

Btrfs bringt alles mit, was die großen Spieler im Linux-Business von einem Dateisystem erwarten: Es ist schnell, erweiterbar und flexibel. Dieser Artikel stellt Ihnen das neue Linux-Dateisystem vor.
Das Dateisystem Btrfs stammt von Chris Mason [1] und entstand ursprünglich unter den Fittichen von Oracle. Mason beantragte im Dezember 2008 die Integration in den Kernel, was nach einer kurzen Diskussion auch klappte. Btrfs gehört somit ab Kernel 2.6.29 zu den offiziellen unterstützten Linux-Dateisystemen. Das als Journaling-Filesystem ausgelegte Btrfs benutzt klassische B-Trees zur Datenspeicherung. Zu den wichtigsten Features gehören Copy on Write (COW), Snapshots und integrierter RAID-Support. Der Kasten “Dateisystem-Grundlagen” erklärt einige Grundbegriffe zu Dateisystemen.
Chris Mason arbeitete früher bei Suse und war unter anderem für den Support von ReiserFS verantwortlich – er kennt sich somit mit dem Thema Dateisysteme bestens aus. Parallel zu Btrfs arbeitet Oracle auch an dem neuen Netzwerkdateisystem “Coherent Remote File System” (Crfs) [2], das ebenfalls über Snapshot-Fähigkeiten verfügen soll. Es befindet sich aber noch in einem sehr frühen Entwicklungsstadium.
Auch Btrfs selbst muss man noch mit aller Vorsicht benutzen: Das Dateisystemformat dürfte sich in den nächsten Monaten noch ändern, wodurch die Kompatibilität zwischen alten und neuen Btrfs-Volumen verlorengeht.
Dateisystem-Grundlagen
Ein Dateisystem stellt man sich am besten als ein Regal mit sehr vielen Kisten vor. In jeder davon befinden sich weitere Kisten, die ihrerseits wiederum kleinere Kisten enthalten können. Die kleinsten Kisten sind so groß wie die Blockgröße des Dateisystems, in den meisten Fällen also 4 KByte.
Steht man nun vor dem Regal und hat die Aufgabe, etwas darin zu verstauen, muss man sich entscheiden, in welche Kiste man es packt. Eine Strategie besteht darin, eine Kiste so gut wie möglich voll zu packen, dann die nächste zu füllen und so weiter. Eine andere Herangehensweise wäre, so wenig Kisten wie möglich öffnen zu müssen. Damit Sie die verstauten Gegenstände so schnell wie möglich wieder finden, schreiben Sie dann auf eine Kiste zum Beispiel “Lego” oder “Buntstifte”. Die Informationen, was sich wo befindet, nennt man Metadaten, die Legosteine entsprechen dann den Daten.
Das Dateisystem kämpft mit ähnlichen Problemen, es legt Dateifragmente in so genannten Bäumen ab. Btrfs nutzt dazu B-Bäume (B-Tree-FS). Ein Baum besteht aus Blättern (“leaves”) und Verzweigungen/Knoten (“nodes”). B-Trees versuchen, den Baum so flach wie möglich zu halten, um die Schreib- und Lesezugriffe zu beschleunigen. B+-Bäume speichern die Metadaten nur in den Knoten, die eigentlichen Daten in den Blättern. Traditionelle B-Bäume, wie sie auch Btrfs benutzt, halten sich nicht streng daran. Im Unterschied zu den fest vorgegebenen H-Bäumen, wie sie zum Beispiel Ext4 benutzt, legt Btrfs die Anzahl der möglichen Knoten und Blätter nicht beim Anlegen des Dateisystems fest, sondern bei Bedarf dynamisch. Die Zahl der möglichen Dateien pro Dateisystem hängt deshalb nicht von der Größe des Speichermediums ab.
Wie bei den meisten aktuellen Dateisystemen handelt es sich auch bei Btrfs ein so genanntes Journaling-Filesystem: Das bedeutet, dass das Dateisystem über sämtliche Dateioperationen Buch führt und so verhindert, dass eine Datei in einem nicht benutzbaren Zustand verbleibt. Dazu schreibt das Filesystem die Dateien zunächst in den Journal-Bereich, und erst wenn dieser Vorgang erfolgreich war, frischt es die Informationen dazu auf.
