

Der fünfte Teil der Postscript/PDF-Reihe legt den Fokus auf Tipps und Tricks, die den Umgang mit Postscript und PDF im Alltag leichter machen.
Serie Postscript/PDF-Tools
| Teil 1 | Anzeigen und Konvertieren | https://www.linux-community.de/artikel/19014 |
| Teil 2 | Zerlegen und Zusammensetzen | https://www.linux-community.de/artikel/17410 |
| Teil 3 | Mehrfachdruck und Poster | https://www.linux-community.de/artikel/19376 |
| Teil 4 | Flyer, Booklets und Bücher | https://www.linux-community.de/artikel/19481 |
| Teil 5 | PDF-Werkzeuge | https://www.linux-community.de/artikel/19635 |
Die Überprüfung eines Files auf dessen Korrektheit gehört zu den ersten Aufgaben einer Druckerei oder eines Archivierungssystems. Nichts ist schlimmer als der Fall, dass das übergebene File Fehler aufweist oder benötigte Informationen nicht vorliegen. Lediglich den Dateinamen zu kontrollieren, reicht hier nicht aus, da dieser keinen eindeutigen Rückschluss auf den tatsächlichen Inhalt der Datei gestattet.
Informationen sammeln
Eine grundlegende Prüfung auf das vorliegende Datenformat bietet das file-Kommando. Es vergleicht die ersten Bytes – die sogenannten Magic Numbers – mit Einträgen in einer Datenbank, die im File /usr/share/file/magic lagert. Findet file eine Übereinstimmung, gibt es den dazu hinterlegten Dateityp zurück [1]. Abbildung 1 zeigt, dass sich hinter dem File irgendwas.ps mit hoher Wahrscheinlichkeit ein OpenOffice-Dokument verbirgt, die zweite Datei Postscript Level 2 beinhaltet und es sich beim dritten File ein PDF-Dokument handelt, das der PDF-Version 1.6 entspricht. Die Versionsangaben sind hier wichtig, da viele Postscript-Tools nur Level 1 und 2 unterstützen. Für PDF gilt hier die Version 1.5 als magische Grenze. Nachfolgende Erweiterungen lassen sich unter Linux bisher nur unvollständig nutzen.
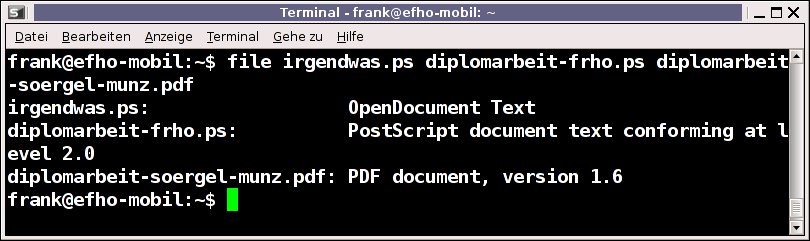
file den Dateityp.” width=”300″ height=”89″ />
Abbildung 1: Anhand der sogenannten Magic Numbers erkenntfile den Dateityp. Wer detailliertere Informationen braucht, benötigt ein Tool, das den Datei-Inhalt genauer analysiert. Bereits ein kurzer Blick in die Linux-Werkzeugkiste fördert pdfinfo aus dem Xpdf-Paket [2] zu Tage. Damit entlocken Sie einem PDF eine ganze Menge Interna, wie die Abbildungen 2 und 3 demonstrieren. In der Datei hinterlegt finden sich nicht nur Autor und Titel (“Author”, “Title<“), sondern unter anderem auch die genutzten Schlüsselworte (“Keywords”), das Erzeugungs- und Modifikationsdatum (“CreationDate”, “ModDate”), die Seitenanzahl (“Pages”), die PDF-Version (“PDF version”) und die verwendeten Werkzeuge (“Creator”, “Producer”).
