

Wer mit Python programmiert, bekommt mit dem Doctest-Modul eine einfache Möglichkeit, die Programmfunktionen anschaulich zu dokumentieren und gleichzeitig zu testen.
Wie schön wäre es, wenn jede geschriebene Programmzeile automatisch fehlerfrei wäre. Ist sie aber nicht, was das Testen von Software notwendig macht. Manuelle Tests – das heißt das Sichten der Ergebnisse bei jedem Testdurchlauf durch den Programmierer – ist vor allem beim Überarbeiten von Software zeitaufwändig und fehleranfällig. Deshalb empfiehlt sich automatisiertes Testen. Dabei programmieren Sie nicht nur die eigentliche Software, sondern zusätzlich die Tests (siehe Kasten “Testgetriebene Entwicklung”). Das Testprogramm überprüft dann beim Aufruf sowohl die alten als auch die neuen Funktionen. So zahlt sich das Entwickeln speziellerer Tests aus. Unter Python unterstützt Sie das Modul Doctest beim Schreiben der Tests.
Testgetriebene Entwicklung
Eine oft empfohlene Vorgehensweise sieht vor, die Tests vor der zu testenden Software zu schreiben [6]. Was zunächst widersinnig oder zumindest nicht gerade intuitiv erscheint, hat gute Gründe: Haben Sie den Test zuerst geschrieben, machen Sie sich mehr Gedanken über eine saubere Schnittstelle des Codes und passen nicht unbewusst die Tests an die konkrete Implementation an.
Manche Programmierer finden, dass das Schreiben der Tests vor dem zu testenden Code, die so genannte testgetriebene Entwicklung, süchtig macht: Die Arbeit geht leichter von der Hand, weil die Tests wirklich nur die spezifizierte Funktionalität prüfen und klar erkennen lassen, wann die Implementation des nächsten Features ansteht: Nämlich dann, wenn alle Tests zu einer neuen Funktion fehlerfrei laufen.
Erste Schritte mit Doctest
Das Prinzip von Doctest [1] ist, die Tests in den Docstring des zu testenden Moduls beziehungsweise der Klasse, Methode oder Funktion schreiben. Die Tests bestehen aus Anweisungen und den zugehörigen Ausgaben, so wie sie im interaktiven Python-Interpreter aussehen würden. Die Testblöcke grenzen Sie vom umgebenden Text durch Leerzeilen ab. Gegenüber dieser einfachen Vorgehensweise wirkt der Umgang mit dem Unittest-Modul [2] meist recht schwerfällig.
Ein Beispiel zeigt den Einsatz von Doctest: Eine Funktion wertet eine Zeile des so genannten Common-Formats [3] einer Webserver-Zugriffslogdatei aus und gibt die Werte in Form einer Liste zurück. Den Aufbau einer solchen Log-Zeile zeigt Listing 1. Die Informationen umfassen:
- die IP-Adresse,
- die Identd-Information (normalerweise unbenutzt und daher nur durch ein Minuszeichen gekennzeichnet),
- die Benutzerkennung gemäß HTTP-Authentifikation,
- den Zeitstempel aus Datum, Zeit und Zeitzoneninformation,
- eine Zeichenkette in Anführungszeichen, bestehend aus HTTP-Befehl, Pfad und Protokollversion,
- den HTTP-Ergebniscode sowie
- die Anzahl übertragener Bytes (oder alternativ ein weiteres Minuszeichen).
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /index.html HTTP/1.1" 200 2326
Schafft es die Funktion nicht, eine Zeile auszuwerten, soll die Funktion eine Ausnahme ParserError erzeugen. Eine erste Implementation zeigt Listing 2. Führen Sie das Skript aus, liefert der Aufruf von doctest.testmod() in der letzten Zeile ein Ergebnis, wie in Abbildung 1.
#! /usr/bin/env python
# coding: latin1
import doctest
import time
class ParserError(Exception):
pass
def parse_common_log_line(line):
"""Werte eine Zeile im Common-Log-Format aus und gib eine
Liste mit den entsprechenden Werten für IP, Nutzerkennung,
Datum, Zeit (beide ISO-8601-Format), Befehl, Pfad, Protokol,
Status und Länge (0 für unbestimmte Länge) zurück.
