
Bei der Arbeit mit strukturierten Textdateien bietet Miller eine clevere Alternative zu herkömmlichen Werkzeugen wie Grep, Cut, Sed und anderen.
Ein Werkzeug für viele Aufgaben, auch mit strukturierten Dateien – dieses Versprechen versucht Miller (http://johnkerl.org) zu erfüllen. Anstelle langer, von Pipes gesäumten Anweisungen kommen Sie mit kompakteren Konstrukten zum Ziel. Für diesen Beitrag kam Version 3.1.2 zum Einsatz, frisch aus den Quellen kompiliert.
Das Kommandozeilentool Miller unterstützt eine Vielzahl von Formaten (siehe Tabelle “Datenstrukturen”), die es beim Aufruf mit mlr --usage-data-format-examples auflistet. Wollen Sie das Dateiformat für die Ein- und Ausgabe getrennt bestimmen, verwenden Sie ein vorangestelltes i für die Eingabe und ein o für die Ausgabe.
Datenstrukturen
| Typ/Formatangabe | Merkmale |
|---|---|
dkvp |
Bezeichner mit Wertzuweisungen, Komma als Feldtrenner (Variable=Wert,) |
nidx |
numerische Feldbezeichner, Komma als Feldtrenner (1=Wert1,) |
csv |
keine Feldbezeichner, Text optional in Anführungszeichen, Komma als Feldtrenner (a,b,c) |
pprint |
formatierte Ausgabe durch Miller, erzeugt Tabellen |
xtab |
gibt Tabellen vertikal aus, je Zeile ein Feldbezeichner mit einem Wert |
TIPP
Erscheint keine Ausgabe, fehlt Miller der Hinweis auf das Sonderzeichen “Zeilenvorschub”, was besonders bei CSV-Dateien häufig auftritt. Geben Sie mlr --csv --rs lf am Anfang des Kommandos ein, sollte das Verarbeiten klappen.
Um die Teile eines Datensatzes voneinander abzugrenzen, kommt in der Regel ein Komma zum Einsatz. Darüber hinaus besteht die Möglichkeit, diese Angabe getrennt für die Eingabe, die Ausgabe oder beide gemeinsam vorzunehmen. Wiederum erkennen Sie dies am vorangestellten i oder o. Die Tabelle “Trenner” listet die entsprechenden Parameter auf.
Trenner
| Aufgabe | Angabe | Hinweise |
|---|---|---|
| Satztrenner | --rs |
etwa lf oder '\r\n' |
| Feldtrenner | --fs |
etwa ',' oder ';' |
| Paartrenner | --ps |
nur relevant bei DKVP-Dateien |
Die Syntax von mlr verwendet Kommandos mit eigenen Optionen. Diese müssen Sie “bündig” mit dem Kommando absetzen. Die Tabelle “Miller: Kommandoübersicht” zeigt eine Auswahl von Kommandos für mlr. Für die wichtigsten davon stellen wir im Folgenden einige Beispiele vor, wobei als zu verarbeitende Dateien die Files mit den im Kasten “Datenbasis der Beispiele” gezeigten Inhalten dienten.
Miller: Kommandoübersicht
| Kommando | Optionen | Funktion/Hinweise |
|---|---|---|
cat |
wie Shell-Befehl cat |
|
-n |
fügt links eine weitere Spalte mit aufsteigender Nummerierung hinzu | |
-N Name |
wie -n, aber mit Name für die Spalte mit der Nummerierung |
|
decimate |
verwendet jede zehnte Zeile der Daten | |
-n N |
verwendet jede Nte Zeile der Daten |
|
cut |
ähnlich wie Shell-Befehl cut |
|
-f Name,... |
nur die Felder mit diesem Spaltennamen ausgeben | |
-o |
vor -f: die Felder zusätzlich in der angegebenen Reihenfolge ausgeben |
|
-x |
vor -f: die angegebenen Felder nicht ausgeben |
|
filter |
Ausgabe von Datenzeilen mit den angegebenen Merkmalen | |
'FNR == N‘ |
gibt jeweils die Nte Zeile aus |
|
grep |
wie Shell-Befehl grep, aber mit weniger Funktionsumfang |
|
-v |
gibt nicht übereinstimmende Zeilen aus | |
group-by |
gibt identische Zeilen gruppiert aus | |
group-like |
gibt Zeilen mit identischen Bezeichnern aus | |
head |
gibt den Anfang einer Datei aus | |
-n Zeilen |
Anzahl der Zeilen ohne Kopfzeile (obligatorisch) | |
join |
Zeilen zweier Dateien über eine gemeinsame Spalte verbinden | |
-u |
verarbeitet unsortierte Eingaben | |
-j Spalte,... |
Angabe gemeinsamer Felder | |
-f Datei |
Angabe der links stehenden Datei | |
rename Alt,Neu |
Feldbezeichner umbenennen | |
-r |
Angabe des alten Feldnamens als regulärer Ausdruck | |
reorder |
Änderung der Spaltenreihenfolge | |
-f Spalten |
Angabe der Reihenfolge (obligatorisch) | |
–-e |
angegebene Spalten am Schluss der Zeile ausgeben | |
sample |
Ausgabe einer Zahl von Zeilen in beliebiger Position | |
