

Der Traum ist so alt wie der PC auf dem Schreibtisch: Im papierlosen Büro sollen Akten nur noch digital im Rechner vorliegen. Für die Verwaltung des papierlosen Büros wurde Paperwork entwickelt.
Die Idee von Paperwork [1] geht auf den Wunsch nach dem papierlosen Büro zurück: Sie scannen eingehende Briefe, Rechnungen und lose herumfliegende Blätter oder erzeugen auf andere Weise PDF- und JPEG-Dateien der Unterlagen. Diese schicken Sie anschließend durch eine OCR-Texterkennung, die den Inhalt in digitale Form bringt. Anschließend fasst eine Anwendung Bilddaten und Text in überlagerter Form zusammen und sichert sie als PDF.
Bei diesem Verfahren gilt es jedoch, einige Klippen zu umschiffen: Für eine ausreichend gute Texterkennung benötigen Sie möglichst hochwertige Scans oder Fotografien der Textseiten – ein guter Scanner mit mindestens 600 dpi Auflösung ist daher Pflicht. Aber auch die OCR-Software muss ihre Aufgabe erfüllen. Paperwork sucht beim Start zunächst nach Tesseract [2]. Findet es diese sehr leistungsfähige OCR-Engine nicht, greift das Programm auf Cuneiform zurück. In den meisten Fällen erzielen Sie mit Tesseract die besten Ergebnisse.
Installation
Unter Arch Linux installieren Sie Paperwork bequem aus dem AUR. Unter Ubuntu finden Sie Paperwork aktuell noch nicht in den Paketquellen, auch ein PPA fehlt bislang. Das Ubuntuusers.de-Wiki erklärt Ihnen jedoch, wie Sie Paperwork unter Ubuntu aus dem Quellcode kompilieren [3]. Alternativ finden Sie im GitHub des Entwicklers eine englischsprachige Installationsanleitung [4].
Paperwork basiert im Wesentlichen auf vier Komponenten: Zum Scannen der Unterlagen greift Paperwork auf Sane zurück. Die Texterkennung übernehmen Tesseract oder Cuneiform. Whoosh [5] indiziert die per OCR umgewandelten Texte, sodass sie sich gut durchsuchen lassen, zudem generiert das Werkzeug automatisch Vorschläge für Schlüsselwörter. Das Ganze fasst Paperwork dann in einer mit GTK/Glade entwickelten grafischen Oberfläche zusammen.
Die bevorzugt eingesetzte OCR-Engine Tesseract stammt ursprünglich von Hewlett-Packard. Google benutzt die quelloffene Bibliothek etwa zum Digitalisieren von Büchern [6]. Die Software zeichnet sich durch eine hohe Erkennungsrate und weitestgehende Automatisierung aus. Ein Nachteil: Tesseract verarbeitet ausschließlich unkomprimierte TIFF-Eingabedateien, Dokumente gilt es daher gegebenenfalls zu konvertieren.
Das papierlose Büro mit Paperwork
Nach dem Start zeigt Paperwork eine übersichtlich gestaltete Oberfläche mit drei Abschnitten an. Links finden Sie das aktuelle Dokument, daneben die bereits vorhandenen, gescannten und bearbeiteten Seiten, rechts die aktuelle Seite im Detail. Wie der PDF-Scanner GScan2PDF [7] holt sich Paperwork Dokumente direkt aus einem angeschlossenen Scanner oder lädt bereits vorliegende Bilder von der Festplatte.
Die Software fasst eingescannte Bilder als Projekte zusammen und exportiert sie anschließend als PDF-Datei. In der Grundeinstellung speichert Paperwork die Projekte im Ordner papers als Unterverzeichnis mit dem aktuellen Datum als Name (zum Beispiel 20140605_1350_31/). In diesen Verzeichnissen legt es mehrere Dateien an: Unter paper.Nummer.jpg finden Sie JPEG-Bilder der eingescannten Seite, paper.Nummer.words beinhaltet den durch die OCR-Maschine extrahierten Text.
