

Dedizierte Datenbank-Clients haben meist eine steile Lernkurve. Routinearbeiten klappen oft per Shell und Shell-DB-Client einfacher und rationeller.
Das Datenbanksystem PostgreSQL [1] liefert den zugehörigen Shell-Client Psql gleich mit. Ruft man ihn lokal auf dem Rechner auf, auf dem PostgreSQL läuft, fallen weder eine weitere Konfiguration noch eine eigenständige Benutzeranmeldung an. Für die Praxis bedeutet das, dass die Skripte und die Datenbank auf demselben Rechner laufen müssen. Anderenfalls würde die Handhabung von Psql aufgrund der ständigen Benutzeranmeldung unbequem. Eine weitere Voraussetzung für das komfortable Nutzen des Shell-Clients: Es muss dafür systemseitig bereits ein Benutzerkonto existieren.
Als Root ermitteln Sie zunächst mit dem Kommando ps ax | grep postgres, unter welchem Benutzernamen der Datenbank-Daemon läuft. Dann schlüpfen Sie – immer noch als Root – in die Rolle des ermittelten Benutzers und legen das Administrationskonto zum Verwalten der Datenbank an (Listing 1, erste Zeile). Im Folgenden verwenden wir dbadmin für das Benutzerkonto.
Als dbadmin legen Sie einen weiteren Benutzer namens artikel und eine Datenbank an, die Sie ebenfalls artikel nennen (Listing 1, letzte zwei Zeilen). Anschließend melden Sie sich als frisch gebackener Datenbankbenutzer am Linux-System an und geben auf der Shell einfach psql ein. Eine funktionierende Datenbankverbindung sieht so aus wie in Abbildung 1. Mit \q beenden Sie die Sitzung wieder.
Listing 1
Datenbank anlegen
$ su -- postgres -c "createuser -s Benutzer" $ createuser artikel -d $ createdb artikel
Abbildung 1: Aufbau einer Datenbankverbindung mit Psql.
Musterdaten
Die für die Beispiele verwendete Mustertabelle artikel (Tabelle “Daten: artikel”) enthält zwei Felder: info nimmt eine Bauteilbezeichnung auf, gtin enthält entweder die GTIN [2] (früher: EAN-Code) oder eine hausinterne Kodierung. Die Bestandsmenge wird hingegen in der Tabelle bestand (Tabelle “Daten: bestand”) erfasst, die nur die Felder gtin und menge enthält. Als Primärschlüssel dient in beiden Tabellen das Feld gtin.
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Tabellen anlegen
Manuell tippen Sie im Datenbank-Client die Kommandos aus Listing 2 ein, um die Tabellen und einen View (eine Datenabfrage, die sich wiederum wie eine Tabelle abfragen lässt) anzulegen. Wenn man das für mehrere Geräte oder Benutzer einrichten möchte, ist das ein fehlerträchtiges Unterfangen. Dasselbe gilt für den Fall, dass man die Daten von Hand einpflegen will. Alles in allem wäre das ein zeitraubendes und umständliches Prozedere.
Listing 2
anlegen.sql
create table artikel (info text, gtin text primary key); create table bestand (gtin text primary key, menge numeric(10,2)); create view bestandliste as select artikel.info, bestand.menge, artikel.gtin from artikel, bestand where artikel.gtin=bestand.gtin;
Erfreulicherweise lassen sich SQL-Anweisungen aber in einer Datei ablegen; in unserem Fall nennen wir sie anlegen.sql. Sie lässt sich anschließend über den Befehl psql -f anlegen.sql abarbeiten. Das macht die Vorgänge rund um die Datenbank auf beliebig vielen Systemen mit gleichen Voraussetzungen reproduzierbar.
Direkt in der Shell oder in einem Shell-Skript geben Sie Ihre Anweisungen für die Datenbank in der Form psql -c "SQL-Anweisung;" an. Das Skript einspielen.sh (Listing 3) verwendet beide Zugriffsformen, also eine Datei mit SQL-Anweisungen und direkte Aufrufe per Shell. Es enthält in der ersten Zeile ein Kommando, um die SQL-Datei auszuführen. Die beiden folgenden Kommandos lesen zwei CSV-Dateien in die Tabellen artikel und bestand ein.
Listing 3
einspielen.sh
psql -f anlegen.sql psql -c "COPY artikel(info, gtin) from stdin DELIMITER ',';" < artikel.csv psql -c "COPY bestand(gtin, menge) from stdin DELIMITER ',';" < bestand.csv
Mit Psql lesen Sie SQL-Skripte über die Option -f ein. Direkte SQL-Anweisungen erteilen Sie in einem Shell-Skript mit der Option -c, der die in Anführungszeichen eingeschlossenen Anweisungen folgen. Vergessen Sie nicht, die Statements jeweils mit einem Semikolon (;) abzuschließen. Der Weg über stdin samt Eingabeumleitung der CSV-Datei mutet etwas umständlich an. Jedoch können und dürfen auf diesem Weg auch Datenbankbenutzer ohne administrative Rechte CSV-Inhalte einlesen. Abbildung 2 zeigt den Ablauf des Shell-Skripts.
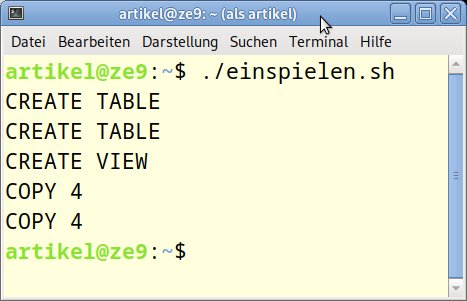
Abbildung 2: Der Ablauf beim Ausführen von einspielen.sh.
