

Im Ordner “Bank” liegen die Kontoauszüge der letzten drei Jahre, und Sie fragen sich, wann Sie im örtlichen Elektronikmarkt den neuen Monitor gekauft haben. Über manuelles Öffnen der Dateien im PDF-Betrachter und dessen Suchfunktion finden Sie das in wenigen Minuten heraus, trotzdem ist die Vorgehensweise umständlich. Mit “pdfgrep” erhalten Sie die Antwort sofort. Einmal dabei, bietet es sich auch an, LibreOffice-Dokumente zu durchsuchen.
Viele Freunde der Kommandozeile kennen das klassische Tool grep, mit dem sich Textdateien nach Suchbegriffen durchforsten lassen [1]; für komplexere Suchen unterstützt das Programm zudem die so genannten regulären Ausdrücke (die sehr grob mit dem Einsatz der Wildcard-Zeichen “*” und “?” bei der Auswahl von Dateinamen verwandt, aber deutlich leistungsfähiger sind – mehr dazu weiter unten). Allerdings liegen heute immer mehr Dateien nicht im einfachen Textformat vor, und grep scheitert fast immer beim Versuch, in PDF- oder LibreOffice-Dateien ein Wort zu finden, denn beide Dokumentformate speichern Textinhalte komprimiert. So erzeugt z. B. der Aufruf
grep -i Linux EasyLinux-CE-2016-02.pdf
der die Community Edition der letzten EasyLinux-Ausgabe nach dem Wort “Linux” durchsuchen soll, keine einzige Ausgabezeile, obwohl ein Blick mit dem PDF-Viewer schnell zeigt, dass das Wort häufig im Dokument vorkommt.
Eine umständliche Möglichkeit, in PDF- und LibreOffice-Dateien dennoch mit grep zu suchen, ist die Konvertierung in ein Textformat. Für die Officeformate geht das über den Export aus LibreOffice heraus, PDF-Dateien könnte man mit pdftotext umwandeln und die so erstellte txt-Datei dann mit grep analysieren:
[esser@quad:~]$ pdftotext EasyLinux-CE-2016-02.pdf [esser@quad:~]$ grep Linux EasyLinux-CE-2016-02.txt Live-Linux-Distribution Beide Linux-Versionen mit uftakt: Mit Linux zum Smart-TV ...
Das ist aber nicht praktikabel, denn der Sinn der Suche mit grep ist ja oft, aus einer Vielzahl von Dateien diejenigen zu identifizieren, die einen Suchbegriff enthalten – dafür müssten aber alle in Frage kommenden Dokumente zusätzlich in einer reinen Textfassung vorliegen. Wir stellen Lösungen vor, mit denen Sie ohne solchen Aufwand direkt in PDF- und LibreOffice-Dateien suchen können.
PDF mit “pdfgrep”
Für das PDF-Format steht mit pdfgrep[2] ein Tool zur Verfügung, das Sie wie grep benutzen können; es erwartet aber, dass die zu durchsuchenden Dateien im PDF- statt im Textformat vorliegen. Für die obige Beispieldatei von EasyLinux findet es entsprechend zahlreiche Treffer zum Suchbegriff “Linux”:
[esser@quad:~]$ pdfgrep Linux EasyLinux-CE-2016-02.pdf Long Term Support (LTS) Live-Linux-Distribution - KDE 4.14 Beide Linux-Versionen mit - Linux-Kernel 3.19 + 4.2.0 Installationsanleitung ab S. 102 ...
In der Ausgabe hebt das Programm die Treffer farbig hervor (was wir hier durch kursive Schrift anzeigen). Listing 1 zeigt die Suche nach dem Wort “Spiegel” in einer größeren Sammlung von Kontoauszügen – neben dem Buchungstext steht zufällig auch direkt das Datum der Abbuchung, pdfgrep zeigt immer ein bisschen Text um die Fundstelle herum an. Wie viel umgebender Text zu sehen ist, hängt von der Breite des Terminalfensters ab: Das Programm schreibt jeweils bis an den Rand der Zeile.
Vor der Nutzung steht die Einrichtung der Software, die nicht zur Standardauswahl der gängigen Distributionen gehört. OpenSuse-Anwender installieren das Programm über die One-Click-Funktion von der zugehörigen Paketseite [3] aus dem Repository Publishing; bei Ubuntu ist das Paket pdfgrep im universe-Repository enthalten, das Sie eventuell erst in der Datei /etc/apt/sources.list aktivieren müssen.