-k Zeilen |
Angabe der Zeilenanzahl, Überschriften nicht eingerechnet | |
sort |
Sortierung | |
-f Name,... |
aufsteigend nach angegebenen Spalten, Zeichen aller Art | |
-f Name,... |
absteigend nach angegebenen Spalten, Zeichen aller Art | |
-nf Name,... |
aufsteigend nach angegebenen Spalten, numerisch | |
-nr Name,... |
absteigend nach angegebenen Spalten, numerisch | |
stats1 |
Berechnungen | |
-a sum -f Spalte,... |
Summe | |
-a count -f Spalte,... |
Anzahl der Datensätze/Zeilen | |
-a mean -f Spalte,... |
Durchschnitt | |
-a min -f Spalte,... |
Minimum | |
-a max -f Spalte,... |
Maximum | |
step |
schrittweise Ausgabe von Rechenergebnissen | |
–-a rsum -f Spalte,... |
Zwischensumme, Ausgabe je Zeile | |
–-a delta -f Spalte,... |
Differenz zwischen zwei aufeinanderfolgenden Zeilen | |
–-a ratio -f Spalte,... |
Verhältnis zweier aufeinanderfolgender Zeilen | |
–-a counter -f Spalte,... |
laufende Ausgabe der Zahl der Datensätze | |
–-a <from-first -f Spalte,... |
Differenz zum ersten ausgegebenen Datensatz | |
tac |
wie Shell-Befehl tac (Ausgabe in umgekehrter Reihenfolge) |
|
tail |
Ausgabe des Dateiendes (Gegenstück zu head) |
|
-n Zeilen |
Anzahl der Zeilen ohne Überschrift | |
top |
Ausgabe von Zeilen/Datensätzen mit dem höchsten oder geringsten numerischen Wert | |
-f Spalte,... |
Angabe der Spalten mit passenden numerischen Werten | |
-a |
alle Spalten einer Zeile ausgeben | |
--min |
Ausgabe des kleinsten numerischen Wertes | |
-n Zeilen |
Anzahl der auszugebenden Zeilen | |
uniq |
gleiche Datensätze zusammengefasst ausgeben | |
-g Spalte,... |
Angabe der auszuwertenden Spalten | |
-n |
nur Zahl der auszugebenden, zusammengefassten Datensätze ermitteln | |
-c |
zu jedem zusammengefassten Datensatz die Zahl seines Vorkommens angeben | |
bar |
Ausgabe numerischer Werte als ASCII-Balkengrafik | |
-f Spalte |
Angabe der Spalte mit den numerischen Werten | |
-c Zeichen |
Angabe des Balkenzeichens (Standard: *) |
|
-x Zeichen |
Angabe des Zeichens für Werte außerhalb des Darstellungsbereichs, (Standard: #) |
|
-b Zeichen |
Angabe des Füllzeichens (Standard: .) |
|
-w Balkenbreite |
Angabe der Balkenbreite, Standard: 40 | |
--lo Wert |
Anfangswert Balkendarstellung | |
--high Wert |
Endwert Balkendarstellung |
Datenbasis der Beispiele
### csv1.txt erste,zweite,dritte a,b,c d,e,f ### csv2.txt erste,zweite,dritte 1,2,3 4,5,6 ### csv3.txt Name,Vorname,Beitrag Müller,Hans,12.34 Meier,Klaus,56.78 Bauer,Stefan,90.12 ### csv4.txt Name,Vorname,Beitrag Schmidt,Johann,12.34 Meier,Klaus,56.78 Albert,Stefan,90.12 ### dkvp1.txt a=1,b=2,c=3 d=4,e=5,f=6 ### dkvp2.txt a=1,b=2,c=3 d=4,e=5 f=7,g=8,h=9
Daten ausgeben
Mit dem Kommando cat lesen Sie Textdateien aus und geben diese – gegebenenfalls entsprechend formatiert – in eine Pipe, eine Datei oder auf dem Bildschirm aus. Mit dem Aufruf aus der ersten Zeile von Listing 1 geben Sie die beiden angegebenen Dateien hintereinander mitsamt der Spaltenüberschriften aus (Abbildung 1). Darüber hinaus fügt Miller eigenmächtig numerische Bezeichner für die Felder hinzu.
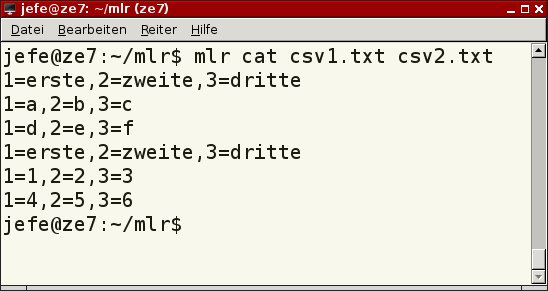
cat gibt ohne weitere Optionen den Inhalt einer Datei aus.” width=”300″ height=”159″ />
Abbildung 1: Das Miller-Kommandocat gibt ohne weitere Optionen den Inhalt einer Datei aus.Listing 1
$ mlr cat csv1.txt csv2.txt $ mlr --csv --rs lf cat csv1.txt csv2.txt $ mlr --opprint cat csv1.txt csv2.txt $ mlr --opprint --csv --rs lf cat csv1.txt csv2.txt $ mlr --csv --rs lf --opprint cat csv1.txt csv2.txt $ mlr --icsv --rs lf --odkvp cat csv1.txt > neudkvp.txt $ mlr --idkvp --ocsv --rs lf cat dkvp1.txt > neucsv.txt $ mlr --icsv --rs lf --oxtab cat csv3.txt > neuxtab.txt
Geben Sie gleichzeitig den Dateityp (hier csv) und das Trennzeichen für die Datensätze den Zeilenvorschub (--rs lf) an, unterlässt Miller die Nummerierung (Listing 1, Zeile 2). Außerdem fasst es identische Spaltenüberschriften zu einer einzigen zusammen (Abbildung 2).