Weitere Optionen für Psql bezüglich des Datenbankzugriffs betreffen die Angabe der Datenbank (-d Datenbank) und eines von der Vorgabe 5432 abweichenden Ports (-p Port). Zusätzliche Parameter für den Verbindungsaufbau umfassen den Zugriff mit Benutzernamen und Kennwort sowie die Angabe eines Rechnernamens oder einer IP-Adresse.
Daten abfragen
Beim Abfragewerkzeug Psql nehmen Sie über verschiedene Optionen Einfluss auf die Ausgabeform. Die wichtigsten davon fasst die Tabelle “Psql: Ausgabeoptionen” zusammen. In Abbildung 3 sehen Sie die ersten vier davon im Einsatz.
|
Format |
Option |
|---|---|
|
normal |
ohne |
|
mit Rahmen |
|
|
nur Datensätze |
|
|
Ausgabe im CSV-Format |
|
|
Ausgabe im HTML-Format |
|
|
Ausgabe als LaTeX-Tabelle |
|
|
Rahmen aus Linien statt Zeichen |
|
|
erweiterte Ausgabe |
|
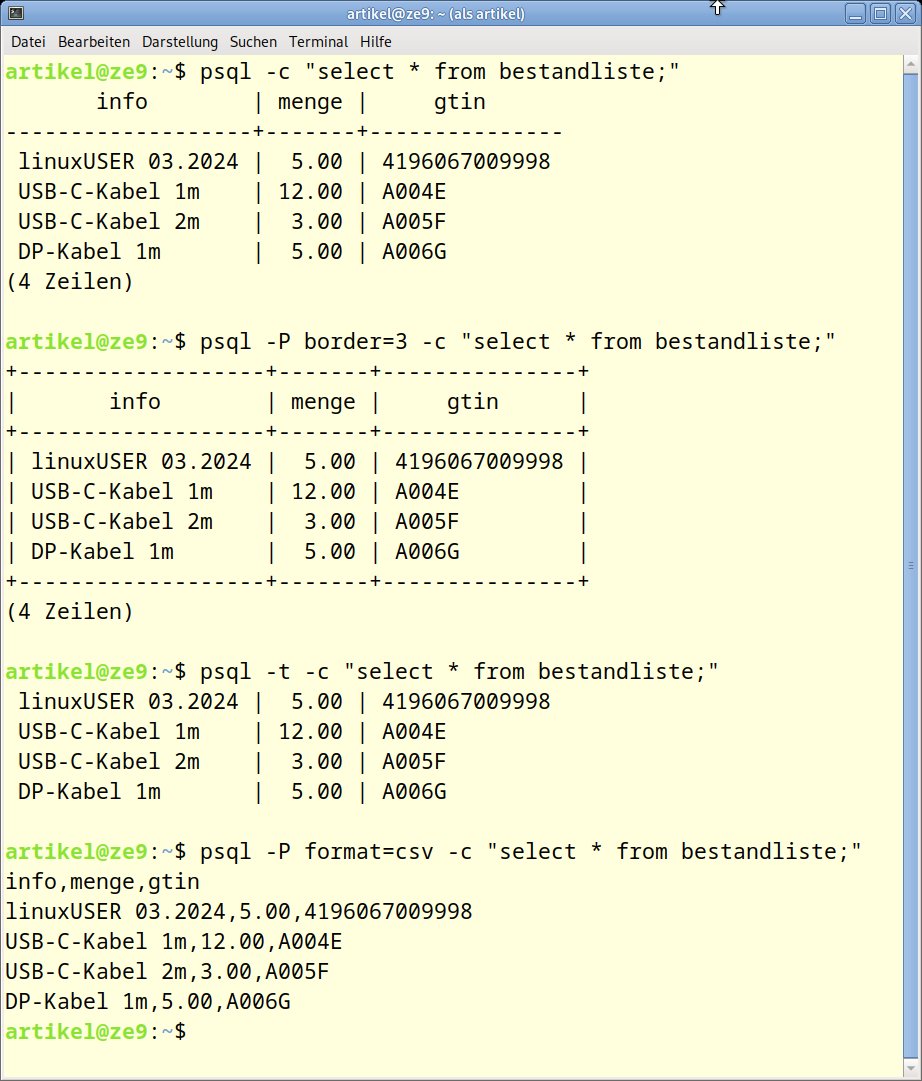
Abbildung 3: Beispiele für eine Datenabfrage mit verschiedenen Optionen.
Ausgabelisten können Sie tabellenartig oder detailliert erzeugen (Abbildung 4). Den zweiten Fall steuern Sie speziell mit der Option -x. In Kombination mit dem Weglassen der Datensatznummer (-t) und des Rahmens (-P border=3) erhalten Sie eine übersichtliche Ausgabe. Damit steht alles bereit, um einfache Listen der Daten auszugeben.
