

Unterschiedliche Zeilenenden oder Zeichenkodierungen machen Linuxern den Datenaustausch schwer. Ein paar Konvertierungstools auf der Shell helfen aus der Misere.
Wenn Sie häufig Textdokumente zwischen Windows- und Linux-Systemen tauschen, passen Sie mit wenigen Kommandos auf der Shell die unterschiedlichen Zeilenenden an – dos2unix und unix2dos konvertieren mit nur einem Befehl. Sollte darüber hinaus ein Zeichensatz Ärger machen, wandeln iconv und recode den Buchstabensalat in ein leckeres und lesbares Gericht um.
Was gibt’s?
Dateiendungen sind Schall und Rauch: Linux unterscheidet Dateitypen nach inhaltlichen Kriterien und nicht nach der Endung des Dateinamens. So erkennt es beispielsweise eine MP3-Datei auch als solche, wenn sie einen Namen trägt, der auf etwas ganz anderes schließen lässt. Abbildung 1 zeigt den Gnome-Dateimanager Nautilus, der sowohl die als Text getarnte MP3-Datei (im Beispiel huhn.txt) als auch die als PNG verkleidete LaTeX-Datei (brief.png) richtig identifiziert hat.
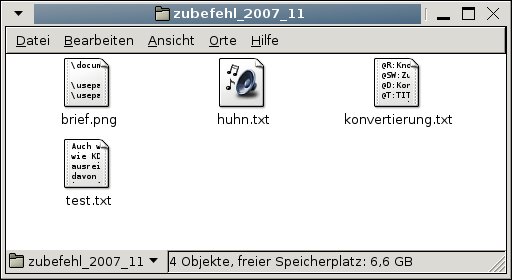
Abbildung 1: Mogeln gilt nicht – Linux erkennt Dateitypen nicht anhand ihrer Enden, sondern anhand ihres Inhalts.
Auf der Kommandozeile hilft das Programm file dabei, die Dateitypen richtig zu erkennen (Listing 1). Das praktische Tool schaut sich Dateien ganz genau an und versucht mit verschiedenen Tests herauszufinden, um was für einen Typ es sich handelt. In der Regel ermöglichen bereits die ersten paar Bytes einer Datei die korrekte Zuordnung. Nur wenn file gar nicht fündig wird, meldet es:
$ file komischedatei komischedatei: data
$ file * brief.png: LaTeX 2e document text huhn.txt: MP3 file with ID3 version 2.3.0 tag test.txt: ISO-8859 text
Das Programm zeigt sich netterweise auch recht informativ, wenn es um Textdateien geht. Dass Text nicht gleich Text ist, zeigt die Ausgabe in Listing 2: Drei Textdateien ergeben drei verschiedene Ausgaben von file: Einmal UTF-8, einmal Windows-Zeilenenden (CRLF, siehe nächster Abschnitt) und einmal ISO-8859. Die nächsten Abschnitte stellen Programme vor, mit denen Sie diese unterschiedlichen Texte für den Austausch mit anderen Systemen fit machen.
$ file * utf8.txt: UTF-8 Unicode text win.txt: ISO-8859 text, with CRLF line terminators iso8859.txt: ISO-8859 text
Das Ende der Zeile …
… ist oft der Anfang des Ärgers, denn die verschiedenen Betriebssysteme nutzen unterschiedliche Kennzeichnungen für Zeilenenden. Die Syntax, die übrigens der Funktionsweise von Schreibmaschinen nachempfunden wurde, fällt unter Linux und Windows unterschiedlich aus: Während Linux-Systemen ein Line Feed (Zeilenvorschub, \n = “new line”) ausreicht, repräsentiert unter Windows eine Kombination aus Line Feed und Carriage Return (Wagenrücklauf, \r = “return”) den Umbruch.
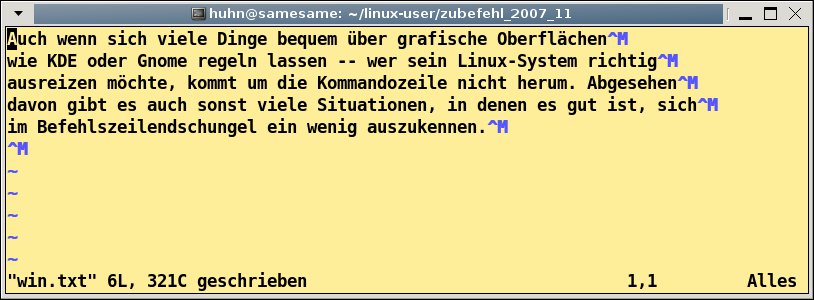
Spätestens beim Öffnen einer Textdatei in einem Editor fällt dieser kleine, aber feine Unterschied auf: Eine unter Windows erstellte Textdatei zeigt im Vim beispielsweise überall ^M-Zeichen (Abbildung 2). Eine mögliche Lösung bieten die beiden Shell-Tools dos2unix (sprich: “DOS to Unix”) und unix2dos (“Unix to DOS”). Wie der Name vermuten lässt, wandeln sie Dateien von einem ins andere Format um.
