

Umleitungen, auf der Shell Pipes genannt, bieten eine überraschende Vielfalt an Möglichkeiten.
Sobald unter Linux ein Prozess startet, bekommt er automatisch drei Kanäle zugewiesen. Diese lassen sich über die vom System zugewiesenen Kanäle ansprechen und besitzen jeweils einen Ursprungs- und einen Endpunkt. Kanal 0 (STDIN) kommt beim Einlesen von Daten zum Zug, Kanal 1 (STDOUT) dient der Ausgabe von Daten, und Kanal 2 (STDERR) gibt mögliche Fehlermeldungen aus. Üblicherweise zeigt Kanal 2 auf dasselbe Gerät wie Kanal 1 (Abbildung 1).
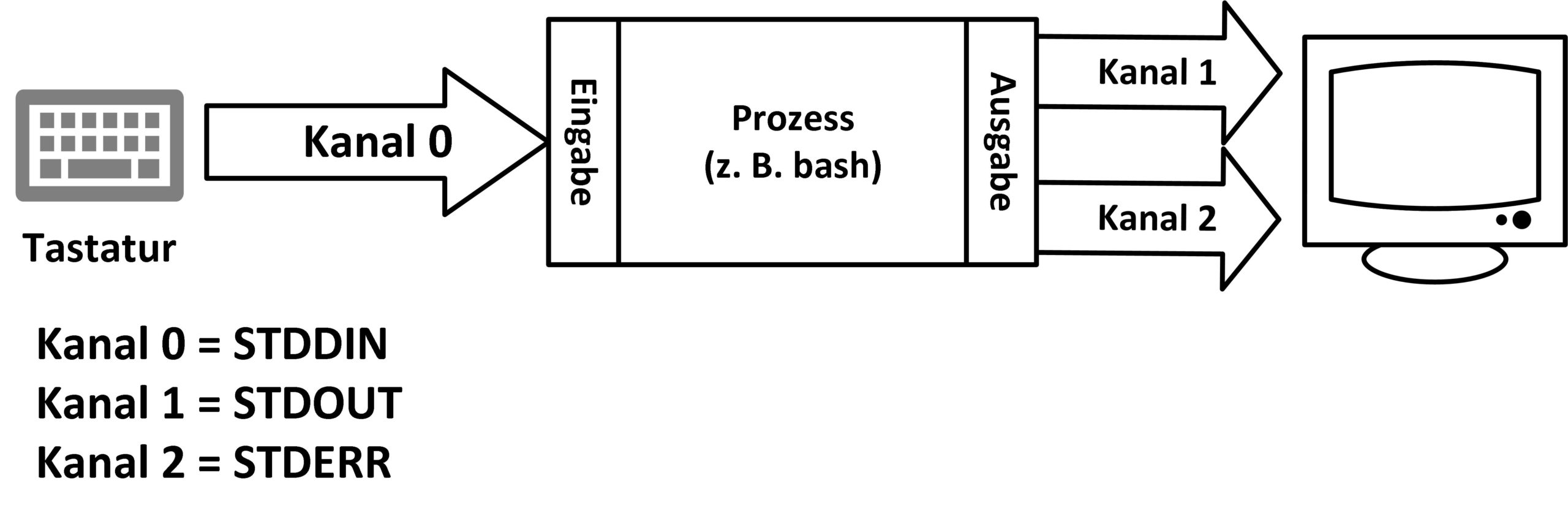
Abbildung 1: Die Shell liest von der Tastatur die Eingaben ein (STDIN, Kanal 0) und die Ergebnisse auf dem Bildschirm aus (STDOUT, Kanal 1). Fehlermeldungen erscheinen via STDERR (Kanal 2).
Die Shell selbst stellt ebenfalls einen Unix-Prozess dar und verwendet ebenso diese drei Kanäle. Jeder davon lässt sich über einen File-Deskriptor ansprechen, der die jeweilige Kanalnummer repräsentiert. Unter Linux finden sich die verwendeten Kanäle im Verzeichnis /proc/PID/fd, wobei PID der Prozess-ID des zu untersuchenden Prozesses entspricht.
Die unter Linux am häufigsten verwendete Shell Bash stellt zusätzlich noch den Kanal 255 bereit. Um beim Umlenken dieses Kanals weiterhin die Job-Kontrolle zu behalten, setzt ihn die Shell beim Start auf STDERR.
Der Artikel bezieht sich im Folgenden in weiten Teilen auf die Skripte funktionen und read.awk, die Sie im Download-Bereich zu diesem Artikel finden.
Umlenkung
Eine Umlenkung liest Kanäle eines Prozesses von einer anderen Quelle ein oder gibt sie auf ein anderes Ziel aus. Die wahrscheinlich am häufigsten genutzten Anwendungsfälle betreffen das Suchen einer Zeichenkette aus dem Fehlerkanal und das Umleiten von Fehlermeldungen in das Device /dev/null.