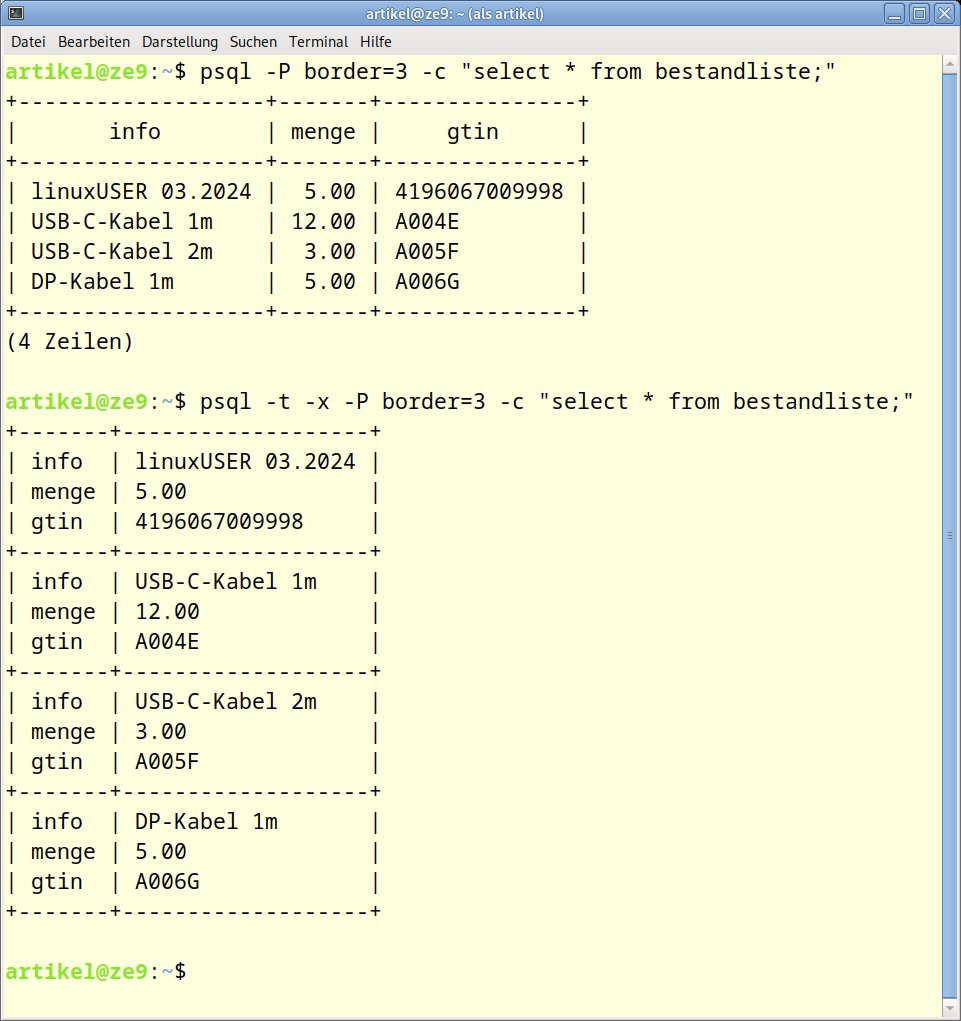
Abbildung 4: Psql kennt verschiedene Ausgabeformate.
Im Arbeitsalltag benötigen Sie oft nur einige wenige Datensätze oder sogar nur einen einzigen. Die where-Klausel in der SQL-Anweisung hilft beim Durchsuchen des Datenbestands. Dabei gibt es verschiedene Filterkriterien, die die Tabelle “SQL: where-Klausel” auflistet. Wie Sie dort sehen, führen durchaus mehrere Wege zum gewünschten Ergebnis. Beachten Sie, dass Sie Text- und Datumswerte mit Hochkommas (') eingrenzen müssen.
|
Suche |
Klausel |
|---|---|
|
Vergleichsoperatoren für Zahlen |
|
|
Spaltenwert = Suchwert |
|
|
Spaltenwert ungleich Suchwert |
|
|
Spaltenwert größer Suchwert |
|
|
Spaltenwert kleiner Suchwert |
|
|
Spaltenwert größer-gleich Suchwert |
|
|
Spaltenwert kleiner-gleich Suchwert |
|
|
Vergleichsoperatoren für Text und Datum |
|
|
Spaltenwert = Suchbegriff |
|
|
Spaltenwert ungleich Suchbegriff |
|
|
Spaltenwert enthält längere Zeichenkette, beginnt mit dem Suchbegriff |
|
|
Spaltenwert enthält Suchbegriff |
|
|
Spaltenwert enthält nicht den Suchbegriff |
|
|
Spaltenwert enthält nicht den Suchbegriff |
|
|
Vergleichsoperatoren für Datumsangaben |
|
|
Datum nach genanntem Datum |
|
|
Datum ab genanntem Datum |
|
|
Datum vor dem genannten Datum |
|
|
Datum bis genanntem Datum |
|
|
Verknüpfungen von Bedingungen |
|
|
Bedingung 1 oder Bedingung 2 wahr |
|
|
Bedingung 1 und Bedingung 2 wahr |
|
|
Bedingung nicht wahr |
|
Um die Möglichkeiten der where-Klausel zu verdeutlichen, zeigt Abbildung 5 einige Abfragen mit festen Abfragewerten. Das erste Beispiel soll den Bestand aller Artikel anzeigen, deren menge mehr als 4 Stück beträgt. Das zweite Exempel durchsucht die Spalte info nach Begriffen, die das Wort Kabel enthalten. Der dritte Aufruf durchsucht dieselbe Spalte, wobei der Wert allerdings mit dem Wort USB beginnen muss. Der führende SQL-Platzhalter % entfällt daher. Beim letzten Beispiel muss der Wert der Spalte gtin exakt dem Suchbegriff entsprechen. Das benötigen Sie in dieser Form auch für Änderungen eines einzelnen Datensatzes.
