

Speech-to-Text und Text-to-Speech in Verbindung mit lokaler KI brauchen sich bei der Qualität keineswegs hinter kommerziellen Angeboten zu verstecken. Obendrein liegen sie beim Schutz der Privatsphäre weit vorn.
Die Geschichte von Sprachsynthese-Techniken Speech-to-Text (STT) und Text-to-Speech (TTS) reicht lange zurück. Bereits im 18 Jahrhundert versuchte man, Maschinen zu entwickeln, die menschliche Sprache erzeugen können. In den 1930er-Jahren forschte der Physiker Homer Dudley in den Bell Laboratories zur Analyse und Synthese menschlicher Sprachen. Das erste als Sprachsynthesizer bezeichnete Geräte stammt von ihm und trug den Namen Voder [1] (Voice Operation Demonstrator).
Erstmals der Öffentlichkeit präsentierte man den Voder auf der Weltausstellung in New York im Jahr 1939. Daneben konstruierte Dudley den Vocoder [2] (Voice Operation Recorder), der dazu diente, natürliche Sprache kodiert als Analogsignal zu übertragen und zu reproduzieren beziehungsweise zu synthetisieren. Mit dem Aufkommen von Computern in den Jahren ab 1960 erlebte die Sprachsynthese einen enormen Aufschwung. Allerdings klangen die erzeugten Stimmen bis vor einigen Jahren unnatürlich und erinnerten eher an Roboter als an menschliche Stimmen.
Beide Technologien finden seit den 1990er-Jahren zunehmend praktische Verwendung. Eine wahre Revolution in diesem Bereich setzte mit der Entwicklung von KI, neuronalen Netzen und Deep Learning ein. Innerhalb der letzten Jahre stieg die Sprachqualität derart, dass es inzwischen schwerfällt, eine künstlich erzeugte Stimme als solche zu identifizieren.
Vielseitig
Ursprünglich unterstützen TTS-Systeme Menschen mit Seh- und Sprachbehinderungen bei der Kommunikation mit ihrer Umwelt, was die Barrierefreiheit bei der Computernutzung wesentlich verbesserte. Mittlerweile sind STT und TTS Kernbestandteile von Sprachassistenten wie Siri, Google Assistant und Alexa. Bei der Heimautomation steuern Nutzer mithilfe von STT Geräte und Dienste. Im Unternehmenskontext lassen sich damit Meetings, Brainstorming-Sitzungen oder Präsentationen transkribieren.
Auch wir Journalisten und Autoren nehmen STT zu Hilfe, um beispielsweise Interviews oder Pressekonferenzen für unsere Artikel zu verschriftlichen. Die Automobilindustrie integriert die Technik, damit Navigationssysteme oder Unterhaltungsgeräte sich sprachbasiert bedienen lassen, und erhöht so die Sicherheit im Fahrzeug. Eine bisweilen eher nervige Ausprägung sind die mittlerweile überall präsenten digitalen Assistenten, die uns beim Telefonieren mit Behörden und Unternehmen unterstützen sollen.
Im Folgenden gehen wir der Frage nach, wie Sie STT und TTS mit freier Software verwenden können. Dabei suchen wir bevorzugt Lösungen, die ohne Cloud-Anbindung auskommen. Wenn Sie mit TTS in wenigen Minuten zum Ziel kommen möchten, sollten Sie sich die Python-Software eSpeak NG [3] ansehen. Viele Distributionen führen sie in ihren Paketmanagern, aus denen heraus sich die Anwendung installieren und sofort starten lässt. Der Open-Source-Sprachsynthesizer (Abbildung 1) unterstützt mehr als hundert Sprachen und Akzente.
