

LLMs lokal ausführen und KI im Terminal nutzen: Das versprechen Ollama und ShellGPT.
Was Ende 2022 mit ChatGPT schwindelerregend schnell in den Fokus der Öffentlichkeit trat, hat sich inzwischen zu einer Technologie entwickelt, die auf fast alle Lebensbereiche Einfluss nimmt. Wenig überraschend hat künstliche Intelligenz (KI) in den letzten Jahren auch im Terminal unter Linux erhebliche Fortschritte gemacht. Dabei bestehen mehrere Möglichkeiten, KI-Funktionen mit lokalen Large Language Models (LLMs, siehe Kasten “Was hinter einem LLM steckt”) direkt in der Kommandozeile einzusetzen. Zahlreiche solcher LLMs lassen sich nicht nur kostenfrei nutzen. Sie versprechen zusätzliche Sicherheit und verstärken den Schutz der Privatsphäre, da keine Daten das heimische Netz verlassen.
Wir haben getestet, was KI im März 2025 im Terminal für den Heimanwender zu leisten vermag. Im LinuxUser 09/2023 haben wir bereits einen Blick auf Shell Genie [1] geworfen. Das Tool wandelt im Terminal eingegebene Fragen mithilfe von KI in Befehle um. Die in diesem Artikel betrachteten KI-Helfer dagegen sind allgemeiner ausgerichtet. Wir installieren Ollama [2], das LLM Mistral [3] und ShellGPT [4] als Schnittstelle zum Terminal.
Was hinter einem LLM steckt
Im vorliegenden Artikel fällt häufig der Begriff LLM [12]. Er steht als Abkürzung für Large Language Model und bezeichnet ein KI-Sprachmodell, das mit riesigen Datenmengen gefüttert wurde und Techniken des maschinellen Lernens und des Natural Language Processing (NLP [13]) dazu verwendet, natürliche Sprache zu verarbeiten. Sie kommen bevorzugt bei automatischen Übersetzungen, Textzusammenfassungen, der Beantwortung von Fragen und der kreativen Textgenerierung zum Einsatz.
Generell gelten kleinere LLMs als weniger leistungsfähig, da sie mit einem geringeren Datenbestand trainiert wurden. Kleinere Modelle halluzinieren mitunter je nach Fragestellung. Konkret liefert die KI dabei frei erfundene Antworten, macht teils falsche Angaben oder die Ausgabe besteht schlicht aus Wortmüll. Dementsprechend ergibt es Sinn, für einen produktiv nutzbaren Ensatz größere Modelle zu verwenden, sofern der vorhandene Platz und die Hardwareressourcen das erlauben. Solche Modelle tragen Namenszusätze wie 7b, 13b oder höher.
Ollama
Die Grundlage unserer Tests mit KI in der Konsole bildet Ollama. Das von Meta (früher Facebook) entwickelte Open-Source-Werkzeug erlaubt, LLMs lokal auf dem eigenen Heimrechner oder Server auszuführen. Damit ist sichergestellt, dass die verarbeiteten Daten nicht in eine externe Cloud abfließen. Dementsprechend üben Sie die Kontrolle darüber aus, was damit geschieht.
Ollama gibt es für Linux, MacOS und Windows. Alternativ nutzen Sie es über Docker. Derzeit lassen sich mithilfe des Tools annähernd 100 LLMs [5] ausführen. Darüber hinaus stellt Ollama eine HTTP-API auf Localhost zum Einbinden in andere Anwendungen zur Verfügung. Mit nur einem Befehl ist das die Software flott installiert und beansprucht rund 4 GByte. Bedenken Sie bitte, dass die Installation von LLMs, die Ollama ausführt, jeweils mehrere GByte belegen können.
Grafikkarten
Sollen LLMs ihre Fähigkeiten voll entfalten, benötigen sie aufgrund der riesigen zu verarbeitenden Datenmengen eine dedizierte Grafikkarte von Nvidia oder AMD mit möglichst viel VRAM. Die Grafikkarten lassen sich mit den installierten Treibern nutzen oder mittels der Grafik-Stacks CUDA oder ROCm zu Höchstleistungen antreiben.
Ollama kann LLMs allerdings auch ohne dedizierte GPU verarbeiten. Es begnügt sich dann mit der Rechenleistung der CPU. Je nach Aufgabe müssen Sie dabei jedoch mit zum Teil wesentlich längeren Antwortzeiten rechnen. Hinweise zur Installation von CUDA oder ROCm entnehmen Sie bitte den Webseite von Nvidia [6] und AMD [7]. Ihre Distribution sollte vor der Installation auf dem aktuellen Stand sein. Bitte informieren Sie sich im Vorfeld über bestehende Probleme in Ihrer Distribution. Im Idealfall setzen Sie aus Aktualitätsgründen auf Arch Linux.
Die VRAM-Anforderungen für den produktiven Einsatz von kleinen und mittelgroßen LLMs wie dem hier getesteten Mistral (7b) oder DeepSeek-r1 (8b) liegen bei 16 GByte. Der Buchstabe b in den Angaben der LLMs steht für “billion”, also Milliarde, und beziffert die Anzahl der Parameter des Modells. Ein mit 7b gekennzeichnetes LLM verfügt dementsprechend über 7 Milliarden Parameter. Größere Modelle glänzen zwar mit höherer Leistungsfähigkeit als kleinere, lassen sich aber auf der für den Heimgebrauch gängigen Hardware nur schwer ausführen. Ein Modell mit 13b verlangt rund 30 GByte VRAM, um komplett im Grafikspeicher zu laufen.
Es gibt mehrere Wege, größere Modelle auf weniger VRAM laufen zu lassen. Beispielweise lässt sich die Genauigkeit von 16 Bit auf 8 oder 4 Bit herunterrechnen. Open-Source-Tools wie LM Studio und GPT4All gestatten Ihnen, die Arbeitslast zwischen CPU und GPU auszugleichen, wenn das LLM lokal lauft. Die Auswahl der LLMs hängt generell vom Einsatzzweck und der verwendeten Hardware ab. Eine Annäherung an das optimale LLM schaffen Sie nur durch Ausprobieren. Hierbei hilft Ollama, indem es erlaubt, zwei oder mehr Modelle parallel auszuführen.
