
Was man im Web-Browser sieht, kann man getrost auf Papier drucken, so die geläufige Ansicht. Sobald Web-Seiten jedoch nicht-lateinische, zum Beispiel kyrillische Buchstaben enthalten, muss die Anwenderin für diese scheinbare Selbstverständlichkeit kräftig arbeiten.
The Answer Girl
Dass der Computeralltag auch unter Linux des Öfteren Überraschungen bereithält, ist eher eine Binsenweisheit: Immer wieder funktionieren Dinge nicht odernicht so, wie eigentlich angenommen. Das Answer-Girl im LinuxUser zeigt, wie man mit solchen Problemchen elegant fertig wird.
Hexen können auch Web-Browser nicht: Sollen sie Seiten mit nicht-lateinischen Buchstaben anzeigen, geht das nur, wenn ihnen entsprechende Schriften zur Verfügung stehen. Doch mittlerweile sehen viele Linux-Distributeure ein, dass ein aus lauter leeren Quadraten bestehender Text im Browser wenig befriedigt. Auch die Hersteller von GUI-Bibliotheken wie Qt oder GTK haben ihre Hausaufgaben zumindest soweit gemacht, dass sich gängige nicht-lateinische Schriftzeichen darstellen lassen.
Damit sieht etwa ein russischer Text in SuSEs Konqueror bereits per Default ganz manierlich aus, und Debian steht dem nach der Installation des Pakets xfonts-cyrillic nicht nach. Wenn Konqueror die Schriften fehlen, besteht immer noch Hoffnung, mit Opera oder Mozilla ein vielleicht nicht schönes, aber doch lesbares Ergebnis zu bekommen.
Ein fast leeres Blatt
Doch wer jetzt davon ausgeht, dass, was sich anzeigen auch ausdrucken lässt, erlebt schnell sein blaues Wunder: Auf dem Papier erscheint anstatt kyrillischer Buchstaben einfach nichts.
Da hierzulande vertriebene Drucker normalerweise selbst keine russischen oder sonstwie fremden Fonts installiert haben, lässt sich nachvollziehen, warum sie eine einfache Textdatei aus dem Texteditor [1] mit lpr dateiname lediglich in “komischen” Zeichen zu Papier bringen: Zunächst fehlt ihnen die Information, in welcher Kodierung (zum Beispiel KOI8) die Datei vorliegt. Und selbst wenn die bekannt wäre, wüsste der Drucker nicht, woher er passende Schriften nehmen sollte – herzaubern kann er sie nämlich nicht.
Dass aber beim Drucken aus einem Web-Browser nicht einmal das auf Papier erscheint, was der korrekt auf dem Bildschirm anzeigt (und von dem er also die richtige Kodierung kennt), verwundert auf den ersten Blick: Schließlich führt hier der Weg über eine (temporäre) PostScript-Datei. PostScript aber kann Schriften einbetten und die entsprechenden Informationen also zum Drucker transportieren.
Druckt man die fragliche Seite wie in Abbildung 1 in eine PostScript-Datei, enthält die jede Menge .notdef-Einträge für in der Schrift nicht definierte Zeichen und bei den Qt-basierten Web-Browsern Konqueror und Opera unter Umständen auch den Kommentar % No embeddable font for … found.
Des Rätsels Lösung: Während X für die Anzeige auf dem Bildschirm verschiedene Schriftarten – Bitmap-, PostScript- und auch TrueType-Fonts – benutzen kann, braucht man zum Einbetten in PostScript vereinfacht gesagt PostScript-Fonts. Hier aber endet die Unterstützung der meisten Distributoren: kyrillische PostScript-Fonts – Fehlanzeige.
