

Bei Software-Projekten gibt es oft mehrere, teils parallel laufende Code-Zweige, an denen Entwickler arbeiten. Git unterstützt das durch sein Branch-Konzept.
Die Grundlagen eines VCS lassen sich schnell erlernen – das gilt auch für Git. Doch echte Projekte verlaufen meist nicht linear: Gerade, wenn mehrere Leute am Code arbeiten, sind parallele Zweige in der Entwicklung die Regel. Git ermöglicht es, diese in einem Repository (kurz: Repo) abzubilden. Selbst das Umstellen der Verzeichnisstruktur bereitet auf diese Weise keine Probleme.
Unser Beispiel [1] aus dem ersten Teil dieses Workshops besteht aus drei Textdateien, die in einem lokalen Repository liegen. Das genügt in der Regel, um die Dateien zu verwalten. Arbeiten Sie jedoch in einem Team, bringt ein entferntes Repository Vorteile mit sich. Es besteht die Möglichkeit, das Projekt damit zu verknüpfen.
Die zugehörigen Git-Kommandos lauten clone (Projekt anlegen und ausbuchen), push (Übertragen der Daten zum entfernten Repository), fetch (Daten vom entfernten Repository holen) und pull (Daten holen und zusammenführen). Der Begriff “Daten” steht in diesem Zusammenhang für die verknüpften oder angegebenen Referenzen und Objekte im Git-Index.
In die Vergangenheit
Abbildung 1 zeigt den Stand des Projekts vom Ende des ersten Workshop-Teils. Das Projekt enthält vier Commits, die entsprechend dem zeitlichen Verlauf auf einer Linie angeordnet sind. Mit Ausnahme des ersten Commits basiert jeder davon auf den jeweiligen Vorgänger. Eine solche Linie heißt Zweig, englisch “branch”.
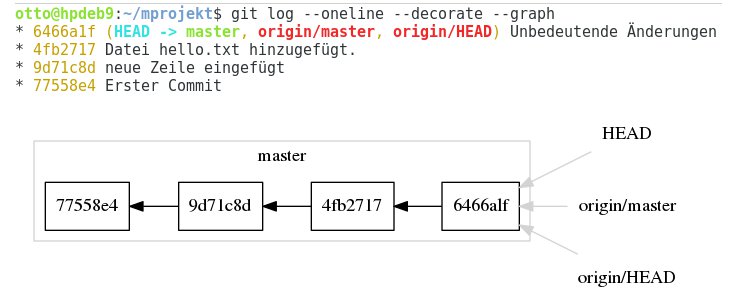
Abbildung 1: Sie ermitteln den Stand des Projekts mit dem Kommando git log --oneline --decorate --graph.
Beim Head (Kopf) handelt es sich um einen Zeiger auf die Version, auf der das aktuelle Arbeitsverzeichnis basiert, also das Ende des ausgecheckten Zweigs. Die Einträge mit dem Namen origin verweisen auf das Remote-Repository, aus dem Sie das Projekt geklont haben – in diesem Fall auf das Remote-Repository origin, zu Deutsch Ursprung. Die Informationen entsprechen dem Stand der letzten Synchronisation. Bei den Namen master und origin handelt es sich um Vorgaben, die Git vergibt, wenn Sie keine expliziten Angaben machen.
Zweige
Zweige ermöglichen eine nebenläufige Entwicklung. Typischerweise enthält der Hauptzweig die fertiggestellten oder bereits ausgelieferten Versionen; die weitere Entwicklung findet auf einem anderen Zweig statt. Idealerweise gibt es für jede Eigenschaft einen eigenen Zweig, der einen aussagekräftige Namen besitzt. Haben Sie die Änderungen in dem jeweiligen Branch abgeschlossen, übernehmen Sie diese in den Hauptzweig, testen sie – und fertig ist die neue Version.
Git agiert als dezentrales Versionsverwaltungssystem. Sie dürfen die Zweige ohne Verbindung zum entfernten Repository anlegen und transferieren sie später bei Bedarf dorthin zurück. Zudem behandelt Git alle Zweige gleich, die bekannten Kommandos funktionieren in der gewohnten und schnellen Weise.
