

Linux bringt bereits von Haus aus zahlreiche Werkzeuge mit, mit denen sich an der Performance schrauben lässt. Profis aus dem Linux Kernel Performance Project zeigen, wie Sie die Tools optimal einsetzen.
Die erste Aufgabe beim Performance-Tuning besteht darin, die Engpässe im System auszumachen. Die meisten davon finden sich im I/O-Subsystem, beim Memory-Management oder dem Scheduler. Zum Aufspüren dieser Flaschenhälse verfügt Linux über eine gut bestückte Werkzeugkiste. Einige Tools darin eignen sich eher, um den Gesamtzustand des Systems zu beurteilen. Andere sammeln sehr spezifische Informationen über einzelne Komponenten. Dieser Beitrag stellt Vertreter beider Klassen vor.
Viele der aufgeführten Tools richten praktisch alle gängigen Distributionen bereits standardmäßig ein. Einige der Werkzeuge zählen zum Umfang des Pakets sysstat, das Sie meist von Hand beziehungsweise über den Paketmanager Ihrer Distribution nachrüsten müssen. Zu guter Letzt erweisen sich noch die von Intel entwickelten Tools Latencytop und Powertop bei der Optimierung als hilfreich.
Überblick mit Vmstat
Ein guter Ausgangspunkt für eine Performanceanalyse ist ein Gesamtüberblick über die Befindlichkeit des Systems, wie ihn vmstat liefert. Das Beispiel in Listing 1 stammt aus der Messung eines CPU-intensiven Java-Workloads:
# vmstat procs ———--memory———- —swap-- —--io—- —system-- —-cpu—- r b swpd free buff cache si so bi bo in cs us sy id wa 7 0 34328 757464 2712 26416 0 0 0 0 12 616773 34 28 37 0
Die ersten beiden Spalten zeigen, wie viele Prozesse das System ausführen kann, sobald ihnen die CPU zur Verfügung steht (r), und wie viele derzeit blockiert (b) sind. In diesem Fall warten sieben Prozesse in der Run-Queue auf eine Zeitscheibe der CPU, es liegen keine blockierten Prozesse vor. Übersteigt die Anzahl der Prozesse in der Warteschlange vor der CPU (Run-Queue) dauerhaft die Anzahl der Prozessoren respektive CPU-Cores im System, dann deutet das auf eine Überlastung der CPU-Ressourcen hin.
Die Prozesse, die die Spalte b zusammenzählt, schlafen, während sie auf einen Event warten. Meistens handelt es sich dabei um einen noch nicht abgeschlossenen Ein/Ausgabe-Vorgang. Eine hohe Anzahl blockierter Prozesse weist auf ein Performance-Problem hin: In dem Fall sollten Sie untersuchen, worauf genau die Prozesse warten müssen. Im Allgemeinen sollten die Werte in den Spalten r und b möglichst niedrig ausfallen.
Die nächsten vier Spalten unter der Überschrift memory vermitteln einen Eindruck von der Speicherverwaltung. Im Einzelnen geben sie an, wie viel Swap-Space das System nutzt, wie viel RAM derzeit frei ist und wie viel Arbeitsspeicher Buffer und Cache verwenden. Von besonderem Interesse sind dabei die beiden Spalten si und so: Sie geben an, wie viel Memory das System auf die Platte auslagert (so, “Swap out”) beziehungsweise wieder einliest (si, “Swap in”). Enthalten die Spalten über einen längeren Zeitraum höhere Werte als Null, so deutet das entweder auf zu knappe RAM-Bestückung des Rechners oder übermäßige Speicheranforderungen der Applikationen hin. In jedem Fall bremst jedes Swappen das System.
Die nächsten beiden Spalten bi und bo zeigen die Anzahl von empfangenen und gesendeten Datenblöcken für die Blockgeräten, was einen Indikator für die Plattenaktivität darstellt. Diese Zahl sollte zur Arbeitslast passen; erweisen sich die Disks länger als viel beschäftigt, handelt es sich um einen I/O-lastigen Workload.