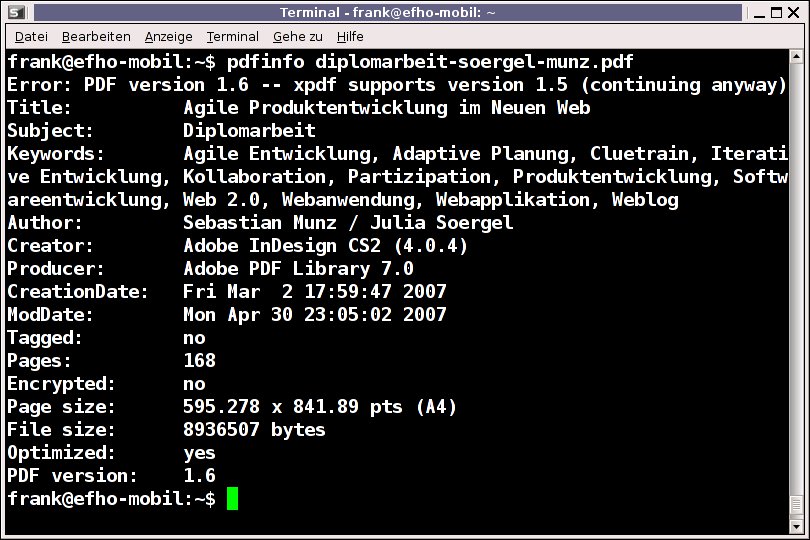
Abbildung 2: Detaillierte Informationen in einem PDF – so soll es sein.
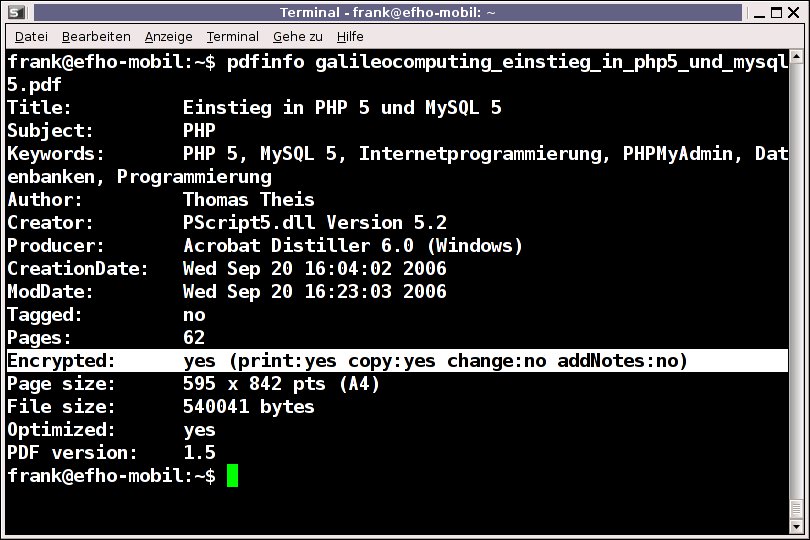
Abbildung 3: Bei diesem PDF hat der Autor die Nutzungsmöglichkeiten beschränkt.
Die in Abbildung 3 untersuchte Datei lässt sich nur eingeschränkt nutzen, da vom Autor das Feld “Encrypted” entsprechend gesetzt wurde. Zwar darf man das File uneingeschränkt drucken und kopieren (“print:yes copy:yes”), aber nicht verändern (“change:no”). Weiterhin gestattet der Autor keine Notizen im Dokument (“addNotes:no”).
Details in der Präambel
Für Postscript hilft ein Blick in die Postscript-Spezifikation [3] oder das Postscript-Referenzhandbuch von Adobe [4]. Beiden lässt sich entnehmen, dass sich am Anfang eines jeden Postscript-Files eine Präambel befindet, die die gesuchten Informationen enthält. In Abbildung 4 umfassen die Zeilen 1 bis 7 die Präambel, bei den Zeilen 8 bis 11 handelt es sich um Kommentare. Zeile 1 nennt das genutzte Postscript-Level (Level 2), Zeile 2 das Programm, mir dem das Postscript-File erzeugt wurde (“Creator”). In diesem Fall ist es dvips, ein Werkzeug zum Umwandeln geräteunabhängiger Files (DVI: “device independent”) nach Postscript.
pdflatex erzeugt wurde.” width=”300″ height=”122″ />
Abbildung 4: Auflistung eingesetzter Fonts in einem PDF, das mitpdflatex erzeugt wurde.In Zeile 3 findet sich der Titel des Dokuments (“Title”), in Zeile 4 die Seitenanzahl (“Pages”) und in Zeile 5 die Seitenabfolge (“PageOrder”) – im vorliegenden Fall aufsteigend (“ascend”). Die “Bounding Box” in Zeile 6 spezifiziert die Seitengröße in pt, hier DIN A4. Die vier Zahlenwerte entsprechen den x- und y-Werten der linken unteren Ecke und der rechten oberen Ecke eines Rechtecks in einem zweidimensionalen Koordinatensystem. Zeile 7 beendet die Präambel mit dem Schlüsselwort “EndComments”.
