

Python ist einfach – aber nicht so einfach, dass man es allein durch Lesen von Code lernen könnte. Mit etwas Hintergrundwissen vermeiden Sie typische Fehler in Python-Code und schreiben so bessere Programme.
Python ist eine relativ leicht zu erlernende Sprache, mit der man in kurzer Entwicklungszeit viel erreichen kann. Das verführt vor allem Einsteiger dazu, Python [1] nur durch Anschauen von Python-Code zu “lernen”, was oft unangenehme Überraschungen nach sich zieht: Python verhält sich nicht unbedingt so, wie man es von den jeweils bisher gelernten Sprachen kennt. Fehler, die zügig zu einer unwarteten Ausnahme mit einem Traceback führen, stellen da noch das geringste Problem dar. Kniffliger sind Fehler in Gestalt von Code, der nur scheinbar das Gewünschte tut.
Dieser Artikel spricht solche Missverständnisse zur Funktionsweise von Python an und erklärt die Hintergründe. Darüber hinaus gibt er diverse Tipps, um kompakten und dennoch lesbaren Code zu schreiben. Der Schwerpunkt des Artikels liegt auf Python 2.x, da sich diese Versionen noch wesentlich häufiger im Einsatz befinden, unter anderem für Systemprogramme diverser Linux-Distributionen.
Einrückungen: Vorsicht, Tabulator!
Python erkennt einen Anweisungsblock wie etwa einen Schleifenrumpf an seiner einheitlichen Einrückung. Dabei empfiehlt der “Style Guide for Python Code” [2] eine Einrücktiefe von vier Zeichen pro logischer Ebene und das ausschließliche Verwenden von Leerzeichen zum Einrücken.
Probleme treten unter Umständen dann auf, wenn Sie sowohl Leerzeichen als auch Tabulatorzeichen zur Einrückung nutzen. Für den Python-Interpreter entspricht ein Tabulatorzeichen acht Leerzeichen beziehungsweise füllt auf das nächste Vielfache von acht Leerzeichen auf. Betrachtet man einen Quelltext mit einer anderen Tabulator-Weite, sieht man unter Umständen eine andere Logik im Code, als sie der Interpreter wahrnimmt.
Ein Beispiel zeigt das Listing 1. Die vier Zeichen breite Sequenz >--- steht hier (in Anlehnung an den beliebten Editor Vim) für einen Tabulator, den der Editor mit vier Zeichen Breite darstellt. Auf den ersten Blick scheint Python die Anweisung b = h(b) auf jeden Fall auszuführen. Da ein Tabulatorzeichen aber acht Leerzeichen entspricht, bearbeitet der Interpreter diese Zeile wie die vorherige aber nur im Fall a > b.
Listing 1
def f(a, b):
if a > b:
a = g(a)
>---b = h(b)
return a, b
Glück im Unglück: Das Mischung von Leerzeichen und Tabulatoren führt eher zu Syntaxfehlern als zu falsch funktionierendem Code. Ein Beispiel zeigt Listing 2. Hier ist aus Sicht von Python das Schlüsselwort else genauso weit eingerückt wie die Zuweisungen an a und b – ein Syntaxfehler.
Listing 2
def f(a, b):
if a > b:
a = g(a)
>---else:
b = h(b)
return a, b
Um die potenzielle Verwirrung durch einen Mix von Leerzeichen und Tabulatoren von vornherein zu vermeiden, lassen Sie den Editor auch bei Drücken der Tabulatortaste immer mit vier Stellen pro logischer Ebene einrücken. Natürlich wären auch andere Regeln denkbar, aber vier Leerzeichen sind wie gesagt die im “Style Guide” empfohlene Variante und daher in den allermeisten Python-Projekten üblich.
Haben Sie Code im Verdacht, inkonsistent eingerückt zu sein, machen Sie mittels des Kommandos
$ find . -name "*.py" -exec grep -EnH "\t" {} \;
alle Python-Dateien im und unterhalb des aktuellen Verzeichnisses ausfindig, die Tabulatorzeichen enthalten. Geht es nur um wenige Dateien, ist es praktikabel, im Editor Tabulatorzeichen explizit anzuzeigen. In Vim geht das mit dem Befehl :set list (Abbildung 1). Viele andere Programmiereditoren bieten ähnliche Möglichkeiten.

list-Option. Diese macht Tabulator- und Zeilenende-Zeichen sichtbar.” width=”300″ height=”261″ />
Abbildung 1: Zwei Ansichten der gleichen fehlerhaften Datei in Vim, oben ohne, unten mit gesetzterlist-Option. Diese macht Tabulator- und Zeilenende-Zeichen sichtbar.Objekte und Namen: Who is who
In Python gibt es keine Variablen wie bei C oder Pascal, die einen bestimmten Speicherbereich kennzeichnen. Die Python-Zuweisung a = 1 verknüpft lediglich das Ganzzahl-Objekt 1 mit dem Namen a verknüpft. Ein und dasselbe Objekt lässt sich prinzipiell unter beliebig vielen Namen erreichen. Es gibt auch anonyme (namenlose) Objekte, wie die Zahl 2 in der Anweisung L = [1, 2, 3].