Installieren
Genug der Theorie, lassen Sie uns zur Praxis schreiten. Wie Sie Ollama einrichten (Abbildung 1), beschreibt der Kasten “Ollama installieren”. Falls das Skript keine dedizierte Grafikkarte von Nvidia oder AMD findet, erhalten Sie eine entsprechende Meldung samt dem Hinweis, dass Ollama im CPU-Modus laufen wird (Abbildung 2).
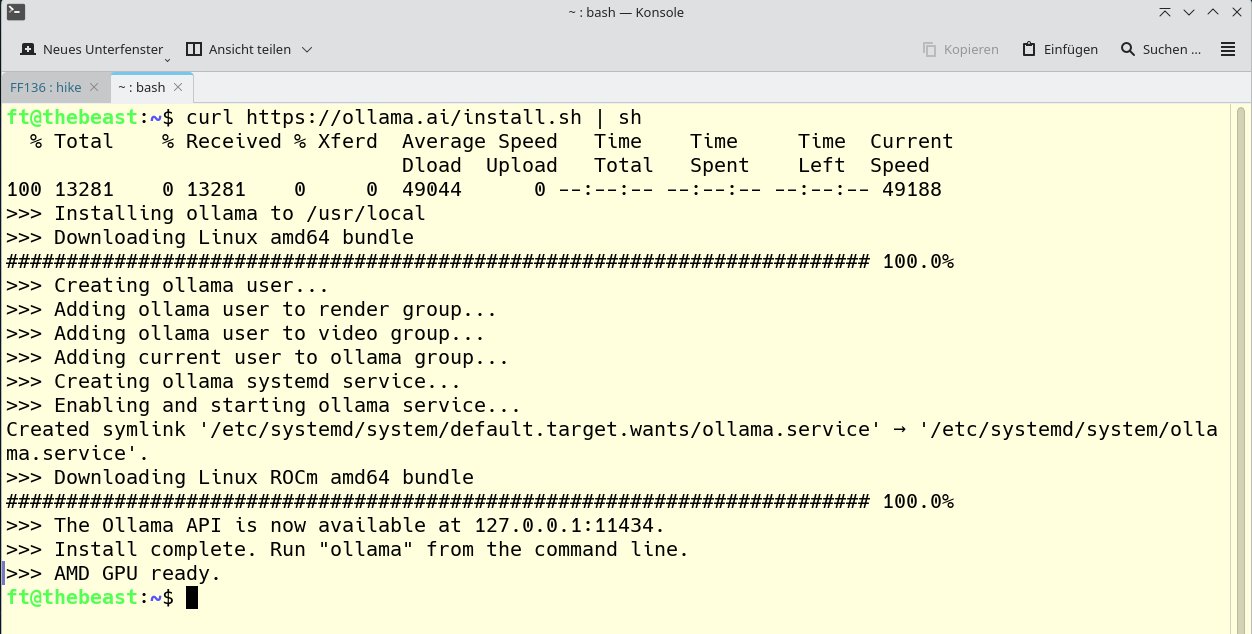
Abbildung 1: Die Installation von Ollama erledigen Sie bequem und schnell per Skript. Im Beispiel wird eine AMD-Grafikkarte erkannt und entsprechend vorbereitet.
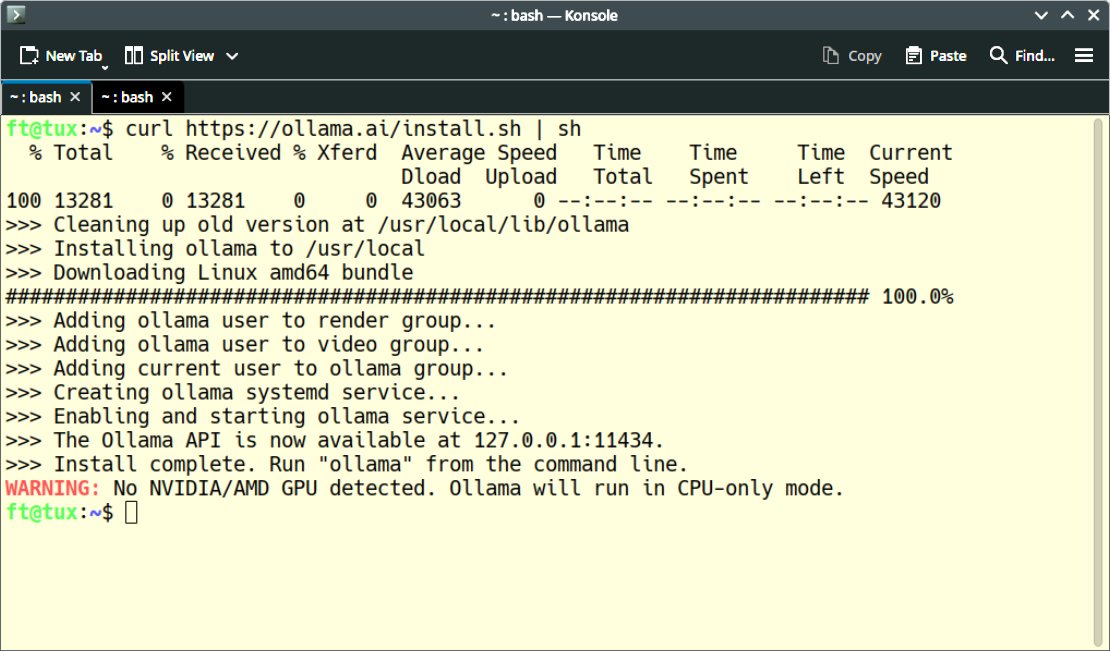
Abbildung 2: Wenn Ollama bei der Installation keine dedizierte Grafikkarte von Nvidia oder AMD findet, wird der Einsatz auf der CPU konfiguriert.
