

Handschriften erkennen? Mithilfe eines neuronalen Netzwerks lernt Kollege Computer hier in atemberaubendem Tempo.
Neuronale Netze sind nur eine Methode von vielen, um Daten zu klassifizieren, zusammen mit Entscheidungsbäumen, einer Nächste-Nachbarn-Klassifikation oder einer Support Vector Machine. Manche davon arbeiten schneller und genauer als neuronale Netze, erweisen sich aber verfeinerten Netzen (deep neural networks, convolutional neural networks) als unterlegen. Googles Spielprogramm AlphaGo setzte auf eine Kombination mehrerer Methoden.
Dieser Artikel möchte anhand einer einfachen Ziffernerkennung zum Experimentieren anregen. Er streift dabei mathematische Details wie Matritzenmultiplikation und Ableitungen von Funktionen nur am Rand. Er stützt sich auf das Demonstrationsprogramm von Tariq Rashid [1]. Parallel zur frei verfügbaren Software hat Rashid ein Buch zum Thema veröffentlicht [2].
Die Software setzt eine Python3-Umgebung unter Jupyter/IPython Notebook voraus. Sie läuft aber auch unter Python 2.7, sofern Sie alle erforderlichen Bibliotheken installiert haben. Beim Bearbeiten von Bildern mit selbst geschriebenen Ziffern hilft ein Bildverarbeitungsprogramm wie Gimp. Mit dem Programm Imagemagick schneiden Sie die Dateien für die Untersuchungen automatisch zu.
Trainingsmaterial
Unter der Abkürzung MNIST (Modified National Institute of Standards and Technology) findet sich im Internet eine umfangreiche Sammlung von Schriftproben der Ziffern 0 bis 9 [3]. Sie umfasst 70?000 Einträge, aufgeteilt in eine sogenannte Trainingsdatei mit 60?000 Bildern und eine Datei zum Testen mit 10?000 Daten. Jedes Bild besteht aus 28 mal 28 Graustufenwerten und einem Label zum Bezeichnen der dargestellten Ziffer.
Der Datensatz kommt häufig zum Einsatz, um unterschiedliche Verfahren miteinander zu vergleichen und zu bewerten. Abbildung 1 zeigt verschiedene Proben der Ziffer 7. Die leichte Variation der Schreibweise macht es konventionellen Programmen sehr schwer, die sinnbestimmenden Elemente herauszulesen.

Abbildung 1: Handgeschriebene Ziffern 7 aus der MNIST-Datenbank.
In Ergänzung zu den standardisierten Daten machen eigene Daten die Untersuchung spannender. Je mehr Ziffern, desto besser – 100 sind es in Abbildung 2. Die hier gezeigte Schriftprobe leidet an einem Manko: Die Schreiber hielten sich nicht immer an die Größe des Zeichenrasters. Wie sich später noch zeigt, schränkt das die Lesbarkeit der Ziffern ein.

Abbildung 2: Selbstgeschriebene Ziffern machen die Auswertung spannender.
Sie zerschneiden das Bild elektronisch und weisen ein Python-Skript an, daraus eine Datei mit allen Bilddaten zu erstellen. Das automatische Aufteilen setzt voraus, dass die Zeichen in einem quadratischen Raster angeordnet sind.
Zunächst scannen Sie die Vorlage möglichst unverzerrt ein. Im nächsten Schritt skalieren Sie das Bild so, dass es sich ganzzahlig teilen lässt. Das Beispiel aus Abbildung 2 hatte zunächst eine Größe von 743 x 743 Pixeln bei 10 x 10 Teilbildern. Nach einer Verkleinerung auf 740 x 740 Pixel belegt jedes Teilbild eine Größe von 74 x 74 Pixeln. Verstärken Sie den Kontrast, damit die blassen Linien des Rasters verschwinden. Das bearbeitete Bild speichern Sie im PNG-Format mit Graustufen, ohne Farben und möglichst ohne Alpha-Kanal.
