

Zu den häufigsten Aufgaben bei der Arbeit am Rechner zählt das Durchstöbern von Texten nach Suchmustern. Icgrep bietet hier eine moderne, parallel arbeitende und Unicode-fähige Alternative zum klassischen Grep.
Es lässt sich heute nicht mehr ganz eindeutig nachvollziehen, woher der Programmname Grep für das wichtigste textdurchsuchende Werkzeug unter Unix stammt. Es sei ein Akronym für “Global/Regular Expression/Print” oder “Global search for a Regular Expression and Print out”, meinen die einen. Der Name habe sich aus dem Kommando g/re/p (global, regular expression, print) des Unix-Standardeditors Ed entwickelt, widersprechen die anderen.
Wie auch immer: Grep durchsucht zeilenweise die Eingaben nach bestimmten, als reguläre Ausdrücke (“regular expressions”) formulierten Mustern. Die Fundstellen zeigt das Tool, abhängig von den verwendeten Optionen, als Zeilen mit den Treffern, deren Position, Anzahl oder Ähnliches an.
Dieses Konzept stößt bei heutigen Texten in mehrfacher Hinsicht an seine Grenzen: Zum einen verwenden moderne Systeme schon lange nicht mehr den antiquierten ASCII-Zeichensatz mit seinen 128 Zeichen oder dessen größere, immerhin 256 Zeichen umfassende Brüder wie etwa Latin 1, sondern zunehmend Unicode [1] (siehe Kasten “Unicode-Zeichen nutzen”).
Ein weiteres Problem liegt in der Definition der Eingabezeilen. Schon bei den bisherigen, nicht Unicode-fähigen Systemen gab es eine Vielzahl von Varianten, einen Zeilenumbruch zu kennzeichnen beziehungsweise hervorzurufen [2]. Unix-Standard ist NL (“New Line”); bei Unicode kommen weitere hinzu, insbesondere NEL (“New Line”), aber auch LS (“Line Separator”) oder PS (“Paragraph Separator”).
Erschwerend hinzu kommt die relativ niedrige Arbeitsgeschwindigkeit von Grep bei großen Eingabemengen und komplexen regulären Ausdrücken. Schon im besten Fall erweisen sich Regexe [3] als relativ kompliziert einzugeben. Beim Bearbeiten von komplexen Ausdrücken benötigt der Rechner eine gehörige Menge Rechenleistung. Obendrein gibt es ja auch bedingte, nichtgierige und gierige Regexe sowie viele erweiterte Varianten. Alle Grep-Spielarten verarbeiten reguläre Ausdrücke zur Laufzeit, sodass sich die Komplexität direkt im Rechenzeitbedarf abbildet.
Wie schnell Icgrep [4] im Unterschied zu den Standard-Greps arbeitet, zeigt eine Untersuchung von Fred Popowich [5]. Sie beschreibt ein Szenario, in dem das Standard-Grep für eine Mustersuche über eine Minute benötigt, während Icgrep dieselbe Aufgabe in einer guten Sekunde bewältigt. Nach Aussagen der Icgrep-Entwickler sind Geschwindigkeitsunterschiede mit dem Faktor von bis zu 100 möglich.
Unicode-Zeichen nutzen
Unicode strebt an, jedem existierenden sinntragenden Schriftzeichen oder Textelement aller bekannten Schriftkulturen und Zeichensysteme einen digitalen Code zuzuweisen. Entsprechend umfangreich fällt der Zeichenraum aus – ein einzelnes Zeichen zu codieren, erfordert mehrere Bytes.
Aufgrund des großen Umfangs des Unicode-Zeichenraums gelingt es oft nicht, Zeichen auf der Tastatur direkt einzugeben, weil dafür schlicht die Tasten fehlen. Unter Linux ermöglichen Qt und GTK allerdings die Eingabe über Tastencodes. Dazu stellen Sie den Codes das Tastenkürzel [Strg]+[U] beziehungsweise [Strg]+[Umschalt]+[U] voran – nicht alle Programme unterstützen das.
Insbesondere, wenn Sie die Codes für ein bestimmtes Zeichen nicht kennen, gestaltet es sich oft viel einfacher, diese mit einem kleinen Tool herauszusuchen. Für GTK-basierte Desktops gibt es die zwei oft verwendeten Hilfsprogramme Gucharmap (Abbildung 1) und Gnome-Characters (Abbildung 2). Letzteres eignet sich besonders gut, um Sonderzeichen herauszufinden und deren Codes zu kopieren.
