

Die Mozilla Foundation schickt mit Llamafile eine eigene, freie KI-Anwendung ins Rennen. Die Besonderheit: Llamafile läuft lokal und kommt völlig ohne Cloud aus.
Der Hype rund um praktische, anschauliche KI-Anwendungen hat schon unzählige Chatbots hervorgebracht. Dabei decken die momentan bekanntesten Werkzeuge wie OpenAI ChatGPT, Google Bard und Jasper Chat dank einer enormen Datenbasis ein breites Spektrum an Anwendungsszenarien ab.
Aus Sicht von Open-Source-Enthusiasten bringen diese KI-Dienste allerdings ganz gehörige Nachteile mit sich: Sie arbeiten Cloud-basiert, verlangen also einen Zugang ins Internet sowie ein Konto beim Anbieter der KI. Große Dienste gehen zunehmend dazu über, den Zugriff auf ihre KIs und deren API an ein kostenpflichtiges Abo zu knüpfen. Aus datenschutzrechtlicher Sicht erscheint es fragwürdig, alle Anfragen mit den KI-Anbietern teilen zu müssen, und in vielen Fällen jenseits einer rein persönlichen Nutzung lässt sich dieser Umstand grundsätzlich nicht mit der DSGVO vereinbaren.
Es gibt also gute Gründe, eine KI selbst zu hosten. Dank des Projekts Llamafile der Mozilla Foundation, das zahlreiche technische Hürden abbaut, fällt das inzwischen nicht weiter schwer. Hinter Llamafile steckt eine KI-Engine, die ein LLM (Large Language Model) in Form eines einzigen ausführbaren Binärprogramms lokal auf dem eigenen Computer ausführt. Als Beispielanwendung liefert Mozilla einen Chatbot mit Bilderkennung mit, der keinerlei Daten in die Cloud schickt und Bedenken zum Datenschutz damit ausräumt [1].
Von klein bis groß
Llamafile baut auf llama.cpp auf, einer in C++ geschriebenen Schnittstellenbibliothek für viele gebräuchliche LLMs. Die Anwendung läuft auf unterschiedlichsten Prozessorarchitekturen und hält ihre Hardwareanforderungen vergleichsweise bescheiden [2]. Optional kann Llamafile die Rechenleistung vorhandener Nvidia- und AMD-Grafikprozessoren nutzen.
Als freies Sprachmodell dient primär die jeweils aktuellste Version von LLaVA, das die US-Universitäten Columbia sowie Wisconsin-Madison in Zusammenarbeit mit Microsoft pflegen. Darüber hinaus kommt Llamafile auch mit anderen, teils sehr umfangreichen Sprachmodellen zurecht. So gibt es die Software mit dem europäischem Mistral-7B oder mit Aquila und Falcon im Gepäck. Dahinter verbergen sich multimodale Modelle, die neben natürlicher Sprache Bilder analysieren können. Die Releases von Llamafile packen jeweils alles in eine einzige Datei: Modell, statische Binaries (unter Zuhilfenahme von llama.cpp und der Cosmopolitan Libc-Bibliothek [3]) sowie ein Web-Interface.
Der Umfang der einzelnen ausführbaren Llamafile-Dateien liegt je nach Modell zwischen schlanken 2 GByte und stattlichen 37 GByte. Mit dem Standardmodell LLaVA passt Llamafile mit 4,3 GByte auf gängige USB-Sticks [4]. Möchten Sie andere, kompatible Sprachmodelle einbinden, erledigen Sie das mit wenigen Befehlseingaben, wie die Github-Seite zu Llamafile in englischsprachigen Anleitungen zeigt. Das Binary haben die Entwickler mit ihren Bibliotheken plattformübergreifend und für Linux, verschiedene BSD-Derivate, MacOS und Windows ausgelegt.
Sogar der jüngste Raspberry Pi 5 findet mit seiner Prozessor-Architektur ARMv8a+ Unterstützung. Um die Platine nicht zu überfordern, sollten Sie dann aber kleinere Sprachmodelle nutzen, etwa Llamafile mit dem Rocket-3B-Modell, mit TinyLLaMA-1.5B oder dem Phi-2-Modell [5].
Um eines der vorbereiteten Sprachmodelle zu nutzen, laden Sie die entsprechende Datei von der Github-Seite des Projekts herunter und machen sie über das Kommando chmod +x Datei ausführbar. Der Befehl ./Datei ruft Llamafile auf, das seinerseits auf dem Port 8080 einen internen Webserver und zusätzlich gleich den Standard-Webbrowser startet. Die Oberfläche des Chatbots wirkt schlicht, aber intuitiv (Abbildung 1).
