

Mit einem digitalen Archiv sparen Sie Platz im Aktenschrank – aber Paperwork macht das Leben nicht unbedingt leichter.
Die Idee von Paperwork [1] geht auf den Wunsch nach einem papierlosen Büro zurück: Briefe, Rechnungen und lose Blätter landen auf dem Scanner, der sie als PDF- und JPEG-Dateien für die Ablage ausspuckt. Die Dateien schicken Sie anschließend durch eine OCR-Texterkennung, die den Inhalt in digitale Form bringt.
Hier schlägt die Stunde von Paperwork: Die Applikation fasst Bilddaten und Text in überlagerter Form zusammen und sichert sie als PDF. Die Textinhalte der aufbereiteten Unterlagen fasst Paperwork in einem Index zusammen, über den Sie später die Dokumente wiederfinden. Bei diesem Verfahren gilt es jedoch, einige Klippen zu umschiffen: Damit die Software die Texte ausreichend gut erkennt, benötigen Sie möglichst hochwertige Scans oder Fotografien der Seiten – ein guter Scanner mit mindestens 600 DPI Auflösung ist daher Voraussetzung.
Paperwork sucht beim Start zunächst nach Tesseract [2]. Findet es diese sehr leistungsfähige OCR-Engine nicht, greift das Programm auf Cuneiform zurück. In den meisten Fällen erzielen Sie mit Tesseract die besten Ergebnisse.
Hier geht Paperwork übrigens einen interessanten Weg: Falls es die Orientierung der eingescannten Seiten nicht ermitteln kann, bearbeitet es die Seite einfach viermal in um 90 Grad gedrehten Varianten und verwendet dann die besten Ergebnisse.
Installation
Allgemeine Informationen zur Installation finden Sie auf der Website des Paperwork-Git-Repositories [3]. Unter Ubuntu und Derivaten befindet sich die momentan aktuelle Version 0.32 nicht in den Repositories, es gibt aber ein PPA. Zu dessen Installation finden Sie online Informationen [4].
Der Einsatz von Paperwork unter Arch Linux gestaltet sich ausgesprochen schwierig. So deckte die Installation für diesen Artikel auf, dass die Version im Repository aufgrund von Problemen im Paket nicht funktionierte. Selbst wenn die Installation erfolgreich verlief, hieß das nicht, dass Paperwork funktionierte. Das Paket weist eine Vielzahl sehr verschachtelter Abhängigkeiten auf, sodass es nach Updates immer wieder die Arbeit versagte.
Ein Test mit paperwork-chkdeps – ein im Paket enthaltenes Testprogramm – stellte ebenfalls nicht sicher, das Paperwork nach der Installation auch funktionierte. Dazu kommt, dass bei Weitem nicht alle Abhängigkeiten ausformuliert sind: So verlangte Paperwork zum Öffnen eines Verzeichnisses nach Nemo, dem Dateimanager von Cinnamon.
Architektur
Die Applikation als solche basiert im Wesentlichen auf vier Komponenten: Zum Scannen der Unterlagen greift Paperwork auf Sane zurück, mit Tesseract oder Cuneiform bearbeitet es die Dokumente, und mit Whoosh [5] indiziert es die per OCR umgewandelten Texte. Zudem generiert das Werkzeug automatisch Vorschläge für Schlüsselwörter. Dabei reduziert es die Wörter auf den Wortstamm, um zu sinnvollen Ergebnissen zu gelangen. Eine mit GTK/Glade entwickelte grafische Oberfläche fasst alle Bestandteile zusammen.
Die bevorzugt eingesetzte OCR-Engine Tesseract stammt ursprünglich von Hewlett-Packard. Google benutzt die quelloffene Bibliothek etwa zum Digitalisieren von Büchern. Die Software zeichnet sich durch hohe Erkennungsraten und weitestgehende Automatisierung aus.
Da Tesseract ausschließlich mit unkomprimierten TIFF-Dateien arbeitet, gilt es, die gescannten Seiten zunächst aufzubereiten. Erfahrungsgemäß ist dieser Schritt sehr anspruchsvoll und nur teilweise automatisch zu erledigen. Hier liegt eine der Schwächen von Paperwork. Programme wie Gscan2pdf [6] bieten da mehr Möglichkeiten.
