

Nach und nach hält künstliche Intelligenz in Form nativer Werkzeuge in Betriebssysteme Einzug. Wir haben uns angesehen, wie weit die Entwicklung von KI-Assistenten unter Linux gediehen ist.
Künstliche Intelligenz kann in verschiedensten Anwendungsszenarien hilfreich sein. Bislang haben es jedoch nur wenige Distributionen geschafft, eigenentwickelte KI-Assistenten, die auf Large Language Models (LLMs) beruhen, in ihre Systeme einzupflegen. Für die Vielzahl von Linux-Derivaten, die noch keine KI-Assistenten mitbringen, gibt es deshalb zunehmend freie und proprietäre Lösungen, die zahlreiche täglich anfallende Aufgaben am Arbeitsplatz vereinfachen. Sie greifen dabei auf unterschiedliche Sprachmodelle zu und können diese teils sogar lokal installieren, sodass die KI-Assistenten auch dann funktionieren, wenn kein Internetzugang besteht. Wir haben uns einige der KI-Helferlein angesehen.
Technische Basis
Unter einem KI-Assistenten verstehen viele Anwender reine Chatbots, mit denen sie kommunizieren können. Solche Applikationen sind zwar die bekanntesten KI-Lösungen, stellen jedoch nur einen Bruchteil der derzeitigen Fähigkeiten künstlicher Intelligenz dar. KI-Anwendungen können ebenso Routineaufgaben im Büroalltag erledigen, im akademischen Bereich bei der Analyse und Strukturierung großer Datenmengen helfen oder visuelle Inhalte generieren und manipulieren. Auch Softwareentwickler profitieren bei der Anwendungsprogrammierung von KI-Unterstützung.
Das technische Fundament aller KI-Assistenten stellen das Natural Language Processing (NLP) und das Machine Learning (ML) dar, mit deren Hilfe sich menschliche Sprache textbasiert anhand von Trainingsdaten verstehen und interpretieren lässt. Die dazu von den KI-Helfern genutzten LLMs umfassen enorme Datenmengen und verfügen über Milliarden von während der Trainingsphase entstandenen Parametern als Variablen. Sie dienen dazu, Zusammenhänge herzustellen und neue Inhalte daraus abzuleiten.
KI-Assistenten für den Linux-Desktop lassen sich generell mit verschiedenen Sprachmodellen verwenden, wodurch man ihren Einsatzzweck individuell fokussieren kann. Sie bieten ein grafisches Frontend auf dem Desktop, während das LLM als Backend fungiert. Damit lassen sich die nativen KI-Applikationen wesentlich flexibler einsetzen als webbasierte Dienste, bei denen bestenfalls verschiedene Sprachmodelle einer einzigen Familie oder eines einzigen Herstellers zum Einsatz kommen.
Zur Nutzung kommerzieller Sprachmodelle benötigen Sie jedoch ein Konto beim jeweiligen Anbieter, wobei die Assistenten dazu entsprechende Konfigurationsmöglichkeiten eröffnen. Sie müssen also nicht bei jedem Aufruf des Assistenten Ihre Kontodaten neu eingeben. Auch ein Wechsel zwischen Online-Sprachmodellen und lokalen Installationen klappt bei den meisten KI-Assistenten ohne größere Umstände.
Alpaca
Alpaca [1] ist ein distributionsunabhängig einsetzbarer grafischer Client für Ollama [2], der sich mit unterschiedlichsten Sprachmodellen verwenden und damit äußerst flexibel einsetzen lässt.
Das als Flatpak bereitgestellte Programm benötigt zur Installation (Listing 1, erste Zeile) eine entsprechende Infrastruktur auf der Zielmaschine. Bitte beachten Sie, dass zum Einsatz von Alpaca Ollama ebenfalls installiert sein muss. Ollama beziehen Sie ebenfalls aus dem Netz (zweite Zeile). Auf der Website von Ollama finden Sie zahlreiche Sprachmodelle für den lokalen Einsatz. Sie lassen sich ebenfalls mit Alpaca verwenden, wobei Sie sie direkt im grafischen Frontend herunterladen und in die Installation integrieren.
Listing 1
Alpaca einrichten
# flatpak install flathub com.jeffser.Alpaca # curl -fsSL https://ollama.com/install.sh | sh
Nach der Einrichtung rufen Sie Alpaca direkt aus der Menühierarchie heraus auf. Das GTK-basierte Programm präsentiert zügig ein sehr schlichtes Fenster mit einem Willkommensgruß (Abbildung 1). Nach einem Klick auf Weiter unten rechts öffnet sich die eigentliche Programmoberfläche. Sie orientiert sich optisch und funktional an den Oberflächen vieler Instant Messenger: Links im Fenster listet Alpaca in einer schmaleren Spalte die Dialogstränge auf, rechts daneben erscheinen im größeren Segment die jeweiligen Dialoge.
Abbildung 1: Das Alpaca-Fenster präsentiert sich beim ersten Aufruf sehr spartanisch.
Zunächst benötigt die Anwendung jedoch ein Sprachmodell. Um es zu laden, klicken Sie auf die blaue Schaltfläche Öffne Modell-Manager. Im Menü Added findet sich beim ersten Öffnen kein Eintrag. Um sich die verfügbaren Sprachmodelle anzeigen zu lassen, klicken Sie oben in der Titelleiste auf die Option Available. In der sich daraufhin öffnenden Listenansicht (Abbildung 2) blenden Sie durch einen Klick auf eines der links im Fenster angezeigten Modelle rechts nähere technische Details dazu ein. Liegt ein Sprachmodell mit mehreren Parameter-Varianten vor, werden sie untereinander eingeblendet mitsamt dem jeweiligen Platzbedarf auf dem Massenspeicher.
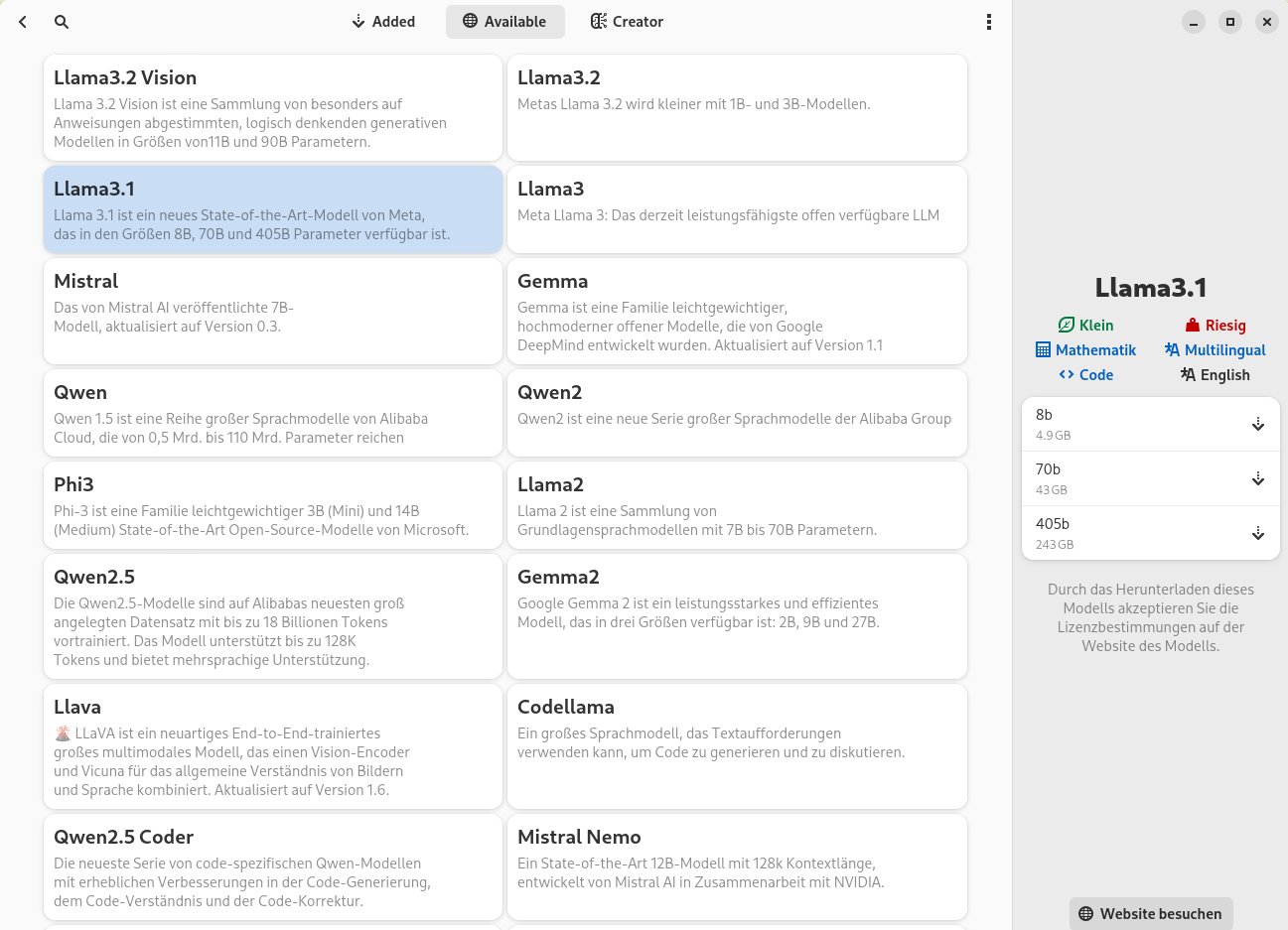
Abbildung 2: Alpaca lässt sich mit zahlreichen Sprachmodellen betreiben.