Nach der Installation sollten Sie zuerst einen Blick in das Verzeichnis /usr/local/lib/ollama/ werfen. Dort finden Sie Ordner mit ROCm und CUDA. Den oder die nicht zu Ihrer Grafikkarte passenden Ordner können Sie löschen, um damit einige GByte Platz einzusparen.
Ollama installieren
Ollama bringt ein Installationsskript mit, das Sie nach einigen vorbereitenden Schritten im Terminal ausführen. Die entsprechenden Kommandos für Debian, Fedora und Arch Linux sehen Sie in den ersten drei Zeilen von Listing 1. Anschließend stellen Sie sicher, dass die Umgebungsvariable PATH das Verzeichnis enthält, in dem Pipx Anwendungen speichert (Zeile 4).
Dann rufen Sie das Skript zur Installation von Ollama auf (Zeile 5) und prüfen danach, ob alles geklappt hat (Zeile 6). Unter Ubuntu und anderen für Snap vorbereiteten Distributionen binden Sie Ollama stattdessen mit sudo snap ollama ein.
Listing 1
Ollama installieren
$ sudo apt install pipx ### Debian $ sudo dnf install pipx ### Fedora $ sudo pacman -S python-pipx ### Arch Linux $ pipx ensurepath $ curl -fsS https://ollama.com/install.sh | sh $ ollama --version
Anschließend geht es daran, ein erstes LLM zu integrieren. Wir empfehlen für den Anfang mistral:7b-instruct, ein Modell, dem hohe Effizienz bei vergleichsweise geringen Anforderungen an die Ressourcen des Rechners nachgesagt wird. Es ist rund 4 GByte groß. Zum Installieren genügt der Befehl ollama run mistral:7b-instruct. Je nach Rechner dauert der Prozess einige Minuten und endet im Erfolgsfall mit der Ausgabe success (Abbildung 3). Um wieder zum Prompt zu gelangen, geben Sie /bye ein.
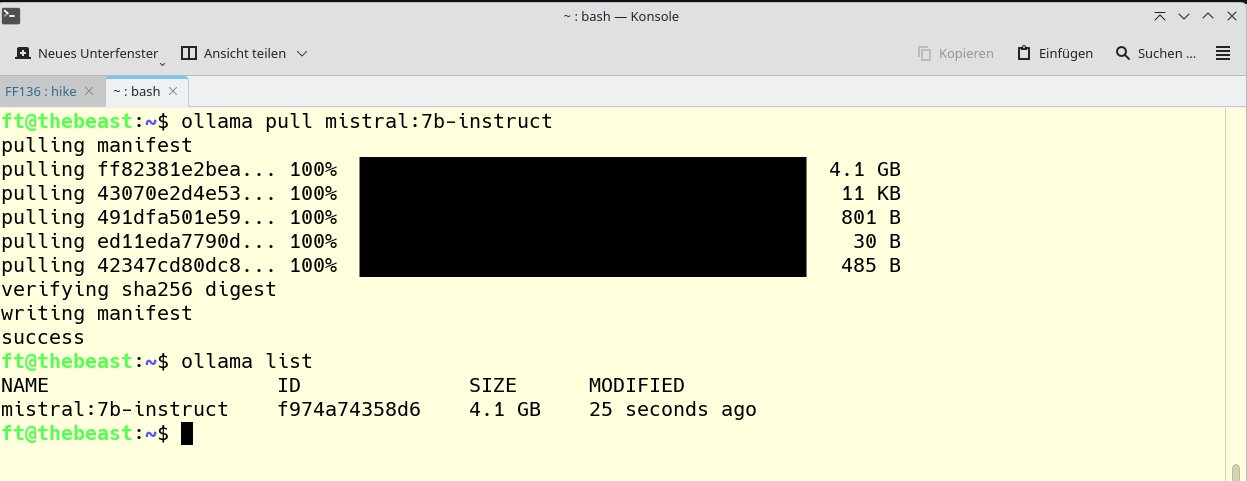
Abbildung 3: Die Bereitstellung eines ersten LLM erledigen Sie mit nur einem Kommando. Das Ergebnis kontrollieren Sie mit dem Befehl ollama list.
Das Kommando ollama list sollte mistral:7b-instruct mit ID, Größe und der letzten Modifikation zurückgeben. Zudem überprüfen Sie mithilfe von systemctl status ollama, ob Ollama als Systemd-Dienst korrekt eingebunden ist und bei jedem Neustart aktiviert wird. Wenn das Ergebnis die Begriffe enabled und active enthält, können Sie im nächsten Schritt mit der Bereitstellung von ShellGPT fortfahren.
ShellGPT
Bei ShellGPT handelt es sich um eine Shell-Erweiterung, die Entwicklern, Systemadministratoren und Terminalanwendern die Arbeit erleichtern möchte. Es ist kompatibel mit allen wichtigen Shells wie Bash, Fish, Zsh, Powershell, cmd.exe und anderen. Wenn Sie auf einem Server ohne grafische Umgebung arbeiten, ersetzt ShellGPT die GUI von ChatGPT. Sie geben Ihre Fragen einfach am Prompt des Terminals ein. Darüber hinaus kann ShellGPT Aufgaben automatisieren, Codeschnipsel erstellen, Texte zusammenfassen, Log-Dateien analysieren und vieles mehr.
Üblicherweise benötigt ShellGPT einen API-Key von OpenAI. Da wir lokale LLMs nutzen, können wir jedoch darauf verzichten und in der Konfiguration einen zufälligen String verwenden. Falls Sie neben den lokalen LLMs entfernte Modelle einsetzen möchten, müssen Sie einen API-Key auf der Webseite von OpenAI [8] erzeugen und beim ersten Start von ShellGPT eingeben. Während lokale LLMs kostenlos zur Verfügung stehen, müssen Sie für die Nutzung derselben LLMs von OpenAI und anderen Anbietern in der Cloud bezahlen.