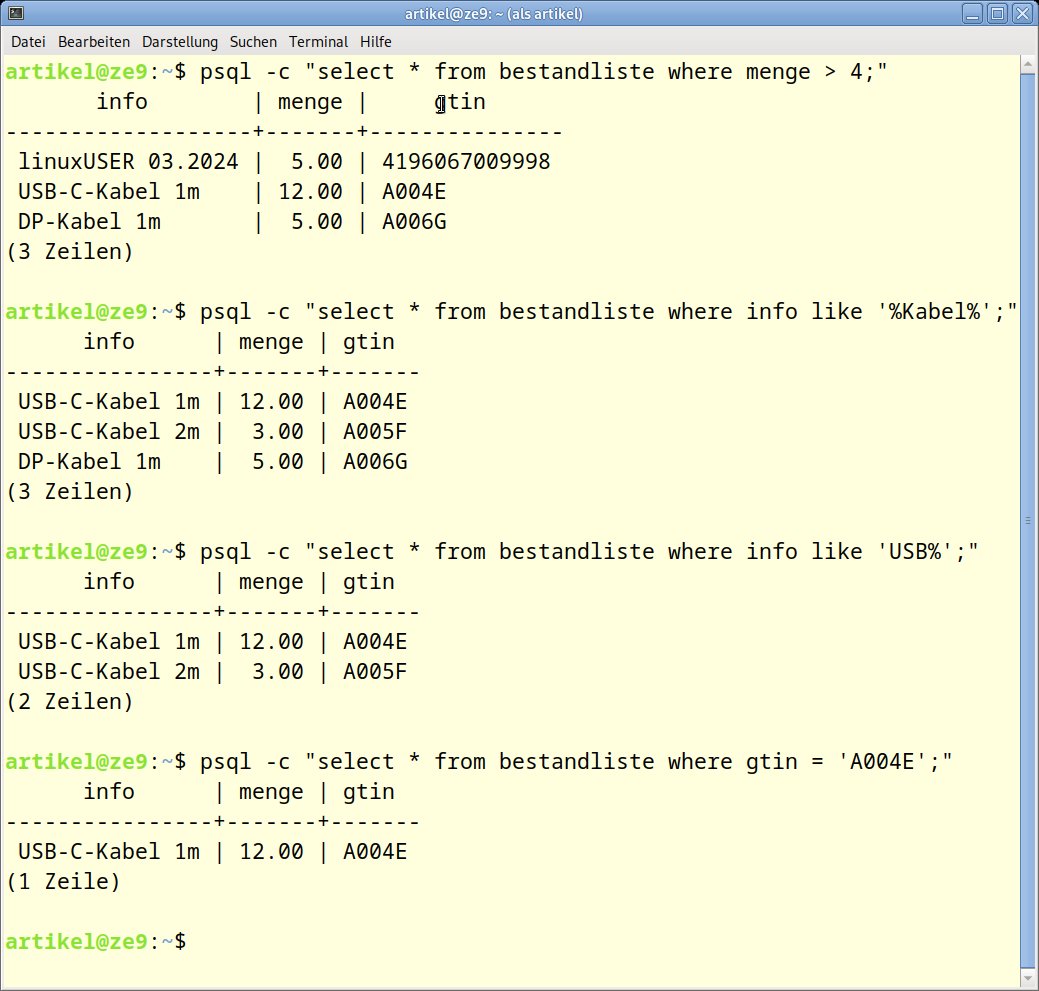
Abbildung 5: Datenabfrage mit eingrenzender Suche.
Ein Beispiel einer interaktiven Abfrage für genau einen Datensatz zeigt Listing 4. Es gibt bei der Shell-Programmierung ja zwei Methoden, um Variablen durch Benutzereingaben zu belegen: als Positionsparameter ($1 bis $9) oder per read-Eingabe. Im Listing sehen Sie die Kombination beider Möglichkeiten: Schnelltipper geben den Suchbegriff gleich beim Aufruf ein, ansonsten fragt das Skript noch einmal nach (Abbildung 6). Anstelle der Tastatureingabe könnten Sie auch einen Barcodeleser oder 2D-Scanner verwenden.
Listing 4
abfra1.sh
#! /bin/bash
sube=$(echo $1)
# Wenn $1 leer, dann ...
if [ -z "$1" ]; then
read -p "GTIN: " sube
if [ -z "$sube" ]; then
echo "Keine Eingabe - Abbruch"
exit
fi
fi
psql -t -x -P border=3 -c "select info, menge from bestandliste where gtin='$sube';"
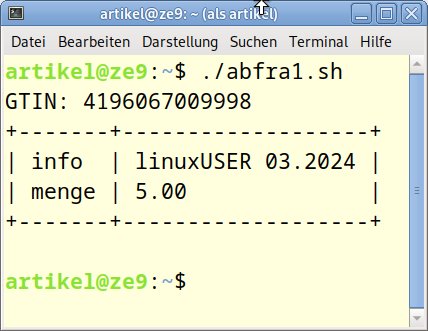
Abbildung 6: Der Ablauf beim Ausführen von abfra1.sh.
Dieselbe Abfrage können Sie auch als SQL-Skript innerhalb von Psql ausführen. Besonders in Fällen, die eine Benutzeranmeldung an der Datenbank erfordern, ist dieser Weg vorteilhafter. In Listing 5 (abfra1.sql) finden Sie die Anweisungen dazu, Abbildung 7 zeigt den Ablauf. Sie rufen die Datei innerhalb einer Psql-Sitzung mittels \i abfra1.sql auf oder verwenden den Befehl psql -f abfra1.sql.