Die Spalten in und cs unter der Überschrift system verraten etwas über die Anzahl der Interrupts und Context-Switches. Im Fall einer sehr hohen Interrupt-Rate empfiehlt es sich, die Quelle dieser Unterbrechungen zu identifizieren. Dabei hilft der Befehl sar -I XALL. Die Menge der Context-Switches sollte im Verhältnis zur Anzahl laufender Prozesse nicht zu hoch ausfallen, weil jeder Context-Switch durch das Zurückschreiben von Cache-Inhalten einen merklichen Overhead erzeugt. Zu viele Kontextwechsel können ein Anzeichen für einen Konflikt um Locks sein (“Lock Contention”): Dann versuchen verschiedene Prozesse gleichzeitig auf eine allen zugängliche Ressource zuzugreifen.
Die nächsten vier Spalten (us, sy. id und wa) dienen als Indikatoren dafür, wie viel Zeit die CPU jeweils für Applikationen im Userland, den Kernel, im Leerlauf und mit Warten auf Ein- und Ausgaben zugebracht hat. Wünschenswert ist hier ein hoher Zeitanteil für Anwendungen (us) und damit für Arbeit, die Ihnen direkt zugutekommt. Beobachten Sie hier dagegen einen hohen Anteil an Systemzeit und gleichzeitig sehr viele Kontextwechsel, weist das deutlich auf ein mögliches Locking-Problem hin. Wie man in diesem Fall einer solchen Lock-Contention weiter auf den Grund geht, erläutert dieser Beitrag weiter unten im Abschnitt “Locking-Probleme”.
Ein hoher Anteil Idle-Zeit sollte idealerweise ebenfalls nicht das Ziel sein. Summiert sich dazu Leerlaufzeit in der Spalte wa, dann weist das auf einen I/O-Bottleneck hin: Der Rechner muss dann in der Regel auf die Festplatten warten.
Platten-Check
Ein einfaches Mittel, um zu überprüfen, ob Sie die Festplatten richtig konfiguriert haben und diese störungsfrei laufen, bietet hdparm. Das Kommando gibt einmal die Lesegeschwindigkeit beim Zugriff über den Buffer-Cache und zum anderen ohne Pufferung aus (Listing 2). Der zweite Wert sollte nahe an der Maximalgeschwindigkeit der Platte liegen. Fällt er zu niedrig aus, sollten Sie überprüfen, ob die Konfiguration möglicherweise nicht dem Optimum entspricht – so könnten Sie beispielsweise im BIOS einen Kompatibilitätsmodus eingestellt haben.
Einen guten Überblick über alle hardwarenahen Parameter der Platte vermittelt der Aufruf von hdparm -I /dev/Device beziehungsweise für SCSI-Platten analog sdparm. Performance-relevante Parameter wie DMA Setup Auto-Activate optimization sollten korrekt eingestellt sein.
# hdparm -tT /dev/sda /dev/sda: Timing cached reads: 11724 MB in 2.00 seconds = 5870.80 MB/sec Timing buffered disk reads: 184 MB in 3.02 seconds = 60.88 MB/sec
I/O-Engpässe
Um der Befindlichkeit des I/O-Systems weiter auf den Zahn zu fühlen, bietet sich iostat an. Bei einem sehr I/O-intensiven Workload ergibt sich etwa eine Ausgabe, wie sie Listing 3 zeigt. Ergibt sich hier ein hoher Wert für %iowait, so bedeutet das, dass die CPU durch Warten auf die Festplatten häufigen Zwangspausen einlegen muss. Abhilfe ließe sich schaffen, wenn es möglich wäre, einen eigenen Thread für die I/O-Aktionen anzulegen, wodurch der Programmablauf nicht mehr komplett unterbrechen würde, oder aber mit asynchronem I/O zu arbeiten.
