

Wer seine Dateien nach festgelegten Kriterien benennt, der spart beim Suchen nach wichtigen Dokumenten oder Bildern Zeit und Nerven.
Wohl jeder Anwender hatte schon einmal das Problem, fein säuberlich auf dem eigenen Rechner abgelegte Daten nicht mehr finden zu können. Das Navigieren durch die zahllosen Verzeichnisse führt nicht zum Ziel, weil das Gesuchte möglicherweise an verschiedenen Stellen liegt und man sich deshalb in den Ordnerhierarchien verirrt.
Eine Volltextsuche verspricht da Abhilfe, erfordert aber meist zusätzliche Ressourcen – und das oft nicht zu knapp. Zudem geht trotz einer ausgefeilten Volltextsuche das gewünschte Dokument möglicherweise in der Fülle der Ergebnisse unter, wenn die Schlagworte zu weit gefasst sind.
Viele Untersuchungen belegen, dass mehr oder weniger alle Computeranwender diese Situation schon erlebt haben. Das liegt oft weder an mangelnder Erinnerungsfähigkeit oder fehlendem Computerwissen, sondern vielmehr am Design der modernen Umgebungen: sie erfordern es allzu oft, dass der Nutzer sich an den Computer anpasst statt der Rechner an die Situation.
Die Grundlagen des “modernen” Dateimanagements legten Entwickler Mitte des vorigen Jahrhunderts. Trotzdem folgen auch heutige Systeme weitgehend nach denselben Prämissen. Um das Verwalten von ein paar Dutzend oder bestenfalls ein paar Hundert Dateien zu erleichtern, entstand das Konzept von verschachtelten Verzeichnissen, die mit dem Aufkommen der Desktop-Metapher [1] dann “Folder” hießen. Der Begriff steht im Englischen für Mappe, Aktendeckel oder Ordner.
Auf der Ebene des Dateisystems lautet der Konzeptbegriff nach wie vor “Verzeichnis”, wohingegen sich “Ordner” als Konzept eher auf die Ebene der grafischen Oberflächen bezieht. Äquivalent dazu ist “Datei” ein Konzeptbegriff auf Dateisystemebene, während der Begriff “Dokument” vermehrt auf der Benutzeroberfläche zum Einsatz kommt.
Ständig steigende Zahlen an verlorenen Informationen in Kombination mit der massiv zunehmenden Anzahl von Dateien pro Benutzer verlangen nach einer grundlegend neuen Denkweise beim Verwalten von Dateien. Die Forschung im Umfeld des Personal Information Management hat seit drei Jahrzehnten sehr gute Verbesserungen mit entsprechenden Prototypen erzielt. Jedoch fanden davon so gut wie gar keine Erkenntnisse daraus Einfluss in die Computersysteme, wie wir sie heute benutzen (siehe Kasten “Nur in der Forschung”).
Nach wie vor wiegt Rückwärtskompatibilität schwerer als fortschrittliche Konzepte. Mangelhafte Schulbildung im Bereich PIM einerseits und fehlendes Problembewusstsein bei der Mehrheit der Benutzer andererseits verschlechtern die Situation darüber hinaus.
Forschungsergebnisse wie etwa jene aus dem Tagstore-Projekt [2] zeigen, dass selbst kleine, schrittweise Verbesserungen aktueller EDV-Umgebungen viel Potenzial bergen. Dieser Artikel beschreibt ein in der Praxis erprobtes Konzept, das aus den Erkenntnissen mit der Arbeit an Tagstore entstand und das Sie als interessierter Anwender sofort einsetzen könnten.
Es besteht aus einer Sammlung an freien Python-Skripten. Sie stellen in Kombination ein paar Methoden bereit, die bereits verfügbare Informationen ergänzen. Die vorgestellte Methode funktioniert selbst im Kleinen, auch wenn Sie lediglich Teile davon verwenden. Wir zeigen, wie die Teile zusammenwirken.
