

Mit ZFS haben Sun und Oracle ein erstklassiges Dateisystem für “große Eisen” entwickelt. Doch auch der Linux-Desktop kann davon profitieren – sofern es gelingt, gravierende Lizenzprobleme zu klären.
Mit nahezu 15 Jahren kontinuierlicher Entwicklungszeit gehört ZFS eher zu den Oldies unter den aktuellen unixoiden Dateisystemen. Gleichwohl eilt dem ursprünglich von Sun Microsystems für das Betriebssystem Solaris entwickelten und erstmals 2005 öffentlich vorgestellten Dateisystem ein legendärer Ruf voraus. Der kommt nicht von ungefähr: ZFS vereint Eigenschaften in sich, die es zu einem der besten Dateisysteme auch im Linux-Universum machen. Allerdings ist das System nicht nur zukunftsorientiert konzipiert, sondern setzt auch eine moderne Hardware-Ausstattung voraus.
Grundlagen
ZFS stellt eine universelle Antwort auf die historische Entwicklung der Massenspeichertechnologien und der daraus abgeleiteten Bedürfnisse professioneller Anwender ab dem Ende des 20. Jahrhunderts dar: Die bis zum Ende der 80er-Jahre gebräuchlichen Dateisysteme waren aufgrund der extrem hohen Kosten des Speicherplatzes auf einen möglichst sparsamen Umgang mit jedem verfügbaren Bit ausgelegt.
Als ab Beginn der 90er-Jahre dank neuer technischer Entwicklungen die Speicherkapazitäten der damals gebräuchlichen IDE- und SCSI-Festplatten immer weiter wuchsen und gleichzeitig die Massenspeicher dank neuer Fertigungstechnologien immer günstiger wurden, gerieten herkömmliche Dateisysteme zunehmend an ihre Grenzen: In größeren Unternehmen mit eigener IT-Infrastruktur und Rechenzentren mit großen Speicherclustern kam der Ruf nach mehr Datensicherheit auf, die sich primär durch Datenspiegelung erzielen ließ.
Gleichzeitig entwickelten sich Konzepte des Volume Managements, die mithilfe eines Logical Volume Managers (LVM) mehrere physische Datenträger zu einem logischen Verbund zusammenfassten und damit die Kapazitätsgrenzen einzelner Massenspeichersysteme überwanden. Der Logical Volume Manager wurde dabei jedoch zusammen mit den alten Dateisystemen genutzt, sodass deren Beschränkungen auch die Gesamtleistung des Verbundes determinierten.
Mit wachsender Komplexität des gesamten Massenspeichersubsystems wuchs nicht nur der Administrationsaufwand beträchtlich, sondern auch die Gefahr einer mangelnden Datenintegrität durch Übertragungs- und Speicherfehler. Zudem verlangten die Konzepte der Datenspiegelung in den Anfangsjahren nach sündhaft teurer Zusatzhardware, die für Highend-Systeme meist in Gestalt von Einsteckkarten angeboten wurde.
Diese Platinen unterstützten meist sowohl die Datenspiegelung als auch das Verteilen von Datenbeständen über verschiedene physische Massenspeicher hinweg, sodass sich ein beträchtlicher Geschwindigkeitsgewinn beim Abruf der Daten durch parallelisierte Zugriffsmechanismen erzielen ließ.
Lösung: ZFS
Die ZFS-Entwickler berücksichtigten all diese Schwachstellen integrierten Funktionen in das Dateisystem, die sich vorher nur durch externe Lösungen erreichen ließen. Daher stellt ZFS kein Dateisystem im originären Sinn des Wortes dar, sondern eher eine Kombi-Lösung: Das Dateisystem integriert einen internen Logical Volume Manager und legt einen sogenannten Storage-Pool an, der die Massenspeicher selbstständig verwaltet.
Dabei passen sich die einzelnen Pools automatisch in ihrer Größe an, sobald sich – etwa durch das Bereitstellen eines neuen physischen Massenspeichers im System – die Gesamtkapazität ändert. Die Modifikation der Pools nimmt ZFS transparent vor, sodass keinerlei manueller Verwaltungsaufwand anfällt [1]. Zudem erzeugt ZFS automatisch Redundanzen, um eine erhöhte Datensicherheit zu erreichen.