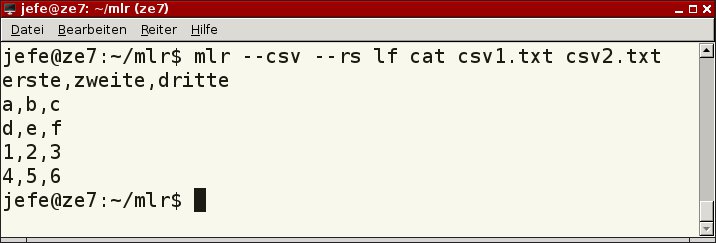
Abbildung 2: Geben Sie den Dateityp und das Trennzeichen für die Datensätze als Parameter an, ermöglicht das eine verbesserte Ausgabe.
Mit der Option --opprint bekommen Sie eine noch übersichtlichere Ausgabe (Listing 1, Zeile 3), die jedoch noch kleine Fehler aufweist. Hier fügt das Programm eigene Spaltenüberschriften ein (Abbildung 3, erste Zeile). Die in den Ausgangsdateien vorhandenen Überschriften listet Miller wie Datensätze auf.
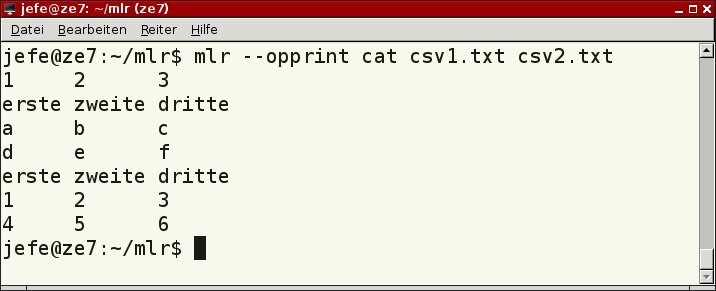
Abbildung 3: Eine optisch etwas aufgewertete Ausgabe überzeugt bis auf kleine Patzer.
Die Reihenfolge der Optionen wirkt sich auf das Ergebnis aus (Abbildung 4). Während mit dem Aufruf aus der vierten Zeile von Listing 1 die Option --opprint anscheinend unbeachtet bleibt, funktioniert es umgekehrt richtig (Listing 1, Zeile 5): Die Software fasst die identischen Überschriften zusammen und zeigt die Werte mit Abstand an, passend zur Überschrift.
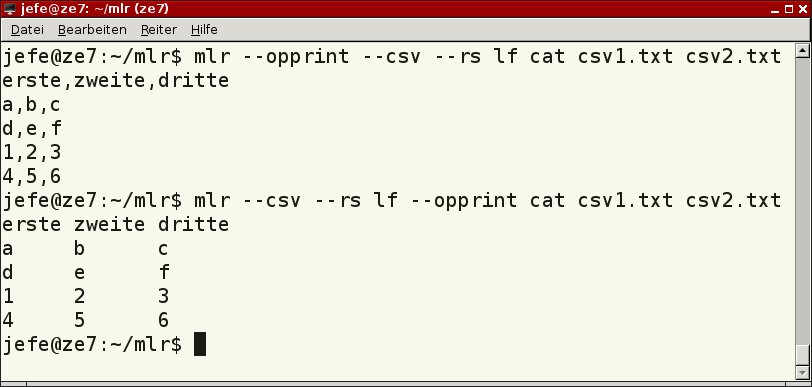
Abbildung 4: Die Reihenfolge, in der Sie die Optionen angeben, hat eine Auswirkung auf das Ergebnis.
Miller konvertiert
Mittels cat konvertiert Miller die in der Tabelle “Datenstrukturen” aufgeführten Formate. Dazu setzen Sie vor die Bezeichnung für die Eingabe ein i, vor die für die Ausgabe ein o. Aus einer CSV-Datei entsteht auf diesem Wege eine im DKVP-Format (Listing 1, Zeile 6). Der umgekehrte Weg funktioniert auf dieselbe Weise (Listing 1, Zeile 7).
Das Umsetzen in die zeilenweise Anzeige (XTAB-Format) erweist sich beispielsweise beim Erstellen von Nicht-GUI-Anwendungen als sehr hilfreich, etwa bei einer Abfrage von Adressen (Listing 1, Zeile 8). Die abgearbeiteten Beispiele finden Sie in der Abbildung 5.
