
Wer heutzutage mit einem handelsüblichen Computer arbeitet, verwendet meistens automatisch auch eine Festplatte. Wie die Dateien auf der Festplatte gespeichert werden, und welche Möglichkeiten dabei geboten werden, weiß hingegen kaum jemand. Dieser Artikel will etwas Licht ins Dunkel bringen.
Physikalisch gesehen bestehen Festplatten aus rotierenden Scheiben und bewegbaren Schreib- und Leseköpfen. Die Anzahl der Scheiben sowie der Schreib- und Leseköpfe hängt von der Bauart der jeweiligen Festplatte ab. Beim Hochfahren des Rechners fährt auch die Festplatte an, und der Motor rotiert die Scheiben gleichmäßig. Bei älteren Festplatten sind das 5400 oder 7200 Umdrehungen pro Minute (rpm, rotations per minute) bei den neuesten Modellen sind es sogar 10000 oder 15000 Umdrehungen pro Minute.
Bei Lese- und Schreibvorgängen wird der Schreib-/Lesekopf an die passenden Stellen bewegt. Dieser Vorgang wird auch als Seek bezeichnet. Die Geräusche, die Festplatten machen, haben daher auch zwei Ursachen. Zum einen stammen sie von den rotierenden Scheiben des Motors, der sie antreibt. Diese Geräusche sind permanent. Falls die Festplatte zu laut ist, kann man die Drehzahl teilweise herunterregeln und damit eine schnurrendleise Festplatte erhalten. Zum anderen stammen die Geräusche von den Bewegungen der Schreib-/Leseköpfe bzw. deren Motoren. Diese Geräusche sind abhängig von den Zugriffen auf die Festplatte.

Abbildung 1: Aufbau einer Festplatte
Adressierung
Bei der Adressierung der Daten auf der Festplatte werden zwei unterschiedliche Schemata verwendet. Das Betriebssystem muss zur Speicherung der Daten auf den Scheiben irgendwie festlegen, an welcher Stelle die Daten geschrieben werden sollen beziehungsweise von wo sie später wieder gelesen werden sollen. Dazu wird der Platte die gewünschte Position mitgeteilt, daraufhin wird der entsprechende Kopf an die korrespondierende Stelle bewegt, und die Daten werden gelesen bzw. geschrieben.
Die kleinste adressierbare Einheit ist dabei ein Sektor mit einer Kapazität von 512 Byte. Mehrere Sektoren sind in einer Spur organisiert. Die Spuren ergeben konzentrische Kreise auf der Oberfläche einer Scheibe, um den Mittelpunkt herum (siehe Abbildung). Die Anzahl der Spuren und die Anzahl der Sektoren auf diesen entsprechen dem Grad der Dichte der schreibbaren Bereiche. Je dichter die Bits gepackt werden können, desto dichter liegen Spuren bzw. Sektoren nebeneinander, und desto mehr von ihnen sind vorhanden. Daraus ergibt sich hauptsächlich die Kapazität der Festplatte.
