

Zwar können Sie Simon keine Briefe oder ärztlichen Befunde diktieren, doch mithilfe der leistungsfähigen Sprachsteuerung folgt Ihnen der Rechner ab sofort aufs Wort.
Unter Windows und Mac OS X ist es seit langem gang und gäbe, den PC nicht nur über Tastatur und Maus zu bedienen, sondern auch per Sprache. Linux holt hier seit einigen Jahren auf, auch dank des gemeinnützigen Vereins “Simon listens” [1]. Der wurde von Franz Stieger gegründet und agiert als treibende Kraft hinter der Spracherkennungssoftware Simon.
Ursprünglich war die bereits seit mehreren Jahren entwickelte Anwendung dafür gedacht, körperbehinderten Menschen die Benutzung eines PCs zu erleichtern. Dieses Ziel verfolgt der Verein nach wie vor, aber die Entwickler haben auch einige zusätzliche Anwendungsgebiete für ihre Software entdeckt. Dazu zählen verbale Steuerungssysteme, die älteren Menschen die einfache Nutzung moderner Kommunikationstechnologien ermöglichen oder mit denen sich Roboter, Rollstühle oder Lifte via Spracheingabe bedienen lassen. Wer dagegen vorhat, dem PC seine Texte zu diktieren, wird mit Simon nicht glücklich werden und muss sich nach anderen Lösungen umsehen.
Seit April 2012 ist Simon ein offizielles KDE-Projekt [2] und nutzt somit auch die KDE-Infrastruktur. Die Spracherkennungssoftware folgt dem Client/Server-Prinzip. Sie besteht aus mehreren Komponenten und greift auf verschiedene andere Programme zurück, wie etwa das Spracherkennungstoolkit CMU Sphinx [3], die Spracherkennungsengine Julius [4] mit dem Hidden Markov Model Toolkit (HTK, [5]) und das Aussprachewörterbuch Hadi-Bomp [6]. Zu den Bestandteilen der Anwendung gehören neben dem Frontend Simon und dem Daemon Simond auch der Simon Acoustic Modeller Sam und der Simon Sample Collector SSC.
Simon installieren
Am einfachsten klappt die Installation für Nutzer der OpenSuse-Entwicklerversion: Für diese gibt es im OpenSuse Build Service Binärpakete [10], die sich mit den distributionseigenen Paketwerkzeugen installieren lassen.
Verwenden Sie eine andere Distribution, klonen Sie die Quelltexte aus dem KDE-Git (Listing 1) beziehungsweise holen sich das Tar-Archiv [11] und packen es aus. Dann wechseln in das neu entstandene Verzeichnis und starten das darin liegende Script build.sh beziehungsweise build_ubuntu.sh. Eventuell gilt es vorab noch einige Abhängigkeiten [12] aufzulösen, damit die Installation fehlerfrei durchläuft.
Um alle Funktionen des Spracherkennungsfrontends voll auszureizen, benötigen Sie zusätzlich entweder CMU Sphinx (sphinxbase, pocketsphinx und sphinxtrain jeweils in einer Version größer 0.8) oder Julius mit dem HTK sowie Entwicklerpakete von OpenCV, Libsamplerate, QAccessibilityClient und Libkdepimlibs4. Seit der Version 0.4 verwendet Simon in der Vorgabe die CMU-Sphinx-Engine als Backend zur Spracherkennung, unterstützt aber auch weithin Julius und das proprietäre HTK vollständig.
Listing 1
$ git clone git://anongit.kde.org/simon simonsource
Simon starten
Nach der Installation erscheint Simon im Startmenu der Desktop-Umgebung unter Eingabehilfen. Alternativ starten Sie die Anwendung mit dem Befehl simon auf der Kommandozeile. Beim ersten Start erscheint ein Assistent, der sie bei der Einrichtung unterstützt (Abbildung 1). Hier legen Sie fest, welche Szenarien und Sprachmodelle Simon später standardmäßig lädt, wo sich der Spracherkennungsserver Simond befindet und ob er automatisch starten soll.
