

Welche Strecken haben Sie im Laufe des Jahres zurückgelegt? Ein paar Python-Bibliotheken sowie OpenLayers verhelfen Ihnen zu einer eigenen OpenStreetMap-Karte.
Der Autor zählt sich zur Klasse der Vielreisenden und digitalen Nomaden [1] beziehungsweise Location Independents [2]. Nachdem bereits 2016 die 100?000-Kilometer-Marke mit Trips durch Europa und Afrika geknackt war, zeichnet sich für 2017 ein ähnliches Bild ab, speziell angesichts der im August 2017 stattfindenden Entwicklerkonferenz DebConf [3] im kanadischen Montreal.
Die Reisen erfolgen entweder bedingt durch Aufträge oder persönliche Interessen. Dabei spielt stets die langjährige Erfahrung als Selbstständiger eine Rolle, um an einem Ort mit einer besonderen Atmosphäre dessen Potenzial voll auszuschöpfen und produktiv tätig zu sein.
Nicht zu vergessen ist die Freude am Kennenlernen und Erleben einer Region. Über das letzte Jahrzehnt hinweg haben sich als bislang bevorzugte Ballungsräume neben der Großstadt Berlin, der Region Bodensee, dem Französisch-Schweizer Jura beziehungsweise der Romandie (Franche Comté/Jura/Vaud) mit den Oberzentren Besançon, Neuchâtel, Genf und Lausanne sowie das Western Cape mit dem Schmelztiegel Cape Town (Kapstadt) herauskristallisiert.
Als Verkehrsmittel kamen in jeweils unterschiedlicher Kombination und Verfügbarkeit Fern-, Stadt- und Nachtbus, Straßenbahn, U- und S-Bahn, Zug, Flugzeug und Schiff beziehungsweise Fähre zum Einsatz. Je nach konkreter Route und Anlass, Motivation, zu überbrückender Distanz, Erfordernis zur Termintreue, Mitreisenden auf der gleichen Strecke, Region, Jahreszeit und Wetterlage variierte diese, gegebenenfalls erfolgte die Reise alternativ mit dem Auto oder zu Fuß [4]. Zweiräder blieben aus persönlicher Abneigung eher ungenutzt.
Meist zum Ende eines Jahres wächst dann die Neugierde, welche Strecken (siehe Kasten “Streckenmessung”) im Laufe der vergangenen zwölf Monate anfielen. Die aufgezeichneten Daten ermöglichen dabei ein genaues Auswerten, so etwa die gesamten Kilometer pro Zeitraum (Jahr, Quartal, Monat, Woche), sowie die längste und kürzeste Strecke oder aber Frequentierung der Orte. Das geschah in der Vergangenheit schon mit einfachen Mitteln (siehe Kasten “Verwandte Beiträge”).
Mit einer überschaubaren Anzahl von Programmzeilen gelang es, die erfassten Strecken statistisch auszuwerten. Zum Einsatz kam dabei die Programmiersprache Python und die auf das Auswerten von Daten spezialisierten Bibliotheken NumPy [5] und Pandas [6]. Mittels Matplotlib [7] war es möglich, die Daten grafisch aufzubereiten. Eine Ansicht auf einer Karte von OpenStreetMap gelang mithilfe der in Javascript entwickelten OpenLayers-Bibliothek [8].
Streckenmessung
Um die direkten Entfernungen zwischen zwei Orten zu erhalten, hilft unter anderem Luftlinie.org [25] weiter (Abbildung 1): Mithilfe der Webseite berechnen Sie neben der Luftlinie zwischen zwei Orten eine mögliche Route über Land unter Einsatz der Maps-API von Google.