Wichtig zum Verständnis von Python sind die Konzepte der Identität und der Gleichheit. Identität bedeutet, dass es sich um ein und dasselbe Objekt handelt, während Gleichheit zweier Objekte aussagt, dass diese den gleichen Wert haben. Ob zwei Objekte identisch sind, stellen Sie mithilfe des Operators is fest (Listing 3).
Listing 3
x = 1.0
y = x # Das Objekt 1.0 mit dem Namen x ist
# jetzt auch über den Namen y erreichbar.
print x is y # True
print x == y # True
y = 1
print x is y # False
print x == y # True, 1.0 bezeichnet den gleichen Wert wie 1
Für von Ihnen definierte Datentypen legen Sie selbst fest, wie Gleichheit zwischen deren Instanzen definiert ist. Wie Listing 4 verdeutlicht, könnten Sie auf diese Weise sogar dafür sorgen, dass zwei Objekte zwar identisch, aber dennoch ungleich sind!
Listing 4
class ImmerUngleich(object):
def __eq__(self, rechte_seite):
"""Definiere Verhalten des Operators ==."""
return False
x = ImmerUngleich()
y = x
print x is y # True
print x == y # False
In Python-Code bedeutet der Wert None üblicherweise, dass ein Name keinen “richtigen” Wert hat, zum Beispiel weil er bisher nicht explizit initialisiert wurde. Prüfungen eines Namens auf None sollten Sie immer mit is vornehmen, nicht mit ==. Analog zu Listing 4 kann eine Klasse ja den Vergleichsoperator so definieren, dass alle Vergleiche einen wahren Wert liefern (Listing 5). Nur die Operation in der letzten Zeile des Listings, die is verwendet, funktioniert zuverlässig.
Listing 5
class ImmerGleich(object):
def __eq__(self, rechte_seite):
"""Definiere Verhalten des Operators ==."""
return True
x = ImmerGleich()
print x == None # True, obwohl x nicht None ist
print None == x # True, obwohl x nicht None ist
print x is None # False
Wie schon erwähnt, führt eine Zuweisung nur zur Verknüpfung von Namen und Objekten. Objekte werden dabei nicht kopiert. Das erklärt auch das Ergebnis in Listing 6, das bei Python-Einsteigern immer wieder für Überraschungen sorgt.
Listing 6
L1 = [1, 2] L2 = L1 L1.append(3) print L1 # [1, 2, 3] print L2 # ebenfalls [1, 2, 3] print L1 is L2 # True
Die erste Zuweisung erzeugt eine Liste mit den Elementen 1 und 2, die zweite Zuweisung gibt der derart erzeugten Liste einen zweiten Namen L2. L1 und L2 stehen nun für ein- und dasselbe Objekt. Die dritte Anweisung hängt die Zahl 3 ans Ende der Liste. Da L2 nur ein anderer Name für dieselbe Liste ist, bekommen Sie bei der Ausgabe von L1 und L2 auch ein identisches Ergebnis. Die letzte Zeile bestätigt das vorher Gesagte: L1 und L2 bezeichnen ein und dieselbe Liste.
Objekt-Verknüpfungen können natürlich auch komplexer ausfallen. So greifen Sie nach den ersten drei Anweisungen in Listing 7 auf die erzeugte Liste sowohl unter dem zuerst vergebenen Namen L als auch über das Tupel t zu.
Listing 7
L = [1] t = (L,) # Tupel mit der Liste als einzigem Element L.append(2) print L # [1, 2] print t[0] # [1, 2] print L is t[0] # True
Unveränderliche und veränderliche Objekte
Die Veränderbarkeit von Objekten stellt ein wichtiges Konzept von Python dar. erst, wenn man es verstanden hat, ergeben vermeintlich seltsame Verhaltensweisen von Python einen Sinn.
Sogenannte unveränderliche Objekte, zum Beispiel Zahlen oder Zeichenketten, kann man – wie der Begriff schon sagt – nicht verändern. Mitunter gibt es das Missverständnis, dass sich in den Zuweisungen
a = 1 a = 2
der Wert von a ändern würde, es sich bei Zahlen also nicht um unveränderbare Objekte handelte. Das Konzept der Veränderbarkeit bezieht sich aber nicht auf Namensverknüpfungen, sondern auf das jeweilige Objekt selbst: So ist nach der zweiten Zuweisung immer noch das Objekt 1 das Objekt 1; aus der Ganzzahl Eins ist ja nicht die Ganzzahl Zwei entstanden.
Anders sieht es bei veränderbaren Objekten aus. Dazu gehören in Python Listen, Dictionaries, Sets sowie im Allgemeinen Klassen und Instanzen. In Listing 5 änderte die Methode append() der Liste diese selbst; das Listenobjekt erhielt ein zusätzliches Element. Alle Zugriffe auf dieses Objekt, egal über welchen Namen, “sehen” die Veränderung.
“Wahrheit” und “Falschheit”
Für die eingebauten Datentypen von Python gilt: Als “falsch” gelten nummerische Null-Werte (0, 0.0, 0.0+0.0j), leere Strings ("", u""), leere Container ([], (), {}, set(), frozenset()) sowie None und False. Alle anderen eingebauten Objekte sind “wahr”.
Folglich lassen sich viele if-, elif– und while-Bedingungen wie in der Tabelle “Idiomatische Bedingungen” aufgeführt auch einfacher schreiben. Eine Anwendung zeigt das Listing 8.
