

Nextcloud bietet einen KI-Assistenten, dessen Fähigkeiten Sie mit lokal betriebenen Sprachmodellen wirkungsvoll aufbohren. Dazu benötigen Sie lediglich den Container-Dienst Docker und ein paar Mausklicks.
Nextcloud hat sich in rund zehn Jahren zu einer überaus beliebten Open-Source-Kollaborationsplattform entwickelt. Unternehmen, Institutionen und Privatanwender nutzen die Software, um ihre Daten unter eigener Kontrolle zu behalten. Im Frühjahr 2023 zog mit dem Nextcloud-Assistenten erstmals eine optionale KI ein. Aufgrund ihrer Quelloffenheit und der rein lokalen Ausführung bezeichnet sie der Hersteller als ethische KI.
Mit dem Release des aktuellen Nextcloud Hub 10 erhielt auch der Assistent ein interessantes Update [1]. Seine Version 3.0 integriert einen KI-Agenten in Nextcloud, der unter anderem Chats mit der KI ermöglicht, Texte übersetzt, Gesichter auf Fotos erkennt und intelligent den Posteingang verwaltet. Der KI-Agent kann zudem Informationen aus verschiedenen Anwendungen extrahieren und damit Aktionen ausführen. So verfasst er auf Wunsch automatisch E-Mails, wandelt Sprache in Text, liest Nachrichten oder erstellt Kalendereinträge. Wie bei Nextcloud üblich, können Sie den KI-Agenten selbst hosten.
Der Nextcloud-Assistent bringt bereits ein lokales Large Language Model (LLM) mit, nutzt auf Wunsch aber auch andere große Sprachmodelle. Die dürfen lokal auf Ihrer eigenen Hardware oder bei einem externen Anbieter laufen. Nextcloud verbindet sich dabei prinzipiell mit allen KI-Diensten, die eine OpenAI-kompatible Schnittstelle anbieten.
Lokal mit LocalAI
Sofern Sie die volle Kontrolle über die KI in Nextcloud behalten möchten, bleibt nur der Betrieb eines LLMs auf eigener Hardware. Das gelingt entweder über LocalAI oder Ollama. Da der Artikel “Hirn installieren” [2] Ollama ausführlich vorstellt, soll im Folgenden LocalAI im Fokus stehen. Ollama ist obendrein auf textbasierte Anwendungen beschränkt, während LocalAI unter anderem auch mit grafischen Elementen umgehen kann.
Wenn Sie Nextcloud bereits auf einem eigenen Server betreiben, ist die Hardware häufig auf diesen Zweck zugeschnitten und somit nicht für den flotten Betrieb von LLMs ausgelegt. Zumeist fehlt dem System eine dedizierte Grafikkarte mit ausreichend RAM – die Nextcloud-Oberfläche zeichnet schließlich der Browser. Für einen ersten Test genügt dennoch der bereits vorhandene Server. Ohne dedizierte GPU führt LocalAI das LLM allerdings wesentlich langsamer direkt auf dem Prozessor aus.
Installieren
Besonders komfortabel binden Sie LocalAI über Docker ein. Sollten Sie den Container-Dienst noch nicht nutzen, holen Sie ihn über die Softwareverwaltung Ihrer Distribution hinzu. In der Docker-Dokumentation [3] finden Sie darüber hinaus Installationsanleitungen für verschiedene Distributionen .
Für diesen Artikel kommt das All-in-One Docker-Image von LocalAI [4] zum Einsatz. Im Gegensatz zum Standard-Image offeriert es von Haus aus fast den gesamten Funktionsumfang von LocalAI, einschließlich der dazu nötigen vorkonfigurierten Backends. So erlaubt das All-in-One-Image neben der Textgenerierung beispielsweise die multimodale Bildverarbeitung und eine Sprach-zu-Text-Erkennung.
Das All-in-One-Image existiert in einer Fassung für Systeme mit und ohne dedizierte Nvidia-GPU – im letzten Fall springt die CPU bei allen Berechnungen ein. Steckt bei Ihnen eine AMD-Grafikkarte im Rechner, müssen Sie derzeit noch auf die CPU-Fassung oder Ollama zurückgreifen. Zwar steht die AMD-Unterstützung von LocalAI kurz vor der Veröffentlichung, zum Redaktionsschluss fehlte aber noch ein einsatzfertiges Image. Dementsprechend sollten Sie in diesem Kontext die LocalAI-Dokumentation im Auge behalten.