Nur in der Forschung
In den letzten Jahrzehnten hat sich beim Verwalten von Dateien mit Ausnahme der inzwischen etablierten lokalen Suchmaschinen kaum etwas Grundlegendes getan. Geht es um Daten auf dem eigenen Computer oder im lokalen Netzwerk, bevorzugen die Benutzer nach wie vor die Navigation im Dateimanager und verwenden nur sehr selten lokale Suchmaschinen.Im Gegensatz dazu hat sich die in den 1980ern entstandene Forschungsdisziplin Personal Information Management (PIM) in den letzten beiden Jahrzehnten hauptsächlich mit der Suche beschäftigt, weniger mit der Navigation.
Dabei gibt es enormen Bedarf an Forschung und an neuen Konzepten. Seit vielen Jahrzehnten weiß die Wissenschaft, dass das Verwalten von Dateien in strikten Hierarchien von Verzeichnissen Anwender unnötig einschränkt. Hinzu kommt ein massives Anwachsen an zu verwaltenden Dateien pro Benutzer. Das führt zu Frustration, verlorenen oder redundanten Informationen. Allein der Anteil von redundanten Daten beläuft sich bei Analysen im privaten als auch im Firmenumfeld im Bereich von 15 bis 50 Prozent am gemeinsam genutzten Speicher.
Zwar helfen technische Lösungen dabei, solche Redundanzen durch Deduplizierung abzubauen. Dadurch verbessert sich jedoch die Situation bei der Suche nach Informationen sowie bei sich daraus ergebenden Problemen durch abweichende Versionen keinesfalls. Täglich entsteht pro Person durch diese Suche ein unnötiger Zeitverlust, der sich nach Ansicht des Autors auf mindestens 15 bis 30 Minuten beläuft. Durch ein grundlegend neues Konzept der EDV ließe sich eventuell sogar ein Mehrfaches davon gewinnen, je nach Umfang und Weitblick. Der einzige vielversprechende Vorstoß in diese Richtung kam von Microsoft mit WinFS [17], fand jedoch keinen Einzug in die alltäglichen Arbeitsumgebungen.
Konventionen
Das Konzept entfaltet mittels einer Konvention für Dateinamen ein Maximum an Konsistenz. Dabei leitet in den meisten Fällen ein Datums- oder Zeitstempel im angepassten ISO-8601-Format [3] den Dateinamen ein. Das Anpassen des Zeitstempels ist notwendig, da Microsoft-Systeme den im Standard enthaltenen Doppelpunkt in Dateinamen nicht zulassen.
Die Frage, welcher Zeitpunkt in den Dateinamen einfließt, sollten Sie sich möglichst bereits am Anfang stellen. Der Autor verwendet zumeist einen, der mit dem Entstehen oder Publikation der Information im Zusammenhang steht. Als Fallback dient das Datum der Aufnahme ins System, meistens das Datum des Downloads oder des Digitalisierens [4].
Hinter dem optionalen Datums- oder Zeitstempel folgt der eigentliche Dateiname. Der möglichst aussagekräftige Titel muss lang genug sein, um die Datei eindeutig zu beschreiben, und kurz genug, um sich in einer Liste noch gut lesen zu lassen.
Dahinter folgt ein optionaler Teil, der aus einem Trenner und einer Reihe von Schlagworten (Tags) besteht (siehe Kasten “Tagging”). Der Trenner besteht im Beispiel aus einem Leerzeichen, zwei Minuszeichen und einem weiteren Leerzeichen. Zwischen den Tags sind Leerzeichen eingefügt; sie selbst bestehen im optimalen Fall nur aus Kleinbuchstaben und Ziffern. Ein Beispiel, das dieser Konvention folgt, sehen Sie in Listing 1.