Der Befehl git branch Zweig legt einen neuen Branch an, dessen Ausgangspunkt der aktuell ausgecheckte Stand bildet. Mit dem Kommando git checkout Zweig wechseln Sie in den jeweiligen Zweig. Im Arbeitsverzeichnis liegt anschließend der Stand des letzten Commits des angegebenen Zweigs. Existiert der Branch noch nicht, fasst git checkout -b Zweig beide Aktionen zusammen.
Abbildung 2 zeigt ein Projekt mit den Zweigen master und zweig. Der Branch master enthält die fertigen Versionen MA und MB, auf dem Zeig zweig findet die Entwicklung statt. Dort gibt es bereits die Zwischenversionen ZA, ZB und ZC.
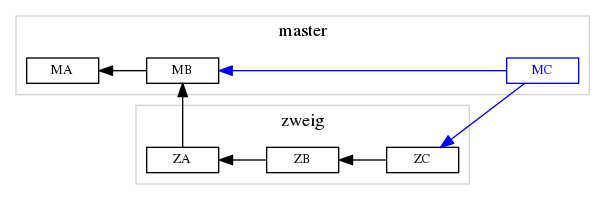
Abbildung 2: Mit Zweigen untergliedern Sie die Arbeit an einem Projekt in abgeschlossene Einheiten, die Sie bei Bedarf wieder in den Hauptzweig aufnehmen.
Der Wechsel zwischen den Zweigen erfolgt mit git checkout master und git checkout zweig. Das funktioniert nur, wenn im Arbeitsverzeichnis keine Änderungen gegenüber dem Git-Archiv vorliegen. Ein solches Arbeitsverzeichnis heißt sauber. Gibt es Änderungen, buchen Sie diese mit git add -u gefolgt von git commit -m ... ein oder setzen die Änderungen mittels git reset --hard zurück.
TIPP
Prüfen Sie über die Ausgabe von git status oder das Klonen in ein Testverzeichnis regelmäßig, ob alle Dateien auch im Git-Index stehen.
Mit dem Kommando git stash bietet Git eine weitere Möglichkeit, die geänderten Daten zu sichern. Das erfolgt in einem speziellen Bereich des lokalen Repositorys. Die Änderungen dürfen Sie jederzeit ins Arbeitsverzeichnis einspielen, unabhängig von der ausgecheckten Version. Mehr Details liefern die zugehörige Handbuchseite (git stash --help) sowie das Online-Handbuch “Pro Git” [2].
Git legt die Zweige im lokalen Repository an. Um sie ins Remote-Repository einzubinden, müssen Sie eine entsprechende Verknüpfung anlegen. Das Push-Kommando aus der ersten Zeile von Listing 1 erstellt diese und startet das Übertragen der Daten. Im Anschluss stehen beide Zweige, master und zweig, unter Verfolgung. Arbeiten mehrere Personen an einem Zweig oder möchten Sie eine Sicherheitskopie des jeweiligen Zweigs erstellen, übertragen Sie den Branch auf das Remote-Repository.
Listing 1
$ git push --set-upstream origin zweig [...] $ git remote show origin Hauptbranch: master Remote-Branches: master gefolgt meinzweig gefolgt Lokale Branches konfiguriert für 'git pull': master führt mit Remote-Branch master zusammen zweig führt mit Remote-Branch zweig zusammen Lokale Referenzen konfiguriert für 'git push': master versendet nach master (aktuell) zweig versendet nach zweig (aktuell)
Das Kommando git branch -a zeigt die lokal und entfernten vorhandenen Zweige an. Jede Person, die über die passenden Zugriffsrechte verfügt, darf diese Branches auschecken. Das Klonen bringt alle im entfernten Repository enthaltenen Zweige mit auf die Platte. Geben Sie dabei keinen Branch an, steht das Arbeitsverzeichnis auf dem letzten Stand von master. Aus dem Remote-Repo ausgebuchte Zweige besitzen immer den Status gefolgt.
Nach dem Abschluss der Arbeiten auf dem Zweig übernehmen Sie die Änderungen in einen anderen Zweig (im Beispiel in master). Ob es sich bei den Unterschieden um modifizierte, hinzugekommene oder gelöschte Dateien handelt, spielt dabei keine Rolle. Um Probleme zu vermeiden, sollte es im Arbeitsverzeichnis aber keine zusätzlichen Modifikationen geben.
Merge
Das Mergen, also Verschmelzen, führt die Änderungen aus Zweigen zusammen. In Abbildung 2 stammt der Zweig zweig vom letzten Commit des Zweigs master ab. Seither gab es in master keine Änderungen. Der blaue Pfad beschreibt den Merge-Vorgang, den Sie mit den Kommandos aus Listing 2 vornehmen.