Als zweiten Parameter sollten Sie die Anzahl der I/O-Requests in der Warteschlange der Disk, avgqu-sz, im Auge behalten. Er sollte kleiner als Eins sein – andernfalls verlangsamen die Platten das System merklich. Schließlich vermittelt auch der Parameter %util einen guten Eindruck davon, wie beschäftigt die Festplatten jeweils sind.
# iostat -x sda 1 avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 2.16 20.86 0.00 76.98 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 17184.16 0.00 1222.77 0.00 147271.29 0.00 120.44 3.08 2.52 0.81 99.01
CPU-Zeit-Verbrauch
Wer ein Performance-Problem lösen will, der muss wissen, wofür welche Software CPU-Zyklen verbraucht. Beim Beantworten dieser Frage bewährt sich besonders das nützliches und verbreitete Tool Oprofile ([1], Abbildung 1). Sobald es eine vorher einstellbare Anzahl Events beobachtet hat, erzeugt es einen Interrupt und gibt dann über den Systemstatus Auskunft.
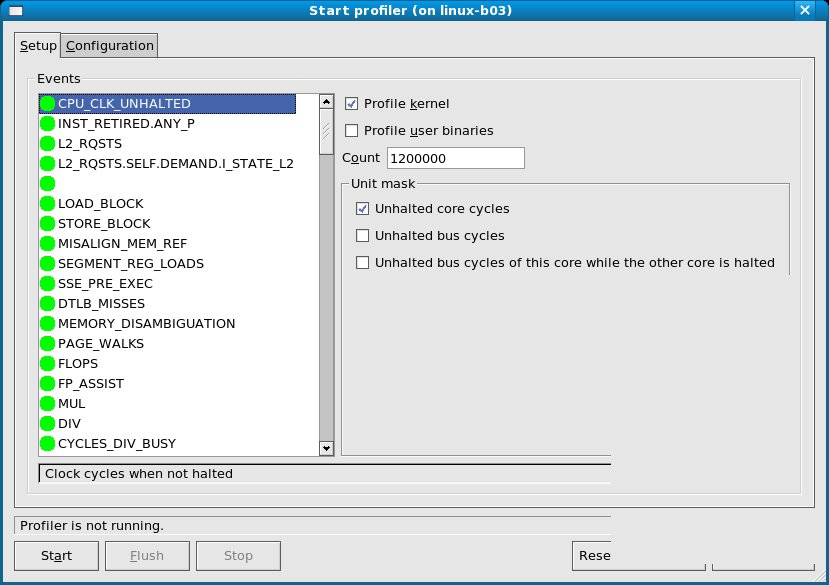
Abbildung 1: Oprofile protokolliert den Zeitverbrauch ausgewählter Events und verrät so auch, wofür die Rechenzeit der CPU eingesetzt wurde.
Alle gängigen Distributionen bringen die Unterstützung für Oprofile bereits fest in den Kernel einkompiliert mit und stellen auch Pakete für das Tool zur Verfügung. Für Ubuntu und seine Derivate finden Sie beispielsweise die Pakete oprofile und oprofile-gui im Repository Universe. Möchten Sie einen eigenen Kernel bauen, müssen Sie für den Einsatz von Oprofile die Optionen CONFIG_OPROFILE=y und CONFIG_HAVE_OPROFILE=y in der Kernel-Konfiguration setzen.
Am einfachsten starten Sie man Oprofile über seine GUI: So brauchen Sie sich nicht mit den Kommandozeilenoptionen des Tools herumzuschlagen. Dazu geben Sie als root in der Konsole den Befehl oprof_start ein. Das bringt ein Fenster mit den Registern Setup und Configuration auf den Bildschirm. Möchten Sie auch den Kernel in das Profiling einbeziehen, geben Sie unter Configuration den Pfad zum Image-File des aktuellen Betriebssystemkerns ein. Haben Sie beispielsweise den Kernel selbst kompiliert, geben Sie also den Speicherort des unkomprimierten Files vmlinux an. Hier lässt sich auch die Option Callgraph aktivieren, die den Call-Stack einer bestimmten Funktion darstellt.