In den nachfolgenden Kommentaren verweist Zeile 8 auf die Webseite von dvips (“DVIPSWebPage”), Zeile 9 zeigt den vollständigen Kommandozeilenaufruf von dvips, mit dem das Postscript-File erzeugt wurde (“DVIPSCommandLine”). Zeile 10 verrät uns, dass das Postscript-File mit einer Auflösung von 600dpi erzeugt und dabei zusätzlich komprimiert wurde (“DVIPSParameters”). Zeile 11 verweist auf die Daten, die dvips ursprünglich verwendete (“DVIPSSource”). Im vorliegenden Fall handelte es sich um LaTeX-Quellen, die Übersetzung nach DVI fand am 6. März 2004 um 11:21 Uhr statt.
Diese Informationen gestatten Rückschlüsse auf den Ersteller und den Erstellungszeitraum der Datei sowie die dabei eingesetzten Werkzeuge und Optionen. Relevant ist das insbesondere bei wissenschaftlichen Arbeiten, speziell im Zusammenhang mit der Diskussion um Plagiate und die Herkunft von Dokumenten.
Eingebettete Fonts
Viele Anwender vergessen, die verwendeten Fonts in ihr PDF-Dokument einzubetten. Öffnet man ein solches PDF-File auf einem anderen Computersystem, auf dem die verwendeten Fonts nicht vorliegen, so ersetzt der Viewer sie in der Darstellung durch eine mehr oder weniger passende Alternative. Dasselbe gilt für die Ausgabe auf Druckern, die die verwendeten Fonts nicht kennen.
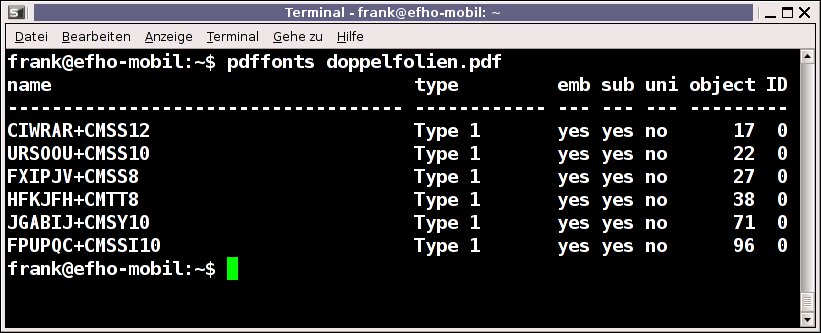
Um zu prüfen, ob das PDF-File die Fonts enthält, liefert das Xpdf-Paket das Werkzeug pdffonts mit. Es ermittelt die verwendeten Schriftartdateien, deren Typ (Type 1, Truetype, CID) und deren Nutzung im Dokument.
Abbildung 4 zeigt, dass im vorliegenden PDF-File sechs verschiedene Type-1-Fonts zum Einsatz kommen, darunter Computer Modern Sans Serif 12pt (CMSS12) und Computer Modern Tele Type 8pt (CMTT8). Alle Fonts sind korrekt in das PDF eingebettet, wie das “yes” aus der Spalte “emb” bestätigt. Das “emb” steht hier als Abkürzung für “embedded” (deutsch: eingebunden, eingebettet).
Texte und Bilder extrahieren
Obwohl Postscript- und PDF-Dokumente primär für den Druck konzipiert wurden, finden sie zunehmend Eingang in Datenbanken und Archive. Automatische Verschlagwortung und Kategorisierung sind dabei aufgrund der Materialfülle unabdingbar geworden. Dateien, die vorwiegend aus eingebetteten Bilddaten und kaum Text bestehen, lassen sich meist nur manuell und mit erheblichem Aufwand klassifizieren. Auch in Sachen Barrierefreiheit erweisen sie sich als problematisch: Sie grenzen Sehbehinderte aus, da man den Inhalt nicht über die Kombination Screenreader [5] und Braille-Zeile auslesen kann. Es gibt keine Möglichkeit, in vertretbarer Zeit die Bilddaten angemessen zu interpretieren und in brauchbaren Text zu überführen.