Listing 2
$ git checkout master Gewechselt zu Zweig 'master'. $ git merge zweig Aktualisiere 6466a1f..eff29ab Fast-forward [...] $ git log --oneline --decorate --graph --all * 9dd9027 (HEAD -> zweig, origin/zweig, origin/master, origin/HEAD) Projektdatei bearbeitet [...]
Git verschiebt in diesem Fall den Pointer HEAD auf den letzten Commit von zweig. Dieser Vorgang heißt Fast-forward. Nach dem Mergen haben beide Zweige denselben Stand. Gab es zwischenzeitlich Änderungen auf master, sucht Git ausgehend vom gemeinsamen Ausgangspunkt beider Zweige (in diesem Fall MB) nach den Änderungen (Drei-Wege-Vergleich) und versucht diese abzugleichen.
Liegen die Änderungen an unterschiedlichen Stellen vor oder betreffen sie unterschiedliche Dateien, klappt alles wie beschrieben. Die sich aus dem Verschmelzen ergebende, neue Version checkt die Software im Rahmen des Vorgangs direkt ein. Sofern nicht anders angegeben, startet Git dazu den Editor, mit dem Sie dann eine entsprechende Nachricht eingeben.
Liegen die Änderungen an der gleichen Stelle, kommt es dort zu Konflikten (Listing 3). Git gibt die Namen der entsprechenden Dateien aus und kennzeichnet bei Textdateien die Konflikte innerhalb der Files unmissverständlich (Abbildung 3). Haben Sie die Probleme beseitigt, befördern Sie den resultierenden Stand mit den bekannten Kommandos git add -u und git commit -m ... in die Git-Datenbank.

Abbildung 3: Probleme beim Mergen – hier ist die Software am Ende, und es bleibt nichts anderes übrig, als von Hand die Unterschiede zu untersuchen und anschließend die gewünschte Variante zu übernehmen.
Listing 3
$ git checkout master Gewechselt zu Zweig 'master' $ git merge zweig automatische Zusammenführung von init.c KONFLIKT (Inhalt): Zusammenführungskonflikt in init.c Automatische Zusammenführung fehlgeschlagen; beheben Sie die Konflikte und tragen Sie dann das Ergebnis ein. $ git status [...] # von beiden geändert:init.c [...]
Rebase
Mit dem Rebase bietet Git eine weitere Methode, um Änderungen von einem Zweig in einen anderen zu übernehmen. Im Gegensatz zum Merge geht es beim Rebase aber um das Verschieben des Ausgangspunkts eines Zweigs (zumindest beschränkt sich dieser Artikel darauf). Das zugehörige Kommando lautet git rebase Zweig.
Abbildung 4 zeigt den grundlegenden Ablauf. Der graue Block zweig stellt den Stand vor dem Rebase dar, der blaue zweig' entspricht dem Stand nach dem Rebase. Die Kommandos git checkout zweig und git rebase master bewirken das Verschieben des Ausgangspunkts von zweig von MB auf MD.
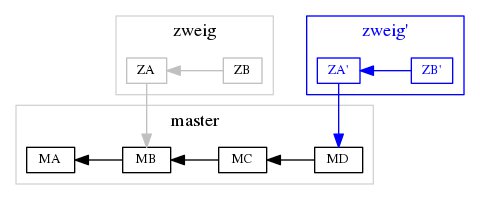
Abbildung 4: Rebase verschiebt den Ausgangspunkt eines Zweigs.
Beide Kommandos fassen Sie bei Bedarf zu git rebase master zweig zusammen. Beim Rebase erhalten die Versionen ZA und ZB die Änderungen von MB und MC. Es entstehen die neuen Versionen ZA' und ZB'. Ein gelegentliches Rebase verhindert, dass beteiligte Zweige zu stark auseinanderdriften.
Der resultierende Aufbau entspricht der in Abbildung 2 gezeigten Struktur. Da der Head von zweig auf dem letzten Commit von master basiert, können Sie eventuelle Funktionstests auf zweig vornehmen. Anschließend führen Sie die Zweige per Fast-Forward-Merge in Richtung master zusammen. Damit gibt es keine ungetestete Version master – zumindest, solange Sie dort zwischenzeitlich nichts geändert haben.