Idiomatische Bedingungen
| Langform | Idiomatische Kurzform |
|---|---|
| if wert == True | if wert |
| if liste != [] | if liste |
| if liste == [] | if not liste |
| if len(liste) == 0 | if not liste |
| if string == u”” | if not string |
| … und so weiter | |
Listing 8
def zeige_namen(namen):
"""Gib die Namen in der Liste `namen` aus."""
if namen:
print "\n".join(namen)
else:
print "keine Namen vorhanden"
Abgesehen davon, dass sie sich kompakter schreiben und leichter lesen lässt, hat die kurze Form noch einige weitere Vorteile:
- Sie führt zu einem höheren Abstraktionsniveau. Man fragt also zum Beispiel nicht, “Ist die Liste
namenungleich der leeren Liste?”, sondern “Gibt es Namen?” - Die Kurzform macht Code-Änderungen unnötig, wenn sich der Container-Typ ändert. Die Funktion
zeige_namenin Listing 8 kann unverändert bleiben, wenn sie der Funktion statt einer Namensliste ein Tupel oder ein Set übergeben. - Deshalb gilt die Funktion nicht nur für Listen, sondern auch für andere Sequenzen. Ein Umstellen der Schnittstelle ist also nicht nötig, sondern die Funktion kann mehrere Schnittstellen gleichzeitig anbieten.
Funktionen und Methoden
Manche Sprachen erlauben, die Klammern am Ende eines Funktionsaufrufs wegzulassen, wenn man keine Argumente übergibt. In Python sind die Klammern jedoch Pflicht. Der Ausdruck fobj.close in Listing 9 liefert nur die Methode selbst, ruft diese aber nicht auf. Die Datei bleibt daher offen.
Listing 9
fobj = open(dateiname, 'rb') # Lies die ersten 100 Bytes. data = fobj.read(100) # Keine Klammern nach `close` -> kein Aufruf. fobj.close
Default-Argumente werden nur einmal erzeugt, nämlich während der Definition der Funktion oder Methode. Deshalb bleibt das Listen-Objekt L in Listing 10 während der gesamten Laufzeit des Codes erhalten.
Listing 10
def anhaengen(obj, L=[]):
L.append(obj)
return L
print anhaengen(2) # [2]
print anhaengen(5) # [2, 5]
print anhaengen(1, []) # [1]; Default-Argument nicht benutzt
Längere Parameterlisten führen leichter als kurze zu einer falschen Reihenfolge der Argumente in einem Aufruf. In Python minimieren Sie dieses Risiko, indem Sie Parameter beim Aufruf mit deren Namen versehen (Listing 11). Sie müssen also nicht unbedingt auswendig wissen, dass in der Definition die Liste vor der Zeichenkette steht. Die drei Aufrufe von merke sind gleichwertig: Alle hängen die Zeichenkette an die Liste, auch wenn wie im dritten Aufruf der String zuerst steht.
Listing 11
def merke(liste, string):
liste.append(string)
L = []
merke(L, u"Python macht Spaß!")
merke(liste=L, string=u"Python macht Spaß!")
merke(string=u"Python macht Spaß!", liste=L)
In Python dürfen Sie in Funktions- oder Methodenaufrufen ein Tupel, eine Liste oder ein Dictionary implizit in mehrere Argumente umwandeln. Die entsprechenden Beispiele aus Listing 12 sind zwar konstruiert, erklären aber, was hier passiert. Die in Form eines Tupels oder einer Liste übergebenen Argumente nennt man Positionsargumente (“positional arguments”), die als Dictionary übergebenen Argumente dagegen Schlüsselwortargumente (“keyword arguments”).
Natürlich schreibt man in realem Code keine Parameterübergaben wie in Listing 12. Liegen die Argumente aber schon als Tupel, Listen oder Dictionaries vor, vereinfachen Positions- und Schlüsselwortargumente den Code.
Listing 12
def print3(a, b, c):
"""Gib die drei Argumente aus."""
print a, b, c
# Übergabe eines Tupels oder einer Liste für die drei Parameter.
# Entspricht print3("Parameterübergabe", "mit", "*")
print3(*("Parameterübergabe", "mit", "*"))
print3(*["Parameterübergabe", "mit", "*"])
# Übergabe eines Dictionarys für die drei Parameter.
# Entspricht print3(a="Parameterübergabe", c="**", b="mit")
print3(**{"a": "Parameterübergabe", "c": "**", "b": "mit"})
Positions- und Schlüsselwortargumente lassen sich nicht nur beim Aufruf einer Funktion oder Methode anwenden, sondern auch in deren Definition. Dabei “sieht” die aufgerufene Funktion die Parameter als Tupel beziehungsweise Dictionary. Ein Beispiel dazu zeigt Listing 13. Die Funktion parameterausgabe gibt die für eine Funktion bestimmten Argumente aus und ruft die Funktion anschließend mit diesen Argumenten auf. Die Funktion parameterausgabe muss dabei nichts über die aufzurufende Funktion wissen, sondern reicht einfach nur die Parameter durch.
Listing 13
def parameterausgabe(func, *args, **kwargs):
"""Gib die Argumente aus und rufe die Funktion func
mit diesen auf.