>>> parse_common_log_line(
… '127.0.0.1 - frank [15/Oct/2000:13:55:36 -0700] '
… '"GET /index.html HTTP/1.1" 200 2326')
['127.0.0.1', 'frank', '2000-10-15', '13:55:36', 'GET', '/index.html', 'HTTP/1.1', 200, 2326]
Lässt sich die Zeile nicht auswerten, löse eine ParserError-
Ausnahme aus.
"""
parts = line.split()
timestamp = time.strptime(parts[3], "[%d/%b/%Y:%H:%M:%S")
# Identd-Kennung entfernen
del parts[1]
# Datum und Zeit einfügen
parts[2:4] = (time.strftime("%Y-%m-%d", timestamp),
time.strftime("%H:%M:%S", timestamp))
# Zahlen umwandeln
parts[7] = int(parts[7])
parts[8] = int(parts[8])
return parts
if __name__ == "__main__":
doctest.testmod()

Abbildung 1: Der erste Doctest-Lauf zeigt: Es gibt noch überschüssige Anführungszeichen im Ergebnis.
Vergleichen Sie die erwartete (Expected) und die tatsächliche (Got) Ausgabe, fällt in letzterer auf, dass vor dem HTTP-Befehl GET und nach der Protokoll-Angabe noch Anführungszeichen stehen. Diese entfernen Sie leicht, indem Sie im Listing 2 zwei Anweisungen ergänzen (Abbildung 2).

parts aus dem Beispiel.” width=”300″ height=”132″ />
Abbildung 2: Mittels Slicing entfernen Sie die Anführungszeichen von den beiden Elementen der Listeparts aus dem Beispiel. Starten Sie das noch einmal, erhalten Sie – nichts. Das geschieht immer dann, wenn Doctest keine Fehler findet. Herzlichen Glückwunsch! Möchten Sie auch eine Ausgabe zu den bestandenen Tests, erreichen Sie das mit der Option -v (für “verbose”) nach dem aufgerufenen Programm.
Es wartet aber noch ein wenig Arbeit: Ein Minuszeichen als Längenangabe (siehe Funktions-Docstring) führt noch zu einem Fehler. Um das zu prüfen, fügen Sie im Docstring einen zweiten Test ein (Abbildung 3). Das Ausführen der Tests zeigt Abbildung 4. Hier erscheint nur der fehlgeschlagene Test, der bestandene nicht. Die in Abbildung 5 gezeigte Modifikation am Code behebt das Problem und akzeptiert nun auch ein Minuszeichen statt der Längenangabe.

Abbildung 3: Mit einem weiteren Test prüfen Sie, ob das Skript das Minuszeichen in eine Null umwandelt.
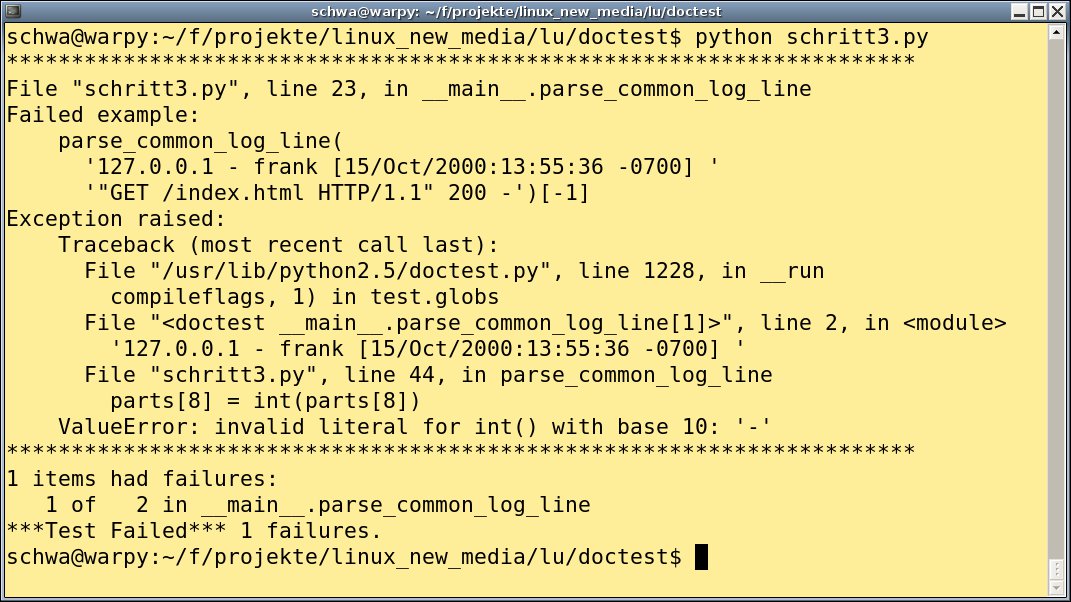
Abbildung 4: Das Umwandeln des Minuszeichens nach Null fehlt noch, deshalb schlägt der neue Test fehl.

