

Schon mit wenigen Zeilen Shell-Code programmieren Sie einen maßgeschneiderten Download-Manager, der Ihnen beim Herunterladen von Dateien aus dem Internet viel Arbeit abnimmt.
Es gehört schon fast zum Alltag, Daten aus dem Internet herunterzuladen. Dabei dient meist der Webbrowser als Schnittstelle. In der Regel bieten Webseiten Dateien zum Herunterladen an, die Sie dann einzeln im Browser anklicken. In der Standardeinstellung landen diese dann meist im Ordner Downloads/. Laden Sie viele Dateien herunter, gerät die manuelle Auswahl des Speicherorts schnell zur Geduldsprobe. Einfacher wäre es, ein Werkzeug würde diesen Job für Sie übernehmen.
Planung
Wie schon aus der Kurzbeschreibung hervorgeht, handelt es sich bei diesem Unterfangen um ein größeres Projekt, das durchaus einer guten Planung und eines sinnvollen Konzepts bedarf. Der Download-Manager soll nicht nur Dateien herunterladen, sondern auch davor warnen, wenn die Festplatte durch den Download vollzulaufen droht. Zudem tragen die meisten Dateien eine Endung, wie etwa .jpg, .iso oder .epub. Die nutzt unser Projekt dazu, die Dateien gleich in entsprechende Ordner mit passendem Namen zu sortieren.
Für dieses Unterfangen benötigen Sie zwei weitere Kommandozeilenprogramme, die moderne Linux-Distributionen standardmäßig nicht vorinstalliert mitbringen: Xclip und Lynx. Das Kommandozeilentool Xclip überwacht die Zwischenablage, Lynx dient als Webbrowser fürs Terminal. Es bietet aber auch für die Kommandozeile etliche Optionen, sodass es sich auch als Link-Spider verwenden lässt, der für das Anzeigen von Links viele Optionen bietet.
Grundlegend gilt es, beim Planen zu berücksichtigen, dass die URL der Download-Seite und deren Links erst einmal ins Terminal gelangen müssen. Dabei helfen Xclip und Lynx. Dieses Projekt enthält auch Funktionen, die bestimmte Teilaufgaben übernehmen, wie etwa das Erfassen und Auswählen der Links. Selbst wenn eingangs noch nicht genau feststeht, was diese Funktionen später enthalten, ist es ein guter Anfang, ein Skript anzulegen, das diese Funktionen erst einmal leer vereint (Listing 1).
Listing 1
Skriptgerüst ohne Funktionen
#!/bin/bash
function erfassung () { :; }
function splitter () { :; }
function umbenennen () { :; }
function download () { :; }
function menu () { :; }
Dieses Gerüst dient als Basis, von der ausgehend Sie sich stückweise um die Einzelteile kümmern. Am besten legen Sie den Fokus zunächst auf eine einzelne Funktion und nicht aufs große Ganze. Sie überlegen für jedes Teil einzeln, welche Aufgaben es erledigt, wie viele und welche Parameter es braucht, und ob es irgendwelche Rückgabewerte gibt.
Falls es Ihnen leichter fällt, lagern Sie Teile des Skripts aus und binden den Quellcode dann mit der Dot- oder Source-Notation ein, etwa via . ausgelagerteFunktion. Als gute Idee erwies sich auch der Ansatz, solche Funktionen möglichst abstrakt und unabhängig vom Skript zu gestalten, sodass sich zum Beispiel eine Funktion zum Umbenennen von Dateien auch in andere Skripte einfügen ließe, ohne sie zu modifizieren.
Abstrakt gesagt nimmt eine Funktion keinen, einen oder mehrere Parameter entgegen und liefert eventuell irgendetwas zurück, egal, ob Sie eine Funktion in diesem Skript einsetzen oder in einem völlig anderen Kontext.
Grundlegendes
In Listing 2 sehen Sie einige Dinge, die es grundlegend für das Skript zu erledigen gilt. Dazu zählen das Deklarieren grundlegender Variablen, die im späteren Verlauf den Programmablauf bestimmen und Dateitypen in einem Array speichern.