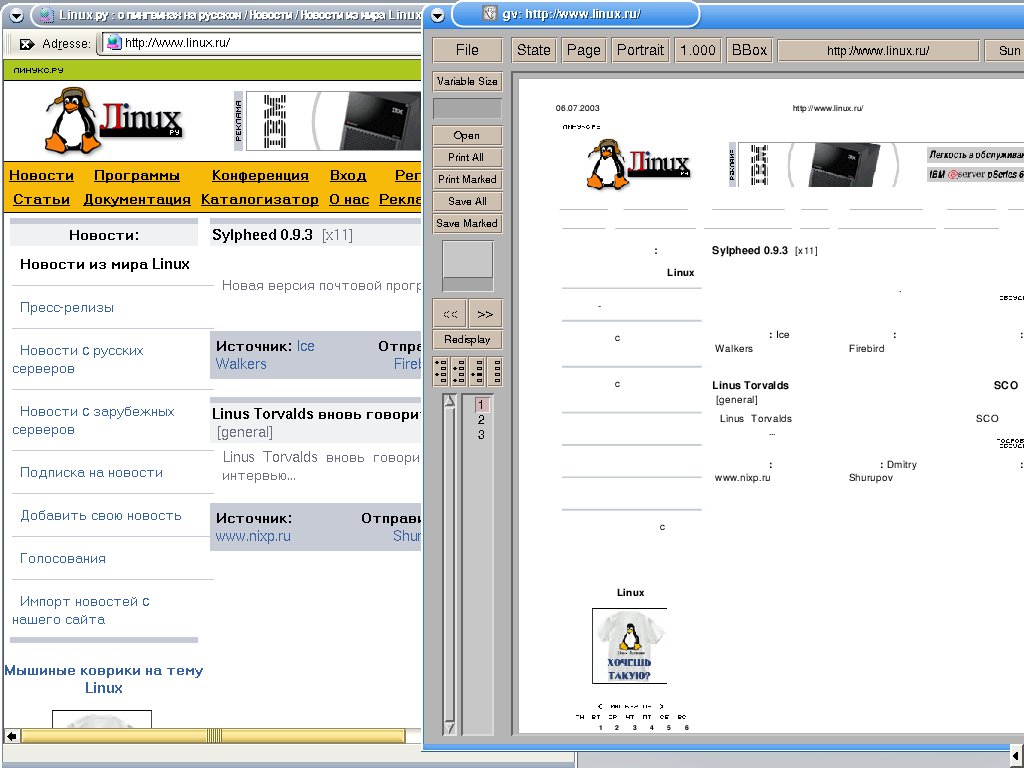
Abbildung 1: Das vom Druckbefehl generierte PostScript-File unterschlägt alle im Konqueror (links) dargestellten russischen Zeichen
Die Suche nach solchen Schriften führt die Nutzerin ins WWW, und bei den Stichworten “PostScript russian font X” findet Google zum Beispiel die nützliche englischsprachige Seite http://www.ibiblio.org/sergei/Software/x.html. Sie verrät, dass es ein Paket namens XType1.tar.gz mit kyrillischen Type-1-PostScript-Schriften gibt. Von [2] heruntergeladen und mit tar -xzvf ausgepackt, muss das X-Window-System sie jedoch erst einmal finden.
Zu diesem Zweck benötigt es eine ASCII-Datei namens fonts.scale, die den im Verzeichnis enthaltenen Dateien mit skalierbaren Fonts einen Font-Namen in X-Notation zuordnet:
Advertisement.pfb -unknown-advertisement-medium-r-normal--0-0-0-0-p-0-adobe-fontspecific
Die können Wissende von Hand schreiben, doch spart das ebenfalls unter [2] zu findende Perl-Skript type1inst eine Menge Arbeit. Vorausgesetzt, der Befehl pfbtops aus dem Paket groff ist installiert, wechselt man ins XType1-Verzeichnis und ruft das Skript zum Beispiel mit dem Befehl
perl pfad/zu/type1inst
auf. Gewissenhafte Menschen korrigieren in der so erzeugten fonts.scale-Datei den Hinweis auf die Kodierung, indem sie den String adobe-fontspecific am Zeilenende gegen koi8-r austauschen. Auch den Herstellerhinweis unknown kann man in paragraph ändern.