Listing 5
abfra1.sql
\pset tuples_only on \pset expanded on \pset border 2 \pset linestyle unicode \prompt 'GTIN: ' sube \echo Suchergebnis zu :sube select info, menge from bestandliste where gtin=:'sube';
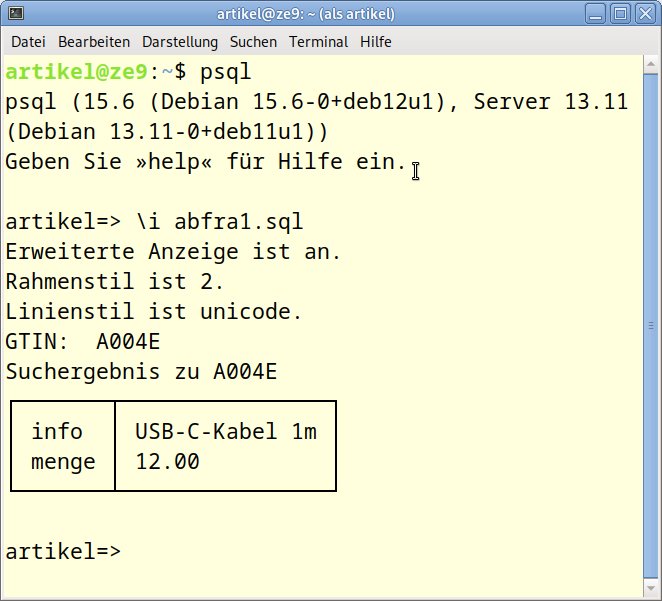
Abbildung 7: Ablauf von abfra1.sql.
Auswahl per Shell
Um ein Etikett zu drucken oder eine Änderung an den Daten vorzunehmen, müssen Sie aus einem listenartigen Suchergebnis einen einzelnen Datensatz auswählen. Mithilfe von Smenu [3] lösen Sie diese Aufgabe in einem Shell-Skript (abfra2.sh, Listing 6) auf übersichtliche Art. Den Ablauf mit der Darstellung des Ergebnisses finden Sie in Abbildung 8.
Listing 6
abfra2.sh
#! /bin/bash
sube=$(echo $1)
# Wenn $1 leer, dann ...
if [ -z "$1" ]; then
read -p "Suchbegriff: " sube
if [ -z "$sube" ]; then
echo "Keine Eingabe - Abbruch"
exit
fi
fi
# Datensatz auswählen
dwahl=$(psql -t -A -c "select gtin, info from artikel where info like '%$sube%';" | smenu -m "Datensatz auswählen" -n 10 -c)
# gtin aus Ergebnisstring herausnehmen
gtin=$(echo $dwahl | cut -d \| -f1)
# Einzelansicht
psql -t -x -P border=3 -P linestyle=unicode -c "select gtin, info, menge from bestandliste where gtin='$gtin';"
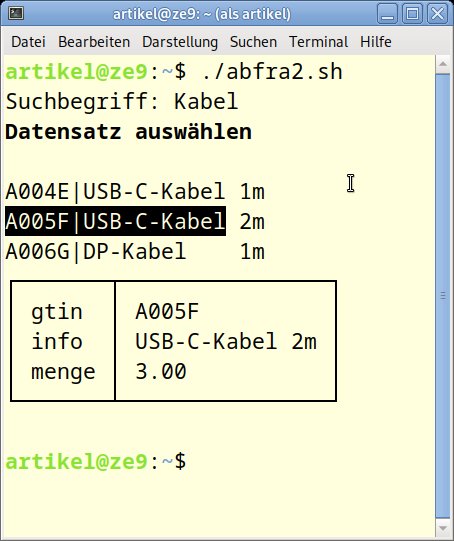
Abbildung 8: Der Ablauf des Skripts abfra2.sh.
Als Ergebnis der Auswahl soll die eindeutige Kennzeichnung des gewünschten Datensatzes hervorgehen, in unserem Beispiel also der Inhalt von gtin. Der Aufruf von Psql erfolgt mit der Option -A: Die Ausgabezeilen werden zusammengeschoben, die Feldtrenner sitzen bündig. Das ist für die Übergabe an Smenu notwendig, das die konkrete Datensatzauswahl ermöglicht.
Bei Smenu setzen Sie die Überschrift mit der Option -m "Text". Mit dem Parameter -n 10 bietet Smenu maximal 10 Zeilen an, mit den Pfeiltasten nach oben und unten können Sie aber aus beliebig vielen Zeilen wählen. Den spaltenweisen Modus aktiviert der Schalter -c.
Im nächsten Schritt erweitern wir das Skript um Funktionen zum Ändern und Löschen der ausgewählten Daten.
Neue Datensätze erfassen
Beim Erfassen neuer Datensätze ergänzt man die Dateneingabe als solche um möglichst viele Plausibilitätsprüfungen. Das Entfernen verbotener Zeichen und das Umstellen von Zahlen- und Datumsformaten beugt syntaktisch fehlerhaften Eingaben vor.
In unserem Beispiel gilt es, einen Mengenartikel (“Lötzinn fein”) mit einer Gewichtsangabe (in Kilogramm) zu erfassen. Dabei entschärft eine Skriptzeile das Problem der unterschiedlichen Dezimaltrenner, alle Werte für menge werden mit einem Punkt als Trennzeichen erfasst. Damit umgeht man das Problem, dass bei der Ausgabe im CSV-Format das Komma als Dezimal- und als Feldtrenner eine inkonsistente Datei verursacht, die sich nicht weiterverarbeiten lässt. Das Datenerfassungsskript eingabe.sh finden Sie in Listing 7, seine Ausführung zeigt Abbildung 9.