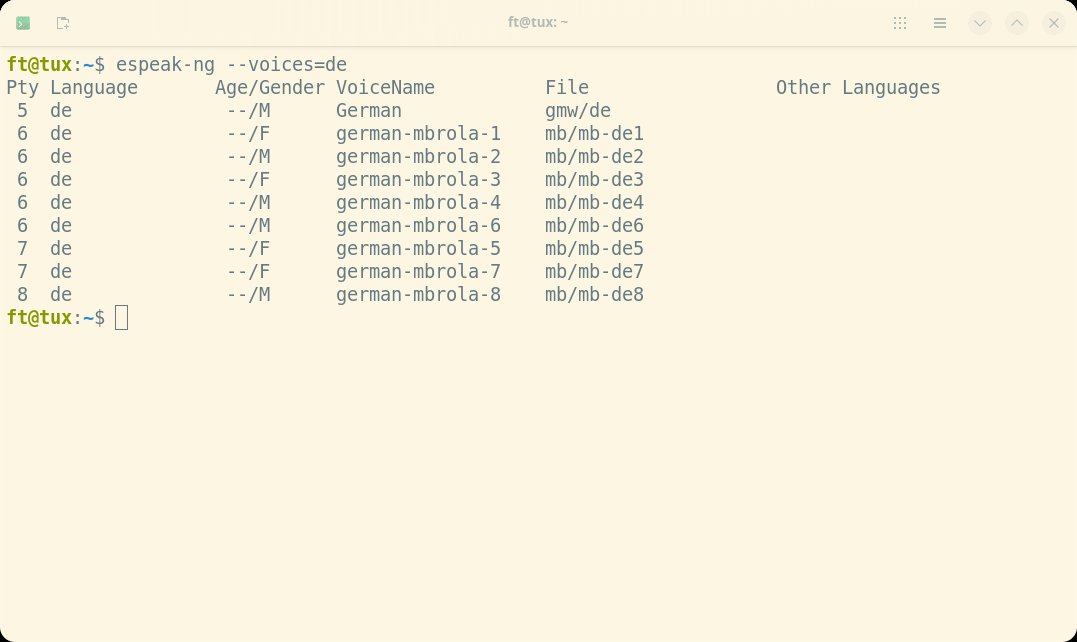
Abbildung 1: Hinter eSpeak NG steckt ein kompakter Text-to-Speech-Synthesizer, der Text in über 100 Sprachen und Dialekten ausgibt. Die Ausgabe klingt jedoch nicht so natürlich wie bei größeren Synthesizern.
Sie nutzen die Software entweder über die Kommandozeile oder binden sie als Bibliothek in andere Anwendungen wie den Screenreader Orca [4] ein. Texte lassen sich direkt eingegeben oder aus Dateien lesen. Die Sprachausgabe passen Sie an unterschiedliche Bedürfnisse an. Das Programm bedient sich der Technik der Formantsynthese [5], die sich mit wenig Speicherplatz begnügt. Dadurch eignet sich eSpeak NG gut für eingebettete Systeme. Zudem steht die Anwendung plattformübergreifend zur Verfügung und läuft unter Linux, Windows, macOS und Android.
Thorsten-Voice
Wenn Sie lediglich Unterstützung für die deutsche Sprache benötigen, lässt sich die Sprachausgabe von eSpeak NG durch Integrieren des Open-Source-Projekts Thorsten-Voice [6] auf ein natürliches Sprachniveau (Abbildung 2) anheben. Das Projekt funktioniert mit lokalen LLMs auch ohne Internetanbindung, alle Daten verbleiben bei Ihnen. Die TTS-Stimmen wurden mit den Programmen Coqui TTS und Piper TTS erstellt, die frei zugänglichen LLMs wurden mit über 30 000 Aufnahmen trainiert.
Thorsten-Voice lässt sich unter Linux, macOS und Windows einsetzen. Wie Sie die Software auf auf einem Raspberry Pi verwenden, hat bereits ein Artikel [7] im LinuxUser 02/2025 beschrieben. Wenn Sie sich vorab einen Eindruck von der Qualität der Stimmausgabe machen möchten, finden Sie Beispiele auf der Webseite unter dem Reiter Anleitungen. Das Projekt bietet zwei Modelle: VITS und DDC, die unterschiedliche Backends benutzen.
Thorsten-Voice verlangt Python in Version 3.7 oder höher. Der Befehl python3 -V verrät, welche Version bei Ihnen vorliegt. Eine Anleitung zur Installation unter Linux liegt als Youtube-Video [8] vom Entwickler vor. Zusätzlich erklärt er, wie Sie die Anwendung per Kommandozeile oder Web-Interface bedienen. Diese Methode funktioniert jedoch nur bis einschließlich Python 3.11, da Coqui TTS nicht mehr weiterentwickelt wird. Mit aktuelleren Versionen weichen Sie auf die KI-Sprachsoftware Piper TTS [9] aus. Sie erlaubt die Sprachausgabe (Abbildung 3) allerdings ausschließlich über die Kommandozeile.

Abbildung 2: Ein kurzer Satz ist mit Piper TTS in weniger als zwei Sekunden synthetisiert. Thorsten-Voice verleiht der Sprachqualität beeindruckende Natürlichkeit.
Abbildung 3: Die Qualität der erzeugten Stimme ist bei Verwendung von Thorsten-Voice beim Abspielen kaum von einer natürlichen Stimme zu unterscheiden.