Aus den aufbereiteten Seiten eines Projekts erzeugt Paperwork eine durchsuchbare – mit Text versehene – PDF-Datei. Derzeit unterstützt die Software neben dem direkten Scannen das Einlesen von PDF-Dokumenten sowie das Auswerten von gescannten Bildern. Moderne Bildformate wie JPEG2000 unterstützt sie zwar nicht, dafür aber die klassischen Varianten wie JPEG oder PNG.
Allerdings ist derzeit weder möglich, mehrere Bilddateien gleichzeitig in ein Projekt zu laden, noch einen ganzen Ordner mit gescannten Bildern. Das macht die Arbeit extrem aufwendig und mühselig, wenn Sie bereits vorliegende Scans weiterverarbeiten möchten.
Einstellungen
Die Konfiguration ist bisher nur für wenige Parameter möglich. So dürfen Sie den Ordner zum Ablegen der Informationen und den Scanner sowie die OCR-Engine einstellen (Abbildung 1). Die Spracheinstellungen steuern zwar die Rechtschreibprüfung, Erfolge zeigte das im Test aber nicht.
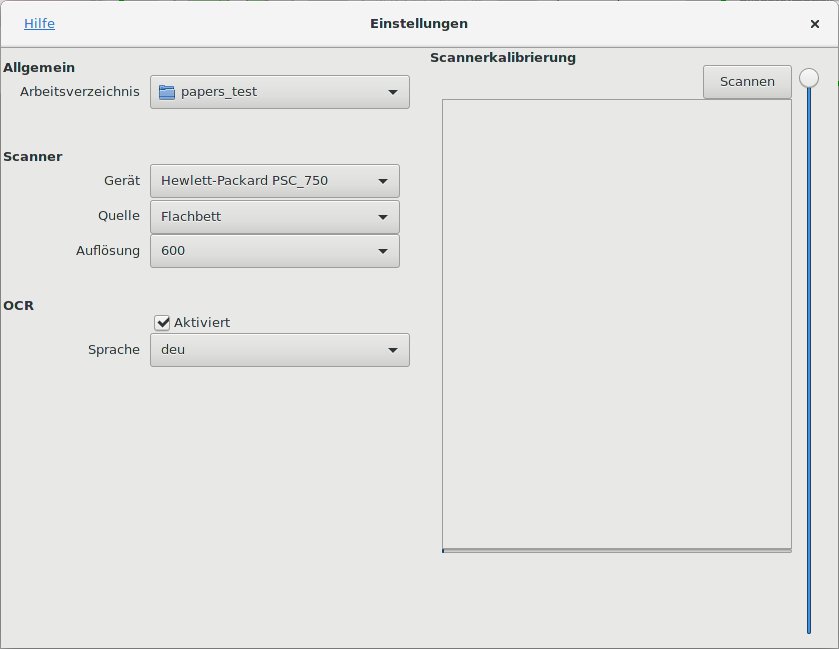
Abbildung 1: Paperwork erlaubt nur sehr wenige Einstellungen. Allerdings macht das den Einsatz der Software nicht unbedingt einfacher.
Mit ~/.config/paperwork.conf existiert eine benutzerspezifische Konfigurationsdatei. Hier überprüfen Sie, ob das Programm tatsächlich die richtige Sprache für die OCR-Engine und die Rechtschreibprüfung verwendet. Das funktioniert jedoch nicht in allen Versionen korrekt.
Erkennt Paperwork jedoch viele Wörter mit Umlauten nicht, ist das ein Hinweis auf eine fehlerhafte Spracheinstellung. Beenden Sie dann erst die Applikation, da diese dabei die Konfigurationsdatei zurückschreibt. Anschließend tragen Sie mit einem Editor de als Wert für die entsprechende Variable lang im Abschnitt [OCR] ein. Nach dem Wechsel der Sprache starten Sie die Texterkennung erneut.
Eine wichtige Einstellung ist die Wahl des Scanners, sofern Sie mehrere geeignete Geräte betreiben. Achten Sie dabei auf die gewählte Auflösung. Warum die Applikation bei einigen Geräten, die eine physikalische Auflösung von 600 DPI erlauben, lediglich 300 DPI empfiehlt, blieb im Test unklar.
Praxis
Nach dem Start zeigt Paperwork eine übersichtlich gestaltete Oberfläche mit zwei Abschnitten an (Abbildung 2). Links finden Sie in der Datenbank das aktuelle Dokument hervorgehoben. In einer entsprechenden Vorschau zeigt das Programm dessen gescannte und bearbeitete Seiten.