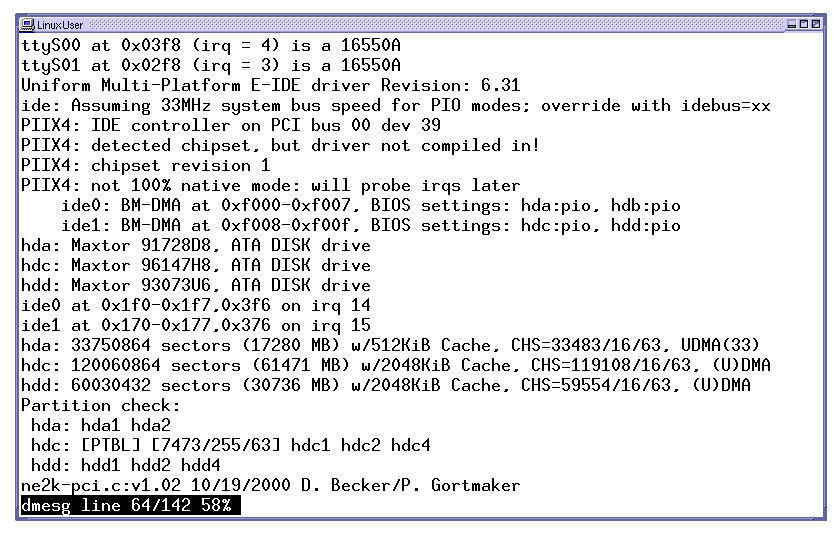
Abbildung 2: Linux findet drei Festplatten beim Booten
Spur 0 ist dabei die äußerste Spur, und zur Mitte der Scheibe wird hochgezählt. Spuren mit der gleichen Nummer werden zu Zylindern zusammengefasst. Die Kapazität einer Festplatte berechnet sich somit aus der Anzahl der Köpfe, der Anzahl der Spuren beziehungsweise Zylinder, der Anzahl der Sektoren pro Spur und der Größe der Sektoren.
Beim Starten des Linux-Kernels werden Informationen über die erkannten Festplatten auf der Konsole ausgegeben. Linux schreibt dabei auch gleich die von der Festplatte übermittelte Plattengeometrie und die sich daraus ergebende Anzahl der Sektoren und Gesamtkapazität (siehe Abbildung 2) auf.
Tabelle 1: Berechnung der Festplattengröße aus der Plattengeometrie
| 5005 | x 255 | x 63 | x 512 Bytes | = 40 GB |
| 119108 | x 16 | x 63 | x 512 Bytes | = 60 GB |
Ein mögliches Adressierungsschema wird mit CHS bezeichnet. Die Buchstaben ergeben sich aus den ersten Buchstaben von “Cylinder-Head-Sector”. Wenn auf einen Sektor auf einer Festplatte zugegriffen werden soll, übermittelt das Betriebssystem dem BIOS über den Interrupt 0x13 (hexadezimal 13, dezimal 19) die passende Kombination aus Kopf, Zylinder und Sektor.
Größenbeschränkung
Die Sache hat allerdings einen kleinen Haken. Für die Darstellung der Adresse stehen weder im BIOS des Rechners noch in der Schnittstelle zwischen BIOS und Festplatte beliebig viele Bits zur Verfügung. Dadurch ergeben sich gewisse Einschränkungen in der maximal addressierbaren Größe und der Geometrie der Festplatten.
Die Schnittstelle zwischen dem BIOS des Rechners und der Festplatte unterliegt der folgenden Spezifikation:
Tabelle 2: Bits zwischen BIOS und IDE-Schnittstelle
| 16 | Bits für Zylinder (0..65535) |
| 4 | Bits für Köpfe (0..15) |
| 8 | Bits für Sektoren (0..255) |
Damit lassen sich also 65536 x 16 x 256 x 512 Byte = 128 GB adressieren.
Diese Spezifikation stammt aus einer Zeit, in der man sich kaum vorstellen konnte, einmal Festplatten mit einer derartigen Kapazität zu betreiben oder den Platz überhaupt zu nutzen. Das war eine Zeit ohne Online-Tauschbörsen und digitale Filme.
Damals konnte man sich auch nicht vorstellen, dass ein Computer irgendwann einmal 1GB RAM besitzt, und irgendwer meinte sogar, dass 640KB ja auch ausreichend seien. Western Digital hat kürzlich die Festplattenserie WD2000 mit 200GB in den Handel gebracht, die mit diesem Schema schon nicht mehr vollständig adressierbar ist.