Der Aufruf aus der ersten Zeile von Listing 1 versucht, das nicht existente Verzeichnis /dev/pseudo/ anzuzeigen, was eine Fehlermeldung auf Kanal 2 erzeugt. Der Aufruf aus der letzten Zeile ergänzt das Kommando um eine Umleitung von Kanal 2 nach /dev/null. Die Fehlermeldung erscheint nun nicht mehr auf dem Bildschirm, der Rückgabewert des Kommandos bleibt jedoch unverändert.
Listing 1
Rückgabe umleiten
# ls -ld /dev/pseudo ls: cannot access /dev/pseudo: No such file or directory # ls -ld /dev/pseudo 2>/dev/null
Pipes
Eine Pipe stellt eine besondere Art einer Datei dar, die als FIFO-Speicher zur Interprozesskommunikation dient. Wenn zum Beispiel Prozess 1 die Werte 1 Z 2 Y 3 X 4 W 5 V in eine Pipe schreibt, liest Prozess 2 diese auch so aus der Pipe aus. Linux stellt zwei Arten von Pipes bereit: anonyme und die benannte.
Anonyme Pipes dienen zum Aneinanderreihen von Kommandos, die das Pipe-Symbol (|) verbindet. Man spricht von anonymen Pipes, da der Nutzer diese zur Laufzeit üblicherweise nicht sieht. Die anonymen Pipes befinden sich wie die Standardkanäle im Verzeichnis /proc/PID/fd/. Der Aufruf einer Kommandokette generiert temporär diese Art von Pipe.
Die benannten Pipes lassen sich mit dem Kommando mkfifo im Dateisystem anlegen und bleiben so lange erhalten, bis man sie mittels rm wieder löscht. Beim Umgang mit benannten Pipes müssen Sie selbst für die entsprechende Umlenkung der Ein- und Ausgabekanäle sorgen, was bei den anonymen Pipes die Shell automatisch handhabt.
Pipes einsetzen
Als versierter Linux-User kennen Sie wahrscheinlich das Verwenden von Pipes. Das folgende Beispiel ermittelt alle Unterverzeichnisse des Verzeichnisses, in dem Sie es aufrufen, und zählt sie:
$ ls -l | grep "^d" | wc -l
138
Die Ausgabe des Aufrufs von ls führt in den Eingabekanal des Kommandos grep, dessen Ausgabe wiederum in der Eingabe des Befehls wc landet (Abbildung 2).
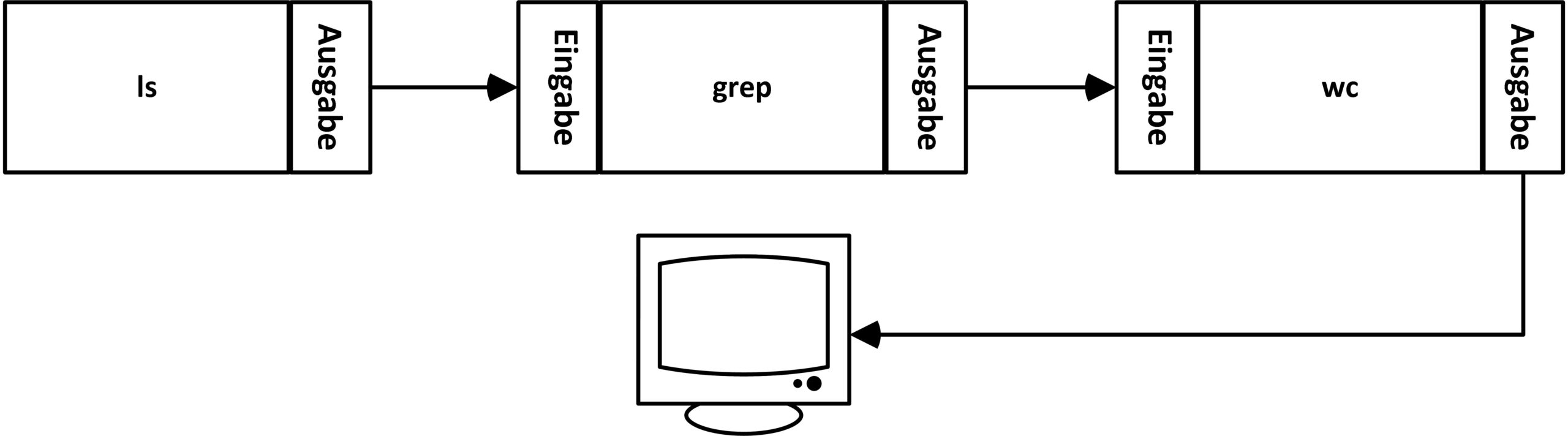
Abbildung 2: Mit Pipes lassen sich beliebig viele Kommandos miteinander verknüpfen.
Die Richtung der Umlenkung gibt bei anonymen Pipes die Shell vor. Sie erfolgt immer von links nach rechts. Der komplette Durchlauf der Kommandokette beendet alle Prozesse und hebt die Umlenkungen auf.