Abbildung 1: Die Bedienoberfläche wirkt sehr schlicht, braucht dafür aber keine langen Erklärungen.
Es gibt einige Optionen und im unteren Teil des Fensters ein Freitextfeld. Ein Klick auf Send schickt die Anfrage an die KI und zum verwendeten Modell. Llamafile generiert die Antwort und zeigt sie in einem neuen Fenstersegment an. Je nach der Präzision der Frage und dem Umfang der Antwort liefert das Tool mehrere Absätze. Unter Verwendung des Standardmodells erfolgt die Antwort recht schnell, selbst ohne GPU.
Lost in Translation
Je nach verwendetem Sprachmodell fallen die Antworten unterschiedlich aus. Das LLaVA-Sprachmodell versteht Deutsch. Andere Modelle kommunizieren bislang ausschließlich auf Englisch, halten dabei aber immerhin die Sprache einfach. Genügen Ihre Englischkenntnisse trotzdem nicht zum Verständnis, hilft Ihnen ein Übersetzungswerkzeug weiter.
Hier zeigt sich der Nachteil von statisch erzeugten Sprachmodellen: Nicht jedes Modell kann mit ausreichender Präzision antworten. In unseren Tests fielen die Unterschiede der Modelle und der dazugehörigen Trainingsdaten auf. So beantwortete das Standardsprachmodell LLaVA unsere Testfrage nach unserem Verlag Computec Media GmbH kurz und korrekt. Das Mistral-7B-Sprachmodell verwechselte das Unternehmen aber mit anderen Firmen aus unterschiedlichen Branchen (Abbildung 2) und lieferte sogar abweichende Antworten auf dieselbe Frage.
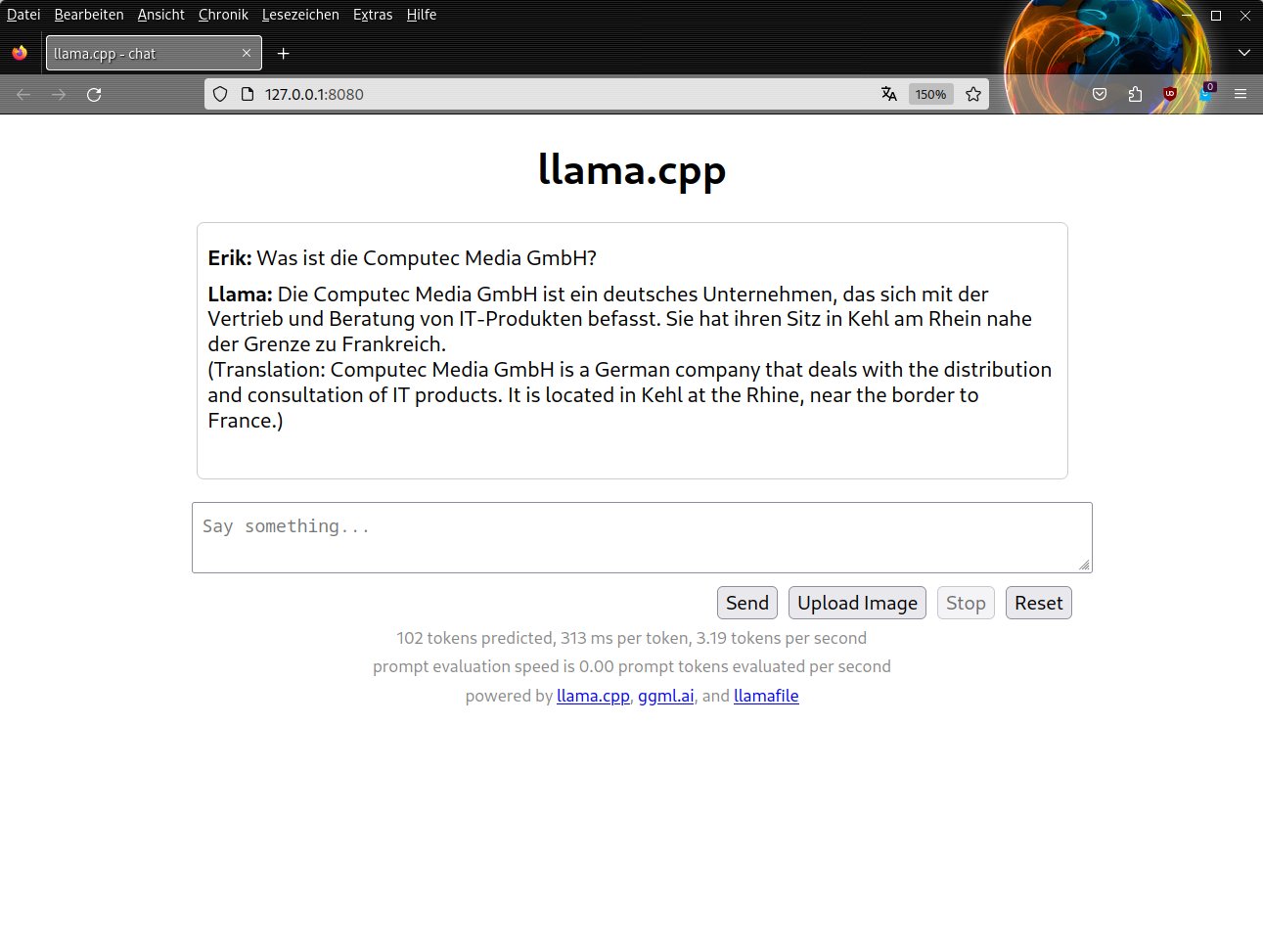
Abbildung 2: Llamafile verfügt mit dem Mistral-7B-Sprachmodell noch nicht über eine ähnlich große Trainingsdatenmenge wie aktuelle Cloud-basierte Chatbots.