Doch damit nicht genug der Probleme, denn ein herkömmliches (etwas älteres) PC-BIOS ist knauserig und sieht statt der 28 Bit selbst nur 24 Bit vor, die zudem anders verteilt sind:
Tabelle 3: Bits im BIOS für IDE-Adressierung
| 10 | Bits für Zylinder (0..1023) |
| 8 | Bits für Köpfe (0..255) |
| 6 | Bits für Sektoren (0..62) (max. 63 Sektoren) |
Damit lassen sich insgesamt nur noch 1024 x 256 x 63 x 512 Byte = 7.844 GB adressieren.
Da die niedrigste Breite pro Datenfeld jedoch insgesamt ausschlaggebend ist, bleiben unglücklicherweise nur folgende Werte übrig:
Tabelle 4: Bits insgesamt für IDE-Adressierung
| 10 | Bits für Zylinder (0..1023) |
| 4 | Bits für Köpfe (0..15) |
| 6 | Bits für Sektoren (0..62) (max. 63 Sektoren) |
Damit lassen sich dann nur noch 1024 x 16 x 63 x 512 Byte = 504 MB adressieren, was heutzutage nicht mehr wirklich viel ist.
Um dennoch größere Festplatten vollständig nutzen zu können wurde ein Upgrade oder der Disk Manager von Ontrack benötigt. Nach einem BIOS-Upgrade auf ein BIOS, das CHS-Angaben übersetzen kann, unterscheidet sich bei großen Festplatten die physikalische Geometrie von der logischen. Die logische wird im BIOS angegeben und bei Zugriffen automatisch auf die physikalische umgerechnet. Damit konnte man immerhin einen Großteil der älteren Festplatten doch noch vollständig nutzen.
Im nebenstehenden Screenshot ist die physikalische Geometrie der zweiten IDE-Festplatte mit CHS=119108/16/63 angegeben. Allerdings liefert das BIOS andere Werte, nämlich CHS=7473/255/63, was der Kernel ein paar Zeilen später beim Untersuchen der Partitionstabelle notiert.
Adressierung per LBA
Wie man leicht sieht, stößt man mit einer derartigen Adressierung und heutigen Festplatten andauernd an die Grenzen des Machbaren. Der Ausweg besteht in einer komplett anderen Art der Adressierung. Diese wurde 1995 mit LBA eingeführt. LBA ist die Abkürzung für “Logical Block Addressing” und nummeriert alle Sektoren beziehungsweise Datenblöcke auf der Festplatte von 0 beginnend durch.
Anfangs standen für LBA nur 28 Bit zur Verfügung, was gegenüber der CHS-Adressierung bereits eine erhebliche Verbesserung darstellt und die vollständige Adressierung von Festplatten bis 128 GB ermöglichte. Inzwischen stehen für die Adressierung jedoch 48 Bit zur Verfügung, womit bei einer Blockgröße von 512 Byte insgesamt 131.072 Terabyte adressiert werden können. Eigentlich sollten ab 2000 jedoch 64 Bit für die LBA-Adressierung vorgesehen sein, womit bei einer Blockgröße von 512 Byte insgesamt 8.589.934.592 Terabyte adressiert werden könnten.
Mehrere Adressierungen im Kernel
Die Kernel-Entwickler sind natürlich bestrebt, dass Linux so viele Systeme wie möglich unterstützt. Daher kennt der Linux-Kernel mehrere Adressierungsarten. Die höchste Priorität hat dabei 48-Bit-LBA. Wenn das von der Hardware oder vom BIOS nicht unterstützt wird, verwendet der IDE-Treiber 28-Bit-LBA. Erst wenn auch das nicht möglich ist, wird als letzter Ausweg die Adressierung mit 28-Bit-CHS verwendet.
Diese Probleme betreffen übrigens nur IDE-Festplatten. Bei SCSI-Festplatten, die unter anderem für Server-Systeme und professionelle (Unix-) Workstation gedacht sind, gibt es diese Probleme nicht. Server-Platten müssen generell größer ausgelegt sein, da sie oftmals viel mehr Daten speichern müssen als einfache IDE-Platten in einem Heim-PC. Bei SCSI-Festplatten wird daher seit jeher LBA zur Adressierung der Blöcke verwendet.