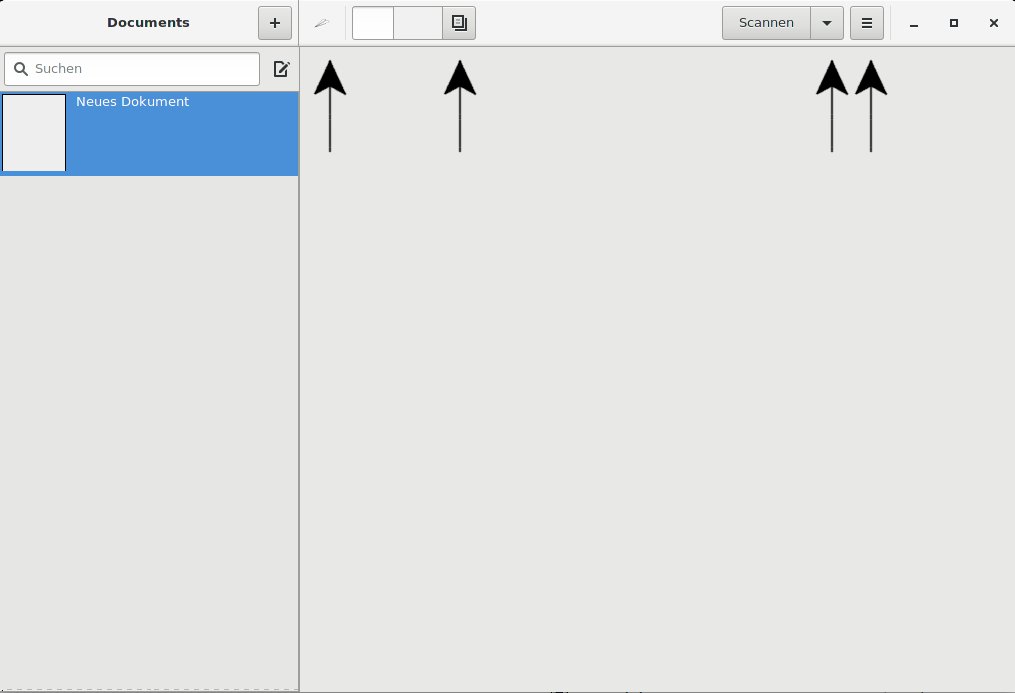
Abbildung 2: Wenige Programme präsentieren sich so unaufgeregt wie Paperwork. Die Funktionen verstecken sich hinter unauffälligen Schaltern (Pfeile).
Ein Mausklick auf eine der in der Vorschau angezeigten Seiten aktiviert die Anzeige in Originalgröße. So sehen Sie im Detail, was das Programm beim OCR-Prozess erkannt hat (Abbildung 3).

Abbildung 3: Fahren Sie nach dem OCR-Prozess mit dem Mauszeiger über ein Wort, zeigt die Software, was sie erkannt hat. Hier macht sie aus “Indexgröße” einen “Index”, den Wortteil “größe” hat sie nicht erkannt.
Am oberen Rand des Fensters befinden sich mehrere, teils sehr unauffällige Schalter, über die Sie die Funktionen des Programms aufrufen. Die Pfeile in Abbildung 2 weisen darauf hin. Über die linke Schaltfläche verwalten Sie grundlegende Funktionen, die daneben steuert die Ansicht der Dokumente, und die rechte spezielle Einstellungen. Unter Scannen stehen die Möglichkeiten zum Einlesen von Daten bereit.