Diese Texte liegen allerdings nicht als einfache Textdateien vor, sondern in Form von speziellen XML-Dateien im hOCR-Format [8], in denen neben dem reinen Text auch die Position im ursprünglichen Dokument vermerkt ist. Im Texteditor lassen sich diese Dateien nur schlecht lesen, dafür kann man die extrahierten Texte exakt über die Bilddateien legen. Das speziell für gescannte Dokumente entwickelte Dokumentenformat Djvu [9] baut auf dieser Konstruktion auf.
Weiterhin speichert Paperwork im Verzeichnis noch Vorschaubilder der eingelesenen Seiten. Sie erkennen diese an dem Namensbestandteil thumb. Mit labels benannte Dateien nehmen manuell zugewiesene Labels für das Dokument auf, eine als extra.txt abgespeicherte Datei enthält die von Ihnen zusätzlich vergebenen Stichwörter.
Paperwork unterstützt mehrere Quellen zum Einlesen von Dokumenten: Aus der Anwendung lässt sich direkt ein Scanner ansteuern, den das Programm auch selbstständig über das Sane-Backend zu finden versucht. Alternativ unterstützt Paperwork per USB angeschlossene Webcams, was aber bei der normalerweise geringen Auflösung und Qualität meist keine gute Lösung darstellt. Zum anderen nutzt Paperwork auf beliebige Art erstellte Bilder als Quelle, etwa Screenshots von PDFs. Aufgrund mangelnder Qualität liefert die OCR-Engine hier aber nur selten vernünftige Ergebnisse.
Daneben erlaubt Paperwork auch das direkte Bearbeiten von PDF-Dateien. Diese laden Sie über Dokument | Datei(en) importieren ins Programm. Paperwork importiert bei Bedarf gleich mehrere PDFs in einem Rutsch, allerdings nicht rekursiv aus Unterverzeichnissen. Legen Sie daher die zu importierenden Daten gesammelt in ein Verzeichnis ab.
Texterkennung einrichten
Bevor Sie mit dem Einlesen der Dokumente beginnen, sollten Sie das Programm grundlegend einrichten (Abbildung 1). In der Werkzeugleiste finden Sie den entsprechenden Schalter als vierten von links. Neben dem Arbeitsverzeichnis konfigurieren Sie hier den Scanner und bestimmen die Sprache für die Texterkennung. Paperwork speichert die Einstellungen in der Datei ~/.config/paperwork.conf, den Index aller eingelesenen Dokumente schreibt es nach ~/.local/share/paperwork/index/.
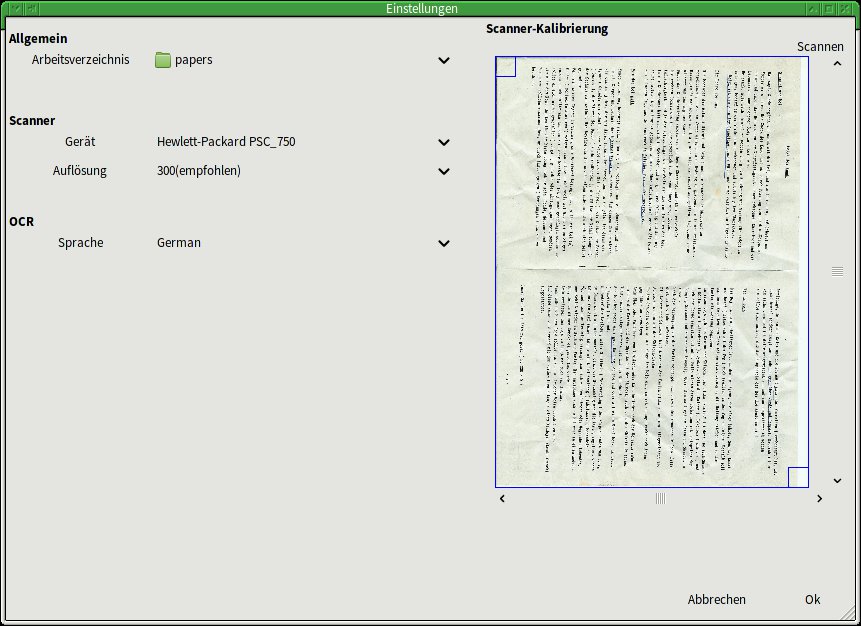
Abbildung 1: Die Konfiguration von Paperwork beschränkt sich auf einige wenige Einstellungen.