In manchen Aufrufen und Skripts benötigt man Pipes aber längerfristig oder für mehrere Prozesse. In diesem Fall kommen benannte Pipes zum Einsatz. Sie liegen wie andere Dateien im File-System, überstehen aber einen Reboot. Sie lassen sich von mehreren Prozessen verwenden, wobei der Datenfluss lesend und schreibend ohne Einschränkung erfolgt.
Benannte Pipes
Um eine dauerhafte Pipe zu erzeugen, verwenden Sie das Kommando mkfifo. Das Beispiel aus Listing 2 legt die Pipe /var/tmp/testpipe an. Mittels ls sehen Sie den Erfolg der Aktion. Der Marker p ganz links in der Ausgabe (Zeile 3) weist darauf hin, dass es sich um eine Pipe handelt. In diese lässt sich nun die Ausgabe eines Kommandos umlenken. Das Kommando wartet so lange mit dem Abarbeiten, bis ein anderer Prozess die Pipe ausliest (Listing 3).
Listing 2
Benannte Pipe anlegen
$ mkfifo /var/tmp/testpipe $ ls -l /var/tmp/testpipe prw-r--r-- 1 root root 0 Jan 4 23:35 /var/tmp/testpipe
Listing 3
Benannte Pipes verwenden
### Session 1: Schreiben $ echo "3.1415" >/var/tmp/testpipe ### Session 2: Lesen $ ls -l /var/tmp/testpipe prw-r--r- 1 root root 0 Jan 4 23:35 /var/tmp/testpipe $ pi=$(cat /var/tmp/testpipe) $ ls -l /var/tmp/testpipe prw-r--r- 1 root root 0 Jan 4 23:42 /var/tmp/testpipe $ echo $pi 3.1415
Sie erkennen, dass der Aufruf den Zeitstempel von 23:35 Uhr nach dem Auslesen auf 23:42 Uhr setzt. Die Größe der Datei beträgt aber nach wie vor 0 Byte, da die Pipe ja theoretisch nur Daten durchreicht. Tatsächlich stellt das Betriebssystem aber einen Puffer bereit, der jedoch in der allgemeinen Handhabung keine Rolle spielt.
Dass aus Sicht der Prozesse das Schreiben in eine Pipe erst mit dem Auslesen beginnt, lässt sich an einem einfachen Beispiel zeigen. In einer Session schreibt ein Aufruf das aktuelle Datum mit Uhrzeit in die Variable start und deren Inhalt danach in die Pipe. Im Anschluss liest er nochmals Datum und Uhrzeit und speichert sie in der Variablen ende. Deren Wert schreibt der Prozess ebenfalls sofort in die Pipe. Die zweite Session liest beide Zeilen aus der Pipe und gibt sie aus.
Um zu zeigen, dass die Ausgabe tatsächlich innerhalb kürzester Zeit geschieht, starten wir zuerst einen Testlauf ohne Umlenkung (Listing 4). Nun werden nochmals die beiden Variablen mit Zeitstempeln belegt und die Ausgaben jeweils in die Pipe geschrieben. Kurz darauf wird aus einer zweiten Session die Pipe Zeile für Zeile ausgelesen und das Ergebnis auf dem Bildschirm ausgegeben (Listing 5). Sie sehen, dass eine Differenz von etlichen Sekunden zwischen Start und Ende liegt. Die Differenz ergibt sich aus der Tatsache, dass der zweite Zeitstempel erst nach dem Lesen der ersten Zeile aus der Pipe entsteht.
Listing 4
Variablen festlegen
# start=$(date +'%H:%M:%S') ; echo $start # ende=$(date +'%H:%M:%S'); echo $ende 23:04:44 23:04:44
Listing 5
Pipe auslesen
### Terminal 1: $ start=`date +'%H:%M:%S'` ; echo $start >/var/tmp/testpipe ; ende=`date +'%H:%M:%S'` ; echo $ende >/var/tmp/testpipe ### Terminal 2: $ read start </var/tmp/testpipe ; read ende </var/tmp/testpipe ; echo "Start: $start" ; echo "Ende: $ende" Start: 23:08:40 Ende: 23:08:52
Anwendungsbeispiel
Das folgende Beispiel realisiert eine Netzwerkverbindung auf Basis benannter Pipes, die dazu dient, auf einem entfernten Rechner Kommandos auszuführen.
Der interessante Aspekt für die Kommunikation zwischen zwei Rechnern besteht darin, dass es für den lesenden oder schreibenden Prozess keine Rolle spielt, was vor oder hinter der Pipe geschieht, da sich das Lesen und Schreiben für den jeweiligen Prozess nicht ändert. Das Beispiel setzt voraus, dass zwischen den beiden verwendeten Rechnern ein Zugang ohne Passwort erfolgt, im Beispiel via SSH.