Die Software fasst eingescannte Bilder als Projekte zusammen und exportiert sie anschließend als PDF-Datei. Dazu legt sie im Datenbankverzeichnis für jedes Projekt ein Unterverzeichnis in der Form Datum_ID-Nummer an, in dem sie alle Dateien sammelt. Im Frontend erscheint allerdings nur das Datum, was die Suche nach dem richtigen Projekt erschwert (Abbildung 4)
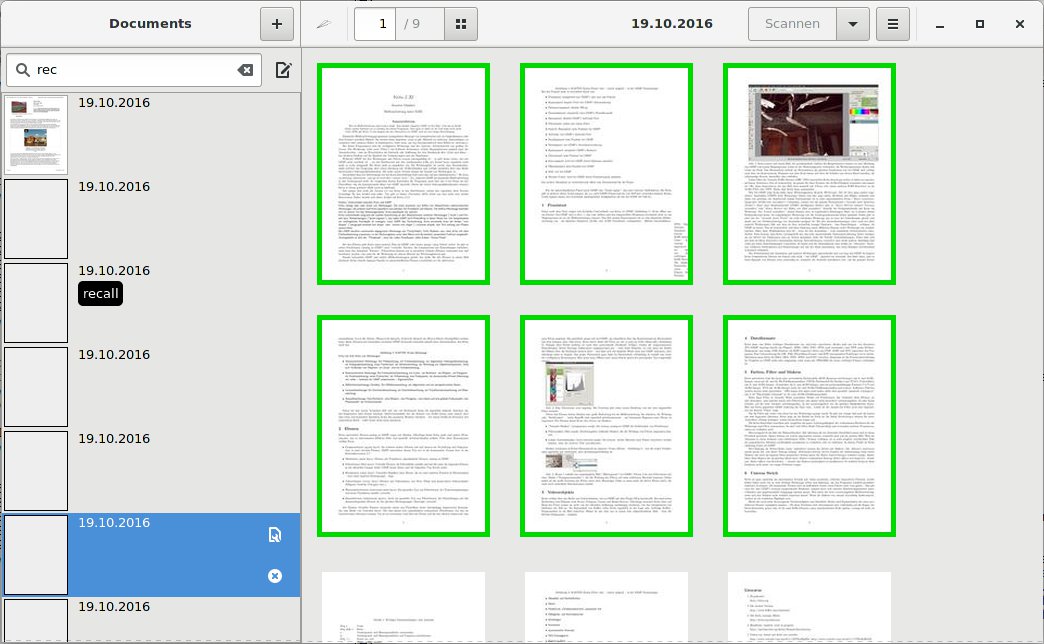
Abbildung 4: Nach dem Einlesen einer Reihe von Dokumenten wirkt Paperwork immer noch sehr übersichtlich. Das ausgewählte Dokument zeigt Paperwork als Vorschau.
In der Grundeinstellung verwendet Paperwork den Ordner ~/papers/ als Arbeitsverzeichnis. In den Verzeichnissen für die Projekte legt die Software stets mehrere Dateien an: Unter paper.Nummer.jpg finden Sie JPEGs der eingescannten Seite, paper.Nummer.words enthält den durch die OCR-Engine extrahierten Text.
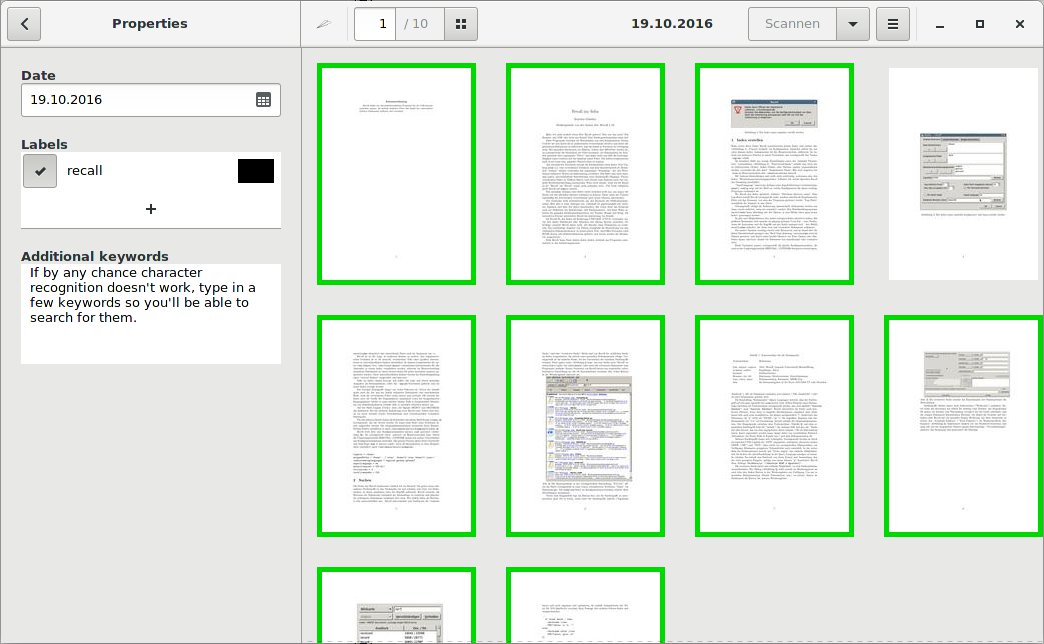
Eine Datei labels enthält die Stichwörter, falls Sie diese manuell vergeben haben (Abbildung 5). Die erzeugte PDF-Datei trägt in diesem Verzeichnis immer den Namen doc.pdf.