Einige Sprachmodelle antworten zweisprachig, andere beschränken sich auf die Ausgangssprache. Sachbezogene Fragen führen zu ausführlicheren Antworten durch die Modelle (Abbildung 3).
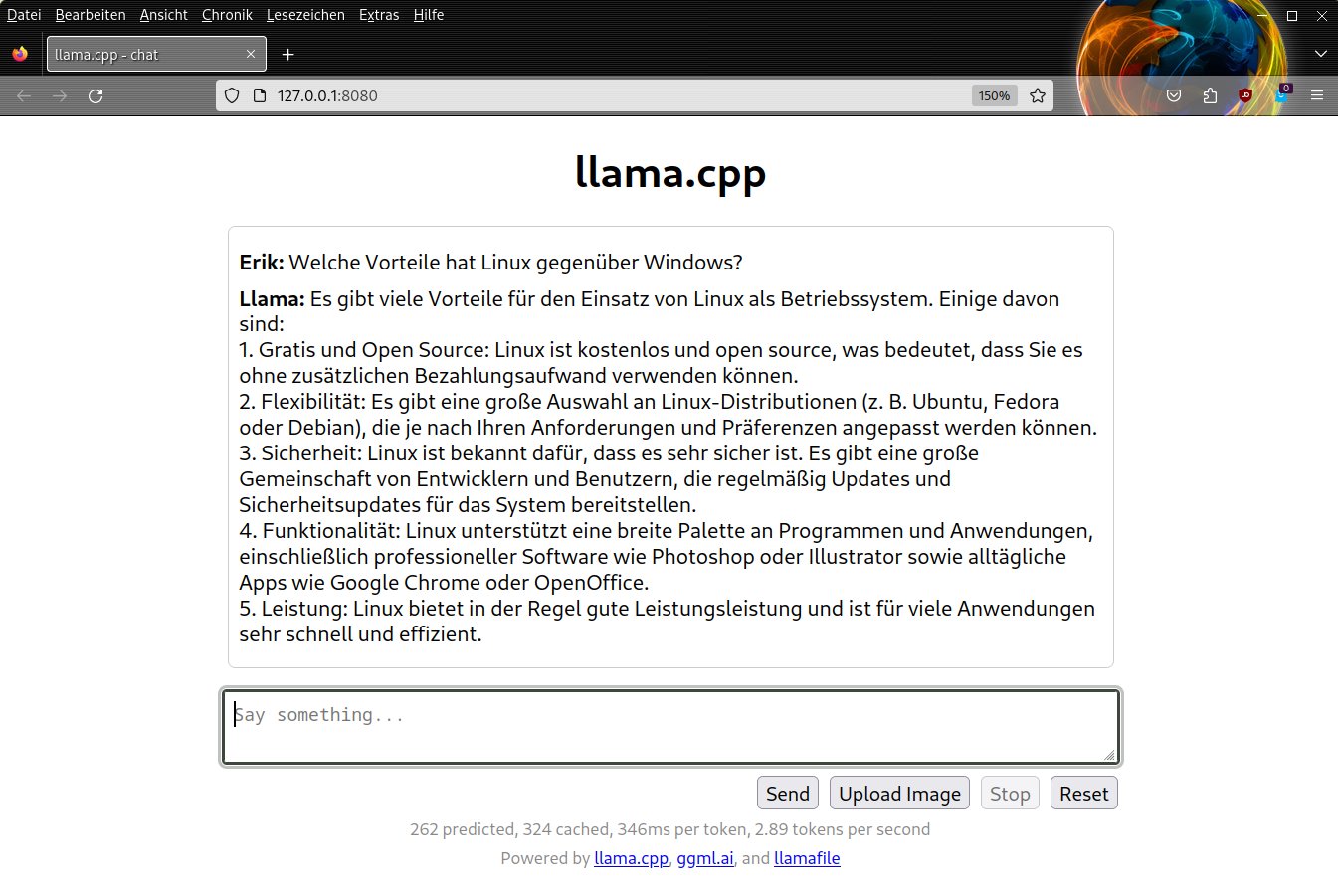
Abbildung 3: Nicht ausufernd, sondern auf das Wesentliche bezogen – so antwortet Llamafile mit dem LLaVA-Sprachmodell.