Piper TTS beherrscht außer der Ausgabe des gewünschten Texts in eine Datei auch die Ausgabe direkt über aplay. Für längere Texte wie Interviews können Sie auf unterschiedliche Stimmen zurückgreifen. Neben Thorsten-Voice bietet Piper TTS Unterstützung für zahlreiche weitere Sprachen und Stimmen. Die Software kommt vielen Projekten zum Einsatz, beispielsweise bei Home Assistant und LocalAI.
Als Modell taucht Thorsten-Voice zudem in der kleinen App Speech Note [10] auf – nicht zu verwechseln mit der proprietären Anwendung Speechnotes [11]. Speech Note (Abbildung 4) steht auf Flathub für Linux und für Sailfish OS zur Verfügung. Damit erstellen Sie Notizen in mehreren Sprachen mit der Option, die Texte gleich zu übersetzen. Die App unterstützt sowohl STT als auch TTS (Abbildung 5) und verarbeitet Texte und Sprache vollständig lokal und offline. Nachdem Sie die Anwendung eingebunden haben, wählen Sie die gewünschten Sprachen und installieren sie.
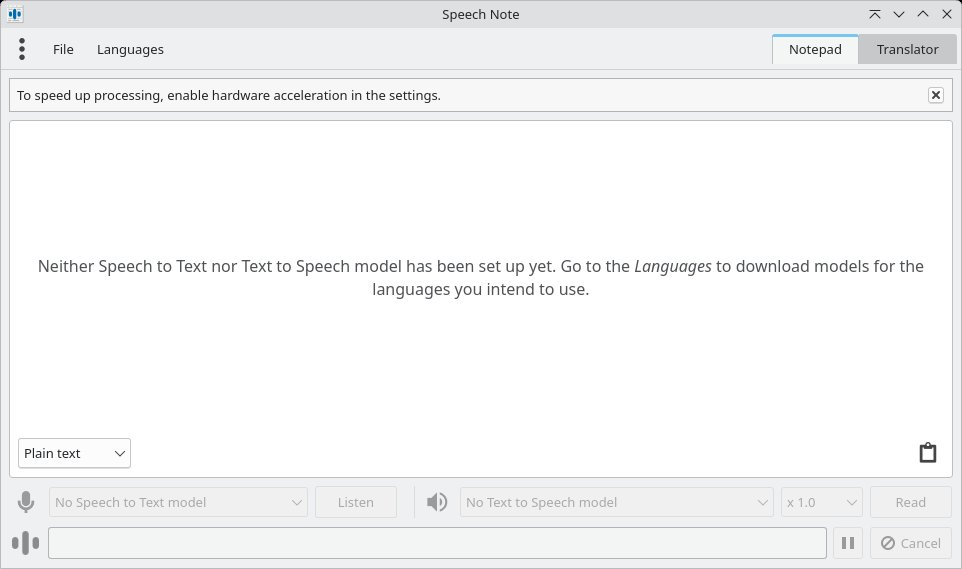
Abbildung 4: Die kleine Notiz-App Speech Note kommt als Flatpak ohne integrierte Sprachmodelle. Nach dem ersten Start müssen Sie diese zunächst installieren.
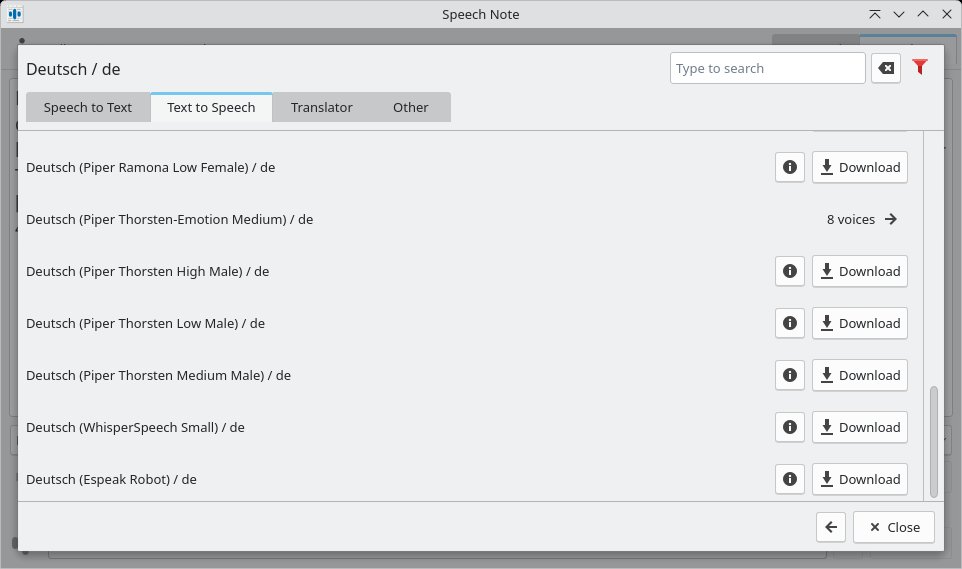
Abbildung 5: Unter dem Reiter Text to Speech finden Sie auch die Stimme von Torsten-Voice in verschiedenen Ausführungen wieder.
