanbd-$zeitstempel.txt chmod 666 $ordner/scanbd-$zeitstempel*
Das Skript test.script in Listing 4 umfasst alle Funktionen, die Scanbd beim Druck auf die Scantaste des Scanners ausführen soll. Es setzt zuerst die Umgebungsvariablen, erstellt dann einen Zeitstempel (Zeile 5) und definiert den Speicherort (Zeile 6). Die Scan-Routine sichert das Dokument dann zuerst unter /tmp (Zeile 8), wandelt es danach in ein PDF um (Zeile 9) und führt das auf Tesseract [4] aufbauende Konsolenprogramm OCRmyPDF [5] aus, das den Text analysiert und dann unter das Bild in das PDF einbaut (Zeile 10). So lässt sich der Text dann später beispielsweise per Copy & Paste aus dem Dokument übertragen oder über Dokumentsuchmaschinen und Organisationswerkzeuge durchsuchen.
OCRmyPDF
Das ambitionierte Projekt OCRmyPDF analysiert mithilfe der Open-Source-Texterkennung Tesseract eingescannte Dokumente und hinterlegt deren Inhalt in Textform im PDF/A-Format im digitalen Dokument. So lässt sich der Text mit Suchmaschinen organisieren oder per Copy & Paste übertragen. Darüber hinaus optimiert OCRmyPDF den Scan durch die Integration weiterer Tools wie etwa Imagemagick oder Unpaper, indem es beispielsweise die Blätter automatisch geraderückt, die Seiten dreht oder unnötige Elemente entfernt, die zum Beispiel beim Scannen von Büchern oder anderen dicken Vorlagen entstehen.
In test.script erfolgt der Aufruf von OCRmyPDF in Zeile 10. Die angehängten Parameter bewirken, dass OCRmyPDF still im Hintergrund arbeitet, den Scan automatisch dreht sowie gerade zieht und am Ende auch den erkannten Inhalt als TXT-Datei speichert (siehe Tabelle “OCRmyPDF-Optionen”). Mit der Option --rotate-pages-threshold 8 müssen Sie eventuell ein wenig experimentieren. Dreht OCRmyPDF Ihre Dokumente unnötigerweise, dann setzen Sie den Wert hoch. Umgekehrt senken Sie den Wert, falls das Programm es verpasst, Seiten automatisch zu drehen.
Klappt das automatische Drehen nicht zufriedenstellend, testen Sie die Funktion, indem Sie das Programm das Kommando aus Listing 5 von Hand aufrufen. Im Test unter Ubuntu 21.04 zeigte OCRmyPDF in der Version 10.3.1+dfsg zum Beispiel an, dass das Dokument gedreht werden müsse, dies tat es jedoch nicht. Erst durch ein Upgrade auf die Version 11.7.3 über das Python-Paketverwaltungsprogramm (Listing 6) schaffte es das System die Dokumente, zuverlässig zu drehen.
|
Option |
Langform |
Funktion |
|---|---|---|
|
|
|
Zeigt eine Hilfe mit Erklärungen zu allen Optionen an. |
|
|
|
Unterdrückt alle Fehlermeldungen und Hinweise. |
|
|
|
Liefert Meldungen zur Analyse des Dokuments. Die ausgegebenen Details lassen sich mit |
|
|
|
Entfernt mit Unpaper [9] vor der Texterkennung unnötige Relikte des Scan-Vorgangs, speichert die gesäuberte Version jedoch nicht im PDF ab. |
|
|
|
Säubert das Dokument vor der Texterkennung mit Unpaper und schreibt die gesäuberte Fassung am Ende auch in das PDF-Dokument. |
|
|
|
Rückt schief eingescannte Dokumente automatisch gerade. |
|
|
|
Dreht das Dokument automatisch, sodass der Text waagrecht steht. |
|
– |
|
Regelt, ab wann das Programm den Text dreht (Vorgabe *15). |
|
– |
|
Schreibt den erkannten Text nicht nur ins PDF-Dokument, sondern erzeugt zusätzlich eine einfache Textdatei. |
|
– |
|
Wahlweise |
|
|
|
Gibt die Sprache des Dokuments an, anhand derer OCRmyPDF das entsprechende Wörterbuch lädt. Für zwei- oder mehrsprachige Dokumente setzen Sie die Option in der Form |
Listing 5
Rotationstest
$ ocrmypdf -v --rotate-pages --rotate-pages-threshold 8 --deskew Input.pdf Output.pdf
Listing 6
Upgrade via Pip
$ ocrmypdf --version 10.3.1+dfsg $ sudo apt remove ocrmypdf $ sudo apt install python3-pip $ sudo pip3 install ocrmypdf $ ocrmypdf --version 11.7.3
Zugriff übers Netzwerk
Als Speicherort definiert test.script das Verzeichnis /home/shares/scans/. Diesen Ordner geben Sie nun per Samba für Nutzer im Netzwerk frei. So müssen die Kollegen oder Familienmitglieder einfach nur an den Scanner gehen, ihren Brief einlegen und auf den Knopf drücken. Zurück am Platz, holen sie dann das eingelesene Dokument über die Netzwerkfreigabe ab.
