

Mit LVM haben Linux-Anwendern ein mächtiges Werkzeug zur Hand, das den Grenzen physikalischer Datenträger ihren Schrecken nimmt.
Wer kennt das nicht: Ein einst großzügig ausgelegtes Dateisystem läuft langsam, aber sicher voll – höchste Zeit, das entsprechende Laufwerk zu ersetzen. Fragt sich bloß, wie das ohne Unterbrechung funktioniert. Und wie lange wird es dauern, bis derselbe Schritt erneut anfällt? Ohne vom physikalischen Datenträger zu abstrahieren, wird das Phänomen immer und immer wieder für Probleme sorgen. Exakt an dieser Stelle springt der Logical Volume Manager LVM [1] ein und bringt im Gepäck noch viel mehr mit [2].
LVM abstrahiert vom physikalischen Medium [3]. Dabei steht die Art des Speichermediums im Hintergrund. Es kann sich um Partitionen oder komplette Laufwerke handeln – egal, Hauptsache, es ist ein Block Device. Das jeweilige Gerät erhält bei der Initialisierung durch LVM neben einigen Metadaten eine Art Formatierung mit Physical Extents (PE). PEs sind die kleinsten Einheiten auf Physical Volumes (PV) und lassen sich mit Blöcken vergleichen. Ihre Größe können Sie beim Erzeugen der PVs angeben und bei Bedarf nachträglich ändern. Standardmäßig sind PEs auf 4 MiB festgelegt.
Physical Volumes lassen sich zu Volume Groups (VG) zusammenfassen. Deswegen können Sie problemlos mehrere Festplatten oder Partitionen in einer VG bündeln. Alternativ generieren Sie ganz simpel eine eigene VG aus einer einzelnen PV. VGs lassen sich als eine Art Speicherplatz-Pool betrachten. Der darin zur Verfügung stehende Speicher unterteilt sich in gleich große Logical Extents (LE), die wiederum eine Abstraktion zu den PEs sind.
Sofern die gewünschte Kapazität vorhanden ist, können Sie nun auf VGs Logical Volumes in beliebiger Größe erzeugen. Volume Groups und Logical Volumes erhalten dabei Namen, die Sie im Nachhinein anpassen können. Über die Namen lassen sie sich später adressieren. Erzeugt man zum Beispiel eine VG namens vg_system und darauf ein LV namens lv_var, stellt der Device Mapper das Volume über den Pfad /dev/vg_system/lv_var beziehungsweise via /dev/mapper/vg_system-lv_var bereit. Abbildung 1 zeigt den schematischen Aufbau.
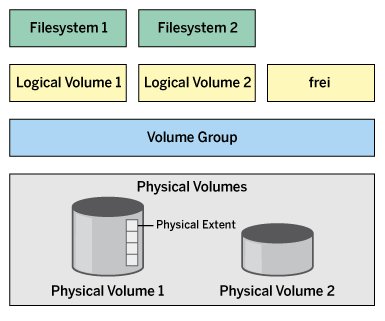
Abbildung 1: Der schematische Aufbau von LVM als Schichtenmodell verdeutlicht die Zusammenhänge zwischen den Volumes.
Ein weiterer wissenswerter Aspekt: LVM adressiert intern die zugehörigen Physical Devices über deren UUID, nicht über Gerätedateien. Das wiederum erweist sich besonders bei der Virtualisierung als nützlich: Es gibt keine Garantie dafür, dass die Reihenfolge virtueller SCSI-Controller einer VM dieselbe ist wie im jeweiligen Gastsystem.
Linear Volumes
Eines der simpelsten Einsatzszenarien für LVM besteht aus einem Linear Volume, einem Dateisystem, das sich über mehrere Physical Devices aufspannt.
Vor allem, wenn man eben auf keiner der großen Virtualisierungslösungen arbeitet, kommt es durchaus vor, dass irgendwann die maximale Auslastung des Speicherplatzes erreicht ist. Besteht dann die Möglichkeit, einen weiteren physikalischen Datenträger in die VG aufzunehmen und fällt dieser Datenträger hinreichend größer aus als ein bestehender, lässt er sich in den JBOD-Verbund integrieren. Daraufhin kann er sämtliche PEs eines der bisherigen Datenträger übernehmen. Auf diese Weise ließen sich kontinuierlich zu kleine Datenträger durch größere ersetzen, allein über LVM – und wohlgemerkt ohne Downtime.