Lesen von der Festplatte
Die gesamte Festplatte ist in Datenblöcke von 512 Byte aufgeteilt. Mit einem Lese- oder Schreibzugriff werden daher immer Vielfache von 512 Byte verarbeitet. Anders ausgedrückt erfolgt der Zugriff auf Festplatten immer blockweise mit einer festen Blocklänge. Gleiches gilt übrigens auch für CD-ROMs.
Wenn die Festplatte angewiesen wird, einen Sektor zu lesen, muss die Festplattensteuerung bei LBA-Adressierung die Sektornummer zuerst in Zylinder/Kopf/Sektor umrechnen. Bei der CHS-Adressierung werden diese Werte direkt aus dem Befehl übernommen. Anschließend wird der Schreib-/Lesekopf an die entsprechende Position gebracht, und während die Oberfläche der Scheiben am Kopf vorbeirauscht, werden die Bits gelesen.
Nach einer internen Pufferung im Festplatten-Controller wird ein Interrupt ausgelöst, der dem Betriebssystem mitteilt, dass Daten gelesen wurden und wo sie liegen oder dass sie erfolgreich geschrieben wurden. Das Betriebssystem kann nun die gelesenen Daten weiterverarbeiten.
Um die Zugriffe zu beschleunigen, insbesondere wenn die gleichen Sektoren erneut gelesen werden, kann ein Block-Cache im Kernel zwischengeschaltet werden. Linux verwendet nicht benötigten Speicher dafür und schrumpft den Cache bei größerem Speicherbedarf der normalen Programme automatisch.
Master Boot Record
Das Betriebssystem kann jedoch nicht alle Sektoren der Festplatte gleichermaßen nutzen. Der allererste Block der Festplatte wird für Metadaten benötigt. In diesem Block wird auf einem PC das Boot-Programm für den Computer gespeichert. Dieses wird beim Rechnerstart vom BIOS aufgerufen, damit der Rechner ordentlich gestartet wird. Unter Linux wird dort meistens lilo oder grub installiert. Der Bootloader kann anschließend weitere Programme starten, z.B. den Linux-Kernel, dessen Plattenposition ebenfalls im Boot-Sektor gespeichert ist.
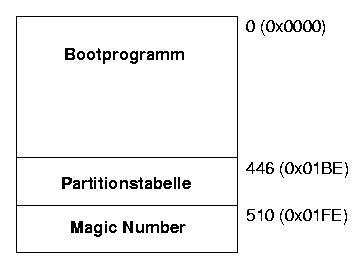
Abbildung 3: Der Master Boot Record (MBR)
Aus diesem Grund wird der erste Block auch Master Boot Record (MBR) genannt. Darüber hinaus wird am Ende dieses Blockes die Partitionstabelle gespeichert, in der die logische Struktur der Festplatte aus Sicht der Betriebssysteme beschrieben wird. Betriebssysteme verwenden meistens nicht die gesamte Festplatte am Stück, sondern einzelne Teile, Partitionen genannt (Abbildung 3 und 4). Die dritte Komponente im MBR ist ein Marker, der standardmäßig auf 0xAA55 steht.
Speichern der Daten
Nachdem die technische Seite geklärt ist, stellt sich natürlich die Frage, wie die Dateien auf der Festplatte gespeichert werden. Eine sehr einfache Möglichkeit wäre es, zu speichernde Dateien der Reihe nach auf die Blöcke zu verteilen, wie es in Abbildung 4 illustriert ist. Die erste Datei ist dabei drei Blöcke groß, gefolgt von einer fünf Blöcke großen Datei. Daran schloss sich eine weitere Datei an, die fünf Blöcke groß war, jedoch später gelöscht wurde, und es folgt eine weitere drei Blöcke große Datei.