Den zur Installation des All-in-One-Image notwendigen Befehl sehen Sie in Listing 1. Wenn Sie das LLM nur auf dem Prozessor laufen lassen möchten, verwenden Sie das Kommando aus der zweiten Zeile. Wenn Ihre Nvidia-Grafikkarte die Berechnungen beschleunigen soll, müssen Sie zunächst den proprietären Nvidia-Treiber und das Nvidia Container Toolkit [5] einspielen.
Ermitteln Sie daraufhin mit nvidia-smi --version die bei Ihnen vorhandene CUDA-Version. Holen und starten Sie schließlich das Docker-Image über den Befehl aus der letzten Zeile in Listing 1. Sofern auf Ihrem System noch die CUDA-Bibliothek in der Version 11 arbeitet, ersetzen Sie die Zahl am Ende des Kommandos mit einer 11.
Unabhängig davon, ob Sie die CPU- oder GPU-Fassung nutzen, wartet LocalAI an Port 8080 auf Anfragen. Ist dieser Port bei Ihnen belegt, ändern Sie im entsprechenden Befehl seine Nummer links vom Doppelpunkt auf den nächsten freien Port, beispielsweise auf 8081.
Listing 1
LocalAI installieren
# LocalAI AIO mit Docker für die Nutzung per CPU: $ docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-cpu # LocalAI AIO mit Docker für die Nutzung mit Nvidia GPU: $ docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
LocalAI ohne Docker installieren
