

Die grundlegenden Konzepte der regulären Ausdrücke haben Sie bereits in der letzten Folge kennengelernt. Damit kommen Sie über das klassische Suchen und Ersetzen weit hinaus. Diesmal machen wir Sie mit den erweiterten Möglichkeiten vertraut.
Ein Aspekt der regulären Ausdrücke, der mich anfangs immer wieder stolpern ließ, ist die Indexierung von Gruppen. Stellen Sie sich beispielsweise vor, Sie bekommen eine CSV-Datei, in der jede Zeile einem Datensatz entspricht, wobei Strichpunkte die einzelnen Attribute trennen (Listing 1).
Listing 1
CSV-Daten
Aspect;Alain;Frankreich;Physik;2022 Clauser;John;Vereinigte Staaten;Physik;2022 Zeilinger;Anton;Österreich;Physik;2022 Agostini;Pierre;Frankreich;Physik;2023 Krausz;Ferenc;Ungarn;Physik;2023 L'Huillier;Anne;Frankreich;Physik;2023
Ich bereite die einzelnen Wissenschaftler und Wissenschaftlerinnen aus dem Listing mithilfe von Gruppen zum Weiterverarbeiten auf. Als Regex dafür könnte der Ausdruck aus der ersten Zeile von Listing 2 dienen. Abbildung 1 zeigt die Ergebnismenge, wenn ich über die Python-Funktion findall() sämtliche Fundstellen ausgeben lasse. Der Regex lässt sich nicht übermäßig gut lesen, deswegen passe ich ihn etwas an (Listing 2, Zeile 2).
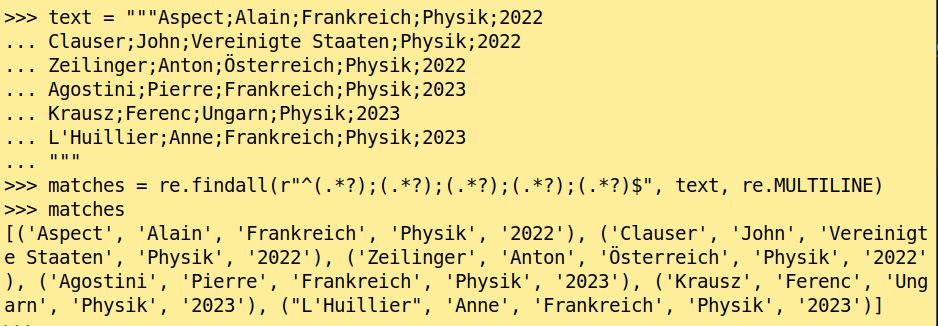
Abbildung 1: Mithilfe von findall() lasse ich mir Named Groups ausgeben.
Listing 2
Regex-Varianten
^(.*?);(.*?);(.*?);(.*?);(.*?)$
^(.*?);(.*?);(.*?);(Physik|Chemie|Medizin|Literatur|Wirtschaftswissenschaften|Frieden);(\d{4})$
^(?<Name>.*?);(?<Vorname>.*?);(?<Land>.*?);(Physik|Chemie|Medizin|Literatur|Wirtschaftswissenschaften|Frieden);(\d{4})$
^(\w+(?# Name));(\w+(?# Vorname));(\w+(?# Land));(\w+(?# Fach));(\d+(?# Jahr))$
Inzwischen ist zumindest klar, was man in den Gruppen 4 und 5 zu erwarten hat. Spätestens bei den Ländern würden Optionen wie die für die Preiskategorien ausufern. Abhilfe schaffen in solchen Fällen Named Groups, also benannte Gruppen. Die Syntax gestaltet sich dabei für Regex-Verhältnisse einigermaßen intuitiv: (?<Name>.*). Innerhalb der Gruppe vergeben Sie den Namen über ein Fragezeichen, gefolgt vom Namen in spitzen Klammern. Der Beispiel-Regex zu Listing 1 liest sich mit Named Groups schon deutlich leichter (Listing 2, Zeile 3).
Wie Sie in Python diese benannten Gruppen weiterverarbeiten, demonstriert Abbildung 2. Ein Hinweis noch: Die Syntax für Named Groups fällt von Programmiersprache zu Programmiersprache unterschiedlich aus. Darum lohnt es sich, einen Blick in die entsprechende Dokumentation zu werfen.