Tagging
Das Verschlagworten von Dateien ist eine Wissenschaft für sich. Dieser Artikel berücksichtigt nicht die vielfältigen Implikationen, die sich ergeben, wenn sich mehrere Benutzer Dateien und Verzeichnisse teilen. Sowohl aus der persönlichen Praxis heraus als auch basierend auf den Erkenntnissen aus einigen wissenschaftlichen Arbeiten empfiehlt der Autor folgende Richtlinien:
- Beschränken Sie sich auf ein vordefiniertes Set an Tags, oder, wie es in der Fachsprache heißt, ein kontrolliertes Vokabular (controlled vocabulary, CV). Dessen Umfang sollte so klein sein wie möglich. Ein CV von mehreren Hundert Einträgen sorgt für mehr Verwirrung als Hilfe.
- Benötigen Sie sehr viele Tags pro Datei, ist eine Volltextsuche die bessere Wahl. Die verwendeten Tags sollen den eigentlichen Dateinamen nicht ergänzen, sondern erweitern ihn lediglich um generalisierte Konzepte. Schränken Sie die Anzahl der Tags ein, verhindern Sie so außerdem Probleme durch Synonyme und indirekt durch Homonyme.
- Per Konvention sind die Tags im Plural definiert, um Probleme bei Fragen von Einzahl und Mehrzahl zu eliminieren – also manuals statt manual oder templates statt template. Verwenden Sie nur englische Begriffe, vereinfacht das unter Umständen die Suche (manuals versus Anleitungen).
- Tags, die sich direkt aus dem Dateityp ergeben, wie etwa images und movies für Dateien mit den Endungen
.jpegund.avi, bringt keinen nennenswerten Mehrwert. In der Praxis hat sich beim Autor eine Ausnahme ergeben: Der Tag presentations leistet gute Dienste sowohl bei Dateien vom Typ LibreOffice Impress als auch bei entsprechenden Fotos, Filmen oder Audiodateien.
Es empfiehlt sich außerdem, auf das Auszeichnen von Versionen in Dateinamen zu verzichten, wie etwa Dokument v2.pdf. Stattdessen lohnt es sich, sprechende Tags wie Abschlussarbeit -- draft.pdf zu nutzen. Wer eine noch detailliertere Versionierung benötigt, für den lohnt sich ohnehin ein (lokales) Git-Repository.
Listing 1
/a/path/Picknick in Graz -- food graz.jpg /a/path/2014-04-20 Picknick in Graz -- food graz.jpg /a/path/2014-04-20T17.09 Picknick in Graz -- food graz.jpg /a/path/2014-04-20T17.09 Picknick in Graz.jpg
Im Gegensatz zu anderen Ansätzen tauchen hier die Metadaten in Form von Tags direkt im Dateinamen auf. Das bietet einige Vorteile. Vor allem bietet es Kompatibilität zu jeglicher Anwendung. Man benötigt keine spezielle Software, um auf spezifische Daten zuzugreifen, wie es etwa bei Exif und IPTC (Bilder) oder ID3 (Musik) notwendig wäre.
Darüber hinaus sind solche Daten gegenüber dem Bearbeiten mit Programmen immun. Bei den genannten Standards für Bilder und Musik besteht die Möglichkeit, diese Metadaten zu verlieren, sobald Sie die Datei mit einem Werkzeug bearbeiten, das diese nicht ordentlich ins Ergebnis überträgt.
Diese Methode stellt außerdem sicher, dass es keine Schwierigkeiten bei Austausch zwischen Betriebssystemen oder beim Kopieren gibt. Metadaten, die in Alternate Data Streams (ADS, NTFS) oder entsprechenden Pendants von HFS+ oder APFS gespeichert sind, gehen dabei unter Umständen verloren. Beim Kopieren entstehen oft Sidecar-Dateien, die Sie unter Umständen beim Bearbeiten von der dazugehörigen Datei trennen.