Doch auch ein noch so schön geschriebenes fonts.scale-File muss X erst einmal wahrnehmen. fonts.@L: *-Dateien fallen dem X-Server nämlich nur auf, wenn sie in Verzeichnissen liegen, die in der Section “Files” der XF86Config-Datei hinter dem Stichwort FontPath verzeichnet sind. Zum Glück lässt sich der Schriften-Suchpfad der aktuellen X-Session mit dem Kommando xset erweitern:
xset +fp /home/pjung/XType1/
xset q (“query”) bestätigt die Aufnahme des Verzeichnisses in den Font Path:
Font Path: /home/pjung/XType1,/usr/X11R6/lib/X11/fonts/misc,/usr/X11R6/lib/X11/fonts/Type1, […]
Ruft man jetzt das Tool xfontsel auf, das alle von X gefundenen Schriften anzeigt, lässt die Belohnung nicht lange auf sich warten: Hält man die Maus über dem fmly-Knopf gedrückt, erscheinen die neuen Font-Familien advertisement, college, handbook, lazurski, magazine, textbook und courierkoic im Menü zu Begutachtung. Liegen die Schriften in verschiedenen Schriftschnitten vor, bietet das slant-Menü zum Beispiel die Möglichkeit, kursiv (i – “italic) oder gerade (r – “roman”) auszuwählen. Unter wght (“weight” – Gewicht”) stellt man die Schriftprobe auf fett (b – “bold”) um. Die vierte Zeile der Probe beweist es – diese Schriften kennen nicht nur 7-Bit-ASCII-, sondern auch kyrillische Zeichen (Abbildung 2).
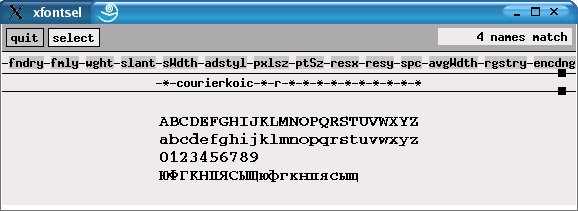
Abbildung 2: xfontsel zeigt den Roman-Schnitt der neuen PostScript-Schrift courierkoic
Überredungskünste
Leider ändert das erst einmal gar nichts an der Tatsache, dass die von einer nun gestarteten Konqueror- oder Opera-Instanz erzeugten PostScript-Dateien bei den kyrillischen Buchstaben weiterhin vor .notdefs strotzen. Die Detektivarbeit besteht jetzt darin, die verwendeten, lückenhaften Schriften aufzuspüren und bei Opera unter File / Preferences / Fonts and colors, beim Konqueror im Einstellungsdialog Einstellungen / Konqueror einrichten … gegen einen der neuinstallierten Fonts auszutauschen. (Je nach KDE-Version und Distribution findet sich der Schriftendialog des KDE-Browsers zum Beispiel unter Konqueror-Browser / Erscheinungsbild oder Schriften.)
Netterweise enthalten von Qt generierte PostScript-Dateien im Vorspann einen Eintrag %%DocumentFonts:, der die verwendeten Fonts auflistet. Findet man die eine oder andere dieser Schriften dann noch in einem Kommentar wie
% No embeddable font for Helvetica found
wieder, steht der Übeltäter fest: In diesem Fall gilt es, alle Helvetica-Einträge im Schriftendialog gegen eine der neuen Fonts auszutauschen.
Schwieriger wird es, wenn Qt 3 aus vorhandenen Schriften eigene Composite-Fonts zusammenzimmern konnte. Dann sucht man nach .notdefs. Das Beispiel des unter SuSE 8.0 mit Konqueror generierten Ausschnitts aus Listing 1 zeigt: Hier ist die Schrift NimbusSansL unvollständig. Im Erscheinungsbild-Tab des Konquerors findet sie sich bei dieser Distribution als Standardschrift unter der Bezeichnung Nimbus Sans l [Xft] wieder.