Listing 1
Suche nach “Spiegel”
[esser@quad:Kontoauszuege]$ pdfgrep -i Spiegel *2015*pdf Kontoauszug_20150131.pdf: SPIEGEL Verlag 14.01 Kontoauszug_20150131.pdf: 3000865, DER SPIEGEL - Hans-Georg Kontoauszug_20150501.pdf: SPIEGEL Verlag 14.04 Kontoauszug_20150501.pdf: 3000865, DER SPIEGEL - Hans-Georg Kontoauszug_20150530.pdf: SPIEGEL Verlag 06.05 Kontoauszug_20150530.pdf: 3101021, DER SPIEGEL digital - Ha Kontoauszug_20150801.pdf: SPIEGEL Verlag 14.07 Kontoauszug_20150801.pdf: 3912865, DER SPIEGEL - Hans-Georg Kontoauszug_20151031.pdf: SPIEGEL Verlag 13.10 Kontoauszug_20151031.pdf: 3912865, DER SPIEGEL - Hans-Georg Kontoauszug_20151201.pdf: SPIEGEL Verlag 04.11 Kontoauszug_20151201.pdf: 3101021, DER SPIEGEL digital - Ha [esser@quad:Kontoauszuege]$ _
Seitenzahlen und Trefferzahl
Beim Durchsuchen von Textdateien mit grep erscheinen neben den Treffern auf Wunsch auch die Zeilennummern – das ist bei PDF-Dateien nicht möglich, aber wenn Sie z. B. in einem mehrere hundert Seiten starken Buch suchen, wäre etwas mehr Hilfe beim Aufspüren des Treffers praktisch. Dafür bietet pdfgrep die Option -n, über die das Programm Seitenzahlen ausgibt (Abbildung 1). Bei der parallelen Suche in mehreren Dateien (ebenfalls Abbildung 1) erscheinen vor den Treffern auch jeweils die Dateinamen. pdfgrep verwendet unterschiedliche Farben, um Dateiname, Seitenangabe und Treffer vom umgebenden Text abzusetzen.
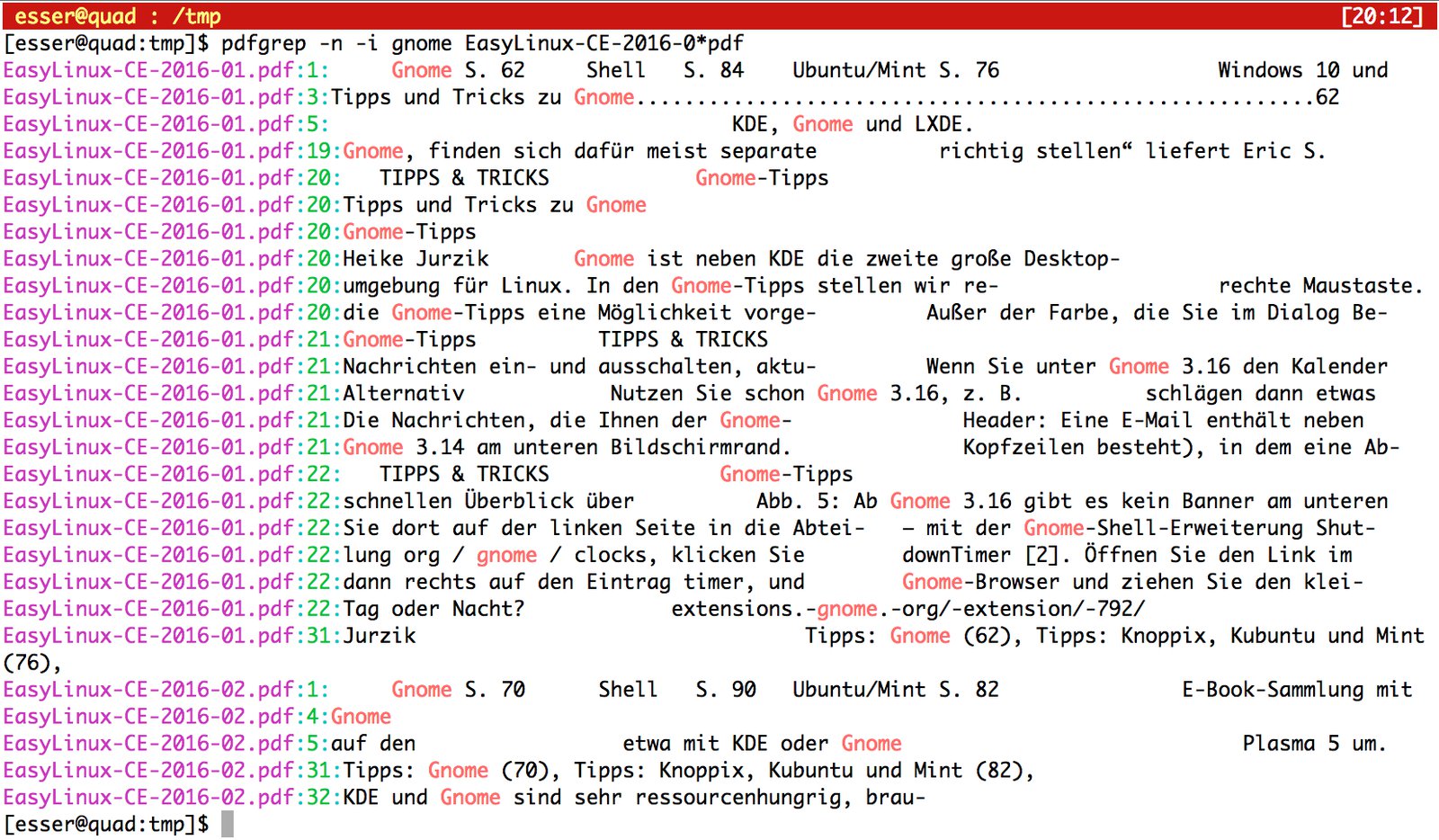
Abbildung 1: Über die Option “-n” zeigt “pdfgrep” auch Seitenzahlen zu den Treffern an. Hier hat es das Wort “Gnome” auf mehreren Seiten in zwei Community Editions von EasyLinux gefunden.
Sind Sie dagegen an der Trefferzahl interessiert, setzen Sie die Option -c (count, zählen) ein – dann gibt das Programm keine Textstellen aus, sondern verrät nur für jede Datei, wie oft der Suchbegriff vorkommt. (Hier erscheinen auch Dateien, in denen die Suche erfolglos war; die Trefferzahl ist dann 0.)