Das Kommando ssh erlaubt es, neben dem Zielrechner auch eine Kommandokette zu übergeben. Das Konstrukt baut sich dann so auf wie in der ersten Zeile von Listing 6. SSH nimmt in diesem Fall die Verbindung zum Zielsystem auf, führt die angegebenen Kommandos aus und beendet danach die Verbindung. Einfacher wäre es, eine Funktion aufzurufen, die ein auszuführendes Kommando übergeben bekommt, es auf dem anderen Rechner ausführt und die Ausgabe auf dem lokalen Bildschirm ausgibt (zweite Zeile).
Listing 6
Remote-Befehl
$ ssh [-q] Ziel "Befehl1 [; Befehl2 [;...]]" $ rcmd "Befehl1 [; Befehl2 [;...]]"
Bei rmcd handelt sich um eine Funktion aus dem Skript funktionen. Pro Rechner kommt je eine Pipe zum Senden und eine zum Empfangen zum Einsatz. Ein Prozess liest permanent die Sende-Pipe aus und lenkt die gelesenen Zeilen in einen Datenstrom, den in diesem Beispiel SSH an den entfernten Rechner schickt. Die Empfangsseite lenkt den eingehenden Datenstrom wiederum in die Empfangs-Pipe um und liest ihn dort aus. Sie verarbeitet die gelesenen Daten und schreibt das Ergebnis wiederum in die Sende-Pipe, um sie zum Ursprungsrechner zurückzusenden (Abbildung 3).
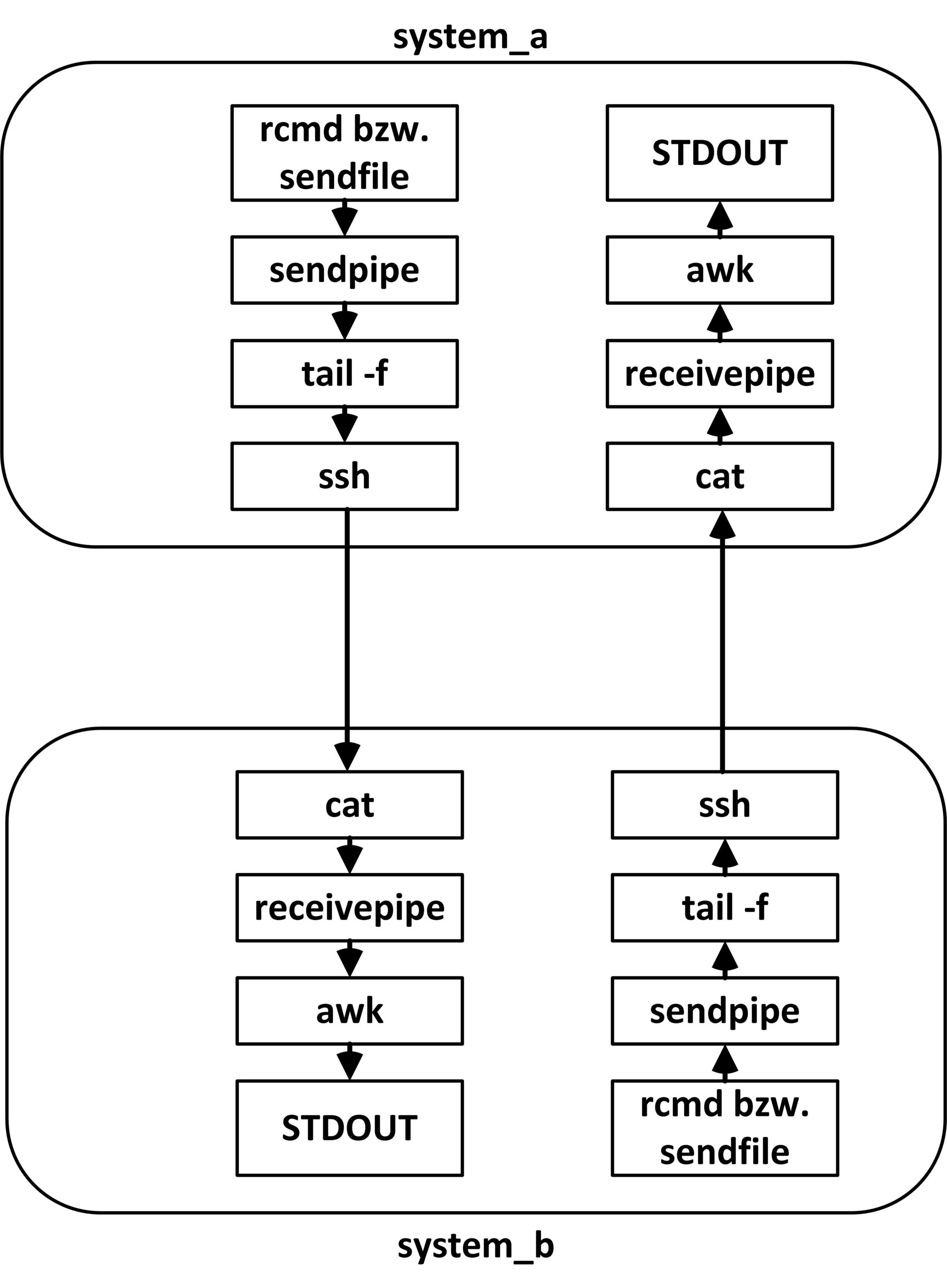
Abbildung 3: Der Aufbau zeigt die Kommunikation mit anderen Rechnern unter Zuhilfenahme von Pipes und diversen Bordwerkzeugen.