Listing 1 zeigt, wie Sie mit wenigen Kommandos einen JBOD-Verbund über zwei Physical Devices erstellen. Per pvcreate kennzeichnen Sie beide Geräte als Physical Volumes. Mit vgcreate fügen Sie beide PVs zur VG volgrp_1 hinzu. Im nächsten Schritt erzeugen Sie per lvcreate ein einfaches Linear Volume beziehungsweise JBOD namens lv_jbod aus dem kompletten verfügbaren Speicherplatz in volgrp_1. Abschließend legen Sie per mkfs.ext4 ein Dateisystem auf der LV an (Abbildung 2), das sie dann einhängen können.
Listing 1
Einen JBOD-Verbund aufbauen
# pvcreate /dev/sd[a-d] # vgcreate volgrp_1 /dev/sda /dev/sdb # lvcreate -n lv_jbod -l 100%FREE volgrp_1 # mkfs.ext4 /dev/volgrp_1/lv_jbod # mount /dev/volgrp_1/lv_jbod /mnt/
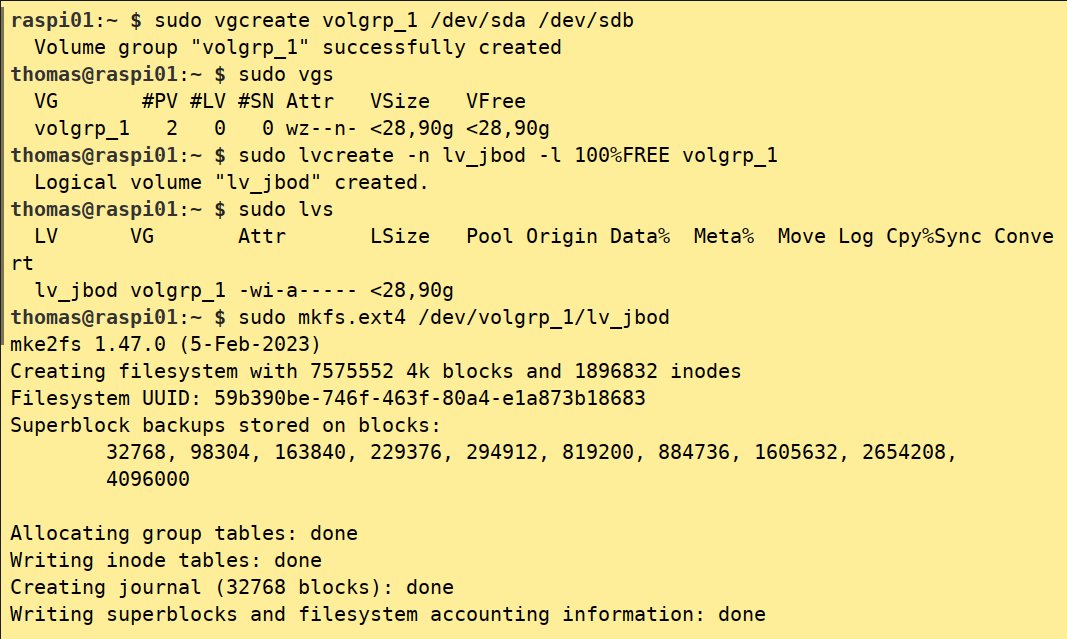
Abbildung 2: Aufbau eines Logical Volumes und Erzeugen eines Dateisystems.
Wie schon beschrieben, lassen sich im laufenden Betrieb sämtliche Extents eines Physical Volumes auf ein anderes übertragen – vorausgesetzt, innerhalb der Volume Group existiert noch ein physikalischer Datenträger mit einer ausreichenden Anzahl freier Physical Extents. Den Transfer erledigen Sie mittels pvmove. Abbildung 3 zeigt, wie sich die Volume Group volgrp_1 um das Gerät /dev/sdd erweitern und anschließend die Physical Extents auf dieses Gerät verschieben lassen.
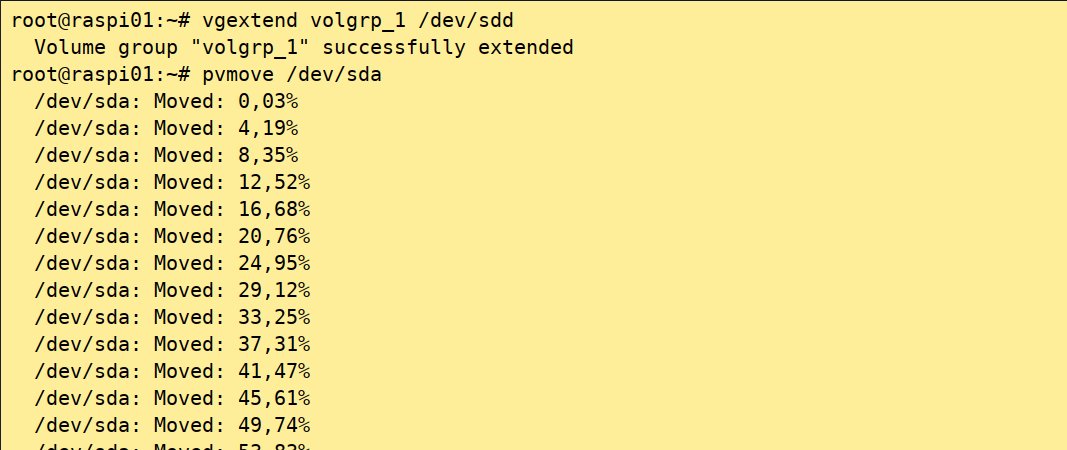
Abbildung 3: Mithilfe des Kommandos pvmove lassen sich Extents auf bestimmte Devices verschieben.