Auf dem Reiter Setup aktivieren Sie nun noch CPU_CLK_UNHALTED in der Event-Tabelle und rechts daneben die Event-Maske Unhalted core cycles. Beim Wert im Feld Count, der besagt, wie viele Events Oprofile in eine Probe aufnehmen soll, passt die Voreinstellung meist. Nun starten Sie zuerst die zu beobachtende Applikation, danach Oprofile, und lassen beide eine Weile laufen. Im Anschluss können Sie sich das aufgezeichnete Profil mittels des Befehls opreport -l ansehen (Listing 4).
# opreport -l CPU: Core 2, speed 2400 MHz (estimated) Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (Unhalted core cycles) count 1200000 samples % app name symbol name 295397 63.6911 cc1 (no symbols) 22861 4.9291 vmlinux-2.6.25-rc9 clear_page_c 11382 2.4541 libc-2.5.so memset 10959 2.3629 genksyms yylex 9256 1.9957 libc-2.5.so _int_malloc 6076 1.3101 vmlinux-2.6.25-rc9 page_fault 5378 1.1596 libc-2.5.so memcpy 5178 1.1164 vmlinux-2.6.25-rc9 handle_mm_fault 3857 0.8316 genksyms yyparse 3822 0.8241 libc-2.5.so strlen […]
Opreport verrät, wie viel Prozent der CPU-Zeit jede Applikation sowie der Kernel verbraucht haben und welche Funktionen sie dabei am häufigsten ausführten. Die Applikationen mit dem höchsten Zeitverbrauch sind natürlich auch die dankbarsten Ziele für eine Optimierung. Haben Sie die Callgraph-Option aktiviert, dann können Sie zusätzlich mit opreport -c eine Statistik wie in Listing 5 abrufen: Dort erkennen Sie im Beispiel heftige Aktivitäten der Speicherverwaltung, die eine Vielzahl an Speicherseiten anfordert und wieder löscht.
# opreport -c CPU: Core 2, speed 2400 MHz (estimated) Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (Unhalted core cycles) count 1200000 samples % image name app name symbol name ——————————————————————————- 295397 63.6911 cc1 cc1 (no symbols) 295397 100.000 cc1 cc1 (no symbols) [self] ——————————————————————————- 1 0.0044 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 path_walk 2 0.0087 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 __alloc_pages 2 0.0087 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 mntput_no_expire 22922 99.9782 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 get_page_from_freelist 22861 4.9291 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 clear_page_c 22861 99.7121 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 clear_page_c [self] 36 0.1570 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 apic_timer_interrupt 24 0.1047 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 ret_from_intr 3 0.0131 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 smp_apic_timer_interrupt 2 0.0087 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 mntput_no_expire 1 0.0044 vmlinux-2.6.25-rc9 vmlinux-2.6.25-rc9 __link_path_walk ——————————————————————————- 11382 2.4541 libc-2.5.so libc-2.5.so memset 11382 100.000 libc-2.5.so libc-2.5.so memset [self] ——————————————————————————- 10959 2.3629 genksyms genksyms yylex 10959 100.000 genksyms genksyms yylex [self] […]
Zu wenig Cache-Treffer
Die Leistung eines Systems hängt in hohem Maß von der Effektivität des Cache ab. Jede erfolglose Suche im Cache (“Cache Miss”) blockiert die CPU und vermindert die Performance. Zuweilen lösen dieses Problem häufig verwendete Felder in Datenstrukturen aus, die nicht in einen Cache-Eintrag passen. Hinweise darauf liefert wiederum Oprofile.
Dazu wählen Sie in dessen Event-Tabelle LLC_MISSES aus und zeichnen so alle L2-Cache-Requests auf, die zu keinem Treffer führen. Erläuterungen zu den einzelnen Event-Typen erhalten Sie übrigens mittels des Aufrufs opcontrol --list events. Nach der Probensammlung gibt opreport -l eine Statistik wie in Listing 6 aus.