Listing 7
eingabe.sh
#! /bin/bash
while true; do
clear
echo "Dateneingabe (Abbruch mit leerer Eingabe bei GTIN)"
echo ""
read -p " GTIN: " gtin
# Plausi: Leere GTIN unzulässig, Abbruch
if [ -z "$gtin" ]; then
echo "Leere GTIN unzulässig! ABBRUCH!"
exit
fi
read -p " INFO: " info
read -p "Menge: " menge
# Komma -> Punkt
menge=$(echo $menge | tr \, \.)
# Soll das in die Tabelle geschrieben werden?
read -p "Erfassen (*) " we
if [ "$we" = "*" ]; then
psql -c "insert into artikel values ('$info','$gtin');"
psql -c "insert into bestand values ('$gtin',$menge);"
fi
echo "Erfasster Datensatz:"
psql -t -x -P border=3 -P linestyle=unicode -c "select gtin, info, menge from bestandliste where gtin='$gtin';"
sleep 3
done
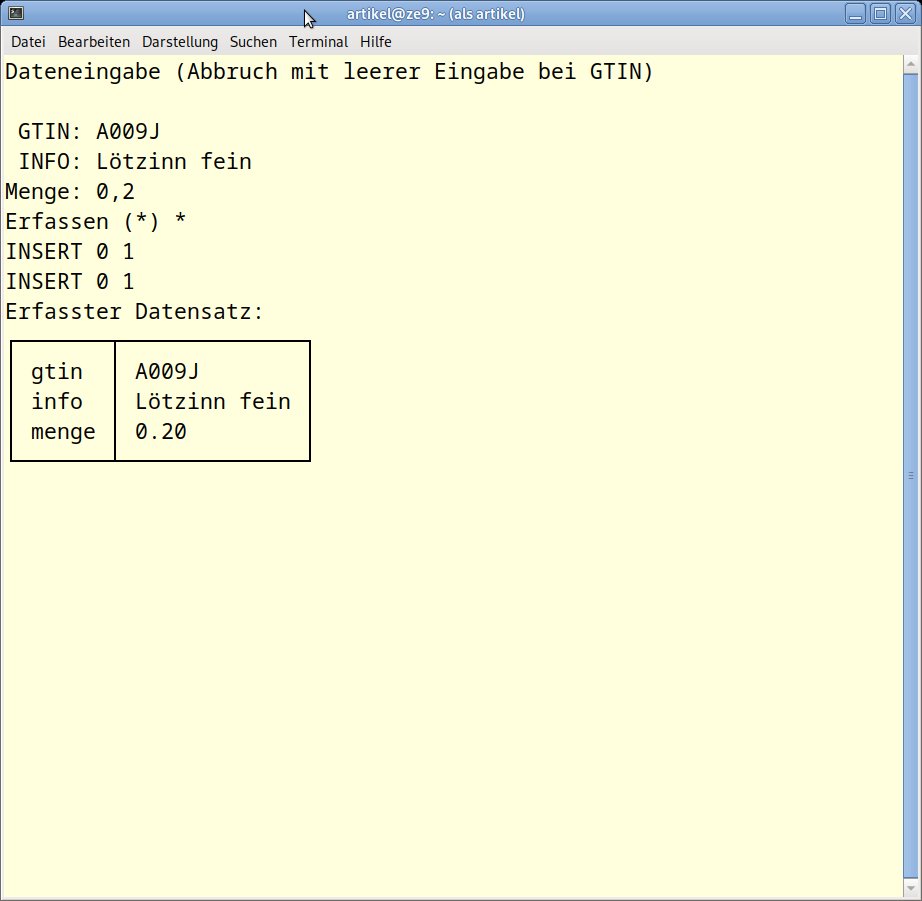
Abbildung 9: Der Ablauf einer Datenerfassung via eingabe.sh.
Datensätze bearbeiten
Auch Änderungen in Datensätzen gelingen per Shell-Skript – zumindest mittlerweile: Vor einiger Zeit haben die Entwickler am read-Kommando der Bash Erweiterungen vorgenommen, sodass man damit den Wert einer Variablen editieren kann. Dazu muss die Variable in Anführungszeichen stehen, sodass die Shell den Variableninhalt auch dann als Zeichenkette erkennt, wenn sich Leerzeichen darin befinden (Listing 8, bearbeiten.sh).
Gerade bei Bearbeitungsfunktionen können Sie problemlos tabellenübergreifend, ja sogar datenbankübergreifend in einem Shell-Skript arbeiten. Das Zurückspeichern eines Werts in die Datenbanktabelle bereitet allerdings hinsichtlich des Feldtyps Probleme. Eine Zeichenkette wird ja in Hochkommas (') eingeschlossen, ein numerischer Wert dagegen nicht. Es gilt also, die Tabellenstruktur nach dem Feldtyp zu befragen. Bei unserem recht minimalistischen Beispiel erscheint das ein wenig überkandidelt, vor allem, weil nur ein einziger Datentyp vorliegt. Das Beispiel soll Ihnen aber als Grundlage für eigene Lösungen dienen und zeigt deshalb den grundsätzlichen Weg auf (Abbildung 10).