Ohne Docker installieren Sie LocalAI über folgenden Einzeiler:
curl https://localai.io/install.sh | sh
Er lädt mit dem Werkzeug Curl ein Shell-Skript herunter und führt es direkt aus. Diese Installationsmethode wirkt verlockend kurz und bequem. Da mit ihr allerdings ein Skript aus dem Internet ungesehen weitreichende Rechte erhält, raten wir aus Sicherheitsgründen davon ab.
Erste Schritte
Nach der Eingabe des passenden Befehls rollt Docker das LocalAI-Image aus und fährt den Container hoch. Der wiederum lädt mehrere LLMs herunter, was einige Minuten dauert. Ist die Einrichtung abgeschlossen, öffnen Sie LocalAI in Ihrem Browser über http://<I>Rechner-IP<I>:8080. Ersetzen Sie dabei gegebenenfalls den Port durch den von Ihnen bei der Installation von LocalAI gewählten.
Danach begrüßt Sie LocalAI und lässt Sie wissen, dass neun Standard-LLMs (Abbildung 1) für unterschiedliche Anwendungszwecke zur Verfügung stehen. Für einen Funktionstest klicken Sie oben in der Leiste auf Chat und stellen dem dort zuständigen Modell GPT-4 eine Frage. Wenn Sie eine Antwort (Abbildung 2) erhalten, ist LocalAI einsatzbereit. Möchten Sie weitere Modelle installieren, präsentiert ein Klick auf Models eine Vielzahl verfügbarer LLMs. Achten Sie darauf, dass das gewählte Modell zu den auf Ihrem System vorhandenen Hardwareressourcen passt.
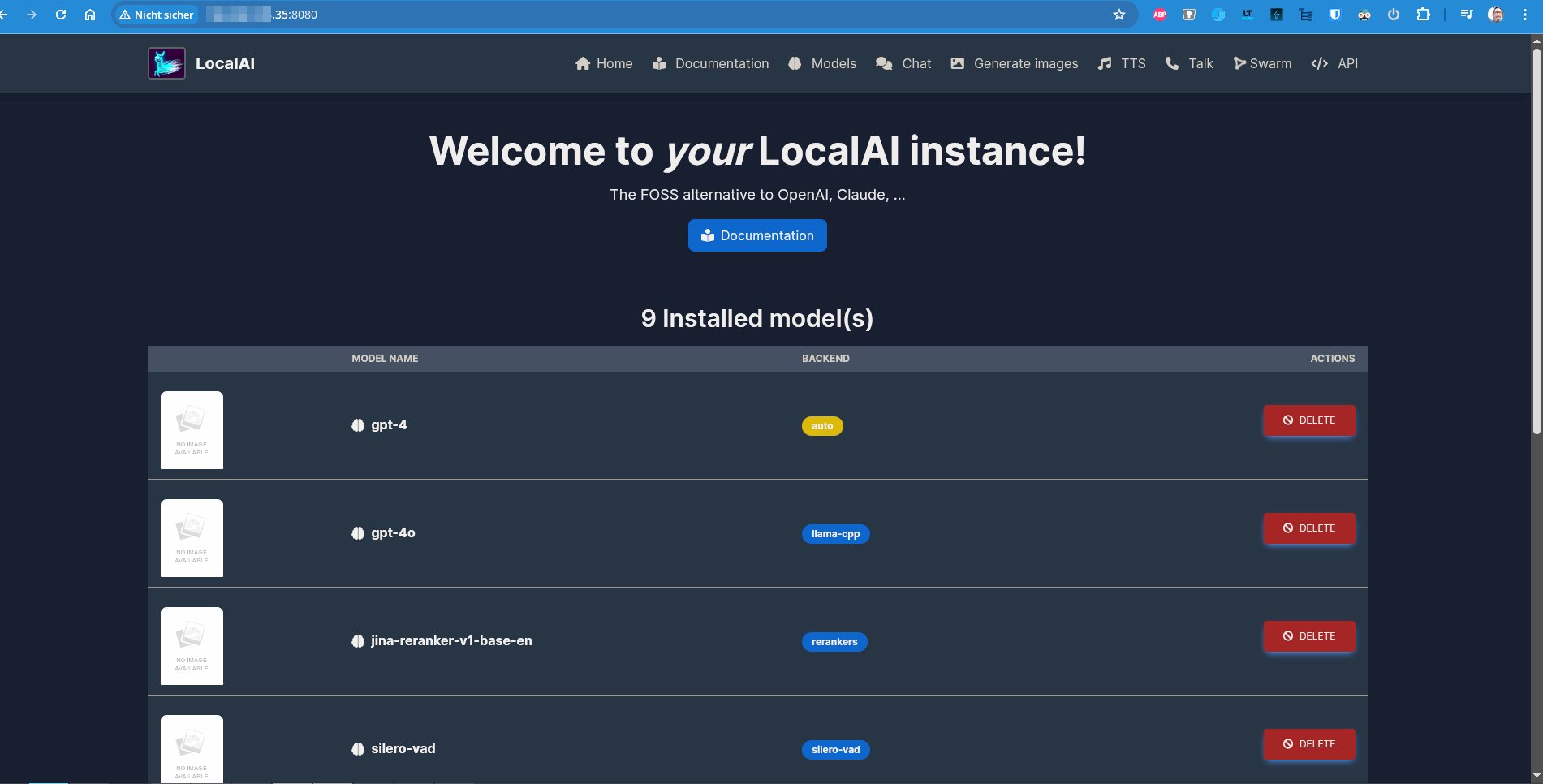
Abbildung 1: Der erste Start von LocalAI verrät, dass bereits neun LLMs auf Arbeit warten. Was Sie nicht benötigen, können Sie hier vorab löschen.
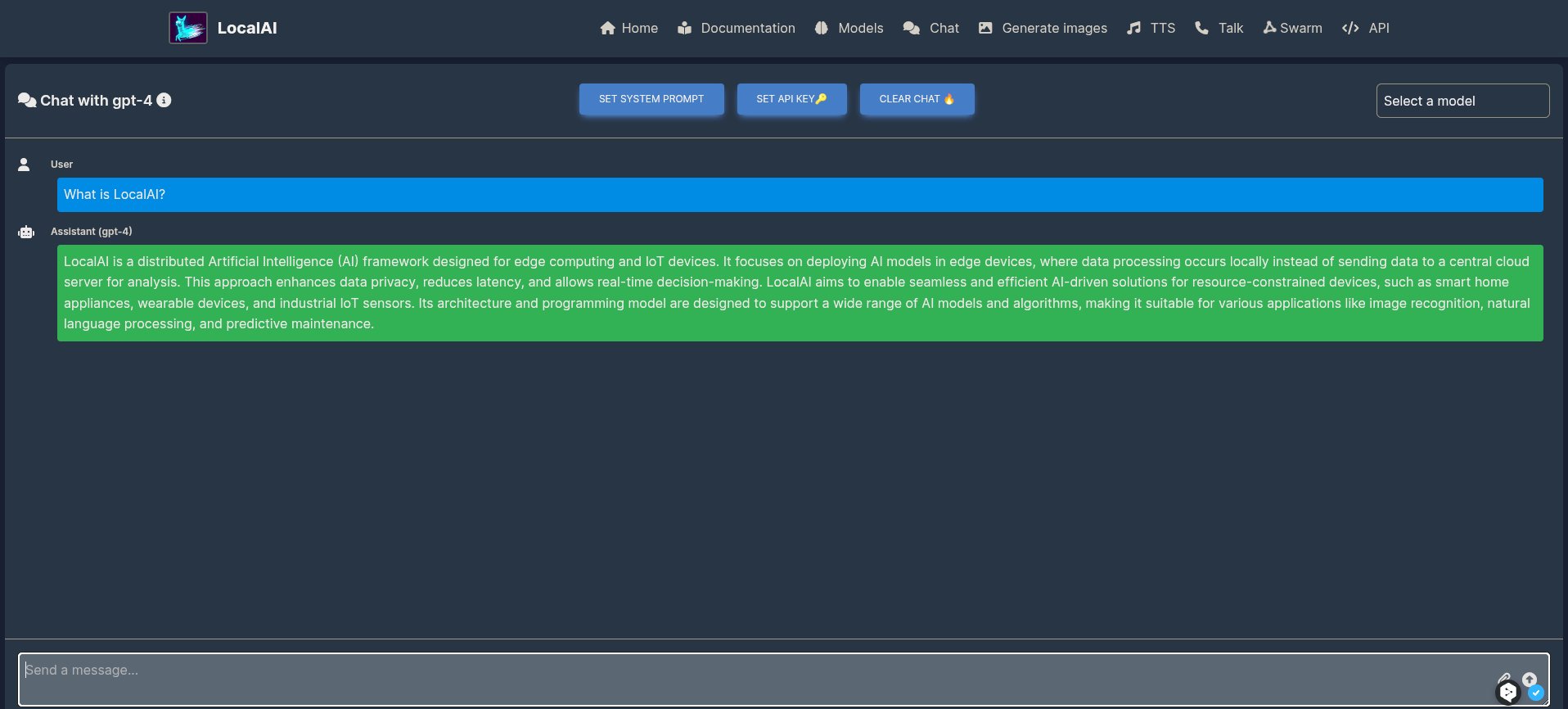
Abbildung 2: Um sicherzugehen, dass die Installation reibungslos geklappt hat, starten Sie einen ersten Chat und bitten wie hier LocalAI um eine Selbstbeschreibung.
Apps bereitstellen
Wechseln Sie jetzt in Ihre Nextcloud, wählen Sie aus den Einstellungen rechts oben den Menüpunkt Apps und geben Sie in der Suche den Begriff Assistant ein. An oberster Stelle sollte die App Nextcloud Assistant erscheinen, rechts daneben sehen Sie ihren Status. Falls die App bereits installiert und aktiviert ist, gibt es nichts zu tun. Ansonsten müssen Sie sie Herunterladen und aktivieren (Abbildung 3). Tippen Sie nun den Suchbegriff