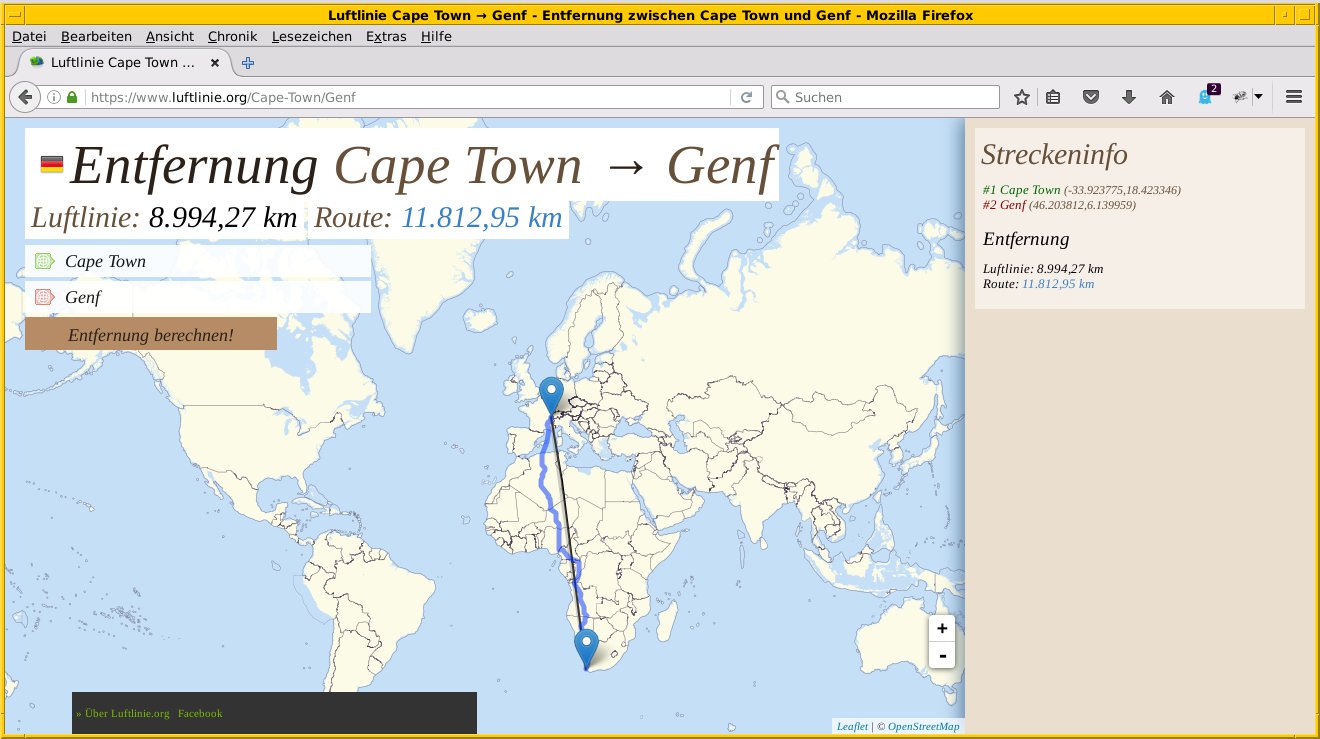
Abbildung 1: Die Webseite Luftlinie.org ermöglicht es, die Strecke zwischen zwei Orten auf verschiedenen Wegen zu berechnen, hier im Beispiel zwischen Cape Town und Genf.
Verwandte Beiträge
Dieser Beitrag schließt inhaltlich an “Sieben Brücken: Fahrtenbuch mit Bordmitteln auswerten” aus LU 05/2016 [26] an. Auf diesen hin gab es bereits vielfältige Rückmeldungen, die von Aha-Effekt bis hin zu Tipps für Verbesserungen reichten. An dieser Stelle vielen Dank für die Anregungen. Sie inspirierten zu weiteren Lösungen sowie zum Vortragsduett mit Harald König [27] auf dem Linux-Day Dornbirn (AT) im November 2016 [28].