Zwar gibt es eine Vielzahl verschiedener Dateitypen, die man aus dem Web herunterlädt. Es bleibt Ihnen überlassen, ob Sie dem Array noch irgendwelche Dateitypen hinzufügen möchten und welche Struktur Sie dabei wählen. Es bietet sich jedoch an, eine gewisse Ordnung einzuhalten, etwa indem Sie Grafiken in einer Zeile und Video- oder andere Dateitypen in einer anderen Zeile erfassen. Die letzte Zeile erfasst noch den zur Verfügung stehenden Speicherplatz in einer Variablen.
Listing 2
Grundlegende Variablen
VERBOSE=true
LYNX="$(which lynx)"
XCLIP="$(which xclip)"
download_verzeichnis=~/Downloads7
dateitypen=(jpg jpeg png tiff gif bmp swf svg)
dateitypen+=(mp4 mp3 mpg mpeg vob m2p ts mov avi wmf asf mkv webm 3gp flv)
dateitypen+=(gzip zip tar gz tar.gz 7zip)
dateitypen+=(pdf doc xlsx odt ods epub txt mobi azw azw3)
dateitypen+=(iso dmg exe deb rpm)
dateitypen+=(java kt py sh zsh)
dateitypen+=($(echo ${dateitypen[@]} | sed -r 's/.+/\U&/'))
frei=$(df /home | gawk 'NR == 2{print $4}')
Listing 3 enthält zwei Funktionen, die Sie im weiteren Verlauf des Programms benötigen, um Meldungen auszugeben, falls die Variable VERBOSE auf true steht. Des Weiteren sehen Sie zwei If-Abfragen, die das Vorhandensein von Lynx und Xclip überprüfen. Fehlt eines von beiden, gibt das Skript eine Fehlermeldung aus und terminiert mit exit 1. Sollte das Download-Verzeichnis nicht existieren, legt das Skript es in der letzten Zeile an. Falls zu ausführliche Warnungen oder Fehlermeldungen Sie stören, setzen Sie VERBOSE auf false.
Listing 3
Fehlermeldungen ausgeben
function warn () {
if ${VERBOSE}; then
echo "WW: ${1}";
fi;
}
function err () {
if ${VERBOSE}; then
echo "EE: ${1}";
fi;
}
if [ -z ${LYNX} ]; then
err "Lynx nicht im System vorhanden."
err "Abbruch."
exit 1
fi
if [ -z ${XCLIP} ]; then
err "Xclip nicht im System vorhanden."
err "Abbruch."
exit 1
fi
[ ! -e ${download_verzeichnis} ] && mkdir -p ${download_verzeichnis}
Funktionen
Ähnlich wie mit den Variablen verfahren Sie am besten auch mit Funktionen. Es empfiehlt sich, sie so zu gestalten, dass sie möglichst unabhängig voneinander in diesem und eventuell anderen Skripten koexistieren.
Wenn es bei einer Funktion nicht so leicht ersichtlich ist, wie viele Parameter sie entgegennimmt und was sie zurückgibt, beschreiben Sie das in Kommentaren. Die Funktion erfassung kümmert sich um das Erfassen und Abspeichern der in der Webseite enthaltenen Links. Listing 4 legt erst einmal drei Arrays an, die die Funktionen mit Werten füllen. Das erste Array speichert die URLs ab und bearbeitet sie.
Da das Skript die Downloads nach Größe ordnen soll, ermittelt Wget diese mit der Option --spider (Zeile 12). Danach erfasst das Array indizierte_downloads die Datei, die sich herunterladen lässt, indem es als Index die Dateigröße verwendet und als Wert den Namen des Downloads selbst (Zeile 15). Dadurch gibt es für das Array nicht die typischen Indexe wie 0, 1, 2, 3 und so weiter, sondern beispielsweise 233, 1004, 780 etc., die die Bash beim Auflisten aller Indexe der Größe nach aufsteigend ausgibt. Das geschieht auch in der Zeile 19, wo das Arrayindizierte_indexe die Größen der Dateien abgespeichert.