Keine Frage: Die beschriebene Konvention bringt zusätzlichen Aufwand mit sich. Die nun folgenden Abschnitte geben Hilfestellungen und stellen Werkzeuge vor, mit denen Sie sich einerseits das digitale Leben erleichtern und die andererseits einiges an zusätzlichem Nutzen bereitstellen.
Beispielumgebung
Der Autor arbeitet zur Zeit mit Debian, Xubuntu sowie Windows 10. Als Umgebung kommen unter Linux die Z-Shell, der grafische Dateibrowser Thunar sowie der Bildbetrachter Geeqie zum Einsatz. Das Einbinden in andere grafische Werkzeuge setzt voraus, dass diese eine Möglichkeit bieten, externe Werkzeuge aufzurufen.
Die meisten im Folgenden erwähnten Programme laufen gleichermaßen auf Linux, Windows und Mac OS X. Es empfiehlt sich, sie in die eigene Umgebung einzubinden, um sie rasch und einfach auf Dateien anzuwenden. Die jeweiligen README-Dateien erklären, wie die Installation und das Einbinden in die beschriebene Umgebung funktionieren.
Das Hinzufügen der Datums- und Zeitstempel am Anfang der Dateinamen übernimmt das Werkzeug Date2name [5]. Der Aufruf date2name "foo bar.txt" benennt die Datei in 2019-09-26 foo bar.txt um. Mit date2name --withtime "foo bar.txt" entsteht dann 2019-09-26T14.45 foo bar.txt.
Einen häufig wiederkehrenden Arbeitsschritt bei der Arbeit mit Dateien stellt das Hinzufügen von Wörtern des eigentlichen Dateinamens dar. Möchten Sie dem Foto 2019-09-26T14.52.36.jpg eine Beschreibung hinzufügen, hilft das Werkzeug Appendfilename [6]. Ein Aufruf wie appendfilename --text="foo bar" 2019-09-26T14.52.36.jpg benennt die Datei in 2019-09-26T14.52.36 foo bar.jpg um. Ohne den Parameter --text wartet das Werkzeug in einem interaktiven Modus auf die Eingabe vom Text.
Verpackt man den Aufruf wie in Listing 2 gezeigt in ein Wrapper-Skript, kann Appendfilename aus einem Dateibrowser heraus alle markierten Dateien ergänzen, nachdem der Benutzer im erscheinenden Fenster den Text eingegeben und bestätigt hat.
Listing 2
/usr/bin/gnome-terminal \
--geometry=90x5+330+5 \
--hide-menubar \
-x appendfilename "${@}"
Filetags
Ähnlich wie Appendfilename fügt Filetags [7] dem Dateinamen einen Text hinzu, allerdings so, dass Sie sich keine Gedanken um den Trenner vor den Tags zu machen brauchen. Sowohl das Kommando in der ersten Zeile von Listing 3 als auch das in der zweiten ergibt foo -- bar baz.txt als Dateiname. Der Befehl aus der dritten Zeile führt wieder zurück zu foo.txt.
Listing 3
$ filetags --text "bar baz" "foo.txt" $ filetags --text "baz" "foo -- bar.txt" $ filetags --remove --text "baz bar" "foo -- bar baz.txt"
Im interaktiven Modus ohne den Parameter --text entfernen Sie vorhandene Tags, indem Sie sie mit einem vorangestellten Minuszeichen eingeben: So entfernt -bar baz das Tag bar und fügt baz hinzu.
Zudem schlägt das Tool Tags aufgrund des Einsatzes in anderen Dateien im selben Verzeichniss vor. Diese Vorschläge versieht Filetags mit Nummern, die bei 1 beginnen. Diese Kürzel dürfen Sie wiederum in der Eingabe verwenden. So sorgt die interaktive Eingabe von 1 bar 42 dafür, dass das Tool die Vorschläge 1, 2 und 4 gemeinsam mit dem Tag bar hinzufügt.