"""
# Funktionsname.
print "Funktion:", func.__name__
# `args` ist ein Tupel; kein * davor.
print "Positions-Argumente:", args
# Dito für Dictionary.
print "Schlüsselwort-Argumente:", kwargs
# Rufe Funktion auf.
return func(*args, **kwargs)
def polynom(x, a, b, c):
return a * x**2 + b * x + c
# Ausgabe:
# 18
#
# Funktion: polynom
# Positions-Argumente: (2,)
# Schlüsselwort-Argumente: {'a': 2, 'c': 4, 'b': 3}
# 18
print polynom(2, a=2, b=3, c=4)
print
print parameterausgabe(polynom, 2, a=2, b=3, c=4)
Eine weitere nützliche Anwendung zeigt Listing 14. Hier muss die abgeleitete Klasse nicht im Einzelnen wissen, welche Parameter der Konstruktor der Basisklasse verarbeitet. Sie kümmert sich stattdessen nur um das für sie bestimmte Argument titel.
Listing 14
class Person(object):
def __init__(self, vorname, nachname):
self.vorname = vorname
self.nachname = nachname
def __str__(self):
return "%s %s" % (self.vorname, self.nachname)
class Autor(Person):
def __init__(self, *args, **kwargs):
self.titel = kwargs.pop("titel")
super(Autor, self).__init__(*args, **kwargs)
autor = Autor(u"Stefan", u"Schwarzer",
titel=u"Robuste Python-Programme")
Die Übergabe eines Arguments läuft wie eine Zuweisung ab: Der lokale Name innerhalb der Funktionsdefinition wird mit dem übergebenen Objekt verknüpft. Zuweisungen innerhalb des Funktionsrumpfes beziehen sich aber standardmäßig nur auf den lokalen Namensraum der Funktion. Der Code in Listing 15, der die übergebene Liste löschen soll, funktioniert daher nicht.
Listing 15
def liste_loeschen(liste):
liste = []
eine_liste = [1, 2, 3]
liste_loeschen(eine_liste)
print eine_liste # [1, 2, 3], nicht gelöscht!
Tatsächlich entsteht hier innerhalb der Funktion eine neue Liste, die mit dem lokalen Namen liste verknüpft wird. Die vorherige Bindung an die Liste [1, 2, 3] geht verloren, sodass das ursprüngliche Argument nicht mehr zugänglich ist. Dennoch lässt sich die übergebene Liste innerhalb von liste_loeschen leeren, indem man die Zeile liste = [] durch liste[:] = [] ersetzt. Dadurch ändert sich die übergebene Liste.
Im Gegensatz dazu funktioniert so etwas bei unveränderlichen Objekten definitionsgemäß nicht. Hier ist das übliche Vorgehen, das Ergebnis eines Funktionsaufrufs dem ursprünglichen Namen zuzuweisen. Bei veränderlichen Argumenten verfährt man aber oft genauso.
Umgang mit Ausnahmen (Exceptions)
Einige Sprachen, wie die Unix-Shell oder C, nutzen typischerweise Rückgabewerte zur Fehlerbehandlung. Verschiedene anderen Sprachen, unter anderem Python, arbeiten stattdessen mit Ausnahmen (“Exceptions”). Zwei Erörterungen des Programmierers Ned Batchelder beschreiben anhand von Beispielen ausführlich die Vorteile der beiden Strategien ([3],[4]).
Oft findet man in Python-Code “leere” except-Anweisungen wie in Listing 16. Der Hintergedanke des Programm-Autors dabei ist normalerweise, dass nur ein bestimmter Fehler auftreten kann. Das würde die gezielte Kontrolle auf einen IOError, OSError oder eine andere Ausnahme unnötig machen. Dieser Ansatz erweist sich als problematisch, weil ein leerer except-Zweig auch Schreibfehler in Form von NameError– und AttributeError-Ausnahmen abfängt.
Listing 16
# Dieser Code tut nicht, was man erwartet.
try:
fobj = opne("evtl_nicht_da")
except:
print "Datei nicht vorhanden"
Im Beispiel steht in der zweiten Zeile opne statt open. Das ist nicht etwa ein Syntaxfehler, sondern erzeugt – zur Laufzeit – einen NameError. Der Code weist beim Lauf also auf eine nicht gefundene Datei hin, auch wenn es diese tatsächlich gibt. Viel Spaß beim Finden solcher Fehlers! Falls nicht ausgesprochen gute Gründe dagegen sprechen, sollten Sie die zu behandelnden Ausnahmeklassen also immer angeben.
Eine Übersicht der von der Sprache selbst erzeugten Ausnahmen gibt es unter [5]. Die mit Python gelieferten Module können darüber hinaus freilich noch andere Ausnahmen auslösen, deren Dokumentation sich jeweils in den Modulbeschreibungen findet.
Tückisch ist auch zu viel Code in einem try-Block. Listing 17 zeigt ein Beispiel, in dem eine Funktion alter_aus_db das Alter einer Person aus einer Datenbank laden soll. Die Idee dabei: Ein Zugriff auf person[name] löst einen KeyError aus, falls es keinen Personen-Datensatz im Dictionary person gibt. (Der Dictionary-Zugriff über den Schlüssel alter kann nicht zu einem KeyError führen, da der Schlüssel alter gegebenenfalls erzeugt wird.)
Listing 17
def alter_aus_db(name):
...
try:
person[name][alter] = alter_aus_db(name)
except KeyError:
print 'Kein Datensatz für Person "%s"' % name
So weit, so gut. Enthält aber alter_aus_db selbst einen Dictionary-Zugriff, zum Beispiel return cache[name], fängt dies unabsichtlich auch einen dadurch entstandenen KeyError ab.
