

PDFs haben sich als verlustfreies Austauschformat durchgesetzt. Mit den passenden Werkzeugen kombinieren Sie Seiten aus verschiedenen Dateien und machen das Ergebnis fit für den Mail-Versand.
Der Postscript- und PDF-Interpreter Ghostscript ist auf jedem Linux-Desktop installiert und eignet sich hervorragend, um die Auflösung und das Kompressionsverfahren von eingebetteten Bildern zu verändern. Seine Aufrufparameter fallen allerdings recht unhandlich aus. Das smarte Konsolenwerkzeug Stapler verbirgt sie und erlaubt es außerdem, Seiten aus PDFs zu extrahieren oder mehrere solcher Dateien bei Bedarf zusammenzufügen.
Das Portable Document Format PDF eignet sich aus mehreren Gründen als optimales Format zum Archivieren und Austauschen von Dokumenten: Es kapselt Bitmaps, Vektorgrafiken und Text und bettet zusätzlich Schriften ein – eine unabdingbare Grundlage für eine identische Anzeige auf allen Geräten. Außerdem stehen sowohl verlustfreie als auch verlustbehaftete Verfahren zum Komprimieren von Bitmaps bereit.
Unter Linux exportieren viele Programme Daten verlustfrei als PDF, die Funktion zum Drucken basiert auf dem verwandten Format Postscript. Im Zweifelsfall lässt sich nach Installation des Pakets cups-pdf immer noch ein virtueller Druckertreiber installieren, der als Ergebnis ebenfalls eine PDF-Datei liefert. In der Cups-Administrationsseite, die Sie mit Browser über den Port 631 auf dem entsprechenden Rechner erreichen, also etwa http://localhost:631/admin, steht dafür gleich nach Klick auf Add Printer der Druckertyp CUPS-PDF (Virtual PDF Printer) zur Auswahl.
Der Nachteil des komplexen Formats: Es gibt nur wenige freie Programme, um es zu bearbeiten. Wir zeigen Ihnen drei Werkzeuge, mit denen Sie Seiten aus PDFs herauslösen oder mehrere PDFs kombinieren, große PDFs stärker komprimieren und die Dokumente mit Notizen versehen.
Richtig zusammengestellt
Die erste Fingerübung besteht darin, Seiten aus einem PDF herauszulösen. Oft muss man dazu Ausschnitte aus mehreren Dateien zusammenführen, wobei dann gelegentlich die Ausrichtung der Seiten nicht übereinstimmt. Hier springt das praktische Python-Programm Stapler [1] – der Name leitet sich vom englischen Begriff für Heftmaschine ab – in die Bresche: Es beherrscht das Herauslösen, Kombinieren und Drehen von Seiten (Abbildung 1).

Abbildung 1: Mit den Parametern sel oder cat (oben) von Stapler lösen Sie Bereiche aus PDFs, die Sie bei Bedarf in 90-Grad-Schritten drehen (unten).
Dazu rufen Sie Stapler nach dem in der ersten Zeile von Listing 1 gezeigten Schema auf. Der am häufigsten genutzte Parameter sel weist das Programm an, die nach dem Dateinamen angegebenen Bereiche zu extrahieren. Das klappt auch für mehrere PDFs.
Listing 1
$ stapler sel a.pdf 1-3 b.pdf 5-end out.pdf $ stapler sel a.pdf 4-8D 20-40 b.pdf 1-5L out.pdf $ stapler zip a.pdf 1-6D b.pdf 1-6
Der gezeigte Befehl fügt die Auswahlen zur neuen Datei out.pdf zusammen. Das Schlüsselwort end steht, wie sich unschwer erraten lässt, für die letzte Seite eines PDFs. Statt eines Bereichs dürfen Sie auch einzelne Seitennummern angeben. Ohne Angabe von Seite oder Bereich wählt Stapler alle Seiten eines Dokuments aus. Geben Sie einen negativen Bereich an, etwa 5-1, fügt die Software die Seiten in umgekehrter Reihenfolge ein.
