

Gute OCR-Programme sind unter Linux Mangelware. Mit Tesseract erhalten Sie eine universelle, mehrsprachige Software zum automatisierten Erkennen von Texten.
Scanner werden mittlerweile auch unter Linux in den meisten Fällen unterstützt. Selbst exotische Modelle stellen Sane [1], das Linux-Standard-Framework zum Ansteuern von Scannern, nicht mehr vor eine Herausforderung. Mithilfe grafischer Frontends wie XSane scannen Sie problemlos Dokumente jeglicher Art vom Linux-Desktop aus ein. Proprietäre Software wie VueScan [2] enthält Treibermodule für zusätzliche Scanner-Modelle, sodass es inzwischen schwer wird, einen Scanner zu finden, den man unter Linux nicht verwenden kann.
Anwender, die Textdokumente einscannen und weiterverarbeiten möchten, stehen dennoch vor einem Problem: Da herkömmliche Scanner Dokumente in Form eines Rasters einlesen und die so gewonnenen Daten anschließend in eine Grafikdatei konvertieren, lassen sich Texte aus diesen Dateien nicht zur weiteren digitalen Bearbeitung extrahieren. Es bedarf eines OCR-Programms, das Texte in den Grafikdateien erkennt und extrahiert, sodass man sie in andere Anwendungen wie eine Textverarbeitung laden kann.
Herausforderungen
Die Aufgabe der Texterkennung ist dabei alles andere als trivial. OCR-Programme müssen zunächst grafische Elemente auf den Vorlagen detektieren und vom eigentlichen Text trennen. Danach gilt es, in den Textbereichen Fehler zu finden und zu beheben. Dazu zählen handschriftliche Vermerke in gedrucktem Text ebenso wie schief eingescannte Vorlagen oder ungebräuchliche Schriftarten, die die Software nicht korrekt erfasst. Daher verwenden gute OCR-Programme Algorithmen, die die an die einzelnen Zeichen angrenzenden Pixel überprüfen und bei Bedarf korrigieren. Zudem bieten sie die Möglichkeit, spezielle Schriftarten wie Fraktur, Schwabacher oder Rotunda in eigenen Mustersammlungen zu hinterlegen, sodass sie besser erkannt werden.
Nach der internen Korrektur der Vorlage gleicht die Software die gefundenen Zeichen mit einer Musterdatenbank ab, die verschiedene Schriftarten mit unterschiedlichen Schriftschnitten enthält. Je umfangreicher diese Datenbank, desto besser fällt die Erfolgsquote aus. Vor allem bei Dokumenten, die verschiedene Schriftarten und -schnitte enthalten, arbeitet die OCR-Software mit einer umfangreichen Musterdatenbank deutlich effektiver und treffsicherer.
Im nächsten Schritt prüft das OCR-Programm mögliche Verwechslungen und behebt anhand von Wörterbüchern und mit linguistischen Prüfverfahren Fehler. Das betrifft insbesondere sehr ähnliche Zeichen und Ziffern wie “S” und “5”, die bei falscher Erkennung sinnentstellend wirken. In diesem Bearbeitungsstadium können Anwender meist auch manuelle Korrekturen vornehmen.
Haben Sie mehrsprachige Dokumente eingescannt, steht das OCR-Programm vor einer weiteren Herausforderung: Viele Sprachen verwenden Sonderzeichen, die im Deutschen unüblich sind. Die Software muss also sowohl die verwendeten Sprachen als auch die jeweiligen Sonderzeichen korrekt identifizieren. Dementsprechend sind moderne Texterkennungsprogramme mehrsprachenfähig und erlauben die Ergänzung der internen Musterdatenbank durch solche spezielle Zeichen.
Der Alleskönner
Unter Linux hat sich das Texterkennungsprogramm Tesseract [3] als Quasi-Standard etabliert. Die Software blickt auf eine lange Entwicklungsgeschichte zurück: Sie wurde ursprünglich ab den 1980er-Jahren vom US-Hersteller Hewlett-Packard als proprietäre Software entwickelt, jedoch 2005 unter die freie Apache-Lizenz gestellt. Seit 2006 unterstützt Google das Tesseract-Projekt finanziell.