Listing 8
bearbeiten.sh
#! /bin/bash
sube=$(echo $1)
# Wenn $1 leer, dann ...
if [ -z "$1" ]; then
read -p "Suchbegriff: " sube
if [ -z "$sube" ]; then
echo "Keine Eingabe - Abbruch"
exit
fi
fi
# Datensatz auswählen
dwahl=$(psql -t -A -c "select gtin, info from artikel where info like '%$sube%';" | smenu -m "Datensatz auswählen" -n 10 -c)
# gtin aus Ergebnisstring herausnehmen
gtin=$(echo $dwahl | cut -d \| -f1)
# Zu bearbeitende Tabellenspalte auswählen
feld=$(psql -t -x -A -c "select gtin, info from artikel where gtin='$gtin';" |
smenu -m "Zeile für Änderung auswählen" -n 10 -c | cut -d \| -f1)
# Belegen Variable für die Änderung
feldwert=$(psql -t -c "select $feld from artikel where gtin='$gtin';")
read -ei "$feldwert" -p "Ändern $feld: " feldwert
read -p "Änderung eintragen (*): " we1
if [ "$we1" = "*" ]; then
# Feldtyp ermitteln
feldtyp=$(psql -c "\d artikel;" | grep $feld | cut -d \| -f2 | tr -d [:blank:])
# Feldtyp text
if [ "$feldtyp" = "text" ]; then
psql -c "update artikel set $feld='$feldwert' where gtin='$gtin';"
fi
# Feldtyp numerisch
if [ "$feldtyp" = "numeric(10,2)" ]; then
psql -c "update artikel set $feld=$feldwert where gtin='$gtin';"
fi
# Einzelansicht
psql -t -x -P border=3 -P linestyle=unicode -c "select gtin, info, menge from bestandliste where gtin='$gtin';"
fi
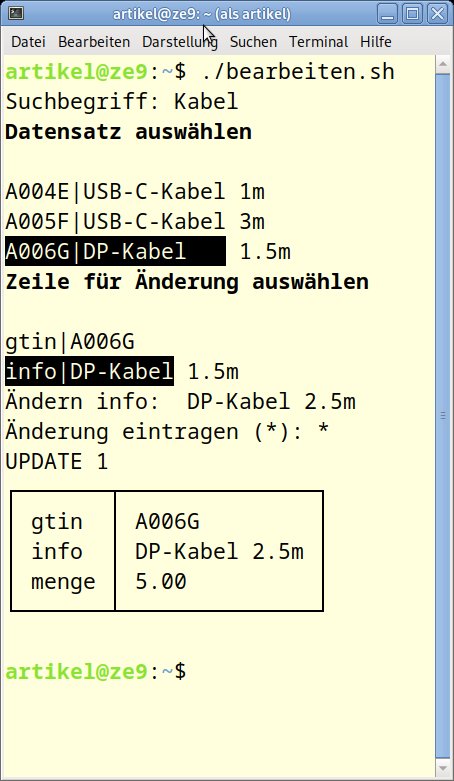
Abbildung 10: Per bearbeiten.sh ändern Sie Einträge.
Fallen Rechenarbeiten an, überlassen Sie diese dem Shell-Rechner Bc [4] oder auch dem Datenbanksystem selbst. Die Shell selbst hält für Rechenoperationen nur sehr begrenzte Möglichkeiten bereit. Das Skript bestand.sh (Listing 9) aktualisiert den Wert der Spalte menge in der Tabelle bestand. Der Ablauf beginnt wie bei fast allen Beispielen mit der Datensatzsuche. Anschließend geben Sie eine Zugangsmenge ohne Vorzeichen ein, einen Abgang kennzeichnen Sie mit einem führenden Minus. Das Skript berechnet die neue menge und ändert den Tabelleneintrag passend. Abbildung 11 zeigt den Buchungsablauf.
Listing 9
bestand.sh
#! /bin/bash
sube=$(echo $1)
# Wenn $1 leer, dann ...
if [ -z "$1" ]; then
read -p "Suchbegriff oder GTIN: " sube
if [ -z "$sube" ]; then
echo "Keine Eingabe - Abbruch"
exit
fi
fi
# Datensatz auswählen
dwahl=$(psql -t -A -c "select gtin, info from artikel where info like '%$sube%' or gtin='$sube';" | smenu -m "Datensatz auswählen" -n 10 -c)
# gtin aus Ergebnisstring herausnehmen
gtin=$(echo $dwahl | cut -d \| -f1)
# Einzelansicht
psql -t -x -P border=3 -P linestyle=unicode -c "select gtin, info, menge from bestandliste where gtin='$gtin';"
# Bestand abfragen
menge=$(psql -t -c "select menge from bestand where gtin='$gtin';")
# Bestand ändern
read -p "Zugang/Abgang: " zuab
# Inhalt darf nicht leer sein!
if [ -z "$zuab" ]; then
echo "Leerer Eintrag, ABBRUCH!"
exit
fi
# Punkt/Komma
zuab=$(echo $zuab | tr \, \.)