Festival
Darüber hinaus widmen sich viele weitere Anwendungen dem Thema TTS. Ein mächtiges Werkzeug ist Festival [12], das unter einer MIT-ähnlichen Lizenz angeboten wird. Sie können es frei verwenden und in proprietäre Anwendungen integrieren. Die in zahlreichen Distributionen verfügbare Software installieren Sie über die drei Pakete festival, festival-doc und festival-freebsoft-utils .
Anschließend ist zunächst Englisch als Sprache mit einem Sprecher vorinstalliert. Zusätzliche Sprachen wie Italienisch, Spanisch, Tschechisch, Russisch und Finnisch finden Sie in Ihrem Paketmanager mit der Suche nach festvox-*. Wegen der komplexen Phonetik haben die Verantwortlichen bis dato keine deutsche Übersetzung vorgesehen. Allerdings existieren einige an der Universität Stuttgart entwickelte Mbrola-Pakete [13] wie mbrola-de1 oder mbrola-de2, die Sie hinzuholen können. Bitte beachten Sie: Dazu müssen Sie Festival aus dem Quellcode erstellen.
Neben einer Vielzahl an kostenpflichtigen, meist proprietären Lösungen gibt es das unter der LGPL lizenzierte Java-basierte Client-Server-System MaryTTS [14], das deutsche Stimmen bietet. Das noch junge KI-Projekt Zonos TTS [15] spricht ebenfalls Deutsch. Außerdem ermöglicht es, Sprechgeschwindigkeit, Tonhöhe sowie Audioqualität zu steuern und Emotionen wie Freude, Angst, Traurigkeit und Wut auszudrücken. Die Entwickler empfehlen für den Echtzeitbetrieb eine Grafikkarte mit mindestens 6 GByte VRAM.
Ein spannender Einsatzzweck von TTS liegt im Open-Source-Projekt ebook2audiobook [16]. Die KI-Anwendung (Abbildung 6) verwandelt E-Books in Hörbücher in vielen Sprachen. Die App kann E-Book-Formate wie EPUB, Mobi, PDF und Text in Hörbücher mit vollständigen Kapitelmarkierungen und Metadaten im Format m4b konvertieren und verwendet dazu intern Calibre.
Das Tool bietet eine intuitive Web-GUI, lässt sich aber genauso gut über die Kommandozeile bedienen. Es unterstützt den Betrieb per CPU- oder GPU und kommt bereits mit 4 GByte Hauptspeicher zurecht. Sie installieren die Software auf Ihrem Rechner oder in einen Docker-Container, bei Unraid greifen Sie auf ein vorbereitetes Skript zur automatisierten Installation zurück. Auf der Webseite Huggingface [17] nutzen Sie die App als Online-Dienst.