LocalAI ein und installieren Sie die App OpenAI und LocalAI-Integration. Möchten Sie später die KI wieder aus Nextcloud verbannen, genügt es, die beiden Apps zu entfernen.
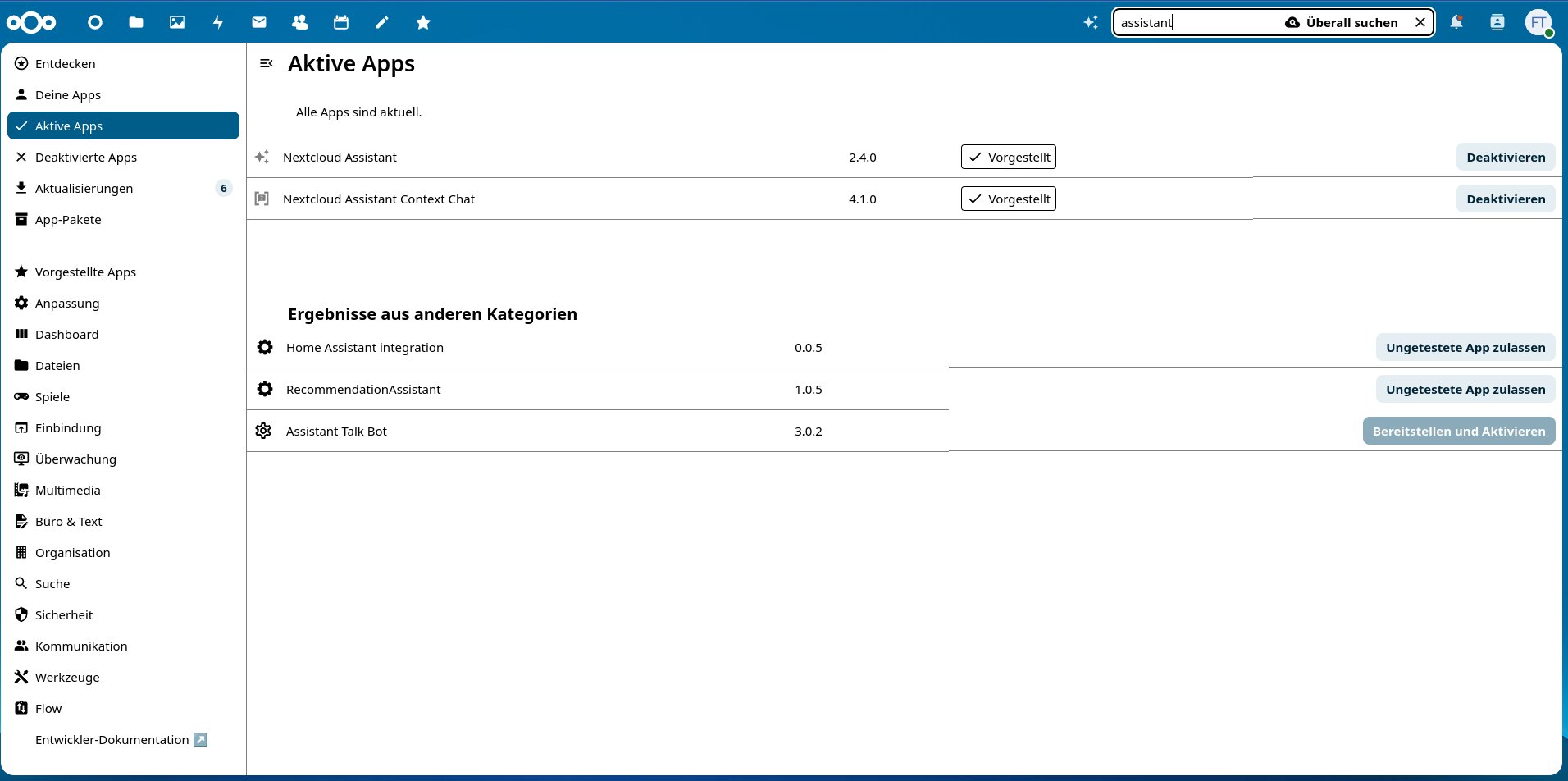
Abbildung 3: Stellen Sie zunächst in Nextcloud sicher, dass die notwendigen KI-Apps installiert und aktiv sind. Dazu zählt neben dem Nextcloud Assistant auch die App OpenAI und LocalAI-Integration.
Der nächste Schritt führt Sie in die Verwaltungseinstellungen (bei älteren Versionen Administrationseinstellungen). Klicken Sie dort auf den Punkt Künstliche Intelligenz (Abbildung 4). Im neuen Bildschirm sollte überall LocalAI als Provider definiert sein.
Scrollen Sie nach unten bis zum Punkt OpenAI und LocalAI-Integration. Im ersten Eingabefeld mit der Aufschrift Service-URL verbinden Sie die Nextcloud mit dem Container von LocalAI. Dazu tragen Sie die URL (Abbildung 5) ein, die Sie zuvor für den Test von LocalAI genutzt haben. Liegt der Container auf demselben Rechner wie Nextcloud, wäre dies http://localhost:8080. Ansonsten ersetzen Sie localhost durch die IP-Adresse des entsprechenden Rechners.