Wir installieren ShellGPT mit der Erweiterung LiteLLM. Dahinter steckt eine Bibliothek, die es ShellGPT erlaubt, mit unterschiedlichen LLM-Anbietern und Modellen zu interagieren. Sie bietet eine einheitliche Schnittstelle für den Zugriff auf über 100 verschiedene, auch lokale LLMs, darunter OpenAI, Hugging Face, Ollama und Openroute. Der Befehl pipx install shell-gpt[litellm] installiert LiteLLM. Dazu benötigen Sie mindestens Python 3.8.
Die Ausgabe des Befehls informiert Sie über die Version von ShellGPT sowie die von Python und deklariert deren globale Verfügbarkeit. Dazu legt die Installation in ~/.local/share/pipx/venvs/shell-gpt/ eine Struktur an. Sie ermöglicht es Anwendungen wie ShellGPT, über das Python-Modul Venv [9] per CLI überall verfügbar zu sein, ohne dass eine herkömmliche virtuelle Umgebung aktiviert sein muss.
Nun schließt sich die Konfiguration (Abbildung 4) von ShellGPT an. Der Kasten “ShellGPT konfigurieren” fasst sie zusammen. Damit haben Sie die Installation und Konfiguration Ihrer KI im Terminal abgeschlossen. Nun ist es an der Zeit, mit ShellGPT Kontakt aufzunehmen. Um damit zu kommunizieren, dient sgpt als Präfix. Fragen oder Anweisungen setzen Sie in Anführungszeichen dahinter. Geben Sie zunächst nur shellgpt ein, stellt sich die Anwendung mit ihren Fähigkeiten (Abbildung 5) kurz vor.
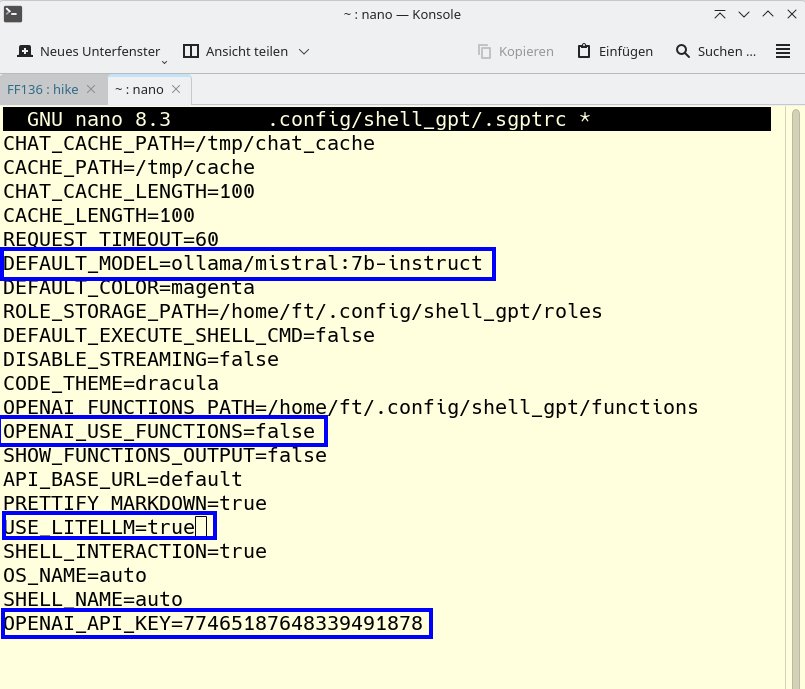
Abbildung 4: Die Konfigurationsdatei von ShellGPT müssen Sie in vier Punkten anpassen. Als API-Key geben Sie einen zufällig erzeugten String ein.
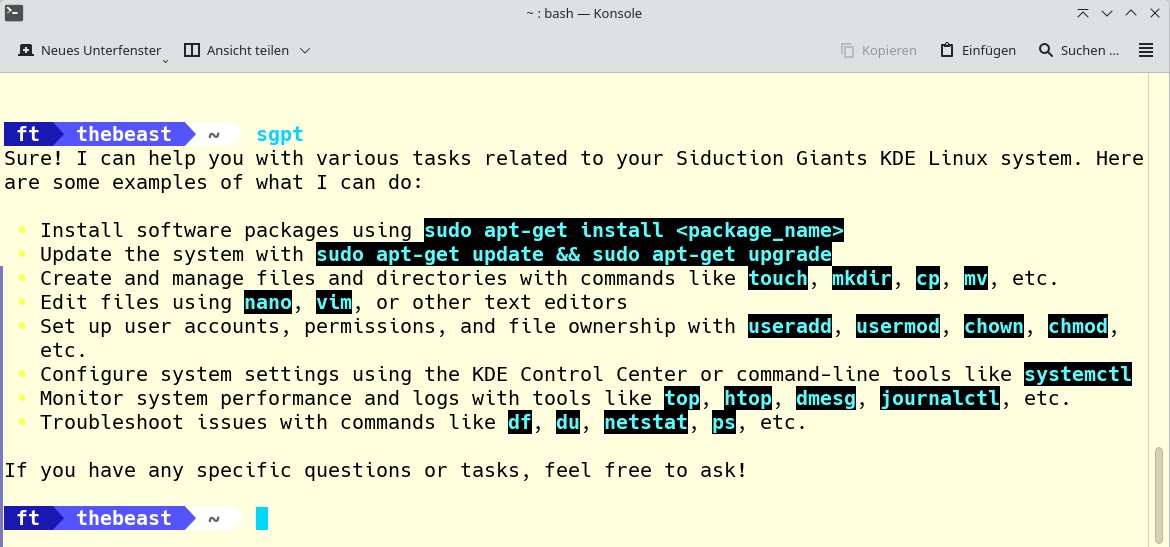
Abbildung 5: ShellGPT erkennt das Betriebssystem und informiert kurz über seine Fähigkeiten.