Die Kommunikation teilt sich in mehrere Bereiche auf. Im Wesentlichen geht es darum, Daten über einen Datenstrom zu empfangen, zu verarbeiten und einen entsprechenden Datenstrom zurückzusenden. Wie aber erhält man einen kontinuierlichen Datenstrom zwischen zwei Rechnern aufrecht, um darüber Kommandos und weitere Informationen zu senden?
Listener
Zum Auslesen bietet sich das Kommando tail -f an, da es sich erst auf Anweisung oder bei Empfang eines EOF beendet. Es genügt jedoch nicht, einen einzelnen Befehl umzulenken, da nach dem Abarbeiten des Kommandos ein EOF folgt. Eine Textdatei als Transportmittel zu verwenden, funktioniert ebenfalls nicht, da die Lage der Informationen sich ständig verschiebt und das Tail-Kommando keine validen Informationen mehr ausliest.
Das testen Sie, indem Sie in einer Session ein tail -f auf eine leere Datei absetzen und in einer zweiten Session die Ausgabe eines Befehls in diese Datei umlenken. Sie erhalten dann die Meldung file truncated. Die einzige Möglichkeit bestünde darin, alle Informationen, die der entfernte Rechner verarbeiten soll, an die Textdatei anzuhängen, wodurch diese jedoch unnötig anwachsen und Speicherplatz verbrauchen würde.
Die Lösung liefern benannte Pipes. Da der Prozess Daten nur dann in die Pipe schreibt, wenn die Gegenstelle sie zum selben Zeitpunkt ausliest, benötigt der Vorgang keinen zusätzlichen Speicherplatz für die Pipe – das Tail-Kommando liest die Daten immer an derselben Stelle aus der Pipe aus. Um eine Kommunikation zwischen den beiden Rechnern aufzubauen, benötigt man zwei benannte Pipes. Die eine empfängt den Datenstrom des entfernten Rechners und die zweite sendet die verarbeiteten Daten an das Zielsystem.
Den Datenstrom stellt die Ausgabe von tail -f mithilfe einer anonymen Pipe bereit. Diesen lenken Sie in eine SSH-Session um, die auf dem entfernten Rechner in die Empfangs-Pipe schreibt. Das Konstrukt realisieren Sie mit dem Aufruf aus Listing 7.
Listing 7
Datenstrom
$ tail -f Sende-Pipe | ssh -q Ziel "cat >Empfangs-Pipe"
Im nächsten Schritt geht es darum, in welcher Form die Daten das jeweilige Zielsystem erreichen. Eine relativ einfache Möglichkeit besteht darin, eine Funktion zu definieren, die die auszuführenden Kommandos in eine entsprechende Sequenz einbettet. In unserem Beispiel übernimmt das die Funktion rcmd, der wir als Argument das auszuführende Kommando übergeben.
Damit das Zielsystem erkennt, was mit den empfangenen Daten passieren soll, beginnt die Übertragung mit dem Marker BEGIN_CMD als Text, gefolgt vom auszuführenden Kommando. Das Zielsystem prüft beim Empfang einer Zeile, was für eine Zeichenkette das erste Argument enthält. Handelt es sich um BEGIN_CMD, leitet es das zweite Argument in eine Shell um. Diese lenkt das Ergebnis wiederum in die Pipe um und schickt es dem Absender zurück.
Der Vorteil dieser Methode besteht darin, dass aus dem Programm heraus keine Bearbeitung des Kommandos erfolgen muss. In Listing 8 erfolgt das Schreiben der Zeichenkette in eine Subshell, die dann die Kommandos ausführt und das Ergebnis auf dem Bildschirm ausgibt. Das landet dann beim entfernten Rechner als Antwort.
Listing 8
Ergebnis ausgeben
$ echo "cd /var/tmp; ls -l | wc -l" | /bin/bash
29
Möchten Sie mehrere Kommandos auf dem Zielsystem ausführen, jedoch nicht in dessen Standardverzeichnis, machen Sie für jedes davon eine Subshell auf. Damit agiert jedes Kommando auch in einer identische Umgebung (Listing 9). Wie Sie hier sehen, gilt das Zielverzeichnis /root nur bis zum Abarbeiten der Kommandosequenz. Der zweite Durchlauf zeigt das aktuelle Arbeitsverzeichnis des Elternprozesses an.