Abbildung 5: Ein Minuszeichen für die Content-Länge erlauben.
Zwei weitere Tests im Docstring prüfen, ob bestimmte fehlerhafte Log-Zeilen zu einer Ausnahme ParserError führen. Zunächst geschieht dies nicht. Python löst andere Ausnahmen (IndexError, ValueError) aus. Die Endversion der Funktion (Listing 3) behandelt auch diese Probleme, sodass das Ausführen des Moduls keine Fehler mehr liefert. Beachten Sie, dass ein Test auf eine Ausnahme nicht alle Zeilen des Tracebacks enthält: Stattdessen deutet eine eingerückte Folge von Punkten die Aufrufhierarchie an.
def parse_common_log_line(line):
"""Werte eine Zeile im Common-Log-Format aus und gib
eine Liste mit den Werten für IP, Nutzerkennung, Datum,
Zeit (beide ISO-8601-Format), Befehl, Pfad, Protokol,
Status und Länge (0 für unbestimmte Länge) zurück.
>>> parse_common_log_line(
… '127.0.0.1 - frank [15/Oct/2000:13:55:36 -0700] '
… '"GET /index.html HTTP/1.1" 200 2326')
['127.0.0.1', 'frank', '2000-10-15', '13:55:36', 'GET', '/index.html', 'HTTP/1.1', 200, 2326]
Eine unbestimmte Länge am Zeilenende wird zur Zahl 0:
>>> parse_common_log_line(
… '127.0.0.1 - frank [15/Oct/2000:13:55:36 -0700] '
… '"GET /index.html HTTP/1.1" 200 -')[-1]
0
Lässt sich die Zeile nicht auswerten, löse eine
ParserError-Ausnahme aus.
>>> parse_common_log_line("bla")
Traceback (most recent call last):
…
ParserError: kein Common-Log-Format
>>> parse_common_log_line(
… '127.0.0.1 - frank [123/Oct/2000:13:55:36 -0700] '
… '"GET /index.html HTTP/1.1" 200 2326')
Traceback (most recent call last):
…
ParserError: Datum oder Zeit ungueltig
"""
parts = line.split()
if len(parts) != 10:
raise ParserError("kein Common-Log-Format")
try:
timestamp = time.strptime(parts[3], "[%d/%b/%Y:%H:%M:%S")
except ValueError:
# "time data did not match format"
raise ParserError("Datum oder Zeit ungueltig")
# Identd-Kennung entfernen
del parts[1]
# Datum und Zeit einfügen
parts[2:4] = (time.strftime("%Y-%m-%d", timestamp),
time.strftime("%H:%M:%S", timestamp))
# Anführungszeichen vor HTTP-Befehl und nach Protokoll-
# Info entfernen
parts[4] = parts[4][1:]
parts[6] = parts[6][:-1]
# Zahlen umwandeln
parts[7] = int(parts[7])
if parts[8] == "-":
parts[8] = 0
parts[8] = int(parts[8])
return parts
Literate Testing
Das Code-Beispiel zeigt, wie einfach Sie Code durch Testfälle im Docstring prüfen. Dabei geht jedoch die Übersicht verloren, wenn der Docstring länger als der eigentliche Programm-Code gerät. Besonders häufig passiert dies bei zahlreichen Tests für subtile Sonderfälle.
Sie vermeiden das, indem Sie die Tests in eine Textdatei schreiben und diese mit der Funktion testfile des Moduls doctest ausführen. Eine solche Datei enthält im Wesentlichen den Docstring der zu testenden Funktion ohne die umschließenden Anführungszeichen, eventuell ergänzt um weitere Beschreibungen zwischen den Tests (Listing 4). Dies nennt sich auch Literate Testing [4].
Liegen mehrere solcher Testdateien mit dem Namensmuster test_*.txt in einem Verzeichnisbaum, führen Sie diese mit den Befehlen find und python aus (Listing 5).