Listing 1
Ausschnitt aus einem von Konqueror generierten PostScript-File
[…] /NimbusSanL-Regu-ENC-00 [ /.notdef/F/A/Q/T/o/p/comma/space/one/five/parenleft/parenright/zero/period/U […] /Z/slash/three/seven/eight/V/G/q/P/B/semicolon/quotedbl/copyright/backslash /quotesingle/.notdef/.notdef/.notdef/.notdef/.notdef/.notdef/.notdef/.notdef /.notdef/.notdef/.notdef/.notdef/.notdef/.notdef/.notdef/.notdef/.notdef […]
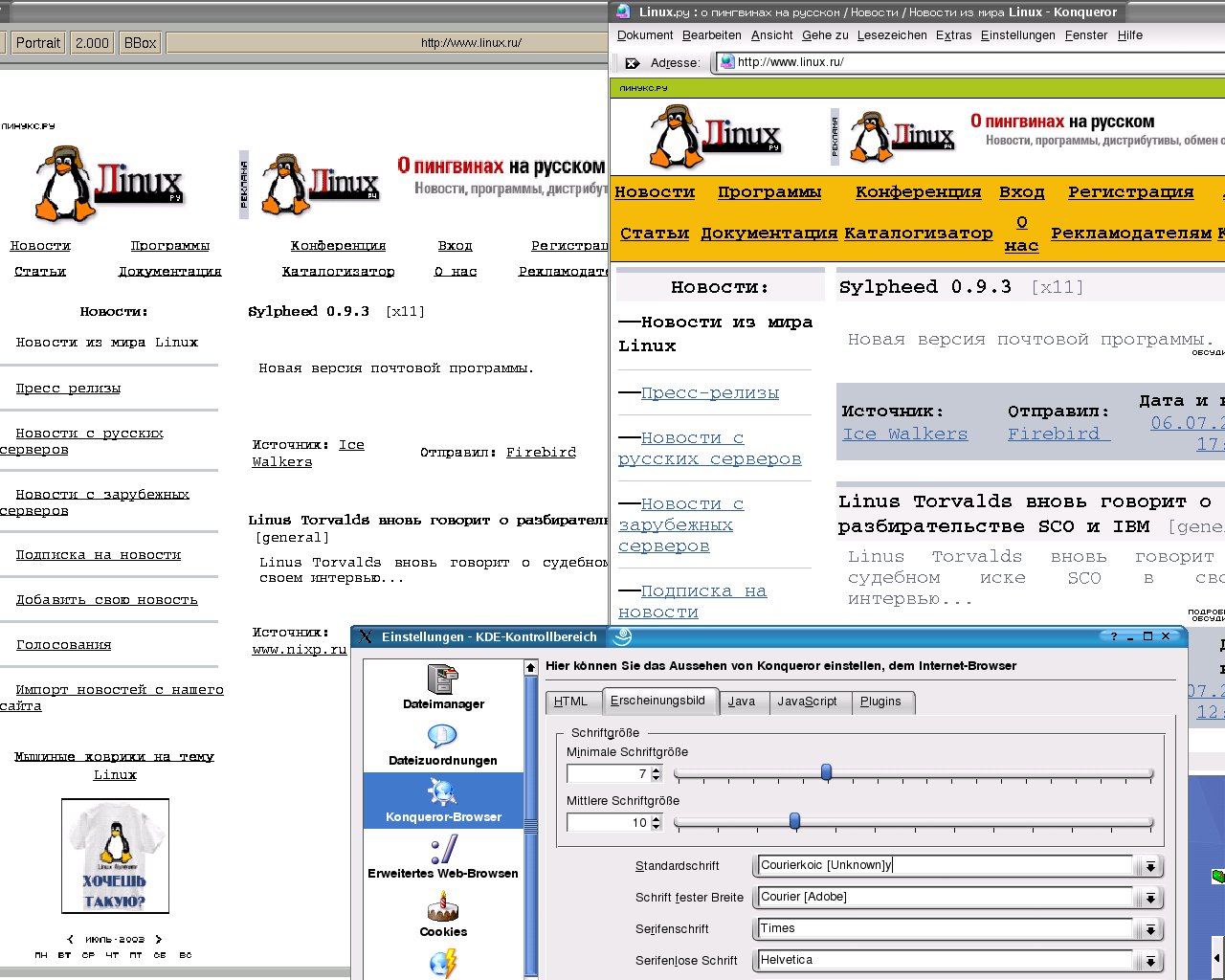
Abbildung 3: Mit Courierkoic als Standardschrift ändert sich nicht nur das Aussehen der Web-Seite – sie lässt sich sogar ausdrucken, wie der PostScript-Viewer links beweist
Tauscht man die wie in Abbildung 3 gegen die Schreibmaschinenschrift Courierkoic aus und drückt auf Anwenden, erhält man beim Ausdruck wunderbar kyrillischen Text. Doch wehe dem, der stattdessen eine der anderen neuen, in @L: *.pfb-Dateien steckenden Schriften wählt!
Fehler in Qt
Dann weigert sich der PostScript-Betrachter gv plötzlich mit einem Unrecoverable error, von der erzeugten ps-Datei überhaupt etwas anzuzeigen. Der Schuldige hierfür steckt tief im Qt-Quellcode versteckt, genaugesagt in der Datei src/kernel/qpsprinter.cpp: Enthält eine pfb-Datei Leerzeilen oder die Zeichenkombination CR/LF als Zeilenende, geht einiges schief. Dummerweise steckt in allen pfb-Fonts aus dem XType1-Paket jeweils eine Leerzeile. Qt-Hersteller Trolltech verspricht, diesen Fehler in Version 3.2 zu beheben, doch das hilft derzeit aktuellen Installationen leider nicht weiter.