Sie sehen später, dass die möglichen Downloads der Größe nach aufsteigend erscheinen. Es kommt gelegentlich auch vor, dass zwei Dateien dieselbe Größe aufweisen. Das fängt aber die While-Schleife in den Zeilen 13 bis 17 ab. Damit sich dieser Index für den Download eignet, erhöht das Skript in diesem Fall die angezeigte Größe um ein (virtuelles)) Byte.
Listing 4
Funktionen
declare -a download_links
declare -a indizierte_downloads
declare -a indizierte_indexe
function erfassung () {
lynx_options="-dump -listonly -nonumbers" # weitere mögliche Optionen
lynx_befehl="lynx $lynx_options $url" # -hiddenlinks=[option], -image_links
grep_suchstring="http.+($(sed 's/ /|/g' <<<${dateitypen[@]}))$"
grep_befehl="grep -Eoi $grep_suchstring"
download_links=(`$lynx_befehl | $grep_befehl`)
for x in ${download_links[@]}; do
datei_gr=$(wget --spider $x 2>&1 | gawk -F " " '/Länge/{print $2}')
while true; do
[ -z ${indizierte_downloads[$datei_gr]} ] &&
indizierte_downloads[$datei_gr]=$x &&
break || (( datei_gr++ ))
done
done
indizierte_indexe=(${!indizierte_downloads[@]})
}
Kurz und schmerzlos
In Listing 5 sehen Sie eine Funktion, die für das vernünftige Aufsplitten der Auswahl an Downloads sorgt. Sie treffen nach dem Auflisten der Downloads die Auswahl, indem Sie zum Beispiel 1,2,3,4-10 eintippen. In diesem Fall übernimmt das Skript die Downloads von 1 bis 10, die dann in der Form von (1:*2 3:*4 ...) in einem Array landen.
Die Funktion splitter befreit den String von Kommas und erstellt von Bereichen wie 4-10 eine sortierte, durch Leerzeichen getrennte Zahlenfolge. Mithilfe dieser Auswahlnummern findet Sie im späteren Verlauf die Downloads, die das Array indizierte_downloads enthält.
Behalten Sie schon einmal im Hinterkopf, dass bei Arrays der Bash die Zählung immer ab 0 beginnt. Wählen Sie beispielsweise die Datei Nummer 5 aus, dann finden Sie diese durch Abfrage von indizierte_indexe[4]. Denselben Index verwenden Sie beim Array indizierte_downloads, um den dazugehörigen Wert abzufragen.
Listing 5
Auswahl aufsplitten
function splitter () {
sed 's/,/\n/g' <<<$* | sed -r '/-/ s/([0-9]+)-([0-9]+)/seq \1 \2/e' | sort -nu
}
Listing 6 zeigt die Funktion, die beim Herunterladen das Umbenennen der Dateien übernimmt. Ihr übergeben Sie als Parameter den Basisnamen der URL. Das Skript befindet sich zu diesem Zeitpunkt schon im passenden Verzeichnis für die Dateiendung, wie etwa jpg/. Die Parameter ab Zeile 3 lokalisieren andere Dateien, die sich vor dem Start des Downloads schon darin befinden. Die Bash prüft mit dem Kommando aus Zeile 4, ob eine Namensgleichheit vorliegt. Falls ja, dann fügt das Skript zwischen dem Namen und dem Punkt vor der Endung einen Unterstrich (_) ein. Daraus ersehen Sie auch, wie oft die Datei umbenannt wurde. Zeigt der Name einen Unterstrich, wurde die Datei einmal umbenannt, zeigt er zwei, war es zwei Mal der Fall, und so weiter.
Listing 6
Umbenennen
function umbenennen () {
dateiname=$1
andere_dateinamen=`echo ${@:2}`
while grep -q -F "${dateiname}" <<<${andere_dateinamen}; do
dateiname=$(sed -r 's/(.+)(\.)(.+)/\1_\2\3/' <<<${dateiname})
done
echo ${dateiname}
}
Es schadet an dieser Stelle auch nicht, zwischendurch Funktionen im Einzelnen zu debuggen, indem Sie diese isolieren. Mit Sed und dem Kommando aus Listing 7 würden Sie beispielsweise die Funktionen warn und umbenennen in eine separate Datei schreiben, wo Sie sie im Anschluss mit dem Befehl bash -x debug debuggen, indem Sie innerhalb der Datei etwa die Funktion umbenennen und mit den dazugehörigen Parametern aufrufen.
