

Sprachassistenten werden immer beliebter. Mit dem Datenschutz nehmen es die gängigen Anbieter allerdings nicht so genau. Mit dem freien Sprachassistenten Mycroft bleiben Sie Herr über Ihre Daten.
Sprachassistenten wie Amazon Alexa, Apple Siri, Microsoft Cortana oder der Google Assistant erfreuen sich immer größerer Beliebtheit. Doch alle diese mit künstlicher Intelligenz arbeitenden Helferlein basieren auf proprietärer Software, und wie zahlreiche Datenschutzskandale demonstrieren, respektieren die smarten Sprachassistenten kommerzieller Anbieter die Privatsphäre der Anwender nicht immer ausreichend. Zudem machen die Anbieter kein Geheimnis daraus, dass sie die mithilfe der Assistenten gewonnenen Daten auch für Werbung und Marketing auswerten. Anwender dieser innovativen Technologien verlieren damit völlig die Kontrolle über ihre persönlichen Daten.
Evolution
Moderne Sprachassistenten hängen in ihrer Wirksamkeit stets von Spracherkennungssystemen ab. Deren Entwicklung machte in den letzten drei Jahrzehnten rasche Fortschritte. Als Pionier auf diesem Gebiet stellte 1990 das US-Unternehmen Dragon Systems seine Spracherkennungssoftware Dragon Dictate vor, die gesprochene Wörter in Text umwandelte [1]. Damit konnte man nicht nur die seinerzeit gängigen Betriebssysteme bedienen, sondern etwas später auch Texte direkt in Editoren diktieren. Seit der Jahrtausendwende hielten Spracherkennungsfunktionen vermehrt Einzug in Bürosuiten, und Google etablierte 2007 in den USA eine auf Spracherkennung beruhende telefonische Suche in Geschäftsverzeichnissen.
Der Durchbruch und die Weiterentwicklung zum Sprachassistenten gelangen jedoch erst ab etwa 2010. Inzwischen standen breitbandige Zugänge ins Internet zur Verfügung, und mit dem Aufkommen der Smartphones erlebten Sprachassistenten einen signifikanten Aufschwung. Ihr Funktionsspektrum reicht dabei inzwischen weit über die Bedienung von Rechnern, Smartphones und Tablets sowie die reine Diktierfunktion hinaus. Digitale Assistenten führen mittlerweile mündliche Anweisungen aus, führen eine Konversation mit dem Anwender und steuern IoT-Geräte auf Zuruf. Zudem arbeiten sie hinterlegte To-do-Listen ab und managen so smarte Endgeräte vollkommen selbstständig.
Nachteile
Die Sprachassistenten proprietärer Anbieter wie Amazon, Google, Apple und Microsoft bestehen größtenteils aus einer Kombination von Hard- und Software. Die Geräte verfügen über mehrere Mikrofone, die permanent in den Raum hineinlauschen, um gesprochene Anweisungen entgegennehmen und ausführen zu können. Jeder Befehl führt zu einem Datentransfer an die Server des Herstellers. Die übertragenen Kommandos und Konversationen dienen – so beteuern es alle Anbieter – lediglich der Verbesserung der Software. Die genaue Verwendung der so gewonnenen Daten legen die Konzerne jedoch nicht offen, und auch Datenschutzpannen durch fehlinterpretierte Befehle kommen immer wieder vor.
Ein weiteres Problemfeld ergibt sich durch das Verarbeiten der abgehörten Daten beim jeweiligen Gerätehersteller. Da die Sprachbefehle bei den gängigen Anbietern transkribiert werden und diese nicht offenlegen, in welchem Umfang sie weitere Daten wie Seriennummern der Geräte oder Account-Nummern mit den Transkripten zusammenführen, lässt sich nicht nachvollziehen, in welchem Ausmaß sie die Daten dem jeweiligen Anwender zuordnen. Ein Zusammenführen der Datenbestände ließe bei regelmäßiger Nutzung der Sprachassistenten einen großen digitalen Fußabdruck entstehen, der selbst intimste Details aus der Lebenswelt der Anwender verriete und längerfristig bei der Anlage digitaler Personenprofile behilflich sein könnte.