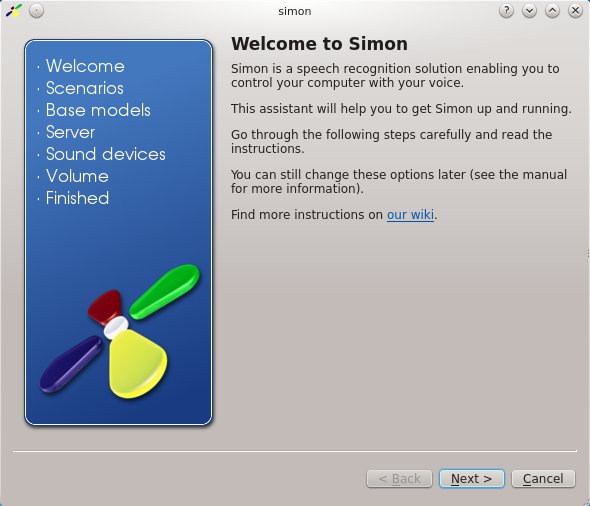
Abbildung 1: Ein Konfigurationsassistent erleichtert das Einrichten von Simon.
Simond kümmert sich darum, dass die Spracheingaben der Clients ausgewertet werden. Standardmäßig läuft er auf dem selben Rechner wie Simon und lauscht am Port 4444. Wie es sich für einen Server gehört, darf er aber auch auf einem separaten Rechner laufen und mehrere Clients bedienen, weshalb es später eventuell noch passwortgeschützte Nutzer anzulegen gilt.
In einem weiteren Schritt konfigurieren Sie die Soundkarte (Abbildung 2) und finden Sich dann im Hauptfenster der Anwendung wieder (Abbildung 3).
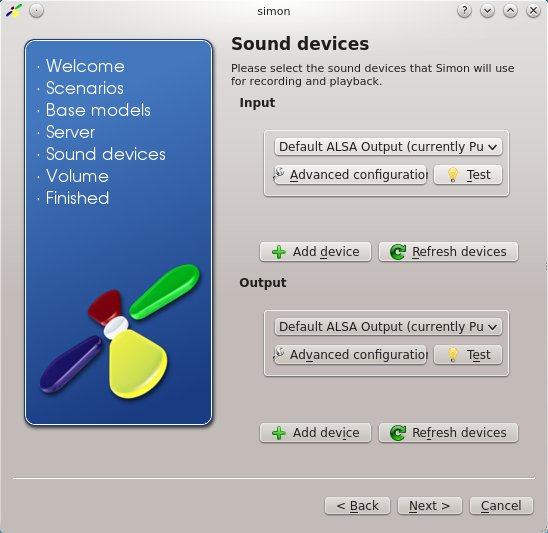
Abbildung 2: Mehrere Soundkarten und Mikrofone in USB-Webcams stellen für Simon kein Problem dar.
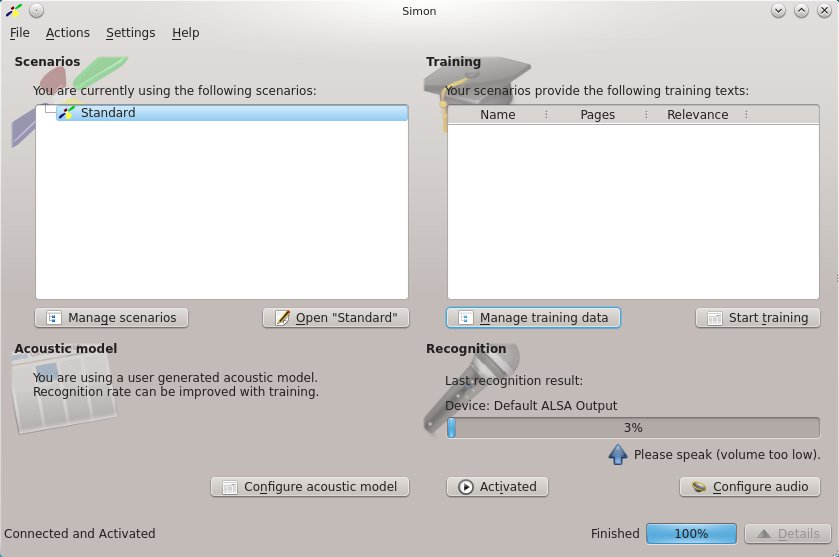
Abbildung 3: Verfügbare Szenarien, erkannte Worte, Verbindungsstatus: Im Hauptfenster präsentiert Simon übersichtlich alle Informationen. Viele Funktionen erreichen Sie von hier aus per Mausklick.