Die Funktion parse_common_log_line ================================== Die Funktion befindet sich im Modul parse_common_log_line: >>> import parse_common_log_line as parse Eine als Argument übergebene Zeichenkette aus einer Log-Datei im Common-Format wird damit in eine Liste der Bestandteile zerlegt: >>> parse.parse_common_log_line( … '127.0.0.1 - frank [15/Oct/2000:13:55:36 -0700] ' … '"GET /index.html HTTP/1.1" 200 2326') ['127.0.0.1', 'frank', '2000-10-15', '13:55:36', 'GET', '/index.html', 'HTTP/1.1', 200, 2326] Datum und Zeit werden dabei als Zeichenketten im ISO-8601- Format erzeugt. Die Zeitzoneninformation geht verloren. HTTP-Status und Länge werden in Ganzzahlen umgewandelt. Falls für die Länge nur ein Minuszeichen angegeben ist, ist der entsprechende Listeneintrag 0: >>> result = parse.parse_common_log_line( … '127.0.0.1 - frank [15/Oct/2000:13:55:36 -0700] ' … '"GET /index.html HTTP/1.1" 200 -') >>> result[8] 0 Hier könnten jetzt weitere Absätze und Tests folgen. …
$ find testverzeichnis -name 'test_*.txt' -exec python -c "import doctest; doctest.testfile('{}')" \;
Trickkiste
In der Praxis helfen einige nützliche Funktionen beim Testen. Doctest formatiert die Testergebnisse so, wie es auch der interaktive Interpreter tun würde. Erwartete Zeichenketten verlangen also einfache Anführungszeichen. Es gelten jedoch einige komplexere Regeln, zum Beispiel, falls eine Zeichenkette selbst ein einfaches Anführungszeichen enthält (siehe Kasten “Tipps und Tricks für Doctests”, Zeilen 1 bis 4).
Der Kasten “Tipps und Tricks für Doctests” fasst der Übersichtlichkeit halber mehrere Beispiele zusammen. Jede Leerzeile trennt ein Beispiel vom nächsten ab. Alle Zeilen eines Beispiels gehören – analog zu den Beispielen oben – in den Docstring Ihres Codes, den Sie testen möchten oder in eine getrennte Testdatei.
Tipps und Tricks für Doctests
>>> "ohne Apostroph"
'ohne Apostroph'
>>> """Wie geht's?"""
"Wie geht's?"
>>> class A(object): pass
…
>>> A()
<__main__.A object at 0x8388b0c>
>>> class A(object): pass
…
>>> A() #doctest: +ELLIPSIS
<__main__.A object at 0x…>
>>> range(1000) #doctest: +ELLIPSIS
[0, 1, 2, 3, …, 997, 998, 999]
>>> list(1) #doctest: +IGNORE_EXCEPTION_DETAIL
Traceback (most recent call last):
…
TypeError: 'int' object is not iterable
>>> range(20) #doctest: +NORMALIZE_WHITESPACE
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
>>> print "a\n\nb"
a
<BLANKLINE>
b
>>> vorwahlen
{'Hannover': '0511', 'Berlin': '030'}
>>> d = gib_mir_ein_dictionary()
>>> d == {'Hannover': "0511", 'Berlin': "030"}
True
>>> d = {}
>>> mach_was_mit(d)
>>> d['Berlin']
'030'
>>> 1./13
0.076923076923076927
>>> round(1./13, 6) # immer noch fehleranfaellig
0.076923000000000005
>>> print round(1./13, 6) # viel besser
0.076923
>>> daten = erzeuge_daten()
>>> daten #doctest: +ELLIPSIS
'\x7fELF\x01\x01\x01\x00\x00\x00…\x01\x00\x00\x00\x00\x00\x00\x00'
>>> import md5
>>> md5.new(daten).hexdigest()
'f58860f27dd2673111083770c9445099'
Für einige Situationen bietet das Doctest-Modul Optionen, die Sie an die zu testenden Befehle anhängen [5]. Vor den eigentlichen Optionen steht #doctest: als einleitender String, mehrere Optionsangaben trennen Sie durch Kommas ab. Manchmal tauchen in der Ausgabe eines Tests Bestandteile auf, die sich von einem Testlauf zum nächsten ändern (Zeilen 6 bis 9). Die Adresse in den spitzen Klammern wechselt bei jedem Aufruf. Für einen dennoch konstant funktionierenden Test verwenden Sie den Zusatz ELLIPSIS und kennzeichnen den variablen Teil durch drei Punkte (Zeilen 11 bis 14).