Die Abhilfe besteht darin, gezielt nur jenen Code in den try-Block zu schreiben, der von der Ausnahmebehandlung betroffen sein soll (Listing 18). Noch besser: Lassen Sie alter_aus_db einen KeyError gar nicht erst “durchreichen”, sondern setzen Sie ihn in eine stärker abstrahierte Exception wie CacheError um. Dazu fangen Sie den KeyError in alter_aus_db und lösen die stärker abstrahierte Ausnahme mit raise aus.
Listing 18
def alter_aus_db(name):
...
db_alter = alter_aus_db(name)
try:
person[name][alter] = db_alter
except KeyError:
print 'Kein Datensatz für Person "%s"' % name
Erzeugen Sie irgendwo im Code Ressourcen wie Dateien, Sockets oder Datenbank-Verbindungen, dann sollten Sie diese nach der Verwendung mit einem try/finally– oder einem with-Konstrukt freigegeben (Listing 19).
Listing 19
db_conn = connect(datenbank)
try:
# Datenbank-Operationen
...
finally:
db_conn.rollback()
db_conn.close()
# Für Dateien alternativ mit `with` (ab Python 2.5) ...
# Import-Anweisung ist nur bei Python 2.5 nötig.
from __future__ import with_statement
with open(dateiname) as fobj:
# Datei wird am Ende des `with`-Blocks automatisch geschlossen.
data = fobj.read()
Wollen Sie mehrere Ausnahmetypen gleich behandeln, umgeben Sie diese wie in Listing 20 mit Klammern. Fehlen letztere, versteht Python das folgendermaßen: Fange einen ValueError ab und mache das Ausnahme-Objekt unter dem Namen IndexError verfügbar. In Python 3 sollte diese Fehlerquelle nicht mehr vorkommen, denn es macht beim gleichzeitigen Fangen mehrerer Ausnahmeklassen solche Klammern zur Pflicht; ein Ausnahme-Objekt wird stattdessen durch except ValueError as exception_object zugänglich. Python 2.6 erlaubt diese Syntax ebenfalls.
Listing 20
try:
# Kann `ValueError` oder `IndexError` auslösen.
...
except (ValueError, IndexError):
# Gleiche Fehlerbehandlung für `ValueError` und `IndexError`
...
Da bei mehreren passenden except-Zweigen immer der erste verwendet wird, müssen abgeleitete Ausnahmeklassen wie in Listing 21 vor deren Basisklassen erscheinen. Anderenfalls wird nur der except-Zweig der Basisklasse ausgeführt.
Listing 21
class DatabaseError(Exception):
pass
class NotUniqueError(DatabaseError):
pass
...
try:
...
# Abgeleitete vor der Basisklasse!
except NotUniqueError:
...
except DatabaseError:
...
Vom Umgang mit <C>exec<C> und <C>eval<C>
Python gilt als eine sehr dynamische Sprache. Das bringt manchen Zeitgenossen auf die Idee, die Anweisung exec beziehungsweise die Funktion eval zur Ausführung von Text als Code zu verwenden. Tatsächlich benötigt man exec und eval aber nur sehr selten, da Python für deren vermeintlich typische Anwendungen bessere Möglichkeiten bietet. Das ist auch gut so, denn exec und eval haben eine ganze Reihe von Nachteilen:
- Die Übersichtlichkeit des Codes leidet.
- Einrückungsfehler passieren leichter.
- Die Kontrolle der Syntax findet erst zur Laufzeit statt.
- Es schleichen sich leicht Sicherheitslücken ein.
- Die Möglichkeiten, Code mit speziellen Programmen (dazu später mehr) zu untersuchen, werden eingeschränkt.
Eine “typische” Anwendung von exec stellt es dar, Code unter Verwendung von vorher definierten Bezeichnern zu generieren. Ein Beispiel findet sich in Listing 22. Die Funktion baue_addierer erzeugt eine andere Funktion addierer, die zu ihrem Argument n einen Offset hinzuzählt. Der Code von baue_addierer erscheint recht unübersichtlich; die Einrückungen des Codes der eingebetteten Funktionsdefinition addierer müssen Python-gemäß natürlich stimmen, jedoch muss die Einrückung “von Null aus” am linken Rand starten.
Listing 22
def baue_addierer(offset):
# Fuer konsistente Einrueckungen sorgen.
code = """
def addierer(n):
return n + %d
""" % offset
exec code
return addierer
neuer_addierer = baue_addierer(3)
print neuer_addierer(2) # 3 + 2 = 5
Wie Listing 23 zeigt, geht es viel einfacher, denn in Python lassen sich Funktionsdefinition beliebig verschachteln. Sie dürfen sogar ganze Klassen innerhalb von Funktionen oder Methoden erzeugen und als Resultat zurückgeben.
Listing 23
def baue_addierer(offset):
def addierer(n):
return n + offset
return addierer
Die Funktion eval setzen manche Programmierer dazu ein, auf ein erst zur Laufzeit bekanntes Attribut eines Objekts zuzugreifen (Listing 24). Genau hierfür gibt es jedoch eigentlich die Funktionen getattr, setattr und delattr. Der eval-Ausdruck lässt sich daher durch getattr(obj, "wert%d" % n) ersetzen. (Bei mehreren Attributnamen, die sich wie hier nur durch Zahlen unterscheiden, sollten sie eher eine Liste beziehungsweise ein Dictionary nutzen. In diesen fungieren die Zahlen dann als Indizes beziehungsweise Schlüssel.)