recall.” width=”300″ height=”185″ />
Abbildung 5: Zu ausgewählten Dokumenten machen Sie bei Bedarf zusätzliche Angaben, wie im Beispiel etwa das Labelrecall.Die extrahierten Texte liegen in den Projektverzeichnissen allerdings nicht als einfache Textdateien vor, sondern in Form spezieller XML-Dateien im hOCR-Format [7], in denen neben dem reinen Text die Position im ursprünglichen Dokument vermerkt ist. Das ermöglicht es, die Texte exakt über die Bilddateien zu legen.
Nach dem Erstellen eines Dokuments als Projekt können Sie diesem zusätzliche, vom OCR-Prozess nicht erkannte oder im Dokument nicht vorhandene Stichwörter zuordnen. Das erledigen Sie über eine Schaltfläche, die an den ausgewählten Dokumenten erscheint.
Darüber wählen Sie entweder ein bestehendes Label aus oder fügen neue Labels mit der entsprechenden Schaltfläche hinzu. Zusätzlich erscheint der Schlagwort-Editor, der es ermöglicht, farbige Marken mit dem Dokument zu verknüpfen (Abbildung 6). Diese abstrakten Marken erweisen sich zwar als interessantes Konzept, helfen in der Praxis aber nur bedingt weiter, denn die Software erlaubt weder das Suchen noch Sortieren nach diesem Kriterium.
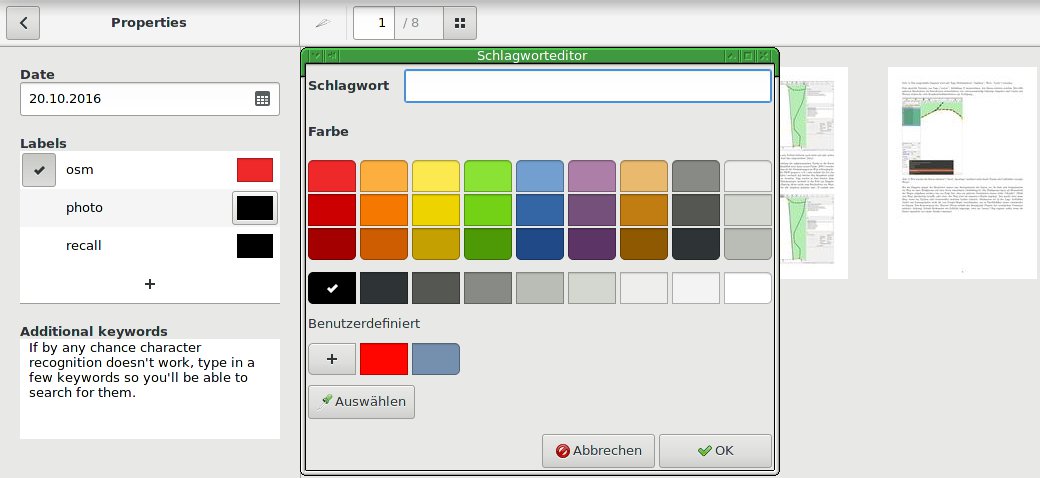
Abbildung 6: Label, farbige Marken und Schlüsselwörter erlauben es Ihnen, die Dokumente mit zusätzlichen Informationen zu versehen.
Die Applikation erlaubt es, beim Scannen einen gewissen Einfluss auf das Ergebnis zu nehmen. Dazu starten Sie das Scannen über die gleichnamige Schaltfläche im Dialog Einstellungen. Dort legen Sie dann fest, in welchen Bereichen die Software relevanten Text findet.
Beim Scannen selbst zeigt das Programm nach jeder Seite eine Vorschau (Abbildung 7). Am oberen rechten Rand dieser Seiten erscheinen mehrere Schaltflächen, mit denen Sie nachträglich die Seite drehen und beschneiden. Weitergehende Bearbeitungen sieht Paperwork nicht vor. So ist es insbesondere nicht möglich, den Kontrast der Scans zu verbessern oder via Unpaper Korrekturen vorzunehmen.