Modellpflege
Um gesprochene Worte zu erkennen, greift Simon auf akustische Modelle (“Basismodelle”) zurück. Diese gibt es in den drei Kategorien statisch, angepasst oder komplett nutzergeneriert. Die vorgefertigten statischen Modelle lassen sich nicht auf einzelne Nutzer zuschneiden: Damit sie korrekt funktionieren, muss der Anwender so sprechen, wie es die Urheber des Modells vorgesehen haben.
Auch angepasste Modelle liegen bereits vorgefertigt vor, lassen sich aber vom Nutzer noch für seine Stimme und Sprechweise trainieren – das erhöht die Treffergenauigkeit. Komplett nutzergenerierte Modelle müssen Sie zwar selbst erstellen, doch dafür bieten sie die höchste Trefferquote und eignen sich bestens auch für Individuen mit Sprachproblemen oder starken Dialekten.
Der Einsatz angepasster und nutzergenerierter Modelle setzt das Verwenden einer Spracherkennungsengine wie CMU Sphinx oder Julius voraus. Vorsicht: Die beiden verwenden nicht kompatible Modelle, weswegen sich ein Engine-Wechsel bei einem gut trainierten Modell nicht empfiehlt. Simon erkennt in der aktuellen Version das verwendete Modell und wählt automatisch das richtige Backend aus. Gute Anlaufstellen für für adaptierbare Modelle bieten die Download-Funktion von Simon unter Settings | Configure Simon | Sprachmodelle | Open model | Download oder das Voxforge-Projekt [7].
Von Voxforge heruntergeladene Modelle müssen Sie zunächst importieren. Um etwa das deutsche CMU-Sphinx-Modell zu nutzen, laden sie es von Voxforge herunter und entpacken es. Anschließend wählen Sie in der Konfiguration bei den Sprachmodellen anstelle des Downloads den Punkt Create from model files und geben die Pfade zu den nötigen Dateien an. Für andere verfügbare Sprachen oder Julius-Modelle klappt das Verfahren analog.
Szenarien
Innerhalb von Simon lassen sich bestimmte Anwendungsfälle für die Spracherkennung als Szenarien definieren. Typische Szenarien wären etwa, den Mauszeiger oder Browser mittels Stimmeingabe zu steuern. Das Simon-Team hat bereits einige häufige Szenarien gesammelt, die Sie über Manage scenarios | Open | Download laden können. Achten Sie darauf, dass Zielsprache und Akustikmodell stimmen, sofern Sie ein adaptiertes oder statisches Basismodell einsetzen. Ferner ist es wichtig, dass Szenario und Basismodell das gleiche Phonem-Set verwenden.
Oft werden Sie eigene Szenarien anlegen wollen – etwa, weil sie das Benötigte im Download-Bereich nicht finden haben oder dort vorhandene Szenarien das falsche Basismodell erfordern. Alternativ lassen sich auch bestehende Szenarien, etwa Standard, um neue Wörter erweitern. Neue Szenarien fügen Sie über Manage scenarios hinzu. Um diese mit eigenen Wörtern zu befüllen, genügt ein Klick auf Open <Name_des_Szenariums>. Hier zeigt Simon die Liste des bestehenden Vokabulars an, die es in den meisten Fällen erst noch zu befüllen gilt (Abbildung 4).
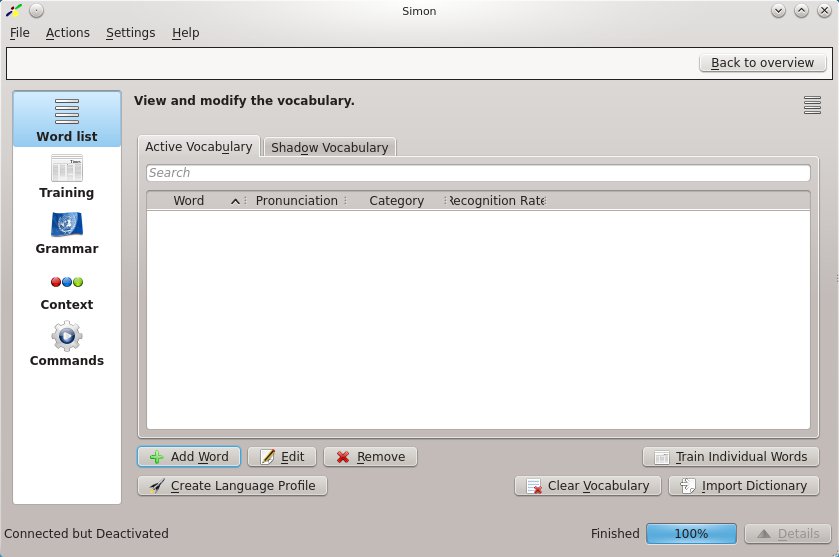
Abbildung 4: Eigene Szenarien müssen Sie erst einmal mit dem benötigten Vokabular befüllen.