Das Zerschneiden und Zentrieren übernimmt das Programm Imagemagick (Listing 1). Bei einer Größe von 740 x 740 Pixeln teilt der Parameter -crop 74x74 das Bild in zehn Mal zehn Einzelbilder. Der Parameter -trim entfernt alle Randpixel. Er bereitet gleichzeitig das Zentrieren der Zeichen auf der bereitstehenden Fläche vor.
Der Ausdruck -resize 28x28 verkleinert die Bilder auf die gewünschte Größe, -gravity center platziert es in die Mitte, und -extend 28x28 stellt sicher, dass die Bilder quadratisch sind. Mit +repage löschen Sie Metainformationen zur Position.
Der Ausdruck my%03d.png weist allen Bildern Namen mit fortlaufender Nummer zu, von my000.png bis my099.png. Gleichzeitig entspricht bei dieser Anordnung die dritte Ziffer des Dateinamens der abgebildeten Ziffer.
Listing 1
$ convert input.png -crop 74x74 -trim -background white -resize 28x28 -gravity center -extent 28x28 +repage -alpha off my%03d.png
Das Originalformat der MNIST-Daten enthält in einer Datei die Grauwerte aller Bilder, in einer zweiten die Label der abgebildeten Ziffern. Zur Demonstration ist es anschaulicher, die Werte unkomprimiert in einer CSV-Datei zu speichern. Darin entspricht jede Zeile einem Bild und beginnt mit einem Label für den Wert der dargestellten Zahl, gefolgt von 784 (28 x 28) Grauwerten zwischen 0 und 255.
Das Konvertieren der MNIST-Daten hat Joseph Redmon bereits für Sie erledigt [4]. Wenn Sie die Dateien lokal im IPython-Unterverzeichnis mnist_dataset/ ablegen, brauchen Sie das Programm später nicht anzupassen.
Das Python-Skript aus Listing 2 dient dazu, eigene Bilder in ein CSV-Format umzuwandeln. Das Programm benötigt drei Bibliotheken. Die Library os zeichnet für die Iteration über alle Bilddateien im Unterverzeichnis zuständig (Zeile 12). Mit numpy verwalten Sie die Bildpunkte als Matrix mit 28 x 28 Feldern. Die Bibliothek matplotlib.image verarbeitet PNG-Bilder.
Listing 2
import matplotlib.image as mpimg
import numpy as np
import os
def writeImagestoCSV(mydir,csvfile,picid):
'''Write images like picid-nnm.png in
directory mydir to csvfile in current directory.
-nnm are three digits, the last one
identifying the name of the number.
'''
with open(csvfile,'wb') as fp:
for fn in os.listdir(mydir):
fna = fn.split('.')[0][-1]
if (fn.split('.')[0][0:2] == picid):
img = mpimg.imread(mydir+fn)
pixels = np.asarray(img)
# print(pixels.shape,fn)
apixels = np.reshape(pixels,28*28)
apixels = 255-(apixels*255).astype(int)
apixels = np.append(int(fna),apixels)
np.savetxt(fp,[apixels],fmt='%i',delimiter=",")
writeImagestoCSV('meinbildverzeichnis/','test.csv','my')
Der Aufruf in Zeile 23 übergibt das Verzeichnis für die Bilder, den CSV-Dateinamen und die Anfangsbuchstaben für die Dateinamen – im Beispiel dient my als Präfix. Bricht das Programm mit der Fehlermeldung Cannot reshape array ab, enthalten die Ausgangsbilder entweder noch Farbinformationen oder einen Alpha-Kanal. In diesem Fall liefert der Aufruf pixels.shape (in Zeile 17, auskommentiert) nicht den Wert (28,28), sondern ein Tupel mit drei Einträgen.