Durch Snapshots lässt sich außerdem ein fest definierter Zustand des Systems duplizieren, sodass man im Falle eines Ausfalls das System auf Basis des Snapshots wieder rekonstruieren kann. Diese als Copy-on-Write bezeichnete Technologie arbeitet dabei transparent im Hintergrund, während das Dateisystem aktiv ist. Dabei kann das Dateisystem zusätzlich durch eine integrierte Datenkomprimierung für sparsamen Umgang mit dem vorhandenen Speicherplatz sorgen. Je nach Art der gespeicherten Dateien lassen sich so erhebliche Ressourcen einsparen.
Eine weitere Innovation von ZFS stellt die Integritätsprüfung dar: Durch Prüfsummen für alle Blöcke gewährleistet ZFS die Datenintegrität zwischen Massen- und Arbeitsspeicher. Dabei bietet das Dateisystem sogar Mechanismen der Selbstheilung. Erweist sich bei redundant vorgehaltenen Daten eine Variante aufgrund unterschiedlicher Checksummen als korrumpiert, repariert ZFS den Fehler mithilfe der gespeicherten Kopie. Als Nutzer können Sie außerdem einen manuellen Prüflauf anstoßen, sodass die Datenintegrität jederzeit gewährleistet bleibt. Durch diese Mechanismen fallen aufwendige und zeitfressende manuelle Dateisystemchecks – bei großen Datenverbünden können sie Tage beanspruchen – weitgehend weg.
Zu guter Letzt haben die Entwickler ZFS auf hohe Arbeitsgeschwindigkeiten getrimmt: Durch verschiedene Zwischenspeicherebenen sowohl im Arbeitsspeicher (“Adaptive Replacement Cache”, ARC) als auch auf gerätebasierten Pufferspeichern (“Cache-vdev”, L2ARC) bietet das Dateisystem deutliche Geschwindigkeitszuwächse beim Datentransfer. Da bei beiden Cache-Leveln die zwischengespeicherten Inhalte nur Datenduplikate darstellen, besteht bei einem Ausfall des Systems kein Risiko des Datenverlusts.
Voraussetzungen
ZFS wurde vor allem für Server und den Einsatz in Rechenzentren konzipiert. Daher beansprucht es einige Ressourcen, wozu zwingend ein 64-Bit-Prozessor und ein ausreichend großer Arbeitsspeicher gehören. Für jedes Terabyte Kapazität auf dem Massenspeicher sollte man mit einem GByte RAM kalkulieren. Zwar lässt sich das Dateisystem auch mit geringeren Hardware-Ressourcen nutzen, kann dann jedoch seine Vorteile nicht voll zur Geltung bringen.
Für Heimserver kann sich der Einsatz von ZFS jedoch bereits bei einem aktuellen Computer mit mehreren Festplatten oder SSDs lohnen. Da ZFS komplett mit 128 Bit breiten Zeigern arbeitet, vermag es enorme Speicherkapazitäten ansprechen: Die größtmögliche Kapazität eines ZFS-Dateisystems beträgt 16 Exabyte, wobei die maximale Größe einer Datei identisch ausfällt. Solche Kapazitäten dürfte die Hardware-Industrie nicht so bald ausschöpfen.
Unter Linux
Bislang konnte sich ZFS unter unixoiden Betriebssystemen vor allem bei diversen BSD-Derivaten durchsetzen. So ist es in FreeBSD ab Version 8.0 als stabiles Dateisystem integriert und dient bei PC-BSD als Standard-Dateisystem. Unter Linux stehen der direkten Einbindung in den Kernel bislang lizenzrechtliche Probleme im Weg: Da die vom ursprünglichen Entwickler Sun Microsystems für ZFS genutzte Common Development and Distribution License (CDDL) nicht kompatibel zur unter Linux genutzten GPL ist, lässt sich das Dateisystem nicht direkt in den Kernel-Quellen implementieren.