ShellGPT konfigurieren
Die Konfiguration von ShellGPT finden Sie in der Datei .sgptrc im Verzeichnis ~/.config/shell_gpt/. Um sie zu editieren, öffnen Sie zunächst die Datei in einem Editor und nehmen dort wie in Listing 2 gezeigt in den mit DEFAULT_MODEL, OPENAI_USE_FUNCTIONS, USE_LITELLM und OPENAI_API_KEY beginnenden Zeilen Anpassungen vor. Vergessen Sie nicht, die Datei anschließend zu speichern.
Listing 2
ShellGPT konfigurieren
### DEFAULT_MODEL=ollama/mistral:gtp-4o DEFAULT_MODEL=ollama/mistral:7b-instruct ### OPENAI_USE_FUNCTIONS=true OPENAI_USE_FUNCTIONS=false ### USE_LITELLM=false USE_LITELLM=true ### OPENAI_API_KEY=77465187648339491878 OPENAI_API_KEY=ZufälligErzeugterString
Mistral hat uns gleich zu Anfang mit einer falschen Antwort auf eine einfache Frage enttäuscht (Abbildung 6). Wir wollten wissen, wie wir ShellGPT in Debian einrichten können. Mistral schlug vor, es per Apt zu installieren, obwohl ShellGPT nicht in den Repositories von Debian enthalten ist. Auf unseren Hinweis, dass das nicht möglich sei, kam dann zwar eine korrekte Antwort, aber nicht die bevorzugte Lösung, die eine Venv-Umgebung in Python nutzt.
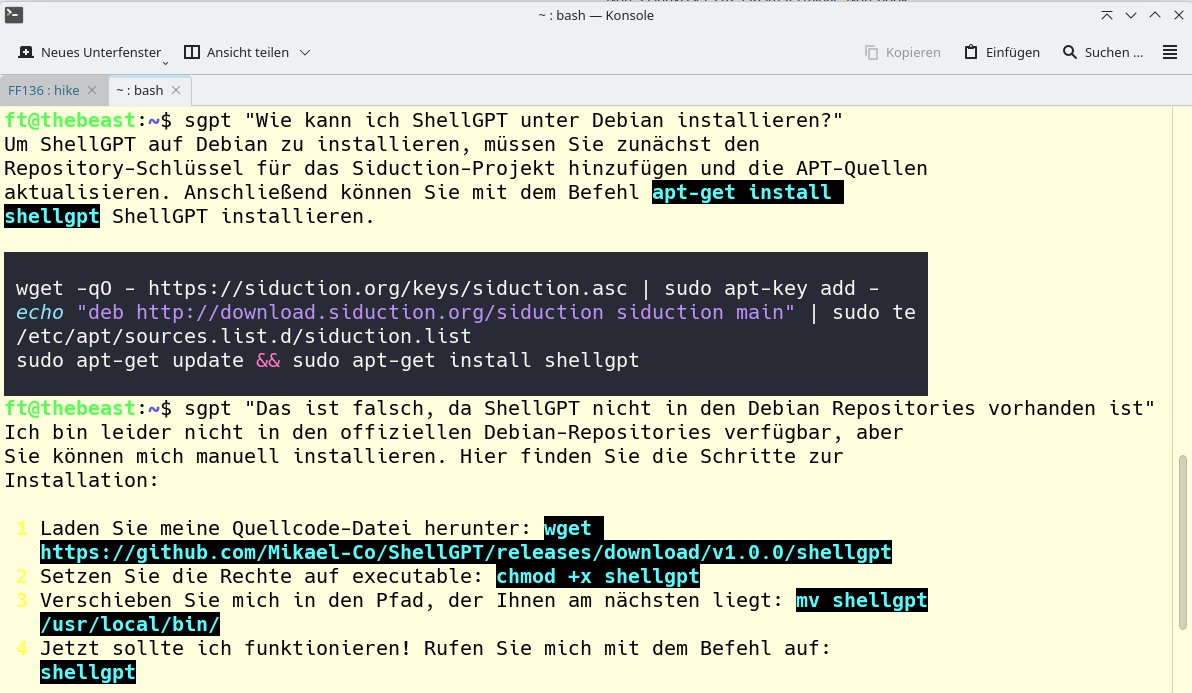
Abbildung 6: Die erste Frage, die wir ShellGPT mit dem Mistral-LLM beantworten ließen, war die nach der Installation unter Debian. Wir erhielten eine falsche Antwort, die ShellGPT erst nach unserem Rüffel berichtigte.
Deshalb haben wir mit ollama run deepseek-r1 zusätzlich das derzeit gehypte chinesische LLM DeepSeek eingebunden. Mit b8 rangiert es etwas höher als Mistral. DeepSeeks Antwort auf dieselbe Frage entsprach in etwa der, die wir von Mistral nach dem Hinweis auf die falsche Antwort erhielten. Dabei zeigte sich das Modell allerdings übermäßig geschwätzig (Abbildung 7) und legte erst einmal nahe, Bash zu installieren. Egal: Besser ausführlich und im Plauderton als falsch.
Dieser kleine Test zeigt, dass auch mittelgewichtigen LLMs eklatante Fehler unterlaufen. Grundsätzlich erweist es sich als vorteilhaft, wenn Sie Ihre Fragen in korrektem Englisch formulieren. Um einschätzen zu können, ob eine Antwort richtig ist, hilft es selbstverständlich, über Grundkenntnisse bezüglich der abgefragten Materie zu verfügen.