Anders als bei vielen kommerziellen Spracherkennungssystemen mit vorgefertigten Sprachmodellen spielen bei Simon Sprachprobleme des Nutzers kaum eine Rolle: Neben den vorgefertigten Sprach- und Akustikmodellen kann der Anwender auch eigene, maßgeschneiderte Versionen generieren, indem er die benötigten Wörter in Simon trainiert.
Das Training selbst gestaltet sich recht einfach. Die Schwierigkeit besteht darin, dass man die Wörter in “Terminale” (Verben, Pronomen etc.; in Simon auch als Kategorien bezeichnet) unterteilen und in Phoneme zerlegen muss. Da Nichtlinguisten hier Schwierigkeiten bekommen könnten, bietet Simon an, dazu sogenannte Schattenlexika zu importieren. Diese enthalten neben vielen Wörter auch sämtliche Informationen über Terminale und die auf Phonemen basierte Aussprache. Die darin verfügbaren Wörter lassen sich leicht in den Simon-Wortschatz übernehmen. Fehlt ein Wort, können andere, vorhandene Wörter als Beispiele dienen.
Simon unterstützt Schattenlexika in den Formaten Hadifix, HTK, PLS, CMU Sphinx und Julius, die Sie alle über den Button Import Dictionary laden. Meist erwartet Simon dabei den Pfad zu einer auf dem Rechner liegenden Datei. Im Fall Hadifix existiert dank einer Vereinbarung mit der Universität Bonn jedoch die Möglichkeit, das Hadifix-Bomp-Lexikon direkt herunterzuladen. Hierzu müssen Sie Namen und E-Mail-Adresse angeben sowie die unfreie, aber kostenlose BOMP-Lizenz akzeptieren. Eine gute und ebenfalls sehr umfassende Alternative zum Bomp-Lexikon stellt das auf Voxforge verfügbare German Dictionary dar.
Training
Nehmen Sie ein neues Wort in ein Szenario auf (Abbildung 5), müssen Sie es mindestens zweimal trainieren, also ins Mikrofon sprechen. So machen Sie Simon mit Ihrer Stimme und Aussprache bekannt. Erfordert das Szenario nur wenige Worte, fällt die Erkennungsrate nach zwei Trainingsrunden schon recht akzeptabel aus. Zusätzliches Training steigert die Trefferquote jedoch gehörig und lohnt sich insbesondere sich bei zunehmendem Wortschatz oder ähnlich klingenden Wörtern.
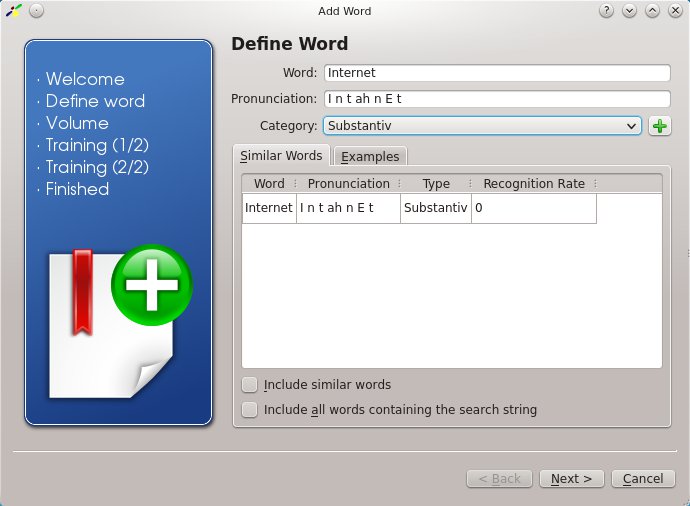
Abbildung 5: Ein Schattenlexikon hilft enorm, wenn Sie neue Wörter in Phoneme zerlegen müssen.