Freie Alternativen
Doch freie Entwickler schlafen nicht, und so gibt es für Linux und IoT-Geräte wie den Raspberry Pi inzwischen ebenfalls brauchbare Sprachassistenten, die auf freier Software basieren. Manche davon lassen sich komplett offline nutzen, sodass die Sprachanalyse in Ihren eigenen vier Wänden erfolgt, selbst ohne Zugang zum Internet. Einige der Open-Source-Angebote benötigen zwar einen Account beim Anbieter, speichern jedoch laut Eigenauskunft keine personenbezogenen Daten in der Cloud. Alle FOSS-Projekte agieren zudem unabhängig von großen Konzernen, deren Geschäftsmodell aus der Analyse und dem Weiterverkauf von Daten besteht. Insofern besteht bei ihnen keinerlei Interesse an einer ausufernden Datensammelei.
Spezialisiert
Mehrere Sprachassistenten befinden sich derzeit in der Entwicklung und decken dabei allesamt spezielle Anforderungsprofile ab. Das Dragonfire-Projekt [7] arbeitet an einem auf Ubuntu basierenden virtuellen Assistenten primär für die Nutzung im Dragon-Helm, der dabei die Hardware der herkömmlichen Sprachassistenten ersetzt. Der modular aufgebaute Sprachassistent Kalliope [8] erlaubt als Framework eine weitgehende Konfektionierung durch den Benutzer. Das System fokussiert primär auf die Sprachsteuerung von Smart-Home-Geräten. Der lokal gehostete Sprachassistent Leon [9] lässt sich offline betreiben und auch per Texteingabe steuern. Das Sepia-Framework [10] dient zur Entwicklung individueller Sprachassistenten für spezielle Zwecke. Das weitgehend anpassbare System lässt sich ebenfalls auf On-Premises-Servern hosten.
Problematisch
Doch die Entwicklung von Sprachassistenten durch freie Programmierer bringt auch Nachteile mit sich. So schreitet die Entwicklung der Software langsamer voran als bei kommerziellen Produkten, hinter denen finanzstarke Konzerne stehen. Daher hat sich in der Welt freier Software bei Sprachassistenten im Laufe der Zeit eine Fragmentierung ergeben. Zahlreiche Produkte eignen sich nur für Spezialanwendungen.
Auf eigenen Servern gehostete, offline betriebene Sprachassistenten hinken den Online-Pendants funktional hinterher, da sie Daten wie Nachrichten und Wetterdienste nicht ständig aktualisieren können. Auch Zugriffe auf Datenbanken wie die Wikipedia fallen bei ihnen flach. Zudem beschränken sich zahlreiche unter Linux verfügbare Assistenten auf spezielle Plattformen. Hier macht sich die fehlende Manpower bemerkbar: Mit nur wenigen aktiven Entwicklern und begrenztem Zeitkontingent zur Weiterentwicklung der Software lassen sich nur schwer Allrounder programmieren.
Mycroft
Mycroft [2], die weltweit erste komplett auf freier Soft- und Hardware basierende Sprachassistentenplattform, entstand bereits 2015 als Alternative zu kommerziellen Angeboten. Auf den Crowdfunding-Plattformen Kickstarter und Indiegogo sammelte das Projekt in den Jahren 2015 und 2018 genügend Mittel für die Produktion des Mycroft Mark I und des Mycroft Mark II ein. Diese kombinierten Hard- und Softwarelösungen stehen in direkter Konkurrenz zu den kommerziellen Produkten.
Während der Mycroft Mark I [3] auf einem Raspberry Pi 2 (bei neueren Modellen ein RasPi 3) aufsetzt, verwendet der Mycroft Mark II einen Xilinx-Vierkern-Prozessor mit ARMv8-Architektur und 2 GByte Arbeitsspeicher. Mit einem kleinen IPS-Touchscreen sowie leistungsfähigen Lautsprechern und Mikrofonen ausgestattet, bietet er dieselbe Funktionalität wie die Produkte der etablierten Big-Tech-Hersteller.