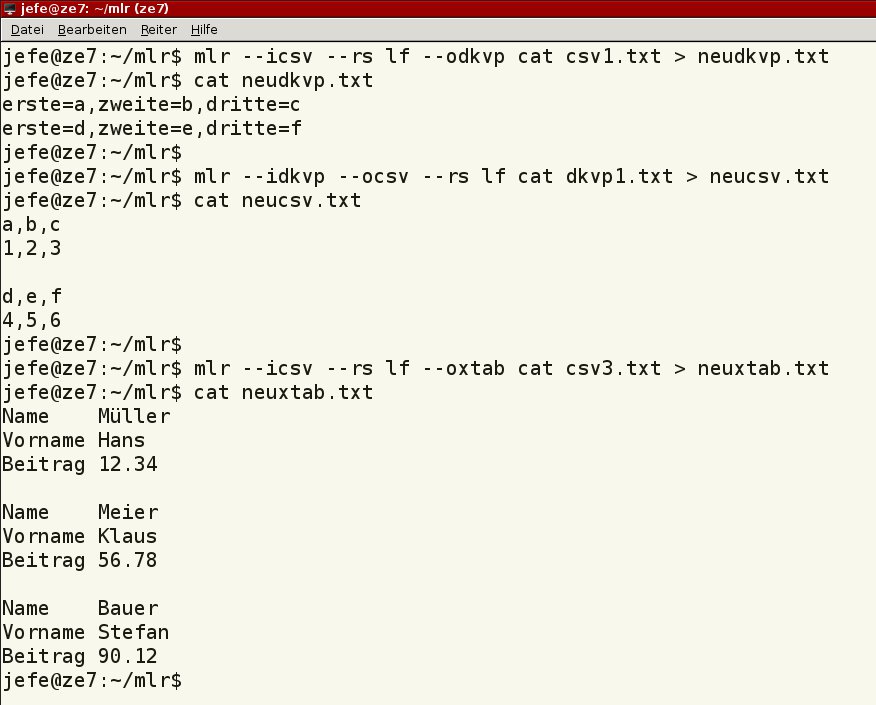
Abbildung 5: Miller konvertiert Datenstrukturen auf einfache Weise von einem Format in ein anderes.
Suchen und finden
Für das Durchsuchen von strukturierten Textdateien verfügt Miller über die Kommandos grep und filter. Letzteres kennt eine Vielzahl von Möglichkeiten, besonders hinsichtlich numerischer Auswertungen. Dabei gibt die Software stets die Kopfzeile mit aus.
Das Beispiel aus den ersten beiden Zeilen von Listing 2 zeigt das Durchsuchen der Datei csv3.txt nach dem Namen “Meier”. Beim Kommando filter geben Sie die Spalte an, mit grep brauchen Sie das nicht. Insoweit arbeitet die erste Methode präziser, da der Suchbegriff ja möglicherweise in mehreren Spalten steckt.
Listing 2
$ mlr --csv --rs lf filter '($Name == "Meier")' csv3.txt $ mlr --csv --rs lf grep 'Meier' csv3.txt $ mlr --csv --rs lf filter '($Beitrag > 20)' csv3.txt
Das Beispiel in der letzten Zeile von Listing 2 dreht sich um das Ergebnis einer numerischen Auswertung. Dabei extrahiert Miller aus cvs3.txt alle Beiträge, die 20 Euro übersteigen.
Abbildung 6 zeigt die drei Kommandos sowie die daraus resultierenden Ausgaben.
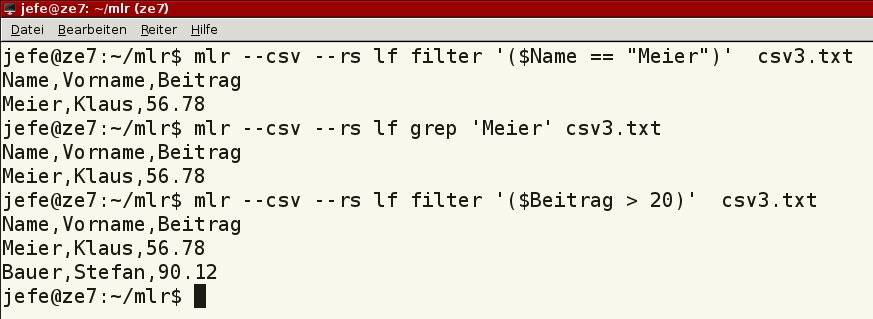
filter und grep bieten einen einfachen Weg, um spezielle Datensätze aus den Feldern zu extrahieren.” width=”300″ height=”110″ />
filter und grep bieten einen einfachen Weg, um spezielle Datensätze aus den Feldern zu extrahieren.Ordnen und sortieren
Mit den Miller-Kommandos group-by, group-like, head, join, rename, reorder, sample, sort, tail und uniq sortieren und gruppieren Sie Daten.
Das Beispiel aus Abbildung 7 demonstriert den Unterschied zwischen den Kommandos group-by und join (Listing 3, Zeile 1 und 2). Ersteres fasst gleiche Zeilen zusammen, Letzteres gibt nur die übereinstimmenden aus. Bei join geben Sie die Option -u mit an, um beliebig sortierte Dateien zu verarbeiten.
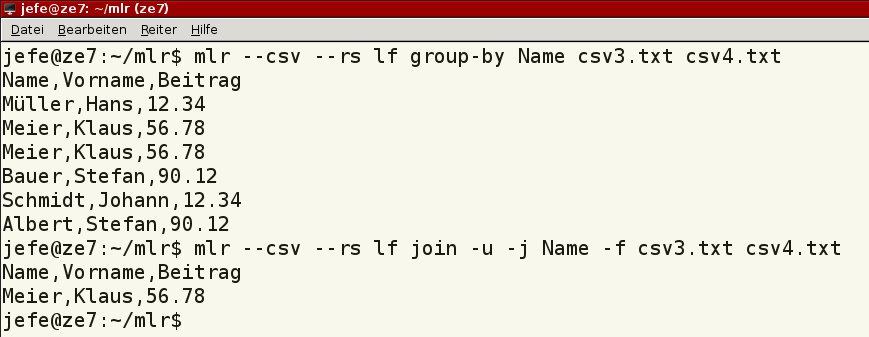
group-by und join erlauben es, Zeilen mit gleichen Inhalten zusammenzufassen.” width=”300″ height=”116″ />
group-by und join erlauben es, Zeilen mit gleichen Inhalten zusammenzufassen.Listing 3
$ mlr --csv --rs lf group-by Name csv3.txt csv4.txt $ mlr --csv --rs lf join -u -j Name -f csv3.txt csv4.txt $ mlr --csv --rs lf head -n 1 csv3.txt $ mlr --csv --rs lf tail -n 1 csv3.txt
Beachten Sie, dass beide Methoden die Angabe der Spalte benötigen, nach der sich die Ausgabe richtet. Außerdem gibt Miller stets Kopfzeilen mit aus. Dies gilt es bei zeilenorientierten Anweisungen wie denen aus den letzten beiden Zeilen von Listing 3 zu beachten, deren Ergebnis Abbildung 8 zeigt. Stören die Kopfzeilen bei der Weiterverarbeitung, greifen Sie einfach auf die Originalbefehle des Betriebssystems zurück.