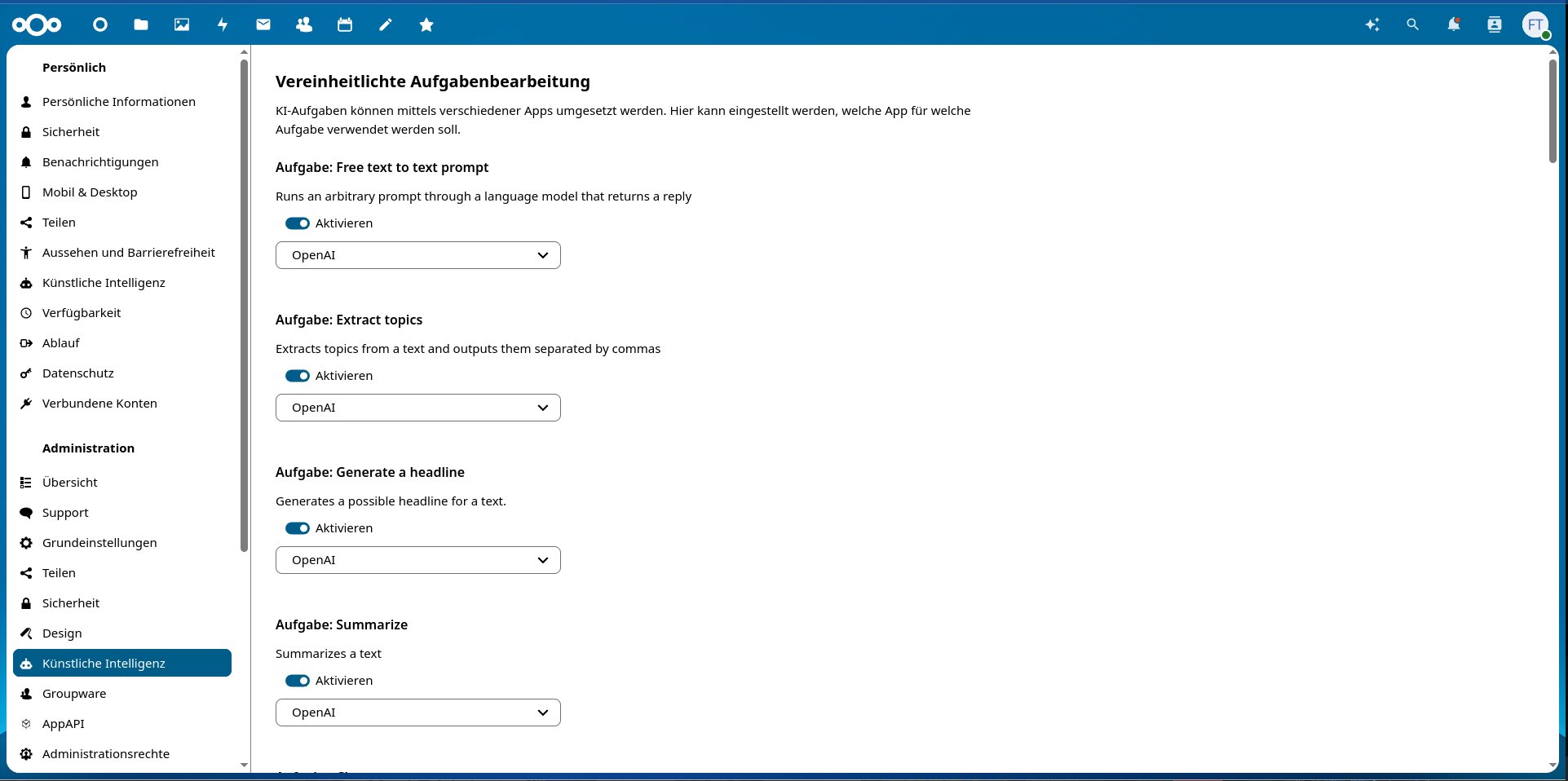
Abbildung 4: In der Rubrik Künstliche Intelligenz sollte zu diesem Zeitpunkt überall OpenAI als Provider stehen. Nicht benötigte Module lassen sich hier deaktivieren.
Abbildung 5: Diese Maske stellt über die URL die Verbindung zur Nextcloud her. Funktioniert hier alles, sind Sie im nächsten Schritt bereit für LocalAI in der Nextcloud.
Falls Sie einen OpenAI-API-Key besitzen, hinterlegen Sie ihn jetzt ebenfalls in Nextcloud. Unter Endpunkt zur Textvervollständigung stellen Sie schließlich noch Chat completions ein. Damit ist die Grundkonfiguration bereits erledigt. Klicken Sie oben rechts auf das Symbol mit den Sternen, wodurch der Nextcloud-Assistent bei LocalAI anklopft.
Aufgabenverteilung
Die jetzt erscheinende Maske spricht noch nicht durchgehend Deutsch. Im oberen Teil präsentiert sie die verfügbaren Elemente. Dabei im Angebot sind unter anderem der obligatorische Chat, ein Modul, um Texte zu erstellen, ein Context Chat, der Fragen zu den in der Nextcloud liegenden Dokumenten beantwortet, sowie ein Übersetzer. Ein Klick öffnet die jeweils zuständige Maske (Abbildung 6), die Sie passend ausfüllen.