# opreport -l CPU: Core 2, speed 1801 MHz (estimated) Counted L2_RQSTS events (number of L2 cache requests) with a unit mask of 0x41 (multiple flags) count 90050 samples % app name symbol name 2803 63.4163 cc1 (no symbols) 190 4.2986 vmlinux-2.6.25-rc9-ltop get_page_from_freelist 102 2.3077 as (no symbols) 60 1.3575 vmlinux-2.6.25-rc9-ltop __lock_acquire 53 1.1991 libc-2.7.so strcmp 39 0.8824 vmlinux-2.6.25-rc9-ltop unmap_vmas 38 0.8597 vmlinux-2.6.25-rc9-ltop list_del
Locking-Probleme
Wie schon erwähnt, ist eine im Verhältnis zur Prozessanzahl hohe Kontextwechsel-Rate nicht wünschenswert und kann auf ein Locking-Problem hinweisen. Um das genauer herauszufinden, nutzen Sie eine Lock-Statistik, die der Kernel seit Version 2.6.23 anbietet. Dazu müssen Sie allerdings den Kernel mit der Option CONFIG_LOCK_STAT=y neu kompilieren. Bevor Sie dann ans Wertesammeln gehen, löschen Sie noch mit echo 0 > /proc/lock_stat die entsprechende Statistik. Dann starten Sie den zu untersuchenden Workload und sehen sich anschließend die Ergebnisse mit cat /proc/lock_stat an.
Die Ausgabe enthält eine Liste der Kernel-Locks, sortiert nach der Anzahl konkurrierender Zugriffsversuche (“Contention”). Für jeden Lock findet sich zusätzlich die kürzeste, die maximale und die kumulierte Wartezeit aufgrund der Konkurrenzsituation. Zudem lässt sich abzulesen, wie oft der Lock gesetzt wurde, wie lange er bestand (kürzeste, längste und kumulierte Zeit) und wer die häufigsten Aufrufer waren. Allerdings erzeugt die Infrastruktur für diese umfangreichen Statistiken auch einen merklichen Overhead – Sie sollten sie daher nur für die Dauer der Untersuchung einschalten, nicht aber im Produktivbetrieb.
Zu hohe Latenz
Ist der Durchsatz eines Programms inkonsistent und stottert es? Hat es den Anschein, das eine Anwendung es erst einschläft, bevor Sie richtig zum Leben erwacht? Tauchen in der Spalte blocked von Vmstat viele Prozesse auf? All das sind oft Anzeichen einer zu hohen Latenz.
Das relativ neue Werkzeug Latencytop [2] spürt eben solche Latenzen auf. Seit dem Release 2.6.25 lassen sich für Latencytop die Optionen CONFIG_HAVE_LATENCYTOP_SUPPORT=y und CONFIG_LATENCYTOP=yin den Kernel einkompilieren. Danach verfolgen Sie über das Userspace-Werkzeug latencytop (Abbildung 2) nach, wo genau die Latenz entsteht.
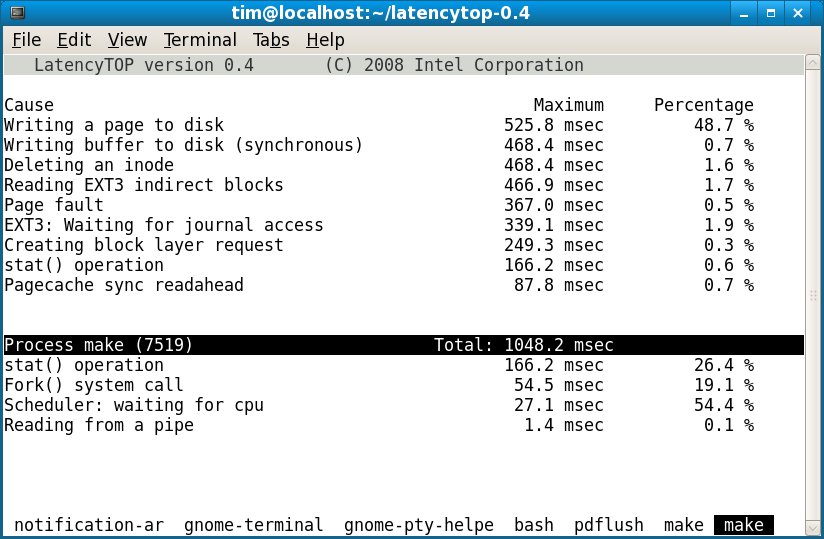
Abbildung 2: Latencytop schlüsselt die hauptsächlichen Ursachen für Latenzen übersichtlich auf.