[esser@quad:tmp]$ pdfgrep -ci gnome EasyLinux-CE-2016-0*pdf EasyLinux-CE-2016-01.pdf:22 EasyLinux-CE-2016-02.pdf:5 [esser@quad:tmp]$ pdfgrep -ci heuristisch EasyLinux-CE-2016-0*pdf EasyLinux-CE-2016-01.pdf:2 EasyLinux-CE-2016-02.pdf:0
Um nacheinander aufzulisten, wie oft verschiedene Suchbegriffe in einem Dokument vorkommen, schreiben Sie sich eine kleine for-Schleife – der folgende Befehl sucht in einem älteren Linux-Buch nach den Begriffen KDE, Gnome und Linux und gibt die Ergebnisse übersichtlich aus:
[esser@quad:~]$ for suche in gnome kde linux; do echo -n "$suche: "; pdfgrep -ci $suche lgb2007.pdf; done gnome: 133 kde: 493 linux: 1930
Dabei durchläuft die Schleifenvariable suche die drei Begriffe und ruft pdfgrep jeweils passend auf. Vorab gibt der echo-Befehl noch den aktuellen Suchbegriff aus; seine Option -n unterdrückt den normal üblichen Zeilenumbruch, so dass Suchbegriff und Zahl in einer Zeile bleiben.
Reguläre Ausdrücke
Die Programme grep und pdfgrep verstehen für die Suche auch reguläre Ausdrücke. Die kommen immer dann zum Einsatz, wenn Sie nicht nach einem bestimmten Wort suchen, sondern den Suchbegriff allgemeiner fassen wollen. Ein Beispiel dafür wären Worte, die mit “a” anfangen, dann zwei beliebige Buchstaben haben und mit “e” enden (z. B.: “alle”, “alte”, “arme”). Um solche Worte zu finden, würden Sie als Suchbegriff a..e (mit zwei Punkten in der Mitte) verwenden und hätten damit einen ersten einfachen regulären Ausdruck erstellt. Eine weitere Möglichkeit ist die parallele Suche nach mehreren Suchbegriffen, die Sie erreichen, indem Sie die Suchbegriffe mit “|” verbinden und in Anführungszeichen setzen – Abbildung 2 zeigt die Treffer in zwei PDF-Dateien bei der Suche nach blau|grün.