Da die Software unter freien Lizenzen steht, müssen Sie jedoch nicht zwangsläufig ein entsprechendes Gerät kaufen. Dank der frei verfügbaren Apps können Sie jeden Laptop, PC oder Raspberry Pi mit dem Mycroft-Sprachassistenten aufrüsten. Anders als kleinere Projekte greift Mycroft nicht auf die Voice-Engines von Firmen wie Google oder Amazon zurück, sondern nutzt einen eigenen, freien Voice-Stack. Die Entwickler versichern zudem, keinerlei übertragenen Daten zu verkaufen oder für Werbung zugänglich zu machen.
Vorkonfiguriert
Der aktuelle Mycroft Mark II [4] stellt im Grunde ein vollwertiges herkömmliches Computersystem im All-in-one-Design dar (Abbildung 1). Der Rechner weist eine im Vergleich zu Desktop-Systemen erweiterte Konnektivität auf: So ist er mit Bluetooth 5.0 ausgestattet, besitzt ein WLAN-Interface nach dem aktuellen 802.11ac-Standard im 2,4/5-GHz-Frequenzband und nimmt über nicht weniger als fünf USB-Schnittstellen sowie ein RJ45-Interface Kontakt zu Peripheriegeräten und der Außenwelt auf.

Abbildung 1: Der Mycroft Mark II bietet neben vielen Funktionen auch ein gefälliges Design.
Als Betriebssystem nutzt der Mycroft Mark II ein auf Pantavisor Linux [5] basierendes, angepasstes System mit einem LXC-Container, in dem Mycroft läuft. Pantavisor Linux stellt dabei lediglich den vereinfachten Rahmen, in dem sich individuelle Systeme für Embedded Devices entwickeln lassen. Der Mycroft-Container hingegen basiert auf Ubuntu und wurde speziell für den Mark II angepasst.
Das Gerät lässt sich dank seiner Leistung auch offline betreiben. Allerdings muss es für zahlreiche Dienste wie die Wetteransage oder Nachrichtenmeldungen Drittanbieter im Internet kontaktieren, um jeweils aktuelle Ansagen des Sprachassistenten zu generieren. Im reinen Offline-Betrieb unabhängig vom Internet bietet der Mycroft Mark II über einen Mediaserver oder einen entsprechend bestückten Massenspeicher beziehbare Audiodateien, eine Zeit- und Datumsansage sowie einen Timer und eine Alarmfunktion. Das in Höhe, Breite und Tiefe je rund 20 Zentimeter große Gerät lässt sich auf der Website des Projekts vorbestellen und soll ab September 2022 zu einem Preis von 299 US-Dollar zuzüglich Versandkosten erhältlich sein.
Softwarelösung
Die Sprachassistentensoftware Mycroft lässt sich auf einem herkömmlichen PC unter verschiedensten Distributionen einsetzen. Die Installation nehmen Sie entweder anhand einer ausführlichen Anleitung vor, die Sie auf der Github-Seite des Projekts finden, oder Sie nutzen ein Snap-Paket. Das enthält jedoch derzeit nur eine Alpha-Version des Sprachassistenten und lässt sich zudem nur auf Linux-Derivaten installieren, die die Snap-Paketverwaltung unterstützen. Für Anwender, die den KDE-Plasma-Desktop nutzen, gibt es noch ein Plasmoid, zu dem ebenfalls eine ausführliche Installationsanleitung vorliegt. Arbeiten Sie in einer Container-Umgebung, greifen Sie alternativ zum vorkonfigurierten Docker-Image von der Docker-Hub-Seite [6].
Bevor Sie mit der lokalen Installation auf dem Massenspeicher beginnen, benötigen Sie zunächst ein Konto beim Mycroft-Projekt. Dazu rufen Sie in einem Webbrowser die URL https://home.mycroft.ai auf und klicken nach dem Laden der Seite auf den Link create an account oben in der Seitenmitte. Anschließend geben Sie zur Authentifizierung Ihre E-Mail-Adresse und ein Passwort ein. Danach loggen Sie sich mit diesen Credentials ein. Sie gelangen auf eine Seite, von der Sie verschiedene sogenannte Skills herunterladen können (Abbildung 2). Dabei handelt es sich um Sprachsteuerungssysteme für spezifische Anwendungsszenarien. Außerdem registrieren Sie hier Geräte für die Anwendung mit Mycroft.