Möchten Sie Seiten drehen, dann hängen Sie an die Angabe für einen Bereich die Buchstaben R (90 Grad im Uhrzeigersinn), L (90 Grad gegen den Uhrzeigersinn) oder D (180 Grad) an (Listing 1, zweite Zeile).
Statt mit sel bestimmte Bereiche auszuwählen, schließen Sie sie mit del gegebenenfalls aus. Der Befehl split spaltet ein PDF in Dateien mit jeweils einer Seite auf – praktisch, wenn Sie die Seiten einzeln in Inkscape bearbeiten möchten. Geben Sie dabei keinen Namen für die Ausgabedatei an, benennt das Tool die Dateien nach der Eingabedatei mit einer per Unterstrich angehängten Seitenzahl.
Liegen gerade und ungerade Seiten in zwei separaten PDFs vor, dann mischt der Befehl zip (“zipper”) die beiden Dateien nach dem Reißverschlussverfahren (Listing 1, letzte Zeile). Geben Sie dazu einfach die zwei PDFs an, wenn nötig mit einer Auswahl an Seiten und mit Drehrichtung. Stapler reiht immer eine Seite der ersten Quelle und eine Seite der zweiten aneinander.
Luft rauslassen
Nun enthält das PDF schon die richtigen Seiten in einheitlicher Ausrichtung. Doch gerade selbst eingescannte PDFs fallen oft so groß aus, dass es Probleme bereitet, sie per E-Mail zu verschicken. Das liegt unter Umständen an der Auflösung der eingebetteten Bitmaps oder an einer zu schwachen oder sogar fehlenden Kompression. Das ansonsten praktische Tool Xsane [2] beispielsweise erzeugt gänzlich unkomprimierte PDFs, bei denen schon eine in 150 dpi Auflösung eingescannte farbige Seite über 5 MByte belegt (Abbildung 2).

Abbildung 2: Das Programm Xsane liefert für den Farbscan einer DIN-A4-Seite ein 5,1 MByte großes PDF. Das in diesem Beitrag vorgestellte Skript quetscht die Datei – mit Qualitätseinbußen, aber in gleicher Auflösung – bis auf 161 KByte zusammen.
Es gibt eine pfiffige Methode, um herauszufinden, mit welchen Kompressionsverfahren ein PDF behandelt wurde: Dazu rufen Sie strings PDF-Datei | grep /Filter auf der Konsole auf. Das Programm Strings, ein Teil der Binutils, filtert aus dem Zeichensalat eines PDFs die in Abbildung 3 gezeigten Zeichen heraus. Mit Grep suchen Sie dann nach Zeilen mit dem Schlüsselwort /Filter, auf das dann einer der in der Tabelle “Kompressionsverfahren” genannten Algorithmen folgt – im konkreten Fall FlateDecode.
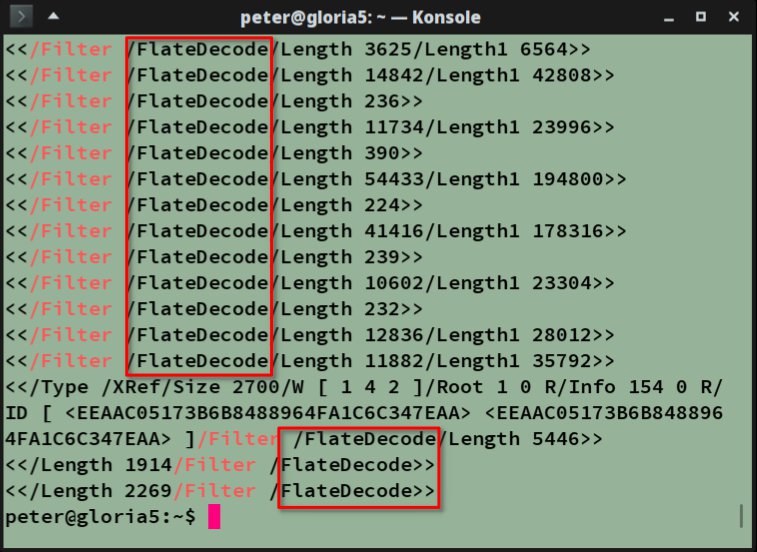
Abbildung 3: Unkomfortabel, aber zuverlässig: Indem Sie das PDF mit Grep nach der Zeichenfolge /Filter durchsuchen, finden Sie schnell das eingesetzte Kompressionsverfahren heraus.