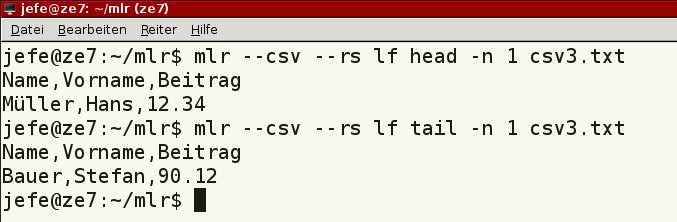
Abbildung 8: Stören die Kopfzeilen beim weiteren Verarbeiten, greifen Sie auf die klassischen Unix-Tools mit ähnlicher Funktion zurück.
Wenn Sie mittels rename die Namen der Spalten ändern möchten, geben Sie die Bezeichner in der Form AlterName,NeuerName an. Das funktioniert zwar auch für mehrere Bezeichner gleichzeitig, sieht aber zuweilen unübersichtlich aus, da Sie die Namen bündig und nur durch ein Komma getrennt angeben müssen.
Achten Sie darauf, dass die Zahl der alten und neuen Spaltenbezeichner immer geradzahlig sein muss – dann haben Sie nichts vergessen. An der Benennung der Felder in der Kopfzeile der Datei ändert sich durch den Befehl nichts, die neuen Namen tauchen nur in der Ausgabe auf. Die erste Zeile von Listing 4 zeigt ein Beispiel für eine solche Umbenennung, wobei die Option --opprint für eine übersichtlichere Optik sorgt.
Listing 4
$ mlr --csv --rs lf --opprint rename Name,Familienname,Beitrag,Jahresbeitrag csv3.txt $ mlr --csv --rs lf reorder -f Beitrag,Vorname,Name csv3.txt $ mlr --csv --rs lf sort -f Name,Vorname csv3.txt csv4.txt $ mlr --csv --rs lf --opprint uniq -c -g Name,Vorname,Beitrag csv3.txt csv4.txt
Zum Umstellen der Spaltenposition brauchen Sie das Kommando reorder. Geben Sie alle vorhandenen Spaltennamen an (Listing 4, Zeile 2), kommt die Ausgabe in der gewünschten Reihenfolge zustande. Andernfalls stellt Miller die Änderungen an das Ende oder den Anfang. Zwei entsprechende Beispiele finden Sie in Abbildung 9.
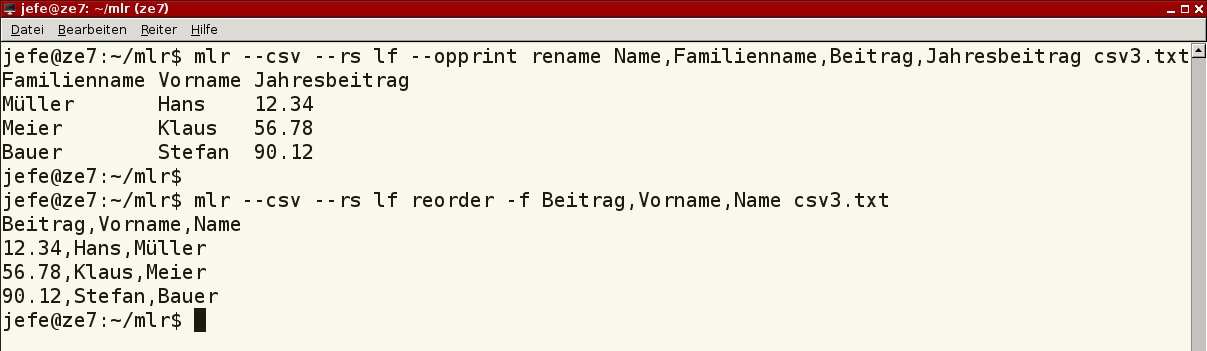
–opprint für mehr Übersicht.” width=”300″ height=”87″ />
Abbildung 9: Bei Bedarf ändern Sie die Namen der Spalten und deren Reihenfolge. Im Beispiel sorgt die Option--opprint für mehr Übersicht. Mittels der Kommandos sort und uniq nehmen Sie Einfluss auf die Reihung der Datensätze beziehungsweise Zeilen. Während Sie mit sort ähnlich group-by gleichwertige Zeilen in der Reihung hintereinander ausgeben, fasst uniq diese zusammen (Listing 4, Zeile 3 und 4).