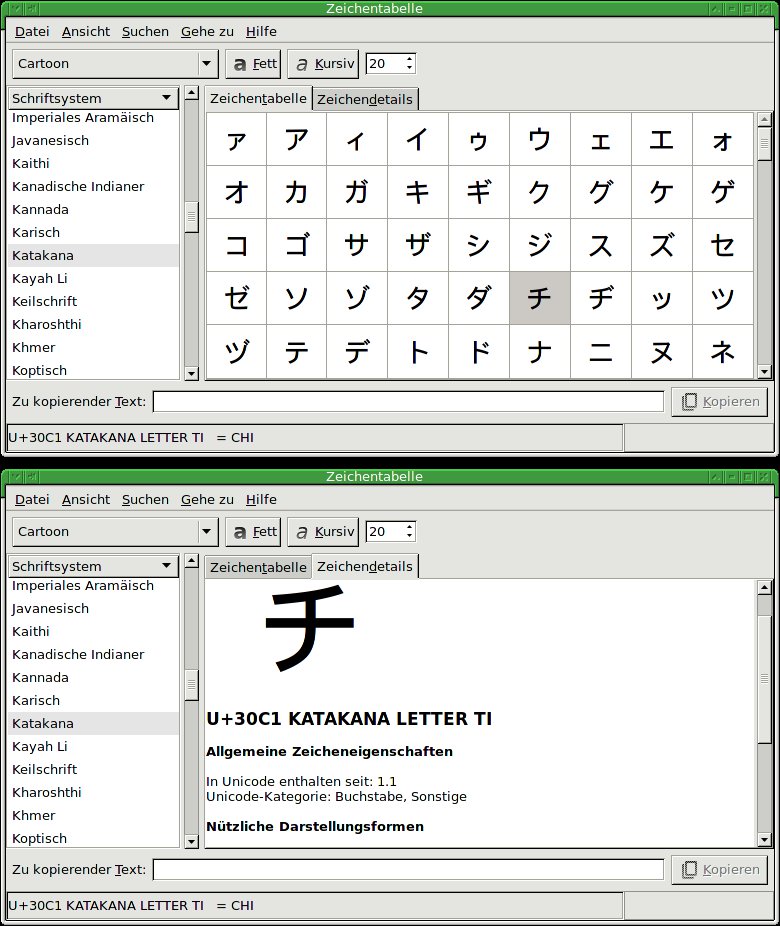
Abbildung 1: Das Werkzeug Gucharmap führt die Zeichen vieler Sprachen systematisch auf. Dazu gibt es jeweils weitere Informationen, um die Gefahr von Verwechslungen zu minimieren.
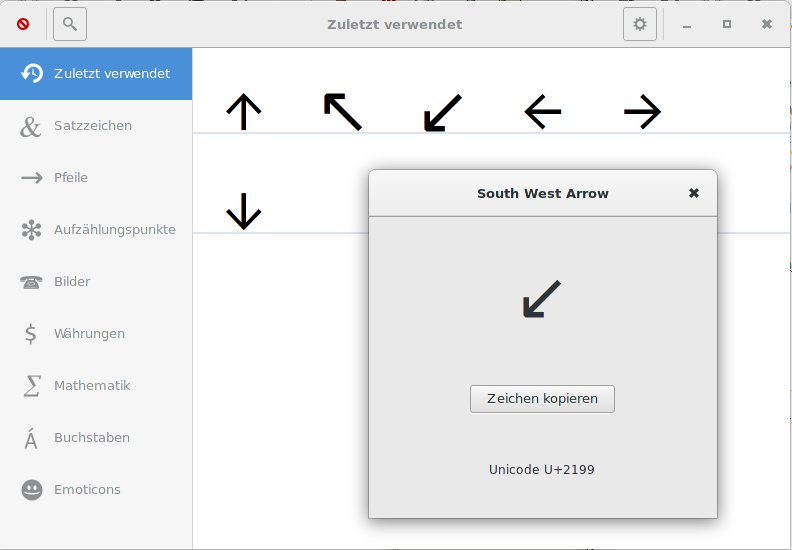
Abbildung 2: Das Programm Gnome-characters sortiert Sonderzeichen in verschiedene, oft unmittelbar einsichtige Klassen.
Installation
Die Installation von Icgrep erwies sich im Test als nicht ganz trivial und etwas zeitraubend, als Voraussetzungen benötigen Sie Subversion, Cmake und Clang (Listing 1, Zeile 1).