Listing 24
def wert_n(obj, n):
return eval("obj.wert%d" % n)
Für Modul-globale Werte funktionieren zwar nicht die oben angegebenen Funktionen, Sie können aber direkt das von der Funktion globals gelieferte Dictionary manipulieren. Dies zeigt Listing 25.
Listing 25
for name in u"Dies ist ein Beispiel".split():
globals()[name] = name
Das ist äquivalent zu:
Dies = u"Dies" ist = u"ist" ein = u"ein" Beispiel = u"Beispiel"
Ein weiteres Problem von exec und eval: Sie reißen leicht Sicherheitslöcher, falls beliebige Eingabedaten in auszuführenden Code gelangen. Die Abbildung 2 zeigt als Beispiel eine Eingabemaske für einen Funktionsplotter im Internet. Listing 26 enthält den zugehörigen Code. Die Schleife durchläuft eine Wertetabelle von -10 bis +10 (Multiplikation des Schleifenzählers mit 0.1), wertet die vom Anwender eingegebene Funktion für den aktuellen X-Wert aus und trägt den Punkt in eine Liste ein, aus der nach Ende der Schleife ein Diagramm entsteht.
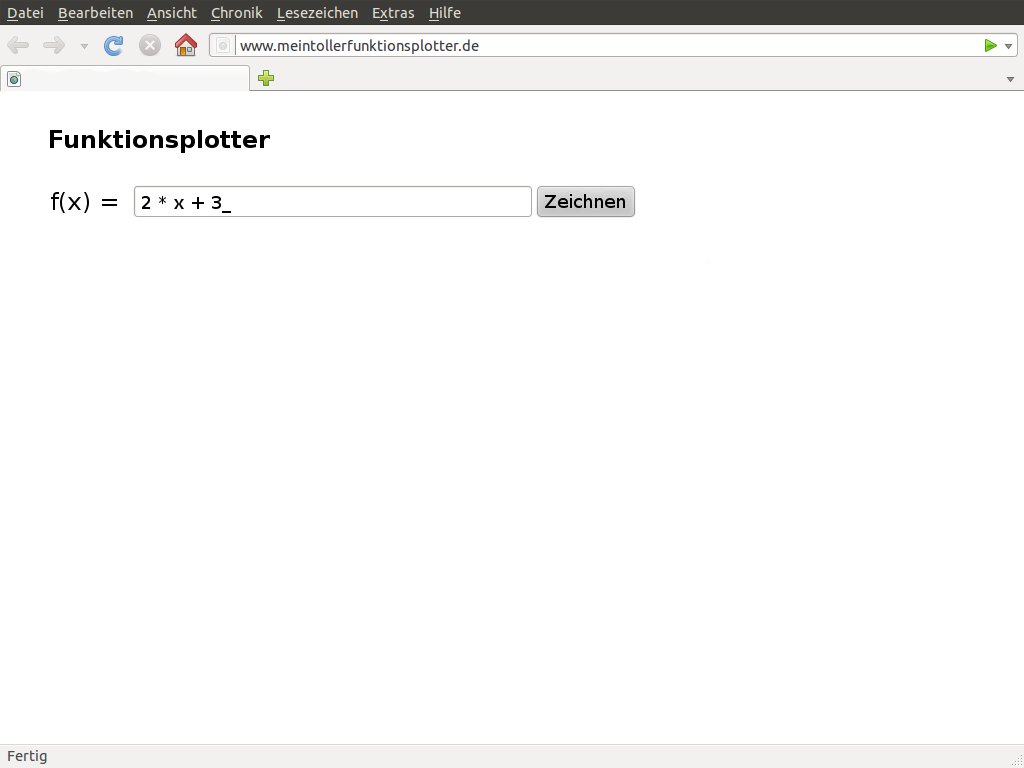
Abbildung 2: Ein Funktionsplotter mit eingebauter Sicherheitslücke (siehe auch Listing 26).
Listing 26
def auswertung(funktion):
for i in xrange(-100, 101):
x = 0.1 * i
y = eval(funktion)
punkte.append((x, y))
zeige_funktion(punkte)
Was aber geschieht, wenn die anzuzeigende “Funktion” nicht 2*x + 3 heißt, sondern os.system('rm -rf *')? Falls irgendwo im Modul das Modul os importiert wurde und der Funktionsplotter mit Schreibrechten auf das Verzeichnis zugreifen kann, löscht er in diesem Fall alle dort gelagerten Dateien!
Es gibt mehrere Möglichkeiten, um solche Sicherheitslücken beim Umgang mit exec und eval zu vermeiden. Zum einen sollten Sie eine erhaltene Eingabe möglichst auf gültige Werte prüfen (Listing 27). Im Code könnte gueltige_werte eine Liste oder ein Set sein. Lässt sich keine Menge gültiger Werte erzeugen, muss ein Parser her. Damit zerlegen Sie die Eingaben für eine sinnvolle Auswertung.
Listing 27
if eingabe in gueltige_werte:
# Alles ok - exec oder eval anwendbar.
...
else:
# Erzeuge Fehlermeldung oder verwende einen Vorgabwert.
...