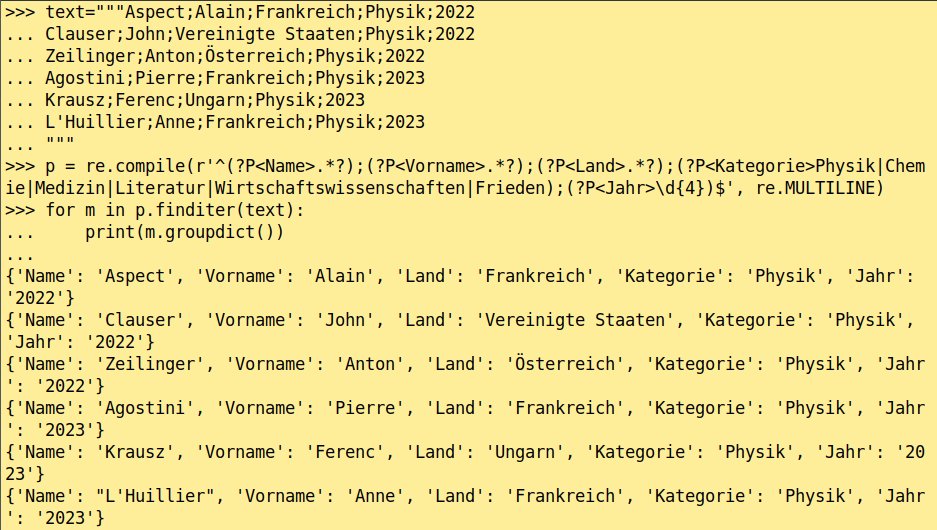
Abbildung 2: Die Named Groups lassen sich nach dem Ausgeben in Python weiterverarbeiten.
Kommentare
Code sollten Sie stets an den relevanten Stellen kommentieren. Über das Thema Codedokumentation ließen sich sicher mehrere Artikel schreiben. Gerade bei regulären Ausdrücken, die für sich allein schon oft sehr schwer zu lesen sind, erweisen sich Kommentare als überaus hilfreich. Einige Programmiersprachen kennen Inline-Kommentare, andere End-of-Line-Kommentare (EoL), und bei wieder anderen müssen Sie sich etwas Eigenes ausdenken. Im obigen Beispiel könnten Sie die Capturing Groups etwa so kommentieren wie in Zeile 4 von Listing 2.
Das wirkt sich im konkreten Fall tatsächlich weniger leserfreundlich aus, als einfach eine Named Group zu verwenden. Ein schönes Beispiel für EoL-Kommentare liefert das E-Book “Dive Into Python” [1]. Die Programmiersprache kennt Verbose Regular Expressions, die Whitespace ignorieren. Listing 3 zeigt, wie EoL-Kommentare in Python funktionieren. Wie aus verschiedenen Skriptsprachen bekannt, leiten Sie sie mit einem Hashtag # ein, ab dem alles bis zum Zeilenende keinerlei Rolle mehr spielt.
Mehrzeilige Strings begrenzen Sie in Python durch jeweils drei einfache oder doppelte Anführungszeichen. Ab der zweiten Zeile ergänzt in Listing 3 ein EoL-Kommentar jede Codezeile. Leerzeichen und Zeilenumbrüche ignoriert Python komplett. Wollte ich hier an einer bestimmten Stelle Whitespace im Pattern fordern, müsste ich ihn per Backslash \ escapen. In der letzten Zeile des Listings startet eine Regex-Suche, die das Muster pattern verwendet und im String M danach fahndet. Das Flag re.VERBOSE indiziert, dass der Ausdruck Kommentare enthält und Whitespace nicht berücksichtigt wird.
Listing 3
Verbose Regex
>>> pattern = '''
^ # beginning of string
M{0,3} # thousands: 0 to 3 Ms
(CM|CD|D?C{0,3}) # hundreds: 900 (CM), 400 (CD), 0-300 (0 to 3 Cs),
# or 500-800 (D, followed by 0 to 3 Cs)
(XC|XL|L?X{0,3}) # tens: 90 (XC), 40 (XL), 0-30 (0 to 3 Xs),
# or 50-80 (L, followed by 0 to 3 Xs)
(IX|IV|V?I{0,3}) # ones: 9 (IX), 4 (IV), 0-3 (0 to 3 Is),
# or 5-8 (V, followed by 0 to 3 Is)
$ # end of string
'''
>>> re.search(pattern, 'M', re.VERBOSE)
Wo ist mein Kollege?
Es gibt eine Binsenweisheit zu Regex: XML-Daten – und dazu gehören ebenso Webseiten nach XHTML- und HTML5-Standard – parst man nicht mit regulären Ausdrücken. Das hat recht simple Gründe – etwa, dass es im Wesen der XML-Sprachen liegt, Elemente nahezu beliebig tief zu verschachteln. Um einen Eindruck davon zu bekommen, werfen Sie einfach einen Blick in den Quelltext einer Webseite: Mit regulären Ausdrücken lässt sich eine solche Struktur praktisch nicht abbilden.
Manchmal brauchen Sie aber nur kleine Ausschnitte. Vielleicht interessiert Sie auf einer Webseite nur ein ganz bestimmter Inhalt, zum Beispiel die aktuelle Version einer Software, die etwa über eine ganz bestimmte id zu erreichen ist:
<div id="release">25.0.3.1</div>
Ungünstigerweise verwenden manche hier ein Div- und andere ein Span-Element – man kann sich also nicht auf die Eindeutigkeit des umschließenden Elements verlassen. Dennoch findet sich zügig ein Ausdruck, bei dem ich nicht auf das Div-Element festgelegt bin (Listing 4, erste Zeile).