Dadurch wurde es nicht nur möglich, die seit etwa 1995 vernachlässigte und kaum noch weiterentwickelte OCR-Engine signifikant zu verbessern, sondern es konnten auch zahlreiche fremdsprachige Module in das Programm integriert werden. Heute unterstützt die Anwendung weit mehr als 100 Sprachen sowie verschiedenste Schriftarten und -schnitte und setzt damit Maßstäbe.
Zusätzlich ist die Software bereits seit mehreren Versionen in der Lage, separierte Textblöcke zu erkennen und sie korrekt zusammenzufügen. Das ermöglicht es beispielsweise, in mehrspaltigen Vorlagen die einzelnen Spalten miteinander zu verbinden. Dadurch eignet sich Tesseract hervorragend zur Verarbeitung von Texten in alten Büchern.
Trotz seiner Leistungsfähigkeit stellt Tesseract nur recht geringe Anforderungen an die Hardware: Es genügen ein Zweikernprozessor und 2 GByte Arbeitsspeicher als Mindestvoraussetzung. Mehr RAM und zusätzliche CPU-Cores beschleunigen freilich die Texterkennung.
Installation
Tesseract lässt sich plattformübergreifend nutzen. Unter Linux finden sich die nötigen Pakete in den Paketquellen so gut wie aller gängiger Distributionen, sodass Sie die Anwendung bequem über die jeweilige Paketverwaltung installieren. Das primäre Programmpaket heißt in der Regel tesseract oder tesseract-ocr, die Sprachpakete sind meist einzeln unter der Bezeichnung tesseract-langpack-<Sprache> eingepflegt. In vielen Repositories gibt es ein zusätzliches Paket, das alle unterstützten Sprachen beherbergt.
Da es sich bei Tesseract um ein reines Kommandozeilenprogramm handelt, ist die Verwendung mit einigem Lernaufwand verbunden. Sie starten die Anwendung im einfachsten Fall mit dem Befehl tesseract Input-File Output-File -l Sprache Ausgabeformate. Das OCR-Programm verarbeitet gegebenenfalls Dateien auf entfernten Systemen. Die Angabe der zu nutzenden Sprachdatei sorgt dafür, dass Tesseract Sonderzeichen problemlos erkennt. Bei Bedarf hängen Sie noch eine individuelle Konfigurationsdatei ans Ende des Befehls an oder definieren Segmente zum Einlesen.
Vereinfachung
Grafische Frontends vereinfachen die Arbeit mit Tesseract enorm, insbesondere wenn es darum geht, bei der Erkennung umfangreicher Dokumente befriedigende Ergebnisse zu erzielen. Eine GUI ermöglicht das Verwenden von Optionen per Mausklick und verringert dadurch das durch die zahlreichen Parameter verursachte Risiko von Fehleingaben am Prompt. Daher wurden im Lauf der Zeit gleich mehrere Frontends eigens für Tesseract entwickelt.
Eines der mittlerweile am häufigsten genutzten Tesseract-Frontends ist GImageReader [4], das sich in den Paketquellen aller gängigen Linux-Distributionen findet. Der Installer legt in der Menühierarchie der verwendeten Arbeitsumgebung einen passenden Starter an. GImageReader bemerkt eine bestehende Tesseract-Installation; Sie müssen beim Aufruf der Software also das OCR-Programm nicht noch einmal gesondert aktivieren.
Nach dem ersten Start der Anwendung öffnet sich ein unspektakuläres Fenster, in dem ein großes, leeres Segment in der Mitte ins Auge sticht. Darin zeigt das Programm später die geladene Bilddatei im Originalzustand an. Rechts daneben finden Sie einen nahezu gleich großen Bereich, in dem die erkannten Texte erscheinen. Am oberen Fensterrand befindet sich eine Optionsleiste, während zwei kleinere, links untereinander angeordnete Fenstersegmente die Dateiverwaltung erleichtern.
Der Reiter Dateien dient dem Bearbeiten bereits erfasster Bilddateien, im Reiter Erfassen laden Sie Dokumente direkt vom Scanner in das Programm. Sie benötigen also kein externes Programm zum Einscannen von Vorlagen (Abbildung 1). Im ersten Schritt passen Sie die verwendete Sprachdatei an. Voreingestellt ist die US-Variante aktiv. Durch einen Klick auf die blaue Flagge in der Optionsleiste öffnen Sie das Menü für installierte Sprachen und wählen dort eine der deutschen Optionen. Das entsprechende Anzeigefeld links daneben stellt GImageReader dann sofort um.
