

Fällt ein Shell-Skript komplexer aus, lohnt sich ein genauer Blick auf die Abläufe: Oft findet sich noch Optimierungspotenzial.
Shell-Skripte bestehen im Wesentlichen aus einer Aneinanderreihung von auszuführenden Befehlen und Verzweigungen. Listing 1 zeigt als typisches Beispiel ein Skript namens frage.sh.
Der interessante Aspekt daran: Im Code finden sich alle grundlegenden Komponenten eines Shell-Skripts. Er enthält Schlüsselwörter (Keywords) wie if, then, else und fi, in die Shell integrierte Kommandos (Built-ins) wie echo und read, die eckige Klammer und zu guter Letzt externe Kommandos (/bin/echo).
Listing 1
#!/bin/bash echo "Eigene Prozess ID: $$" echo -n "Sind Sie Administrator? " read answer if [ "$answer" = "J" -o "$answer" = "j" ]; then echo "Sie sind ein Administrator." else /bin/echo "Sie sind kein Administrator." fi
Tatsächlich verhalten sich die Aufrufe echo und /bin/echo unterschiedlich, obwohl sie zu gleichen Resultaten führen. Um den Unterschied zu sehen, rufen Sie das Skript zwei Mal auf, während Sie die Shell mit dem Kommando strace überwachen.
Listing 2 zeigt den ersten Durchlauf, Listing 3 die zugehörige Ausgabe durch Strace. Zu Beginn erzeugt das System einen neuen Shell-Prozess mit der PID 2489, der für das Abarbeiten des Skripts zuständig ist. Beantworten Sie die gestellte Frage mit j, erscheint die passende Ausgabe, und das Skript terminiert (Listing 3, letzte Zeile).
Listing 2
# ./frage.sh Eigene Prozess ID: 2489 Sind Sie Administrator? j Sie sind ein Administrator.
Listing 3
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,child_tidptr=0x7fa8fc515e50) = 2489
strace: Process 2489 attached
[pid 2489] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=2489, si_uid=0,si_status=0, si_utime=0, si_stime=0} ---
Nun rufen Sie das Skript ein zweites Mal auf und beantworten die Frage mit n (Listing 4). Die Verzweigung veranlasst nun den Aufruf des externen Kommandos /bin/echo. Strace zeigt nun eine völlig andere Ausgabe (Listing 5). Darin sehen Sie, dass zu Beginn ebenfalls ein neuer Shell-Prozess startet (PID 2510). Diesmal entsteht darüber hinaus aber noch ein weiterer Prozess mit der PID 2511: Hier handelt es sich um die PID des Kommandos /bin/echo.
Listing 4
# ./frage.sh Eigene Prozess ID: 2510 Sind Sie Administrator? n Sie sind kein Administrator
Listing 5
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,child_tidptr=0x7fa8fc515e50) = 2510
strace: Process 2510 attached
[pid 2510] clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7fbce6ffee50) = 2511
strace: Process 2511 attached
[pid 2511] +++ exited with 0 +++
[pid 2510] --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=2511,si_uid=0, si_status=0, si_utime=0, si_stime=0} ---
[pid 2510] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=2510, si_uid=0,si_status=0, si_utime=0, si_stime=0} ---
Wenn ein Skript externe Kommandos aufruft, erzeugt die Shell also einen neuen Prozess, wohingegen der Einsatz der in die Shell eingebauten Kommandos wie echo keinen zusätzlichen Prozess erfordert.
Abbildung 1 zeigt eine schematische Darstellung der beiden Beispiele. Die Grafik erhebt keinerlei Anspruch auf Vollständigkeit, sondern soll nur vermitteln, wie sich die beiden Aufrufvarianten verhalten.

Abbildung 1: Links ist der Aufruf des Shell-Built-ins echo skizziert, während im Ablauf auf der rechten Seite die Ausgabe mithilfe des Kommandos /bin/echo erfolgt.
Unterprozesse
Die Shell dient als interaktive Schnittstelle zwischen Benutzer und Betriebssystem. Als solche hat sie unter anderem die Aufgabe, von Ihnen eingegebene Kommandos aufzurufen und deren Rückgabewerte in Umgebungsvariablen zu speichern.