Auch wenn diese Möglichkeit sehr einfach aussieht, so hat sie doch zumindest einen Haken: Es wurden keine Dateinamen gespeichert. Ein Programm kann zwar auf die Dateien eins bis vier zugreifen, jedoch keinen Namen mit ihnen verbinden. Für einen Computer mag das vielleicht noch akzeptabel sein, Menschen beschreiben Dateien allerdings lieber mit symbolischen Namen wie /bin/bash oder /usr/bin/emacs.
Abbildung 4: Kontinuierliches Speichern von Daten
Leicht abgewandelt wird dieses Prinzip jedoch trotzdem auch noch heutzutage verwendet. Wer früher mit einem Unix-System auf eine Diskette schrieb, hat meistens einen Befehl ähnlich diesem verwendet:
tar cf /dev/fd0 verzeichnis/
Die Dateien im angegebenen Verzeichnis werden von tar zusammengepackt und anschließend Block für Block hintereinander auf den Datenträger geschrieben. Wenn die Daten später wieder gelesen werden sollten, wurde der Befehl umgedreht:
tar xf /dev/fd0
Auf diese Weise kann zwar immer nur ein Archiv auf Diskette geschrieben werden, und Zugriffe sind nur über tar möglich, aber eine Diskette hat sowieso keine große Kapazität und ist langsam, so dass dieses verzeihlich ist. Der wahlfreie Zugriff auf einzelne Dateien zu jeder Zeit, die bearbeitet, gelöscht und neu geschrieben werden, ist mit dieser Methode nicht möglich.
Heutzutage werden für Disketten meist das DOS-Dateisystem und die M-Tools verwendet. Bei Bandlaufwerken werden die Daten in den meisten Fällen jedoch immer noch roh geschrieben wie früher auf Disketten. In diesen Fällen gehen die Dateinamen nicht verloren, denn solche Informationen werden von tar in den gespeicherten Daten kodiert, so dass sie beim Einlesen wieder zur Verfügung stehen.
Das Dateisystem
Um neben den gespeicherten Daten auch Namen und Attribute auf der Festplatte zu speichern, dürfen die Daten offensichtlich nicht stumpf nacheinander gespeichert werden, insbesondere wenn zur gleichen Zeit auch auf beliebige Daten bzw. Dateien zugegriffen werden soll. Stattdessen muss für den gesamten verwendeten Bereich (meistens eine Partition) eine einheitliche Struktur vorgesehen werden, in der Dateien (und Verzeichnisse) eingebettet werden. Diese Struktur wird üblicherweise Dateisystem oder auf Englisch Filesystem genannt.
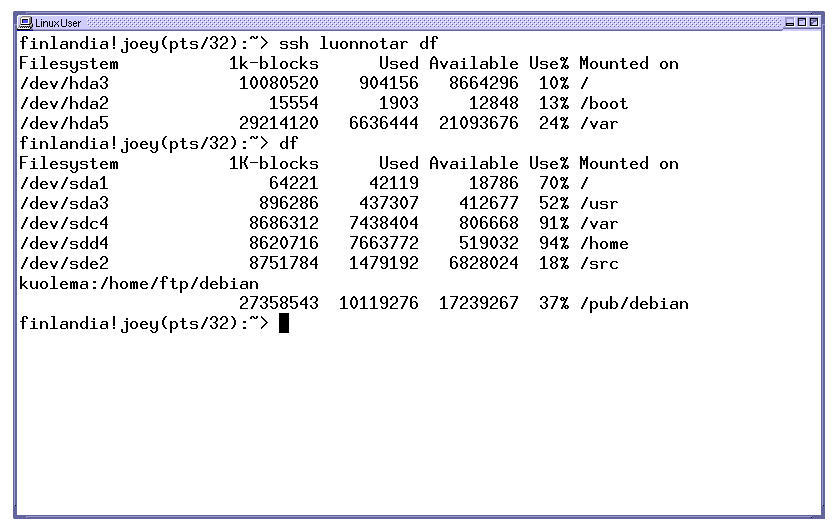
Abbildung 5: Konfiguration der Dateisysteme auf zwei Rechnern
Dateisysteme werden mit mount in das laufende System eingebunden. Das geschieht üblicherweise automatisch während des Boot-Vorgangs. Nur wenn neue Festplatten beziehungsweise Partitionen zu einem System hinzugefügt werden, ergibt sich die Notwendigkeit, manuell einzugreifen. Die Konfiguration des Systems bezüglich der einzubindenden Dateisysteme befindet sich in der Datei /etc/fstab, die beim Booten gelesen wird.