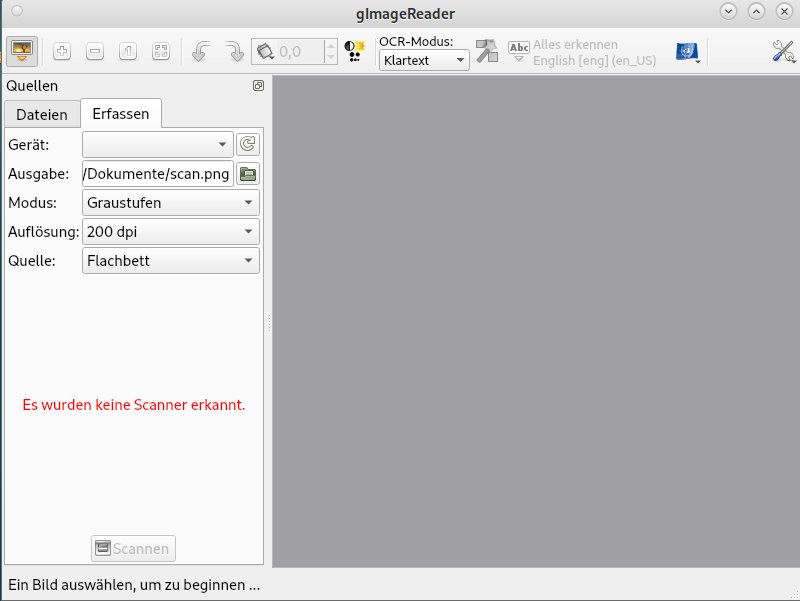
Abbildung 1: Die Oberfläche von GImageReader fällt weitgehend selbsterklärend aus.
Im nächsten Schritt laden Sie entweder eine bereits vorhandene Datei in das Programm oder stoßen über den Erfassen-Dialog das Einscannen einer Vorlage an. Enthält die Vorlage oder die zu ladende Datei jedoch eine Frakturschrift, müssen Sie vorab entweder auf das Zahnrad- oder das Werkzeug-Symbol rechts im Programmfenster klicken. Dann wählen Sie im Dialog Voreinstellungen | Vordefinierte Sprachdefinitionen die Frakturvariante aus (Abbildung 2).
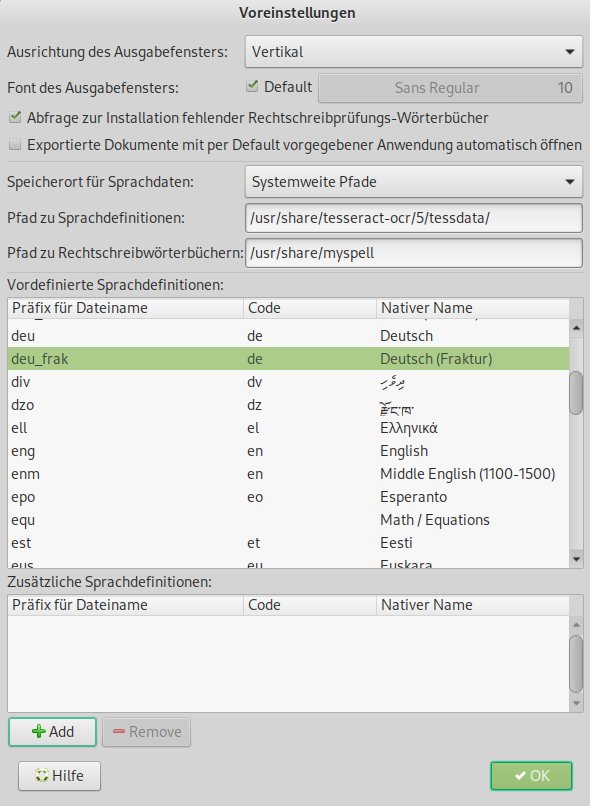
Abbildung 2: Mit der Fraktur-Option machen Sie Tesseract für Texte mit alten Schriften fit.