Je nach gewünschten Ein- und Ausgabedaten können Parser aber recht aufwändig sein. Zum Glück gibt es verschiedene Parser-Frameworks für Python [6]. Interessanterweise findet sich im dort genannten PyParsing-Paket auch ein Parser für arithmetische Ausdrücke, wie man ihn für den Funktionsplotter aus dem Beispiel benutzen könnte.
Auch für das Auswerten des JSON-Formats [7], das oft für den Datenaustausch zwischen Browsern und Webservern zum Einsatz kommt, missbrauchen manche Programmierer gerne eval. Für JSON gibt es jedoch in der Python-Standardbibliothek das Modul json. Viele andere spezialisierte Parser finden sich im Python Package Index, PyPI [8].
Lücken vermeiden mit <C>subprocess<C>
Das Modul subprocess hilft ebenfalls beim Vermeiden von Sicherheitslücken. Bis vor einigen Jahren dient zur Ausführung von externen Kommandos in der Regel die Funktion system aus dem Modul os. Entsprechend oft finden sich entsprechende Stellen noch in älterem Code – und neuerem, bei dem sich der Autor den älteren zum Vorbild genommen hat.
Die Funktion os.system weist jedoch einen großen Nachteil auf, wie Listing 28 zeigt. Für “normale” Verzeichnisnamen ohne Leerzeichen funktioniert dieser Code. Stammt allerdings der Name von außerhalb des Programms, lässt er sich so manipulieren, dass der Code etwas Unerwünschtes tut. Lautet name zum Beispiel . ; rm -rf *, dann zeigt der Aufruf von verzeichnis nicht nur das aktuelle Verzeichnis an, sondern leert es anschließend auch.
Listing 28
import os
def verzeichnis(name):
return os.system("ls -l %s" % name)
Zwar verhindern Sie diesen Angriff durch Einschließen des Platzhalters %s in einfache Anführungszeichen, aber eine nur wenig kompliziertere Zeichenkette umgeht auch diesen vermeintlichen Schutz. Solche Sorgen ersparen Sie sich mit dem subprocess-Modul. Der Code aus Listing 29 deckt die gleiche Funktionalität ab wie jener aus Listing 28, lässt sich aber von hinterhältigen Zeichenketten wie oben nicht verwirren. Hier geht der Inhalt von name direkt an den ls-Befehl, ohne Interpretation durch eine Shell.
Listing 29
import subprocess
def verzeichnis(name):
return subprocess.call(["ls", "-l", name])
Im subprocess-Modul finden sich daneben auch noch sichere Varianten von os.popen und ähnlich gearteten Funktionen.
<C>for<C>-Schleifen vereinfachen
Umsteiger von manchen Programmiersprachen sind es gewohnt, auf Arrays über Indizes zuzugreifen. Nach diesem Muster könnte man die Namen einiger Programmiersprachen so ausgeben, wie in Listing 30 zu sehen.
Listing 30
sprachen = [u"Python", u"Ruby", u"Perl"]
for i in range(len(sprachen)):
print sprachen[i]
Da Pythons for-Schleife jedoch einfach Wert für Wert über eine Sequenz iteriert, kann man den vorherigen Code deutlich einfacher schreiben, wie Listing 31 zeigt. Benötigen Sie den Index doch einmal, nehmen Sie am besten die eingebaute Funktion enumerate in Anspruch (Listing 32). Der bei jedem Schleifendurchlauf erzeugte Index startet bei Null.
Listing 31
sprachen = [u"Python", u"Ruby", u"Perl"]
for sprache in sprachen:
print sprache
Listing 32
sprachen = [u"Python", u"Ruby", u"Perl"]
for index, sprache in enumerate(sprachen):
print "%d: %s" % (index + 1, sprache)
Einfacher Umgang mit Zeichenketten
Zeichenketten, sowohl Byte-Strings als auch Unicode-Strings, gelten in Python als unveränderbar. Sie können hier also nicht wie bei Listen einzelne Abschnitte verändern, sondern müssen bei Bedarf ein neues Zeichenketten-Objekt erzeugen.
Zwar besitzen Strings die Methoden index und find. Wollen Sie aber nur feststellen, ob eine Zeichenkette in einer anderen enthalten ist, erledigen Sie das einfach wie in der ersten if-Anweisung in Listing 33. Daneben gibt es noch Zeichenketten-Methoden, um festzustellen, ob ein String mit einer bestimmten Zeichenkette beginnt beziehungsweise endet. Das demonstrieren die beiden weiteren if-Anweisungen des Listings.
Listing 33
string = "Python"
if "th" in string:
print 'String enthält "th".'
if string.startswith("Py"):
print 'String beginnt mit "Py".'
if string.endswith("on"):
print 'String endet mit "on".'
Wichtig für robuste Python-Programme ist auch die Unterscheidung zwischen Byte-Strings und Unicode-Strings. Dazu gilt es aber weiter auszuholen, so dass dieses Thema einem späteren Artikel vorbehalten bleibt. Einen Einstieg ins Thema finden Sie in der Python-Unicode-FAQ [9].