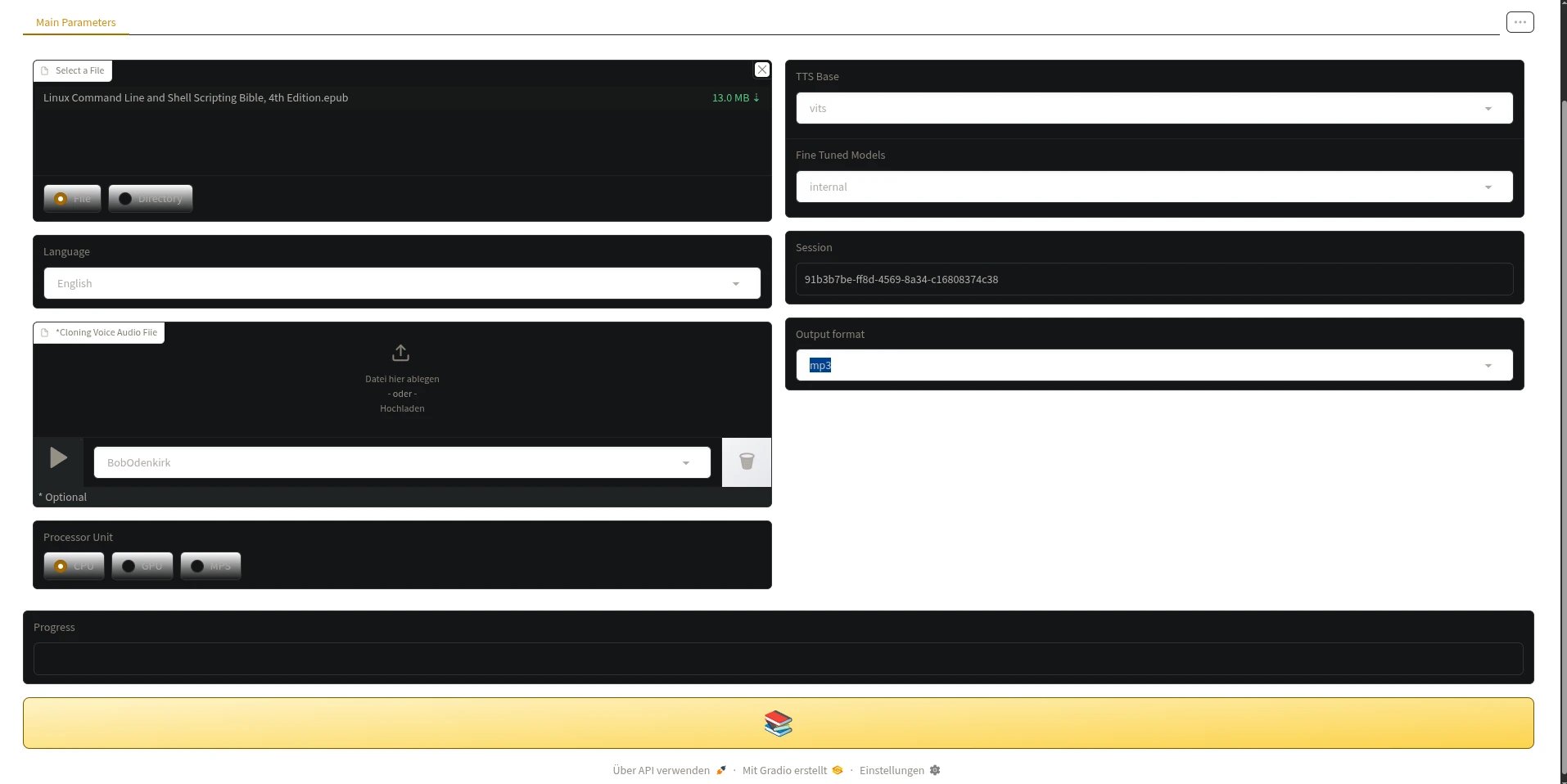
Abbildung 6: Aus einem E-Book mit rund 700 Seiten erzeugt die KI-Anwendung ebook2audiobook innerhalb einer Stunde ein Hörbuch. Ohne eine leistungsfähige Grafikkarte benötigt die Anwendung auf der CPU aber wesentlich länger.
Speech-to-Text
Auch bei der STT-Technologie hat Linux in den letzten Jahren große Fortschritte gemacht: Inzwischen existiert eine Reihe an Sprache-zu-Text-Werkzeuge sowie passende Bibliotheken. Viele der Anwendungen sind eher für die akademische Forschung gedacht. Teilweise müssen Sie sie erst selbst trainieren, bevor sie sich praktisch einsetzen lassen. Mozillas bekanntes Projekt DeepSpeech, das maschinelles Lernen unter Verwendung des TensorFlow-Frameworks umsetzte, fiel den Sparmaßnahmen bei der Umstrukturierung von Mozilla zum Opfer und wird nicht mehr weiter entwickelt.
Als schnell zu installierende Offline-Lösung sticht die in Python verfasste plattformübergreifende Open-Source-Software Vosk [18] heraus. Vosk verspricht STT für rund 20 Sprachen inklusive Deutsch und läuft unter Linux, macOS, Windows, Android und iOS. Neben X86 unterstützt Vosk ARM für Raspberry Pi 3 bis 5. Die Software bietet zudem Bindings für Java, Python, JavaScript, C# und NodeJS.
Für die Installation sollten Sie im ersten Schritt die Pakete pip3 und python3 einbinden oder aktualisieren. Das Kommando pip3 install vosk stellt danach das Paket bereit. Je nach Distribution findet pipx (Abbildung 7) anstatt pip Verwendung.