Um eine bereits vorhandene Datei einzulesen, klicken Sie links im Reiter Dateien auf das Ordnersymbol und wählen anschließend im sich öffnenden Dateimanager die gewünschte Datei aus. Die erste Seite erscheint nun im großen Fenstersegment in der Mitte. Bei mehrseitigen Dokumenten blendet GImageReader unten links im Programmfenster in der Ansicht Thumbnails kleine Vorschauen der einzelnen Seiten ein. Diese Anzeige ermöglicht ein schnelles Navigieren selbst in Dokumenten mit vielen Seiten.
Nun bereiten Sie die eingelesene Datei für die Texterkennung vor. Dazu markieren Sie in der Seitenansicht alle Textblöcke, die Tesseract einbeziehen soll. Der Mauszeiger verändert sich beim Überfahren der Vorlage zu einem Kreuz. Durch Ziehen des Mauszeigers bei gedrückter linker Taste wird der Text markiert und ein Rahmen aufgezogen. Möchten Sie mehrere Rahmen auf einer Seite erzeugen, um etwa mehrspaltige Texte in einem Durchlauf erkennen zu lassen, halten Sie während des Markiervorgangs [Strg] gedrückt. GImageReader nummeriert die einzelnen Rahmen dabei fortlaufend durch und hinterlegt sie blau. Durch einen Rechtsklick auf einen Rahmen und Auswahl der Option Löschen aus dem Kontextmenü können Sie versehentlich markierte Rahmen wieder deaktivieren und so von der Erkennung ausschließen (Abbildung 3).
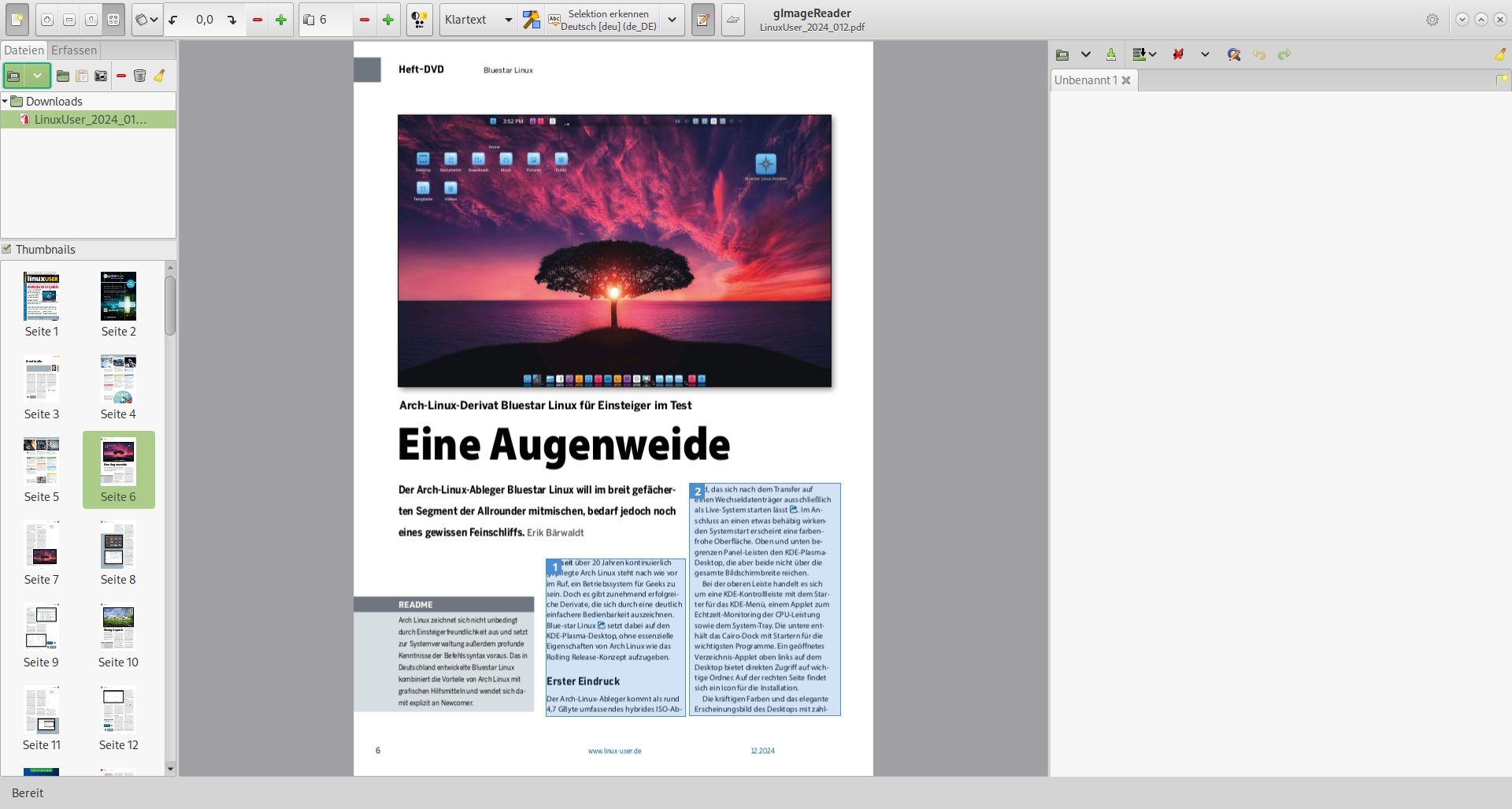
Abbildung 3: Nach dem Markieren einzelner Textabschnitte auf der Seite extrahieren Sie den entsprechenden Text.
Stattdessen können Sie auch auf einer Seite einen Rahmen um alle Elemente ziehen. Dann wählen Sie nach einem Rechtsklick aus dem Kontextmenü die Option Erkennen aus, um den aktuellen Textrahmen einzulesen. Bei mehreren nicht zusammenhängenden Textrahmen klicken Sie oben mittig in der Optionsleiste auf Selektion erkennen und wählen im sich daraufhin öffnenden Menü, ob Tesseract nur die aktuelle oder alle Seiten berücksichtigen soll.