Durch einen Klick auf den Pfeil rechts daneben laden Sie das entsprechende LLM herunter. Dabei visualisiert ein Verlaufsbalken mit einer prozentualen Anzeige den Fortgang der Installation. In diesem Dialog erscheinen auch alle bereits heruntergeladenen und verfügbaren Sprachmodelle. Nach dem Download übernimmt Alpaca das neue Sprachmodell ins Menü Added.
Sie können ohne weitere Konfiguration sofort mit dem geladenen Sprachmodell arbeiten. Dazu geben Sie im primären Fenster der Anwendung unten in der Eingabezeile Ihre Frage ein und schließen die Anfrage durch einen Klick auf den blauen Senden-Button rechts daneben ab. Je nach Größe des Arbeitsspeichers des Rechners und dessen CPU-Leistung antwortet die KI nach einigen Augenblicken, wobei sie die Antwort sukzessive im rechten Fenstersegment ausgibt. Zur besseren Unterscheidung stellt Alpaca die Frage stets in einem kleinen Kasten rechts dar, während die Antwort links darunter erscheint. Die Antworten können je nach verwendetem Sprachmodell recht umfangreich ausfallen (Abbildung 3).
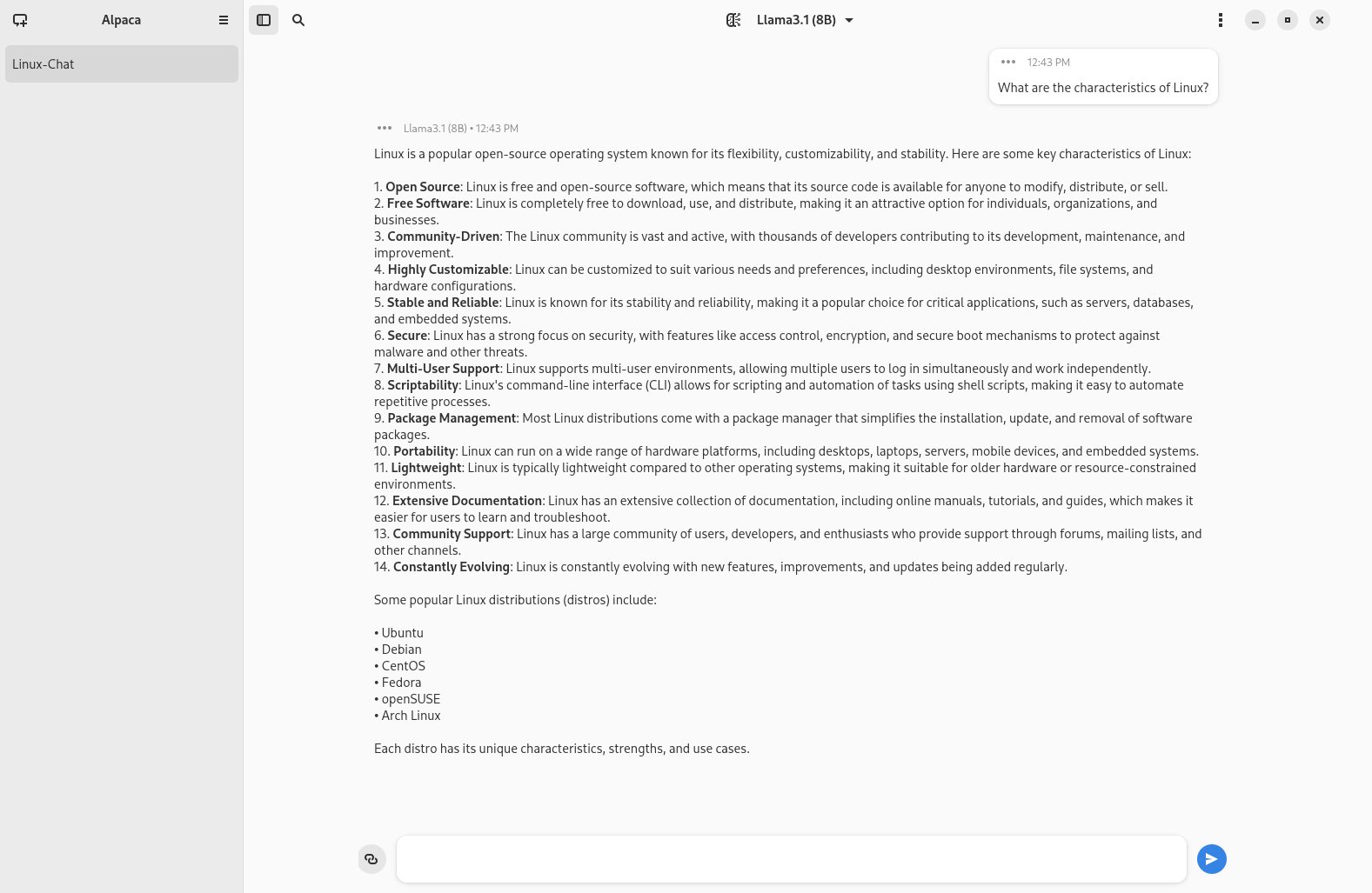
Abbildung 3: Alpaca gruppiert Fragen und Antworten unterschiedlich und gewährleistet so bei längeren Dialogen eine gewisse Übersicht.
Sie können jederzeit zusätzliche Sprachmodelle für spezifische Anwendungsbereiche nachladen, indem Sie im Hamburger-Menü der linken Spalte oben rechts die Option Modelle verwalten aufrufen und anschließend in der Titelleiste des Fensters den Eintrag Available anklicken. Das ermöglicht es beispielsweise, die KI-Maschine Code für Anwendungsprogramme schreiben (Abbildung 4) oder Bilder bearbeiten zu lassen. Das gewünschte Sprachmodell für einen neuen Dialog legen Sie im primären Anwendungsfenster oben mittig in der Titelleiste über das entsprechende Auswahlfeld fest.
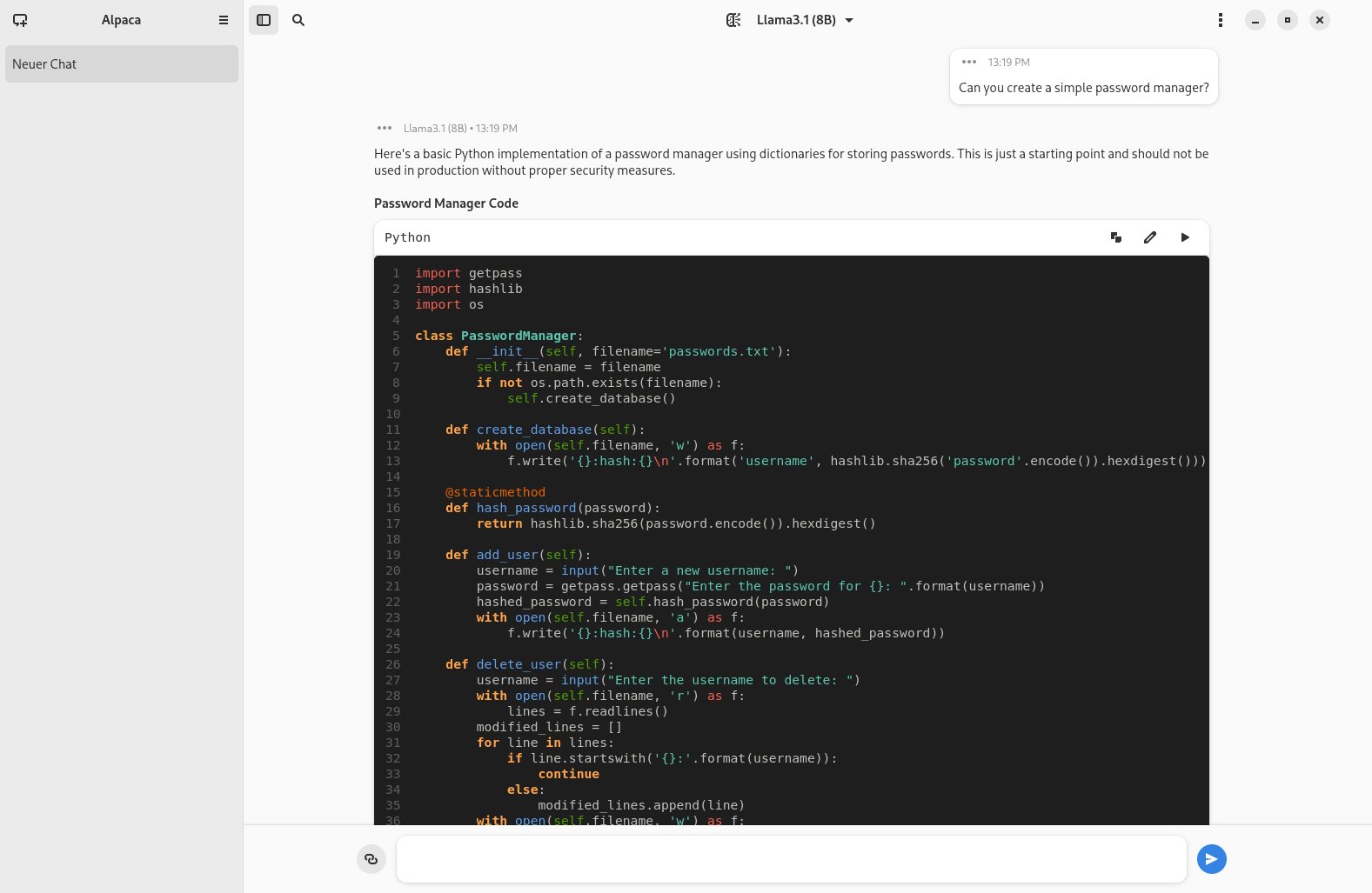
Abbildung 4: Alpaca schreibt bei Bedarf sogar komplette Anwendungsprogramme inklusive einer Anleitung und Kommentaren.