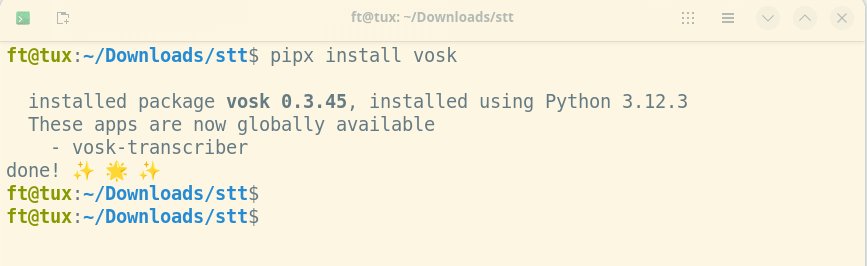
Abbildung 7: Vosk ist in Windeseile mit einem einzigen Befehl installiert und gibt sich bei der Hardware bereits mit einem Raspberry Pi ab Version 3 zufrieden.
STT-Systeme benötigen zusätzlich Sprachmodelle, um Audiodateien oder Sprache in Echtzeit über ein Mikrofon in geschriebenen Text umzuwandeln. Um mit Vosk Audiodateien in Text zu konvertieren, klonen Sie die Vosk-API [19] und laden anschließend ein Vosk-Modell [20] in der gewünschten Sprache herunter. Wie Sie Sprache über ein Mikrofon direkt in Text umwandeln, erläutert ein Artikel auf der Webseite gnulinux.ch [21]. Vosk eignet sich für den Einsatz auf vergleichsweise schwacher Hardware wie dem Raspberry Pi ab Version 3 oder auf älteren Rechnern mit mindestens 4 GByte RAM. Dafür stehen kleine Sprachmodelle mit nur rund 50 MByte bereit.
WhisperAI
Anders sieht das bei der von OpenAI entwickelten Open-Source-Spracherkennung WhisperAI [22] aus. Dabei handelt es sich um ein automatisches Spracherkennungssystem (ASR), das mit 680 000 Stunden mehrsprachiger Daten aus dem Internet trainiert wurde. Dabei zählt Deutsch zu den mehr als 100 unterstützten Sprachen, die WhisperAI automatisch erkennt. Die Software kann mit Audio- und Video-Dateien sowie mit Telefongesprächen umgehen und wandelt auch Sprache per Mikrofon in Text um.
WhisperAI, das derzeit die wohl beste Alternative zu proprietären Diensten wie Google Speech-to-Text ist, lässt sich lokal und offline betreiben. Dabei agiert WhisperAI jedoch nicht gerade ressourcenschonend und setzt für die Ausführung in Echtzeit leistungsfähige CPU-, GPU- und RAM-Unterstützung auf moderner Hardware voraus. Die lokale Installation des Tools erledigt der folgende Aufruf:
$ pip install git+https://github.com/openai/whisper.git
Je nach Distribution verwenden Sie erneut pipx statt pip. Zusätzlich braucht es ffmpeg.
WhisperAI gibt es in den Ausführungen tiny, base, small, medium und large. Die Ausgabequalität steigt mit der Größe des verwendeten Modells. Wir haben die verschiedenen Modelle auf einem durchschnittlichen Notebook mit 8 GByte RAM und ohne dedizierte Grafikkarte getestet. Dazu haben wir eine Audiodatei mit dem ersten Absatz dieses Artikels eingesprochen und mit den verschiedenen Modellen als Text ausgeben lassen. Erwartungsgemäß war das Modell in der Variante tiny (Abbildung 8) der Aufgabe nicht gewachsen.
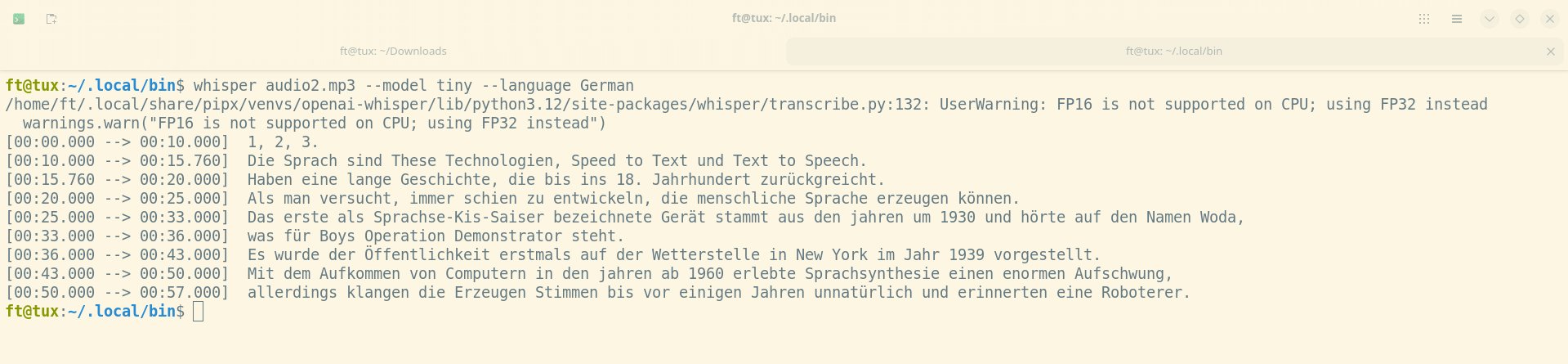
Abbildung 8: Das Modell tiny ist für produktives Arbeiten nicht zu gebrauchen, da es viele Worte falsch erkennt.