Listing 4
Webseiten durchsuchen
<\w+ id="release">(?P<content>.*?)<\/\w*?> <(\w+)[^>]*>(?P<content>.*)<\/\1>
Die Sache hat allerdings einen Haken: Die umschließenden Elemente müssen nicht notwendigerweise zusammengehören. \w+ bedeutet lediglich, dass hier Word-Characters vorkommen dürfen, also alphabetische Zeichen. Das öffnende und schließende Element können sich aber unterscheiden. Das wächst sich dann zum Problem aus, wenn beispielsweise jemand beschließt, dass es doch nett wäre, die Major-Release-Nummer fett auszugeben. Dann steht im Quelltext:
<div id="release"><b>25</b>.0.3.1</div>
Um das schließende Div-Element zu finden, brauche ich eine Back Reference, also einen Rückbezug. Das funktioniert, indem ich für das entsprechende Teilmuster eine Gruppe einführe. Gruppen sind nummeriert, somit bildet \1 einen Rückbezug zur ersten und \9 einen zur neunten Gruppe. \0 bezieht sich üblicherweise auf den gesamten Treffer.
Mit einer solchen Back-Reference kann ich einen Ausdruck bauen, der ebenjenes schließende Div-Element erkennt. Sie finden ihn in der zweiten Zeile von Listing 4. Auch hier dient als Elementname eine Folge von mindestens einem alphabetischen Zeichen, die als erste Gruppe vermerkt wird. Genau auf diese Gruppe passt \1 am Ende. Das öffnende Element darf zudem noch Attribute enthalten wie id="asdf" oder class="emphasized". Die Zeichenklasse [^>]* limitiert lediglich dahingehend, dass bis auf die schließende spitze Klammer alle Zeichen beliebig oft auftauchen dürfen. Die zweite Gruppe, die den gewünschten Inhalt enthält, bekommt den Namen content.
Wo bin ich?
Es gibt vier Varianten, bestimmte Zeichen um den eigentlichen Such-String herum zu fordern oder zu negieren (siehe Tabelle “Lookaround”). Konkret blickt Lookahead hinter den Such-String, Lookbehind davor. Beide Blickrichtungen gibt es sowohl in positiver als auch in negativer Form. Die Betonung liegt hier tatsächlich auf “Blick”, denn Lookaround bewegt den Cursor nicht durch die Zeichenkette, der Ausdruck wird auch nicht als Teil des Match-Ergebnisses geliefert.
|
Ausdruck |
Typ |
Anmerkung |
|---|---|---|
|
|
(Pos.) Lookahead |
Fordert, dass sich hinter der aktuellen Position der String |
|
|
(Pos.) Lookbehind |
Fordert, dass sich vor der aktuellen Position der String |
|
|
Negative Lookahead |
Stellt sicher, dass hinter der aktuellen Position nicht |
|
|
Negative Lookbehind |
Stellt sicher, dass vor der aktuellen Position nicht |
Möchten Sie aus Listing 1 ermitteln, welche Preise nach Frankreich gingen, klappt das mit einem positiven Lookbehind wie (?<=Frankreich;)(\w+). Der Ausdruck liefert drei Fundstellen von Physik. Um herauszufinden, in welche Länder das Nobel-Komitee den Preis für Physik verliehen hat, benötigen Sie den positiven Lookahead ([\w ]+)(?=;Physik). Erwartungsgemäß erhalten Sie als Ergebnis Frankreich, Vereinigte Staaten, Österreich und Ungarn, wobei Frankreich mehrfach vorkommt.
Interessiert Sie, welche Preise in Physik nicht ins Jahr 2022 gehören, hilft der Ausdruck (Physik)(?!;2022) weiter. Abschließend ermitteln Sie noch die Preise in Physik, die nicht nach Frankreich gingen. Hier passt der Ausdruck (?<!Frankreich;)(Physik).
Fazit
Das Erstellen von regulären Ausdrücken muss nicht notwendigerweise zu traumatischen Erlebnissen führen. Regexe versetzen Sie in die Lage, sehr elegante Abfragen zu formulieren, die weit über einfaches Suchen und Ersetzen hinausgehen. Umfangreiche Änderungen an Textdaten lassen sich über das Bilden von Gruppen erreichen, sei es nun in einem Shell-Skript mittels Sed oder in erweiterten Editoren wie Vim, Kate oder Emacs. Angesichts der Omnipräsenz regulärer Ausdrücke kann ich jeder Leserin und jedem Leser nur ans Herz legen, sich zumindest Grundkenntnisse im Umgang mit Regulären Ausdrücken anzueignen. (csi)
Infos
-
“Dive Into Python”: https://diveintopython3.problemsolving.io/regular-expressions.html#verbosere