Das Kalibrieren des Scanners erfolgt im Einstellungsdialog durch einen Mausklick auf das Symbol auf der rechten Seite. Paperwork beginnt daraufhin einen Scan, den es als Basis für die weiteren Eingaben mit diesem Gerät verwendet. Wie gut das klappt, hängt nicht zuletzt auch von den eingesetzten Fonts ab.
Abbildung 2 zeigt ein Beispiel, in dem die OCR von Paperwork trotz schräg eingescanntem Text das Dokument fast vollständig erkannte. Welche Wörter wie entziffert wurden, zeigt die Funktion Alle Wörter hervorheben im Menü Dokument unter Erweitert durch blaue Rahmen an. Ob der erzeugte Klartext nun aber auch wirklich stimmt, dass müssen Sie von Hand prüfen.
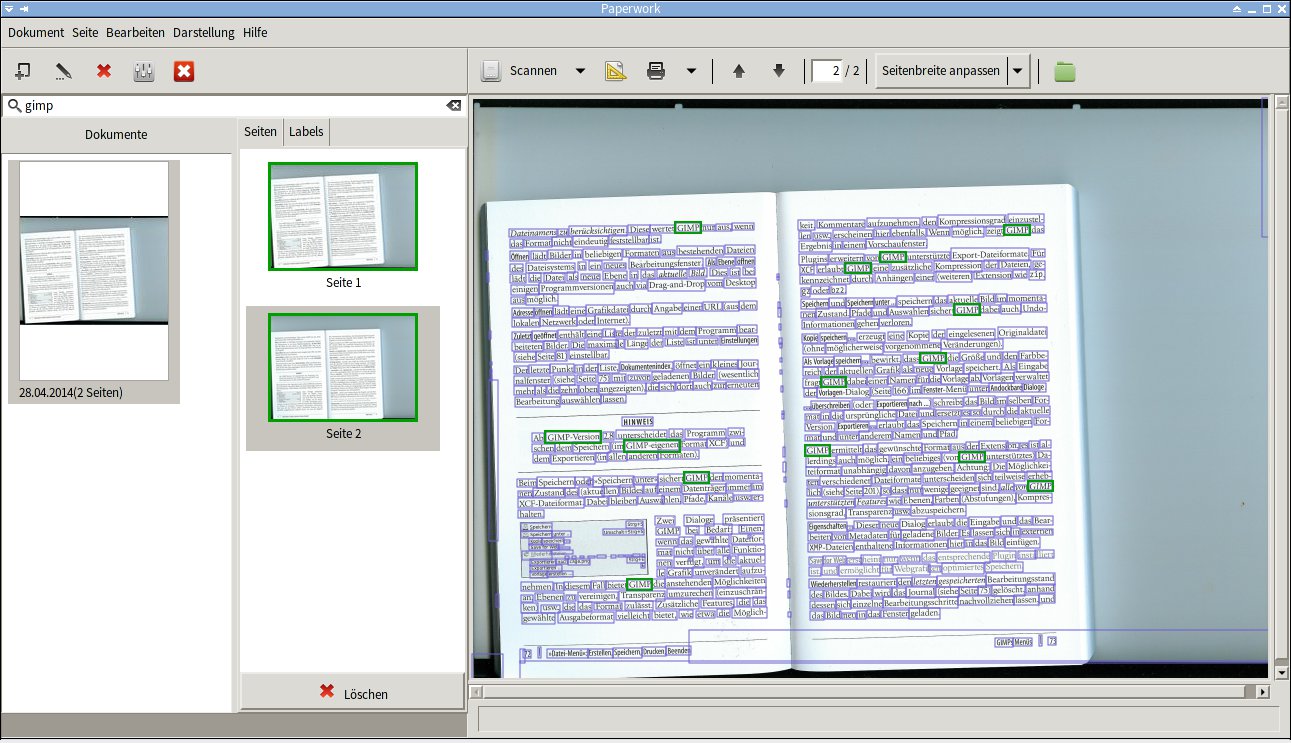
Abbildung 2: Die Texterkennung von Paperwork erzielt auch bei schlecht eingescannten Unterlagen gute Trefferquoten.