|
Schlüsselwort |
Erläuterung |
|---|---|
|
|
verlustbehaftete JPEG-Kompression |
|
|
verlustfreie ZIP-Kompression |
|
|
JPEG-2000-Kompression, steht in Ghostscript auf vielen Linux-Systemen nicht bereit |
|
|
für Monochrombilder, Fax-Kompression |
|
|
für Monochrombilder, veraltet |
|
|
für Monochrombilder, veraltet |
Hier kommt Ghostscript ins Spiel, das Schweizer Taschenmesser zum Bearbeiten von PDFs, auf dem unter anderem das Drucken unter Linux aufsetzt. Es passt sowohl die Auflösung als auch den eingesetzten Algorithmus zum Komprimieren Ihren Bedürfnissen an und verkleinert auf diese Weise Dateien oft um ein Mehrfaches. Allerdings fallen die Optionen des Kommandozeilenwerkzeugs äußerst sperrig aus. Es liegt daher nahe, einen passenden Aufruf in ein Shell-Skript zu verpacken; Listing 2 zeigt ein Beispiel.
Listing 2
#!/bin/bash
# FlateEncode, wenn dritter Parameter=1
compression="DCTEncode"
if [ "$3" -eq 1 ]; then
compression="FlateEncode"
fi
# Ghostscript-Aufrufparameter
params="-q -dNOPAUSE -dBATCH \
-sDEVICE=pdfwrite \
-dCompatibilityLevel=1.3 \
-dCompressPages=true \
-dEmbedAllFonts=true \
-dSubsetFonts=true \
-dPDFSETTINGS=/screen \
-dAutoFilterColorImages=false \
-dAutoFilterGrayImages=false \
-dAutoFilterMonoImages=false \
-dColorImageDownsampleType=/Bicubic \
-dColorImageResolution=$2 \
-dGrayImageDownsampleType=/Bicubic \
-dGrayImageResolution=$2 \
-dMonoImageDownsampleType=/Bicubic \
-dMonoImageResolution=$2 \
-dColorImageFilter=/$compression \
-dGrayImageFilter=/$compression \
-dMonoImageFilter=/CCITTFaxEncode \
-sOutputFile=${1%\.pdf}_comp.pdf \
"
# Postscript für hohe JPEG-Qualität
if [ $3 -eq 2 ]; then
ps='.setpdfwrite << /ColorImageDict << /Blend 1 /VSamples [1 1 1 1] /QFactor 0.4 /HSamples [1 1 1 1] >> >>setdistillerparams'
fi
# Postscript für niedere JPEG-Qualität
if [ $3 -eq 4 ]; then
ps='.setpdfwrite << /ColorImageDict << /Blend 1 /VSamples [2 1 1 2] /QFactor 2.4 /HSamples [2 1 1 2] >> >>setdistillerparams'
fi
gs $params -c "$ps" -f "$1"
Das Skript rufen Sie nach dem Schema aus Listing 3 auf, wobei Sie die Auflösung als dpi-Wert angeben. Der letzte Parameter, ein Wert von 1 bis 4, wählt die Qualität der Kompression. 1 steht für verlustfreie Kompression, 2 bis 4 für verlustbehaftete Kompression in hoher, mittlerer oder niedriger Qualität.
Listing 3
$ pdfshrink.sh Datei Auflösung Kompression
Am Ende des Skripts erfolgt der Aufruf von gs mit den Parametern aus der Variablen params (Zeile 8). Alle Ghostscript-Optionen beginnen mit -d, was bei der weiteren Erläuterung keine Rolle spielt.
Da Ghostscript die Einstellungen zur Kompressionsqualität nicht als einfache Parameter akzeptiert, müssen Sie diese über einen kurzen Postscript-Schnipsel abweichend von den Standardeinstellungen setzen, falls der dritte Parameter des Skripts 2 oder 4 lautet.