Eigenheiten
Dank der Basis Ollama unterstützt Alpaca eigenentwickelte Sprachmodelle für spezifische Zwecke. Dazu erzeugen Sie im Dialog für Sprachmodelle durch einen Klick auf Creator in der Titelleiste eine Abwandlung eines bereits in das System integrierten LLMs oder erstellen aus einer GGUF-Datei ein neues. Dabei können Sie das Sprachmodell (Alpaca bezeichnet es als Identität) frei wählen und seine Genauigkeit anhand der Parameter Vorstellungskraft und Fokus definieren. Diese Werte geben Sie als absolute Zahlen an. Dabei können Sie nach Belieben experimentieren, bis das selbst erstellte Modell Ihren Vorstellungen entspricht.
Kommunikativ
Alpaca gestattet es außerdem, Dialoge für eine spätere Weiterverwendung außerhalb der Applikation zu sichern. Dazu klicken Sie im rechten Fenstersegment auf das punktierte Menü und wählen dort den Eintrag Chat exportieren.
In einem neuen Dialog legen Sie dann zunächst das gewünschte Dateiformat für den Export fest. Zum Speichern von Codeschnipseln offeriert Alpaca beispielsweise mehrere Dateiformate, darunter Markdown sowie zwei JSON-Varianten. Nach Auswahl des gewünschten Formats und einem Klick auf Akzeptieren öffnet sich ein Dateimanager zur Vergabe des Dateinamens und Angabe des Zielpfads. Voreingestellt dient die Bezeichnung des Chats als Dateiname.
Da Alpaca neben Markdown und JSON lediglich noch ein SQLite-Datenbankformat unterstützt, lassen sich die Chat-Daten nicht sofort in einer Textverarbeitung nutzen. Sie müssen sie beim Sichern über die Exportfunktion entsprechend nachbearbeiten, wenn sie in einen Text einfließen sollen. Einfacher klappt der Export von Chat-Verläufen in eine Textverarbeitung, indem Sie den gesamten Kommunikationsstrang oder einen Teil davon in der Verlaufsanzeige markieren und in die Zwischenablage kopieren. Diese Daten lassen sich dann ohne Formatierung in jede Textverarbeitung einfügen.
HINWEIS
Bitte beachten Sie, dass das Herunterladen eines Sprachmodells zur lokalen Nutzung je nach Geschwindigkeit des vorhandenen Internetzugangs viel Zeit beanspruchen kann, da die LLMs meist einen Umfang von mehreren Gigabyte aufweisen.
Bavarder
Der freie KI-Assistent Bavarder [3] wird primär für den Gnome-Desktop entwickelt, lässt sich jedoch auch unter anderen Arbeitsumgebungen einsetzen.
Das Projekt stellt die Software nicht für konventionelle Paketverwaltungssysteme bereit, sondern ausschließlich als Flatpak. Sie installieren daher zunächst – sofern nicht bereits vorhanden – die benötigte Flatpak-Infrastruktur und fügen anschließend Bavarder als Flatpak dem System hinzu (Listing 2). Dabei entsteht ein Starter in der Menühierarchie der verwendeten Arbeitsumgebung.
Listing 2
Bavarder einrichten
# flatpak install io.github.Bavarder.Bavarder
Nach einem Klick darauf öffnet das Werkzeug ein übersichtliches Fenster mit lediglich zwei Spalten (Abbildung 5). In der kleineren linken Spalte erscheinen die Namen der Unterhaltungen mit der KI, während rechts ähnlich wie bei einem Instant Messenger der Kommunikationsstrang der Dialoge festgehalten wird.
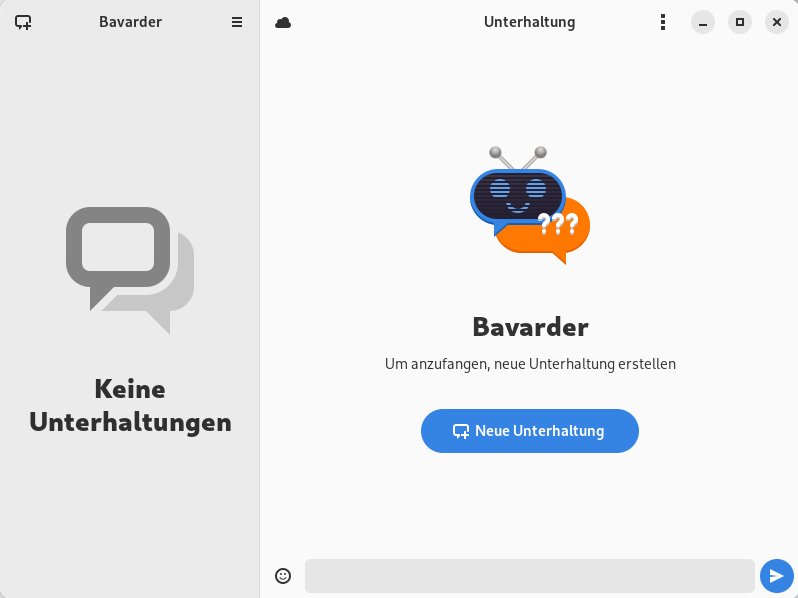
Abbildung 5: Auch das Programmfenster von Bavarder ist sehr übersichtlich gestaltet.
Konfiguration
Um das Tool überhaupt nutzen zu können, müssen Sie zunächst einige Grundeinstellungen vornehmen. Dazu klicken Sie in der linken Spalte auf das Hamburger-Menü oben in der Titelleiste und wählen die Option Einstellungen aus.
Im folgenden Dialog wählen Sie zunächst einen der gelisteten, zum Programm kompatiblen Anbieter von Sprachmodellen aus. Bavarder unterstützt eine ganze Reihe unterschiedlicher Anbieter, die sich über einen Schieberegler aktivieren lassen. Voreingestellt sind die beiden LLMs Google Flan T5 XXL und GPT2 freigeschaltet, sodass Sie sofort mit einem Dialog beginnen können. Beachten Sie, dass Sie für die meisten Sprachmodelle einen API-Key eingeben müssen, der ein Konto beim jeweiligen Anbieter voraussetzt.
Im Konfigurationsfenster führt Bavarder unterhalb der voreingestellten Anbieter in der Rubrik Modelle zahlreiche weitere LLMs auf, die Sie bei Bedarf einzeln durch einen Klick auf den jeweils rechts neben jedem Eintrag platzierten Pfeil auf den lokalen Massenspeicher herunterladen. In der Liste der Anbieter findet sich zudem der Eintrag Local (Abbildung 6), mit dessen Hilfe Sie jeden beliebigen Anbieter in Bavarder integrieren.