In Abbildung 3 versucht sich Paperwork an einem aus OpenOffice heraus generierten PDF. Dieses bietet eigentlich bessere Voraussetzungen als ein per Scanner eingelesenes Dokument, doch das Ergebnis zeigt viele nicht erkannte Wörter, hier bleibt die Markierung mit einem blauen Rahmen aus. Durch Eingrenzen des von der OCR-Engine bearbeiteten Bereichs unter Dokument | Bearbeiten lässt sich das Ergebnis oft optimieren (Abbildung 4), dabei startet allerdings jedes Mal auch ein neuer zeitraubender OCR-Lauf.
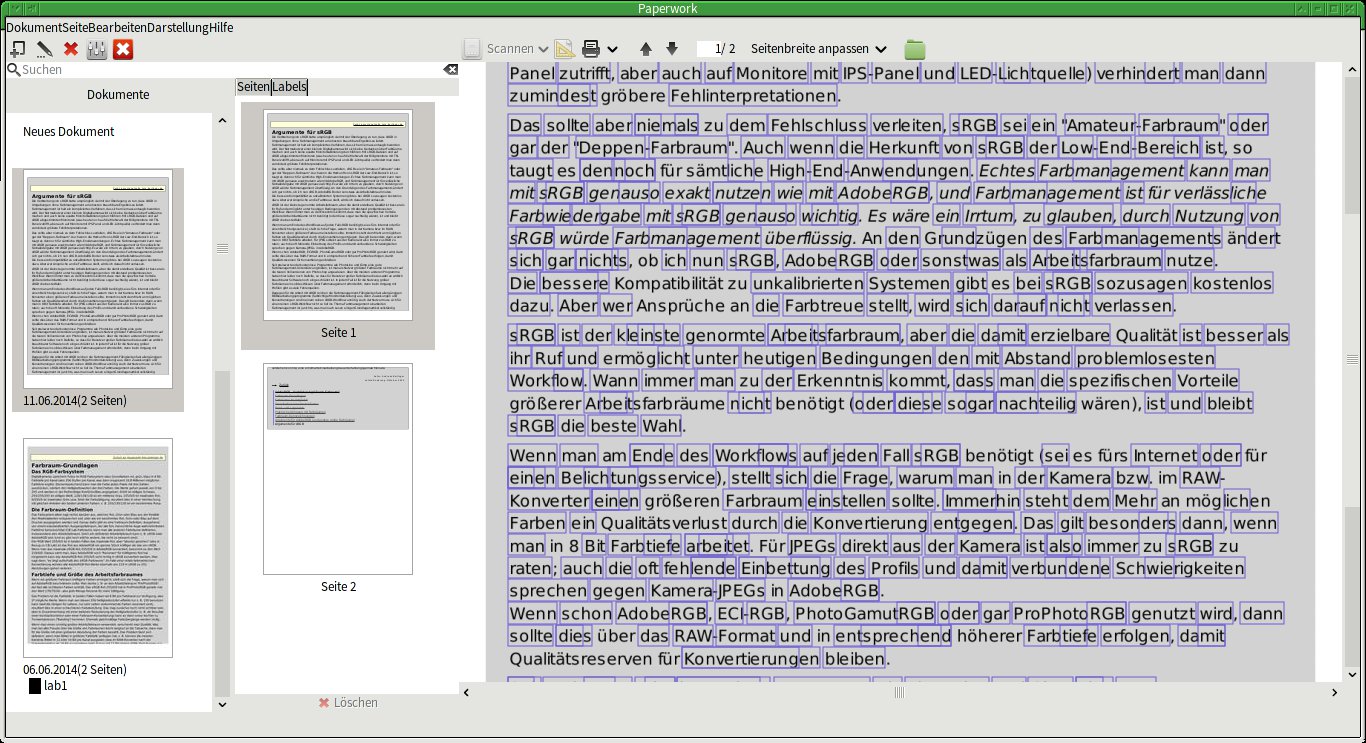
Abbildung 3: Textpassagen ohne blaue Umrandung wurden von der Paperwork-Texterkennung nicht als Text erfasst.