Listing 3
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def printrecord(record):
picdata = record.split(',')
picarray= np.asfarray(picdata[-28*28:]).reshape((28,28))
print("Number: ", picdata[0:-28*28])
#print("Number: detected; true) ", picdata[0:-28*28])
plt.imshow(picarray,cmap='Greys', interpolation='None')
plt.show()
with open("test.csv") as fp:
data=fp.readlines()
printrecord(data[11])
Listing 3 beschreitet den umgekehrten Weg. Es gibt eine Zeile, im Beispiel Zeile 11, aus der Datei test.csv über printrecord(data[11]) als Grafik aus. Neben den Bibliotheken numpy und matplotlib leitet die Zeile %matplotlib inline unter Ipython Notebook die Ausgabe im Browser ein. Die Funktion printrecord nimmt an, dass es sich bei den letzten 28 x 28 Werten (in Python: [-28*28:]) um Bildpunkte handelt und bei allen davorstehenden Zeichen um Labels ([0:-28*28]).
In der Theorie
Ein neuronales Netz bietet eine Methode, viele freie Parameter einzuführen, die bei geeigneter Wahl ein System hinreichend genau beschreiben. In Abbildung 3 besteht das Netz aus einer Eingabeebene mit den Eingabegrößen i1 bis i3, einer versteckten Ebene (hidden layer) mit den drei Knoten h1 bis h3, einer Ausgabeebene o1 bis o2 und den Kanten w_ij, die die Knoten miteinander verbinden.

Abbildung 3: Die Variablen eines neuronalen Netzes.
Die Knoten multiplizieren die Eingangsgrößen mit einem Gewichtungsfaktor, bilden daraus die Summe, begrenzen das Ergebnis und leiten es über die Ausgangsverbindungen zur nächsten Ebene. Dabei gibt das zu lösende Problem die Zahl der Knoten für Eingang und Ausgang vor. Bei der Auswahl der richtigen Anzahl der versteckten Ebenen und ihrer Knoten handelt es sich dagegen um “Alchemie”. Je mehr es gibt, desto genauer lässt sich ein Problem abbilden. Andererseits steigt damit der Rechenaufwand, und das System lernt schwerer.
Im Beispiel der Bilderkennung liefern 784 Pixelwerte (28 x 28) die Eingabe. Jeweils einer der zehn Ausgabeknoten gibt eine Wahrscheinlichkeit für eine erkannte Ziffer aus. Im einfachsten Fall “gewinnt” der größte Wert, die anderen Vorschläge werden ignoriert. Unser Beispiel beschränkt sich auf eine versteckte Ebene mit 200 Knoten.
Bezeichnet i die Knotenebene, dann empfangen die Knoten jeweils j Eingaben xj der vorgeschalteten Ebene. Die Gewichtungsfaktoren w fassen Sie in einer Matrix der Größe xij zusammen, hier mit 784×200 Elementen.
Das Ausgangssignal z der Ebene ergibt sich als Summe der Produkte der Gewichtungsfaktoren mit den Ausgangsgrößen der vorgeschalteten Ebene:
z = Summe(w_ij*xj) mit j=1..200
Die Python-Bibliothek numpy schreibt diese Matrix-Operation als dot(w,x) aus, Listing 4 zeigt ein Beispiel. Das erste Element des Produkts aus der 5×3-Matrix und 3×1-Matrix lautet: 0*0.1 + 1*0.2 + 2*0.3 = 0.8. Die Produktmatrix besteht aus 5 x 1 Elementen.
Listing 4
import numpy as np def sigmoid(x): return 1/(1+np.exp(-x)) w = np.arange(15).reshape(5,3) x = np.arange(0.1,0.35,0.1).reshape(3,1) wx= np.dot(w,x) print(w,"\n\n",x,'\n\n',wx,'\n\n',sigmoid(wx))
Das Beispiel aus Listing 5 erläutert die Wirkungsweise einer Aktivierungsfunktion, hier der Sigmoid-Funktion. Da es sich bei wx um eine Matrix (Vektor) handelt, bewirkt der Aufruf von sigmoid(wx) ein Anwenden der Funktion auf jedes Element der Matrix.