Listing 7
Debuggen
$ cat <(sed -r -n '/function (warn|umbe)/,/^}/p' downloader_optimiert2.bash) > debug
Listing 8 zeigt die Funktion für den Download. Als Erstes filtert sie den Basisnamen aus dem Download-Link heraus. Dazu löscht sie alle Pfadangaben sowie http://... oder https://..., bis nur noch der eigentliche Dateiname übrig bleibt. Das Skript ermittelt im weiteren Verlauf die Dateiendung und legt, sofern noch nicht vorhanden, ein Verzeichnis mit diesem Namen an. Anschließend wechselt es dorthin und startet nach dem Durchlauf der Funktion umbenennen das Herunterladen.
Listing 8
Download-Funktion
function download () {
name=$(basename $1)
endung=$(cut -f 2 -d "." <<<${name})
[ ! -e ${download_verzeichnis}/${endung} ] && mkdir ${download_verzeichnis}/${endung}
cd ${download_verzeichnis}/${endung} && dateien_im_verzeichnis=$(ls)
zukuenftiger_name=$(umbenennen $name $dateien_im_verzeichnis)
wget -O $zukuenftiger_name $1
}
Der Inhalt aus Listing 9 dient zum Generieren des Menüs, das die möglichen Downloads auflistet. In dieser Funktion startet eine Schleife, die das Array indizierte_downloads durchläuft und die Größe sowie den Basisnamen, die der Index des Arrays enthält, in jeweils einer Zeile ausgibt. Das Ende der Schleife in Zeile 6 übergibt dann alles mittels einer Pipe an Gawk.
Mit der Option -f cutter.awk weiß Gawk, welche Awk-Datei es als Programmtext verwenden muss. Als zusätzliche Option steht im Aufruf --assign frei=${frei}. Das sorgt dafür, dass das Gawk-Skript den zuvor in der Bash ermittelten Umfang des freien Speicherplatzes kennt. Gawk untersucht dann jeweils in einer Zeile die Dateigröße sowie den Basisnamen und wertet sie Zeile für Zeile aus.
Listing 9
Menü
function menu () {
for index in ${!indizierte_downloads[@]}; do
local base_name=$(basename ${indizierte_downloads[$index]})
local groesse=${index}
echo "${groesse} ${base_name}"
done | gawk --assign frei=${frei} -F " " -f cutter.awk
}
Formatierte Anzeigen
Listing 10 zeigt im Gawk-Skript zunächst zwei selbst definierte Funktionen. cutter dient dazu, lange Basisnamen für die Anzeige zu kürzen, indem es sie in zwei Teile zerlegt und dazwischen drei Punkte einfügt. Die zweite Funktion erzeugt Trennlinien in der Anzeige, um bei Download-Seiten mit vielen Links die Übersicht zu erhöhen.
Der Block BEGIN definiert grundlegende Dinge und Überschriftenformate. Darüber hinaus zeigt er in der Zeile nach der Überschrift den freien Platz auf der Festplatte beziehungsweise im Home-Verzeichnis an.
Der Befehlsblock ohne Angabe eines Patterns in den Zeilen 21 bis 27 arbeitet schließlich die einzelnen Zeilen ab, wobei im ersten Feld die Download-Größe (in KByte, MByte und GByte) erscheint und im zweiten der Basisname. Das erweist sich dann als nützlich, wenn Sie kleinere Dateien herunterladen, wie Wallpapers, E-Books oder MP3-Dateien. Eine Angabe beispielsweise nur in GByte würde hier nicht viel Sinn ergeben. Dieser Befehlsblock berechnet auch den Gesamtumfang aller Downloads und gibt ihn schließlich über den END-Block aus (Abbildung 1).