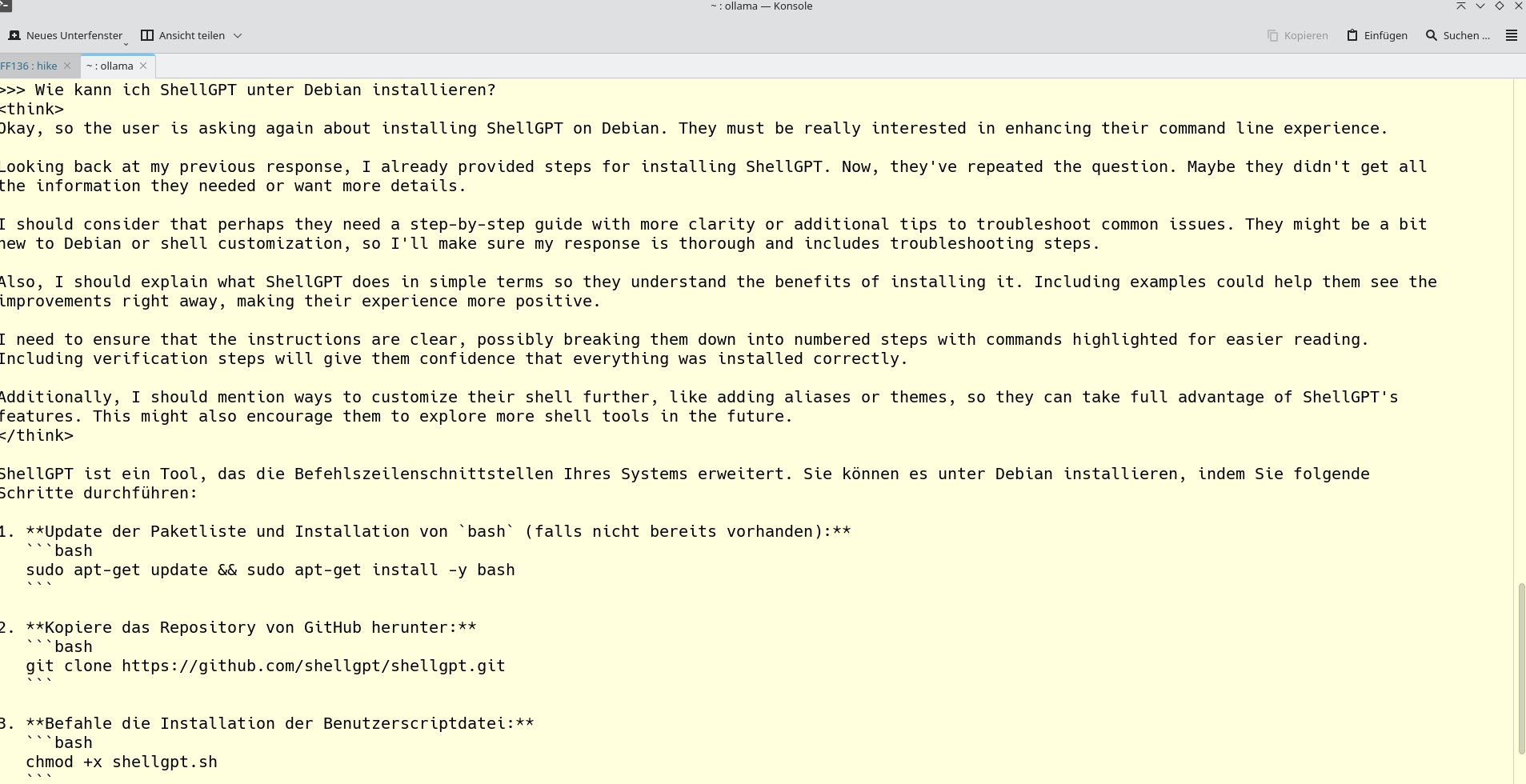
Abbildung 7: Das noch junge, aus China stammende LLM DeepSeek ist zwar sehr geschwätzig, wusste aber auf Anhieb die richtige Antwort.
Arbeit im Terminal
Zum Abschluss zeigen wir Ihnen einige einfache Beispiele für die Interaktion mit ShellGPT, die seine Vielseitigkeit beim Codegenerieren, dem Analysieren von Protokollen oder dem Erzeugen von Shell-Befehlen demonstrieren. ShellGPT stellt sich und seine Fähigkeiten durch die Eingabe von shellgpt vor. Wir erstellen zunächst einen Befehl (Abbildung 8), der rekursiv JPG-Bilder löscht, die von einem Pixel-Smartphone stammen und deren Namen mit PXL beginnen.
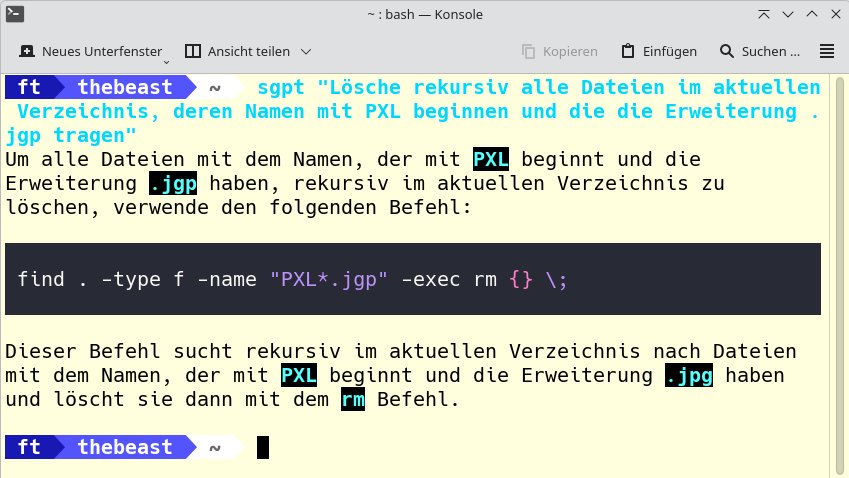
Abbildung 8: Anstatt die betreffenden Dateien händisch zu suchen, lassen wir ShellGPT ein kleines Skript schreiben, um Dateien rekursiv zu löschen.
Dazu geben wir die Anfrage aus der ersten Zeile von Listing 3 ein. Die Antwort entspricht dem, was das bereits erwähnte Shell Genie ausgibt. Zusätzlich liefert ShellGPT eine kurze Erklärung des Kommandos. Daraufhin lassen wir uns ein Backup-Skript (zweite Zeile) schreiben, das unsere tägliche Arbeit nachts speichert (Abbildung 9).