Für das Anwendungsbeispiel mit uniq kommt auch dessen Option -c zum Einsatz. Sie erhalten damit eine Zählung der Häufigkeit von identischen Zeilen. Abbildung 10 zeigt die entsprechenden Beispiele.
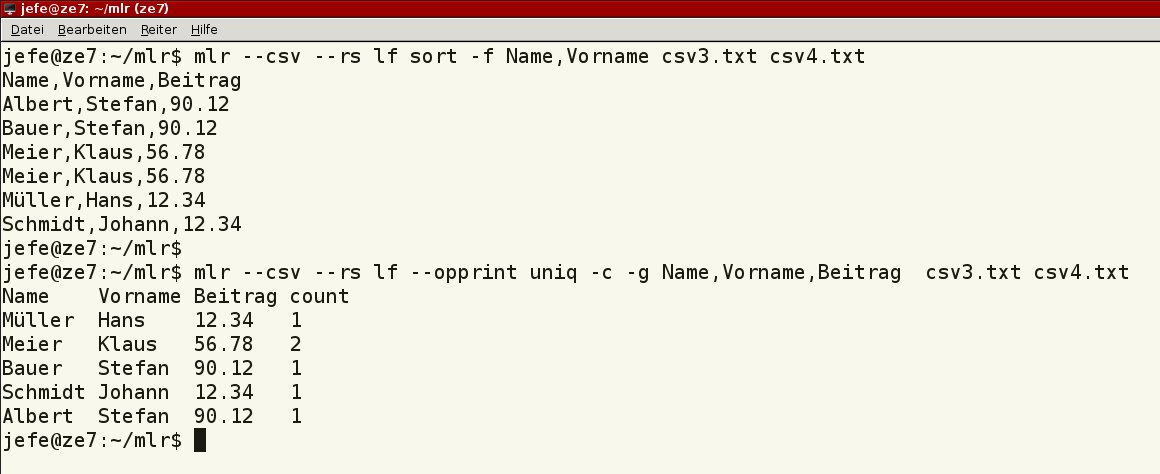
sort und uniq zurück.” width=”300″ height=”123″ />
sort und uniq zurück.Miller rechnet
Für Berechnungen und statistische Auswertungen bietet Miller unter anderem die Kommandos stats1, step und top an. Mittels stats1 nehmen Sie zusammenfassende statistische Auswertungen vor. Die Befehle in Listing 5 ermitteln die Summe, die Anzahl, den Durchschnitt, das Minimum und das Maximum aus der Spalte Beitrag; in Abbildung 11 sehen Sie die Codezeilen mit den Ergebnissen.
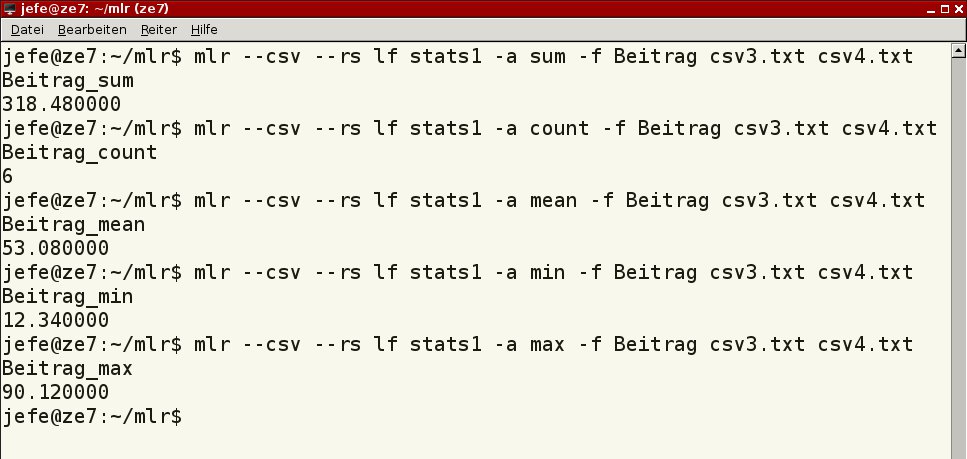
Abbildung 11: Möchten Sie einfache Berechnungen vornehmen, lässt sich Miller auch dazu einspannen.
Listing 5
$ mlr --csv --rs lf stats1 -a sum -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf stats1 -a count -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf stats1 -a mean -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf stats1 -a min -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf stats1 -a max -f Beitrag csv3.txt csv4.txt
Mittels step erhalten Sie zu jeder Zeile Auswertungen. Die jeweils aufgelaufene Summe je Zeile ermittelt rsum. Den Unterschied zwischen zwei aufeinanderfolgenden Zeilen erhalten Sie durch delta, das Verhältnis mittels ratio.
Eine laufende Zählung der ausgegebenen Zeilen bewirkt counter. Die Differenz zwischen der ersten und n-ten Zeile gibt from-first aus. Beispiele für solche Kommandos finden Sie in Listing 6, Abbildung 12 zeigt wie Miller diese abarbeitet.