Darüber hinaus gibt es eine Vervollständigung mittels Tabulator. Dafür empfiehlt sich das Anlegen einer Datei .filetags im aktuellen oder einem übergeordneten Verzeichnis. Dabei sucht die Software rekursiv aufwärts, wobei die erste gefundene Definitionsdatei gewinnt. Das ermöglicht unterschiedliche Definitionen für verschiedene Hierarchien.
Die Struktur dieser Textdatei ist denkbar einfach. Jede Zeile besteht aus einem oder mehreren Tags. Stehen mehrere davon in einer Zeile, so behandelt Filetags sie als sich gegenseitig ausschließend. Fügen Sie auf Basis der .filetags aus Listing 4 einer Datei foo -- draft.txt das Tag final hinzu, ersetzt Filetags das Tag draft automatisch durch final, anstatt es zusätzlich anzuhängen.
Listing 4
§§nonumbers books presentations cheatsheets cliparts finance manuals templates draft final submitted
Raten und verpacken
Das in Python geschriebene Werkzeug Guessfilename [8] hilft beim Umbenennen häufig vorkommender Dateinamen. Durch Mustererkennung im Dateinamen und gegebenenfalls durch Parsen des Inhalts ermittelt es Varianten für die Dateinamen. Kommt der monatliche Gehaltszettel etwa in Form einer PDF-Datei wie Gehalt.pdf, dann erkennt es entsprechend eines konfigurierten Musters die Zeichenkette Gehalt sowie den Dateityp PDF und generiert daraus den neuen Dateinamen 2019-09-29 Gehaltszettel September -- finance company.pdf.
Es liegt in der Natur der Sache, dass man Guessfilename für die eigenen Bedürfnisse anpassen muss – es handelt sich quasi nur um eine zu personalisierende Vorlage. Zum Anpassen der entscheidenden Funktion derive_new_filename_from_old_filename() benötigen Sie grundlegende Python-Programmierkenntnisse.
Als Entschädigung für den Aufwand winkt eine Vielzahl von Erleichterungen im täglichen Umgang mit Dateien. Der Autor verwendet Guessfilename nicht nur beim Gehaltszettel, sondern ebenso bei mittels MediathekView [9] heruntergeladenen Aufnahmen, digitalen Fotos direkt von der Kamera, Screenshots, Rechnungen und anderen Dateien – überall dort, wo Programme keine Konfiguration des Dateinamens ermöglichen, um sie in das gewünschte Schema einzupassen.
Die Werkzeuge Guess-target-folder.sh und Move2archive [10] erledigen den logisch nächsten Schritt: das Verschieben in passende Zielordner. Beide Skripte sind in dieser Form in der Regel nur auf Unix-artigen Betriebssystemen sinnvoll.
Bei Guess-target-folder.sh handelt es sich um ein triviales, wiederum stark personalisiertes Shell-Skript; Listing 5 skizziert den grundlegenden Mechanismus. Move2archive verhält sich sehr ähnlich, bietet jedoch keine Mustererkennung. Es verschiebt die Dateien einfach in eine Ordnerstruktur, in der die Verzeichnisnamen sich aus einem archivepath (etwa $HOME/archive/) und der Jahreszahl zusammensetzen.
Listing 5
# Guess-target-folder.sh
#
file="${1}"
move_file()
{
file="${1}"
targetdir="${2}"
echo "* ${file}\n -> ${targetdir}"
mv "${file}" "${targetdir}"
}
case "${file}" in
20*Tatort*mp4)
move_file "${file}" "$HOME/tv/Krimis/";;
20*Verbrauchsablesung\ Wasser*pdf)
move_file "${file}" "$HOME/correspondence/wasser/";;
*Gehalt*pdf)
move_file "${file}" "$HOME/correspondence/company/";;
*1234567*|*1.234.567*)
move_file "${file}" "$HOME/correspondence/versicherung/";;
esac
Die beiden Python-Skripte installieren Sie bei Bedarf mittels Pip3. Wegen der auf Windows-Systemen besonders lästigen Integration entstand Integratethis [11], das für eine einfache Einbindung in den Windows Explorer sorgt. Es spräche aber nichts dagegen, ihm auch die Integration in Geeqie, Thunar und andere Oberflächen beizubringen. Entsprechende Pull-Requests auf Github sind gerne gesehen.