Listing 3
ShellGPT-Aufrufe
$ sgpt "Lösche rekursiv alle Dateien im aktuellen Verzeichnis, deren Namen mit PXL beginnen und die die Erweiterung .jgp tragen" $ sgpt "Schreibe ein Bash-Skript, das täglich um 02:00 ein Backup von /home/ft/arbeit/ nach /home/ft/backup/ schreibt" $ sgpt "Schreibe ein Bash-Skript, dass das Systemd-Journal täglich nach den Begriffen rocm und ROCm durchsucht und das Ergebnis in eine Datei nach dem Schema rocm-YYYY-MM-DD.log speichert"
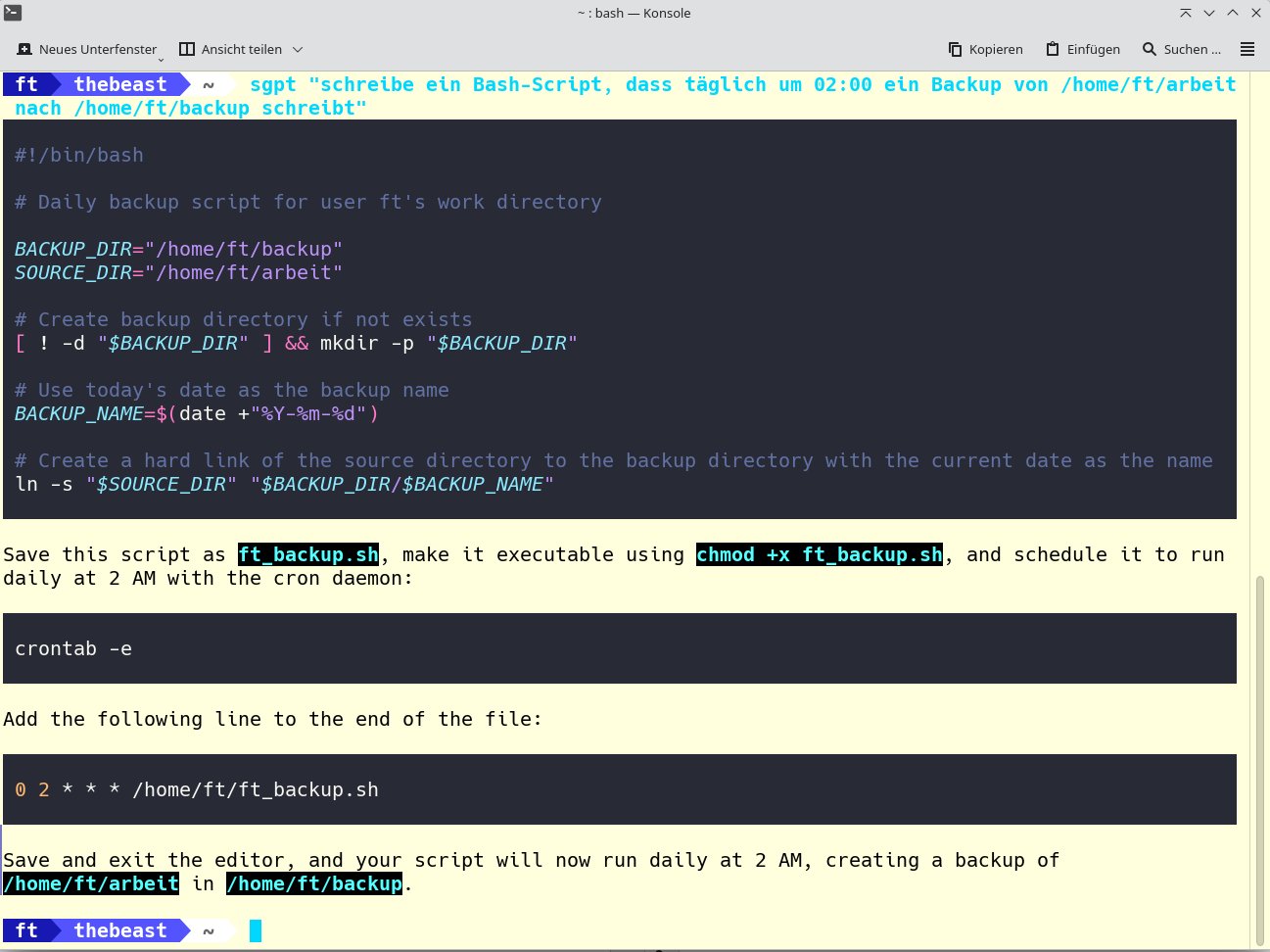
Abbildung 9: Auch ein Backup-Skript ist für ShellGPT kein Problem. Selbstverständlich sollte man kein Backup auf dieselbe Platte schreiben, aber zur Demonstration genügt es.
Wenn Sie wissen möchten, wann und wie oft ein Begriff in einem Log auftaucht, lassen Sie beispielsweise für das Systemd-Journal ein Skript (dritte Zeile) erzeugen, dass die Vorkommen täglich in eine Datei schreibt (Abbildung 10). Reguläre Ausdrücke stellen ShellGPT ebenso wenig vor eine Herausforderung. Die Shell-Erweiterung extrahiert damit zum Beispiel problemlos URLs aus einem Text (Abbildung 11).