Abbildung 2: Mit regulären Ausdrücken sind Sie flexibler als mit der Suche nach einem einfachen Wort.
Über ein Sternchen können Sie mehrfache Wiederholungen eines Teilausdrucks zulassen, so findet etwa das Muster ab\(cd\)*ef Textstellen, die mit “ab” beginnen, mit “ef” enden und dazwischen beliebig oft (oder gar nicht) “cd” enthalten (also z. B. “abef”, “abcdef” und “abcdcdcdef”). Die runden Klammern definieren “cd” als Gruppe, auf die dann das Sternchen wirkt, das die beliebige Wiederholung erlaubt – ohne die Klammern würde das Sternchen sich nur auf den Buchstaben “d” beziehen. Die Backslash-Zeichen “\”, die jeweils vor den Klammern stehen, sind nötig, damit grep oder pdfgrep nicht nach Klammerzeichen im Text suchen, sondern die Klammern als Teil der Syntax regulärer Ausdrücke verstehen.
Es ist sogar möglich zu verlangen, dass Gruppen mehrfach im Text auftreten: Mit dem regulären Ausdruck
"AB\(.*\)CD\1"
finden Sie Textstellen, die aus “AB”, einem beliebigen Text, “CD” und danach der Wiederholung des Textes in der Mitte bestehen; auf dieses Muster passen z. B. “ABCD” (kein Text in der Mitte) und “ABzzCDzz”, nicht aber “ABxxCDyy”. Die Wiederholung wird hier durch \1 markiert (das bedeutet: erste markierte Gruppe); wenn Sie mehrere Gruppen definieren, zählen Sie einfach durch, z. B. so:
"AB\(.*\)XX\(.*\)CD\2YY\1"
Auf dieses zweite Beispiel passt etwa ABsssXXtttCDtttYYsss (mit Vertauschung von sss und ttt im hinteren Teil).
Auch wenn die Schreibweise eines Namens nicht genau bekannt ist, können reguläre Ausdrücke weiterhelfen: Über die eckigen Klammern können Sie eine Auswahl von Zeichen vorgeben, von denen jedes an dieser Stelle auftauchen darf. Der Klassiker ist der Nachname Meier, den es auch in den Varianten Maier, Mayer und Meyer gibt – der Ausdruck M[ae][iy]er erwischt alle vier.
[esser@quad:~]$ pdfgrep "M[ae][iy]er" Download/*pdf Download/CPCAI-86-06.pdf:einen hervorragenden Aufsatz von dem Meier oder Müller Download/DNH_2016-3.pdf: 424; Höfler, Sarah; Mayer, Julia: Der Weg zur
Einen aktuellen und umfangreicheren Artikel zu regulären Ausdrücken finden Sie in unserer Schwesterzeitschrift LinuxUser [7].
Suche in LibreOffice-Dateien
Einmal auf den Geschmack gekommen, möchten Sie vielleicht auch LibreOffice-Dateien (aus Writer, Calc oder Impress) durchsuchen – dafür gibt es kein fertiges Tool, aber für Shell-Anwender ist es kein Problem, in wenigen Minuten eines zusammenzubasteln. Dafür muss man den Aufbau der Dateien kennen: Egal, ob eine Datei die Endung .odt (Writer), .ods (Calc) oder .odp (Impress) hat, es handelt sich dabei um ein einfaches Zip-Archiv, das mehrere Dateien und Verzeichnisse enthält [4]. Wer dieses Archiv mit unzip entpackt, findet auf der obersten Ebene die Datei content.xml, die im Wenn Sie einen Blick in diese XML-Dateien werfen, stellen Sie fest, dass sie in schlecht lesbarer Form gespeichert sind: Es gibt extrem lange Zeilen, in denen keine Struktur erkennbar ist (Abbildung 3). Das Programm xmllint[5] schafft hier Abhilfe und zerlegt die langen Zeilen; danach lässt sich die so aufgeräumte XML-Datei gut mit grep durchsuchen, das ja zeilenweise arbeitet und bei der Originalversion der Dateien Treffer nicht ausreichend isoliert ausgeben würde. xmllint war bei unseren Tests unter OpenSuse und Ubuntu bereits vorinstalliert. Bei OpenSuse gehört es zum Paket libxml2-tools, bei Ubuntu zu libxml2-utils.