Traditionelle Dateisysteme überschreiben beim Speichern einer Datei die vorhandenen Datenblöcke. Ändert sich dabei die Größe einer Datei, benutzt das Dateisystem freie Blöcke in der unmittelbaren Nähe. Je nachdem, wie viel Zeit zwischen dem ersten Speichern und dem Überschreiben verging, kann diese “unmittelbare Nähe” schon ganz weit entfernt sein – der Lesekopf muss somit größere Distanzen zurücklegen. Moderne Dateisysteme schreiben Daten stets an einen freien Ort, bei jedem Speichern wird somit eine neue Kopie angelegt. Diesen Mechanismus nennt man Copy on Write. COW bringt mehr Performance, da der Lesekopf die Daten in der Regel am Stück einlesen kann, und als nützliche Zusatzfunktion eine Versionsverwaltung: Die ursprünglichen Daten sind ja noch vorhanden.
Installation
Wer Btrfs ausprobieren möchte, nutzt dazu am besten den Kernel 2.6.29, der das Dateisystem bereits mitbringt. Damit der Kernel das Dateisystem nutzt, muss in der .config-Datei ein Eintrag CONFIG_BTRFS_FS=y vorhanden sein. Für diesen Artikel und die Tests im Dateisystem-Benchmark-Artikel kompilierten wir den Kernel 2.6.29-rc4 unter OpenSuse in der 64-Bit-Version. Btrfs übersetzten wir als Modul inklusive ACL-Support (CONFIG_BTRFS_FS_POSIX_ACL=y).
Neben dem Kernelmodul benötigt man auch die entsprechenden Tools, um Btrfs-Dateisysteme anzulegen und zu verwalten. Diese findet man auf Kernel.org [3]. Wir nutzten Version 0.18 der btrfs-progs vom 17. Januar 2009. Sowohl der Kernel als auch btrfs-progs ließen sich problemlos kompilieren.
Vorteile von Btrfs
Während Ext4 Dateien und Dateisysteme von maximal 1 Exabyte unterstützt, sind es bei Btrfs gleich 16 EByte (16 Millionen TByte). Die eigentlichen Vorteile liegen aber nicht beim typischen “schneller” und “besser”, sondern bei den Features: Btrfs lässt sich ohne zusätzliches Volume-Management oder Software-RAID über mehrere Datenträger hinweg als RAID 0, RAID 1 oder RAID 10 nutzen. Dazu ruft man einfach mkfs.btrfs mit den gewünschten Gerätedateien auf und legt danach den RAID-Modus fest:
# mkfs.btfs /dev/sdb /dev/sdc # mkfs.btrfs -m raid1 /dev/sdb /dev/sdc
Weitere Festplatten lassen sich bei Bedarf auch im laufenden Betrieb (online) hinzufügen beziehungsweise entfernen.
Im Gegensatz zu Ext4, das nur das Journal mit Prüfsummen versieht, erzeugt Btrfs für alle Dateien eine Prüfsumme (aktuell per CRC32C). Über diese Checksumme kann das Dateisystem fehlerhafte Dateien praktisch sofort erkennen, was bei Dateisystemen von mehreren Terabyte enorm wichtig ist, um lange Dateisystemchecks zu vermeiden.
Ein weiterer Vorteil gegenüber Ext4 besteht in der dynamischen Vergabe von Inodes. Ext3 legt diese beim Formatieren an, die Größe des Datenträgers bestimmt somit die Anzahl Inodes. Da sich aber pro Inode nur eine Datei respektive ein Verzeichnis speichern lässt, kann es bei Ext3 vorkommen, dass man keinen neuen Dateien mehr anlegen darf, obwohl auf der Platte noch freier Platz bleibt. Ext4 kann zwar deutlich mehr Inodes vergeben und umgeht durch die Extents auch das Ext3-Limit von 32?000 Unterverzeichnissen; die Zahl der Inodes bleibt aber weiterhin durch das anfängliche Formatieren festgelegt. Btrfs vergibt sie dagegen komplett dynamisch: Erst, wenn eine Datei auf die Platte geschrieben wird, teilt ihr das Dateisystem einen Inode zu.
Kopieren beim Schreiben
Je mehr Blöcke einer Datei zusammenhängen, desto schneller arbeitet das Dateisystem. Aus diesem Grund legt Btrfs von geänderten Dateien stets eine Kopie an und stellt damit sicher, dass die Blöcke zusammenhängen. Die COW-Funktion bringt aber noch weitere Vorteile mit sich: Durch die Kopie ermöglicht das Dateisystem auch bequeme Zeitaufnahmen, so genannte Snapshots. Dabei handelt es sich eigentlich um Pseudoverzeichnisse innerhalb einer Partition (Subvolumes genannt), die sich per mount in das Hauptvolume einhängen lassen. Da ein Subvolume nur die Änderungen gegenüber dem Hauptvolumen speichert, benötigt es kaum zusätzlichen Speicherplatz.