Der Beitrag “Punktgenau: Python-Bibliotheken zur Erstellung von Grafiken” aus LU 11/2016 [29] legte die Grundlagen für grafische Auswertungen. Das darin vermittelte Wissen nutzen wir hier für eine Anwendung in der Praxis.
Grundlagen und Datenstrukturen
Die erfassten Strecken bedürfen zunächst einer Struktur. Analog zur bisherigen Herangehensweise kommt dabei der Einfachheit halber eine Tabelle zum Einsatz, die in einer Textdatei liegt. Darin trennen Tabulatoren die einzelnen Felder voneinander (Listing 1). Möglich wären statt der TSV-Variante auch eine CSV-Datei beziehungsweise eine SQL- oder XML-Datenbank.
Als Felder für vielfältige Auswertungen speichert die Tabelle die Abfahrt und Ankunft (als Zeitstempel/Zeitwert), die Strecke, die Distanz in Kilometern, die Kosten für die Fahrt und das gewählte Verkehrsmittel. Weitere Felder wären bei diesem Format problemlos möglich.
Listing 1
Abfahrt Ankunft Von Bis Distanz Verkehrsmittel Kosten 2017-01-01 10:00:00 2017-01-01 10:30:00 Berlin Strausberg 30 S-Bahn 5.00 2017-01-01 10:55:00 2017-01-01 11:25:00 Strausberg Friedrichsfelde 25 S-Bahn 4.00 2017-02-01 10:00:00 2017-02-01 11:25:00 Brandenburg (Havel) Berlin 85 DB 5.20
Das Format der Zeitangaben setzt sich aus dem Datum und der Uhrzeit zusammen [9]. Das hier genutzte Schema besteht aus dem Jahr (vier Ziffern), gefolgt von Monat und Tag in Ziffern mit gegebenenfalls führender Null. Als Trennzeichen fungiert ein Bindestrich. Die Zeitangabe besteht aus Stunde, Minute und Sekunde, jeweils durch einen Doppelpunkt voneinander getrennt.
Das entspricht dem Formatstring %Y-%m-%d %H:%M:%S und vereinfacht später das Auslesen und Verarbeiten mit den Datums- und Zeitfunktionen von Python [10], Perl [11] oder dem Unix-Kommando Date [12]. Eine Auswahl weiterer Formatstrings entnehmen Sie der Tabelle “Mit Format”.
Die Reihenfolge der erfassten Strecken in den Datensätzen spielt keine Rolle: Auch ohne vorherige Sortierung nach dem Zeitpunkt liefert die Software später das korrekte Ergebnis. Den Aufwand beim Sortieren übernehmen die Methoden aus den Bibliotheken.
|
Komponente |
Bedeutung |
Format |
|---|---|---|
|
|
Wochentag |
Name in lokaler Übersetzung |
|
|
Tag |
zwei Ziffern, führende Null |
|
|
Stunde (0-23) |
zwei Ziffern, führende Null |
|
|
Stunde (0-12) |
zwei Ziffern, führende Null |
|
|
Monat |
zwei Ziffern, führende Null |
|
|
Minute |
zwei Ziffern, führende Null |
|
|
Sekunde |
zwei Ziffern, führende Null |
|
|
Kalenderwoche |
zwei Ziffern, führende Null |
|
|
Jahr |
vier Ziffern |
Auswertung und Statistik
Das Python-Skript zum Auswerten umfasst rund 80 Zeilen. Die Logik kommt dabei aus den Python-Modulen fileinput [13], re [14], datetime [10] und numpy [5]. Diese lädt das Skript, nach dem der Interpreter feststeht (Listing 2 Zeile 1), in den Zeilen 3 bis 6.
Das Modul fileinput wertet die Eingabeparameter aus, re dient zum Auswerten von regulären Ausdrücken, und datetime offeriert Funktionen für Daten und Zeiten. Das Modul numpy liefert dagegen die Methoden zum effektiven Auswerten von Datenstrukturen und multidimensionalen Arrays.