Wörter lassen sich gezielt trainieren, indem Sie sie mittels Train Individual Words einem Training hinzufügen (Abbildung 6). Möchten Sie das Szenario später vielleicht exportieren und so der Simon-Gemeinschaft zur Verfügung stellen, lohnt sich das Erstellen spezieller Trainingstexte. Dazu wechseln Sie in die Sektion Training und klicken dort auf den Button Add Text. Den zu übenden Text – im Idealfall das gesamte Vokabular des Szenarios – importieren Sie entweder oder geben ihn manuell ein.
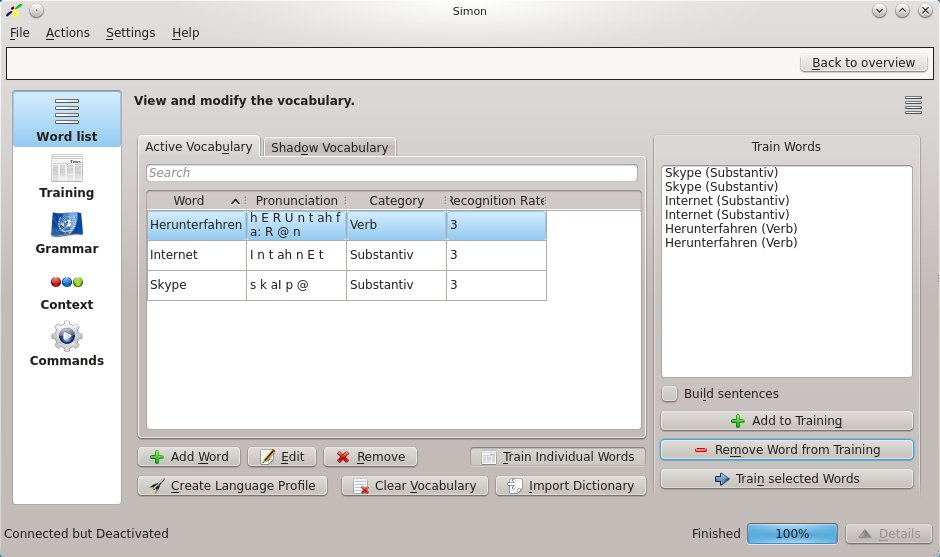
Abbildung 6: Eigens für ein Szenario erstellte Trainings helfen Simon, schnell das gesamte nötige Vokabular zu erlernen.
Liegen die Trainingstexte erst einmal vor, dann lassen sich im Hauptfenster oder im geöffneten Szenario Trainingsrunden starten, indem Sie die entsprechenden Buttons betätigen. In der Voreinstellung nimmt Simon die jeweiligen Zeilen des Trainingstextes, einzelne oder mehrere Wörter, separat auf. Erscheint es Ihnen zu umständlich, zweimal pro Wort den Record-Knopf (Aufnahme starten und stoppen) zu bemühen, setzen Sie das Häkchen bei Power Training. Nun genügt eine Betätigung des Next-Buttons, um ohne viel Geklicke durch den Trainingstext zu peitschen.
Die Grammatik eines Szenarios tut genau das, was der Name vermuten lässt: Sie definiert Regeln, die festlegen, in welcher Form das Vokabular vorkommen darf, damit Simon es sinnvoll interpretiert. Hier müssen Sie sich nicht an die Strukturen gesprochener Sprache halten, sondern dürfen ihre eigenen Grammatik schaffen, etwa Verb Substantiv oder Zahlwort Substantiv. Sie müssen lediglich darauf achten, dass sie Kategorien verknüpfen, die auch im vorhandenen Vokabular vorkommen.
Die Kategorien sind ebenfalls nicht in Stein gemeißelt, sondern lassen sich ergänzen und verändern, sodass neben Substantiven, Verben und Konsorten auch Trigger, Kommandos und andere schöne Dinge vorkommen können. Es ist sogar erlaubt, bestehende Kategorien miteinander zu verschmelzen und so die grammatikalischen Strukturen des Vokabulars im Wörterbuch und Schattenwörterbuch zu vereinfachen.