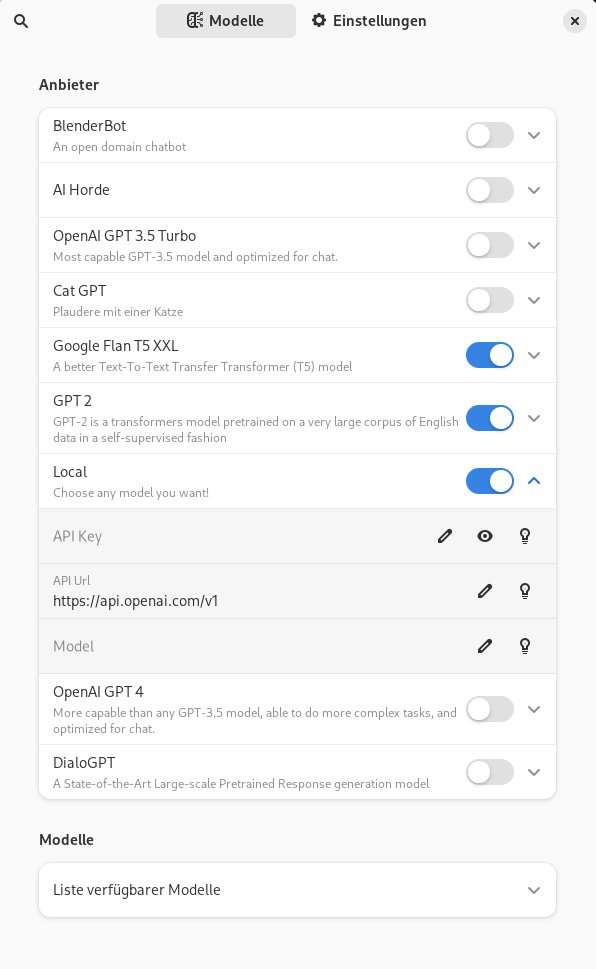
Abbildung 6: Bavarder bindet zahlreiche LLM-Modelle per Mausklick ein.
Im Konfigurationsdialog passen Sie außerdem weitere Optionen an, indem Sie in der Titelleiste auf den Eintrag Einstellungen klicken. Das sich daraufhin öffnende Menü ermöglicht das Leeren des Kommunikationsstrangs und die Definition eines individuellen Namens für den Chatbot und den Anwender.
In medias res
Um mit der eigentlichen Kommunikation beginnen zu können, legen Sie zunächst fest, welches Sprachmodell Bavarder verwenden soll. Da voreingestellt bereits zwei Modelle aktiviert sind, können Sie oben rechts im primären Fenster nach einem Klick auf das Punktemenü durch Setzen eines Radiobuttons das gewünschte LLM auswählen.
Im selben Dialog rufen Sie bei Bedarf durch einen Klick auf Einstellungen unterhalb der Modellauswahl das Konfigurationsfenster erneut auf. Dadurch vermeiden Sie das umständliche Verlassen des Auswahlmenüs und den erneuten Aufruf der Konfiguration aus dem Hamburger-Menü heraus, falls in den Einstellungen des Sprachmodells ein Fehler vorliegt.
Nach Abschluss der Konfiguration klicken Sie im primären Fenster auf die blaue Schaltfläche Neue Unterhaltung. Links startet daraufhin die neue Unterhaltung mit der Bezeichnung New Chat**1. Unten in der Eingabezeile beginnen Sie Ihren Dialog mit der KI und posten Ihre eingetippte Frage durch einen Klick auf den blauen Pfeil unten rechts im Fenster. Erscheint sofort die Antwort Entschuldige, ich weiß nicht, was ich sagen soll., ist das aktivierte Sprachmodell nicht korrekt initialisiert. In den meisten Fällen fehlt schlicht der API-Schlüssel oder wurde fehlerhaft eingegeben.
Die Fragen und Antworten formatiert Bavarder optisch deutlich differenziert mit unterschiedlich gefärbten Kästen und verschiedenfarbigen Symbolen für den Anwender und den Chatbot (Abbildung 7). So lässt sich der gesamte Kommunikationsstrang leicht nachvollziehen.
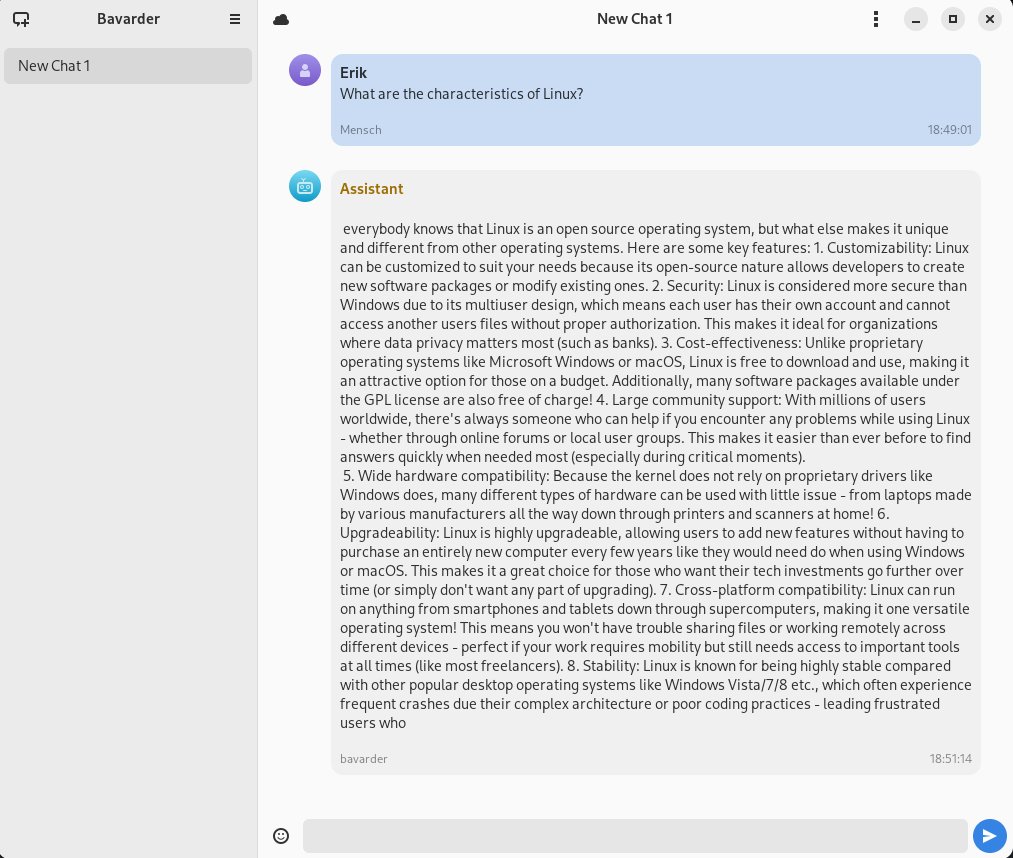
Abbildung 7: Die Dialogstränge werden voneinander abgesetzt angezeigt.
In den Dialogsträngen lassen sich unterschiedliche spezialisierte Sprachmodelle für bestimmte Aufgaben verwenden. Dadurch liefert die KI beispielsweise in einem Strang KI-Hilfe für die Programmierung von Applikationssoftware, während Sie in einem anderen Strang lediglich ein allgemeines Gespräch führen.
Haben sich mehrere Dialoge angesammelt, können Sie diese jederzeit durch einen Klick auf die entsprechende Bezeichnung in der linken Spalte des Programmfensters rekapitulieren. Möchten Sie einen der Dialoge löschen, so klicken Sie mit der rechten Maustaste auf den betreffenden Titel und wählen anschließend aus dem Kontextmenü die Option Löschen. Bavarder entfernt daraufhin nach einer Sicherheitsabfrage den Strang samt dem dazugehörigen Dialog.
Kuriose und einer gewissen Deutungsbandbreite unterliegende Dialogergebnisse liefert Bavarder, wenn Sie Cat GPT als Sprachmodell auswählen. Die KI versucht dann, Katzenlaute nachzuahmen und in lesbaren Text umzusetzen. Die entsprechenden Dialoge lassen sich anschließend allerdings nur noch von Katzenflüsterern und Nutzern, die der vielfältigen Dialekte der Katzensprache mächtig sind, korrekt interpretieren (Abbildung 8).
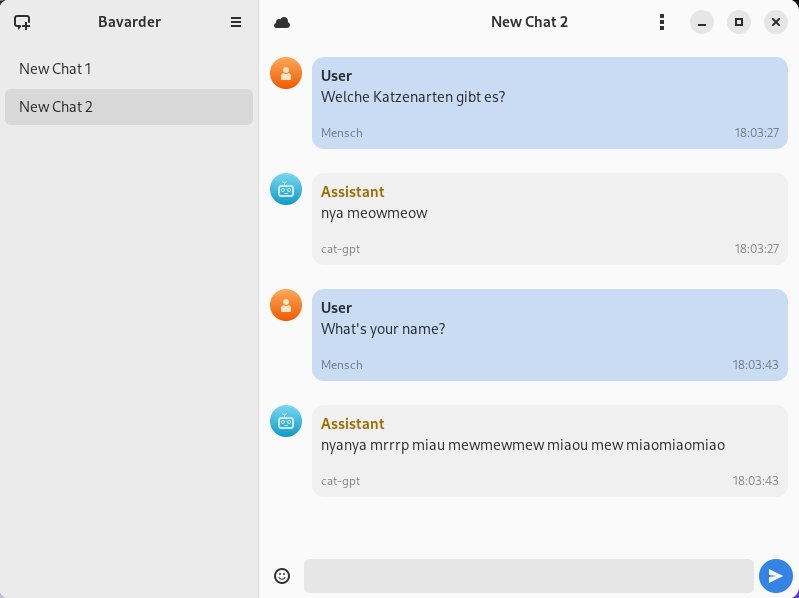
Abbildung 8: Katzen verstehen sicher auf Anhieb, was hier gemeint ist.