Diese Option hilft Ihnen auch, Schreibarbeit zu sparen (Zeilen 16 und 17). Achten Sie aber darauf, nicht etwa für den Test relevante Teile auszublenden.
Mitunter wechseln von einer Python-Version zur anderen die Fehlermeldungen, die in einer Exception-Ausgabe auftauchen. Zum Beispiel führt die Anweisung list(1) unter Python 2.4 zur Meldung TypeError: iteration over non-sequence, unter Python 2.5 gibt der Interpreter jedoch TypeError: 'int' object is not iterable aus. Solche Unterschiede zwischen Fehlermeldungen dürfen Sie wie in den Zeilen 19 bis 22 mit der Option IGNORE_EXCEPTION_DETAIL vernachlässigen. Der Typ der Ausnahme (hier TypeError) muss nach wie vor stimmen.
Die Option NORMALIZE_WHITESPACE normalisiert Leerraum (Whitespace) in der tatsächlich erzeugten und der erwarteten Ausgabe. Folgen von Leerraum-Zeichen mutieren also zu einzelnen Leerzeichen, was es Ihnen ermöglicht, Ausgaben auf mehrere Zeilen aufzuteilen und zusätzliche Leerzeichen einzufügen (Zeilen 24 bis 26).
Normalerweise sieht Doctest Leerzeilen als Ende eines Tests an. Sind in der Ausgabe echte Leerzeilen zu erwarten, hilft der String <BLANKLINE> in der zu erwartenden Ausgabe. Ohne diese Zeichenkette würde das Doctest-Modul nur die Zeile mit dem a erwarten, was sie mit der Zeichenkette <BLANKLINE> umgehen (Zeilen 28 bis 31). Hier brauchen Sie keine Doctest-Option anzugeben.
Denken Sie daran, dass die Schlüssel/Wert-Paare in Dictionarys keine feste Reihenfolge haben. Ein Test wie in den Zeilen 33 und 34 birgt also die Gefahr eines Fehlers, weil unter Umständen die Reihenfolge in der Ausgabe von Fall zu Fall variiert. Als Test bietet sich in diesem Fall an, das Ergebnis-Dictionary mit dem erwarteten zu vergleichen, siehe Zeilen 36 bis 38. Interessieren Sie dagegen nur bestimmte Einträge, prüfen Sie diese direkt (Zeilen 40 bis 43).
Fließkommazahlen erscheinen je nach Betriebssystem und Bibliotheksversionen unterschiedlich formatiert. Wenn auf Ihrem System der Test in den Zeilen 45 und 46 funktioniert, kann er dennoch auf einem anderen System schiefgehen. Verwenden Sie in diesem Fall die Funktion round in Verbindung mit einer print-Anweisung, um die Ausgaben auf verschiedenen Rechnern zu vereinheitlichen (Zeilen 48 bis 51).
Binärdaten vergleichen Sie bequem auch ohne einen langen Bytestring zu schreiben. Eine Möglichkeit besteht im Gebrauch der Option ELLIPSIS, eine andere im Erzeugen einer Prüfsumme. Die Zeilen 53 bis 58 zeigen beide Varianten.
Ab Python-Version 2.5 empfiehlt es sich, statt des Moduls md5 das Modul hashlib zu verwenden.
Fazit
Mit dem Doctest-Modul bringen Sie Tests auf elegante Art in den Docstrings von Modulen, Funktionen, Klassen und Methoden unter. Ausführlichere Tests lagern Sie besser bis auf grundlegende Anwendungsbeispiele in Textdateien aus. Doctest erweist sich als sehr vielseitig: Mit einigen Tricks nutzen Sie es auch in Fällen, in denen Sie es auf den ersten Blick nicht erwarten würden.
Und zum Schluss noch ein Rat: Schreiben Sie am besten die Tests vor den Funktionen, die Sie prüfen möchten – Stichwort “Testgetriebene Softwareentwicklung”. Viel Spass beim Testen!
[1] Doctest-Modul: http://docs.python.org/lib/module-doctest.html
[2] Unittest-Modul: http://docs.python.org/lib/module-unittest.html
[3] Common-Log-Format: http://httpd.apache.org/docs/2.2/logs.html
[4] Literate Testing: http://www.blueskyonmars.com/2004/11/30/literate-testing
[5] Doctest-Optionen: http://docs.python.org/lib/doctest-options.html
[6] Testgetriebene Entwicklung: http://de.wikipedia.org/wiki/Testgetriebene_Entwicklung