Kommandos
Die letzte Sektion im Szenario bilden die Kommandos. Hier legen Sie fest, wie Simon mit erkannten Wörtern verfährt. Es gibt verschiedene Kommando-Plugins, die den Rechner tätig werden lassen. So koppeln Sie leicht unterschiedlichste Tätigkeiten an einen Sprachbefehl. Dann führt der Rechner etwa auf Zuruf Programme aus (Program), emuliert Tastendrücke oder öffnet Ordner und Webseiten.
Ferner lassen sich mit Hilfe der Plugins der Mauscursor über den Desktop navigieren, Punkte in Listen auswählen oder Textbausteine einfügen. Sie können Nummern und Buchstaben diktieren, einen Taschenrechner bedienen oder die Aussprache trainieren und die Übereinstimmung mit einem Basismodell prüfen. Zusammengesetzte Kommandos arbeiten mehrere Aktionen hintereinander ab. Alle Kommando-Plugins detailliert vorzustellen, würde den Rahmen dieses Artikels sprangen – hier sei deshalb auf das sehr ausführliche Simon-Handbuch verwiesen.
Sie laden die Plugins über Manage Plugins (Abbildung 7) und koppeln dann mit New Command die entsprechenden Aktionen an ein oder mehrere Worte. Erkennt Simon ein Wort, arbeitet es die Kommando-Plugins der Reihe nach ab, bis sich eines findet, das die Eingabe verarbeiten kann und die entsprechende Aktion ausführt.
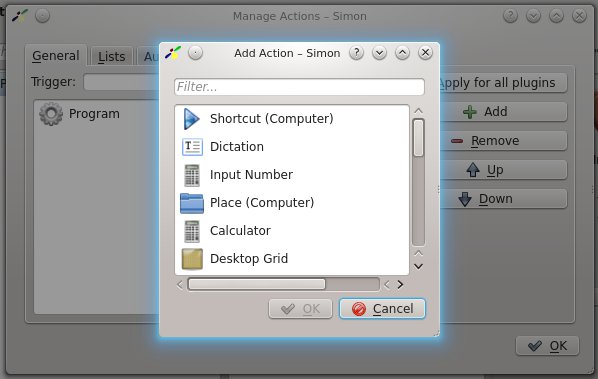
Abbildung 7: Vielfältige Kommando-Plugins ermöglichen eine weitgehende Kontrolle über verschiedene Funktionen des Rechners. Simon prüft der Reihe nach, welches Plugin ein erkanntes Wort verarbeiten kann.
In der optionalen Sektion Context legen Sie die Bedingungen fest, unter denen Simon ein Szenario aktiviert. Etwa könnten Sie ein Szenario Firefox nur dann aktivieren, wenn der Mozilla-Browser auch geöffnet ist. Das ermöglicht, dass identische Kommandos in verschiedenen Szenarien unterschiedliche Aktionen starten.
Zu den möglichen Bedingungen zählt beispielsweise, ob sich ein bestimmtes Fenster auf dem Desktop im Vordergrund befindet (Active Window Condition), eine Webcam ein Gesicht vor dem Rechner erkennt (erfordert OpenCV), ob bestimmte Prozesse laufen oder welchen Status Programme an D-Bus melden. Ferner lassen sich Dateien auf bestimmte Inhalte hin überprüfen.
Sobald Sie etwas an einem Szenario ändern oder Worte neu trainieren, aktualisiert Simond die Übersetzung des Akustik-Modells. Anschließend stehen neue Wörter sofort zur Verfügung. Im Hauptfenster erscheint stets das zuletzt erkannte Wort, egal, ob es an ein Kommando gekoppelt ist oder nicht (Abbildung 8).