Dafür installieren Sie auf dem Scanner-Rechner mit den Befehlen aus Listing 7 den Samba-Server, wobei Sie die per DHCP angebotenen WINS-Einstellungen akzeptieren (Zeile 1). Dann erstellen Sie den Ordner für die Scans und stellen die Rechte passend ein (Zeile 2 bis Zeile 4). Der Aufruf des Editors Nano in Zeile 5 bearbeitet die Samba-Konfigurationsdatei /etc/samba/smb.conf. Dort fügen Sie ans Ende der Datei den Inhalt aus Listing 8 an, ohne die bisherige Konfiguration zu ändern. Die Zeilen definieren die Freigabe scans und erlauben den Zugriff, ohne sich am System authentifizieren zu müssen. Das erleichtert die Konfiguration; sollten jedoch auch Gäste in Ihrem Netzwerk unterwegs sein, empfiehlt es sich, den Zugang entsprechend abzusichern [6]. Nach Abschluss der Änderungen starten Sie Samba neu, damit die Änderungen greifen (Listing 7, letzte Zeile).
Listing 7
Samba-Server installieren
$ sudo apt install samba # per DHCP angebotene WINS-Einstellungen -> Ja $ sudo mkdir -p /home/shares/scans $ sudo chown -R root:users /home/shares/scans $ sudo chmod -R ug=rwx,o=rwx /home/shares/scans $ sudo nano /etc/samba/smb.conf $ sudo service smbd restart
Listing 8
Verzeichnisfreigabe
[scans] comment = Public Storage browseable = yes path = /home/shares/scans create mask = 0666 directory mask = 0777 read only = no guest ok = yes
Scannen auf Knopfdruck
Damit stehen alle Komponenten des Systems: Scannen auf Knopfdruck, die anschließende Texterkennung sowie das Bereitstellen der Dokumente über das Netzwerk. Um die Installation zu testen, rufen Sie auf dem Scanner-Rechner mit journalctl -f das fortlaufend aktualisierte System-Log auf. Es hilft Ihnen, Fehlern auf die Schliche zu kommen. Beachten Sie, dass es nicht nur die Aktionen von Scanbd dokumentiert, sondern auch andere Dienste hier ihre Meldungen schreiben.
Mit einem Druck auf die Taste des Scanners starten Sie den Scanvorgang. Nach einem kurzen Moment sollte der Scanner loslaufen und seine Arbeit verrichten. Etwas später liegen dann im Ordner /home/shares/scans/ die eingescannten Dokumente. Die Datei scanbd-Zeitstempel.pdf enthält das blanke PDF ohne Texterkennung. In scanbd-Zeitstempel.OCR.pdf liegt der Text unterhalb des Bilds (Abbildung 3). In der einfachen Textdatei scanbd-Zeitstempel.txt finden Sie den Text des Dokuments, sodass Sie ihn beispielsweise direkt in eine Textverarbeitung übernehmen können (Abbildung 4).

Abbildung 3: Links das eingescannte Dokument im Originalzustand, rechts die von OCRmyPDF in der Ausrichtung korrigierte und mit dem erkannten Text ergänzte Version.
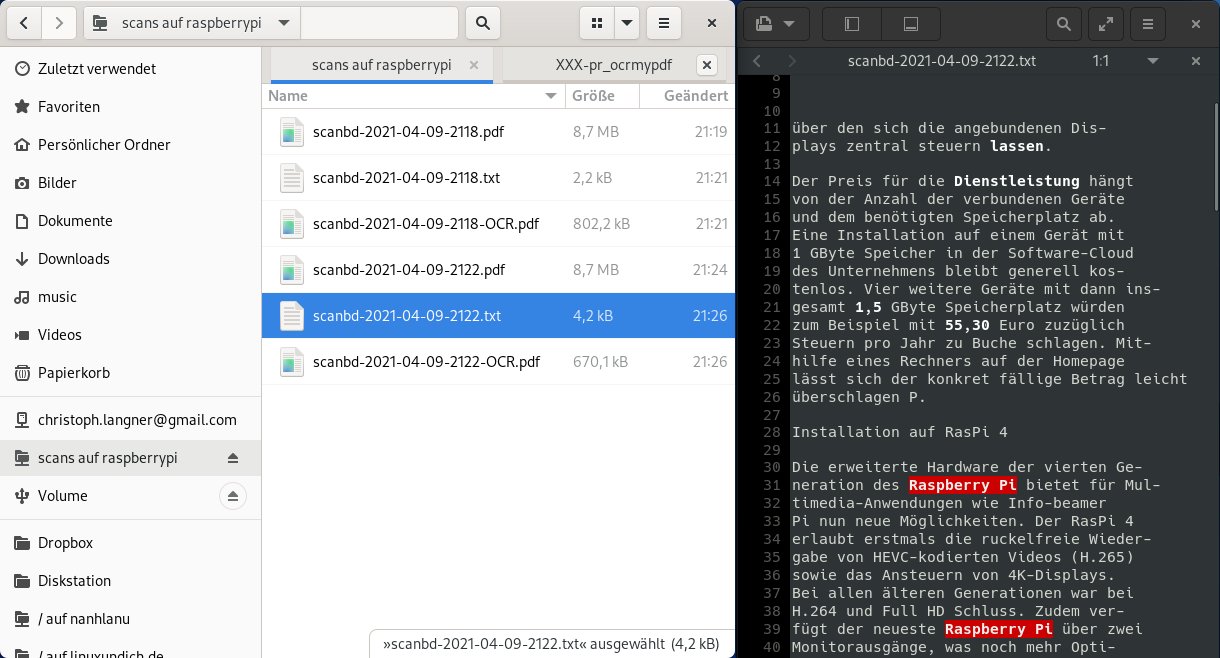
Abbildung 4: Scanbd legt die per Knopfdruck eingescannten Dokumente in einem freigegebenen Ordner ab. In der Sidecar-Datei im TXT-Format finden Sie den blanken Text des Dokuments.