Listing 9
Umgebungspfad
# echo "cd /root ; pwd" | /bin/bash /root § echo "pwd"| /bin/bash /var/tmp
Um dieses Problem für eine Kommunikation zwischen zwei Systemen zu umgehen, erhält das Zielsystem zusätzlich zum eigentlichen Kommando noch die Anweisung, das aktuelle Arbeitsverzeichnis in eine temporäre Textdatei zu schreiben. Beim nächsten auszuführenden Befehl prüft der Prozess, ob es eine solche temporäre Datei gibt, liest diese gegebenenfalls aus und setzt das Verzeichnis entsprechend (Listing 10).
Listing 10
Verzeichnis setzen
# type rcmd
rcmd is a function
rcmd ()
{
setenv;
chkpipes;
if [ $? -ne 0 ]; then
return 1;
fi;
echo "BEGIN_CMD $@ ; { pwd >/tmp/lastpwd.$lhost ;}" > $sendpipe;
return $?
}
Es soll aber nicht nur die Möglichkeit bestehen, Kommandos auf einer entfernten Maschine auszuführen, sondern auch, Dateien zu übertragen. Um das zu bewerkstelligen, gilt es jedoch, eine Hürde zu meistern. Es lassen sich nicht beliebig lange Zeilen mittels echo ausgeben. Damit der Empfänger die gesendeten Zeichen nicht eventuell als Steuerzeichen interpretiert, müssen Sie die Binärdaten zusätzlich in reinen ASCII-Code umwandeln.
In früheren Unix-Varianten gab es für solche Zwecke das Kommando uuencode und das Gegenstück uudecode. Diese Befehle stehen zwischenzeitlich aber nicht mehr zwingend zur Verfügung, weshalb hierfür ein Python-Modul zum Einsatz kommt.
Ablaufplan
Der Listener liest die Empfangs-Pipe aus und leitet entsprechende Aktionen ein. Empfängt er eine Zeile, die ein auszuführendes Kommando enthält, prüft er zunächst, ob es eine Textdatei gibt, die das letzte verwendete Verzeichnis enthält. Im nächsten Schritt schreibt er die Zeichenkette BEGIN_CMD_OUT in den ausgehenden Datenstrom (Abbildung 4).
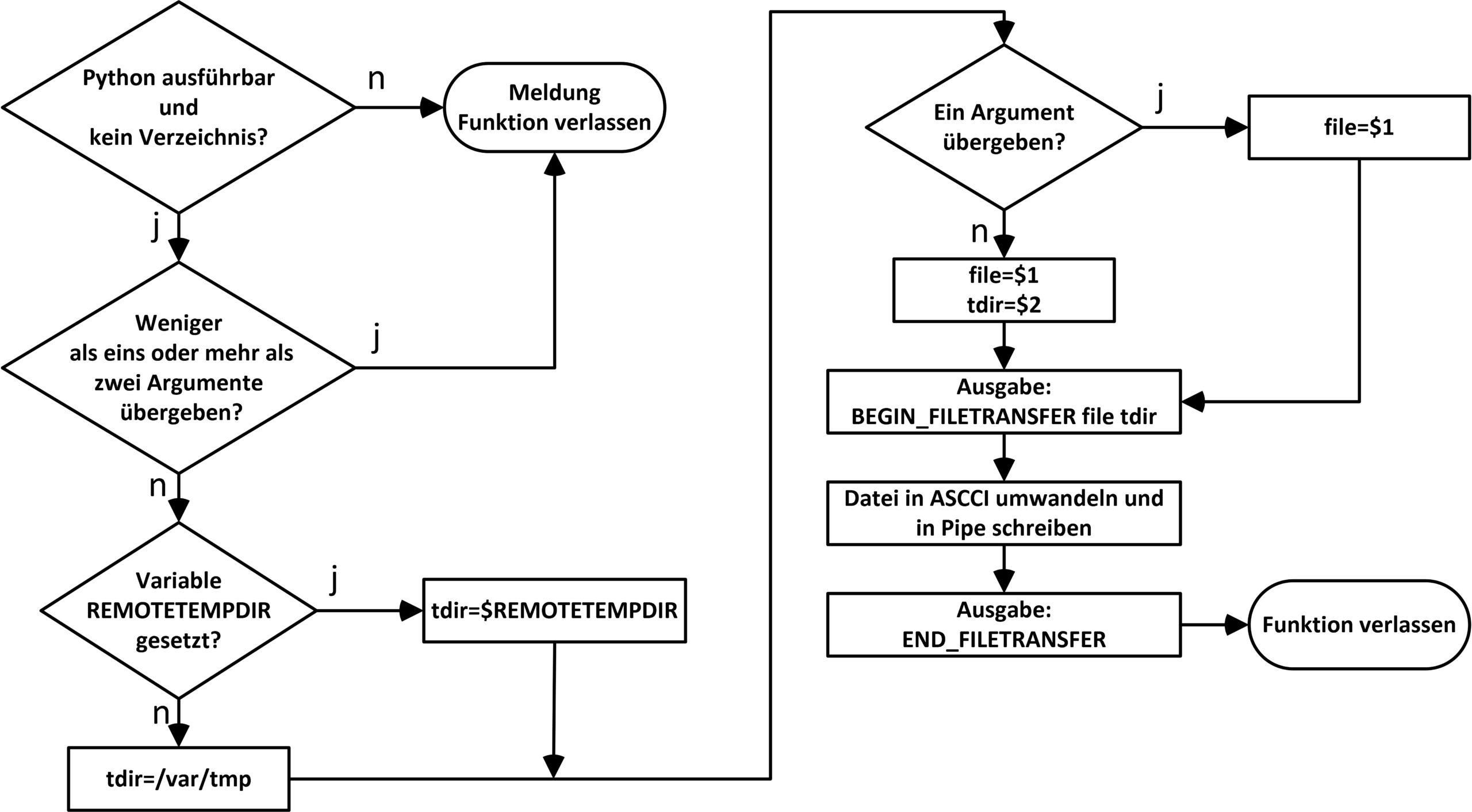
Abbildung 4: Programmablaufplan für das Senden von Dateien an fremde Rechner.