Die Software führt nun eine automatische Erkennung des Layouts aus und klammert intern alle grafischen Elemente aus. Anschließend wird der vorhandene Text erkannt und im rechten, bis dahin noch leeren Fenstersegment angezeigt. Hier stehen Editor-Funktionen zur Verfügung, sodass Sie Korrekturen an den Texten vornehmen können (Abbildung 4). Das umfasst auch einfache Formatiermöglichkeiten sowie automatisiertes Suchen und Ersetzen – praktisch, um sich wiederholende Erkennungsfehler zu beseitigen.
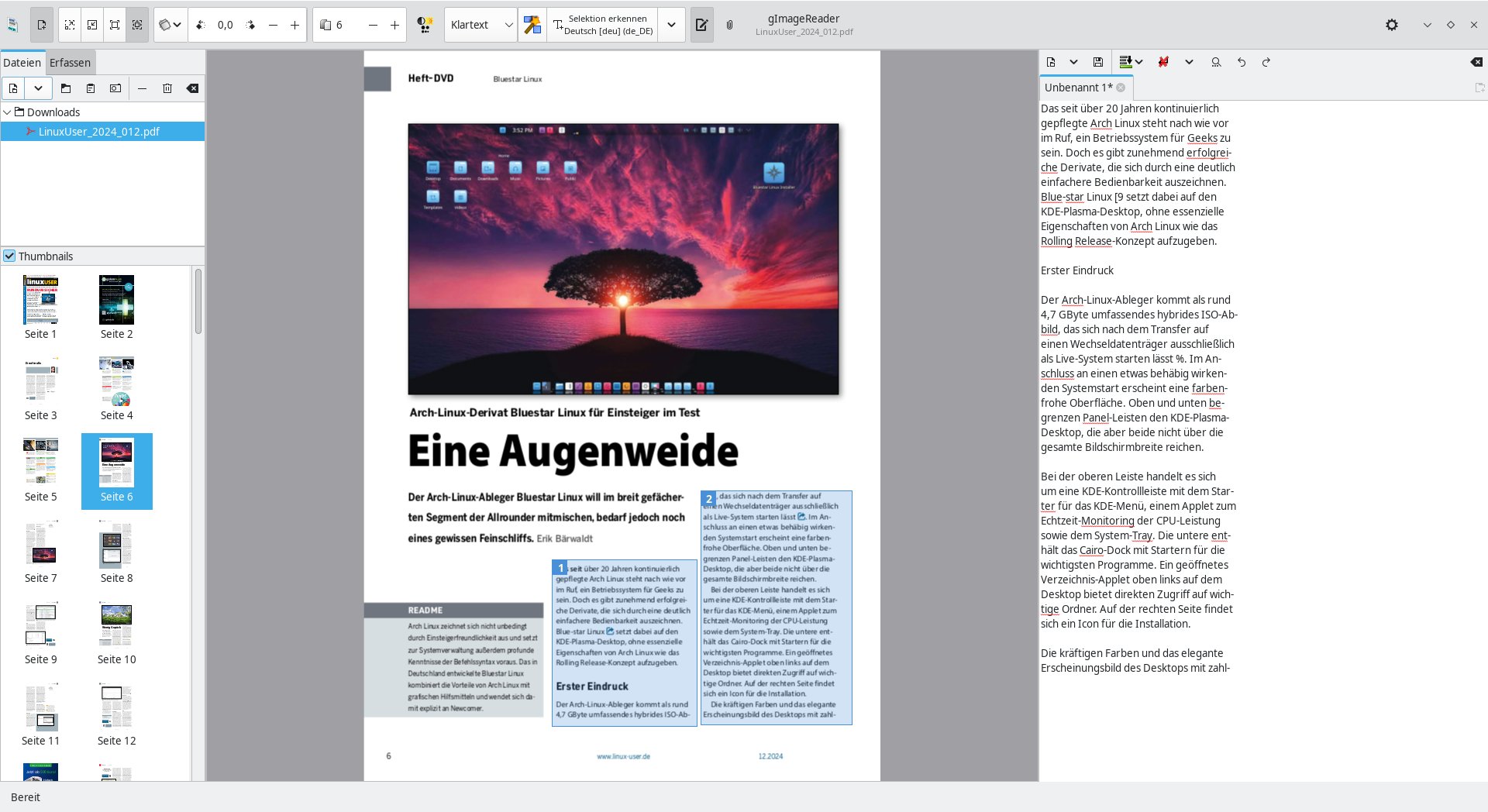
Abbildung 4: Die Software gestattet auch die sofortige Korrektur der erkannten Texte im Editor-Bereich.
Nach dem Editieren sichern Sie den Text durch einen Klick auf die Schaltfläche Ausgabe speichern links oberhalb des Editors. Es erscheint ein Dateimanager, der die freie Auswahl von Pfad und Dateiname gestattet. Optional sichern Sie den Text als ODT- oder PDF-Datei, was eine nahtlose Weiterverarbeitung in LibreOffice, OnlyOffice oder OpenOffice ermöglicht (Abbildung 5).
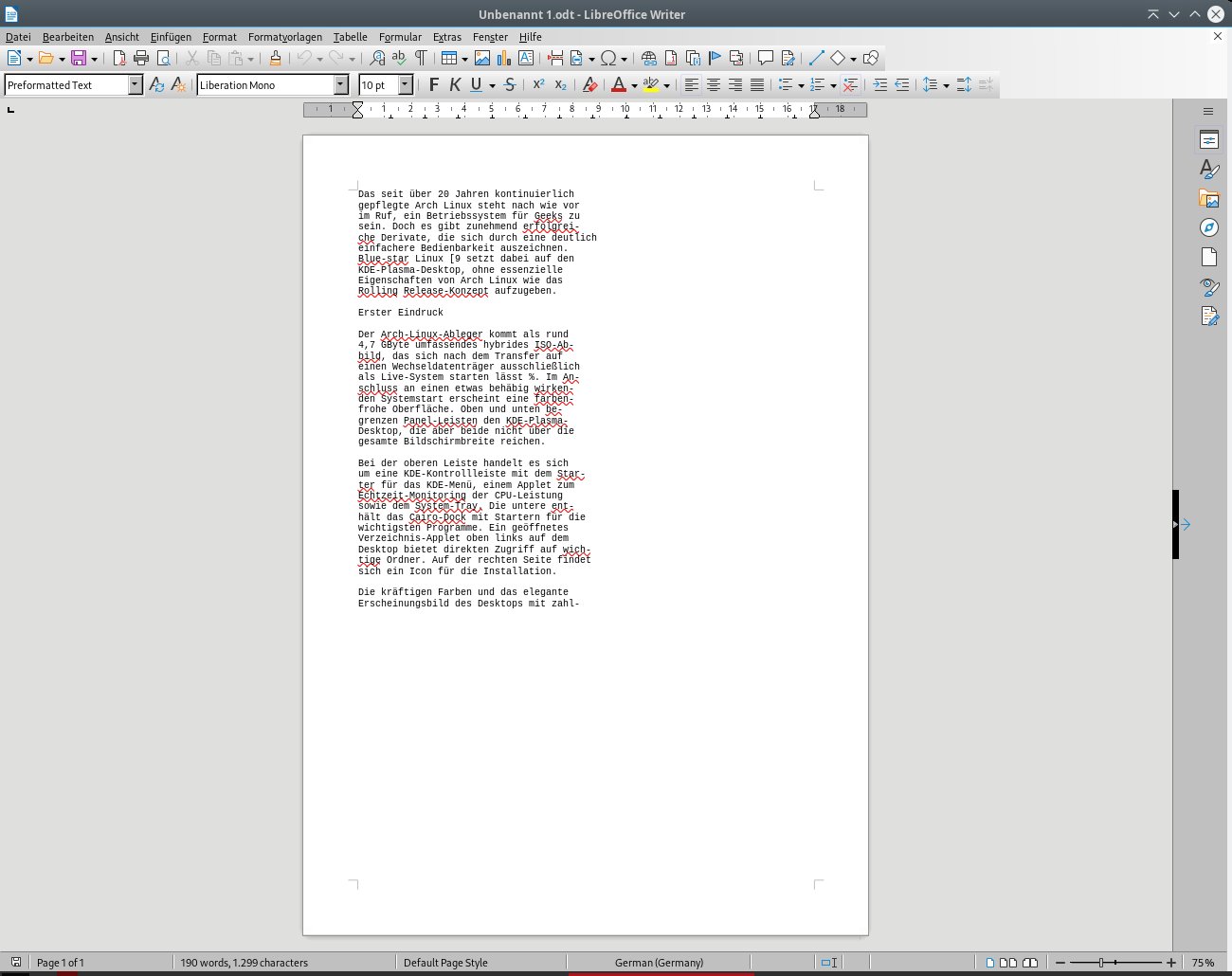