Abbildung 2: Die Weboberfläche zur Administration wirkt selbsterklärend und durchdacht.
Im nächsten Schritt installieren Sie die lokale Software. Dazu kopieren Sie zunächst das Github-Repository auf den lokalen Massenspeicher (Listing 1, erste zwei Zeilen). Anschließend wechseln Sie in das dabei entstandene Unterverzeichnis (Zeile 3) und rufen dort das Installationsskript auf (Zeile 4). Die Routine richtet die Software ein, wobei sie rund 500 MByte an Daten aus dem Internet nachlädt (Abbildung 3). Dabei fallen mehrere Benutzereingaben an. Unter anderem wandert auch die Text-to-Speech-Engine Mimic auf die Platte, die die Sprachausgaben von Mycroft enthält. Sprachsteuerungssysteme für verschiedene Aufgaben landen im neu angelegten Verzeichnis /opt/mycroft/.
Listing 1
Installation
$ cd ~/ $ git clone https://github.com/MycroftAI/mycroft-core.git $ cd mycroft-core $ bash dev_setup.sh $ cd ~/mycroft-core/ $ ./start-mycroft.sh all
Abbildung 3: Die Installation von Mycroft auf dem PC nehmen Sie im Terminal via Skript vor.
Nach der Installation, die einige Zeit dauern kann, loggen Sie sich in Ihrem Mycroft-Konto ein. Mit einem Rechtsklick auf das Nutzer-Symbol öffnen Sie dessen Kontextmenü und wählen dort die Option Add Device aus. Im sich daraufhin öffnenden Dialog geben Sie die Standort- und Systemdaten Ihres Geräts ein. Um den benötigten Pairing-Code zur eindeutigen Identifikation des Geräts zu erfahren, starten Sie in einem Terminal alle Mycroft-Dienste (Listing 1, Zeile 5 und 6). Die Software nennt Ihnen nach kurzer Zeit den sechsstelligen Pairing-Code, den Sie im Browser auf der Geräteseite zusammen mit den anderen benötigten Daten eingeben (Abbildung 4).
Abbildung 4: Nach der Eingabe des Pairing-Codes ist Ihr Mycroft-System online registriert und verbunden.
Zu guter Letzt klicken Sie unten rechts auf der Website auf Next. Das Gerät und Ihr Konto sind nun miteinander verbunden, und Sie können dem Rechner Fragen stellen. Um den Verbindungsstatus zu überprüfen, klicken Sie auf der Webseite erneut auf das Nutzer-Symbol oben rechts und wählen aus dem Kontextmenü die Option Devices. Sie sehen nun das registrierte Gerät und darunter grün hinterlegt den Status Connected.
Fähigkeiten
Mycroft aktiviert bei der Erstinstallation einige grundlegende Skills. Diese umfassen Systembefehle und Routinen zu bestimmten Themengebieten, sodass die Software bereits mit Ihnen kommunizieren kann. Darüber hinaus stehen zahlreiche weitere Skills für unterschiedliche unterstützte Plattformen bereit, mit denen Sie die Fähigkeiten von Mycroft bei Bedarf erweitern.
Dazu rufen Sie in Ihrem Konto im Browser nach Anklicken des Nutzer-Symbols die Option Skills auf. Die Webseite listet nun untereinander alle bereits installierten Skills auf. Links im Fenster finden Sie in der vertikalen Leiste die Option Marketplace, die nach einem Klick darauf eine weitere Option Skills anzeigt. Nach dem Aktivieren dieses Dialogs präsentiert die Oberfläche alle verfügbaren Skills in Kachelform und nach Kategorien sortiert. Bereits installierte Skills kennzeichnet dabei ein grün hinterlegtes Häkchen rechts oben in der jeweiligen Kachel.