Listing 2
#!/usr/bin/python
import fileinput
import re
from datetime import datetime
import numpy as np
init = True
# preparing the data
for line in fileinput.input():
line = re.sub('\n', '', line)
columns = re.split('\t+', line)
if init:
data = np.array([columns])
init = False
else:
columns[0] = datetime.strptime(columns[0], '%Y-%m-%d %H:%M:%S')
columns[1] = datetime.strptime(columns[1], '%Y-%m-%d %H:%M:%S')
data2 = np.array([columns])
data = np.vstack((data, data2))
monthlyRanges = [
['Ganzes Jahr', '2017-01-01 00:00:00', '2017-12-31 23:59:59'],
['Januar', '2017-01-01 00:00:00', '2017-01-31 23:59:59'],
['Februar', '2017-02-01 00:00:00', '2017-02-28 23:59:59'],
['März', '2017-03-01 00:00:00', '2017-03-31 23:59:59'],
['April', '2017-04-01 00:00:00', '2017-04-30 23:59:59'],
['Mai', '2017-05-01 00:00:00', '2017-05-31 23:59:59'],
['Juni', '2017-06-01 00:00:00', '2017-06-30 23:59:59'],
['Juli', '2017-07-01 00:00:00', '2017-07-31 23:59:59'],
['August', '2017-08-01 00:00:00', '2017-08-31 23:59:59'],
['September', '2017-09-01 00:00:00', '2017-09-30 23:59:59'],
['Oktober', '2017-10-01 00:00:00', '2017-10-31 23:59:59'],
['November', '2017-11-01 00:00:00', '2017-11-30 23:59:59'],
['Dezember', '2017-12-01 00:00:00', '2017-12-31 23:59:59']
]
for currentMonth in monthlyRanges:
month, dateFrom, dateTo = currentMonth
dateFromI = datetime.strptime(dateFrom, '%Y-%m-%d %H:%M:%S')
dateToI = datetime.strptime(dateTo, '%Y-%m-%d %H:%M:%S')
print (" ")
print ("----------------------------------------------------")
print (month, dateFromI, dateToI)
print ("----------------------------------------------------")
fromColumn = np.array(data[1:,0:1])
toColumn = np.array(data[1:,1:2])
mask = (fromColumn >= dateFromI) & (toColumn < dateToI)
if mask.any():
# convert mask into list
newFilter = mask.ravel()
stripe = np.compress(newFilter, data[1:], axis=0)
# calculate the total travelling distance
# - select the 5th column except the 1st row
# - convert strings into 32bit integer
distanceColumn = np.array(stripe[:,4], dtype=np.int32)
# count the distances
total = np.sum(distanceColumn)
print ("Gesamt : %i km" % (total))
# count number of travels
number = np.size(distanceColumn)
print ("Anzahl Fahrten : %i" % (number))
# find shortest travel
shortest = np.argmin(distanceColumn)
shortestFrom = stripe[shortest][2]
shortestTo = stripe[shortest][3]
shortestDistance = stripe[shortest][4]
print ("Kürzeste Strecke: %s nach %s mit %s km" % (shortestFrom, shortestTo, shortestDistance))
# find longest travel
longest = np.argmax(distanceColumn)
longestFrom = stripe[longest][2]
longestTo = stripe[longest][3]
longestDistance = stripe[longest][4]
print ("Längste Strecke : %s nach %s mit %s km" % (longestFrom, longestTo, longestDistance))
In den Zeilen 11 bis 21 liest das Skript die Eingabe zeilenweise ein und überführt sie in die interne Datenstruktur. Die Methode fileinput.input() verarbeitet dabei zunächst die Parameter. Rufen Sie das Python-Skript ohne Datei als Parameter auf, liest es stattdessen von der Standardeingabe.