Daher etablierte sich im Linux-Universum zunächst ZFS on FUSE [2], um ZFS auch unter dem freien Betriebssystem nutzbar zu machen. Dieses Projekt ermöglicht, ZFS im Userspace unter Linux einzusetzen, auch auf 32-Bit-Systemen. ZFS on FUSE liegt allerdings lediglich in einer veralteten ZFS-Version vor, das Projekt wurde bereits vor längerer Zeit eingestellt. Zu den Nachteilen der Lösung zählten einerseits Geschwindigkeitsprobleme und andererseits ein geringerer Sicherheitsstandard aufgrund des Einsatzes im Userspace. Bei vielen Distributionen finden sich jedoch noch entsprechende Binärpakete in den Repositories, darunter auch Lösungen für aktuelle 64-Bit-Prozessoren.
Als wesentlich nachhaltiger hat sich das Projekt ZFS on Linux erwiesen, das ein selbst kompiliertes Kernelmodul einbindet. ZFS on Linux verwendet dabei eine neuere Version von ZFS, was die Kompatibilität zu Solaris 10, FreeBSD und OpenSolaris gewährleistet. Die Software gilt seit Version 0.6.3 als stabil und lässt sich somit in Produktivumgebungen einsetzen. Da seit Version 0.6.3 (Juni 2014) auch nahezu sämtliche Funktionen der Referenzimplementation realisiert sind, wartet ZFS on Linux mit den gleichen innovativen Möglichkeiten auf wie unter Solaris oder FreeBSD. Inzwischen gibt es auch für verschiedene Linux-Distributionen vorkompilierte Pakete [3].
Einen neuen Vorstoß zur stärkeren Verbreitung von ZFS unter Linux unternahm im Winter 2016 Canonical. In einer Ankündigung von Mitte Februar [4] erklärte das Unternehmen hinter Ubuntu, dass ab der kommenden Betriebssystemversion 16.04 LTS “Xenial Xerus” das Dateisystem ZFS fest im Kernel implementiert sein wird. Als Grundlage dient dabei das Kernelmodul von OpenZFS, das seit 2013 entwickelt wird.
Da dieses Kernelmodul jedoch ebenfalls unter der CDD-Lizenz steht, rief die Ankündigung massiven Widerspruch sowohl aus der Community als auch aus der Gruppe der Linux-Entwickler hervor. Auch die Free Software Foundation (FSF) meldete Zweifel an diesem Schritt an. Aus Sicht von Canonical dagegen ist die Integration von ZFS in Linux längst überfällig: Aufgrund seiner technischen Eigenschaften, der hohen Sicherheit und der enormen Kapazitäten eignet sich ZFS ideal als Dateisystem für Cloud-Umgebungen und somit für die Nutzung in Clustern.
In der Praxis
Aufgrund der lizenzrechtlichen Probleme verläuft die Integration von ZFS ins Linux-Universum derzeit nur sehr zögerlich. Die vorhandenen Lösungen eignen sich lediglich für den Einsatz in größeren Umgebungen, während Desktop-Varianten – von einer einzigen Ausnahme abgesehen – bislang ZFS nicht unterstützen.
Canonical hat mit seiner Ankündigung viel Staub aufgewirbelt, ZFS fest in Ubuntu 16.04 LTS zu integrieren. Bei näherem Hinsehen entpuppt sich die “Integration” jedoch als halbfertige Mogelpackung, selbst interessierte Power-User scheitern noch an der praktischen Umsetzung. So fehlt dem Ubuntu-Installer Ubiquity beim Einrichten der Massenspeicher die Option, ZFS zu nutzen.
Anwender müssen also auf die Kommandozeile wechseln und das gesamte System händisch einrichten. Das setzt gute Kenntnisse der Nomenklatur und Funktionsweise von ZFS voraus. Für bereits mit Ubuntu oder dessen offiziellen Derivaten installierte Systeme gibt es zwar mittlerweile im Internet eine Anleitung zur Installation mit virtualisierten Containern, die jedoch für Endnutzer in kleinen Umgebungen und auch für ein Selbstbau-NAS hoffnungslos überdimensioniert ist.