Listing 5
[[ 0 1 2] [[0.1] [[ 0.8] [[ 0.68997448] [ 3 4 5] dot [0.2] = [ 2.6] ; sigmoid()= [ 0.93086158] [ 6 7 8] [0.3]] [ 4.4] [ 0.98787157] [ 9 10 11] [ 6.2] [ 0.99797468] [12 13 14]] [ 8. ]] [ 0.99966465]]
Die Aktivierungsfunktion sigmoid(x) konvergiert für negative Werte gegen null, für große gegen eins (Abbildung 4). Sie übernimmt die Aufgabe einer Schwellwertfunktion: Bei kleinen Eingabewerten passiert nichts, ab einer bestimmten Eingangsgröße “feuert” der Knoten.
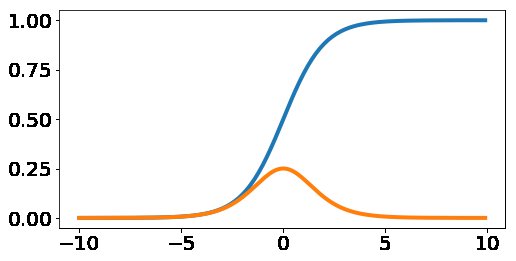
Abbildung 4: Die Funktion Sigmoid (blau) und ihre Ableitung.
Eine Sprungfunktion mit den Werten 0 (für x < 0) und 1 (für x > 0) würde die Ausgangswerte in ähnlicher Weise begrenzen, ist aber nicht differenzierbar. Das bedeutet, dass man hier anders als bei der Sigmoid-Funktion den Sprungpunkten keine Steigung zuordnen kann.
Für kleine und große Werte verläuft die Funktion flach (Steigung 0). Im Nulldurchgang ist die Steigung maximal, wie die orange gezeichnete Ableitungsfunktion in Abbildung 4 verdeutlicht.
Ein neuronales Netz führt viele Gewichtungsfaktoren als freie Parameter ein. Sind sie optimal bestimmt, beschränkt sich das Berechnen der Ausgangswerte auf einfaches Summieren und Multiplizieren ganzer Zahlen. Das macht das Befragen eines solchen Netzes sehr schnell und stellt selbst Rechner auf dem Niveau eines Raspberry Pi vor keine Probleme.
Anders sieht es beim Trainieren aus. Die Gewichtungsfaktoren lassen sich nicht analytisch bestimmen. Stattdessen besteht die Strategie darin, die Abweichung zwischen Soll- und Ist-Wert in vielen Iterationen zu minimieren.
Das hier vorgestellte Netz nutzt für die Fehlerrückrechnung das Gradientenverfahren. Anhand der Steigung (Ableitung) der Aktivierungsfunktion schätzt das Programm für jeden Punkt ab, wie sich der Fehler bei einer kleinen Variation der Gewichtungsfaktoren ändert. Beim Lernfaktor handelt es sich um eine Zahl, die für jeden Lernschritt die Größe der Variation festlegt. Ist sie zu klein, dauert das Lernen sehr lang; ist sie zu groß, divergiert das System.
In IPython
Das Beispiel wurde für IPython Notebook ausgelegt. Da der Schwerpunkt auf einfachen Experimenten mit einem neuronalen Netz liegt, sollten die Begrenzungen des Programms nicht stören (nur eine versteckte Ebene, kein Optimieren auf Rechengeschwindigkeit oder Speichermanagement, keine explizite Angabe eines Biases).
Der Quellcode der Software liegt auf Github [5]. Entweder kopieren Sie die Programmteile stückweise in ein eigenes IPython Notebook, oder Sie speichern den Code als Textdatei mit der Erweiterung .ipynb, um ihn anschließend über eine lokale Notebook-Instanz zu starten. Alternativ klonen Sie über Git das Repository oder laden das ganze Verzeichnis als ZIP-Archiv herunter.
Um die Tiefen des Programms nachzuvollziehen, sei auf das Buch von Rashid verwiesen, das Details zur Programmierung erörtert. Der Autor bemüht sich um einfache Erläuterungen, mit gemischtem Erfolg: Manche Leser ermüden vermutlich die starken Vereinfachungen, andere enttäuscht es, wenn sie nach der Lektüre die Tiefen der Differenzialrechnung nicht ganz erfasst haben.