Aus dem in der content.xml-Datei aus Abbildung 3 versteckten Text macht xmllint eine besser lesbare Variante, welche u. a. die folgenden drei Zeilen enthält:
Einzelne Server-Anfragen i.d.R. problemlos, spannend bei Häufung, also hoher Last. Das ganze evtl. CPU- und I/O-intensiv
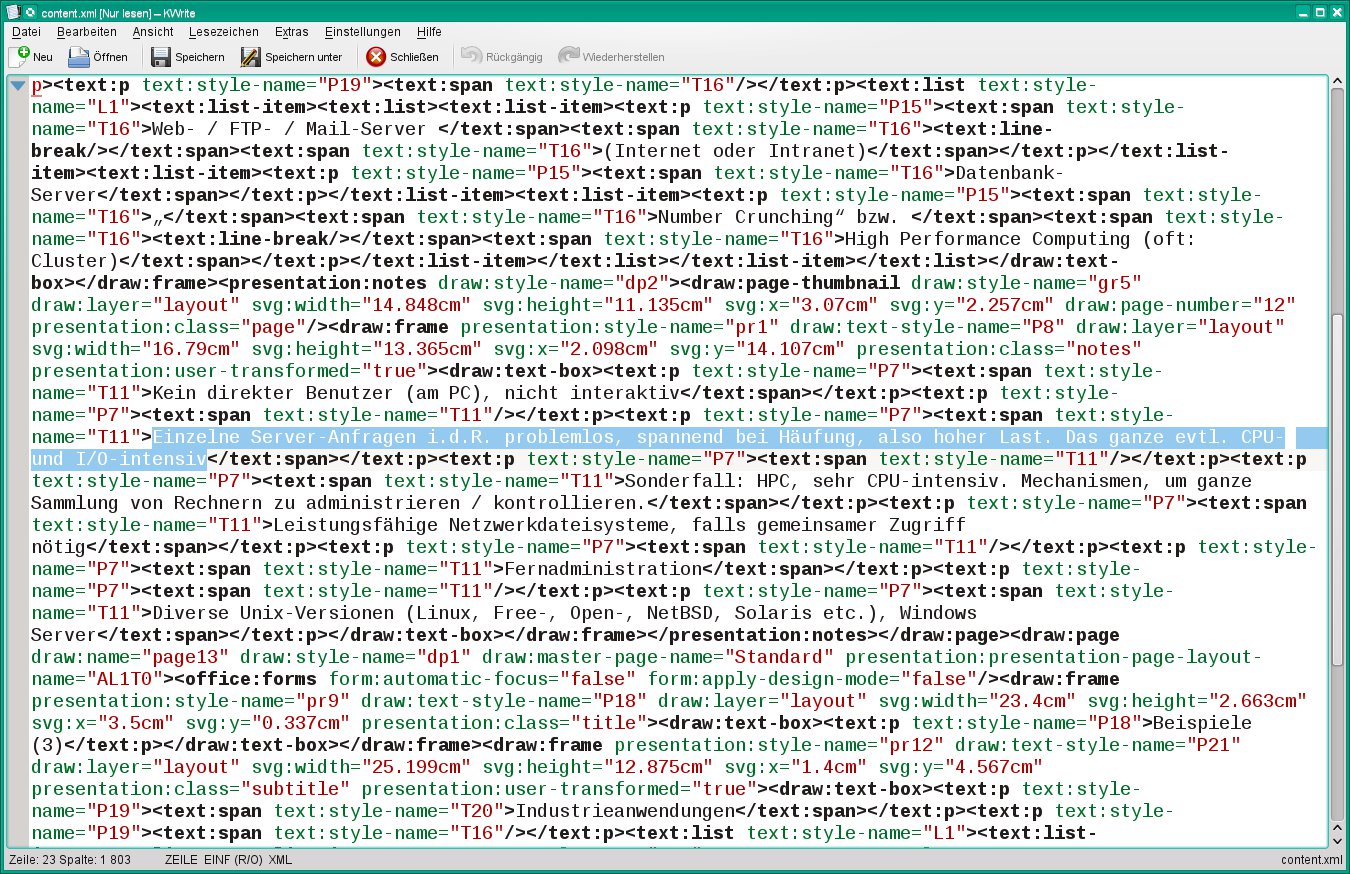
Abbildung 3: Inhalte verstecken die XML-Dateien von LibreOffice in unübersichtlichen Zeilen; “xmllint” räumt auf.