Als Vorreiter in Sachen ZFS-Integration auf dem Linux-Desktop profiliert sich hingegen das Arch-Derivat Antergos. Ohne viel mediales Getöse nahmen die Entwickler der spanischen Distribution eine ebenfalls auf OpenZFS basierende Integration des Sun-Dateisystems vor und passten dabei auch den Installer Cnchi entsprechend an.
Cnchi gestattet zwar bei Weitem nicht die Nutzung des vollen Funktionsumfangs von ZFS, bietet dafür jedoch eine einfache Möglichkeit, das Betriebssystem mit ZFS aus dem Stand sinnvoll zu nutzen. Weitergehende Konfigurationsoptionen können Sie dann bei Bedarf per Kommandozeile setzen. Dabei legen Sie aus dem Live-System heraus bei der Installation von Antergos zunächst fest, ob Sie ein eigenes Home-Volume zusammen mit ZFS nutzen möchten (Abbildung 1).
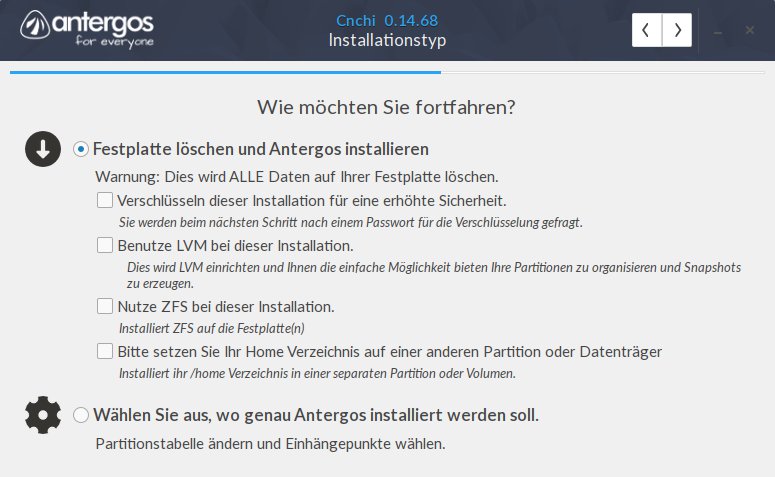
Abbildung 1: Bereits voll integriert ist ZFS in den neuen Cnchi-Installer unter Antergos.
Anschließend fragt der Installer in einem weiteren Schritt die grundlegenden Filesystem-Parameter ab. Hier legen Sie nicht nur die Blockgröße fest, sondern definieren im Bereich Pooltyp auch aus einer Auswahlliste den Betriebsmodus von ZFS. Zur Verfügung stehen verschiedene RAID-Level, sodass Sie in Systemen mit mehreren physischen Massenspeichern auch Datenspiegelung oder Striping aktivieren können (Abbildung 2).
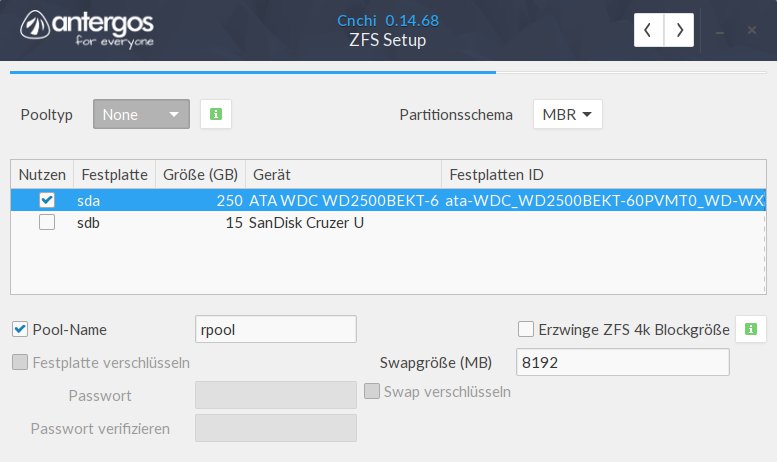
Abbildung 2: Grundlegende Optionen wie RAID-Level oder Blockgröße legen Sie ebenfalls bereits im Antergos-Installer fest.