Abbildung 4: Durch gezieltes Eingrenzen des zu bearbeitenden Bereichs im Bild optimieren Sie die Texterkennung.
Eingescannte Dokumente durchsuchen
Paperwork bleibt nicht beim Erfassen von Dokumenten stehen: Für das papierlose Büro braucht es eine Suchfunktion, und die bringt Paperwork auch mit. Die erkannten Texte speichert das Programm in einem von außen nicht zugänglichen Index ab. Aus Paperwork heraus durchsuchen Sie diesen anhand von Schlüsselwörtern. Das entsprechende Eingabefeld finden Sie links oben unterhalb der Werkzeugleiste. Paperwork zeigt die passenden Dokumente an und markiert die Treffer im Text direkt im rechts angezeigten Dokument (Abbildung 5). Ein Tooltip zeigt, wie Sie die Suche auf ein bestimmtes Datum beschränken oder Suchbegriffe mit booleschen Operatoren verknüpfen.
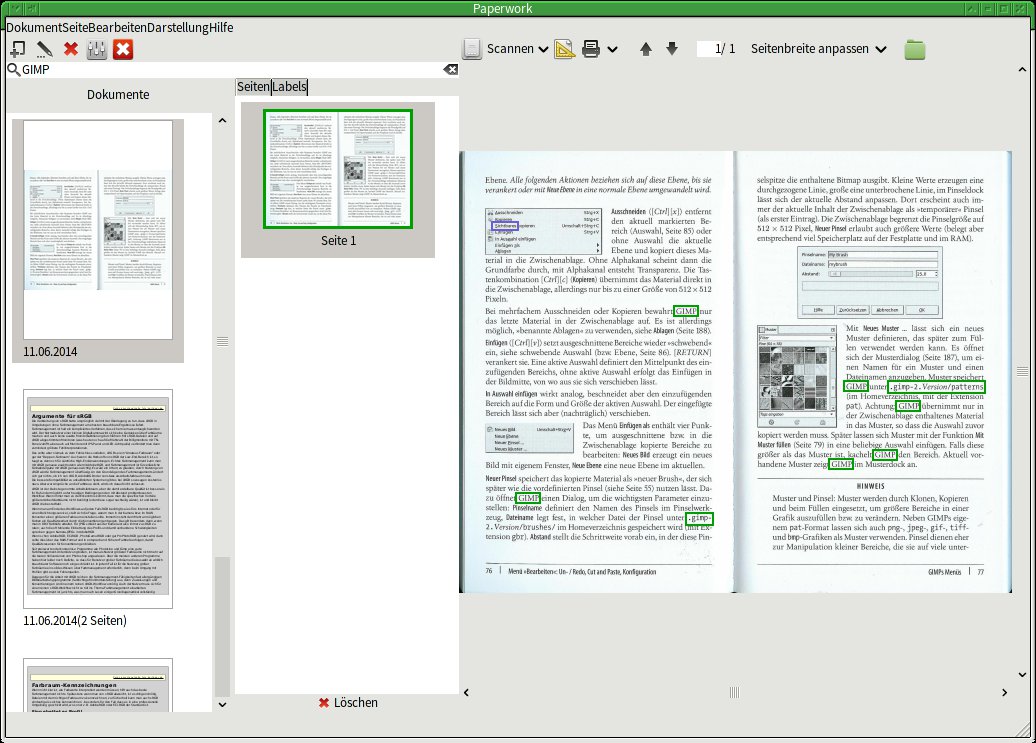
Abbildung 5: Mit der Suchfunktion finden Sie innerhalb der indizierten Dokumente schnell das gewünschte.