Der erste Block des Python-Programms (Block 1) lädt die Bibliotheken numpy, matplotlib und, falls Sie die Aktivierungsfunktion Sigmoid nicht selbst programmieren, zusätzlich scipy.special. Block 2 definiert in der Klasse neuralNetwork alle notwendigen Methoden und Parameter.
Die Vektoren wih (w_input-hidden) und who (w_hidden-output) legen die Startwerte für die Gewichtungsfaktoren fest. Dafür würden beliebige Werte zwischen 0 und 1 funktionieren. Besser sind gleichmäßig verteilte Werte im Intervall 0 bis 1, noch besser zufällig gaußverteilte Werte mit einer Streubreite in Abhängigkeit von der Knotenanzahl. In jedem Fall müssen sich alle Startwerte voneinander unterscheiden. Die Methode query berechnet die Werte für die Ausgangsknoten in Abhängigkeit von den Eingangswerten und den Gewichtungsfaktoren.
Der Kern des neuronalen Netzes steckt in der Methode train. Sie versucht, die Abweichung von den Ausgangs- und Eingangswerten zu minimieren, indem sie die Gewichtungsfaktoren anpasst. Bei 784 Eingangswerten, 200 versteckten Knoten und 10 Ausgangswerten kommen über 150?000 Werte zusammen. Das Berechnen der Variation über den Gradienten der Aktivierungsfunktion und das Verrechnen mit den anderen Werten und der Lernrate lr erfolgt in den letzten beiden Zeilen der Methode.
Der Block 3 legt die Dimension des Netzes fest, setzt die Lernrate auf den Wert 0.1 und erzeugt eine Instanz von neuralNetwork. Block 4 liest die Trainingsdaten ein, 60?000 Zeichen der MNIST-Datenbank, sofern die Dateien im Unterverzeichnis mnist_dataset liegen. Die Grundeinstellung sieht vor, dass die Software in Block 5 alle 60?000 Zeichen in sechs Runden trainiert. Jede Runde dauert, abhängig vom Rechner, einige Minuten.
Für den ersten Test überspringen Sie diesen Schritt und lesen in Block 6 die Daten ein, ebenfalls aus dem Unterverzeichnis mnist_dataset. Das neuronale Netz überprüft anhand der 10?000 Ziffern, wie gut es gelernt hat.
Block 7 ähnelt Block 5, nur zählt die Software hier die Abweichungen, statt sie an eine Trainingsfunktion weiterzugeben. Der letzte Block (Block 8) liefert das Ergebnis performance = 0.1 (sofern Sie das Training in Block 5 übersprungen haben).
Falls Python 2.7 für das Rechnen zum Einsatz kommt, rundet es auf nNull – in diesem Fall multiplizieren Sie mit der Floating-Zahl 1.0, damit das Ergebnis selbst wieder eine Zahl mit Nachkommastellen ausgibt.
Die Menge der 10?000 Schriftproben enthält die 10 Ziffern gleich häufig. Deshalb beträgt die Wahrscheinlichkeit, eine Ziffer zu finden, die zufällig die richtige ist, 1/10 oder 0,1. Das neuronale Netz kann ohne Training nur raten und entspricht der Erwartung von 10 Prozent korrekt erkannter Zahlen.
Vorbereitungen
Bevor die Experimente beginnen, erweitern Sie Block 8, siehe Kommentarzeilen und Listing 6. Zusätzlich stellen Sie einen Block 7b voran (Listing 7). Er definiert zwei Funktionen: printrecord (aus Listing 3) und numprob (aus Listing 6).
Die erste Funktion stellt den gefundenen Ziffernwert dem tatsächlichen gegenüber und zeigt das Bild als Inline-Grafik in der IPython-Notebook-Umgebung. Die zweite Funktion nennt zusätzlich die weniger wahrscheinlichen Ziffernwerte, prozentual gewichtet.