Beachten Sie bitte, dass Cnchi kontextsensitiv arbeitet: Fehlerhafte oder inkompatible Einstellungen verhindern einen Wechsel zum nächsten Schritt, der jeweils durch einen Klick auf den nach rechts weisenden Pfeil oben rechts im Installerfenster erfolgt. So ist es auch unmöglich, bei Computern mit nur einem physischen Massenspeicher ein RAID-Level als Pooltyp zu definieren: In diesem Fall muss die entsprechende Option auf None eingestellt bleiben.
Antergos richtet zudem ohne weiteres Zutun eine Swap-Partition ein. Es konfiguriert sowohl auf Legacy-BIOS- als auch auf EFI-Systemen den Bootmanager Grub automatisch, sodass keinerlei zusätzliche manuelle Nacharbeiten mehr anfallen. Auch eine mit Ext4 formatierte, lediglich 512 MByte umfassende Boot-Partition legt die Routine an.
Beim ersten Neustart nach der Installation sollten Sie darauf achten, im Bootmanager Grub nicht die alternativen Kernel-Varianten aufzurufen, die Antergos zusätzlich zum Standard-Kernel anbietet: Sie bringen keine ZFS-Unterstützung mit und verursachen daher einen sofortigen Systemstillstand.
Details
Nach der Ersteinrichtung konfigurieren Sie die Parameter von ZFS bei Bedarf per Kommandozeile. Dazu gehören beispielsweise die Datenkomprimierung und die Einrichtung von Quotas, die ZFS ebenfalls beherrscht.
Lediglich zwei Befehle – zfs und zpool – ermöglichen die vollständige Kontrolle und Bearbeitung. Während zfs das Dateisystem konfiguriert, verwalten Sie mithilfe von zpool die Datenträger. Um die Datenkomprimierung für einen Storage-Pool einzuschalten, geben Sie mit Administratorrechten am Prompt folgenden Befehl ein:
# zfs set compression=on Pool
Haben Sie mehrere Storage-Pools angelegt, so finden Sie den passenden samt aktueller Statusdaten über den Befehl zpool list. Nach einem Neustart des Systems fragen Sie die Komprimierungsrate ab, indem Sie folgendes Kommando eintippen:
# zfs get compressratio Pool
Das Dateisystem zeigt anschließend in einer übersichtlichen Liste die entsprechenden Daten im Klartext an. Bei bereits zuvor komprimierten Daten wie Bildern oder Video- und Audio-Dateien lassen sich nur geringe Packraten erzielen. Bei reinen Textdateien klappt das wesentlich besser (Abbildung 3).
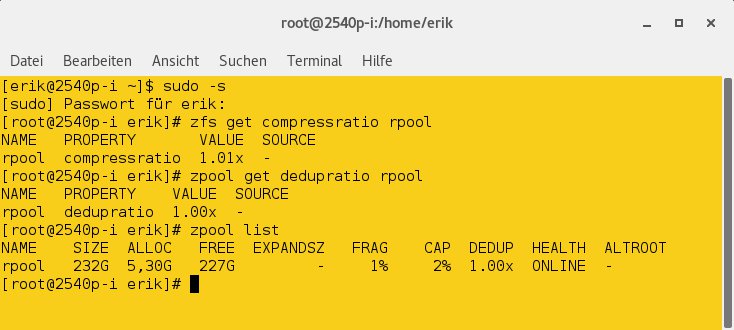
Abbildung 3: Auch die Komprimierung und Deduplikation beherrscht ZFS.
Deduplikation
ZFS beherrscht daneben auch effiziente Mechanismen zur Datendeduplikation. Die Technik dient dazu, die redundante Ablage von Daten zu vermeiden, was ebenfalls Speicherplatz einsparen kann. Sie schalten die Datendeduplikation mithilfe des folgenden Befehls ein:
# zfs set dedup=on Pool
Um im weiteren Verlauf bei der Arbeit mit dem Dateisystem die Deduplikationsrate festzustellen, verwenden Sie folgendes Kommando:
# zpool get dedupratio Pool
Deutlich wahrnehmbare Deduplizierraten erzielen Sie in aller Regel erst bei Arbeitsspeichergrößen von mehr als 4 GByte und bei mehreren Pools. Auch größere Installationen, bei denen in Containern mehrere virtualisierte Betriebssysteme arbeiten, eignen sich besser für die Deduplikation als Desktop-PCs mit nur einem Pool.