Ein neues Subvolume legen Sie über den Befehl btrfsctl -S NameVerzeichnis an, einen Snapshot mit btrfsctl -s NameVerzeichnis. Möchten Sie auf den Snapshot LU zugreifen, hängen Sie das eigentliche Btrfs-Volumen aus und stattdessen den Snapshot ein:
mount -o subvol=LU /dev/sda2 /mnt
In unseren Tests mit Kernel 2.6.29-rc4 führte jedoch das Anlegen eines neuen Snapshots noch zu einer Fehlermeldung.
Die COW-Funktion lässt sich über die Mount-Option -o nodatacow auch ausschalten, um zum Beispiel explizit Dateien immer an den gleichen Ort zu schreiben. Mit Ext3cow [4] gibt es auch eine Ext3-Variante mit Copy-on-Write-Support.
Wer Btrfs auf einer Solid State Disk nutzen möchte, hängt das Dateisystem am besten mit der Option -o ssd ein. Sie optimiert die Schreibvorgänge, was laut unseren Benchmarks (Abbildung 1) allerdings zu einem leichten Leistungsverlust führt. Spätere Versionen von Btrfs sollen SSDs automatisch erkennen und entsprechend reagieren.
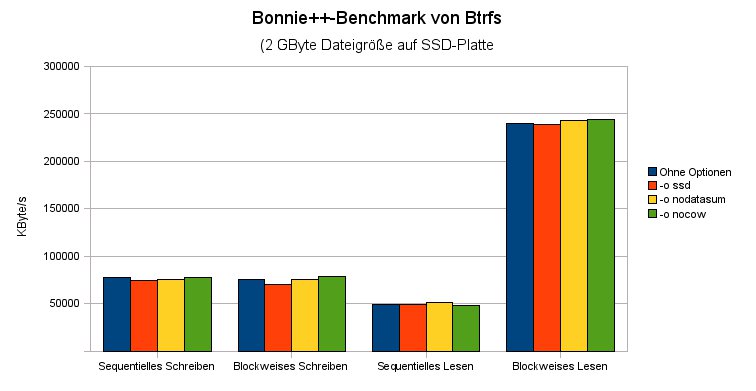
Abbildung 1: Die einzelnen Mount-Optionen wirken sich nur minimal auf die Dateisystem-Performance aus. Die Abbildung zeigt hingegen gut, wie schnell eine SSD (hier von Intel) beim blockweisen Lesen arbeitet.
Für Ext3- und Ext4-Nutzer bietet Mason mit btrfs-convert ein spezielles Tool an, um das Dateisystem nach Btrfs zu konvertieren. Dabei nutzt Btrfs den freien Platz auf der Ext3/Ext4-Partition, um zunächst die Inodes und das Journal abzulegen. Danach erstellt es ein Subvolumen mit dem kompletten Inhalt als Abbilddatei. Dadurch wird das Ext-Dateisystem quasi eingefroren, Änderungen erfolgen nur noch auf Btrfs-Ebene. Bei Bedarf lässt sich das originale Ext3/4-Dateisystem wieder herstellen. Möchten Sie komplett auf Btrfs wechseln, löschen Sie einfach das Subvolume mit den eigentlichen Daten. Details dazu finden sich im Btrfs-Wiki [5].
Fazit
Mit Btrfs bringt der Linux-Kernel ein natives Linux-Dateisystem mit, das dank innovativer Features und Support von bis zu 16 Exabyte Dateisystemgröße gute Chancen hat, zum Linux-Standarddateisystem zu avancieren. Zurzeit eignet es sich allerdings nur für Tests und Spielereien – Heimanwender warten besser, bis die eigene Distribution Btrfs unterstützt.
Glossar
-
CRC32C
-
32-Bit-Cyclic-Redundancy-Check-Algorithmus. Verfahren zur Prüfsummenberechnung nach Castagnoli/Bräuer/Herrmann.
-
Inode
-
Teil des Dateisystems, der die Metainformationen über eine Datei speichert. Jeder Informationsknoten besitzt eine eigene Nummer, die man über den Befehl
ls -i Dateiauslesen kann. -
Extents
-
Fassen mehrere Speicherblocks zu einem zusammenhängenden Bereich (bis zu 128 MByte) zusammen, was Fragmentierung reduziert und die Leistung beim Umgang mit großen Dateien erhöht.
[1] Btrfs-Ankündigung: http://lkml.org/lkml/2007/6/12/242
[2] Crfs: http://oss.oracle.com/projects/crfs/
[3] Btrfs herunterladen: http://www.kernel.org/pub/linux/kernel/people/mason/btrfs/
[4] Ext3cow: http://www.ext3cow.com/Welcome.html
[5] Konvertieren von Ext-Dateisystemen: http://btrfs.wiki.kernel.org/index.php/Conversion_from_Ext3