Die Extraktion von Textbestandteilen gelingt für Postscript-Dokumente hingegen mit den Werkzeugen ps2ascii und pstotext aus dem Ghostscript-Paket ([6],[7]):
$ ps2ascii in.ps out.txt
Der erste Parameter bezeichnet die Postscript-Quelldatei. Aus Ihr extrahiert Ps2ascii den Text und schreibt ihn in das Ausgabefile, das der zweite Parameter benennt. Auch für PDF-Dokumente nutzen Sie Ps2ascii sowie darüber hinaus pdftotext aus dem Xpdf-Paket. Aufrufreihenfolge und Ergebnisse entsprechen jenen bei Ps2ascii:
$ ps2ascii in.pdf out.txt $ pdftotext in.pdf out.txt
Die Qualität des extrahierten Textes variiert erheblich und hängt unter anderem von der Beschaffenheit der Ursprungsdatei ab. Fließtext bereitet kaum Probleme, Schwierigkeiten machen dagegen Worttrennungen, mehrspaltige Dokumente, von Text umflossene Bilder sowie Tabellen. Deren ursprüngliche Anordnung geht nahezu komplett verloren. Umlaute, Sonderzeichen und verwendete Encodings bereiten ebenso Kopfzerbrechen. Als Workaround akzeptiert Pdftotext eine Option -enc Encoding für die gewünschte Kodierung der Ausgabedatei. Sie wirkt allerdings nur sehr begrenzt.
Zum Extrahieren von Abbildungen und Bilddaten gibt es die Werkzeuge psrip[8] sowie pdfimages und pdftoppm (beide aus dem Xpdf-Paket). Das in Perl geschriebene Psrip benötigt als Parameter lediglich das Postscript-File:
$ psrip eingabe.ps $ psrip -d bilder eingabe.ps
Die gefundenen Abbildungen speichert Psrip mit ihrem ursprünglichen Namen im aktuellen Verzeichnis. Über die Option -d Verzeichnis lässt sich auch ein Ordner zum Speichern angeben, im Listing oben ist es das Verzeichnis bilder. Das Ergebnis präsentiert Psrip wie in Abbildung 5.
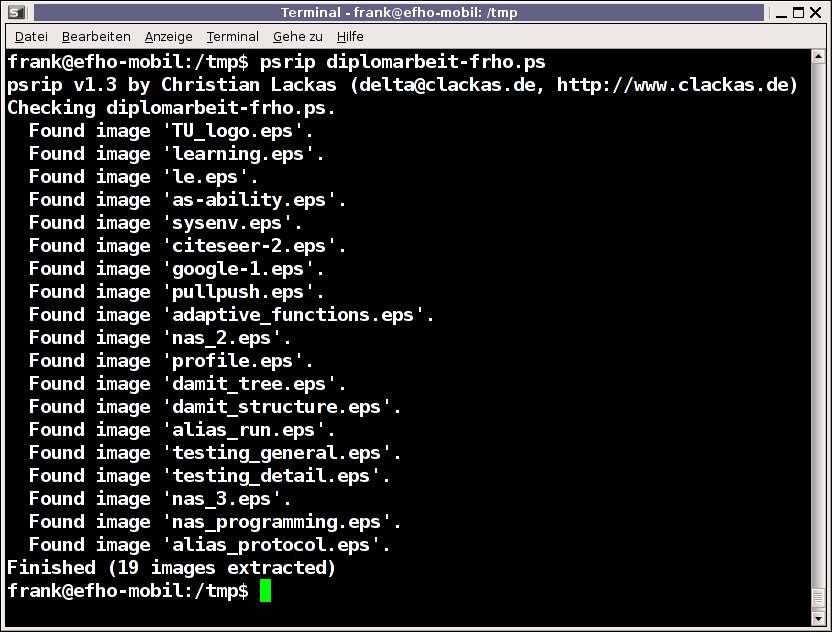
Abbildung 5: Psrip präsentiert die gefundenen und extrahierten Bilddaten.