Striped Volumes
Stellen Sie keine besonderen Ansprüche an die Datensicherheit oder eine entsprechend zuverlässige Storage-Umgebung und präferieren stattdessen maximale Performance, sollten Sie sich mit einem LVM-Stripe Set auseinandersetzen. Stripe Sets lassen sich mit RAID 0 vergleichen. Konkret kümmert sich LVM darum, dass Datenpakete abwechselnd auf alle enthaltenen PVs im Stripe Set geschrieben werden. Dabei können Sie Stripe Sets aus zwei oder mehr PVs aufbauen. Bitte beachten Sie jedoch unbedingt, dass sämtliche PVs über dieselbe Speicherkapazität verfügen müssen. Listing 2 zeigt, wie Sie ein Stripe Set aus zwei Physical Devices erzeugen.
Listing 2
Erzeugen eines Stripe Sets
# pvcreate /dev/sd[ab] # vgcreate volgrp_2 /dev/sd[ab] # lvcreate --stripes 2 --extents 100%VG --name logvol_2 volgrp_2 # mkfs.ext4 /dev/volgrp_2/logvol_2 # mount /dev/volgrp_2/logvol_2 /mnt/
Auf Systemen, die nicht auf besonders zuverlässige Speichertechnologie zurückgreifen können, sollten Sie stets auf ein Mirrored Volume (Listing 3) setzen. Es entspricht einem RAID 1 – die Daten werden also gespiegelt, wie der Name schon andeutet. Typischerweise dürften sich in der Praxis die meisten Admins mit einer Spiegelung begnügen; prinzipiell verursacht es allerdings keine Probleme, mit LVM mehrere Spiegelungen einzurichten.
Listing 3
Erzeugen eines Mirror Sets
# pvcreate /dev/sd[cd] # vgcreate volgrp_3 /dev/sd[cd] # lvcreate --mirrors 1 --extents 100%VG --name logvol_3 volgrp_3 # mkfs.ext4 /dev/volgrp_3/logvol_3 # mount /dev/volgrp_3/logvol_3 /mnt/
Stripes und Mirrors
Die Vor- und Nachteile der Kombination aus zwei Mirror Sets, die man wiederum zu einem Stripe Set zusammenfasst (Listing 4), liegen auf der Hand: Pro Schreibvorgang muss hier nicht nur das passende Speicherobjekt im Stripe Set ermittelt, sondern obendrein ebenso jedes Datenpaket doppelt gespeichert werden. Die mehrstufige Verarbeitung erhöht tatsächlich merklich die Systemlast. Zudem erzielt man je nach Hardware mitunter nicht die gewünschte I/O-Performance.
Listing 4
Erzeugen eines Striped Mirror Sets
# pvcreate -ff /dev/sd[a-d] # vgcreate volgrp_4 /dev/sd[a-d] # lvcreate --type raid10 --mirrors 1 --stripes 2 -l 100%VG -n logvol_4 volgrp_4 # mkfs.ext4 /dev/volgrp_4/logvol_4 # mount /dev/volgrp_4/logvol_4 /mnt/
Auch RAID 5 verwendet intern eine Art von Striping und verteilt dabei Blöcke von Daten auf verschiedene physikalische Speicher. Doch dabei bleibt es nicht: Die Technik berechnet aus den Nutzdaten außerdem Paritätsinformationen, die sie ebenfalls über die PVs verteilt ablegt. Letztlich berechnet RAID 5 aus den vorherigen Blöcken per XOR eine Prüfsumme. Fällt eine Disk aus, lassen sich aus den verbliebenen Blöcken per XOR die defekten Daten wiederherstellen.
Doch alle Theorie ist grau, deshalb hier ein Beispiel. XOR, das exklusive Oder, eignet sich als logisches Gatter zur Addition zweier binärer Zahlen. Beschränke ich mich auf nur eine Binärstelle, gilt: 0 XOR 0 = 0, 0 XOR 1 = 1, 1 XOR 0 = 1 und 1 XOR 1 = 0. Ein genauer Blick zeigt: Egal, welcher Wert aus der Gleichung entfernt wird, er ergibt sich sofort aus den verbleibenden Werten. Prinzipiell stellt RAID 5 auf diese Weise die Integrität der Daten sicher.