Nun handelt es sich bei den meisten der aufzurufenden Kommandos um eigene kleine Programme. Jedes davon benötigt einen eigenen Adressraum, eigene Register und weitere Ressourcen. Unix-artige Betriebssysteme regeln das wie folgt: Sie erzeugen mithilfe des Systemaufrufs fork() (unter Linux clone()) eine Kopie des aufrufenden Prozesses. Innerhalb dieser Kopie starten sie dann mit dem Systemaufruf exec*() das eigentliche Zielprogramm, das damit den kopierten Prozess ersetzt.
In folgenden Fällen erzeugt die Shell mindestens einen weiteren Unterprozess: bei Aufruf eines externen Kommandos, bei der Substitution von Kommandos sowie beim Einsatz anonymer Pipes. Das Verwenden von Funktionen, die in die Shell integriert sind, erzeugt hingegen keine Unterprozesse. Das gilt für die bereits erwähnten Shell-Keywords sowie Built-ins.
Wie bereits erwähnt, generiert die Shell für jedes externe Kommando, jede Prozesskommunikation durch anonyme Pipes und jede Kommandosubstitution weitere Prozesse im Hintergrund. Bei einem Kommando leuchtet das noch ein. Warum gilt dasselbe aber beim Einsatz von Pipes oder der Substitution von Kommandos?
Anonyme Pipes erzeugen Sie durch das Symbol | innerhalb einer Kette von Kommandos. Sie heißen anonym, weil sie im Normalfall für den Benutzer nicht zu sehen sind – das System baut sie auf und löscht sie nach dem Bearbeiten der Daten wieder.
Ein Prozess unter Unix hat normalerweise drei Kanäle: STDIN (Kanal 0), STDOUT (Kanal 1) und STDERR (Kanal 2). Aus STDIN liest die Pipe normalerweise die Daten ein, nach STDOUT gibt sie sie aus. Fehlermeldungen landen in STDERR.
Arbeiten Sie mit anonymen Pipes, so lenkt der erste Prozess seine Ausgabe statt nach STDOUT nach STDIN jenes Prozesses um, der dem Pipe-Symbol folgt. In Listing 6 dient die Ausgabe von ls beispielsweise als Eingabe des Kommandos wc. Die Ausgabe von wc wiederum landet schließlich in der Standardausgabe.
Listing 6
$ ls -l | wc -l
282
Aus einer Pipe dürfen Sie nur lesen, während ein Prozess Daten hineinschreibt. Das erklärt, warum eine anonyme Pipe Unterprozesse erzeugt: Das Kommando wc liest so lange aus der Pipe, wie das Kommando ls in diese hineinschreibt.
Bei der Kommandosubstitution in Listing 7 kommen ebenfalls anonyme Pipes zum Einsatz. In diesem Fall öffnet die Shell einen zusätzlichen Kanal, der zum Lesen von Daten dient – wenn möglich, Kanal 3. Darüber landet die Ausgabe des verketteten Kommandos in der Variablen filecount.
Listing 7
# filecount=$(ls | wc -l) # echo $filecount 28
Skript-Tuning
Die wahrscheinlich wichtigste Regel für schnelle Skripte ist es, unnötige Unterprozesse zu vermeiden. Im Folgenden sollen einige Beispiele die Auswirkungen zu langer Pipelines und Kommandosubstitutionen verdeutlichen. Das Setup dafür umfasst 100 000 Dateien in einem Ordner, von denen einige in einer Zeile die Zeichenkette 50 enthalten.
Im ersten Beispiel (Listing 8) wertet eine Schleife jede Datei aus. Dazu gibt das Skript jede Datei mit dem Befehl cat aus und lenkt die Ausgabe in das Kommando grep um. Das sucht nach Zeilen, die den String 50 enthalten – die Zeichenkette muss also genau zwei Zeichen lang sein, mit einer 5 beginnen und mit einer 0 aufhören.
Die Ausgabe von Grep dient wiederum als Eingabe des Kommandos wc, das die gefundenen Zeilen zählt. Die Ausgabe von Wc landet in der Variablen gefunden. Nimmt diese den Wert 1 an, gibt das Skript den Dateinamen aus. Die Tabelle “Zeitmessung Grep” zeigt das Ergebnis für dieses sowie für drei weitere Varianten, jeweils über den Befehl time ermittelt.