Zuerst laden Sie via Subversion die aktuellste Icgrep-Version auf Ihren Rechner. Die Meldung Ausgecheckt, Revision Nummer. kennzeichnet das Ende dieser Aktion (Zeile 5). Nun wechseln Sie in das Verzeichnis icgrep1.0/icgrep-devel/. In der Datei README-icgrep-1.00a.txt finden Sie unter anderem eine Installationsanleitung. Sie besteht im Wesentlichen aus zwei Teilen: der Übersetzung und der Installation von LLVM (“Low Level Virtual Machine”) sowie dem anschließenden Bau von Icgrep selbst.
Zur Installation von LLVM gilt es, die benötigten Makefiles zu erzeugen. Dazu wechseln Sie ins Verzeichnis llvm-build/ (Zeile 6) und lassen dort Cmake seinen Dienst verrichten (Zeile 7). Schon nach kurzer Zeit können Sie den Bau der Low Level Virtual Machine mit make && make install anstoßen (Zeile 10). Der Übersetzungsvorgang dauert je nach Rechenleistung rund eine Stunde, die anschließende Installation nimmt nur wenige Sekunden in Anspruch.
Listing 1
$ sudo apt-get install cmake clang subversion [...] $ svn co http://parabix.costar.sfu.ca/svn/tags/icgrep1.0 [...] Ausgecheckt, Revision 5012. $ cd icgrep1.0/icgrep-devel/llvm-build/ $ cmake -DCMAKE_INSTALL_PREFIX=../libllvm -DLLVM_TARGETS_TO_BUILD=X86 -DLLVM_BUILD_TOOLS=OFF -DLLVM_BUILD_EXAMPLES=OFF -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_COMPILER:FILEPATH=/usr/bin/clang++ -DCMAKE_C_COMPILER:FILEPATH=/usr/bin/clang ../llvm-3.5.0.src [...] -- Build files have been written to: /home/jluther/icgrep1.0/icgrep-devel/llvm-build $ make && sudo make install Scanning dependencies of target LLVMSupport [ 0%] Building CXX object lib/Support/CMakeFiles/LLVMSupport.dir/APFloat.cpp.o [...] [100%] Built target LTO [sudo] password for jluther: -- Installing: [...]
Im zweiten Schritt erstellen Sie Icgrep (Listing 2). Dazu wechseln Sie ins Verzeichnis icgrep1.0/icgrep-devel/icgrep-build/ und erzeugen darin die Makefiles mit dem Kommando aus der zweiten Zeile. Dabei erkennt der Compiler automatisch, welche CPU-Extensions das Programm zum Beschleunigen der Verarbeitung nutzen kann. Alternativ übergeben Sie über den Schalter -DSIMD_SUPPORT eine der Optionen SSE2, SSE3, SSE4_1, SSE4_2, AVX1 oder AVX2.
Als letzten Schritt erzeugen Sie mit make ohne Optionen die ausführbare Datei (Listing 2, Zeile 15), was wieder etwas länger dauert. Durch strip lässt sich das so erzeugte Programm icgrep noch verkleinern. Zu guter Letzt installieren Sie das Programm manuell im Verzeichnis /usr/local/bin/.
Listing 2
$ cd ../icgrep-build $ cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_COMPILER:FILEPATH=/usr/bin/clang++ -DCMAKE_C_COMPILER:FILEPATH=/usr/bin/clang ../icgrep-1.00a [... Tests ...] -- Performing Test AVX2 -- Performing Test AVX2 - Failed -- Performing Test AVX1 -- Performing Test AVX1 - Failed -- Performing Test SSE4_2 -- Performing Test SSE4_2 - Failed -- Performing Test SSE4_1 -- Performing Test SSE4_1 - Success -- Configuring done -- Generating done -- Build files have been written to: /home/jluther/icgrep1.0/icgrep-devel/icgrep-build $ make Scanning dependencies of target RegExpADT [ 2%] Building CXX object CMakeFiles/RegExpADT.dir/re/re_re.cpp.o [... Kompilierung ...] [100%] Building CXX object CMakeFiles/icgrep.dir/compiler.cpp.o Linking CXX executable icgrep [100%] Built target icgrep
In der Praxis
Icgrep steuern Sie wie seine Vettern Grep oder Agrep weitgehend durch Optionen. Da es sich bei dem Tool um eine Forschungssoftware handelt, enthält es zwei beziehungsweise drei Gruppen von Optionen mit unterschiedlicher Relevanz für normale Anwender. Wie üblich zeigt -help die wichtigsten davon. Einen Schritt weiter geht -help-list: Es generiert eine kurze, kompakte Liste wichtiger Schalter, die allerdings schon einiges Wissen über reguläre Ausdrücke voraussetzt. Mit -help-list-hidden erhalten Sie schließlich die vollständige Liste der Optionen, von denen allerdings viele nur in speziellen Fällen von Bedeutung sind.