Weiterverarbeitung
Die mithilfe der einzelnen Sprachmodelle generierten Dialoge lassen sich zur Weiterverarbeitung in anderen Anwendungen exportieren. Dazu klicken Sie im rechten Fenstersegment oben auf das Punktemenü und wählen dort die Option Exportieren aus. Die Anwendung öffnet daraufhin ein kleines Fenster, aus dem Sie den Dialog in die Zwischenablage kopieren. Alternativ klicken Sie in diesem Fenster auf Exportieren und gelangen in einen weiteren Dialog zur Angabe des Ablagepfads und Dateinamens. Nach einem Klick auf Speichern legt Bavarder den kompletten Dialog als einfaches Textdokument im angegebenen Pfad ab.
Newelle
Newelle ist ein noch recht junger grafischer KI-Assistent für Linux [4]. Sie integrieren das freie Programm als Flatpak-Paket in jedes Linux-Derivat mit entsprechender Unterstützung (Listing 3, erste Zeile), wobei im Menü Zubehör ein passender Starter entsteht.
Listing 3
Newelle einrichten
# flatpak install flathub io.github.qwersyk.Newelle # flatpak run --talk-name=org.freedesktop.Flatpak --filesystem=home io.github.qwersyk.Newelle
Nach dem ersten Start öffnet das GTK-basierte Programm neben dem eigentlichen Programmfenster in einem gesonderten Dialog einen Assistenten für die Grundkonfiguration. Bereits im zweiten Schritt der Routine, die Sie mithilfe des Pfeil-Buttons rechts im Assistenten erreichen, definieren Sie ein Sprachmodell. Newelle kann dabei sowohl mit cloudbasierten LLMs als auch mit lokal gespeicherten Modellen umgehen (Abbildung 9).
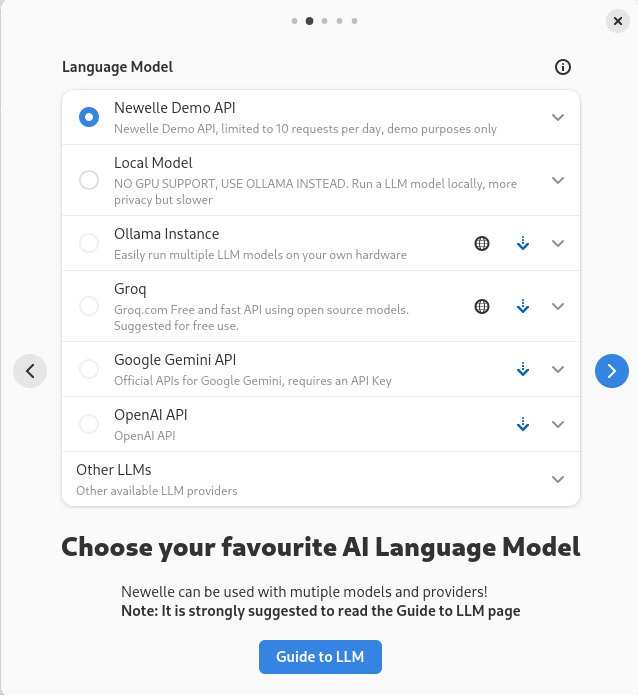
Abbildung 9: Newelle versteht sich sowohl mit cloudbasierten als auch mit lokalen LLM-Modellen.
Voreingestellt ist die stark eingeschränkte Newelle Demo API aktiv, die tatsächlich nur zu Demonstrationszwecken taugt. Durch Setzen eines Radiobuttons aktivieren Sie stattdessen die üblichen Sprachmodelle von Google und OpenAI oder ein lokal gespeichertes LLM. Für das lokale Subsystem unterstützt Newelle Ollama.
Die Gruppe Other LLMs, die Sie ganz unten in der Listenansicht finden, bietet einige Überraschungen: Dort können Sie nicht nur frei erhältliche Anbieter aktivieren, wobei die Software eigenständig eine Auswahl vornimmt, sondern auch das neue DeepSeek-Sprachmodell oder Microsofts Copilot.
Unterhalb der einzustellenden LLMs lassen sich weitere Optionen für die Software konfigurieren. So beherrscht Newelle auch die Ein- und Ausgabe von Sprache. Als Backends dienen dabei wahlweise cloudbasierte Dienste wie Google TTS oder lokal installierbare TTS-Systeme wie eSpeak. Als Speech-to-Text-Backends wählen Sie per Radiobutton je nach Präferenz ebenfalls Clouddienste oder lokal arbeitende Anwendungen aus. Dazu müssen freilich die entsprechenden lokalen Backends im System installiert sein.
Einstellmöglichkeiten
Weitere Einstellmöglichkeiten betreffen die Oberfläche sowie Drittprogramme. Hier können Sie beispielsweise eine Terminalanwendung für am Prompt einzugebende Befehle vorgeben. Ferner legen Sie hier fest, wie viele Kommunikationsstränge Newelle sichern soll. Voreingestellt bleiben die letzten zehn Dialoge erhalten.
Im nächsten Schritt der Konfiguration beziehen Sie Erweiterungen für Newelle. Dazu bringt Sie die entsprechende Schaltfläche auf eine Github-Seite mit speziell für Newelle verfügbaren Extensions, mit deren Hilfe Sie die Funktionalität der Applikation ausbauen. Diesen Schritt können Sie jedoch durch einen Klick auf den Pfeil rechts im Fenster überspringen.
Im letzten Fenster des Konfigurationsdialogs weist die Routine darauf hin, dass Newelle aufgrund seiner Ausführung in einer virtualisierten Flatpak-Umgebung nicht über genügend Benutzerrechte verfügt, um außerhalb dieser Umgebung Befehle ausführen zu können. Durch Eingabe des Kommandos aus der letzten Zeile von Listing 3 gewähren Sie der KI temporär die benötigten Rechte. Mithilfe des Werkzeugs Flatseal vergeben Sie sie bei Bedarf dauerhaft.
Nach der entsprechenden Modifikation erscheint die abschließende Meldung, und Sie können nun durch einen Klick auf die Schaltfläche Start chatting einen Dialog beginnen.
Losgeplaudert
Das nun vollständig sichtbare eigentliche Programmfenster orientiert sich wie die der Konkurrenten optisch und funktional am Erscheinungsbild von Messenger-Diensten: Links gibt es eine Spalte mit einer Liste der vorhandenen Kommunikationsstränge, rechts findet der Dialog statt.
Zunächst klicken Sie unten links auf Einen Chat erstellen. und können dann in die unten rechts angeordnete Eingabezeile Ihre erste Frage an den Chatbot eingeben und sie absenden. Sie erscheint anschließend oben links im Dialogstrang in einem Kasten. Direkt darunter blendet Newelle nach kurzer Zeit seine Antwort ein, die sich allerdings optisch kaum von der Frage abhebt (Abbildung 10). Das schränkt bei längeren Dialogen die Übersicht beim schnellen Scrollen etwas ein.