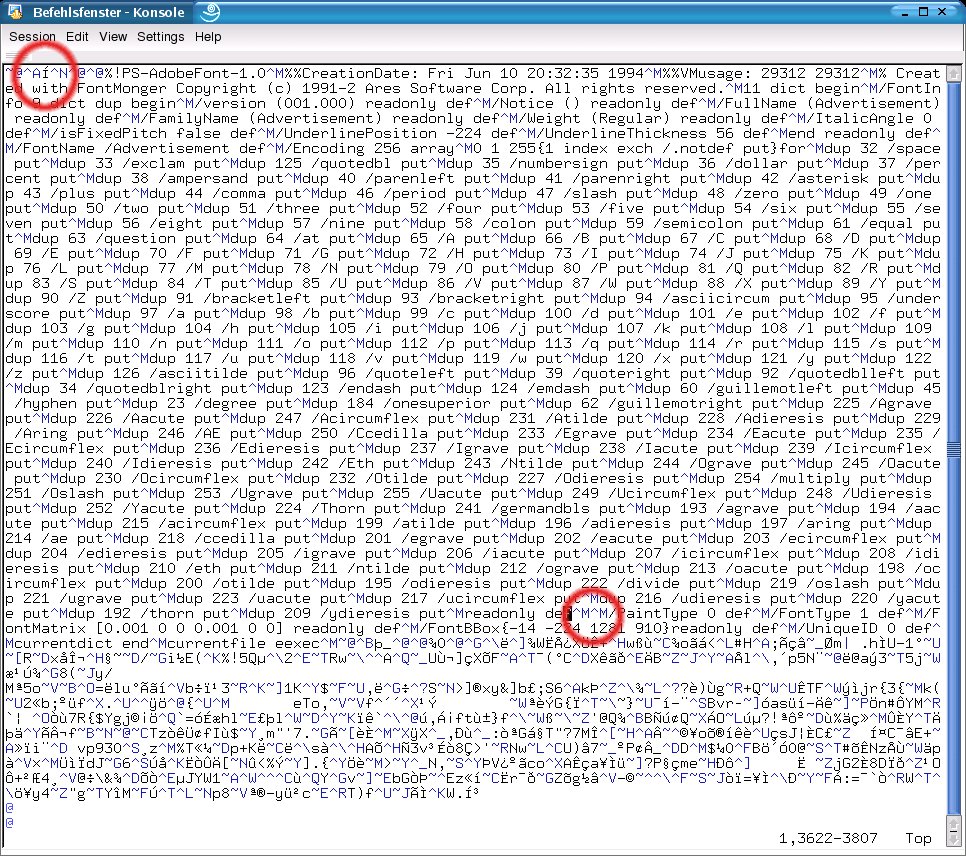
Abbildung 4: Damit Qt richtig arbeitet, muss die markierte Leerzeile aus der Datei Advertisement.pfb entfernt und die Länge des ASCII-Teils am Dateianfang angepasst werden
Zum Glück gibt es einen Workaround, ohne Qt zu patchen: die problematischen Leerzeilen mit einem minimal-invasiven Editor wie vi aus den XType1-PFB-Dateien zu entfernen. Wie Abbildung 4 anhand der XType1-Datei Advertisement.pfb zeigt, bestehen “Postscript Font Binary”-Dateien aus menschenlesbaren ASCII-Teilen (oben) und Binärbestandteilen (die komischen Zeichen im unteren Teil). Die Zeilenumbrüche stellt vi als ein Zeichen ^M ([Strg-M]) dar. Das ist die Kontrollsequenz, die hinter CR steckt.
Um nach einer Leerzeile, also zwei aufeinanderfolgenden [Strg-M]-Sequenzen, zu suchen, gibt man im vi-Kommandomodus das Suchzeichen / und anschließend [Strg-V][Strg-M][Strg-V][Strg-M][Enter] ein. Die im ASCII-Teil gefundene ^M^M-Sequenz (nicht jedoch eventuelle weitere im Binärteil) reduziert der vi-Befehl x (Zeichen unter dem Cursor löschen) auf ein Zeilenumbruchszeichen. Doch ehe :wq speichernd den Editor verlässt, muss man noch die Länge des so um ein Zeichen verkürzten ASCII-Teils anpassen. Die steht am Dateianfang zwischen der Kontrollsequenz ^A und einer weiteren.