Muster, also reguläre Ausdrücke, definieren Sie nach dem Schalter -e (“expression”). Falls die Gefahr besteht, dass die Shell darin Meta-Zeichen erkennt und auswertet oder ersetzt, schließen Sie das Muster zwischen einfachen oder doppelten Hochkommas ein. Dem Aufruf, der mehrfach auftreten darf, kann (muss aber nicht) ein Gleichheitszeichen folgen:
$ icgrep -e Mus -e=ter
Diese Art der Ausdrücke stehen dann für ein logisches Oder: Bedingung 1 ODER Bedingung 2 ODER beide müssen erfüllt sein. Wird die Anzahl der Muster zu groß und die Befehlszeilen damit zu unübersichtlich, empfiehlt es sich, die Muster in eine externe Datei auszulagern, jeweils eines pro Zeile. Diese Datei geben Sie durch icgrep -f Musterdatei an. Die wichtigsten Schalter von Icgrep fasst die Tabelle “Wichtige Optionen von Icgrep” zusammen.
Ein deutliches Manko von Icgrep: Es gibt keine Option, Verzeichnisse rekursiv zu bearbeiten, wie dies GNU-Grep mit dem Schalter -r macht. Stattdessen gilt es, auf die Kombination von Find, Xargs und Icgrep zurückzugreifen:
$ find Pfad -type f | xargs icgrep Muster
Alternativ unterstützen heute zwar mehrere Shells, so auch die Bash, die rekursive Verzeichnissuche durch **. Das setzt aber voraus, dass Sie diese Funktion via shopt -s globstar aktivieren. Der Befehl shopt globstar zeigt dann globstar on. Achtung: Dieses Verfahren führt eventuell zu überlangen Argumentlisten und Fehlermeldungen wie -bash: /usr/local/bin/icgrep: Die Argumentliste ist zu lang.
Zu den weiteren wichtigen Optionen, die Icgrep bisher fehlen, zählen -v (“invert match”), -C, -A, -B (Kontextzeilen anzeigen), -m (maximale Trefferanzahl festlegen), -a, -b (Eingaben als Text beziehungsweise binär interpretieren) sowie --color (Treffer in der Ausgabe farbig hervorheben). Einiges davon wollen die Entwickler demnächst implementieren [6].
Wichtige Optionen von Icgrep
| Option | Funktion |
|---|---|
-e=Muster |
ein Muster definieren, mehrfach angebbar |
-f=Datei |
Musterdatei |
-c |
nur Treffer zählen, nicht zeigen |
-n |
Zeilennummern der Treffer anzeigen |
-H |
Dateinamen anzeigen |
-i |
Groß-/Kleinschreibung ignorieren |
-disable-Unicode-linebreak |
nur noch NL als Zeilenende |
-normalize-line-breaks |
Zeilenenden normalisieren |
-dump-generated-IR |
zeigt die verwendeten regulären Ausdrücke |
-print-REs |
zeigt benannte Ausdrücke |
Regexe testen
Bei großen Datenströmen empfiehlt es sich, reguläre Ausdrücke zunächst zu testen, bevor Sie diese auf die gesamten Daten anwenden. Weniger versierten Anwendern erleichtern hier Tools das Leben, die reguläre Ausdrücke visualisieren. Unter Ubuntu finden sich derzeit zwei dieser Werkzeuge in den Repositories: Kodos und Kiki [7].
Während Kodos sich nur auf älteren Distributionen ohne Klimmzüge installieren lässt, gibt sich Kiki (Abbildung 3) anspruchsloser. Es verwendet die durch Python definierten und erzeugten regulären Ausdrücke, die es testweise auf einen zuvor eingegebenen Text anwendet.