TIPP
Der manuelle Vergleich der Zweige vor dem Merge oder Rebase hilft beim Identifizieren möglicher Probleme. Dazu setzen Sie die Kommandos git diff Zweig1 Zweig2 oder git difftool Hash1 Hash2 ein.
Treten Konflikte auf, zeigt Git die entsprechenden Dateien an und unterbricht den Vorgang. Nachdem Sie die Konflikte beseitigt haben, bringt ein git add -u die Anpassungen in den Index. Ein folgendes git rebase --continue nimmt den Vorgang wieder auf.
Die manuell gemachten Änderungen werden so ein Bestandteil des Zweigs, den Sie verschieben. Der Zweig master bleibt in diesem Fall unverändert. Das Kommando git rebase --abort bricht den Vorgang ab und stellt den vorherigen Stand wieder her.
Das Rebasing verändert den Ausgangspunkt des Zweigs. In der History sieht das anschließend so aus, als ob die Entwicklung zeitlich linear in einem Zweig stattgefunden hätte. Wenden Sie diese Technik nicht auf Commits an, die Sie bereits auf ein öffentliches (also ein für andere Personen zugängliches) Repository hochgeladen haben.
Aus funktioneller Sicht hebt ein Rebase bestehende Commits auf und erstellt statt dessen neue. Das führt bei jedem, der diesen Zweig vor Ihrem Rebase heruntergeladen hat und als Basis für seine Arbeit verwendet, zwangsläufig zu einem zusätzlichen, eigentlich unnötigen Merge. Laden die anderen im Gegenzug ihre Änderungen ins öffentliche Repository hoch, führt das bei Ihnen zu einem Merging, da sich der neue Zweig augenscheinlich geändert hat. Diese Änderungen hatten Sie eigentlich mit dem Rebase bereits eingepflegt.
Solche Spielchen gestalten den Ablauf des Projekts unübersichtlich und kompliziert. Der Abschnitt “Die Gefahren des Rebasings” im “ProGit”-Buch [3] beschreibt das ausführlich anhand eines anschaulichen Beispiels.
Volle Kraft zurück
Was aber, wenn Sie an einer vor Monaten fertiggestellten Version einen Rechtschreibfehler korrigieren wollen? Angenommen, im Projekt aus Abbildung 1 möchten Sie die dritte Version (Hash 4fb2) ändern. Die in den folgenden Versionen hinzugekommenen Änderungen und Erweiterungen dürfen nicht Bestandteil der resultierenden Version sein. Kein Problem: Mithilfe des Hashes und eines eventuell vergebenen Tags können Sie die Version eindeutig identifizieren und auschecken (Listing 4).
Listing 4
$ git checkout 4fb2717
Hinweis: Checke '4fb2717' aus.
Die Version befindet sich nun im Zustand eines sogenannten losgelösten Head. Sie können sich umschauen, experimentelle Änderungen vornehmen und diese wieder committen. Außerdem haben Sie die Möglichkeit, alle Commits, die Sie in diesem Zustand machen, ohne Auswirkungen auf irgendeinen Branch zu verwerfen, indem Sie einen weiteren Checkout vornehmen.
Wenn Sie einen neuen Branch erstellen möchten, um Ihre Commits zu behalten, tun Sie das (jetzt oder später) durch einen weiteren Checkout mit der Option -b. Im Beispiel aus Listing 5 besagt die letzte Zeile, dass sich das Arbeitsverzeichnis wie gewünscht auf dem Stand der Version 4fb2 befindet.
Listing 5
$ git checkout -b meinzweig
HEAD ist jetzt bei 4fb2717... Datei hello.txt hinzugefügt.
Was aber soll diese Menge an Text, und was bedeutet das mit dem losgelösten Head? Letztendlich weist all das darauf hin, dass die ausgecheckte Version bereits archiviert und damit unveränderlich ist. Das Verhindern von Änderungen an eingecheckten Versionen zählt zu den Hauptaufgaben eines VCS. Git empfiehlt in einem solchen Fall einen neuen Zweig zu erstellen und darauf weiterzuarbeiten. Der Umgang mit einem losgelösten Zweig ist nicht empfehlenswert (siehe Kasten “Völlig losgelöst”).