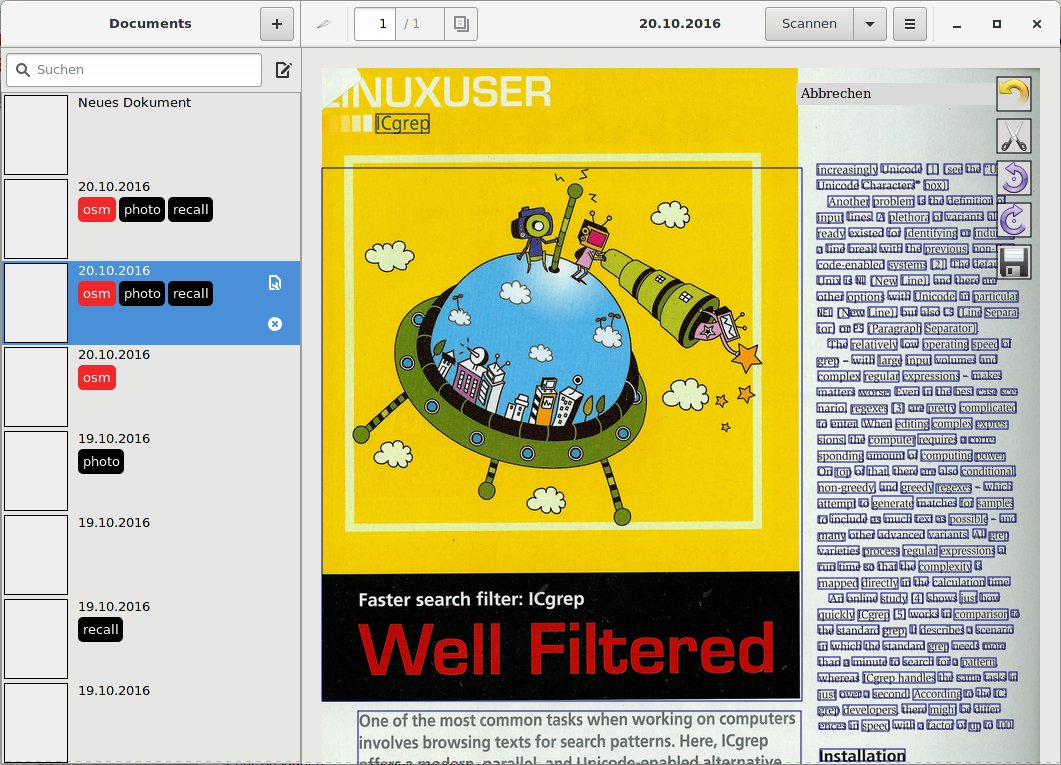
Abbildung 7: Nach dem Scannen zeigt das Programm die zuletzt eingelesene Seite und bietet rudimentäre Möglichkeiten zum Bearbeiten.
Probleme
Bei der OCR-Erkennungsrate weist Paperwork erhebliche Schwächen auf. Selbst bei guten Scans oder sogar bei Text-PDF-Dokumenten erzeugt das Programm eine ganze Reihe von Fehlern. Selbst die nachgeschaltete Rechtschreibprüfung schafft hier kaum Abhilfe (Abbildung 8).