Listing 6
scorecard = []
# Counter for patterns; make it easier to identify images
counter = 0
# error matrix: [true,predicted]
errm = numpy.zeros((10,10),dtype=numpy.int)
for record in test_data_list:
all_values = record.split(',')
correct_label = int(all_values[0])
inputs = (numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
outputs = n.query(inputs)
label = numpy.argmax(outputs)
# fill error matrix with values: true/predicted
errm[correct_label,label] +=1
if (label == correct_label):
scorecard.append(1)
else:
scorecard.append(0)
# print mismatching image number
print("No: {}".format(counter))
# print probabilities for numeric values
numprob(outputs)
# add predicted value ...
record2="{},{}".format(label, record)
# ... and print it together with image
printrecord(record2)
pass
# increase image counter
counter += 1
pass
# print error matrix
print(errm)
Listing 7
def numprob(a):
'''Pretty print probabilities for detected numbers'''
s = numpy.sum(a)
b = [x[0]/s for x in a]
d = numpy.argsort(b)
print("(Number: prob_%.)")
for i in d[::-1]:
p = round(b[i]*100)
if p>0:
print("{:2d}: {:3.0f}".format(i,p))
Experimente
Nachdem der Wert für die Variable epoche auf den Wert 1 gesetzt ist, holen Sie nun den oben übersprungenen Schritt nach und führen die Python-Anweisungen in Block 5 aus. Als Ergebnis nach einer Epoche erhalten Sie eine Erkennungsrate von 95 Prozent.
Bereits nach nur einem Durchlauf aller 60?000 Zeichen ordnet das neuronale Netz also 95 Prozent der handgeschriebenen Zeichen richtig zu. Beim Test mit 10?000 Daten liegt es demnach 500 Mal falsch. Stellen Sie im Block die Anweisung %%time voran, gibt das System die Rechenzeit aus. Sie liegt abhängig vom Rechner pro Schleife bei ein bis zwei Minuten. Mit fünf weiteren Durchläufen, also nach insgesamt sechs Epochen, steigt die Rate auf 97 Prozent, bei einer Trainingszeit von rund 15 Minuten.
Abbildung 5 vergleicht die Fehlermatrix nach dem ersten und sechsten Durchlauf, wobei die richtig bestimmten Werte in der Diagonalen ausgeblendet sind. So interpretiert die Software die Ziffern 4 (34 Mal) und 7 (43 Mal) falsch als 9, nach sechs Durchläufen immer noch jeweils 11 Mal. Es gibt auch umgekehrte Fälle, wo das Programm zuvor richtig erkannte Zeichen nach dem intensiven Lernen falsch zuordnet.

Abbildung 5: Die Fehlermatrix falsch erkannter Zeichen nach einem und nach sechs Durchläufen (Epochen).
Abbildung 6 greift einige Beispiele nicht erkannter Zeichen heraus. Die erste Ziffer 9 in der oberen Reihe interpretierte das neuronale Netz mit einer Wahrscheinlichkeit von 35 Prozent als 3, mit 27 Prozent als 5 und erst an dritter Stelle mit 19 Prozent als 9. Nach sechs Epochen gewinnt die 9 mit 63 Prozent, gefolgt von 15 Prozent für die 3.

Abbildung 6: Beispiele nicht erkannter Ziffern bei MNIST.
Beim dritten Bild tendiert das Netz mit 37 Prozent zu einer 1, gefolgt von 31 Prozent für die richtige Wahl der Ziffer 9. Bei den Zahlen der unteren Reihe scheitert das System. Möglicherweise liegt das aber nicht am Verfahren, sondern an den undeutlich geschriebenen Ziffern 5 (erkannt als 3), 7 (1) und 7 (0).
Eigene Ziffern
Auch bei selbst eingegebenen Ziffern schlägt sich das Netz bemerkenswert gut. Der Umfang aus Abbildung 2 beschränkt sich auf lediglich 100 Proben. Es bietet sich an, die Daten aufzuteilen: Ein Satz für das Training umfasst die Zeichen der ersten neun Zeilen, ein Satz zum Testen enthält die zehn Ziffern der letzten Zeile.