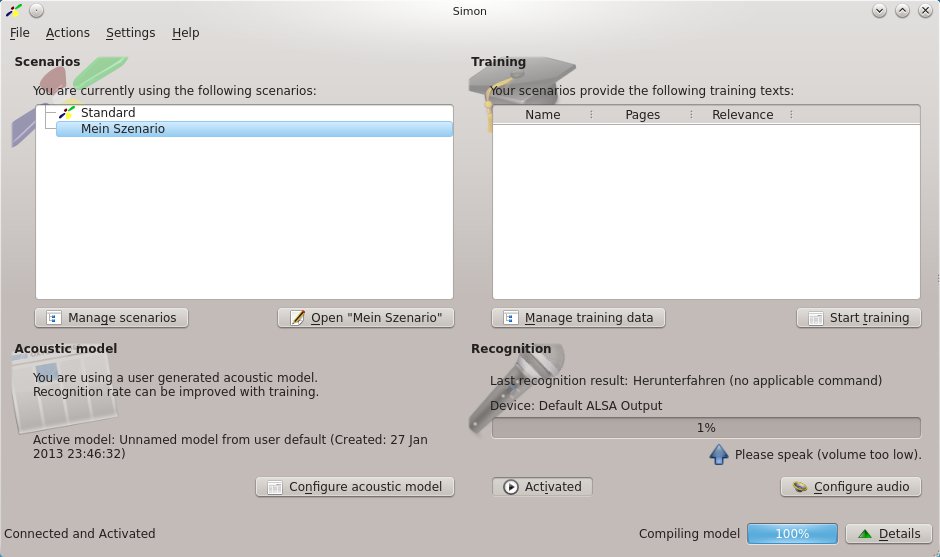
Abbildung 8: Treffer zeigt Simon im Hauptfenster an, unabhängig davon, ob sie an ein Kommando geknüpft wurden.
Sobald Simon lauscht, ist es begierig darauf, auch Wörter zu erkennen. Es kommt daher gelegentlich vor, dass es heftige Schnaufer als Sprachkommando interpretiert oder ein Gespräch mit anderen Personen den Rechner zu allerlei “Späßen” animiert. Um solchen Fehlerkennungen (“False Positives”) vorzubeugen, bietet es sich an, alle Sprachkommandos mit einem Trigger-Wort einzuleiten, etwa “Computer” oder “Abrakadabra”. Damit der Rechner diese auch interpretiert, gilt es die Grammatik entsprechend anzupassen.
Darüber hinaus arbeiten die Entwickler momentan daran, auch Lippenbewegungen abzufragen, um fälschlich erkannte Kommandos zu minimieren: Fehlen bei einer Spracheingabe ein Gesicht oder Lippenbewegung, so die Überlegung, war das erkannte Wort wahrscheinlich ein Hintergrundgeräusch, das Simon dann ignoriert.
CMU Sphinx und Julius
Wie bereits erwähnt, kann Simon mit den Spracherkennungsengines Julius und CMU Sphinx zusammenarbeiten. Beim Einrichten von Sphinxbase, Pocketsphinx und Sphinxtraining sollten Sie das Präfix von /usr/local nach /usr ändern oder zumindest entsprechende symbolische Links setzen.
Hilfsmittel wie Symlinks sind auch dann zwingend erforderlich, wenn Sie Sphinxtrain auf einem 64-Bit-System installieren. Dann landen nämlich Skripte und andere für das Erzeugen des Akustik-Modells wichtige Dateien im Verzeichnis /usr/[local/]lib64/sphinxtrain, Simon sucht sie aber aber später in /usr/lib/sphinxtrain.
CMU Sphinx hatte im Test teilweise Probleme, das Akustikmodell zu kompilieren. Die Ursachen konnten wir bis zur Drucklegung des Artikels nicht endgültig klären. Treten bei Ihnen ähnliche Fehler auf, greifen Sie besser auf Julius zurück.
Bei fertigen Szenarien wählt Simon das Backend zur Spracherkennung automatisch. Erzeugen Sie nutzergenerierte Akustik- und Sprachmodelle, können Sie das bevorzugte Backend in Settings | Configure Simon | Recognition | Configure server | Speech model compilation | Backend auswählen.
Ausblicke
Simon hat sich seit dem letzten Release vor zwei Jahren sehr gemausert und in Sachen Benutzerfreundlichkeit deutlich zugelegt. Die aktuelle Version 0.4 bringt neben der stark verbesserten Nutzerfreundlichkeit, der zusätzlichen Spracherkennungsengine CMU Sphinx und der Kontexterkennung auch Afaras und Simonoid mit. Mit Afaras spüren Sie schlechte Aufnahmen und zerstörte Muster in großen Korpora auf. Das KDE-Plasmoid Simonoid gibt den Erkennungsstatus aus und lässt sich nutzen, um Simon schnell zu starten oder zu beenden.