Filter und Bäume
Die Vorteile der vorgestellten Methode entfalten ihre Wirkung erst dann so richtig, wenn Sie einige ausgewählte Zusatzfähigkeiten und das Zusammenspiel der vorgestellten Werkzeuge berücksichtigen. Mittels des Schalters --filter erzeugt Filetags etwa nach Eingabe von ein bis mehreren Tags eine temporäre Ansicht, die alle Dateien mit den eingegebenen Tags umfasst. Auf Wunsch arbeitet diese Funktion auch rekursiv über alle Unterverzeichnisse.
Die temporäre Ansicht besteht aus Links in einem vordefinierten temporären Verzeichnis. Sowohl Appendfilename als auch Filetags sind darauf ausgelegt, beim Umbenennen von verlinkten Dateien deren Originale ebenfalls zu verändern, sofern sie denselben Namen besitzen. Mit diesem Tag-Filter durchstöbern Sie sehr einfach eine große Menge an Dateien anhand ihrer Tags. Mit filetags --tagtrees erstellen Sie eine temporäre Link-Struktur, auf Wunsch wieder rekursiv für eine gesamte Hierarchie.
Diese Struktur ignoriert die vorhandenen Verzeichnisse und baut parallel eine neue Struktur auf, in der Sie mittels der verwendeten Tags navigieren. Darin existiert etwa ein Link zur Datei foo -- bar baz.txt in den Ordnern bar/, baz/, bar/baz/ und baz/bar/. So fällt es leicht, über Assoziationen zur gesuchten Information zu gelangen. Wie bei den Tag-Filtern geben sowohl Appendfilename als auch Filetags Veränderungen der Links an die Originaldateien weiter.
Aus technischen Gründen wächst die Menge der anzulegenden Links mit der Anzahl der Tags und Dateien exponentiell. Deshalb ist es ratsam, sich auf zwei oder drei Ebenen zu beschränken.
Zusammenspiel
Die einzelnen Bausteine der Methode entfalten ihren vollen Nutzen erst im Zusammenspiel. Die Dateinamenskonvention wäre mühsam, wenn sich nicht die Werkzeuge um das Management der einzelnen Bestandteile kümmern würden.
Die Vorteile des Konzepts lassen sich anhand der Bearbeitung von Fotos eines Smartphones veranschaulichen. Das Android-Handy des Autors erstellt Fotos mit Dateinamen wie IMG_20190926_214730.jpg. Entweder durch manuellen oder automatisierten Aufruf von Guessfilename wird daraus 2019-09-26T21.47.30.jpg.
Beim Betrachten des synchronisierten oder kopierten Verzeichnisses der Bilder leistet Appendfilename gute Dienste. Der Autor hat das Wrapper-Skript aus Listing 2 innerhalb von Geeqie auf das Tastenkürzel [A]+ gelegt. Nach dem Markieren von Dateien und Drücken der Taste fordert das Programm eine gemeinsame Beschreibung an. Einzelne Fotos erhalten in einem zweiten Durchgang mit derselben Methode eine genauere Beschriftung. Ein Wrapper-Skript für Filetags liegt auf dem Tastenkürzel [T]. Damit macht es zum Kinderspiel, ein oder mehrere Fotos zu verschlagworten.
Der Autor verwendet hier gerne die Tags sel (“selection”), cliparts und special. Das erste markiert Fotos, die einen repräsentativen Ausschnitt ergeben. Das Tag cliparts erhält Bilder, die sich für Präsentationen eignen. Das Tag special kennzeichnet besonders gelungene Fotos, die zum Ausarbeiten oder als Hintergrund für den Desktop taugen.