Sie können auf einem Rechner mehrere Instanzen von Llamafile mit verschiedenen Sprachmodellen ausführen. Dadurch lassen sich mehrere Antworten für dieselbe Frage generieren und vergleichen. Das LLaVA-Sprachmodell fordert gelegentlich dazu auf, die Antworten durch Eingabe weiterer Fragen zu verbessern. Ein Verifizieren hinsichtlich des faktischen Wahrheitsgehalts ist in jedem Fall Pflicht.
Ein Bild sagt mehr
Llamafile eignet sich nicht nur als Chatbot, sondern erkennt auch Bilder und beschreibt deren Inhalt nach den erkannten Objekten und Szenen. Diese Funktion nutzen Sie, indem Sie in der Eingangsoberfläche unten rechts auf Upload Image klicken und die gewünschte Bilddatei auf dem lokalen Datenträger auswählen. Der Schalter Öffnen übernimmt zunächst die Abbildung, woraufhin Llamafile ein Eingabefeld für Fragen zum Bild anzeigt. Eine übermittelte Frage öffnet wieder das Dialogfenster des Chatbots. Neben der Frage und der generierte Antwort zeigt es oben links ein Thumbnail des Bilds an (Abbildung 4).
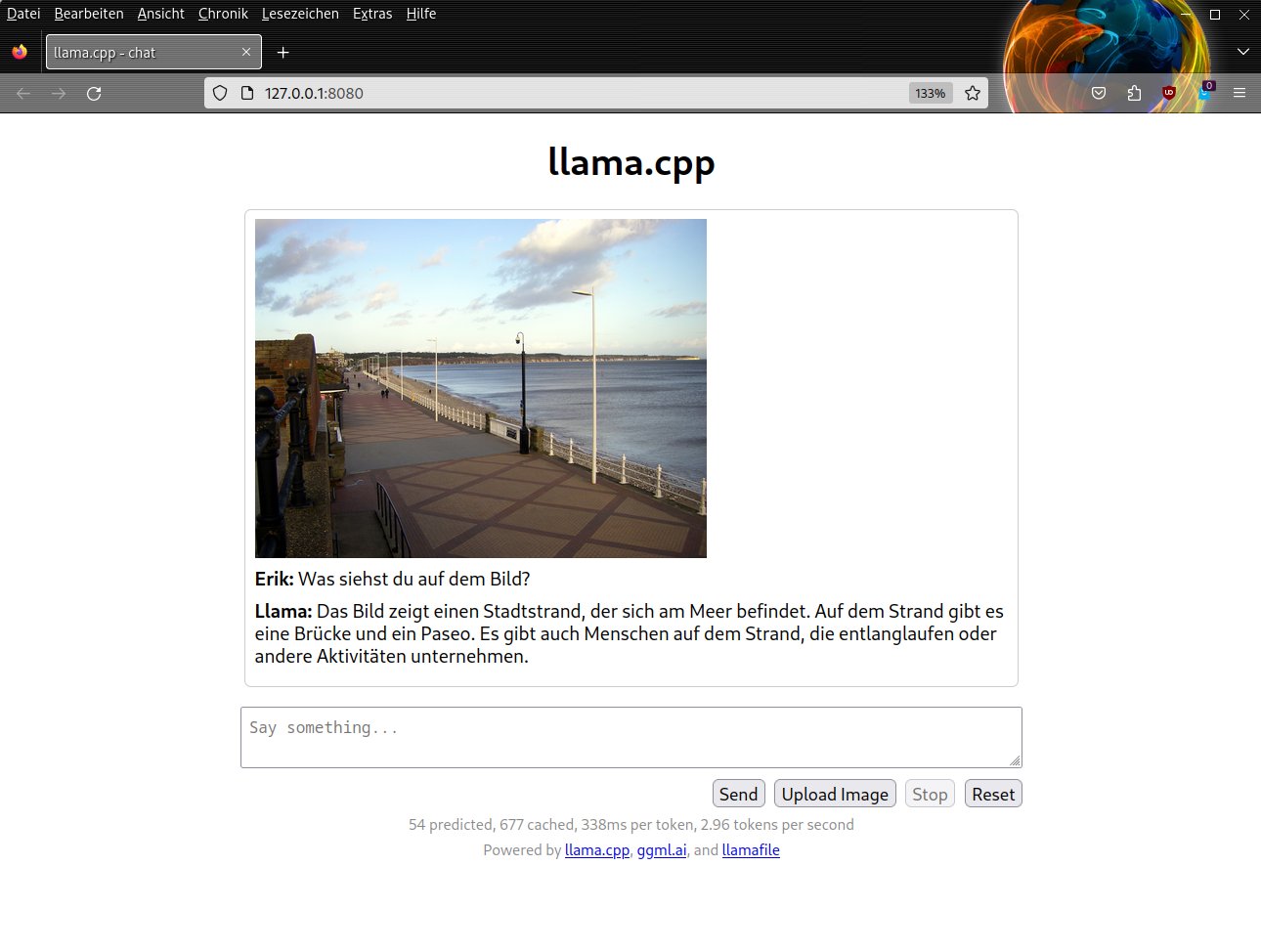
Abbildung 4: Auch Bildbeschreibungen stellen Llamafile nicht vor unlösbare Probleme.
Die Fragen zur Bildanalyse, etwa wo sich ein markantes Gebäude befindet, verlangt schon deutlich mehr Rechenleistung, wie unsere Tests zeigen. Auf gewöhnlicher PC-Hardware ohne rechenstarke GPU ist dann durchaus etwas Geduld gefragt. Mit dem Standardmodell dürfen Sie bei der Bilderkennung jedoch dennoch keine detailversessenen Beschreibungen erwarten. Dazu eignet sich das weitaus umfangreichere Mistral-7B-Modell besser.
Fazit: Kompakte KI