Sofern übergeben, wechselt der Prozess daraufhin in das gewünschte Verzeichnis und schreibt ein anschließendes auszuführendes Kommando in eine Subshell. Deren Ausgabe platziert er ebenfalls in den zu sendenden Datenstrom. Dessen Ende markiert die Zeichenkette END_CMD_OUT. Beginnt die empfangene Zeile mit der Zeichenkette END_COMMUNICATION, verlässt der Prozess die Funktion.
Beginnt die Übertragung mit BEGIN_FILETRANSFER, liest die Funktion die Argumente 2 (Dateinamen) und 3 (Zielverzeichnis) aus und schreibt mithilfe von Awk so lange in ein Python-Modul, das das Dekodieren der Daten vornimmt, bis sie die Zeile END_FILETRANSFER empfängt.
Als letzte Möglichkeit prüft die Funktion, ob die empfangene Zeile die Zeichenkette BEGIN_CMD_OUT enthält. Falls ja, gibt sie alle weiteren Zeilen auf dem Bildschirm aus, bis sie die Zeichenkette END_CMD_OUT erhält. Einen Ablaufplan des Listeners finden Sie in Abbildung 5.
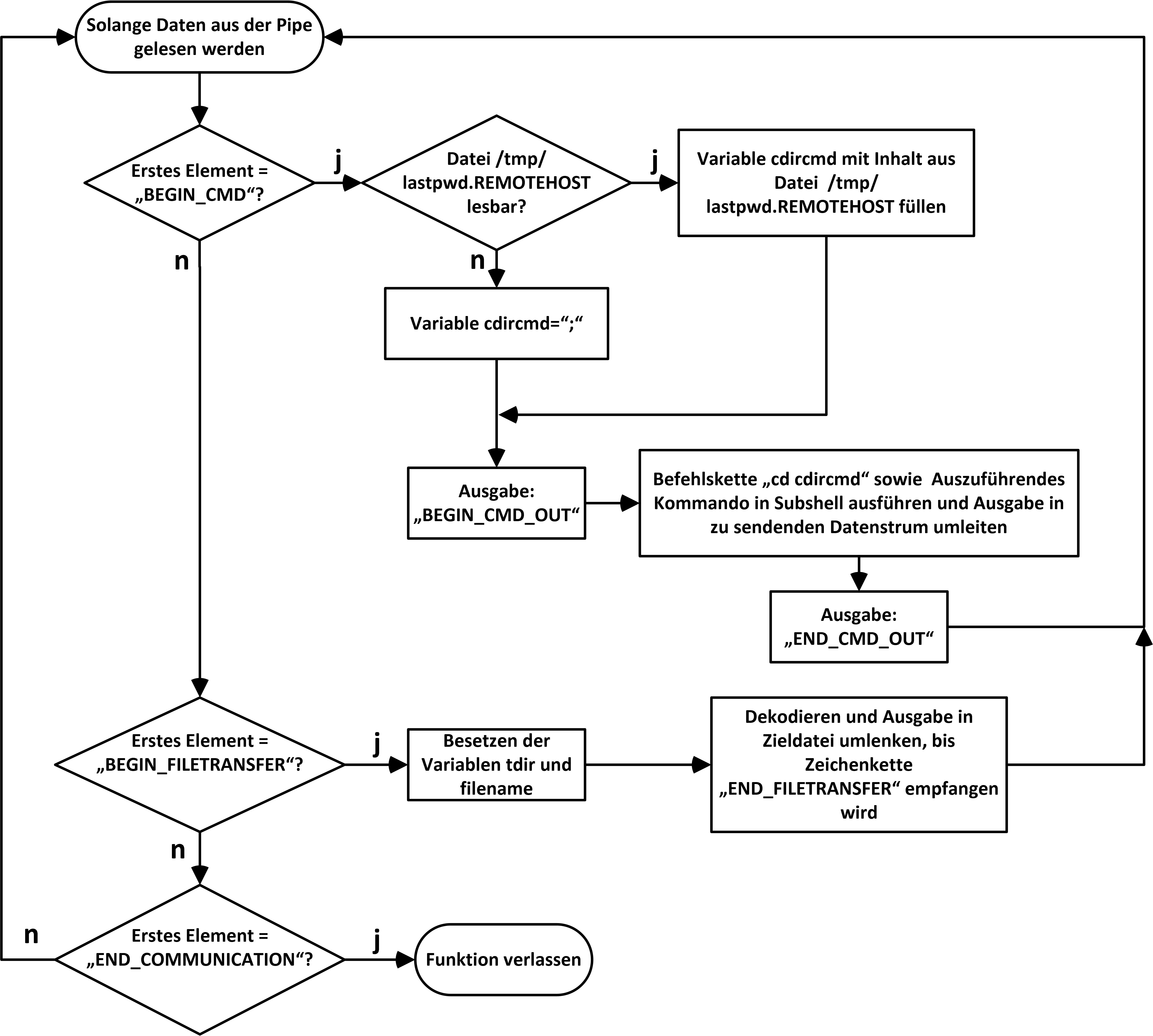
Abbildung 5: Programmablaufplan für den Listener.