Doch bereits mit dem 139 MByte großen Modell base erzeugte Whisper einen gut lesbaren Text, der aber noch einige Fehler aufwies (Abbildung 9). Das nächste getestete Modell small umfasst 461 MByte und erzeugte einen Text mit nur einem Rechtschreibfehler und fast perfekter Interpunktion (Abbildung 10). Hier war kaum Nacharbeit nötig. Warum allerdings ein nicht existentes Wort wie “Roboterer” in den Text gelangt ist, erschließt sich uns nicht. Ein einfacher Abgleich mit einem Wörterbuch würde solche Fehler verhindern.
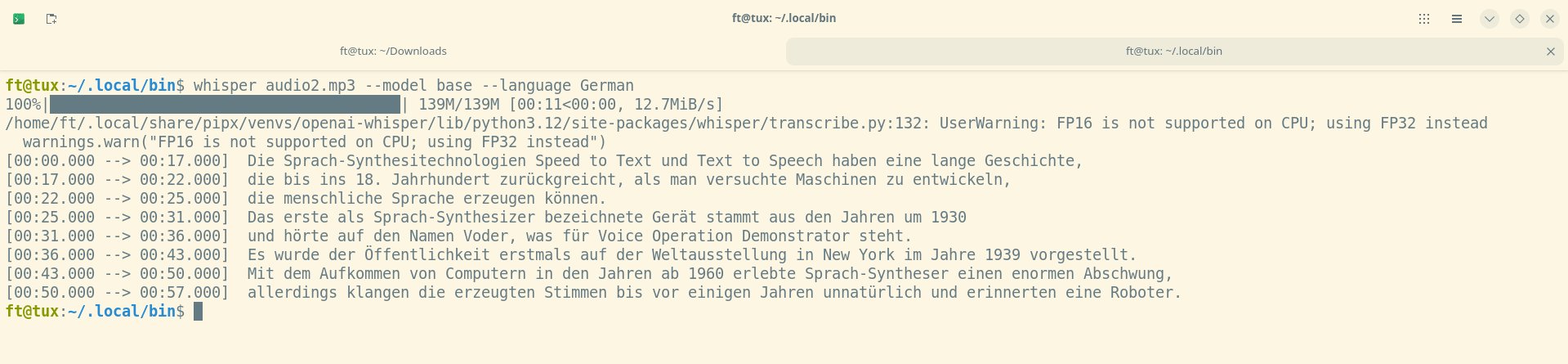
Abbildung 9: Bereits das nächstgrößere Modell liefert zumindest eine verständliche Transkribierung, die aber immer noch einige Fehler enthielt.
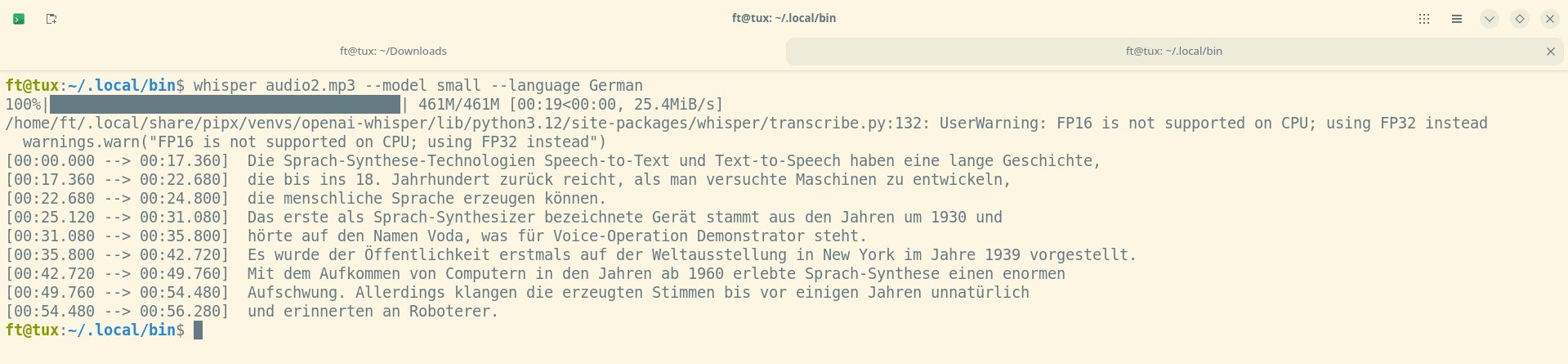
Abbildung 10: Das Modell small, das 461 MByte umfasst, liefert einen Text, der zwar nicht perfekt ist, aber bereits für produktives Arbeiten auf Alltags-Hardware geeignet erscheint.