Alle zusammen: “uvgrep”
Wir haben für Sie ein Shell-Skript uvgrep erstellt, das mit allen drei Dateitypen zurecht kommt und (abhängig von der Dateiendung) grep oder pdfgrep aufruft; bei LibreOffice-Dateien nutzt es die gerade beschriebene Vorgehensweise mit unzip, xmllint und grep. Sie finden es in Listing 2 und können es (in erweiterter Form) auch von der Webseite Github herunterladen [6]. Das Tool versteht die Optionen -i und -n wie folgt:
- Über
-iwird die Groß- und Kleinschreibung ignoriert, - und die Option
-nsorgt bei Text- und PDF-Dateien dafür, dass hinter dem Dateinamen die Zeilen- bzw. Seitennummer erscheint. Für LibreOffice-Dateien ist die Option wirkungslos.
Der folgende Aufruf von uvgrep zeigt, wie das Programm gleichzeitig in allen drei Arten von Dokumenten nach dem Begriff “LibreOffice” sucht:
[esser@quad:~]$ uvgrep -in libreoffice *.sh *.pdf *.odt uvgrep.sh:5:# uvgrep: grep txt, PDF and LibreOffice files uvgrep.pdf:1: 5 # uvgrep: grep txt, PDF and LibreOffice files test.odt:Das ist ein kleiner Test-Text, in dem das Wort "LibreOffice" vorkommt.
Der Treffer aus der LibreOffice-Datei enthält dabei auch die XML-Auszeichnungen, die das Officepaket mitspeichert.
Listing 2
“uvgrep”
#!/bin/bash
# uvgrep (UniVersal Grep), version 0.9el, 2016/07/03
# (c) Hans-Georg Esser, EasyLinux, hgesser@easylinux.de
# uvgrep: grep txt, PDF and LibreOffice files
OPTERR=0
OPTIONS=""
ODTOPTIONS=""
while getopts ":in" option; do
case $option in
"?")
echo $0: Ungueltige Option "-$OPTARG"
exit 1;;
"i")
OPTIONS+=i
ODTOPTIONS+=i;;
"n")
OPTIONS+=n;;
esac
done
if [ "$OPTIONS" != "" ]; then OPTIONS="-$OPTIONS"; fi
if [ "$ODTOPTIONS" != "" ]; then ODTOPTIONS="-$ODTOPTIONS"; fi
shift $((OPTIND-1))
PATTERN=$1
shift
for file in $@; do
ext="${file##*.}"
filetype=$(echo $ext | tr 'A-Z' 'a-z')
case $filetype in
txt | sh | conf | pl | py)
if [ -f $file ]; then
grep -H --color $OPTIONS $PATTERN $file
else
echo $0: $file: Datei nicht gefunden >&2
fi;;
pdf)
if [ -f $file ]; then
pdfgrep -H $OPTIONS $PATTERN $file
else
echo $0: $file: Datei nicht gefunden >&2
fi;;
odt | ods | odp)
unzip -caq $file content.xml | xmllint --format - \
| sed -e 's/ *//' \
| grep $ODTOPTIONS -H --color $PATTERN \
| sed -e "s|^(standard input)|$file|" ;;
*)
echo $0: $file: Kann keine Dateien mit \
Endung "\".$filetype\"" verarbeiten >&2;;
esac
done
Das Skript prüft zunächst, ob Sie eine oder beide der Optionen -i und -n verwendet haben, und passt entsprechend die Variablen OPTIONS und ODTOPTIONS an. (Die Unterscheidung ist nötig, weil es für LibreOffice-Dateien nicht möglich ist, Seitenzahlen für die Treffer auszugeben.) Für die Erkennung der Optionen verwendet das Skript die Bash-Funktion getopts, bei der z. B. die Reihenfolge und Getrennt- oder Zusammenschreibung keine Rolle spielen – die Angaben -i -n, -n -i, -in und -ni sind also gleichwertig.
Der untere Teil des Skripts ist eine Schleife, die für jeden angegebenen Dateinamen prüft, ob es sich um einen Dateityp handelt, mit dem das Tool umgehen kann. Für diese Prüfung schaut es nur auf die Dateiendung (zulässig: .txt, .sh, .conf, .pl und .py für Textdateien, .pdf für PDF-Dokumente und .odt, .ods sowie .odp für LibreOffice- bzw. OpenOffice-Dateien). Eventuelle Groß-/Kleinschreibung in den Dateinamen ist dabei problemlos, weil der Befehl
filetype=$(echo $ext | tr 'A-Z' 'a-z')
mit Hilfe von tr zunächst alle Groß- in Kleinbuchstaben umwandelt.