Abbildung 5: Ein via GImageReader im ODT-Format gespeicherter Text lässt sich problemlos in einer Bürosuite weiterverarbeiten.
Vollautomatik
Sie müssen die Bilddatei nicht unbedingt manuell mit Rahmen zur Texterkennung versehen, sondern können stattdessen durch einen Klick auf Layout AutoDetect oben in der Optionsleiste eine automatische Layoutprüfung und Markierung aktivieren. Nach kurzer Zeit erscheinen die gefundenen Elemente als Rahmen auf der Bilddatei (Abbildung 6).
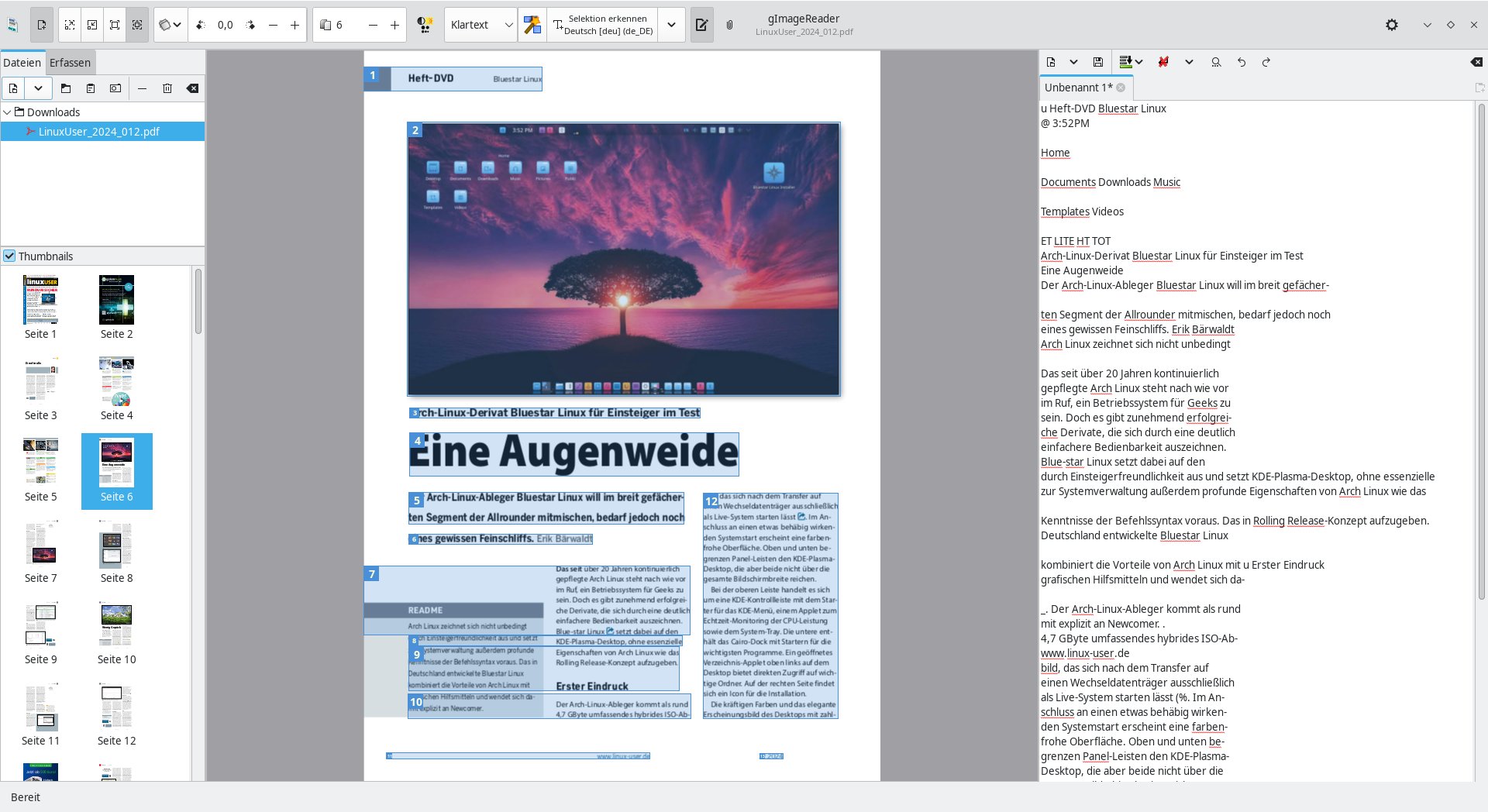
Abbildung 6: Die automatische Erkennung von Textelementen funktioniert bei komplexen Bilddateien nicht in jedem Fall zufriedenstellend.
Dabei werden jedoch grafische Elemente mitmarkiert. Die Funktion weist insbesondere bei Vorlagen mit mehreren Spalten und integrierten Abbildungen oder Grafiken noch einige Defizite auf. Da diese auch bei der anschließenden Erkennung auftreten, empfiehlt es sich, in solchen komplexen Dateien die einzelnen Textelemente manuell zu markieren.
Fazit
Das Zusammenspiel von Tesseract und GImageReader ermöglicht eine schnelle und zuverlässige Texterkennung selbst bei schwierigeren Vorlagen. Das Duo erkennt Texte nach entsprechender Markierung faktisch fehlerfrei, es fällt kaum noch eine Nachbearbeitung an. Für ambitionierte Privatanwender, Freiberufler und kleine Unternehmen ist die Kombination aus Tesseract als Backend und GImageReader als Frontend beim Erkennen von Texten daher erste Wahl. Dank der Unterstützung für das ODT-Format gelingt zudem ein problemloser Import in die üblichen Bürosuiten. Schwierige Vorlagen wie dunkle, schief eingescannte oder fleckige Bilddateien bedürfen allerdings oft noch einer Vorbereitung, um die Erkennungsqualität zu erhöhen. (jlu)
Infos
-
Projektseite von Sane: http://www.sane-project.org
-
VueScan: https://www.hamrick.com
-
Tesseract: https://github.com/tesseract-ocr/tesseract
-
GImageReader: https://github.com/manisandro/gImageReader