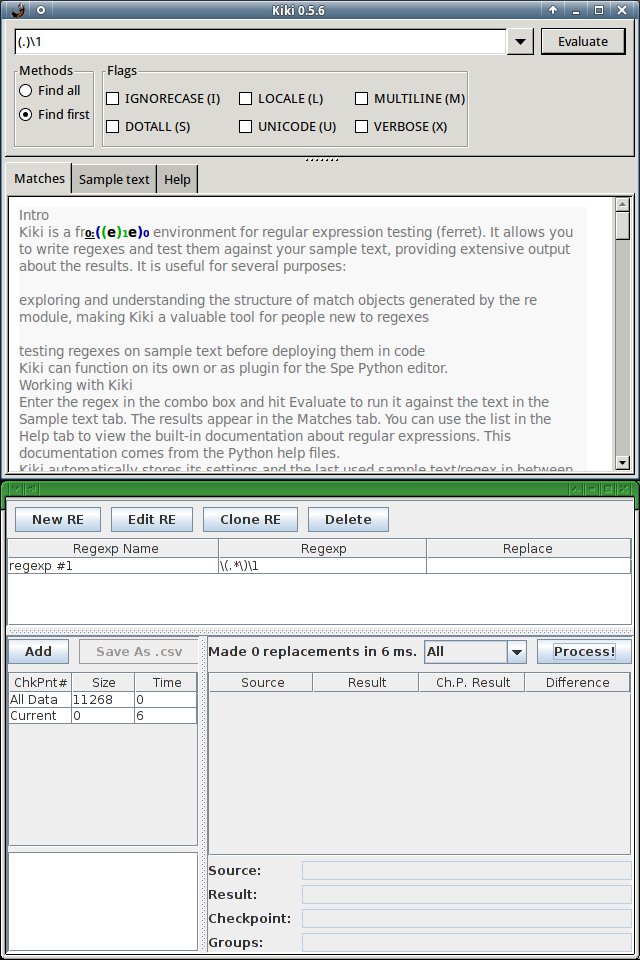
Abbildung 3: Kiki (oben) und Regexper (unten) testen reguläre Ausdrücke, bevor sie auf großen Datenmengen zum Einsatz kommen.
Etwas anders funktioniert das Regexp Testing Tool regexper [8]. Das Java-Programm verwendet naturgemäß Java-basierte Regular Expressions und wendet diese auf eine zuvor geladene Testdatei an (Listing 3). Die Versuchsdaten dürfen relativ groß ausfallen, was sich manchmal als Vorteil erweist.
Listing 3
$ java -Xmx1200M -Dfile.encoding=windows-1251 -jar bin/regexper.jar -f Testdatei
Allerdings weisen alle diese Werkzeuge Schwächen beim Verarbeiten von Unicode-Zeichen auf, sodass sie sich bei der Konstruktion von regulären Ausdrücken nur für erste Tests mit einfachen Zeichen eignen.
Fazit
Sofern Sie keinen Bedarf an Unicode-spezifischen Features haben, genügen für das Durchsuchen kleiner Datenströme beziehungsweise Dateien die herkömmlichen Grep-Varianten völlig – nicht zuletzt deswegen, weil es davon ja spezielle Ableger für unterschiedliche Einsatzgebiete gibt, wie beispielsweise Agrep [9]. Ganz anders sieht es beim Durchsuchen von großen Datenströmen nach komplexen Mustern aus: Hier stellt Icgrep sicherlich eine der bemerkenswertesten Neuentwicklungen der letzten Zeit dar und lässt sich obendrein kostenfrei nutzen.
Glossar
-
gierige Regexe
-
Solche Ausdrücke versuchen, die Treffer für Muster so zu erzeugen, dass sie möglichst viel Text einschließen. Bei nichtgierigen regulären Ausdrücken verhält es sich genau andersherum.
Infos
[1] Unicode: https://de.wikipedia.org/wiki/Unicode
[2] Unicode-Zeilenumbruch: https://de.wikipedia.org/wiki/Zeilenumbruch
[3] Reguläre Ausdrücke: https://de.wikipedia.org/wiki/Regul%C3%A4rer_Ausdruck
[4] Icgrep: http://www.icgrep.com/
[5] “Icgrep Demonstration Rev 2”: http://international-characters.com/download/icGREP_Demonstration.pdf
[6] Icgrep-Roadmap: http://parabix.costar.sfu.ca/wiki/ParabixRegexRoadMap
[7] Kiki: https://code.google.com/p/kiki-re/
[8] Regexp Testing Tool: http://sourceforge.net/projects/regexper/?source=recommended
[9] Agrep: Karsten Günther, “Besser finden”, LU 01/2016, S. 70, https://www.linux-community.de/35929