Faustregel: Optimiere (noch) nicht
Sowohl Programmieranfänger als auch mancher Fortgeschrittene versuchen sich schon beim ursprünglichen Schreiben von Code an Geschwindigkeitsoptimierungen. In aller Regel führt das nicht zu einer schnelleren Ausführung, sondern nur zu schwerer verständlichem Code. Dazu kommt, dass manche “Optimierungen” nicht den gleichen Effekt haben wie in anderen Sprachen und den Code womöglich sogar langsamer machen.
In Bezug auf Geschwindigkeitsoptimierungen sollten Sie sich daher an die Regeln halten, die für alle Programmiersprachen gleichermaßen gelten: Schreiben Sie den Code zunächst so wartbar wie möglich. Stellen Sie parallel dazu sicher, dass der Code wie erwartet funktioniert. Oft läuft das Programm am Ende dieser Entwicklung schon schnell genug.
Tut es das nicht, hilft definitiv kein Raten, um herauszufinden, wo Sie dem Code auf die Sprünge helfen müssen. Mit einem Profiler (in der Regel kommt dazu das Python-Modul cProfile zum Einsatz) finden Sie heraus, wo genau sich die Flaschenhälse verbergen. Nur an diesen Stellen nehmen Sie gezielt Optimierungen vor und nehmen diese im Interesse der Wartbarkeit wieder zurück, falls sie nicht den erwarteten Erfolg bringen.
Einen ausführlichen Leitfaden zum Optimieren von Python-Code finden Sie bei Interesse in einem älteren Artikel unserer Schwesterzeitschrift Linux-Magazin [10].
Freie Werkzeuge zur Code-Analyse
Kein Programmierer hat stets alle Ratschläge zum Vermeiden typischer Fehler im Kopf. Zum Glück gibt es einige Open-Source-Werkzeuge, die Python-Code statisch auf so manches typische Problem untersuchen, wie etwa ungenutzte Module oder Funktionsargumente.
Die bekanntesten Werkzeuge dieses Genres sind PyLint, PyChecker und PyFlakes [11]. Wunder dürfen Sie von diesen Werkzeugen freilich nicht erwarten. Da sich die Prüfungen jedoch automatisiert vornehmen lassen, sollten Sie die gebotenen Möglichkeiten regelmäßig nutzen. Selbst fortgeschrittene Entwickler profitieren noch von diesen nützlichen Tools.
Fazit: Einfach, verständlich, robust
Python ist einfach – aber nicht so einfach, dass man es allein durch Lesen von Code lernen könnte. Um Fehler zu vermeiden, gilt es mögliche Fallstricke zu kennen. Falls Sie aber bei der Lektüre dieses Artikels den Eindruck gewonnen haben, Python sei eine sehr fehleranfällige Sprache, sollten Sie bedenken, dass viele der Ratschläge (speziell jene zum Vermeiden von Sicherheitslücken) ganz ähnlich auch auf andere Sprachen zutreffen.
Manche Verwirrung entsteht dadurch, dass Programmierer Konzepte aus anderen Sprachen unbedacht auf Python anwenden. Wer erst einmal beispielsweise das Konzept von Namen und Objekten begriffen hat, dem unterlaufen entsprechende Fehler nur noch selten. Daneben enthält der Artikel noch diverse Ratschläge, die nicht der Fehlervermeidung dienen, sondern zu leichter verständlichem und besser wartbarem Code führen, zum Beispiel kompakter formulierte Bedingungen in if-Anweisungen.
Glossar
-
Traceback
-
Folge der Funktionsaufrufe bis zum Auftreten eines Fehlers. Python gibt diese Aufruf-Folge, auch Stacktrace genannt, bei bestimmten Fehlern aus. Diese Ausgabe hilft oft sehr bei der Eingrenzung der Fehlerursache.
Infos
[1] Python: http://www.python.org
[2] Style Guide for Python Code (PEP 8): http://www.python.org/dev/peps/pep-0008
[3] Exceptions vs. Statuscodes (1): http://nedbatchelder.com/text/exceptions-vs-status.html
[4] Exceptions vs. Statuscodes (2): http://nedbatchelder.com/text/exceptions-in-the-rainforest.html
[5] Eingebaute Ausnahmeklassen: http://docs.python.org/library/exceptions.html
[6] Parser-Frameworks für Python: http://nedbatchelder.com/text/python-parsers.html
[7] JSON: http://de.wikipedia.org/wiki/JSON
[8] Python Package Index: http://pypi.python.org/pypi
[9] Python-Unicode-FAQ: http://www.p-nand-q.com/python/unicode_faq.html
[10] Optimierung von Python-Code: http://www.linux-magazin.de/Heft-Abo/Ausgaben/2006/12/Gut-gezielt
[11] Analyse-Tools für Python: http://www.doughellmann.com/articles/pythonmagazine/completely-different/2008-03-linters/





Dieser Punkt im Styleguide ist wirklich der größte Mist. Mal abgesehen, dass vier Zeichen eben immer auch als vier Zeichen gespeichert werden müssen, kann es leicht dazu kommen, dass auch mal nur drei verwendet wurden, weil es eben bescheuert ist, eine Ebene durch das vierfache von etwas einzurücken. Zudem sind leerzeichen Starr, wohingegen die Tabweite von jedem Entwickler per Editor-Einstellung an die eigenen Bedürfnisse angepasst werden kann. Deshalb: Auf den Style-Guide scheißen, da waren halt Idioten am Werk, und Tabs benutzen. Immer und überall.