Neben den per Automatik generierten Schlüsselwörtern weisen Sie jedem Dokument zusätzliche Schlüsselwörter (“Labels”) zu, die im Text gar nicht vorkommen müssen. In der Suche nutzen Sie diese von Hand gesetzten Labels mit dem Begriff label:Begriff, optional auch zusätzlich zum Suchbegriff. Die Label verwaltet Paperwork in einer zusätzlichen Datei mit dem Namen labels im Dokumentenverzeichnis. Weitere Stichwörter markieren Sie im aktuellen Dokument über den Schalter mit einem Stift-Symbol oben links in der Werkzeugleiste. Diese Daten schreibt Paperwork in die Datei mit dem Namen extra.txt.
Auf Wunsch exportiert Paperwork die fertig bearbeiteten Dokumente als PDF. Eigentlich sollte auch die Ausgabe in das Djvu-Format möglich sein, was aber in unseren Tests nicht funktionierte. Nachträglich klappt es etwa mit pdf2hocr [10] oder pdfsandwich [11]. Daneben bietet Paperwork auch eine Option zum Drucken der archivierten Unterlagen – für das papierlose Büro sollten Sie auf diese Funktion jedoch nur im Ausnahmefall zurückgreifen.
Fazit
Noch erweist sich Paperwork als zu wenig ausgereift, um die Papierflut im Büro einzudämmen. Daher dürfte das Programm momentan in erster Linie für Python-Programmierer von Interesse sein, besteht es doch hauptsächlich aus Modulen in dieser Sprache.
Suchen Sie ein gutes Scan-Programm mit integrierter OCR-Funktion, sollten Sie eher zu GScan2PDF [7] greifen, das bereits auf stabileren Füßen steht. So finden Sie dort beispielsweise deutlich mehr Möglichkeiten, die gescannten Dokumente für die OCR-Bearbeitung vorzubereiten.
Das Alleinstellungsmerkmal von Paperwork – die Indexfunktion für die im Lauf der Zeit eingescannten Dokumente – lässt sich mindesten ebenso gut durch Recoll [12] realisieren. Die Desktop-Suchmaschine beherrscht nicht nur den Umgang mit indexierten PDF-Dokumenten, sondern bezieht auch Office-Formate in die Suche mit ein.
Infos
[1] Paperwork: https://github.com/jflesch/paperwork/#readme
[2] Tesseract-OCR: http://code.google.com/p/tesseract-ocr/
[3] Installationsanleitung Ubuntu: http://wiki.ubuntuusers.de/Paperwork
[4] Allgemeine Installationsanleitung: https://github.com/jflesch/paperwork/wiki/Update
[5] Whoosh: http://whoosh.readthedocs.org/en/latest/quickstart.html
[6] Gescannte Bücher: http://book.google.com
[7] GScan2PDF: https://www.linux-community.de/21691
[8] hOCR-Files: https://de.wikipedia.org/wiki/HOCR_%28Standard%29
[9] Djvu: https://de.wikipedia.org/wiki/DjVu], [http://DjVu.org
[10] PDF2hocr: https://github.com/KarolS/pdf2hocr
[11] Pdfsandwich: http://www.tobias-elze.de/pdfsandwich/index.html
[12] Recoll: https://www.linux-community.de/24952