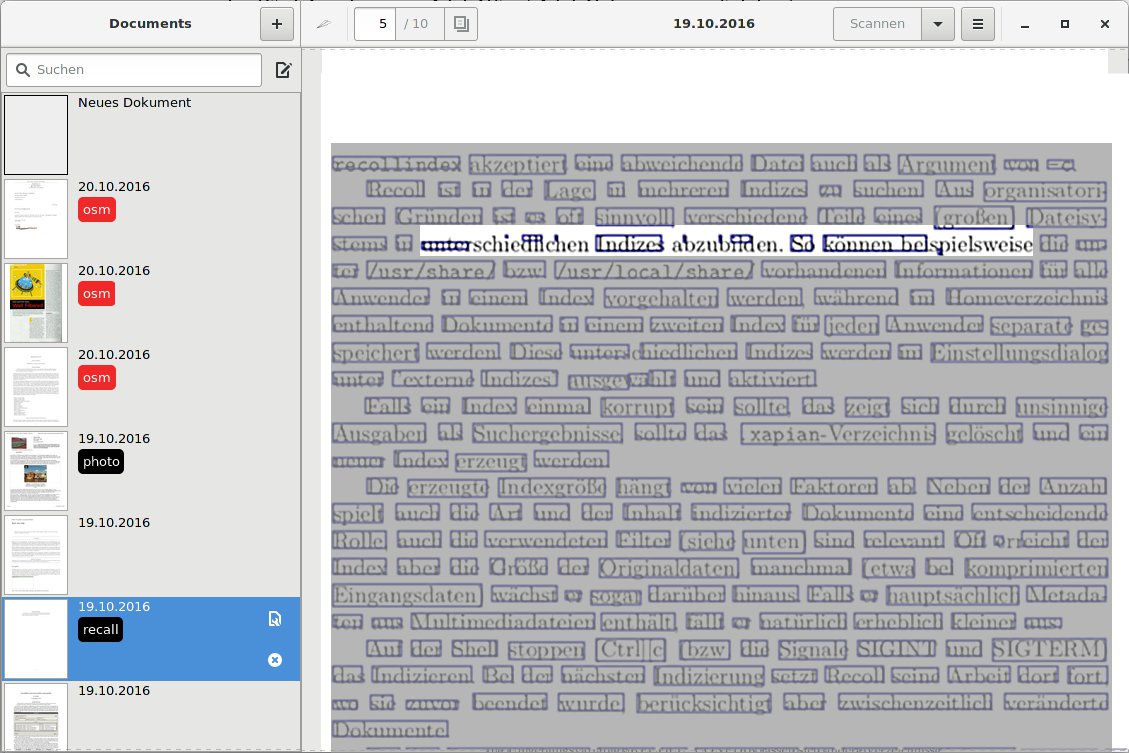
Abbildung 8: Bemerkenswerte Probleme zeigen sich beim OCR-Prozess: Obwohl Tesseract als gute, leistungsfähige OCR-Engine gilt, schafft es Paperwork, aus PDF-Dokumenten fehlerhafte Texte zu erzeugen.
Beim Erstellen des Index sammelt die Applikation die aus den Texten extrahierten Wörter. Als Anwender haben Sie keinen Einfluss darauf, was in den Index gelangt und was nicht. Dazu müssten Sie sich in Whoosh einarbeiten, was nicht ohne erheblichen Aufwand gelingt. Der Indexer ist recht leistungsfähig, allerdings nutzt Paperwork ihn derzeit nicht optimal.
Paperwork speichert den Index im Verzeichnis ~/.local/share/paperwork/index/, also unabhängig von der Datenbank. Das schafft Probleme, wenn es darum geht, größere Mengen an Dokumenten portabel zu verwalten. Im Verzeichnis finden Sie eine Reihe von nicht direkt lesbaren Dateien mit den extrahierten Schlüsselwörtern.
Auch vergibt das Programm bisher weder sinnvolle Titel für die Dokumente, noch ist es möglich, diese Titel manuell zu ändern. Insbesondere, wenn Sie an einem Tag mehrere Dokumente aufnehmen, erweist sich das Verfahren als hilfreich. Das manuelle Taggen mit zusätzlichen Schlagwörtern ist eine mühselige Alternative. Dazu kommt, dass das Programm aktuell verwendete Labels automatisch allen folgenden Dokumenten zuordnet.
Die Suche fällt ebenfalls nicht leicht: Bisher behandelt Paperwork alle Texte gleich; das Programm unterscheidet weder zwischen Inhalt, Label oder Titel des Dokuments. Einzig die Erweiterte Suche erlaubt, in sehr geringem Maße Einfluss auf die Ergebnisse zu nehmen (Abbildung 9).
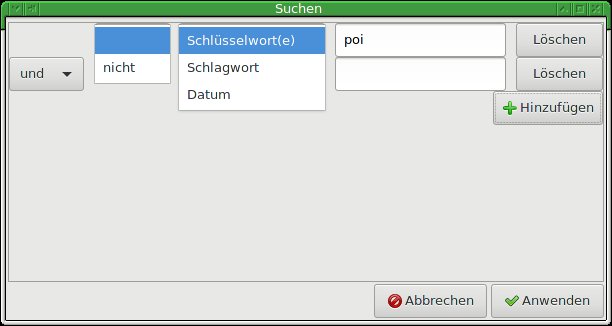
Abbildung 9: Die erweiterte Suche erlaubt, nach mehreren verknüpften Stichwörtern zu suchen.