Snapshots
Eine weitere gebräuchliche Technik, um die Sicherheit eines Dateisystems zu erhöhen, stellt das Anlegen von Snapshots dar. Während herkömmliche Lösungen nur eine beschränkte Anzahl von Snapshots erlauben, bietet ZFS hier keinerlei Einschränkungen. Dank der Copy-on-Write-Technologie bleiben dabei auch die älteren Daten stets gespeichert, da das Dateisystem neue Datenbestände in freien Speicherblöcken ablegt, statt die vorhandenen zu überschreiben. Mit dem folgenden Befehl legen Sie Snapshots eines Volumes an:
# zfs snapshot Pool/Volume@Snapshot
Das System legt den Snapshot dabei im aktuellen Verzeichnis in einem versteckten Ordner mit der Extension .zfs ab. Zwar erscheint dieser Folder selbst bei Eingabe von ls -lisa nicht in der Liste der Verzeichnisinhalte, Sie können jedoch durch ein schlichtes cd .zfs dorthin wechseln. Hier finden Sie wiederum einen Unterordner snapshot/ vor, der Ihre(n) Snapshot(s) beherbergt.
Die einzelnen Snapshots lassen sich wie herkömmliche Dateihierarchien nutzen, also Dateien daraus aufrufen oder kopieren, und Sie können davon auch Backups anlegen. Damit erweist sich die in ZFS integrierte Snapshot-Technologie als wesentlich flexibler als die Pendants anderer Dateisysteme (Abbildung 4).
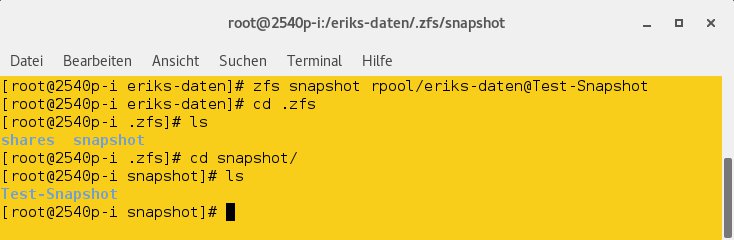
Abbildung 4: ZFS-Snapshots lassen sich sehr einfach im Terminal anlegen und nutzen.
Fazit
Mit ZFS steht eines der innovativsten und modernsten Dateisysteme für unixartige Betriebssysteme bereit. Daher passt das Dateisystem bestens zum ebenfalls innovativen Betriebssystem Linux. Bisherige Beschränkungen durch veraltete Dateisysteme fallen bei ZFS komplett weg; eine ganze Reihe von Zusatzfunktionen wie RAID, Snapshots oder Datenkomprimierung bringt ZFS in einfach zu handhabender Form bereits mit.
Auch auf dem Desktop macht ZFS eine gute Figur. Hier bleibt jedoch abzuwarten, inwiefern sich der noch nicht ganz so ausgereifte, unter Federführung von Oracle entwickelte Konkurrent Btrfs etablieren kann. Auf jeden Fall wird es Zeit, die einschränkenden Lizenzstreitigkeiten rund um ZFS beizulegen und im Interesse qualitätsbewusster Anwender das Dateisystem auch unter Linux in ganzer Breite einsatzfähig zu machen.
Infos
[1] Storage Pools: http://docs.oracle.com/cd/E19253-01/819-5461/gaypk/index.html
[2] ZFS on FUSE: http://zfs-on-fuse.blogspot.co.uk/
[3] ZFS on Linux: http://zfsonlinux.org/
[4] ZFS bei Ubuntu: https://insights.ubuntu.com/2016/02/16/zfs-is-the-fs-for-containers-in-ubuntu-16-04/