Abhängig vom Dateityp ruft das Skript dann grep oder pdfgrep (für Text- bzw. PDF-Dateien) auf, bei LibreOffice-Dokumenten ist mehr zu tun: Dort zieht das Skript aus der Officedatei mit unzip die enthaltene Datei content.xml, jagt sie durch den Pretty Printerxmllint, filtert aus der Ausgabe führende Leerzeichen (mit sed) heraus und filtert das Ergebnis dann mit grep. Schließlich setzt es im Ergebnis mit sed noch den richtigen Dateinamen ein.
Support für Word, Excel, PowerPoint
Auch die Microsoft-XML-Formate .docx (Word), .xlsx (Excel) und .pptx (PowerPoint) lassen sich mit dieser Methode durchsuchen, das ist allerdings ein wenig aufwendiger, weil hier im Zip-Archiv nicht einheitlich eine Datei content.xml liegt, wie es bei LibreOffice der Fall ist. Stattdessen haben die Dokumente der drei Kategorien folgenden Aufbau, wobei sich Pfadangaben auf die Inhalte des Zip-Archivs beziehen:
- Bei Word liegt das Dokument in word/document.xml,
- Excel-Dateien spalten die einzelnen Tabellen in mehrere Dateien xl/worksheets/sheet*.xml auf,
- und bei PowerPoint gibt es für jede einzelne Folie eine separate Datei (ppt/slides/slide*.xml).
Die auf Github abgelegte Version von uvgrep[6] enthält die nötigen Anpassungen, so dass Sie damit auch die Microsoft-Formate durchsuchen können. Mit den älteren Office-Formaten (.doc, .xls und .ppt) funktioniert der Trick nicht, weil diese nicht XML, sondern ein proprietäres Binärformat einsetzen.
Mit ein wenig Arbeit können Sie die Skriptdatei an eigene Bedürfnisse anpassen und mit der eigenen Version auch weitere Dateiformate durchsuchen.
Fazit
Mit pdfgrep und uvgrep dehnen Sie den Einsatz des beliebten Textdateien-Suchwerkzeugs grep auf PDF- und LibreOffice-Dateien aus; die Version auf dem Github-Server ergänzt noch die Officeformate von Microsoft. Dadurch wird die Suche nach der richtigen Datei auf der Shell deutlich vereinfacht. Wenn Sie unter KDE die Desktop-Suchmaschine aktivieren und in Dolphin mit [Strg]+[F] die Suche aufrufen, steht eine ähnliche Funktionalität auch in grafischer Form zur Verfügung (Abbildung 4) – die Desktopsuche kann dabei alle erfassten Dateien des Anwenders finden, was bei vielen Treffern die Auswahl des richtigen Dokuments aber erschwert.