Listing 8
#!/bin/bash
# Beispiel 1
for file in *; do
gefunden=$(cat $file|grep "^50$"|wc -l)
if [ $gefunden -ge 1 ]; then
echo $file
fi
done >anzahl_dateien_1.out
|
Kategorie |
Eingabe |
|||
|---|---|---|---|---|
|
|
3m52.327s |
2m36.079s |
1m2.970s |
0m0.372s |
|
|
3m11.611s |
1m40.114s |
0m46.838s |
0m0.083s |
|
|
0m30.046s |
0m49.343s |
0m13.408s |
0m0.264s |
Listing 9 zeigt in etwa denselben Ansatz, doch speichert dieses Skript die Ausgabe nicht in einer Variablen und ermittelt auch nicht die Anzahl Zeilen, die pro Datei aus genau der Zeichenkette 50 bestehen. Da es damit weniger Unterprozesse erfordert, läuft das modifizierte Skript in etwa 60 Prozent der ursprünglichen Ausführungszeit durch (siehe Tabelle “Zeitmessung Grep”, Spalte 3).
Listing 9
#!/bin/bash
# Beispiel 2
for file in *; do
cat $file|grep -q "^50$"
if [ $? -eq 0 ]; then
echo $file
fi
done >anzahl_dateien_2.out
Im nächsten Schritt verringert sich die Anzahl der aufzurufenden Prozesse nochmals, da das Kommando grep selbst die Datei öffnet und nach der gewünschten Zeile sucht. Dann fragt das Skript den Rückgabewert ab und gibt den Dateinamen aus, falls eine passende Zeile existiert (Listing 10). Das Skript benötigt nun nur noch knapp 30 Prozent der ursprünglichen Zeit, um alle Dateien zu untersuchen.
Listing 10
#!/bin/bash # Beispiel 3 for file in *; do grep -q "^50$" $file if [ $? -eq 0 ]; then echo $file fi done >anzahl_dateien_3.out
Es geht aber noch erheblich schneller. Das Kommando grep hat einen Parameter, über den es im Fall eines Treffers den Dateinamen ausgibt, statt aller Zeilen einer Datei, die die zu suchende Zeichenkette enthalten. Es genügt also ein einziger Aufruf des Kommandos, um alle Dateien zu prüfen und die Namen der Dateien auszugeben (Listing 11).
Listing 11
# time grep -l "^50$" * >anzahl_dateien_4.out
Die Ausführungszeit verringert sich gegenüber dem ursprünglichen Skript aus Listing 8 auf ein Sechshundertstel. Der enorme Zuwachs an Geschwindigkeit beruht auf der Tatsache, dass die Shell nur noch ein Mal einen Unterprozess für das Kommando grep erzeugt. Abbildung 2 skizziert grob, wie sich die einzelnen Varianten der Skripte unterscheiden.