Die Optionen -dBATCH und -dNOPAUSE versetzen Ghostscript in den nicht interaktiven Modus. Die PDF-spezifischen Optionen beginnen mit -sDEVICE=pdfwrite, der Auswahl der Pdfwrite-Ausgabe.
Als Wert für CompatibilityLevel wählt das Skript für kleinstmögliche Dateien die alte Version 1.3. CompressPages schaltet das Komprimieren der PDF-Seitendaten ein, nicht jedoch der eingebetteten Bilder. Das verringert die Größe in der Regel weniger als das Komprimieren der Bitmaps, verursacht aber keinen großen Rechenaufwand.
Mit EmbedAllFonts betten Sie die Schriftdaten ein, wie es bei PDFs zum Austausch und zum Archivieren geboten ist. Der Parameter SubsetFonts beschränkt das auf Zeichen der Schriftarten, die tatsächlich im PDF vorkommen.
Dann folgen die Optionen DownsampleType und Resolution für Farb-, Graustufen- und Monochrombilder. /Bicubic wählt einen qualitativ hochwertigen Algorithmus zum Anpassen der Auflösung. Die Resolution-Optionen setzen die neue Auflösung auf den Wert aus dem zweiten Aufruf-Parameter ($2) des Skripts.
Grau und in Farbe
Die Angaben AutoFilterColorImages=false, AutoFilterGrayImages=false und AutoFilterMonoImages=false sorgen dafür, dass Ghostscript die Dateien stets mit der unter -ColorImageFilter angegebenen Methode komprimiert. Lautet der Wert true, entscheidet die Software, ob es sich um eine Skizze mit Linien oder ein Foto handelt und komprimiert Ersteres verlustfrei, Letzteres dagegen verlustbehaftet.
Hingegen verwendet das Skript stets das in der Variable $compression gespeicherte Kompressionsverfahren, und zwar mit den Aufrufparametern ColorImageFilter und GrayImageFilter, also für Graustufen- und Farbbilder. Für monochrome Bilder gibt es nichts besseres als den Fax-Algorithmus CCITTFaxEncode, der deswegen unabhängig vom Aufruf des Skripts zum Einsatz kommt.
Rufen Sie das Skript mit 1 als drittem Parameter auf, setzt es den Inhalt von $compression auf FlateEncode. Das führt zu einer verlustfreien Kompression, wie man sie aus ZIP-Dateien kennt. Die resultierende, vergleichsweise geringe Kompression hängt vom Detailreichtum ab. Im Scan-Beispiel aus Abbildung 2 dürften Druckraster und Scannerrauschen die Dateigröße in die Höhe treiben.
Liegt der dritte Parameter im Bereich von 2 bis 4, so steht in $compression der Wert /DCTEncode. Das führt zu einer verlustbehafteten JPEG-Kompression samt der bekannten Artefakte (Abbildung 4, erstes bis drittes Teilbild von oben), aber auch zu einer drastischen Verkleinerung auf zwischen 5 und 10 Prozent des Ausgangsumfangs.

Abbildung 4: Unten der Original-Scan, dessen Qualität die verlustfreie Kompression nicht verändert (Skript-Option 1). Darüber folgen verlustbehaftet komprimierte Varianten in abnehmender Qualität (Skript-Optionen 2 bis 4).
Rufen Sie das Skript mit 3 als letztem Parameter auf, kommen über die Option PDFSETTINGS=/screen die Voreinstellungen eines für die Bildschirmanzeige optimierten PDFs zum Einsatz. Adobe hat für dieses Profil eine JPEG-Qualitätseinstellung gewählt, die bei relativ starker Kompression zwar sichtbare Schlieren im Bild hinterlässt (Abbildung 4, zweites Teilbild von oben), aber die Lesbarkeit wenig beeinträchtigt. Falls die Artefakte Sie stören, rufen Sie das Skript mit 2 als drittem Parameter auf. Das weist der Variablen $ps ein kurzes Postscript-Fragment zu, das die JPEG-Kompressionsqualität auf Maximum setzt.