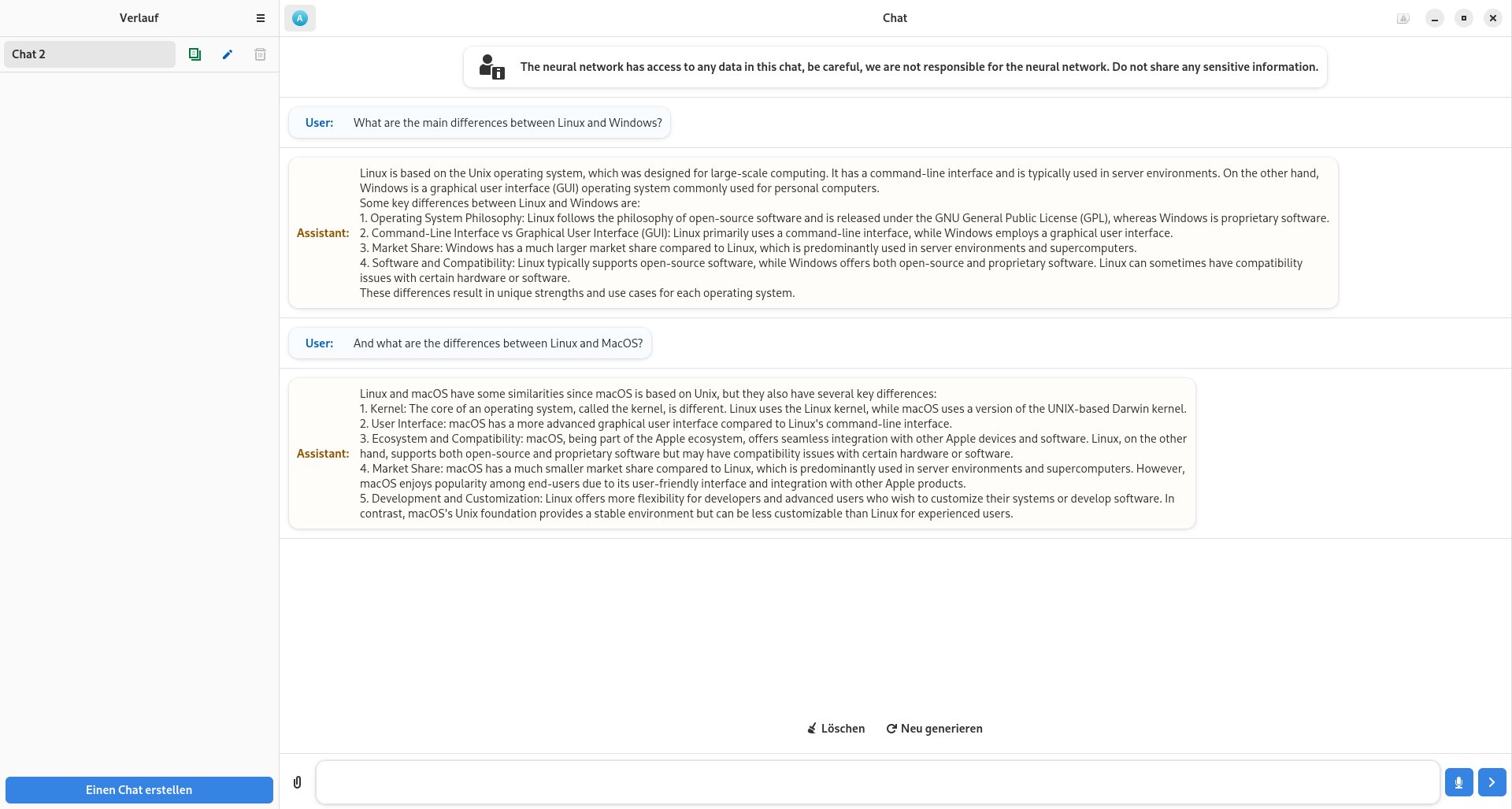
Abbildung 10: Bei Newelle ist nicht immer eine ausreichende Übersicht über den Chat-Verlauf gegeben.
Der KI-Assistent gestattet nicht, manuell einen aussagekräftigen Titel für den Dialog zu vergeben. Stattdessen generiert die KI bei Bedarf automatisch eine Bezeichnung dafür. Um sie einen Titel erzeugen zu lassen, klicken Sie oben links in der Dialogliste auf das Bleistiftsymbol rechts neben dem entsprechenden Eintrag. Newelle lässt sich anschließend etwas Zeit, um einen aussagekräftigen Titel zu vergeben.
Defizitär
Newelle bietet derzeit keine Möglichkeit, einen kompletten Kommunikationsstrang zu speichern. Sie können lediglich einzelne Beiträge durch Markieren und anschließendes Kopieren in die Zwischenablage sichern. Immerhin lassen sich einzelne Fragen und Antworten aus dem Strang löschen, indem Sie auf das Papierkorbsymbol klicken, das die Anwendung links neben einem Beitrag anzeigt, sobald Sie den Mauszeiger darüber bewegen.
Unangenehm fällt der enorme Ressourcenverbrauch von Newelle bei der Verwendung bestimmter LLMs auf. Die Verwendung einer Ollama-Instanz, die mit anderen Frontends wie Alpaca schnell und ohne spürbare Belastung des Gesamtsystems arbeitete, lastete unter Newelle alle Kerne der CPU nahezu vollständig aus. Bei der Verwendung cloudbasierter Dienste trat dieser Effekt nicht auf.
PyGPT
Der quelloffene KI-Assistent PyGPT [5] ist primär für den Einsatz mit ChatGPT von OpenAI ausgelegt. Das Python-Programm lässt sich auf verschiedenen Wegen installieren, die die Projektseite ausführlich dokumentiert. Mit Ausnahme des Snap-Paketformats unterstützt das Projekt derzeit noch keine in Linux integrierten Paketverwaltungen.
PyGPT versteht sich in erster Linie als natives und lokal installiertes grafisches Frontend für ChatGPT, das den Funktionsumfang des KI-Chatbots jedoch erheblich erweitert und zudem lokale Sprachmodelle auf Basis von Ollama unterstützt. PyGPT kann darüber hinaus Kamerabilder in Echtzeit analysieren und mit Daten sowie Dokumenten arbeiten. Die Ausführung von Befehlen ermöglicht das Programm ebenfalls.
Oberflächliches
Nach der Installation rufen Sie PyGPT aus der Arbeitsoberfläche heraus auf. Das Programmfenster wirkt zunächst überladen und wenig übersichtlich. Zusätzlich zu einer konventionellen Menüzeile gibt es nicht weniger als vier Segmente. Das linke und das mittlere enthalten wie bei anderen grafischen KI-Assistenten den Chat-Titel und den Kommunikationsstrang. Rechts daneben zeigt PyGPT den aktiven Betriebsmodus, das verwendete Sprachmodell sowie diverse voreingestellte Parameter an. Unterhalb des mittleren Fensterbereichs findet sich zudem die Eingabezeile für die Texteingaben des Anwenders (Abbildung 11).
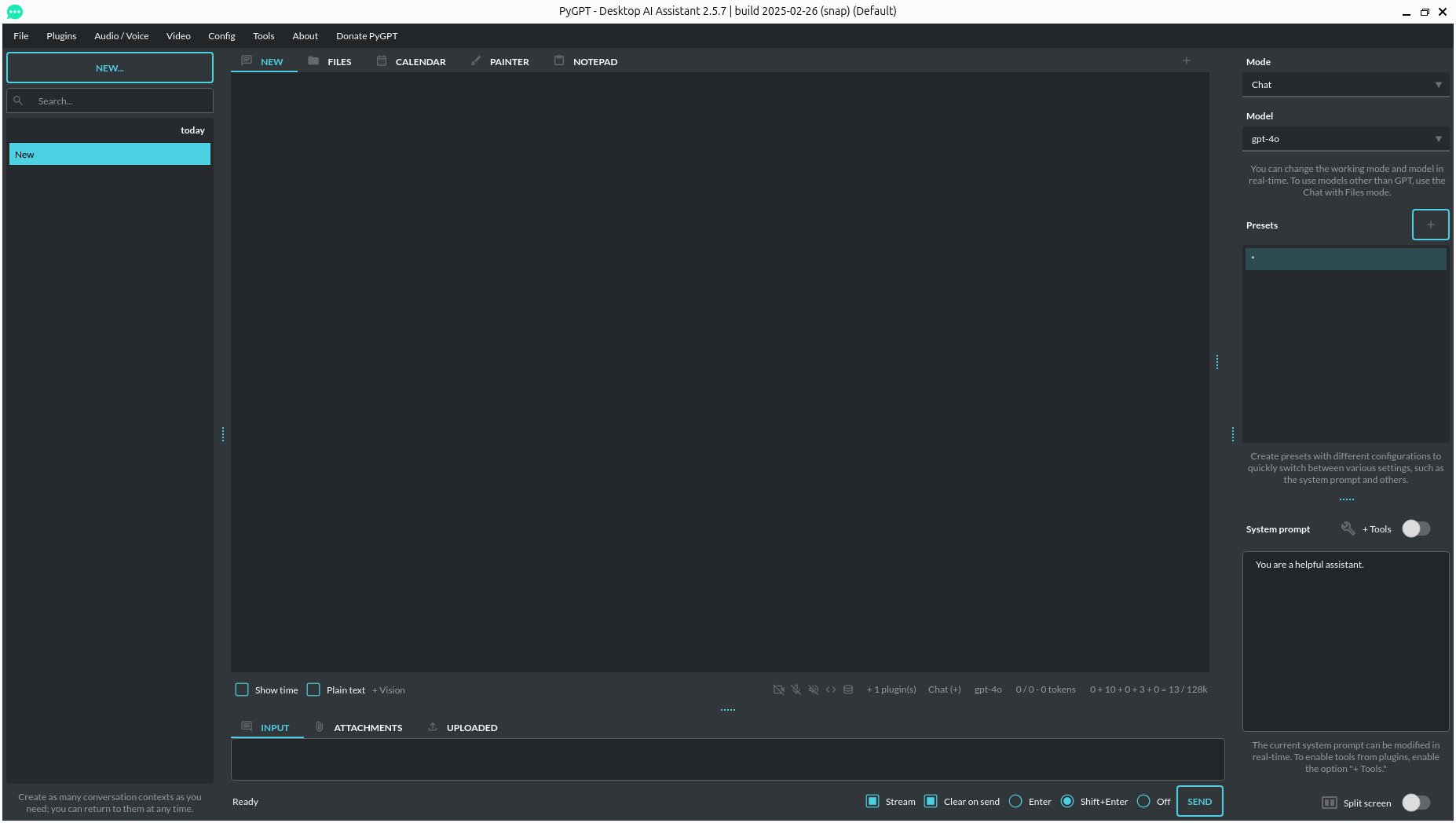
Abbildung 11: PyGPT weist von allen hier vorgestellten Assistenten den größten Funktionsumfang auf.