Bilder aus PDFs extrahieren
Anders als Psrip benötigt Pdfimages neben der Angabe des PDF-Files auch noch eine Bezeichnung oder einen Präfix, um damit die extrahierten Bilder zu benennen. Ohne Angabe weiterer Optionen erzeugt es entweder die Formate Portable Pixmap (PPM) oder – für monochrome Bilder – Portable Bitmap (PBM). Möchten Sie stattdessen Bilder im JPEG-Format erhalten, signalisieren Sie das über die Option -j:
$ pdfimages -j vortrag.pdf bild
Abbildung 6 zeigt den Aufruf von Pdfimages und die Vorschau der aus dem PDF-Dokument extrahierten Bilder. Die Files erhielten das Präfix bild, die Nummerierung erfolgt automatisch in aufsteigender Reihenfolge. Dass bild-002.ppm und bild-003.ppm identisch sind, ist kein Fehler, sondern liegt daran, dass die gleiche Abbildung zwei Mal hintereinander im PDF vorkommt.
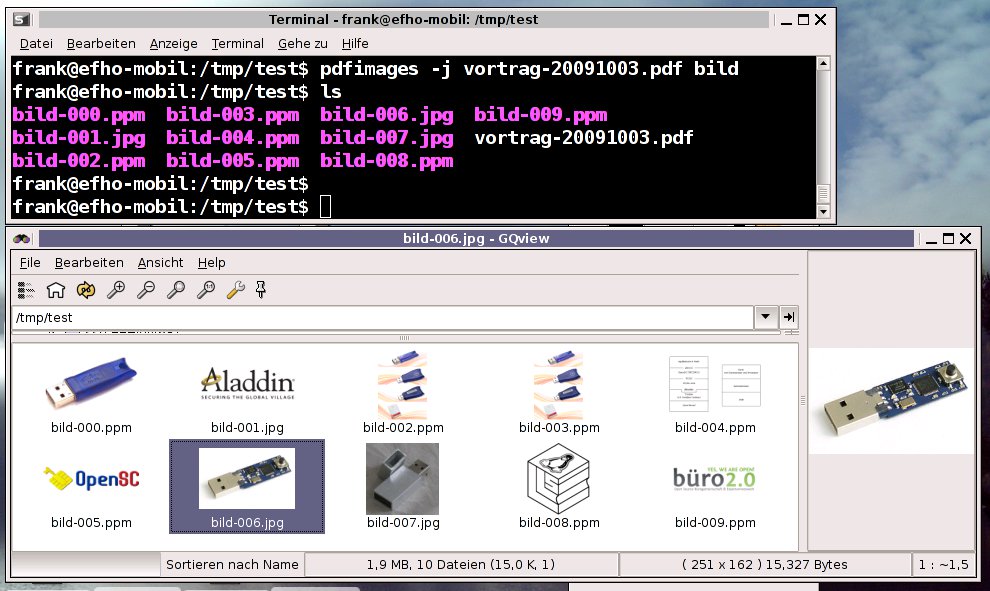
Abbildung 6: Mit Pdfimages aus einem PDF extrahierte Bilder.
Die Qualität der extrahierten Bilder kann Pdfimages nicht beeinflussen, da es die Bilddaten exakt so entnimmt, wie sie im PDF vorliegen. Nachträgliche Veränderungen und das Konvertieren in andere Bildformate erledigen Sie jedoch leicht mittels convert aus dem ImageMagick-Fundus.
Glossar
-
pt
-
Abkürzung für “Points”, ein drucktechnisch begründetes Längenmaß. 1 pt entspricht 0,375 mm.
Infos
[1] Magic Numbers (Wikipedia): http://en.wikipedia.org/wiki/File_format
[2] Xpdf und Foolabs: http://www.foolabs.com/xpdf/
[3] Adobe Postscript Language Specification: http://partners.adobe.com/public/developer/ps/index_specs.html
[4] Postscript Language Reference Manual, Adobe Systems Inc., Addison-Wesley, 1985, ISBN 0-201-10174-2
[5] Screenreader (Wikipedia): http://de.wikipedia.org/wiki/Screenreader
[6] Ghostscript, Ghostview und Gsview: http://pages.cs.wisc.edu/~ghost/
[7] Postscript and Ghostscript Information & Ressource Directory: http://www.inkguides.com/postscript.asp
[8] Psrip für Debian: http://packages.debian.org/de/sid/psrip