Für die nächste Zeit hat das Entwicklerteam um Chief Technology Officer Peter Grasch ambitionierte Pläne: So will man bisher als experimentell deklarierte Funktionen wie die Lippenerkennung fertigstellen. Zudem kooperiert man mit verschiedenen Partnern wie den Universitäten in Bonn und Graz. Das Institut für Österreichisches Deutsch erlaubt es dem Projekt, auf die ADABA-Datenbank [8] zuzugreifen, woraus ein frei verfügbares deutsches Basismodell resultieren könnte. Als weiteren wichtigen Meilenstein auf dem Weg zur Version 0.5 wollen die Entwickler das Framework AT SPI2 (“Assistive Technology Service Provider Interface 2”, [12]) in Simon integrieren.
Dieser Artikel beschäftigte sich nur mit dem Frontend Simon. Andere interessante Bestandteile des Simon-listens-Projekts sind Sam und SSC. Bei Sam handelt es sich um ein Werkzeug, mit dem sich akustische Modelle erstellen und testen lassen. Diese Modelle kann Simon später importieren. Der Simon Sample Collector SSC dient dazu, Proben verschiedener Sprecher und Nutzerumgebungen zu sammeln, um daraus neue Basismodelle zu entwickeln. Weiterhin gibt es noch die Meego-Anwendung Simone, mit der sich Rechner über ein Smartphone steuern lassen.
Das motivierte Simon-Entwicklerteam ist in all den Jahren recht überschaubar geblieben und freut sich über zusätzliche Mitglieder. Neben Programmierern (C++, Qt) können sich auch Menschen einbringen, die Szenarios erstellen, die Dokumentation erweitern oder Simon in ihrer Muttersprache lokalisieren wollen.
Fazit
Die Spracherkennung Simon selbst lässt sich auch von Anfängern leicht installieren und in Betrieb nehmen. Die einzige Hürde bei der Einrichtung stellen die zahlreichen Abhängigkeiten dar. Während des mehrtägigen Tests lief das System absolut stabil, die Anwendung stürzte kein einziges Mal ab.
Als Zuckerl bietet Simon einen einfachen Zugriff auf die ausgefeilten, seit mehreren Jahren entwickelten Spracherkennungsengines Julius und CMU Sphinx. Zwar kann es trotzdem (noch) keine Briefe oder ärztlichen Befunde niederschreiben, doch wenn es ums Steuern geht, folgt der Rechner Simon bereits aufs Wort.
Glossar
-
Meego
-
Das quelloffene Mobile-Betriebssystem auf Linux-Basis entstand 2010 aus der Verschmelzung der Vorgänger Maemo (Nokia) und Moblin (Intel). Es untersteht heute der Ägide der Linux Foundation, soll aber mittelfristig in dessen Smartphone-OS Tizen aufgehen.
Infos
[1] Verein Simon listens: http://www.simon-listens.org/
[2] Simon: https://projects.kde.org/projects/extragear/accessibility/simon
[3] CMU Sphinx: http://cmusphinx.sourceforge.net/
[4] Julius: http://julius.sourceforge.jp/en_index.php
[5] HTK: http://htk.eng.cam.ac.uk/
[6] Hadifix Bomp: http://www.sk.uni-bonn.de/forschung/phonetik/sprachsynthese/bomp
[7] Voxforge: http://www.voxforge.org/home
[8] Adaba: http://www-oedt.kfunigraz.ac.at/ADABA/index.html
[9] AT SPI2: http://www.linuxfoundation.org/collaborate/workgroups/accessibility/atk/at-spi/at-spi_on_d-bus
[10] Simon für OpenSuse Factory: http://software.opensuse.org/package/simon
[11] Simon-Tarball: http://anongit.kde.org/simon/simon-latest.tar.gz
[12] Kompilieranleitung und Abhängigkeiten: http://userbase.kde.org/Simon/Development_Environment#Compiling





Sprachsteuerung schön und gut, aber ich habe nach etwas gesucht, um unter Linux diktieren zu können. Das gibt es nicht und wird es wohl in absehbarer Zeit auch nicht geben.
Jedoch für mich reicht diese Lösung (vielleicht für einige andere auch):
Im Webbrowser Chromium https://speechnotes.co/de/ aufrufen und los geht es mit dem Diktieren.
Viel Vergnügen.