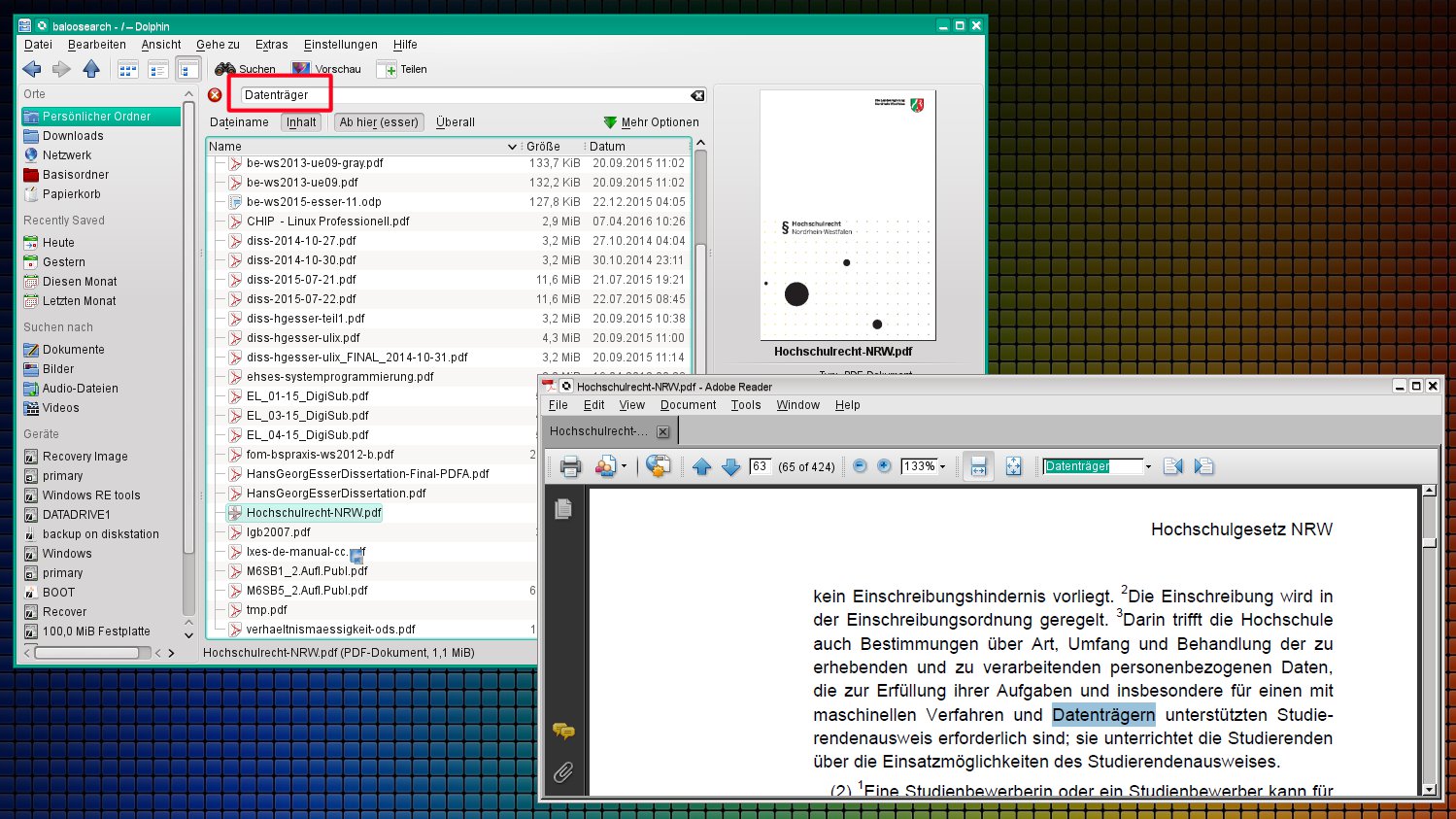
Strg+F die eingebaute Suchfunktion.” width=”300″ height=”169″ />
Strg+F die eingebaute Suchfunktion.Glossar
-
XML
-
Die Extensible Markup Language (XML) ist ein Regelwerk, mit dem man Auszeichnungssprachen definieren kann, die vom Aufbau her an HTML (die Hypertext Markup Language von Webseiten) erinnern. Diese können je nach Zweck der Sprache unterschiedliche Elemente enthalten, so lässt die von LibreOffice definierte Sprache z. B. über das Tag
<text:p>markierte Textabsätze zu. Programme können XML-Dokumente auf korrekte Syntax und “Validität” prüfen; letztere bedeutet, dass das Dokument vorgegebene Regeln einhält (z. B.: kein Absatz außerhalb einer Dokumentseite). -
Pretty Printer
-
Ein Pretty Printer (deutsch etwa: Schöndrucker) überarbeitet Programmtexte und ähnlich strukturierte Textdateien. Das hier benutzte Programm
xmllintversteht die Auszeichnungssprache XML und dient im Beispiel dazu, den von LibreOffice erzeugten Code (der sehr lange Zeilen enthält) mehrfach zu umbrechen, so dass im nächsten Schrittgrepnur die Fundstelle und ihre nähere Umgebung ausgibt.
Infos
[1] Artikel zu “grep”: Heike Jurzik, “Schriftführer des Systems”, EasyLinux 05/2006, S. 90 ff., http://www.easylinux.de/2006/05/090-guru/
[2] pdfgrep: https://pdfgrep.org/
[3] OpenSuse-Pakete (pdfgrep): https://software.opensuse.org/package/pdfgrep
[4] Artikel zum Aufbau von LibreOffice-Dokumenten: Hans-Georg Eßer, “Geheimdokumente”, EasyLinux 04/2011, S. 65 f., http://linux-community.de/24590
[5] xmllint: http://xmlsoft.org/xmllint.html
[6] Github-Seite zu uvgrep: https://github.com/hgesser/uvgrep
[7] Artikel zu regulären Ausdrücken: Frank Hofmann, “Schnipseljagd”, LinuxUser 06/2015, S. 10 ff., http://linux-community.de/35006