Konfiguration
Das zunächst in englischer Sprache lokalisierte Programm passen Sie über den Menüpunkt Config | Language an die deutsche Sprache an, indem Sie die Option DE auswählen. Anschließend stellen Sie im Menü Konfiguration | Thema die dunkle Oberfläche auf eine ergonomischere Variante mit hellem Hintergrund um. Zum dauerhaften Speichern der Konfiguration wählen Sie den Punkt Konfiguration speichern im Menü Konfiguration aus.
Anschließend geht es an das Eingeben der für den Cloudzugriff auf die LLMs der verschiedenen Anbieter benötigten API-Schlüssel. Beachten Sie bitte, dass für viele der entsprechenden Konten je nach Abfragevolumen Kosten anfallen. Um die API-Schlüssel für Anbieter wie OpenAI, Google, DeepSeek, Hugging Face oder Anthropic einzugeben, wählen Sie im Menü Konfiguration den ersten Eintrag Einstellungen. Im folgenden Dialogfenster klicken Sie links in den Einstellkategorien auf die Option API-Schlüssel. Danach wählen Sie rechts den gewünschten Anbieter aus und geben den zugehörigen API-Key in das entsprechende Feld ein (Abbildung 12).
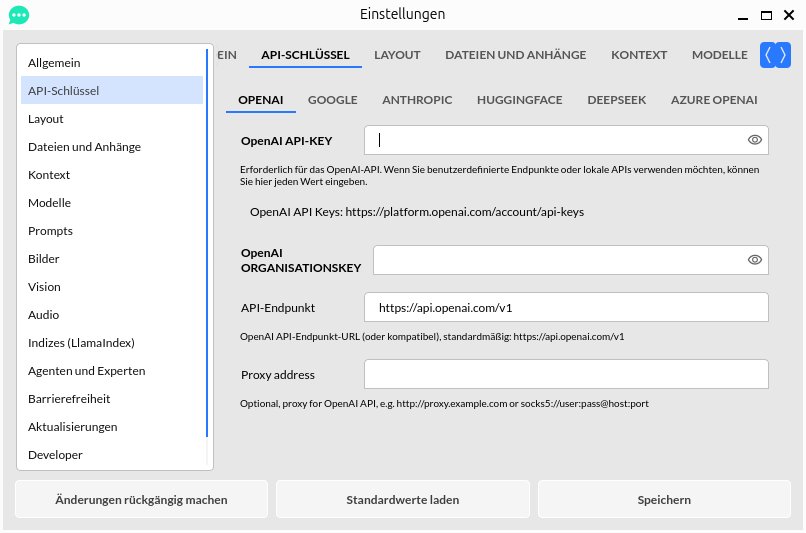
Abbildung 12: Die Felder zur Eingabe der API-Keys sind bei PyGPT gut zu erreichen.
Danach können Sie sofort mit dem Chat beginnen. Als Erstes ersetzen Sie links im Fenster den Titel New durch einen aussagekräftigeren Text, indem Sie ihn rechtsklicken und die Option Umbenennen auswählen. Danach tippen Sie unten in der Eingabezeile Ihre Frage ein. Nach einem Klick auf Senden unterhalb des Eingabebereichs übernimmt PyGPT die Frage in den Kommunikationsstrang und zeigt sie rechts oben in einem grau hinterlegten Kästchen an. Die Antwort erscheint kurz darauf nach links versetzt unterhalb davon, sodass auch bei längeren Konversationen ein guter Überblick über Fragen und Antworten erhalten bleibt (Abbildung 13).
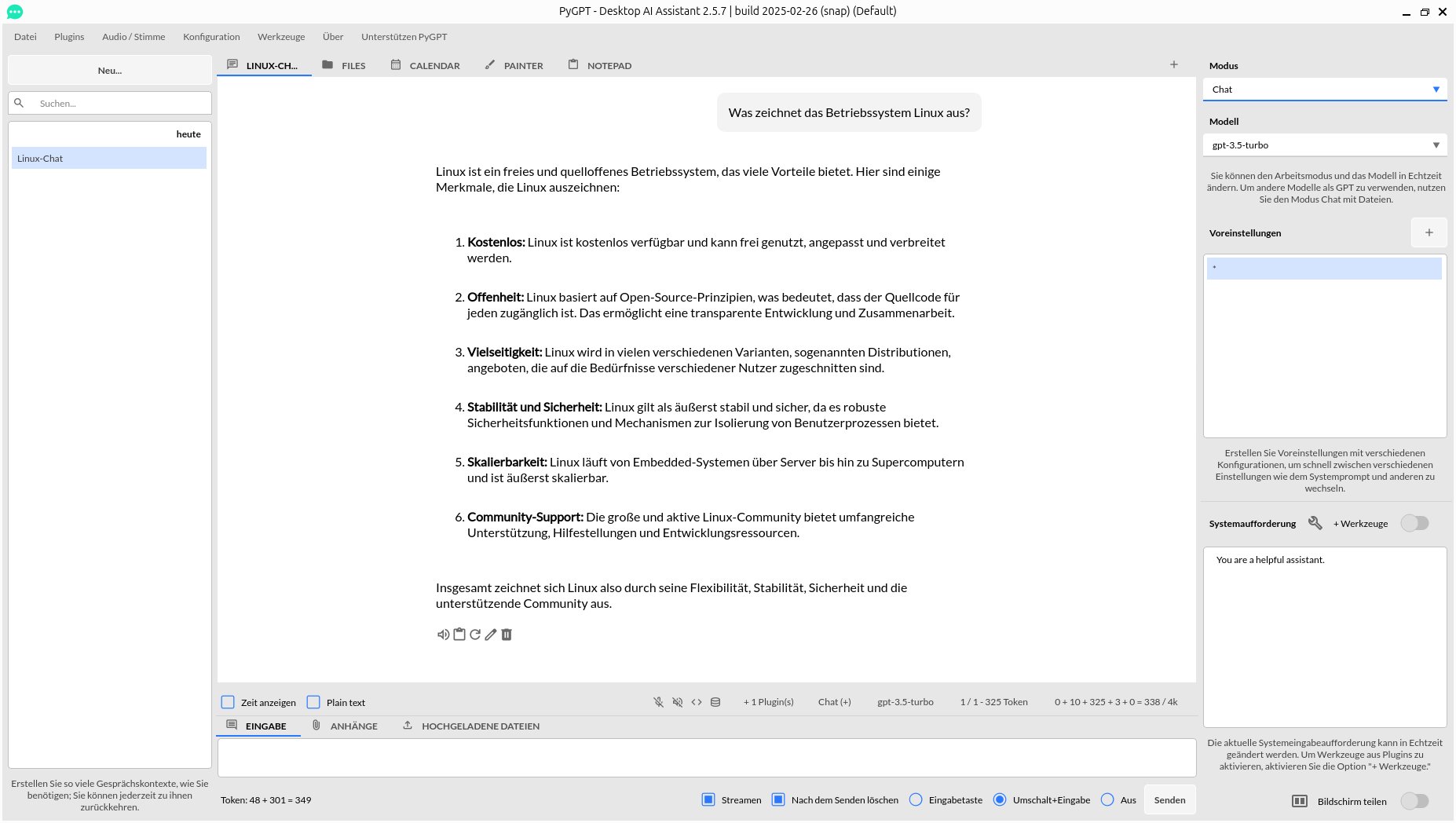
Abbildung 13: Im Kommunikationsstrang stellt PyGPT die Fragen und Antworten gut voneinander abgesetzt dar.
Um ein anderes Sprachmodell einzustellen, klicken Sie im rechten Fenstersegment auf Modell. Daraufhin präsentiert die Anwendung eine Liste zur Auswahl des gewünschten LLMs. Möchten Sie die Darstellung der Dialoge modifizieren, bietet das Menü Konfiguration | Einstellungen | Layout Gelegenheit dazu. Hier wählen Sie bei Bedarf unter anderem andere Schriften und Stile aus.
Modus
PyGPT betätigt sich nicht nur als Chatbot, sondern bietet daneben zahlreiche weitere Betriebsmodi an, mit denen Sie beispielsweise grafische Inhalte KI-gesteuert modifizieren. Zudem ermöglicht die Software Befehlseingaben, mit deren Hilfe Sie das System steuern oder Kommandos ausführen. Den Betriebsmodus ändern Sie im Auswahlfeld Modus oben rechts im Programmfenster. Sowohl die Betriebsart als auch das zugehörige Modell schaltet die Anwendung dabei ohne einen Neustart in Echtzeit um.