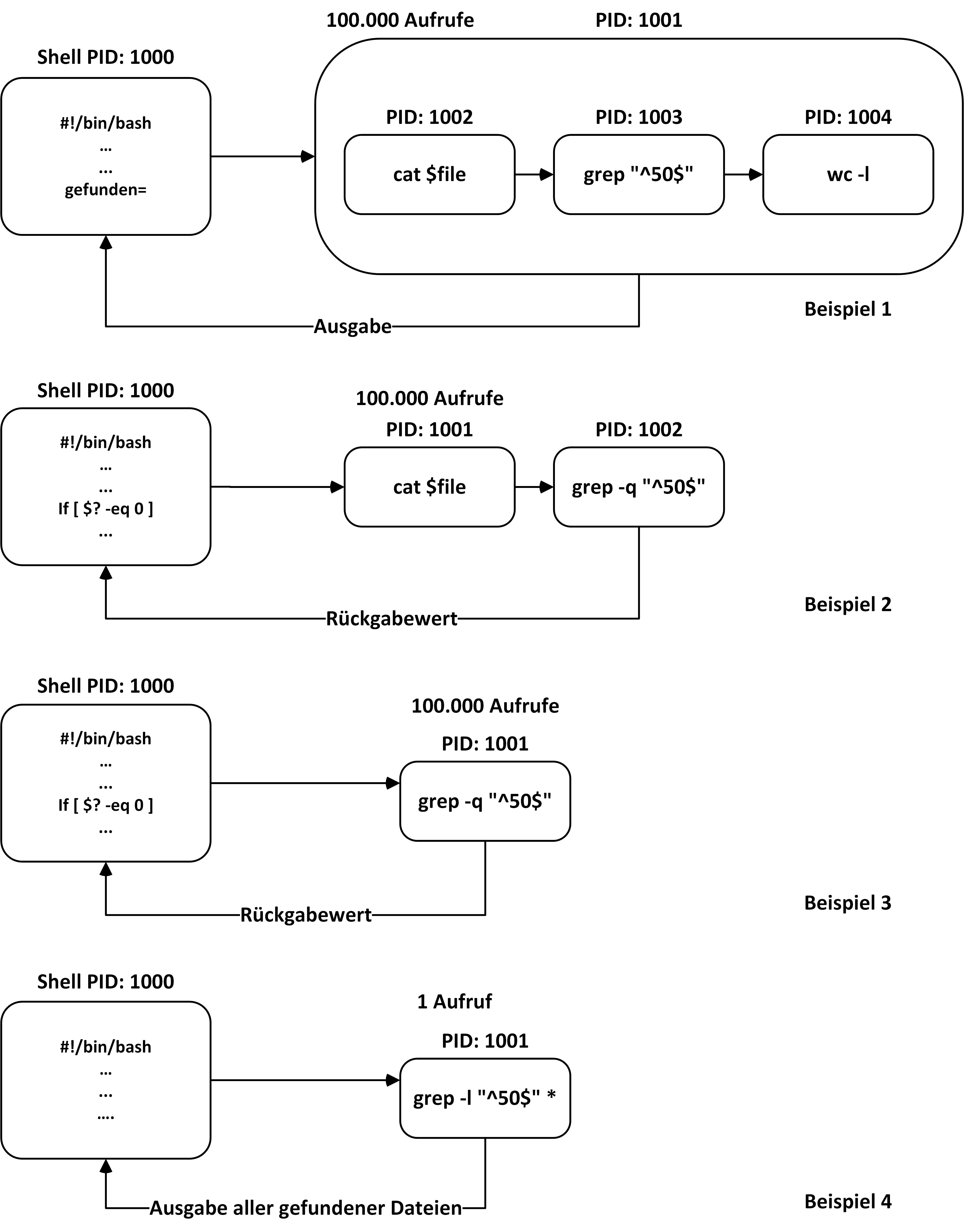
Abbildung 2: Durch die unterschiedlichen Kommandoketten benötigen die Varianten für dieselbe Aktion eine unterschiedliche Anzahl von Unterprozessen.
Im ersten Beispiel erfordert das Durchlaufen von 100 000 Dateien jeweils vier Unterprozesse, also insgesamt 400 000. Beim zweiten Beispiel genügen zwei Unterprozesse je Datei, also insgesamt 200 000. Im dritten Beispiel halbiert sich dieser Wert erneut, es entstehen nur noch 100 000 Unterprozesse. Auf der Kommandozeile erledigt dagegen ein einziger zusätzlicher Prozess den Job.
Beobachten Sie die Skripte zur Laufzeit mittels Strace, und protokollieren Sie dabei die Systemaufrufe zum Erzeugen von neuen Prozessen. Eine Überprüfung mittels Grep nach dem Schlüsselwort clone bestätigt die oben genannten Werte. Um sicherzustellen, dass alle Varianten zum selben Ergebnis führen, vergleichen Sie bei Bedarf die Ausgabe des ersten Beispiels mit allen weiteren Ausgaben – es sollte kein Unterschied auftreten.
Möglichkeiten ausschöpfen
Viele Wege führen nach Rom. Jedoch gibt es Wege, die Sie schneller ans gewünschte Ziel bringen. Um möglichst viel Geschwindigkeit aus Skripten herauszuholen, sollten Sie den eingesetzten Kommandos so viel an Aufgaben übertragen wie möglich.
Ein Beispiel: Sie möchten aus einer Datei jede dritte Zeile ausdrucken. Die simpelste Möglichkeit besteht darin, mit tail alle Zeilen ab der gewünschten Stelle auszugeben und diese Ausgabe in das Kommando head umzulenken, das wiederum aus den eingelesenen Zeilen nur die erste Zeile ausgibt.
Es liegt auf der Hand, dass diese Lösung langsam ist. Daher lohnt es, direkt zu einer vielversprechenderen Möglichkeit überzugehen: einer Schleife mit einem inkrementierten Laufindex (Listing 12). Weist der Index bei einer Division durch 3 einen Restwert von 0 auf (Modulo), gibt das Skript diese Zeile mithilfe des Kommandos sed aus. Für eine Textdatei mit 10 000 Zeilen dauerte das Durchsuchen und Ausgeben knapp 3,5 Sekunden (siehe Tabelle “Zeitmessung Sed”).