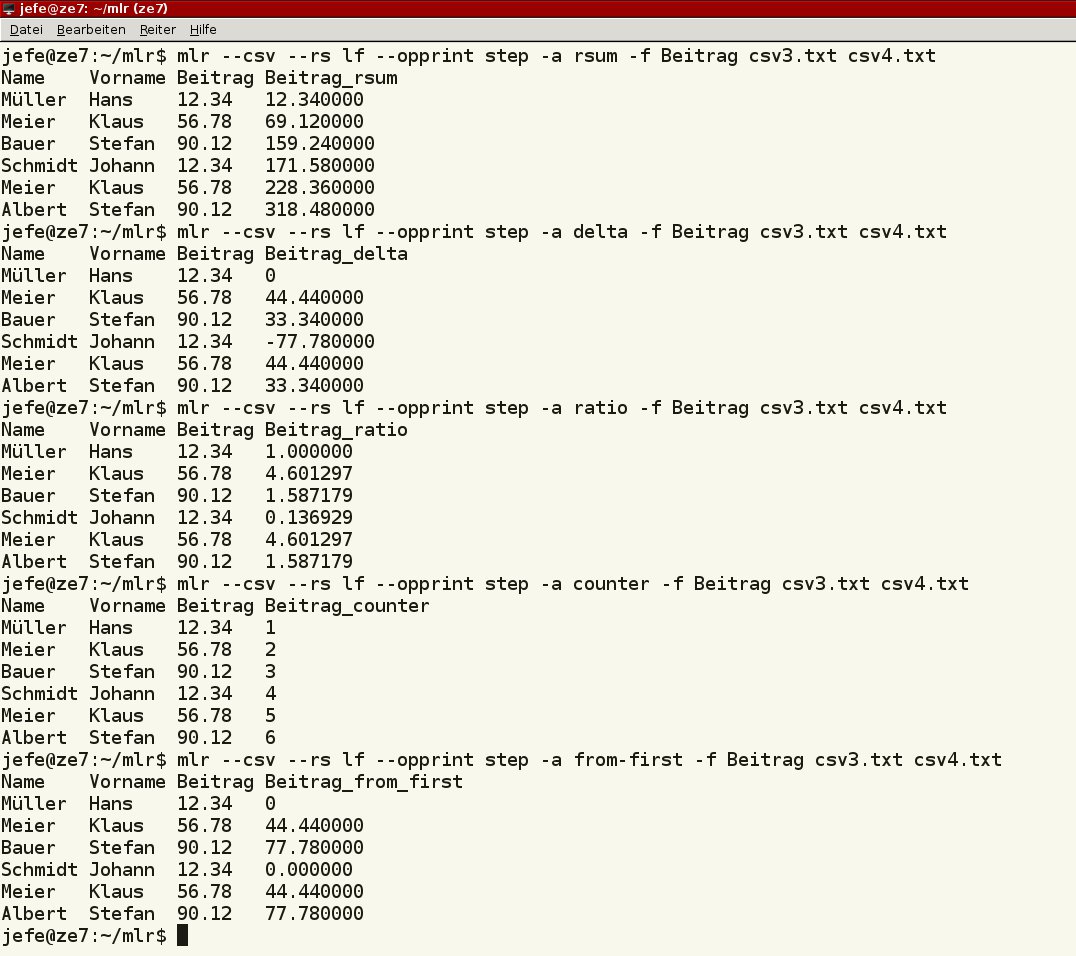
Abbildung 12: Zeilenweise Berechnungen erledigen Sie mit den entsprechenden Operatoren.
Listing 6
$ mlr --csv --rs lf --opprint step -a rsum -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf --opprint step -a delta -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf --opprint step -a ratio -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf --opprint step -a counter -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf --opprint step -a from-first -f Beitrag csv3.txt csv4.txt
Mithilfe von top ermitteln Sie den höchsten numerischen Wert einer Spalte. Um dabei die vollständige Zeile auszugeben, verwenden Sie die Option -a. Mit --min erhalten Sie stattdessen das Minimum. Möchten Sie mehrere Zeilen nach Wert geordnet ausgeben, verwenden Sie -n Zeilen (Listing 7), den Ablauf entnehmen Sie Abbildung 13.
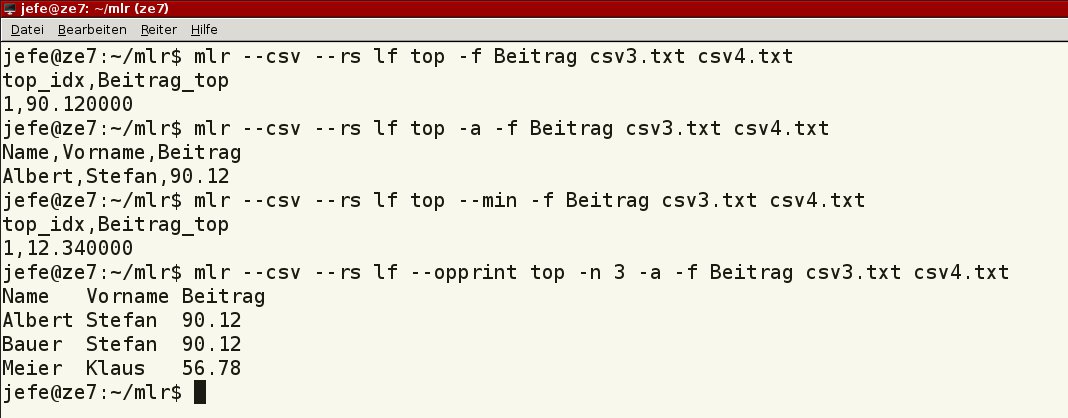
Abbildung 13: Ausgabe des höchsten oder kleinsten Wertes einer Spalte mittels des entsprechenden Operators.