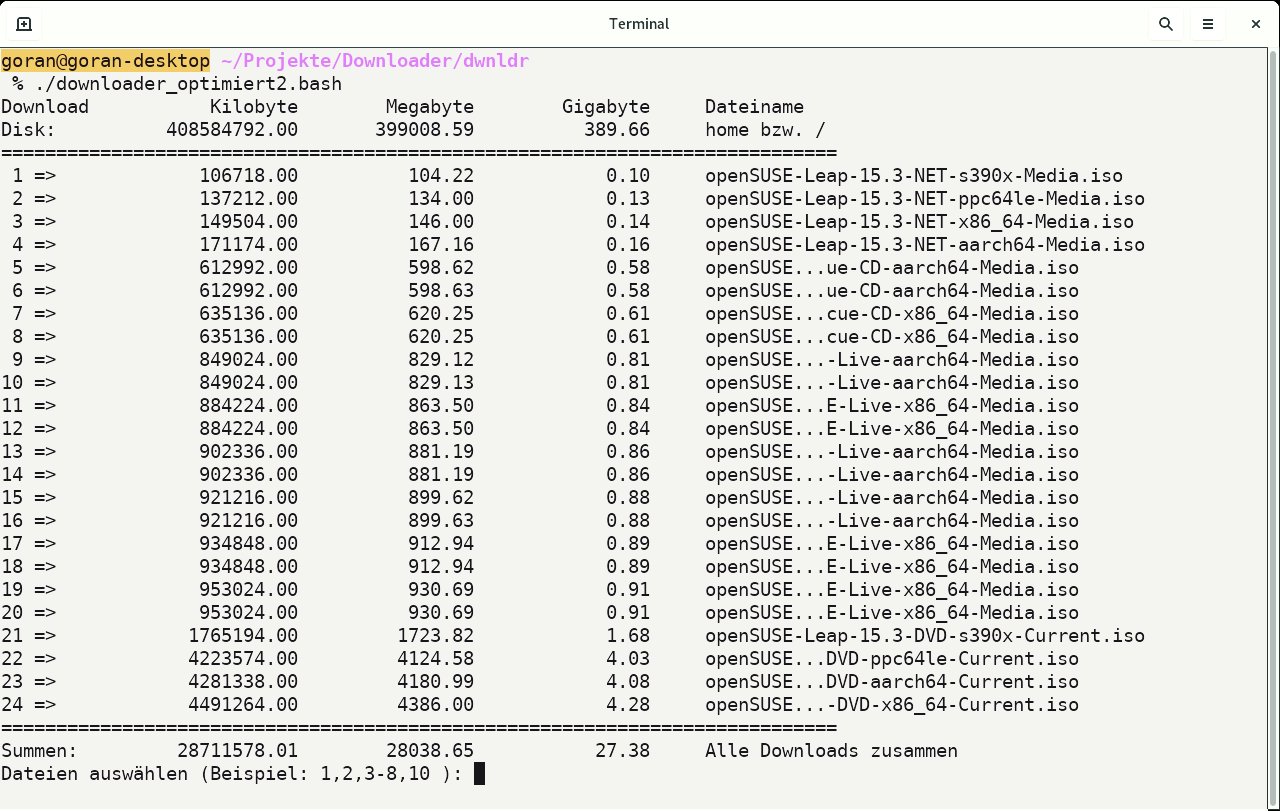
Abbildung 1: Die formatierte Ausgabe zeigt die bereitgestellten Dateien einer Webseite. Die Auswahl erfolgt über die Eingabe der vorangestellten Nummern.