Unter einigen Linux-Distributionen kommen die beiden Helfer in jeweils eigenen Paketen daher; aktuelle Debian-Versionen liefern stattdessen das Paket tofrodos aus, das die beiden Programme fromdos und todos enthält. Hier weisen zwei symbolische Links von /usr/bin/dos2unix und /usr/bin/unix2dos auf die verwandten Tools, sodass der Benutzer einerseits wie gewohnt mit dos2unix und unix2dos, aber auch mit fromdos und todos arbeiten kann. Die Programme leisten grundsätzlich dasselbe, an einigen Stellen weichen sie allerdings voneinander ab. Der Artikel spricht im Folgenden von dos2unix/unix2dos (da der Aufruf ja auch auf Debian-Systemen funktioniert) und erklärt die jeweils abweichenden Optionen.
^M.” width=”300″ height=”111″ />
Abbildung 2: Zeichen wie von Geisterhand – die unterschiedlichen Zeilenenden erscheinen im Vim als^M.Ende gut, alles gut
Um in einer unter Windows erstellten Textdatei die Zeilenenden für Linux-Benutzer zu “reparieren”, lautet der Aufruf:
$ dos2unix win.txt
In der Standardausgabe gibt sich das Tool gesprächig und verrät, was hinter den Kulissen abläuft:
$ dos2unix: converting file win.txt to UNIX format …
Die Version, die bei Debian mit an Bord ist, schreibt keinerlei Informationen in die Ausgabe. Mit der Option -v (“verbose”) bringen Sie aber auch Debian zum Sprechen:
dos2unix: Converting win.txt
Da der Befehl auf allen Distributionen die Originaldatei bearbeitet und es keine automatische Sicherung gibt, können Sie auf Debian-Systemen mit dem Parameter -b veranlassen, dass dos2unix ein Backup (Datei endet auf .bak) erstellt:
$ dos2unix -b win.txt $ ls win.bak win.txt
Anwender anderer Distributionen geben beispielsweise über den Parameter -n eine neue Ausgabedatei an. Die Syntax lautet dos2unix -n EingabeAusgabe, zum Beispiel:
$ dos2unix -n win.txt linux.txt
Eine weitere nützliche Option ist -k (-p unter Debian): Sie sorgt dafür, dass der ursprüngliche Zeitstempel der Datei erhalten bleibt. Alle gezeigten Aufrufparameter gelten ganz genau so für unix2dos, das entsprechend in die andere Richtung konvertiert.
Zeichensatzchaos
Die einen schwören auf den Klassiker, die anderen setzen auf den vielsprachigen Neuzugang – das Thema “ISO-8859-1(5) versus UTF-8” hat in vielen Foren und Mailinglisten schon fast einen ähnlichen Kultstatus Wie die Diskussion um den besten Texteditor unter Linux. Sämtliche moderne Distributionen bieten in der Voreinstellung mittlerweile UTF-8 an.
Wer den Wechsel aus irgendwelchen Gründen nicht mitvollziehen möchte oder kann, stellt in der Regel mit wenigen Handgriffen zurück auf ISO-8859-1(5), sieht sich aber zum Beispiel beim Austausch von HTML- oder Textdateien oft mit merkwürdigen Sonderzeichen konfrontiert. Leere Kästchen in Menüs oder Dialogen, kaputte Umlaute, und vieles mehr machen den Umstieg in beide Richtungen ungemütlich.
Einen Ausweg bieten die Zeichensatz- und Format-Konverter recode und iconv. Während iconv standardmäßig mit dabei ist, müssen Sie recode in der Regel nachträglich einspielen. Die meisten Linux-Distributionen bringen das Umwandlungstool als Paket mit, sodass Sie es schnell über den jeweiligen Paketmanager installieren.
Welche Formate die beiden Tools unterstützen, verraten beide über den Parameter -l; damit die lange Liste nicht aus dem Terminal herausscrollt, leiten Sie die Ausgabe am besten über das Pipe-Zeichen an einen Pager weiter, zum Beispiel mit recode -l | less oder iconv -l | less.
Mehrmals täglich anwenden
Beide Tools nehmen Dateien entweder direkt im Aufruf entgegen oder arbeiten als eine Art “Filter”: Dann nehmen sie Daten aus der Standardeingabe entgegen und schreiben das Ergebnis auf die Standardausgabe (Abbildung 3). Geben Sie am Prompt beispielsweise
$ iconv -f UTF-8
ein, weiß das Tool, dass der Text, der nun kommt, in UTF-8 kodiert ist. Wenn Sie Sie den Text eintippen oder aus einer Anwendung heraus in die Shell kopieren und die Eingabe über [Strg]+[D] beenden, dann wandelt iconv ihn um und präsentiert das Ergebnis auf der Standardausgabe.