Listing 7
$ mlr --csv --rs lf top -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf top -a -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf top --min -f Beitrag csv3.txt csv4.txt $ mlr --csv --rs lf --opprint top -n 3 -a -f Beitrag csv3.txt csv4.txt
Anschauliche Daten
Numerische Werte veranschaulichen Sie mit dem Kommando bar. Durch die Optionen --lo (Beginn Anzeige), --hi (Maximalwert) und -w (Stellenanzahl Anzeige) bringen Sie das Ergebnis passend auf den Bildschirm oder das Blatt (Listing 8). Abbildung 14 zeigt das Ergebnis der Begrenzungen des zweiten Beispiels (“Überlaufzeichen”).
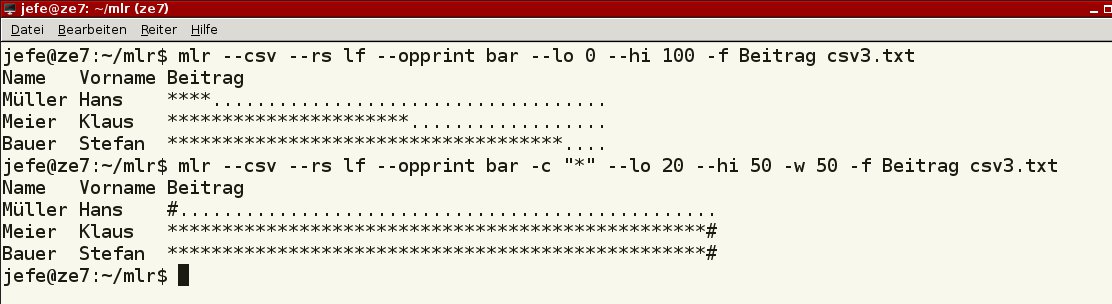
bar erzeugen Sie einfache Balkendiagramme aus den Daten.” width=”300″ height=”82″ />
Abbildung 14: Mit dem Befehlbar erzeugen Sie einfache Balkendiagramme aus den Daten.Listing 8
$ mlr --csv --rs lf --opprint bar --lo 0 --hi 100 -f Beitrag csv3.txt $ mlr --csv --rs lf --opprint bar -c "*" --lo 20 --hi 50 -w 50 -f Beitrag csv3.txt csv4.txt
Je nach Verwendung macht hier unter Umständen Probleme, dass Sie eine Spalte entweder mit bar als “Grafik” oder mit ihrem numerischen Wert ausgeben lassen können, nicht aber beides. Abhilfe schafft hier die doppelte Verwendung der Daten mit verschiedenen Namen für die Spalten.
Ein Beispiel dazu zeigt Listing 9, das die Belegung der Ordner im Home-Verzeichnis ermittelt und zweimal in die Ausgabedatei belegung.txt ausgibt, einmal in die Spalte Belegung(MB) und zusätzlich in die Spalte Wert. Dabei kommt zusätzlich ein abweichendes Trennzeichen für die Felder zum Einsatz. Anschließend wertet das Skript die Ergebnisdatei mittels Miller aus.
Ein Beispiel für eine entsprechende Ausgabedatei zeigt Listing 10, in Abbildung 15 sehen Sie das Resultat der Auswertung durch Miller.
Listing 9
#! /bin/sh # Plattenbelegung ermitteln ... echo "VZ-Name:Belegung(MB):Wert" > /home/tmp/belegung.txt cd /home for i in $(ls -1 /home); do # ... und als CSV speichern k=$(du -shm $i | cut -f1) echo $i:$k:$k >> /home/tmp/belegung.txt done # Ausgabe formatieren mlr --csv --ifs : --rs lf --opprint \ bar -c "*" --lo 0 --hi 500 -w 50 \ -f Wert /home/tmp/belegung.txt
Listing 10
VZ-Name:Belegung(MB):Wert jefe:108:108 tmp:1:1
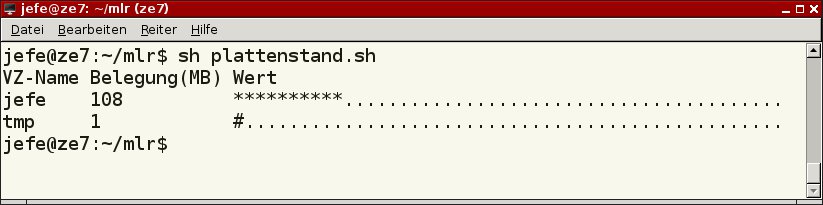
Abbildung 15: Ein Beispiel aus der Praxis zeigt die Fähigkeiten von Miller anhand der Berechnung des verbleibenden Platzes auf den Festplatten.
Fazit
John Kerl hat seinem Programm Miller eine sehr umfangreiche Dokumentation beigelegt. Sowohl das Handbuch als auch die Optionen für die Hilfe liefern gute Hinweise für die Arbeit. Der Quelltext des Tools und viele weitere Informationen liegen auf der Webseite zum Download parat.
Miller eignet sich zum Konvertieren, zum optischen Aufwerten der Ausgabe von strukturierten Textdateien und für viele weitere Sortier- und Auswertungsaufgaben. Die einzelnen Kommandos bieten allerdings nicht dieselbe Funktionsvielfalt wie ihre meist gleichnamigen Unix-Kollegen.
Der Autor
Harald Zisler beschäftigt sich seit Langem mit FreeBSD und Linux. Zu Technik- und EDV-Themen verfasst er Bücher und Beiträge für Zeitschriften. Aktuell hat er die dritte Auflage von “Computer-Netzwerke” beim Rheinwerk Verlag, veröffentlicht. Rund um den Themenbereich Linux und Datenbanken führt er Kurse durch.