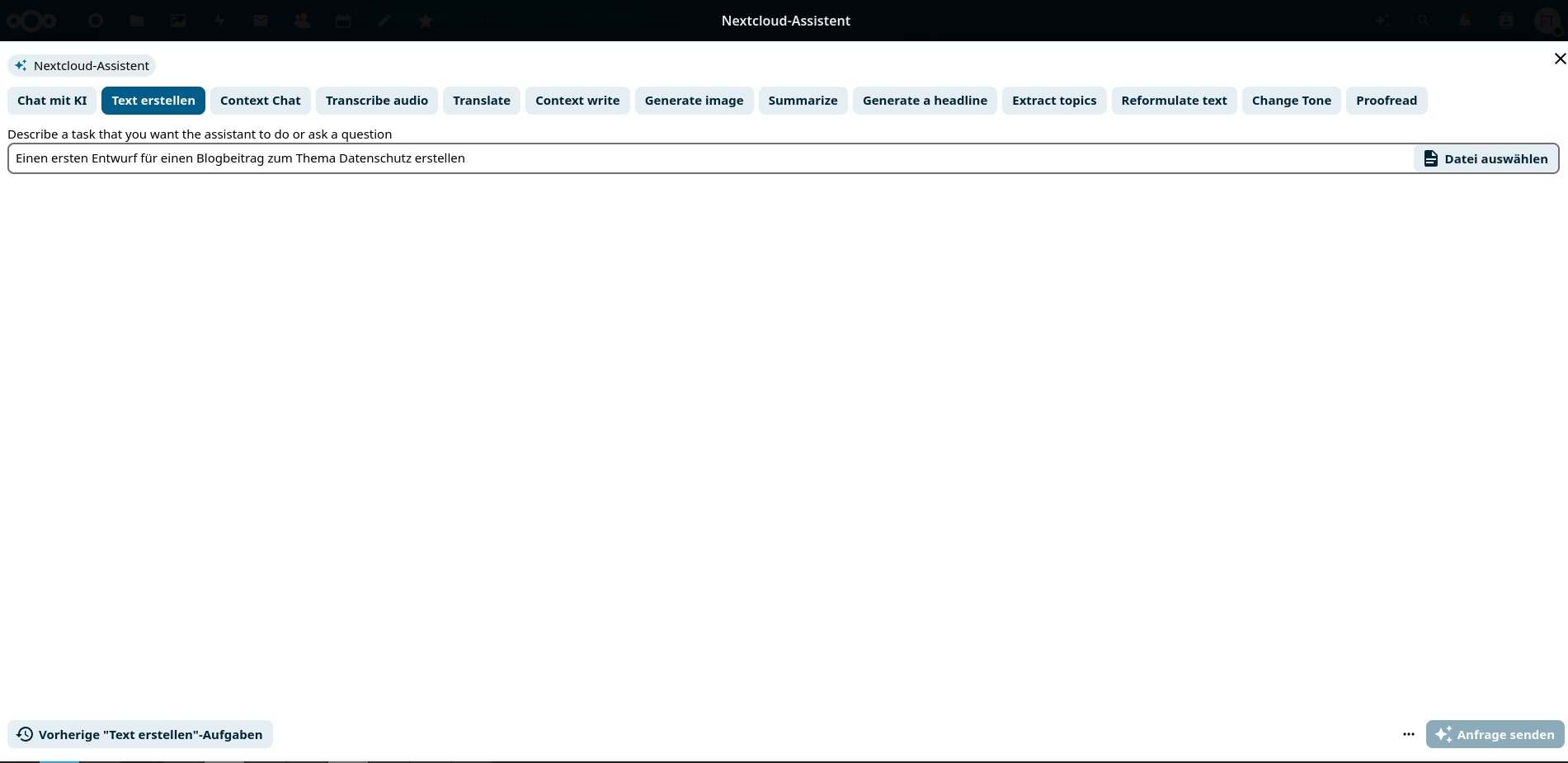
Abbildung 6: Der Nextcloud-Assistent offeriert verschiedene Module, die für die KI-Aufgaben zur Verfügung stehen.
Länger laufende Aufgaben können Sie in den Hintergrund (Abbildung 7) schicken und sich bei Fertigstellung benachrichtigen lassen. Das empfiehlt sich besonders, wenn die CPU das LLM betreiben muss. In unseren Tests fiel auf, dass Nextcloud 30 und 31 selbst bei einfachen Fragen und einer dedizierten Grafikkarte mehrere Minuten für eine Antwort brauchten. Mit der Version 29 funktionierte das deutlich zügiger. Als Verursacher [6] entpuppte sich ein Cronjob, der die Background-Jobs lediglich alle fünf Minuten anstößt. Abhilfe schafft ein eigener Container für Cron [7], dessen Einrichtung allerdings den Rahmen dieses Artikels sprengen würde.