Latencytop zeigt im typischen Stil der Top-Utilities periodisch die häufigsten Ursachen für blockierte Prozesse. Dabei sortiert es die Ergebnisse nach der Dauer der Blockade und dem Anteil der einzelnen Ursachen an der Gesamtdauer aller Blockaden. Die untere Fensterhälfte schlüsselt diese Angaben pro Prozess auf. Damit gewinnen Sie einen guten Eindruck für die Ursachen der Latenz eines bestimmten Prozesses und des Systems als Ganzem.
Praxisbeispiel
Linux hält sehr häufig benutzte Objekte in Kernel-Caches vor, die man “Slabs” nennt. Dort verwaltet sie ein erst kürzlich eingeführter Manager namens SLUB, der für bessere Performance sorgen soll. Das Kernel Performance Project fand nun aber heraus, dass der Benchmark Hackbench [3], der die Performance des Schedulers misst, beim Kernel 2.6.24/2.6.25-rc eine große Differenz zwischen einem System mit 8 und einem mit 16 CPUs aufwies. Eigentlich sollte man erwarten, dass das System mit 16 CPUs schneller ist, aber das Gegenteil war der Fall: Es lief dreimal so langsam. Woran konnte das liegen?
Zuerst sahen sich die Analysten des Projekts die Ergebnis von vmstat an (Listing 7). Es zeigte sich eine hohe Context-Switch-Rate zusammen mit einer großen Zahl laufender Prozesse. Hackbench simuliert viele Chatrooms mit einer großen Zahl übermittelter Nachrichten. Das beschäftigt – wie Vmstat zeigt – auch die CPU stark, sie hat keine Leerlaufzeit.
procs ———-memory———- —swap-- —--io—- --system-- ——cpu—— r b swpd free buff cache si so bi bo in cs us sy id wa st 360 0 0 15730644 17980 120336 0 0 0 0 320 140047 0 100 0 0 0 327 0 0 15739216 17980 120336 0 0 0 0 322 256259 1 99 0 0 0 412 0 0 15743084 17988 120336 0 0 0 16 282 74537 0 100 0 0 0 421 0 0 15741076 17988 120336 0 0 0 0 311 51750 0 100 0 0 0 334 0 0 15745048 17988 120332 0 0 0 0 295 95434 0 100 0 0 0 468 0 0 15747460 17988 120336 0 0 0 0 251 94440 0 100 0 0 0 373 0 0 15750844 17988 120336 0 0 0 0 268 104569 0 100 0 0 0
Als nächstes untersuchte man mit Oprofile, wo denn die CPU-Zeit abgeblieben war (Listing 8). Heraus kam, dass das System 88 Prozent der Zeit beim Slab-Management mit dem Neuanlegen, Auffüllen und Leeren solcher Caches verbracht hatte.