# Berechnung
menge=$(psql -t -c "select $menge + $zuab;")
echo "Bestand neu: $menge"
# Soll das gebucht werden?
read -p "Buchen (*) " we
if [ "$we" = "*" ]; then
psql -c "update bestand set menge=$menge where gtin='$gtin';"
fi
# Einzelansicht
psql -t -x -P border=3 -P linestyle=unicode -c "select gtin, info, menge from bestandliste where gtin='$gtin';"
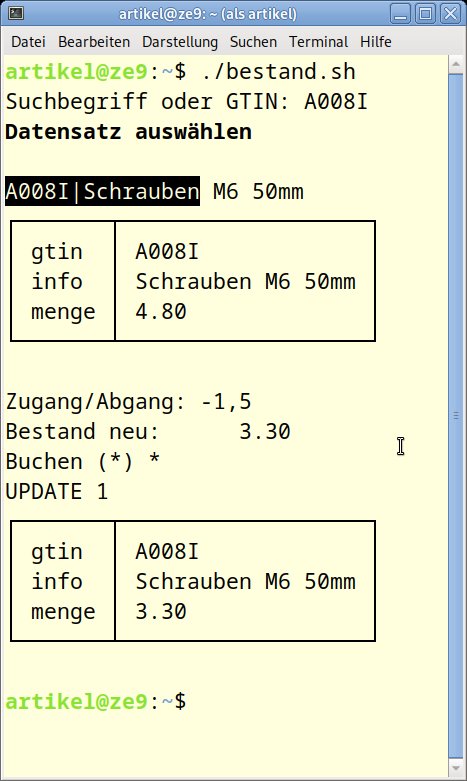
Abbildung 11: Buchungen erledigen Sie mit dem Skript bestand.sh.
Datensätze löschen
Das Löschen von Datensätzen gehört zu den gefährlichsten Arbeiten an Datenbanken. Man muss exakt angeben, was aus der Datenbank entfernt werden soll. Das Skript wechdamit.sh (Listing 10) schreitet daher erst nach einer Sicherheitsabfrage zur Tat.
Im von uns verwendeten Beispiel betrifft das Löschen eines Artikels zwei Tabellen. Fehlt der Artikel lediglich in einer Tabelle, taucht er zwar im View nicht mehr auf, bleibt aber in der anderen Tabelle präsent. Abbildung 12 zeigt den Löschvorgang. Für die Bestätigung zum Löschen verwenden wir hier das Ausrufezeichen (!), für das man bewusst zwei Tasten drücken muss, statt des auf dem Ziffernblock stets griffbereiten Asterisk (*) wie bei den anderen Beispielskripten. Das erschwert ein versehentliches, voreiliges Löschen.
Listing 10
wechdamit.sh
#! /bin/bash
sube=$(echo $1)
# Wenn $1 leer, dann ...
if [ -z "$1" ]; then
read -p "Suchbegriff oder GTIN: " sube
if [ -z "$sube" ]; then
echo "Keine Eingabe - Abbruch"
exit
fi
fi
# Datensatz auswählen
dwahl=$(psql -t -A -c "select gtin, info from artikel where info like '%$sube%' or gtin='$sube';" | smenu -m "Datensatz auswählen" -n 10 -c)
# gtin aus Ergebnisstring herausnehmen
gtin=$(echo $dwahl | cut -d \| -f1)
# Einzelansicht
psql -t -x -P border=3 -P linestyle=unicode -c "select gtin, info, menge from bestandliste where gtin='$gtin';"
# Letzte Frage und löschen
read -p "Soll dieser Datensatz gelöscht werden (!) " wech
if [ "$wech" = "!" ]; then
psql -c "delete from artikel where gtin='$gtin';"
a=$(echo $?)
psql -c "delete from bestand where gtin='$gtin';"
b=$(echo $?)
if [ $a -eq 0 -a $b -eq 0 ]; then
echo "Daten erfolgreich gelöscht"
fi
fi
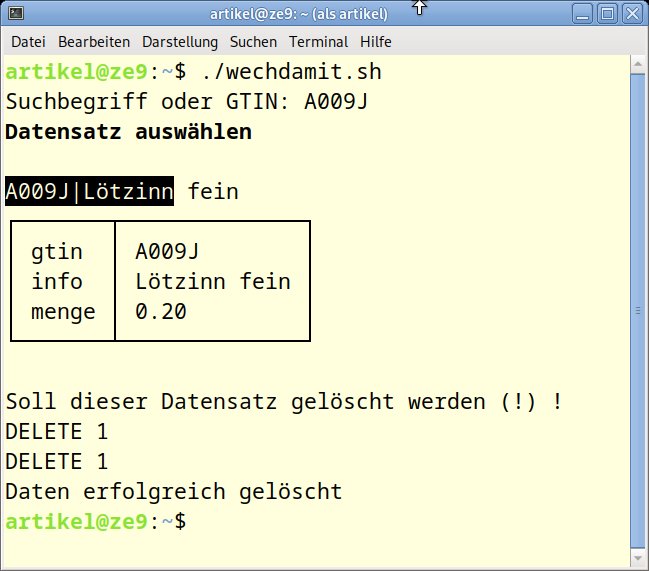
Abbildung 12: Löschen eines Datensatzes mit wechdamit.sh.
Fazit
Mit gängigen Shell-Mitteln und dem PostgreSQL-Datenbank-Client Psql schaffen Sie sich in kurzer Zeit handliche Hilfsmittel für die Arbeit mit Datenbanken. Mit den übersichtlichen Shell-Skripten kommt jeder Anwender ohne langes Einarbeiten zurecht. (jlu)
Der Autor
Harald Zisler beschäftigt sich seit den frühen 1990er-Jahren mit FreeBSD und Linux. Zu Technik- und EDV-Themen verfasst er Zeitschriftenbeiträge und Bücher.
Infos
-
PostgreSQL: https://www.postgresql.org
-
Smenu: Harald Zisler, “Keine Qual der Wahl”, LU 06/2017, S. 84, https://www.linux-community.de/38772