Listing 12
#!/bin/bash typeset -i i=1 while [[ $i -le 10000 ]]; do if (($i % 3 == 0)); then # Laufindex modulo 3 sed -n "$i p" textdatei fi ((i++)) done
|
Kategorie |
||
|---|---|---|
|
|
0m3.474s |
0m0.026s |
|
|
0m2.591s |
0m0.006s |
|
|
0m0.438s |
0m0.004s |
Eine wesentlich schnellere Variante erhalten Sie, indem Sie mittels Awk die Datei einlesen und innerhalb des Tools jede dritte Zeile ermitteln. Dafür bietet sich die interne Variable NR an, die die Software für jeden eingelesenen Datensatz (üblicherweise eine Zeile) inkrementiert (Listing 13). Hier liegt die Ausführungsgeschwindigkeit um ein Vielfaches höher, da die gesamte Auswertung innerhalb eines Kommandos stattfindet.
Listing 13
#!/bin/bash
awk '{
if ((NR % 3 == 0))
# Index modulo 3
print $0
}' textdatei
Rechnen
Wollen Sie die Summe aus Zahlen bilden, die eine Textdatei enthält, gibt es wieder verschiedene Wege. Im Beispiel aus Listing 14 ist jede Zeile interessant, die den String fuenfzigste enthält. Das Skript wertet eine Datei aus, die eine Millionen Zeilen enthält. Jede fünfzigste Zeile enthält dabei die fragliche Zeichenkette.
Listing 14
#!/bin/bash typeset -i sum=0 while read line; do set $line # Feld 6 wird aufsummiert sum=$((sum+$6)) # Ausgabe von grep einlesen done < <(grep " fuenfzigste " largefile) echo "Summe: $sum"
Auch hier bietet sich etwa Awk als Werkzeug zum schnellen Aufsummieren an (Listing 15). Aber das lässt sich noch optimieren: Awk arbeitet nicht direkt in Maschinensprache. Aus diesem Grund lohnt es sich, das Suchen der Zeichenkette dem Kommando grep zu übergeben und die gefundenen Zeilen dann mittels Awk zu addieren (Listing 16).
Listing 15
# time awk '/ fuenfzigste / {sum += $6} END {print "Summe:", sum}' largefile
Listing 16
# time awk '{sum += $6} END {print "Summe:", sum}' < <(grep " fuenfzigste " largefile)
|
Kategorie |
|||
|---|---|---|---|
|
|
0m4.471s |
0m1.408s |
0m0.231s |
|
|
0m2.374s |
0m1.348s |
0m0.050s |
|
|
0m1.956s |
0m0.013s |
0m0.010s |
Auch in diesem Beispiel brachte die Optimierung eine deutliche Beschleunigung. Die Variante aus Listing 15 reduziert die Laufzeit auf rund ein Drittel, die aus Listing 16 läuft zwanzig Mal schneller als die erste (siehe Tabelle “Zeitmessung Awk”).
Fazit
Die Beispiele zeigen, dass Sie durch geschickten Einsatz von Multifunktionswerkzeugen wie Awk, Python oder Perl sowie das weitgehende Vermeiden komplexer Konstrukte mit Tr, Sed oder Grep die Geschwindigkeiten von Skripten teils drastisch erhöhen: Sie vermeiden damit konsequent viele Kontextwechsel.
Allerdings schadet keineswegs jede anonyme Pipe dem Durchsatz, wie gerade das letzte Beispiel zeigt. Vielmehr gilt es, die Stärken der jeweiligen Werkzeuge zu nutzen und die Anzahl an zu erzeugenden Unterprozessen so gering wie möglich zu halten.
Abschließend sei noch darauf hingewiesen, dass auch die Lesbarkeit und damit die Wartbarkeit der Skripte sich verbessert, wenn Sie auf komplexe Ketten aus Kommandos verzichten. (agr/jlu)
Glossar
-
PID
-
Process Identifier oder kurz Process ID. Ein einzigartiger Schlüssel zur eindeutigen Identifikation von Prozessen. Die vom Betriebssystem vergebene PID ändert sich während der Laufzeit des Prozesses nicht.