CPU: Core 2, speed 1602 MHz (estimated) Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (Unhalted core cycles) count 100000 samples % image name app name symbol name 46746994 43.3801 linux-2.6.25-rc4 linux-2.6.25-rc4 __slab_alloc 45986635 42.6745 linux-2.6.25-rc4 linux-2.6.25-rc4 add_partial 2577578 2.3919 linux-2.6.25-rc4 linux-2.6.25-rc4 __slab_free 1301644 1.2079 linux-2.6.25-rc4 linux-2.6.25-rc4 sock_alloc_send_skb 1185888 1.1005 linux-2.6.25-rc4 linux-2.6.25-rc4 copy_user_generic_string 969847 0.9000 linux-2.6.25-rc4 linux-2.6.25-rc4 unix_stream_recvmsg 806665 0.7486 linux-2.6.25-rc4 linux-2.6.25-rc4 kmem_cache_alloc 731059 0.6784 linux-2.6.25-rc4 linux-2.6.25-rc4 unix_stream_sendmsg
Es schien also lohnend, das Slab-Management noch genauer unter die Lupe zu nehmen. Dafür gibt es das Tool Slabinfo: Sein Quelltext findet sich in den Kernelquellen unter Documents/vm/slabinfo.c. Übersetzt und gestartet generierte es den Report aus Listing 9.
# slabinfo -AD Name Objects Alloc Free % Fast :0000192 3428 80093958 80090708 92 8 :0000512 374 80016030 80015715 68 7 vm_area_struct 2875 224524 221868 94 20 :0000064 12408 134273 122227 98 47 :0004096 24 127397 127395 99 98 :0000128 4596 57837 53432 97 48 dentry 15659 51402 35824 95 64 :0000016 4584 29327 27161 99 76 :0000080 12784 33674 21206 99 97 :0000096 2998 26264 23757 99 93
Die Blockobjekte 192 und 512 gehören zu den Messages, die Hackbench produziert: Das eine kommt für den Socket-Buffer-Header zum Einsatz, das andere für den Nachrichtentext. Für jeden Slab-Typ verwaltet der Manager SLUB einen Cache pro CPU. Möchte der Kernel ein neues Objekt anlegen, schaut er zuerst in diesen Caches nach freien Objekten und setzt dabei keinen Lock. Diese Methode ist sehr schnell (“Fast Path”). Findet er dort kein freies Objekt, weist er eine freie Speicherseite zu, wozu er ein Lock benötigt – was langsam ist (“Slow Path”). Dieser Slow Path führt außerdem zu Lock-Contention.
Es zeigte sich, dass das Freigeben und Zuweisen der beiden Blockobjekte sehr langsam ablief, weil der Kernel zum Beispiel für das Objekt 512 nur 68 Prozent der Freigaben und sogar nur sieben Prozent der Zuweisungen über den “Fast Path” realisieren konnte. Um den Anteil der Slow-Path-Allocation zu vermindern, lässt sich der Slab-Cache per CPU erhöhen. Die Tester verwendeten dazu die Boot-Optionen:
slub_max_order=3 slub_min_objects=32
beim Start des Kernels, um die Cache-Größe heraufzusetzen und damit den Anteil langsamer Operationen zu vermindern. Der Durchsatz steigerte sich auf diese Weise signifikant, der Zeitverbrauch sank auf ein Zehntel. Weitere intensive Tests mit verschiedenen Einstellungen brachten ans Licht, dass die optimale Größe für slub_min_objects der doppelten Anzahl der CPUs entspricht. Eine weitere Vergrößerung brachte keine merkliche Verbesserung.
Die Resultate wurden mit der 8-Core-Maschine verifiziert, dann diskutierten die Tester mit den Maintainern des SLUB-Managers. Im Ergebnis entstand ein Kernelpatch, der nun automatisch die optimale Größe für slum_min_objects als Funktion der Anzahl der CPUs einstellt.
Energie-Effizienz
Ein weiteres mögliches Ziel des Performance-Tunings stellt die Verminderung des Energieverbrauchs dar. Prozessoren jüngeren Datums bieten dafür “Processor Performance States” (P-States) und “Sleep States” (C-States) an. Arbeitet die CPU nicht unter Volllast, dann bringt der Wechsel in einen P-State Vorteile, in dem der Prozessor mir niedrigerer Taktfrequenz und Spannung läuft. Im Leerlauf kann die CPU dann sogar in einen C-State wechseln.