Wie um alles in der Welt kann eine Länge wie in Abbildung 4 den Wert Í haben? Das spielt zum Glück keine so große Rolle: Man muss diese “Anzahl” lediglich um eins erniedrigen, und da Í ein Zeichen aus dem ISO-8859- oder Latin-1-Zeichensatz ist, reicht es, in der Latin-1-Code-Tabelle den Vorgänger-Code von Í nachzuschlagen. man latin1 listet die Code-Tabelle auf; die ersten drei Spalten geben den Code des Zeichens aus Spalte vier im Oktal-, Dezimal- und Hexadezimal-Zahlensystem an; am Ende folgt eine Erklärung:
314 204 CC Ì LATIN CAPITAL LETTER I WITH GRAVE 315 205 CD Í LATIN CAPITAL LETTER I WITH ACUTE
Í in Abbildung 4 muss sich also lediglich per Copy&Paste in Ì verwandeln.
Bei anderen Fonts ist die Suche nach dem neuen Längen-Code einfacher: Steht an der entscheidenen Stelle ein großer Buchstabe aus dem lateinischen Alphabet, nimmt man seinen (ebenfalls großgeschriebenen) Vorgänger. So wird aus dem von vi als ~@^AL dargestellten Dateianfang in College-Bold.pfb die Sequenz ~@^AK oder aus ~@^AT in College-Italic.pfb~@^AS.
Um zu testen, dass dabei nichts schiefging, entfernt man das Verzeichnis mit den nunmehr geänderten XType1-Fonts mit
xset -fp /home/pjung/XType1/
aus dem Font Path und fügt es mit xset +fp wie oben gezeigt wieder ein. Somit löscht X seinen Font-Cache und liest die Font-Dateien neu ein. Ruft man jetzt erneut xfontsel auf, lassen sich alle geänderten Fonts prüfend durchgehen.
Stimmt hier alles, ist der Weg zu kyrillischen Ausdrucken aus Konqueror und Opera frei. Einen Haken hat die Font-Auswahl dennoch: Da die kyrillischen Schriften zwar 7-Bit-ASCII-Zeichen, aber keine deutschen Umlaute enthalten, sehen deutschsprachige Seiten mit den neuen Default-Schriften plötzlich merkwürdig aus. Hier hat der Konqueror-Schriften-Dialog den großen Vorteil, dass man mit einem Mausklick wieder zu den Voreinstellungen kommt. Bei Opera mit seinem Font-Einstellungskonzept “eine Schrift pro HTML-Element” wäre ein solcher Knopf noch dringender, zumal man bei aufwändigen Seiten durchaus eine Menge ändern darf. Der Weg zum problemlosen, alphabetunabhängigen Ausdruck ist also noch weit.
Glossar
-
KOI8
-
Eine Zuordnungs- oder Code-Tabelle, die außer 7-Bit-ASCII-Zeichen (die im wesentlichen die Ziffern 0–9, die Buchstaben des amerikanischen Alphabets und einige Kontrollsequenzen wie CR und LF umfassen) auch kyrillischen Zeichen eine Kodierung zuordnet. Sie ist zwar eine sehr verbreitete, aber nicht die einzige kyrillische Codepage. KOI8-R umfasst das russische, KOI8-U das ukrainische Alphabet.
-
CR/LF
-
Die nach den gleichnamigen Aktionen bei der Schreibmaschine benannten ASCII-Zeichen Wagenrücklauf (“Carriage Return”) und und Zeilenvorschub (“Line Feed”) werden unter DOS und Abkömmlingen gleichzeitig durch den Druck auf die Enter-Taste am Ende einer Textzeile erzeugt. Unter Unix dient LF alleine als harter Zeilenumbruch, bei MacOS CR.
Infos
[1] Patricia Jung: “Sprechen Sie Russisch?”, LinuxUser 04/2003, S. 66 ff.
[2] http://www.ibiblio.org/pub/academic/russian-studies/Software/PS/