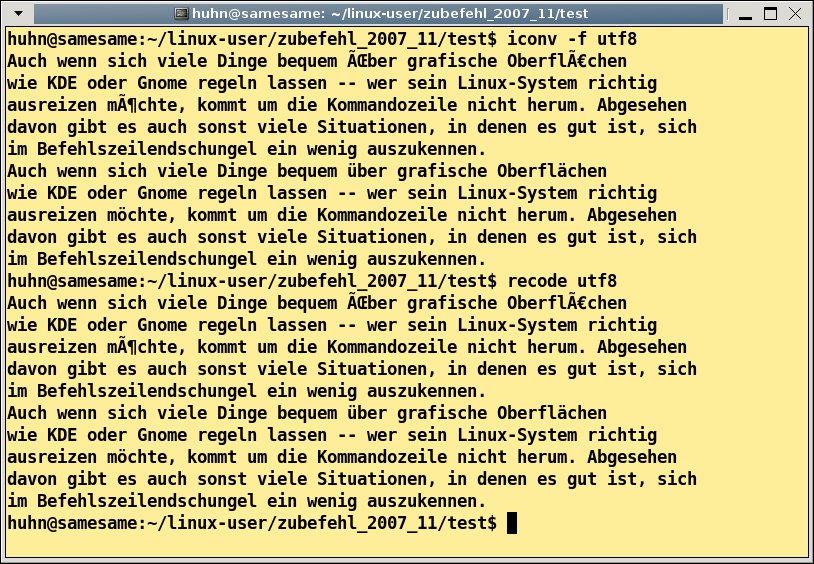
Abbildung 3: Kampf dem Zeichensalat: Wer sich mit UTF-8 nicht anfreunden kann, konvertiert mit einem Befehl in der Shell.
Dabei wählt das Programm in der Voreinstellung für die Ausgabe die Kodierung der eingestellten Locale (echo $LANG, [1]) des Systems. Steht diese beispielsweise auf de_DE@euro, präsentiert iconv das Ergebnis in ISO-8859-15 (Latin-9, enthält neben den in ISO-8859-1 gelieferten Zeichen auch das Euro-Zeichen).
Ähnlich arbeitet recode: Geben Sie recode utf8 ein, wartet das Programm auf einen Text in UTF-8-Kodierung; das voreingestellte Ausgabeformat ist ISO-8859-1 (Latin 1). Ist als Ausgabe etwas anderes gewünscht, geben Sie das bei iconv hinter der Option -t an, zum Beispiel über:
$ iconv -f UTF-8 -t MAC
Eine etwas andere Syntax erwartet recode: Hier übergeben Sie das Ausgabeformat durch zwei Punkte abgetrennt vom Eingabeformat (alte Programmversionen erwarteten einen Doppelpunkt), zum Beispiel:
$ recode utf8..latin9
Die Programme nehmen alternativ schon eine Datei zur Umwandlung beim Aufruf entgegen:
$ iconv -f UTF-8 utf8.txt
$ recode utf8..latin9 utf8.txt
Während iconv das Ergebnis in der Shell ausgibt, überschreibt recode das Original. Ausweg bieten die Umleitungsoperatoren der Shell [2]:
$ recode utf8..latin9 < utf8.txt > iso8859.txt
Ähnliches gilt für iconv; wer die Operatoren nicht einsetzen möchte, kann auf die Option -o ausweichen und dahinter die Ausgabedatei angeben:
$ iconv -f UTF-8 utf8.txt -o iso8859.txt
Fazit
Der Vorteil der Umwandlungskünstler für die Shell liegt auf der Hand: Wer eine große Anzahl von Dateien ans eigene System anpassen möchte, greift zu den bekannten Bash-Tricks:
$ for i in ~/download/*.txt; do recode utf8..lat9 $i; done
Hier sorgt eine kleine for-Schleife dafür, dass recode mehrere Dateien in einem Rutsch verarbeitet. Das funktioniert bei Bedarf natürlich auch mit iconv) sinngemäß.
[1] Umgebungsvariablen für die Bash: Heike Jurzik, “Gut eingerichtet”, LinuxUser 05/2007, S. 88, http://www.linux-user.de/ausgabe/2007/05/088-zubefehl/
[2] Ein- und Ausgabeumleitung: Heike Jurzik, “Datenfluss”, LinuxUser 07/2007, S. 94, http://www.linux-user.de/ausgabe/2007/07/094-zubefehl/