Um das auszunutzen, müssen Sie im BIOS die Option des Rechners Speed Step (oder ähnlich) aktivieren. Für das Regeln der P-States kommt dann noch ein Betriebssystemprozess zum Einsatz, der “CPU Frequency Governor”. Welche Governors Linux anbietet, verrät der Aufruf aus Zeile 1 von Listing 9, den momentan aktiven Governor verrät das Kommando aus Zeile 3.
Der Ondemand-Governor führt zur größtmöglichen Energie-Einsparung, wogegen der Performance-Governor die CPU mit der höchsten Taktfrequenz und Spannung versorgt. Sie schalten den Governor bei Bedarf mit dem Befehl aus Zeile 7 von Listing 10 um, wozu Sie administrative Rechte benötigen.
$ cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors ondemand powersave conservative userspace performance $ cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor performance $ sudo su Passwort: # echo ondemand > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
Für die C-States muss zusätzlich das Tickless-Idle-Feature im Kernel aktiviert sein. Traditionellerweise arbeiten die Linux-Kernel mit einem periodischen Timer-Tick, der die CPU davon abhält, in einen Schlafzustand zu wechseln. Das Tickless-Idle-Feature entfernt diesen Timer-Tick und erlaubt der CPU, im Stromsparmodus für längere Zeit zu schlafen. Wer seinen eigenen Kernel kompiliert, der sollte dabei die Option CONFIG_NO_HZ=y setzen.
Um den gegenwärtigen Status zu überprüfen, eignet sich sehr gut das Utility Powertop ([4], Abbildung 3). Es zeigt die gegenwärtig verwendeten P- und C-States und gibt sogar Empfehlungen, wie durch einfache Konfigurationsänderungen mehr Strom zu sparen wäre. Noch mehr Tipps gibt es auf der Powertop-Website [5].
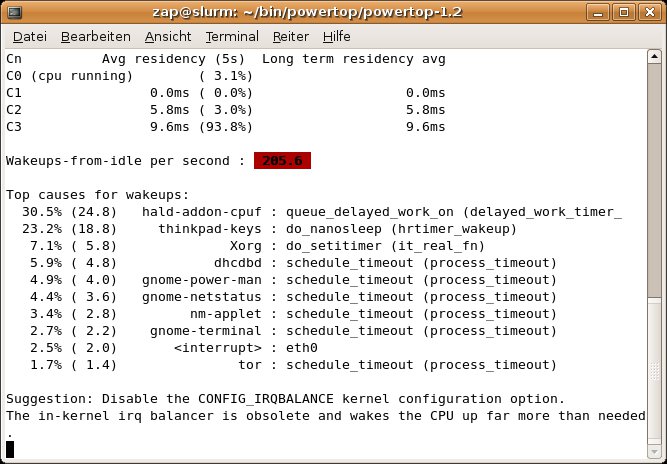
Abbildung 3: Powertop zeigt, dass auf diesem nicht optimierten System die Software den Kernel etwa 205 Mal pro Sekunde aufweckt, was unnötig Energie kostet.
Fazit
Dieser Beitrag bot einen Überblick über nützliche Tools zur Diagnose von Performance-Problemen und deren Behebung. Die Zusammenstellung erhebt keinerlei Anspruch auf Vollständigkeit; sie ermöglicht Ihnen aber einen Einstieg ins Geschäft der Kernel-Optimierung und zeigt, wo und wie Sie nach Engstellen suchen können. Eine ausführliche Liste von weiteren Testwerkzeugen und beispielhafte Ergebnisse von deren Einsatz finden Sie auf der Website des Linux Kernel Performance Project [6].
[1] Oprofile: http://oprofile.sourceforge.net
[2] Latencytop: http://www.latencytop.org
[3] Hackbench: http://devresources.linux-foundation.org/craiger/hackbench/
[4] Powertop-Workshop: Kristian Kißling, “Staying alive”, LinuxUser 08/2007, S. 76, https://www.linux-community.de/artikel/13391/
[5] Powertop: http://www.lesswatts.org/projects/powertop
[6] Linux Kernel Performance Project: http://kernel-perf.sourceforge.net