Ausbaufähig
Eine Zusammenfassung aller Funktionen im Skript funktionen bietet die Tabelle “funktionen im Überblick”. Da es sich hier nur um ein Beispiel handelt, das Möglichkeiten für benannte Pipes aufzeigt, erfasst das Skript naturgemäß nicht alle möglichen Probleme.
|
Funktion |
Erläuterung |
|---|---|
|
|
Setzt alle benötigten Umgebungsvariablen. |
|
|
Prüft, ob benötigte Pipes unter |
|
|
Erzeugt alle benötigten Pipes unter |
|
|
Löscht alle Pipes des jeweiligen Remote-Hosts. |
|
|
Erzeugt einen Listener, der eingehende Daten ausliest und verarbeitet. |
|
|
Erzeugt einen Datenstrom in Richtung des zweiten Rechners. |
|
|
Beendet alle benötigten Hintergrundprozesse. |
|
|
Befehl auf dem entfernten Host ausführen. |
|
|
Datei auf das entfernte System kopieren. |
Derzeit kommt es ab und an noch vor, dass die Funktion killall nicht alle Prozesse beim ersten Durchlauf beendet. In dem Fall müssen Sie sie erneut aufrufen. Auch prüft diese Version beim Starten der Listener nicht, ob eventuell schon ein anderer Prozess die Pipes ausliest, was zu Fehlern führen kann. Zudem fehlt aktuelle eine Funktion, die prüft, ob das Zielverzeichnis beim Kopieren einer Datei existiert.
Wenn der lokale Host-Name nicht dem Alias der zugeordneten IP-Adresse entspricht, kommt es ebenfalls zu Fehlverhalten, da die entfernte Seite das nicht weiß. Es gibt noch weitere Möglichkeiten, die Funktionen auszubauen. So wäre es denkbar, eine Kommunikation zwischen beliebig vielen Rechnern aufzubauen. Hierzu gilt es, den jeweiligen Absender an die entfernte Maschine zu übermitteln, damit diese dann die Ausgaben in die jeweils richtigen Pipes schreibt.
Auch bietet es sich an, zur schnelleren Übermittlung ein Kompressionswerkzeug zwischenzuschalten. Entsprechend muss die Zielseite den Datenstrom wiederum dekomprimieren. Eine weitere, interessante Möglichkeit wäre es, den Rückgabewert des ausgeführten Kommandos an den Absender zu übermitteln.
Beachten Sie, dass der Prozess die Datei read.awk in der Grundeinstellung im Verzeichnis /var/tmp/ erwartet. Liegt sie an einem anderen Ort, müssen Sie die Variable awkfile in der Datei funktionen anpassen.
Fazit
Pipes finden sich nicht nur in langen Befehlsketten, sie dienen auch als sehr interessante Werkzeuge bei der Kommunikation zwischen mehreren Prozessen. Die Tatsache, dass das System sie wie normale Dateien behandelt, macht sie in Verbindung mit der Umlenkung von Kanälen auf vielen Unix- und Linux-Systemen zu einer sehr flexiblen Schnittstelle. Dazu trägt auch der Umstand bei, dass Pipes sich auf allen Unix- und Linux-Derivaten identisch ansprechen lassen und somit die Anwendung für den Anwender stets transparent bleibt. (tle)
Glossar
-
FIFO
-
First In, First Out. Ein Prozess schreibt in die Pipe, während ein weiterer daraus. Der lesende Prozess liest die Zeichen in derselben Reihenfolge, in der sie der schreibende ablegt.