Beachten Sie bitte, dass für die Verwendung von audiovisuellen Geräten die entsprechenden Treibermodule geladen sein müssen. Die Dokumentation erklärt ausführlich, wie Sie eine Kamera und ein Mikrofon zur Steuerung in PyGPT einbinden. Die entsprechenden Funktionen zur Sprachsteuerung und Sprachsynthese müssen Sie allerdings erst einschalten. Dazu setzen Sie im Menü Audio/Stimme vor den gewünschten Funktionen einen Haken. Zusätzliche Modelle für erweiterte Betriebsmodi laden Sie bei Bedarf durch Anhaken der jeweiligen Option im Menü Plugins.
Werkzeugkasten
Wie die meisten Konkurrenten gestattet PyGPT, Chat-Verläufe zur Weiterverarbeitung der KI-generierten Inhalte über die Zwischenablage direkt in andere Applikationsprogramme zu kopieren. Das klappt über das Klemmbrettsymbol links in der kleinen Symbolleiste unterhalb des Chat-Verlaufs: Ein Klick darauf kopiert die letzte Antwort in die Zwischenablage.
PyGPT enthält zudem zahlreiche weitere Werkzeuge, die den Umgang mit täglichen Aufgaben KI-gestützt erleichtern. So finden Sie im Menü Werkzeuge einen Terminplaner, einen Bildbetrachter, ein Notizbuch und einen Dateimanager. Auch ein Texteditor, ein Mediaplayer und ein Indexierer sind in das Programm integriert.
Zudem können Sie mithilfe einer Transkribierfunktion Audioinhalte aus Ton- und Videodateien KI-gestützt in Texte umwandeln lassen. Dazu gilt es allerdings, vorab im Menü Plugins in den Einstellungen einen Anbieter auszuwählen. Diese Funktion ist insbesondere dann von Nutzen, wenn Sie beispielsweise für Untertitel in Multimediainhalten Textdokumente generieren wollen. Die Hilfsprogramme starten entweder direkt im Programmfenster oder in einem kleinen überlappenden Dialog.
XCA AI Chat
Das noch sehr junge Projekt XCA AI Chat [6] ist für die Verwendung unter GTK-basierten Oberflächen wie Gnome konzipiert. Die in der eher exotischen Programmiersprache Swift [7] geschriebene Applikation gibt es bislang lediglich als Flatpak, daneben steht auf der Github-Seite des Projekts der Quellcode zum Herunterladen bereit.
Oberfläche
XCA AI Chat öffnet nach dem Start ein übersichtliches Fenster, in dem die Darstellung des Kommunikationsstrangs im Vordergrund steht. Die einzelnen Beiträge stellt es in Kästen eingefasst dar, was eine gute Übersicht ermöglicht. Am unteren Rand des Programmfensters befindet sich die Eingabezeile. XCA AI Chat arbeitet mit sehr vielen unterschiedlichen ChatGPT-Modellen (Abbildung 14). Andere LLMs oder lokal installierte Sprachmodelle lassen sich jedoch nicht einbinden.
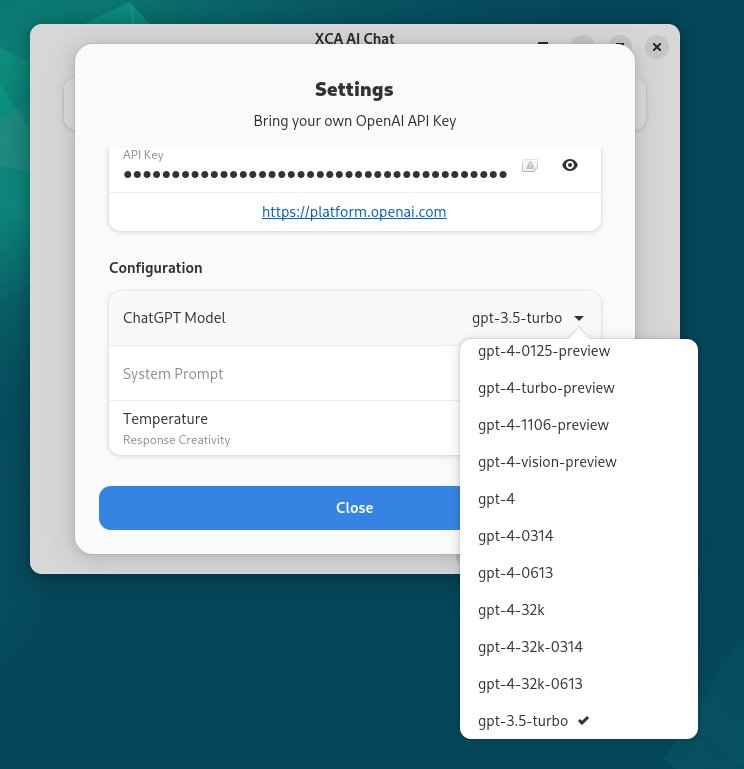
Abbildung 14: XCA AI Chat unterstützt ausschließlich Modelle von OpenAI.
Zur Konfiguration der Anwendung nutzen Sie entweder die Option Preferences im Hamburger-Menü in der Titelleiste oder – noch einfacher – den Werkzeug-Button unten rechts neben der Eingabezeile. Im Einrichtungsdialog geben Sie Ihren API-Schlüssel ein und wählen das gewünschte Sprachmodell aus (Abbildung 15). Außerdem legen Sie das Erscheinungsbild des System-Prompts sowie die Temperature der LLM-Ausgabe fest. Je nach gewähltem Temperaturwert fallen die Aussagen der KI-Maschine fokussierter (höher) oder allgemeiner (niedriger) aus.
Abbildung 15: Das Dialogfenster von XCA AI Chat fällt überaus einfach aus.
Anwendungsbereiche
XCA AI Chat eignet sich aufgrund seines noch recht beschränkten Funktionsumfangs bislang nur zum Bearbeiten einiger Alltagsaufgaben und – bei Verwendung eines entsprechenden Modells – als Programmierhilfe.
Das Programm kann weder Daten exportieren noch LLMs von außerhalb des OpenAI-Universums nutzen. Zudem lassen sich keine Grafiken einbinden, was die Anwendung mehr oder weniger auf die Chatbot-Funktion beschränkt. Besonders schmerzlich fällt das Fehlen von Ollama auf, das als lokale LLM-Lösung ermöglichen würde, KI-Chatbots auch ohne Internetzugang und mit besserem Datenschutz zu nutzen.
|
|
Alpaca |
Bavarder |
Newelle |
PyGPT |
XCA AI Chat |
|---|---|---|---|---|---|
|
Lizenz |
GPLv3 |
GPLv3 |
GPLv3 |
MIT |
MIT |
|
unterstützte Sprachmodelle |
|||||
|
lokale Sprachmodelle |
ja |
ja |
ja |
ja |
nein |
|
eigene Sprachmodelle |
ja |
nein |
nein |
nein |
nein |
|
OpenAI |
nein |
ja |
ja |
ja |
ja |
|
|
nein |
ja |
ja |
ja |
nein |
|
Hugging Face |
nein |
nein |
nein |
ja |
nein |
|
DeepSeek |
nein |
nein |
ja |
ja |
nein |
|
Anwendungsbereiche |
|||||
|
Chat |
ja |
ja |
ja |
ja |
ja |
|
Programmentwicklung |
ja |
ja |
ja |
ja |
eingeschränkt |
|
Bildbearbeitung |
ja |
nein |
nein |
ja |
nein |
|
Befehlsausführung |
nein |
ja |
ja |
ja |
nein |
|
Sonstiges |
|||||
|
Genauigkeit einstellbar |
ja |
nein |
nein |
ja |
ja |
|
Export von Inhalten |
ja |
ja |
eingeschränkt |
ja |
eingeschränkt |
|
Sprachein- und -ausgabe |
nein |
nein |
ja |
ja |
nein |
Fazit
Die Entwicklung von KI-Assistenten für den Linux-Desktop schreitet derzeit rasch voran. Als unangefochtener Platzhirsch platziert sich PyGPT, das für alle nur denkbaren Anwendungsszenarien eine Lösung bereithält, jedoch auch einiger Einarbeitung bedarf.
Suchen Sie ein einfach zu bedienendes, mit unterschiedlichen lokalen LLMs nutzbares Frontend, sind Sie mit Alpaca, Bavarder und Newelle bestens bedient. Alle drei können Abbildungen KI-gestützt bearbeiten und generieren, zudem bieten sie Exportfunktionen für das Weiterverarbeiten von Texten oder Programmcode.
XCA AI Chat dagegen eignet sich bislang ausschließlich für die gepflegte Kommunikation und damit für Desktop-Anwender, die primär von KI-generiertem Wissen und Ideen profitieren wollen. (jlu)
Infos
-
Ollama: https://ollama.com
-
Bavarder: https://github.com/Bavarder/Bavarder
-
Newelle: https://github.com/qwersyk/Newelle
-
PyGPT: https://pygpt.net
-
XCA AI Chat: https://flathub.org/apps/io.github.alfianlosari.GTKChatGPT
-
Swift: https://www.swift.org