Abschließend wagten wir noch einen Versuch mit dem größten Modell mit 2,8 GByte Umfang. Das rief jedoch bei unserem Test-Notebook den OOM Killer [23] des Kernels auf den Plan und beendete den Test. Die Probeläufe mit den ersten drei Modellen dauerten bis zum fertigen Text alle unter einer Minute. Ein Versuch auf einem Rechner mit einer AMD Ryzen 9 CPU, 64 GByte RAM und einer Grafikkarte mit 12 GByte VRAM verkürzte den Versuch mit dem Modell small von 56 auf auf 5,7 Sekunden. Für STT lohnt sich außerdem ein qualitativ hochwertiges Mikrofon wie das für diesen Test verwendete Rode NT1 anstelle des im Notebook oder der externen Webcam integrierten Mikros .
Fazit und Ausblick
Speech-to-Text (STT) und Text-to-Speech (TTS) sind gut vorangekommen, wenn man sich den Stand vor zehn Jahren vor Augen hält. Damals waren beide Synthesen für den praktischen Einsatz auf bezahlbarer Hardware kaum zu gebrauchen. Doch auch heute bleibt noch Luft nach oben, wenn es bei eingesprochenen Texten um Echtzeitverarbeitung geht. Im Gegensatz zu Sprachen wie Englisch oder Spanisch stellt Deutsch wegen seiner Phonetik die Sprachmodelle vor besondere Probleme, die in einer schlechteren Ausgabequalität resultieren können. Das gilt insbesondere bei STT, wenn nicht akzentfrei gesprochen wird.
Hinsichtlich des Tempos bei der Entwicklung von KI, ist damit zu rechnen, dass gute Ergebnisse in Echtzeit bald zum Alltag gehören – ohne das Tausende Euro in Hardware investiert werden müssen. Erfreulich ist, dass es unter Linux für beide Techniken Möglichkeiten gibt, Anwendungen lokal und ohne Cloud-Anbindung zu betreiben. (csi)
Infos
-
Geschichten aus der Geschichte (Podcast), GAG339: Der Vocoder: https://www.geschichte.fm/archiv/gag339/
-
eSpeak NG: https://github.com/espeak-ng/espeak-ng
-
Bibliothek: https://orca.gnome.org/https://orca.gnome.org/
-
Torsten-Voice: https://www.thorsten-voice.de/
-
Piper TTS: Martin Mohr, “Sprachgewandt”, LU 02/2025, S. 72, https://www.linux-community.de/51422
-
Thorsten-Voice unter Linux installieren, YouTube: https://www.youtube.com/watch?v=uyG1Sx7_3Yg
-
Piper TTS: https://www.thorsten-voice.de/thorsten-voice-%f0%9f%92%9b-piper/
-
Speech Note: https://github.com/mkiol/dsnote
-
Speechnotes: https://speechnotes.co/transcribe/
-
Festival: https://wiki.ubuntuusers.de/Festival/
-
Zonos TTS: https://github.com/Zyphra/Zonos
-
Ebook2audiobook: https://github.com/DrewThomasson/ebook2audiobook
-
Hugging Face: https://huggingface.co/spaces/drewThomasson/ebook2audiobook
-
Vosk-API: https://github.com/alphacep/vosk-api
-
Vosk-Models: https://alphacephei.com/vosk/models
-
Gnulinux.ch: https://gnulinux.ch/serie-sprachsteuerung-teil-2
-
WhisperAI: https://openai.com/index/whisper/
-
OOM: https://www.kernel.org/doc/gorman/html/understand/understand016.html