Hier sieht man eine Stärke von Linux und ähnlichen Systemen. Es werden keine Laufwerksbuchstaben vergeben, die sich ändern, sobald eine Partition hinzukommt oder entfernt wird. Stattdessen werden alle Dateisysteme unterhalb von / (Root) in das System eingefügt.
Wenn sich die Bezeichnung der Festplatten später ändert, wenn eine neue Platte eingebaut wird, ändert sich nicht die logische Position im Dateibaum, da die Bezeichnungen die IDE-Channel beziehungsweise SCSI-IDs widerspiegelen. Es müssen in einem solchen Fall keine Anwendungen oder Pfade umgeschrieben, sondern lediglich die Konfigurationsdatei /etc/fstab angepasst werden.
Auf kleinen Systemen existiert oft nur ein einziges Dateisystem für /. Auf größeren Systemen liegen oft zusätzlich /var, /usr und /home auf eigenen Partitionen, um mehr Platz und Unabhängigkeit zu schaffen.
I-Nodes
Dateien werden vom Linux-Kernel automatisch auf die passenden Dateisysteme verteilt beziehungsweise von ihnen gelesen, abhängig vom angegebenen Pfadnamen und den eingebundenen Dateisystemen. Ein Mechanismus im Kernel untersucht dazu den Pfadnamen und ermittelt dadurch das Dateisystem, auf dem die Datei gespeichert wird.

Abbildung 6: Genereller Aufbau einer I-Node
In Unix-orientierten Dateisystemen ist jeder Datei (und jedem Verzeichnis, da es nur eine spezielle Datei ist) zudem ein I-Node zugeordnet. I-Nodes verbinden Verzeichniseinträge mit Datenblöcken auf der jeweiligen Partition. Es handelt sich bei ihnen um spezielle Datenblöcke, die Metadaten zur korrespondierenden Datei speichern. Im Prinzip können sie als Datenstruktur aufgefasst werden, in der zusätzliche Informationen zur Datei gespeichert werden, wie zum Beispiel die Länge, Zugriffsrechte, Besitzverhältnisse, Zugriffszeiten und Zeiger auf die verwendeten Blöcke. Normalerweise werden I-Nodes lediglich intern im Dateisystem verwendet.
Welcher I-Node jedoch zu einer Datei gehört, ist auch für Anwender sichtbar. Mit dem Befehl ls -i (siehe Abbildung) zeigt ls neben dem Dateinamen auch den verwendeten I-Node an. Die Anzahl der Dateien und Verzeichnisse in einem Dateisystem ist damit nicht nur durch die Größe der Dateien und die Gesamtkapazität der Partition, sondern auch durch die Anzahl der I-Nodes limitiert, was bei der Einrichtung berücksichtigt werden muss.
Der generelle Aufbau eines I-Node ist in Abbildung 6 illustriert. Der tatsächliche Aufbau hängt vom zugrunde liegenden Dateisystem ab. Für das Second Extended Filesystem, das für Linux Standard ist, ist der Aufbau in der Datei ext2_fs.h im Kernel beschrieben.
Aus dem Linux Dateisystem lassen sich zahlreiche Informationen entnehmen, denen der Anwender in verschiedener Form begegnet. Ob auf der Kommandozeile oder im Kernel – das Dateisystem ist wortwörtlich allgegenwärtig.