Der Zugriff von den Arbeitsplatzrechnern erfolgt in der Regel über einen Dateimanager wie Dateien (früher: Nautilus). Dort öffnen Sie mit der Tastenkombination [Strg]+[L] die Adresszeile und geben in das Adressfeld smb://Rechnername/scans oder bei einem Raspberry Pi in der Standardkonfiguration smb://raspberrypi/scans ein. Ein Passwort benötigen Sie nicht, der Zugang sollte auch als anonymer Benutzer funktionieren. Auf ähnliche Art lässt sich die Freigabe unter Windows einbinden; dort lautet die Adresse \\Rechnername\scans.
Im aktuellen Aufbau scannt das System immer nur eine Seite und schreibt anschließend das PDF-Dokument auf die Festplatte. Mehrseitige Briefe oder Artikel sind daher immer ein wenig sperrig zu archivieren. Mit Programmen wie dem PDF Arranger [7] fassen Sie gegebenenfalls die einzelnen Seiten sehr leicht zu einem einzigen Dokument zusammen (Abbildung 5). Der von OCRmyPDF hinterlegte Text geht dabei nicht verloren, das Dokument bleibt weiterhin durchsuchbar.

Abbildung 5: Bei Bedarf kombinieren Sie mit Anwendungen wie PDF Arranger die einzelnen Seiten eines Dokuments zu einer alle Seiten umfassenden PDF-Datei.
Raum für Anpassungen
Das System lässt sich leicht an die eigenen Anforderungen anpassen und durch Einsatz besserer oder modernerer Hardware ergänzen. Möchten Sie beispielsweise in Farbe scannen oder mit einer höheren Auflösung arbeiten, müssen Sie lediglich den Aufruf von Scanimage in Zeile 8 des Skripts test.script ändern (Listing 4). Für den Aufbau eines digitalen Archivs für die Geschäftspost lohnt sich der Aufwand in der Regel jedoch nicht. Die farbigen PDFs benötigen meist wesentlich mehr Speicherplatz, einen Mehrwert bieten sie üblicherweise nicht.
Der von uns genutzte Canon-Scanner besitzt nur einen Knopf. Bei anderen Varianten aus der Canonscan-Serie sitzt an der Oberkante des Geräts hingegen eine ganze Knopfleiste. Deren einzelne Tasten lassen sich auch via Scanbd auslesen und dann unterschiedlichen Aktionen zuordnen. So startet ein Knopf Schwarzweißscans, ein zweiter erstellt farbige Dokumente. Ein dritter Button könnte Scanimage mithilfe der --batch*-Optionen im Stapelverarbeitungsmodus aufrufen, sodass das System automatisch mehrseitige PDFs schreibt.
Eine weitere Ausbaustufe könnte im Einsatz von Paperless-ng [8] liegen. Die Software scannt nicht nur Dokumente und führt Texterkennung durch, sondern stellt mit einer Weboberfläche auch ein Frontend zur Verwaltung und Sichtung der Dokumente mitsamt Verschlagwortung bereit. Dieselbe Aufgabenstellung bedient auch das eingangs schon erwähnte Programm Paperwork [1] auf dem Desktop. Wer seine Unterlagen jedoch sauber in einer Ordnerstruktur organisiert, der kommt auch gut mit der hier vorgestellten Eigenbaulösung klar. (cla)
Infos
-
Paperwork: Karsten Günther, “Bits statt Papier”, LU 01/2017, S. 62, https://www.linux-community.de/36724
-
Briefankündigung per E-Mail bei Web.de: https://web.de/email/briefankuendigung
-
Tesseract: https://github.com/tesseract-ocr/tesseract
-
OCRmyPDF: https://github.com/jbarlow83/OCRmyPDF
-
Benutzerauthentifizierung unter Samba: https://wiki.ubuntuusers.de/Samba_Server/smb.conf/#Benutzerauthentifizierung
-
PDF Arranger: https://github.com/pdfarranger/pdfarranger
-
Paperless-ng: https://github.com/jonaswinkler/paperless-ng
-
“Changing the PDF renderer”: https://ocrmypdf.readthedocs.io/en/latest/advanced.html#changing-the-pdf-renderer