Listing 5 demonstriert das Erstellen eines Logical Volumes für RAID 5 aus vier PVs. Dabei dienen die Geräte /dev/sda bis einschließlich /dev/sdd als PVs. Ich gebe als Zielgröße des Logical Volumes 100 Prozent der Extents an, was aufgrund der inneren Strukturen von RAID 5 etwa 32 GByte nutzbarem Speicher entspricht.
Listing 5
RAID 5 mit LVM
# pvcreate -ff /dev/sd[a-d] # vgcreate volgrp_5 /dev/sd[a-d] # lvcreate --type raid5 --size 12G --stripes 3 --name logvol_5 volgrp_5 # mkfs.ext4 /dev/volgrp_5/logvol_5 # mount /dev/volgrp_5/logvol_5 /mnt/
Bei RAID 5 offenbart sich noch deutlicher, dass Software-RAID die CPU-Performance beeinträchtigt. Während der Tests stieg die Systemlast spürbar an, sodass RAID 5 am ehesten dann zu empfehlen ist, wenn das jeweilige System nicht noch zusätzliche rechenintensive Aufgaben bewältigen muss.
In die Vergangenheit
Zu den unstrittig nützlichsten Funktionen von LVM gehören Snapshots. Sie erzeugen sie wie ein Logical Volume mit einigen wenigen angepassten Parametern. Sofern kein Thin Pool vorliegt, entstehen Copy-on-Write-Snapshots (COW). Das greift ebenfalls bei Snapshots, bei denen Sie zur Erzeugungszeit eine Größe angeben.
Oft genügt es, COW-Snapshots auf etwa 20 Prozent des zugehörigen Logical Volumes zu skalieren. Abhängig von der Anzahl der Schreibzugriffe kann diese Zahl durchaus anders ausfallen. Hier empfehle ich, zu testen und währenddessen den Füllgrad der Dateisysteme zu überwachen. Gegebenenfalls können Sie solche Snapshot-Volumes außerdem mit lvextend vergrößern. Bitte beachten Sie, dass innerhalb der Snapshots zusätzlich Metadaten wie Blockadressen gespeichert werden.
Mit dem Erzeugen des Snapshots (Listing 6, erste Zeile) landen Schreibzugriffe schließlich auf dem Snapshot-Volume, während das Ausgangs-Volume unangetastet bleibt. Dementsprechend funktioniert es also, Backups zu erzeugen, während gleichzeitig bestimmte Dateien beschrieben werden.
Listing 6
Erzeugung eines Snapshots
# lvcreate -L 20G --snapshot --name backup_snapshot /dev/volgrp_2/logvol_2 # lvconvert --merge /dev/volgrp_2/backup_snapshot
Mit dem Abschluss des Backups erlischt die Daseinsberechtigung des Snapshots. Nun lässt er sich auf das ursprüngliche Volume übertragen, also mergen. In Listing 6 findet sich das entsprechende Kommando lvconvert (letzte Zeile).
Fazit
LVM gibt Linux-Anwendern ein mächtiges Werkzeug an die Hand, das den Grenzen physikalischer Datenträger ihren Schrecken nimmt. Betreiben Sie Ihre Datenbanken, Bewegungsdaten, Austauschverzeichnisse und so weiter auf Logical Volumes, müssen Sie eine Verknappung des Speicherplatzes nicht fürchten.
Gilt es, besonderen Ansprüchen an die Datensicherheit Rechnung zu tragen, bilden Sie entsprechende RAID-Level per Software ab. Mit Stripe Sets erhöhen Sie den Durchsatz tatsächlich erheblich. LVM-Snapshots wiederum helfen in mannigfaltigen Szenarien. Das beginnt bei einfachen Tests, die sich wieder rückgängig machen lassen müssen, und reicht bis hin zu Snapshot-gestützten Backups beispielsweise einer Datenbank. Im Gegensatz zu Btrfs zeigt sich LVM sehr ausgereift und entsprechend stabil.
Sicher ließen sich viele der gezeigten Fälle sehr elegant mit ZFS umsetzen, doch das spielt seine Stärken erst ab einer großen Disk-Anzahl aus. Zudem erfordert es deutlich mehr RAM als andere Dateisysteme. (csi)
Infos
-
LVM2 Resource Page: https://sourceware.org/lvm2/
-
LVM unter Ubuntu: https://wiki.ubuntuusers.de/Logical_Volume_Manager/
-
LVM-Grundlagen: https://www.thomas-krenn.com/de/wiki/LVM_Grundlagen