Sind die Fotos zu einem Event entsprechend beschriftet und verschlagwortet, markieren Sie sie und benutzen ein weiteres Kürzel wie etwa [M] für Move2archive, um sie in einem neu erstellten Ordner zu archivieren. Abbildung 1 zeigt, welches Tool jeweils seinen Anteil am Dateinamen samt Pfad hat.
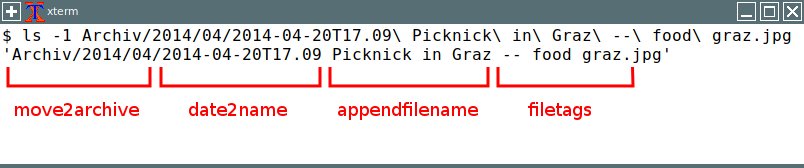
Abbildung 1: Die Teile des Pfads beziehungsweise des Dateinamens, die jeweils durch den Einsatz eines bestimmten Tools entstanden, sind hier rot markiert.
Um nun etwa Urlaubsfotos mit Freunden anzusehen, verwendet der Autor im Bildbetrachter das Kürzel [S], um ein Wrapper-Skript für filetags --filter aufzurufen. Hier kommt dann meist das Tag sel zum Einsatz, um die damit verschlagworteten Fotos in einem neuen Fenster des Bildbetrachters zu öffnen.
Bei der Vorbereitung von Präsentationen verwendet der Autor gerne Tagtrees mit dem Geeqie-Kürzel [Umschalt]+[T]. Das erwähnte Tag cliparts liefert eine erste Auswahl. Als Nächstes filtert er dann nach weiteren Tags, etwa nach passenden Fotos zur Kombination security und surveillance.
Fazit
Die meisten Vorteile der vorgestellten Methode offenbaren sich erst bei längerem Einsatz mit einem größeren Pool an entsprechend benannten Dateien. Die Einschränkung auf ein kontrolliertes Vokabular verhindert schleichenden Wildwuchs und sorgt dafür, dass die Auswahl der Tags bewusst und sorgsam erfolgt.
Die Clou an der vorgestellten Methode: Die hier vorgestellten Werkzeuge unterstützen in flexibler Art und Weise unterschiedlichste Anforderungen. Das verhindert, in die eingangs erwähnte Situation zu kommen, in der sich Dateien nicht mehr aufspüren lassen. Die Stichworte machen es unerheblich, wo genau Sie eine Datei abgelegt haben. Der Computer kommt hier der Art und Weise etwas entgegen, wie Sie als Mensch denken.
Der Autor
Dr. Karl Voit beschäftigt sich privat intensiv mit Personal Information Management und hält zu diesem Thema Vorträge, Workshops und Lehrveranstaltungen. Daneben sind ihm Privatsphäre, Sicherheit, freie Software und Dezentralisierung wichtig. In seinem Blog [16] schreibt er regelmäßig über das Verwalten digitaler Informationen.
Infos
-
Desktop-Metapher: https://Karl-Voit.at/2018/08/25/deskop-metaphor/
-
Tagstore-Projekt: https://Karl-Voit.at/tagstore/
-
ISO 8601: https://de.wikipedia.org/wiki/ISO_8601
-
Digitalisierungsprojekt: https://Karl-Voit.at/2015/04/05/digitizing-paper/
-
Date2name: https://github.com/novoid/date2name
-
Appendfilename: https://github.com/novoid/appendfilename
-
Filetags: https://github.com/novoid/filetags
-
Guessfilename: https://github.com/novoid/guess-filename.py
-
MediathekView: https://mediathekview.de/
-
Move2archive: https://github.com/novoid/move2archive
-
Integratethis: https://github.com/novoid/integratethis
-
Weblog des Autors: https://Karl-Voit.at
-
Microsoft WinFS: https://de.wikipedia.org/wiki/WinFS