Völlig losgelöst
Der Zustand eines losgelösten Head, im Git-Jargon “detached state”, bedeutet, dass der Pointer HEAD auf keinen richtigen Zweig verweist. Er zeigt vielmehr auf eine bereits gesicherte und damit unveränderliche Version. Git selbst stört diese Tatsache erst einmal nicht, es erlaubt auch in diesem Status alle Aktionen.
Abbildung 5 zeigt ein Projekt mit einem losgelösten Zweig (basierend auf 4fb2717), auf dem ein Commit erfolgt ist (cec704b). Solange Sie sich in diesem Bereich befinden, bleibt der Commit sichtbar. Wechseln Sie auf einen anderen Zweig, erreichen Sie den Commit nur noch über die Angabe des Hashes. Es bereitet außerdem Schwierigkeiten, einen solchen Commit ins Remote-Repository zu überführen.
Haben Sie trotz des Hinweises auf dem losgelösten Head Änderungen eingecheckt, wandeln Sie diesen mit git branch Name Hash in einen normalen Zweig um. Das funktioniert aber nur, solange Sie nicht den Zweig wechseln. Den Hash erhalten Sie via git log.
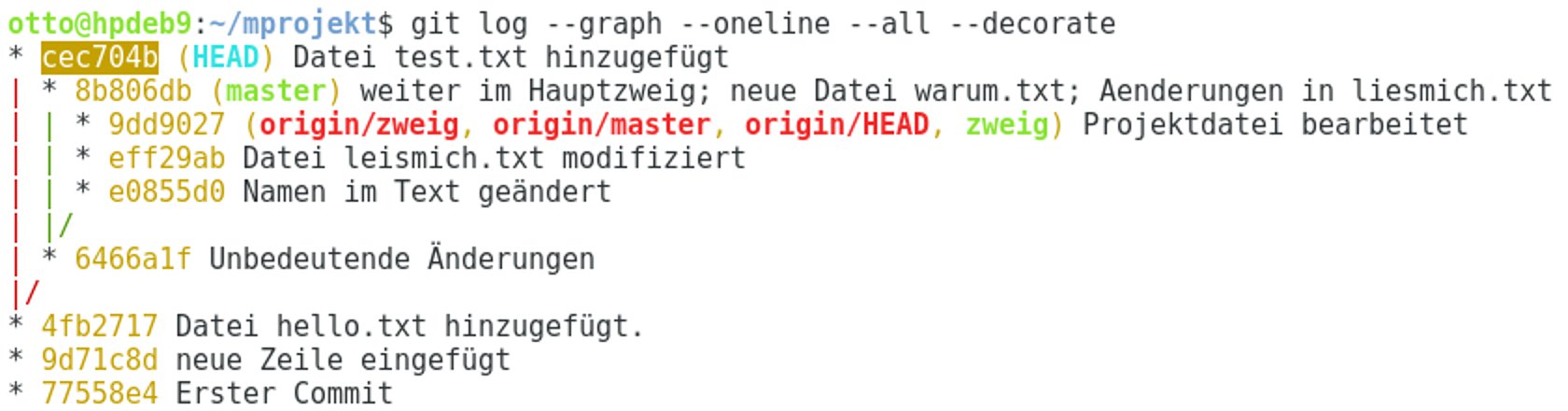
Abbildung 5: Ohne Bindung – ein losgelöster Zweig verweist auf eine bereits gespeicherte Version.
Benötigen Sie einen Zweig nicht mehr, löschen Sie ihn mit git branch -d Branch wieder – zumindest, wenn Sie ihn mit einem anderen Zweig zusammengeführt haben. Möchten Sie ohne vorheriges Zusammenführen löschen, verwenden Sie stattdessen -D mit einem großen D.
Git bietet einen äußerst einfachen Umgang mit Zweigen. Es ist durchaus üblich, mehrere Zweige pro Tag anzulegen. Einige verfügbare Git-Server-Erweiterungen, wie etwa Gitolite, erlauben es außerdem, den Zugriff auf einzelne Zweige zu steuern.
Verzeichnisse umbauen
Vor jedem Ändern an der Struktur von Verzeichnissen gilt: Sichern Sie den aktuellen Stand. Die Unterkommandos rm (“remove”) und mv (“move”) dienen dazu, solche Veränderungen zu bewerkstelligen. Beide arbeiten auf Dateien oder Ordnern.