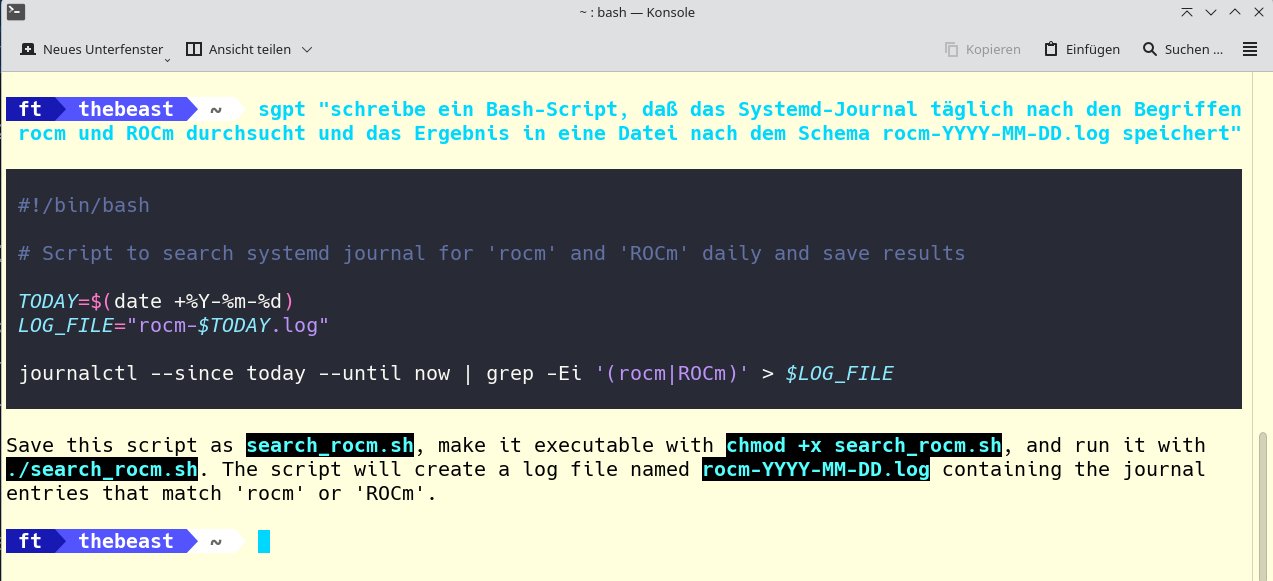
Abbildung 10: Die Analyse von Protokolldateien kann beim Auffinden von Fehlern im Systemablauf helfen. ShellGPT hilft auch dabei.
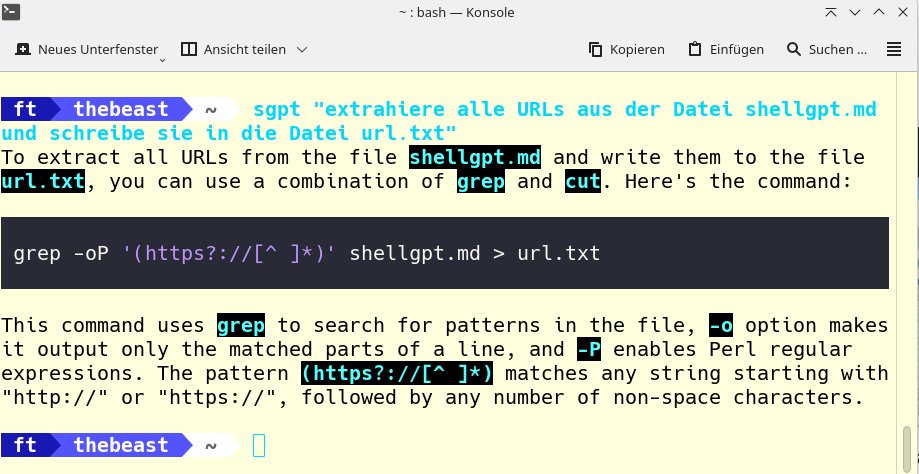
Abbildung 11: Per regulärem Ausdruck fischt der von ShellGPT erstellte Befehl URLs aus einem Testdokument heraus und schreibt sie in eine Datei.
Dass sich ShellGPT je nach verwendetem Modell mitunter gewaltig irren kann, zeigte sich beim Versuch, unser unter Siduction (Debian “Sid”) laufendes System aktualisieren zu lassen. Anstatt zur für einen Debian-Abkömmling korrekten Aufruffolge (Listing 4, Zeile 2 und 3) riet uns das Tool zu einem nur für Arch-Linux-Derivate gültigen Kommando (Zeile 5).
Listing 4
ShellGPT-Patzer
### korrekte Anweisungen $ sudo apt update $ sudo apt full-upgrade ### ShellGPT-Patzer $ sudo pacman -Syu
Fazit
Arbeiten Sie häufiger im Terminal, erweist sich ShellGPT nach einer gewissen Einarbeitungsphase als nützliches Tool. Es kann die Shell tatsächlich etwas intelligenter machen. Welches LLM Sie dafür einsetzen, hängt neben den verfügbaren Hardwareressourcen auch davon ab, ob Sie hauptsächlich Texte behandeln und Fragen beantworten oder Code ausgeben lassen möchten. Mittlerweile beherrscht ShellGPT außerdem Function Calls, mit denen Sie benutzerdefinierte Funktionen [10] für LLMs erstellen.
Eines sollten Sie beim Verwenden von LLMs – egal, ob es sich um Ollama und ShellGPT oder andere Tools wie Open WebUI [11] handelt – immer im Hinterkopf behalten: Die Ergebnisse sind nicht zwangsläufig korrekt. Oft genug halluzinieren die Modelle aus unterschiedlichen Gründen. Mit wirklicher Intelligenz hat das momentan dann doch noch nicht viel zu tun. (csi/jlu)
Infos
-
Shell Genie: Ferdinand Thommes, “Gute Frage!”, LU 09/2023, S. 10, https://www.linux-community.de/49465
-
Ollama: https://github.com/ollama/ollama
-
Mistral:https://mistral.ai
-
ShellGPT: https://github.com/TheR1D/shell_gpt
-
Ollama-Library: https://ollama.com/library
-
ShellGPT erweitern: https://github.com/TheR1D/shell_gpt/discussions/416
-
Open WebUI: https://openwebui.com
-
LLM-Grundlagen: Carsten Schnober, “Maschinensprache”, LM 05/2024, S. 16, https://www.lm-online.de/50528
-
NLP: https://datasolut.com/natural-language-processing-einfuehrung/