So gelingt es zwar, bestimmte Stichwörter hinzuzufügen und auszuschließen, allerdings ist das recht mühsam. Metadaten von PDF-Dokumenten wertet Paperwork bisher gar nicht aus. Auch eine inhaltliche Unterscheidung – etwa zwischen Titel und Autor – kennt das Programm bislang nicht.
Fazit
Eine integrierte Lösung bietet Paperwork derzeit nicht. Dafür fehlen zu viele Features, hinzu kommen eklatante Probleme mit den bisher vorhandenen Funktionen. Die derzeit unterstützten Formate JPEG und PDF reichen bei Weitem nicht aus.
Die Tatsache, dass Paperwork PDFs selbst dann noch via OCR auswertet, wenn sie bereits Text enthalten, ist ebenfalls unverständlich. Dasselbe gilt für die fehlende Möglichkeit, Dokumente unter ihrem Titel aufzunehmen und die Metadaten auszuwerten.
Ein weiteres Manko von Paperwork stellt der Einsatz von Python 2.7 dar: Das führt bei einigen Distributionen zu Problemen, da diese inzwischen voreingestellt auf Python 3 setzen. Bei Arch Linux sind diese Probleme momentan behoben, treten aber möglicherweise nach einem Update erneut auf.
Paperwork-Alternativen
Um gescannte Dokumente mit einer Textebene zu versehen, gibt es inzwischen eine ganze Reihe von Möglichkeiten. Sehr bekannt und in der Praxis erprobt ist Gscan2pdf. Die Alternativen Xsane2djvu oder OCRmyPDF [8] erzeugen ebenfalls oft gute Resultate. Der Vorteil von Gscan2pdf liegt unter anderem darin, dass es eine wesentlich weitergehende Vorbereitung der Seiten erlaubt, bevor es sie an die OCR-Engine sendet.
Um Text aus Dokumenten unterschiedlicher Formate – allerdings ohne explizite OCR-Bearbeitung – zu erschließen, ist Recoll [9] eine gute Wahl. Es verwendet neben dem Index überhaupt keine Datenbank, sondern überwacht und bearbeitet rekursiv eine Reihe von zuvor eingestellten Verzeichnissen. Dabei erkennt es eine Vielzahl von Formaten und erlaubt es, die Suchfunktion zu steuern.
Für die Aufnahme von Text-PDF-Dokumenten in eine Datenbank bedarf es eigentlich fast keiner Vorarbeiten: Programme wie Calibre [10] machen das ohne Probleme, und zwar oft fehlerfrei. Obwohl eigentlich zum Verwalten von E-Books entwickelt, nimmt das Programm Text-, HTML-, ODT- sowie PDF-Dokumente auf und zeigt diese an.
Ohne besondere Vorkehrungen ist Calibre aber nicht in der Lage, eine Volltextsuche vorzunehmen. Allerdings gibt es inzwischen mehrere Plugins, unter anderem auf Basis von Recoll, die das nachrüsten. Die Kombination von Calibre und Recoll erweist sich als gute Lösung, um Dokumente in unterschiedlichen Formaten zu speichern und verwalten. Für die OCR-Verarbeitung bietet sich dabei Gscan2pdf an.
Infos
[1] Paperwork: https://github.com/jflesch/paperwork/#readme
[2] Tesseract-OCR: https://github.com/tesseract-ocr/
[3] Installation: https://github.com/jflesch/paperwork/wiki/Update
[4] Paperwork unter Ubuntu: http://wiki.ubuntuusers.de/Paperwork
[5] Whoosh: http://whoosh.readthedocs.org/en/latest/quickstart.html
[6] Gscan2pdf: Karsten Günther, “Scannen und OCR mit Gscan2pdf”, LU 10/2010, S. 54, https://www.linux-community.de/21691
[7] hOCR-Files: https://de.wikipedia.org/wiki/HOCR_%28Standard%29
[8] OCRmyPDF: https://github.com/jbarlow83/OCRmyPDF
[9] Recoll: Karsten Günther, “Total Recoll”, LU 01/2012, S. 60, https://www.linux-community.de/24952
[10] Calibre: Karsten Günther, “Bibliothekar”, LU 01/2015, S. 34, https://www.linux-community.de/31467