Bei umfangreicheren Änderungen kann es von Vorteil sein, zunächst die Änderungen vorzunehmen und diese anschließend anzumelden. Testen Sie den neuen Aufbau der Verzeichnisse, aktualisieren Sie den Git-Index, verschaffen Sie sich mit git status einen Überblick, und checken Sie den neuen Stand anschließend ein. Abbildung 6 zeigt die Ausgabe von git status, nachdem einige Projektdateien in Unterverzeichnisse verschoben wurden.
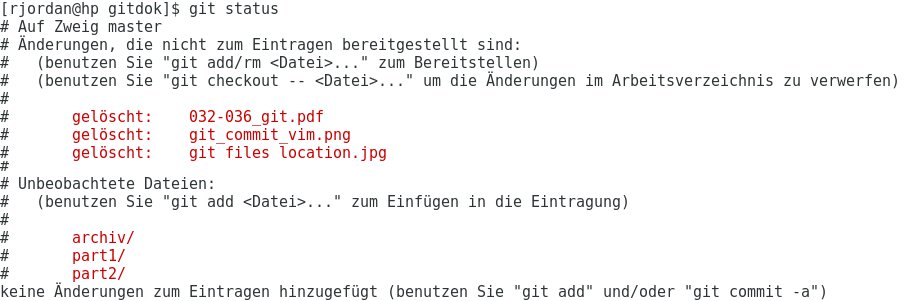
Abbildung 6: Sind die Umbauten an den Verzeichnissen abgeschlossen, schauen Sie sich am besten kurz den Status des Arbeitsverzeichnisses an.
Die Übernahme der Änderungen erfolgt mit den Befehlen aus Listing 6. Das erste Kommando aktualisiert den Git-Index. Im Beispiel wurden drei Dateien im Arbeitsverzeichnis bereits gelöscht, Git entfernt sie damit aus dem Git-Index. Der Befehl in der zweiten Zeile nimmt die neu erstellten Verzeichnisse inklusive der darin enthaltenen Dateien in den Index auf. Das letzte Kommando schließlich bucht das Projekt ein.
Listing 6
$ git add -u $ git add part1 part2 archiv $ git commit -m "Struktur geändert"
Sollten Sie sich während des Umstellens verlaufen, bringen Sie mit git reset --hard das Arbeitsverzeichnis auf den letzten eingecheckten Stand. Ein folgendes git clean -df löscht die nicht im Git-Index befindlichen Dateien und Verzeichnisse aus dem Arbeitsverzeichnis.
Anmerkungen
Der Artikel bezieht sich ausschließlich auf die Verwendung der Dateischnittstelle für das Remote-Repository. Das erspart zwar das Aufsetzen eines Git-Servers, ist aber in der Praxis eine eher ungebräuchliche Variante. Bei größeren Projekten zählt ein Server aus Gründen der Sicherheit und zum einfacheren Steuern des Zugriffs praktisch zum Pflichtprogramm. Informationen dazu, wie etwa zum Umgang mit und dem Innenleben von Git finden Sie im Online-Buch “ProGit” [2].
Fazit
Geht es um das Verwalten von Dateien, erweist sich Git als idealer Begleiter, selbst bei kleinsten Projekten. Die wenigen notwendigen Kommandos, der einfache Umgang mit Zweigen, die Unterstützung bei deren Zusammenführen und vor allem die hohe Performance überzeugen auf ganzer Linie. Obwohl Git seinen Schwerpunkt auf die Verwaltung von Textdateien legt, eignet es sich ebenso für Binärdateien. Gerade im Umgang mit Zweigen und Remote-Repositories hat das VCS noch jede Menge mehr zu bieten.
Der Autor
Roman Jordan arbeitet seit über 20 Jahren mit Linux. Seine Schwerpunkte liegen im Kernel-Bereich und bei der Programmierung kleiner Embedded-Plattformen.
Glossar
-
VCS
-
Version Control System, deutsch: Versionsverwaltungssystem. System zum Erfassen und Verwalten von Änderungen an Dateien. Bei der Software-Entwicklung kommen VCS vor allem zum Verwalten des Quellcodes zum Einsatz.
Infos
-
Git-Workshop (Teil 1): Roman Jordan, “Innerer Zusammenhalt”, LU 08/2018, S. 84, https://www.linux-community.de/41297
-
Online-Buch “ProGit” (Version 2.0, deutsch): https://git-scm.com/book/de/v2
-
Rebase: https://git-scm.com/book/de/v2/Git-Branching-Rebasing