Listing 10
cutter.gawk
function cutter( wort ){
l = length(wort)
part1 = substr(wort,1,8)
part2 = substr(wort,l-22)
return part1"..."part2
}
function trennlinie ( kleiner_gleich ) {
for ( p = 0; p <= kleiner_gleich ; p++){
printf "%s" (p == kleiner_gleich ? "\n" : "") ,"="
}
}
BEGIN {
i = 1
printf "%8s %18s %10s %13s %s\n", "Download", "Kilobyte", "Megabyte", "Gigabyte", "Dateiname"
printf "%-5s %21.2f %10.2f %13.2f %s\n", "Disk:", frei, frei/1024, frei/(1024*1024),"home bzw. /"
trennlinie(75)
}
{
if ( length($2) > 40 ) {
$2 = cutter($2)
}
printf "%2i => %21.2f %13.2f %13.2f %s\n", i++, $1/1024, $1/(1024*1024), $1/(1024*1024*1024), $2
summe += $1
}
END {
trennlinie(75)
printf "Summen: %19.2f %13.2f %13.2f Alle Downloads zusammen\n", summe/1024, summe/(1024*1024), summe/(1024*1024*1024)
}
Steuerung
Schließlich gibt es auch eine Art Hauptfunktion, die den gesamten Programmablauf steuert (Listing 11). Sobald Sie mit [Strg]+[C] eine URL aus dem Browser kopieren, greift Xclip darauf zu (Zeile 1).
Verwendet die grafische Oberfläche mehrere Zwischenablagen, wie das etwa Fvwm tut, müssen Sie mit der Option -selection primary oder secondary explizit angeben, welche davon Xclip berücksichtigt. Nach dem Erfassen der Zwischenablage prüft das Skript, ob die URL auch mit dem Inhalt der Zwischenablage gefüllt wurde. Falls die URL die Länge null hat, bricht das Programm den Vorgang ab.
Die Zeilen 11 bis 16 prüfen dann, ob auf der Seite überhaupt Download-Links erfasst wurden und sich ausgegeben lassen. Gibt es keine relevanten Dateien zum Herunterladen, bricht das Skript auch an dieser Stelle ab.
Zu guter Letzt arbeitet dann eine For-Schleife alle Downloads ab, prüft deren Größen und vergleicht sie mit der freien Kapazität der Festplatte. Übersteigt der Umfang der ausgewählten Downloads die verfügbare Speichergröße, bricht das Skript ab.
Listing 11
Hauptfunktion
url=$(xclip -o 2>/dev/null)
if [ -z $url ]; then
warn "Keine URL vorhanden."
warn "URL aus Browser mit [Strg]+[C] in die Zwischenablage kopieren."
exit 1
fi
erfassung
if [ ${#download_links[@]} -gt 0 ]; then
menu
read -p "Dateien auswählen (Beispiel: 1,2,3-8,10 ): " auswahl
else
warn "KEINE DOWNLOADS VORHANDEN" && exit 1
fi
declare -i gesamtgroesse_dowloads=0
for wahl in $(splitter $auswahl); do
gesamtgroesse_dowloads+=${indizierte_indexe[((wahl - 1))]}
aktueller_download=${indizierte_downloads[${indizierte_indexe[((wahl - 1))]}]}
if [[ ${frei}-5000 -lt ${gesamtgroesse_dowloads}/1024 ]]; then
warn "Zu wenig Speicherplatz."
warn "${aktueller_download} wird abgebrochen."
exit 1
else
download $aktueller_download
fi
done
Da es genügt, die URL, in der Sie nach Downloads suchen, aus der Adresszeile des Browsers herauszukopieren und das Skript dann automatisch startet, arbeitet es mit allen Webbrowsern zusammen. Es holt sich die URL aus der Zwischenablage, wertet die Seite nach Dateien aus, die sich herunterladen lassen, und zeigt sie Ihnen nach Größe geordnet an. Sie wählen dann bequem aus, welche davon Sie herunterladen möchten.
TIPP
Alle gezeigten Skripte finden Sie im Download-Bereich zu diesem Artikel.
Fazit
Generell bietet der selbstgestrickte Download-Manager eine einfache und zuverlässige Methode, um Dateien komfortabel aus dem Netz herunterzuladen. Es genügt, die URL der Download-Seite in die Zwischenablage zu kopieren und im Anschluss die gewünschten Dateien in der Shell anzuwählen.
Da der Autor die Skripte sehr strukturiert aufgebaut hat und die enthaltenen Funktionen größtenteils für sich allein funktionieren, lassen sie sich auch für den Einsatz in eigenen Shell-Programmen nutzen. (tle)