Mithilfe der Methode sub() aus dem Modul re entfernt es danach in der Zeile 15 das Zeilenendezeichen \n – genauer: es ersetzt dieses durch nichts. Mittels split() trennt es anschließend die gelesene Zeile in einzelne Spalten auf. Als Trennzeichen fungiert der Tabulator, der über den regulären Ausdruck '\t+' [15] festgelegt ist und daher einmal oder mehrfach auftreten darf. Die Variable spalten enthält das Ergebnis und besteht aus einer Liste mit den jeweiligen Inhalten.
Die Zeilen 14 bis 21 befüllen die Datenstruktur. Beim Einlesen der ersten Zeile der Eingabe – der Header-Zeile aus der zuvor gelesenen Datei – legt das Skript die Datenstruktur data an. Als Indikator dafür dient die Variable init, die initial auf True steht. Nach dem Verarbeiten der Kopfzeile ändert das Skript das zu False. Zum Befüllen von data kommt die Methode array() aus dem NumPy-Modul zum Einsatz.
Anschließend wandelt das Skript jeweils die erste und zweite Spalte der aktuellen Zeile in ein Datetime-Objekt um. Dabei hilft die Methode strptime(), die den Zeitstempel gemäß des Formatstrings in einzelne Werte zerlegt (“string parse time”). Danach fügt es die Spalten zum bestehenden Feld data. Die Methode vstack() steht hier für das vertikale Anfügen der neuen Struktur an das untere Ende von data.
In den Zeilen 23 bis 37 sind Zeitabschnitte als Liste hinterlegt. Das umfasst das ganze Jahr sowie die einzelnen Monate, Letztere der Verständlichkeit halber fest integriert. Sie ließen sich aber auch ad hoc berechnen. Bei den Einträgen kommt dasselbe Format zum Einsatz wie in der Datei.
Die in Zeile 39 beginnende For-Schleife iteriert danach über jeden Eintrag aus der Liste der Zeitabschnitte, um die Daten für die jeweiligen Monate auszuwerten. Zeile 40 enthält eine Kurzschreibweise und weist jeder der drei Variablen den entsprechenden Wert aus der entsprechenden Spalte des Zeitabschnitts zu.
In den Zeilen 41 bis 46 erfolgt zunächst eine Interpretation der Zeichenkette als Zeitstempel. Danach schließt sich eine Ausgabe einer Zwischenüberschrift mit den Angaben für den Zeitabschnitt an.
In den Zeilen 47 und 48 entnimmt das Skript Teilmengen aus data. Die Schreibweise data[1:,0:1] extrahiert die erste Spalte (mit dem Datum für die Abfahrt) ab der ersten Zeile. Mit data[1:,1:2] fischt es dann die zweite Spalte mit der Ankunftszeit heraus.
Zeile 49 erzeugt eine Liste von Wahrheitswerten aus True und False. True heißt, dass der überprüfte Zeitstempel der Spalte im gerade betrachteten Zeitintervall liegt; False besagt, er liegt außerhalb. Die Länge der Liste entspricht der Anzahl von Daten. Weil die Datentypen der Variablen in den extrahierten Spalten mit den Grenzen des Intervalls identisch sind, führt die verwendete Schreibweise des Vergleichs zum Erfolg.
In Zeile 51 wertet die Methode any() aus, ob es in der Liste mit den Wahrheitswerten überhaupt Einträge mit True gibt. Falls nicht, gibt es nichts zu tun. Dann überspringt das Skript die restlichen Schritte und untersucht das nächste Intervall. Gab es jedoch einen Treffer, ermittelt es nachfolgend die kürzeste beziehungsweise längste Strecke im aktuellen Intervall.