Ghostscript übernimmt den Code über die Option -c, der Schalter -f setzt die Fragmentsprache auf Postscript [3]. Das Resultat der JPEG-Kompression (Abbildung 4, drittes Teilbild von oben) lässt sich optisch kaum von der verlustfreien Variante unterscheiden, fiel aber bei der Testseite etwa siebenmal kleiner aus.
Rufen Sie das Skript mit 4 als drittem Parameter auf, dann stellt der Postscript-Code in $ps die für PDFs maximal mögliche JPEG-Kompressionsstufe ein. Dabei treten deutliche Artefakte auf (Abbildung 4, oberstes Teilbild), normale Schriftgrößen bleiben aber bei einer Auflösung von 150 dpi dennoch gut zu lesen.
Fazit
Mit Stapler und dem vorgestellten Skript erzeugen Sie PDFs mit den gewünschten Seiten und in angemessener Kompression. Möchten Sie das Dokument zusätzlich mit Kommentaren anreichern, gelingt das am einfachsten mit Xournal [4]. Mit dem Programm fügen Sie Text, per Hand gezogene Linien und halbtransparente Hervorhebungen ein (Abbildung 5), wobei eine zusätzliche Ebene entsteht, die die Dateien nicht wesentlich vergrößert.
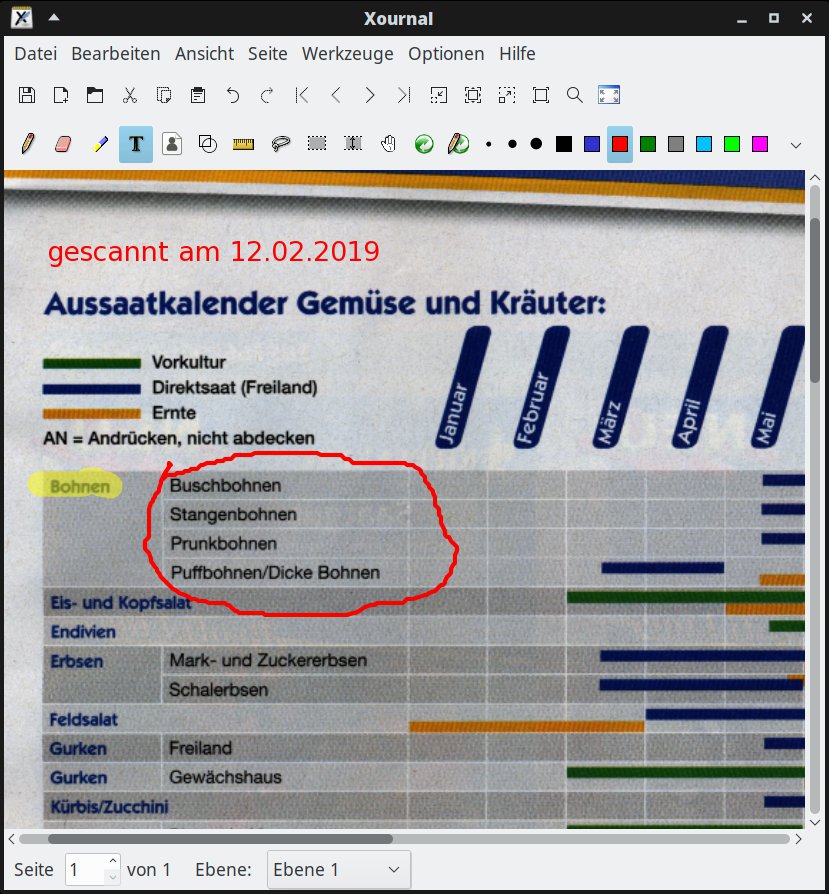
Abbildung 5: Eigentlich wurde Xournal als Programm zum Anfertigen von Notizen konzipiert, kann diese aber unter anderem auch PDF-Dokumenten hinzufügen (Datei | PDF annotieren, danach Datei | Als PDF exportieren).
Infos