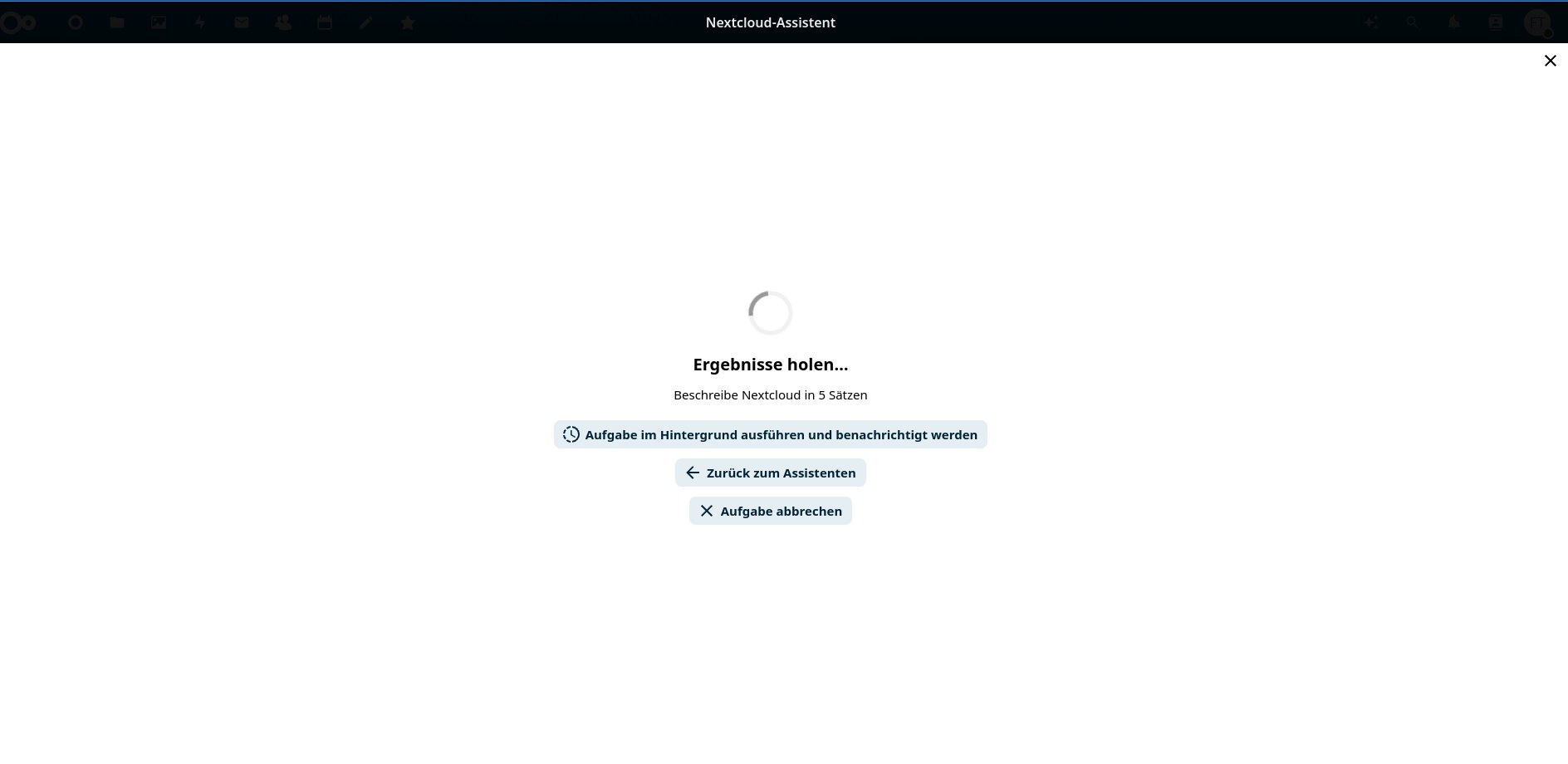
Abbildung 7: Eine Aufgabe lässt sich in den Hintergrund verschieben oder abbrechen. Eine weitere Option führt zurück zum Assistenten.
Fazit
Die Integration von LLMs per LocalAI in die Nextcloud funktioniert problemlos und erweitert die KI-Fähigkeiten der Kollaborationsplattform. Allerdings sind die Antwortzeiten nach der hier beschriebenen Standard-Installation selbst mit dedizierter Hardware zu lang für einen produktiven Einsatz. Geeignet ist die Methode daher ausschließlich als Machbarkeitsstudie, oder um die grundlegenden Abläufe beim Einrichten einer lokalen KI zu erlernen. Wenn mit kommenden Nextcloud-Versionen die Geschwindigkeit wieder auf ein akzeptables Maß steigt, ist LocalAI ein passendes Tool, um Nextcloud auf die KI-Sprünge zu helfen. (tsc)
Infos
- NC Assistant: https://nextcloud.com/de/features/#ai
- KI im Terminal: Ferdinand Thommes, “Hirn installieren”, LU 05/2025, S. 10, https://www.linux-community.de/51891
- Installation von Docker: https://docs.docker.com/engine/install/
- LocalAI-AIO: https://localai.io/basics/container/#all-in-one-images
- Installing the NVIDIA Container Toolkit: https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
- Nextcloud Online-Dokumentation – Improve AI task pickup speed: https://docs.nextcloud.com/server/latest/admin_manual/ai/overview.html#ai-overview-improve-ai-task-pickup-speed
- Background jobs using cron not working in a Nextcloud Docker environment: https://help.nextcloud.com/t/background-jobs-using-cron-not-working-in-a-nextcloud-docker-environment/167544