Llamafile erfüllt tatsächlich den Anspruch, mit wenig Hardwareressourcen arbeiten zu können. Auf Rechnern ohne leistungsfähige Grafikkarte von Nvidia oder AMD lastet es die CPU-Kerne beim Generieren von Antworten allerdings voll aus. Ab Vierkern-CPUs arbeitet Llamafile in Kombination mit dem Standardmodell angenehm flott. Sie sollten aber darauf achten, reichlich Arbeitsspeicher zur Verfügung zu haben: Mindestens 8 GByte erweisen sich dabei als ein sinnvolles Minimum (Abbildung 5).
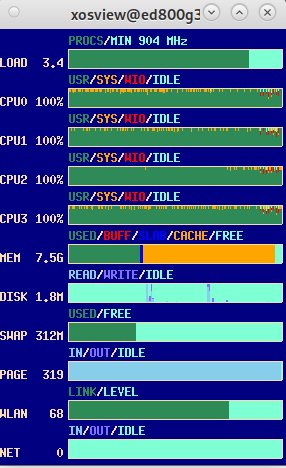
Abbildung 5: Llamafile lastet bei der Generierung seiner Antworten CPU und Arbeitsspeicher weitgehend aus.
Mit Llamafile hat die Mozilla Foundation eine handliche KI-Engine geschaffen, die ganz ohne Cloud brauchbare Ergebnisse liefert, was dem Datenschutz zugutekommt. Dank der statischen, plattformübergreifende Binaries lässt sich das Tool unter Linux einfach installieren, dasselbe gilt für andere Betriebssysteme.
Das noch junge Projekt kann mit den stetig verbesserten, freien Sprachmodellen sicherlich noch erheblich dazulernen. Den universellen, gängigen Chatbots von OpenAI, Microsoft und Google kann Llamafile zwar noch nicht das Wasser reichen, bietet aber mit den größeren zur Verfügung stehenden Sprachmodellen eine bemerkenswerte Alternative. (dwo)
Infos
-
Projektbeschreibung: https://future.mozilla.org/news/introducing-llamafile/
-
Llama.cpp: https://github.com/ggerganov/llama.cpp
-
Cosmopolitan Libc: https://justine.lol/cosmopolitan/
-
Llamafile: https://github.com/Mozilla-Ocho/llamafile
-
RasPi-5-Support: https://hacks.mozilla.org/2024/04/llamafiles-progress-four-months-in/