Bereits nach einem Durchlauf identifiziert das Programm vier, nach zehn Runden sechs Ziffern korrekt. Bei so wenigen Zeichen ist eine statistische Aussage unmöglich. Abbildung 7 führt die Grenzen des Trainings vor Augen: In der ersten Zeile war das Programm Imagemagick nicht in der Lage, die Ziffer 0 korrekt zu zentrieren, verursacht durch Überschreiben des Rasters.
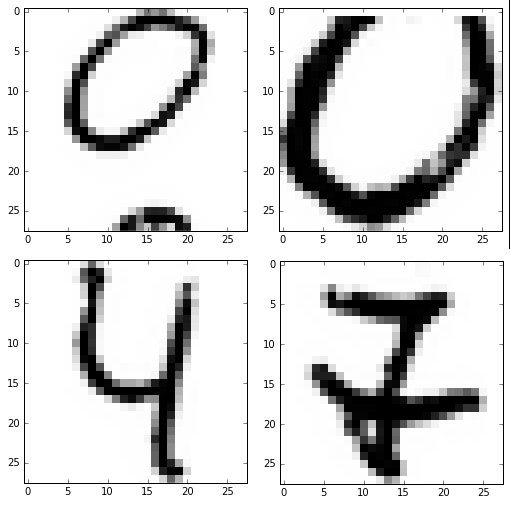
Abbildung 7: Beispiele nicht erkannter Ziffern bei eigenem Zeichensatz.
Zwei der nicht erkannten Ziffern finden sich in der unteren Zeile von Abbildung 7. In der linken sah das Programm mit einer Wahrscheinlichkeit von 32 Prozent eine 9, gefolgt vom korrekten Wert 4 mit 17 Prozent und von 5 und 6 mit jeweils 12 Prozent. Noch schlechter sieht es mit der 7 aus: Hier sieht das neuronale Netz eine 6, 1, 2, 8 oder 5, aber nur zu 3 Prozent eine 7. Ein Training mit mehr und besseren Daten würden die Erkennungsrate allerdings deutlich erhöhen.
Die hier vorgestellten Experimente bieten einen Einstieg in weitere mögliche Versuche. Wie verhält sich das System, wenn Sie es fehlerhaft trainieren? Wie geht es etwa mit der Ziffer 9 um, wenn Sie diese aus dem Trainingsset herausnehmen? Welches Laufzeitverhalten ergibt sich aus einer zu hoch gewählten Trainingsrate?
Wie reagiert ein neuronales Netz, wenn trainierte Knoten ausfallen, also statt 200 nur noch 190 Knoten antworten? Lässt sich diese “Demenz” durch Nachtrainieren ausgleichen? Wie verhält sich das neuronale Netz auf einem Raspberry Pi, wenn es nicht selbst lernen muss, sondern die Knotenwerte von einem trainierten System übernimmt?
Fazit
Bereits hundert Programmzeilen Python-Code konstituieren ein einfaches neuronales Netz. Es lernt anhand kleiner Proben und erkennt handgeschriebene Ziffern. Eigene Experimente visualisieren die Abhängigkeiten von den Trainingsdaten, die aus eigenen Proben stammen. Selbst bei nicht optimiertem Code liegt die Erkennungsrate mit mehr als 10?000 Zeichen pro Minute für viele Zwecke ausreichend hoch. Das Trainieren dauert allerdings etwas länger. Es ist aber nur dann erforderlich, wenn das System neue Zeichen lernt.
Glossar
-
CSV
-
Comma Separated Values. Werte, die durch Kommata oder andere Feldtrenner voneinander abgegrenzt sind.
Infos
-
Grundlage für die Software: https://github.com/makeyourownneuralnetwork
-
Literatur zu Neuronalen Netzen: “Neuronale Netze”, ISBN: 978-3960-090434
-
Konvertierte MNIST-Daten: https://pjreddie.com/projects/mnist-in-csv/
-
Beispiel MNIST-Daten: https://github.com/makeyourownneuralnetwork/makeyourownneuralnetwork/blob/master/part2_neural_network_mnist_data.ipynb
-
Neuronales Netz auf einem Pi Zero: http://makeyourownneuralnetwork.blogspot.de/2017/01/neural-networks-on-raspberry-pi-zero.html