Ein Klick auf die gewünschte Kachel öffnet ein Detailfenster, das darüber informiert, mit welchen gesprochenen Befehlen Sie die jeweiligen Dialoge aktivieren. Rechts im Detailfenster sehen Sie zudem, für welche Plattform es das jeweilige Modul gibt. Um ein Modul zu installieren, nutzen Sie bereits jetzt die Sprachsteuerung und aktivieren das System mit “Hey Mycroft, install Skill-Name“. Die Software richtet das gewünschte Modul daraufhin ein.
Um Mycroft auf dem Linux-PC wieder zu beenden, müssen Sie alle Dienste deaktivieren. Dazu geben Sie im Terminal am Prompt den Befehl ./stop-mycroft.sh ein. Einen Überblick über die zahlreichen Aufrufparameter von Mycroft liefert das Kommando ./start-mycroft.sh ohne weitere Optionen.
Oberflächliches
Weitere Details zum Status von Mycroft erfahren Sie, indem Sie die Software am Prompt mit der Option cli aktivieren. Daraufhin öffnet sich eine rudimentäre Oberfläche, die zunächst Updates der Skills ausführt und diese anzeigt. Besonders bei Problemen mit der Spracherkennung kann es jedoch erforderlich sein, die Eingangsempfindlichkeit des Mikrofons zu modifizieren. Daher sehen Sie in der CLI-Oberfläche rechts unten auch einen stetig aktualisierten Mikrofonpegel. Zusätzlich akzeptiert Mycroft statt einer Spracheingabe auch entsprechende Kommandos in der Konsole. Diese Befehle und die Reaktionen des Systems zeigt die Software in Form eines kleinen Protokolls im Segment History links unten im Fenster an (Abbildung 5).
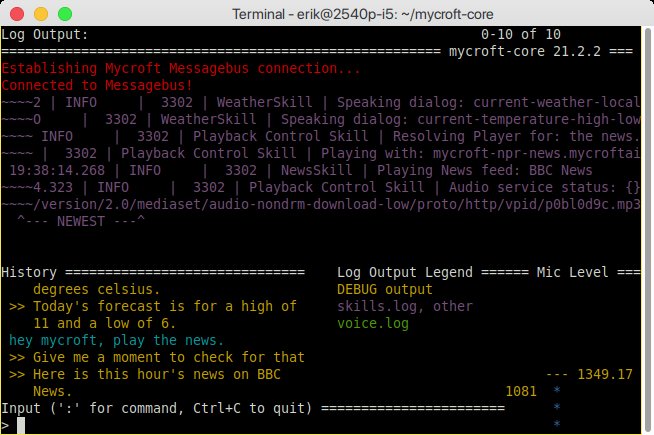
Abbildung 5: Mithilfe einer rudimentären Oberfläche können Sie die Arbeit von Mycroft nachvollziehen.
Fazit
Der Sprachassistent Mycroft ist derzeit das einzige freie Projekt, das bereits Serienreife erlangt hat und mit den kommerziellen, proprietären Konkurrenten funktional mithalten kann. Im Test auf verschiedenen Rechnern zeigte sich, dass das System recht ressourcenschonend arbeitet. So reagiert Mycroft selbst auf älterer Hardware ohne größere Latenzen auf Befehle. Die Spracherkennung arbeitet sehr verlässlich. Auch das Einbinden externer Dienste wie Nachrichtenseiten gelingt schnell und verursacht keine spürbaren Latenzen.
Allerdings versteht Mycroft bislang nur englischsprachige Befehle und kommuniziert auch nur auf Englisch. Die Sprecherstimmen klingen dabei teilweise etwas blechern und unnatürlich. Mit fortschreitender Entwicklung der Software dürfte dieses Manko jedoch bald der Vergangenheit angehören. (jlu)
Infos
-
Infos zu Dragon Dictate: https://en.wikipedia.org/wiki/DragonDictate
-
Mycroft: https://mycroft.ai
-
Mycroft Mark 1: https://mycroft.ai/product/mycroft-mark-1/
-
Mycroft Mark II: https://mycroft.ai/product/mark-ii/
-
Pantavisor Linux: https://pantavisor.io
-
Mycroft herunterladen: https://mycroft.ai/get-started/#download
-
Dragonfire: https://dragon.computer
-
Kalliope: https://kalliope-project.github.io
-
Leon: https://getleon.ai