In Zeile 53 wandelt die Methode ravel() die Maske in eine Liste um, die sich dazu eignet, sie mit der Methode compress() zu verarbeiten. Mit deren Hilfe reduziert das Skript in Zeile 54 das Datenfeld data auf jene Elemente, die dem Zeitfenster entsprechen, sprich: in Zeile 49 zu True geführt haben. Als Filter fungiert hier die Liste der vorher generierten Wahrheitswerte. Die Schreibweise data[1:] betrachtet dabei alle Zeiträume außer dem ersten Eintrag, da an dieser Stelle das gesamte Jahr keine Rolle spielt.
Zeile 59 extrahiert die Spalte, die den Wert für die Distanz enthält. Die Schreibweise stripe[:,4] entnimmt aus allen Zeilen die fünfte Spalte (da 0 die erste Spalte repräsentiert). Die Angabe des Datentyps wandelt im gleichen Schritt alle Werte in Integer um. Das ermöglicht das Aufsummieren der Spalte in Zeile 62 mittels sum() und somit das Berechnen der Gesamtsumme in einem einzigen Schritt.
In Zeile 66 hilft die Methode size(), die Anzahl der Fahrten zu ermitteln. size() zählt die Länge einer Liste und entspricht hier der Anzahl der zurückgelegten Fahrten.
Um die kürzeste Strecke zu ermitteln, kommt in Zeile 70 die NumPy-Methode argmin() zum Einsatz. Auf die Spalte mit den Distanzen angewendet, liefert sie den Index des Elements mit dem kleinsten Wert und somit die kürzeste Strecke. Analog fungiert argmax() in Zeile 77 für die längste Strecke. Am Ende erfolgt die Ausgabe der kürzesten und längsten Strecke im Intervall. Listing 3 zeigt die Auswertung für den Juni 2016.
Listing 3
$ cat fahrten-2016-detailliert.txt | python3 distanz.py
...
----------------------------------------------------
Juni 2016-06-01 00:00:00 2016-06-30 23:59:59
----------------------------------------------------
Gesamt : 1150 km
Anzahl Fahrten : 11
Kürzeste Strecke: Berlin nach Potsdam mit 30 km
Längste Strecke : Zürich nach Berlin mit 850 km
[...]
Grafik mit Matplotlib
Als Nächstes geht es darum, die Daten als Grafik aufzubereiten. Nachfolgend geschieht das anhand der Kilometer in Form von Staffelbalken, aufgeschlüsselt nach den Monaten. Dabei verwendet die Grafik für jede Route eine eigene Farbe, die sich aus dem Schema ergibt, das im Plot-Aufruf steht.
Das dazu verwendete Python-Programm hat die gleiche Basis wie zuvor. Die ersten etwa 40 Zeilen fallen daher identisch aus wie in Listing 2 bis auf zwei Zeilen, die Sie im Header ergänzen (Listing 4, Zeile 7 und 8). Damit binden Sie die noch fehlenden Bibliotheken Matplotlib.pyplot und Pandas ein.
In Zeile 43 folgt aber nun ein leeres Array namens travelRoutes, das Stück für Stück die Daten aus data aufnimmt. Analog zum ersten Teil erfasst es in Zeile 45 mithilfe der Schreibweise data[1:] alle Zeilen außer dem Header. Mithilfe der Methode unique() ermittelt das Skript alle Routen aus unserer Liste (Zeile 50). Das vereinfacht das nachfolgende Auswerten.
Listing 4
07 import matplotlib.pyplot as plt
08 import pandas as pd
[...]
42 # define travel routes
43 travelRoutes = np.array([])
44
45 for entry in data[1:]:
46 route = np.array("%s->%s:%s" % (entry[2], entry[3], entry[4]))
47 travelRoutes = np.hstack((travelRoutes, route))
48
49 # remove double entries
50 travelRoutes = np.unique(travelRoutes)
51 # print (travelRoutes)
52
53 # extract descriptions for every month
54 month = monthlyRanges[1:, 0:1]
55
56 # convert array into list
57 month = np.ravel(month)
58
59 # define number of travels per month
60 # - init with zeros
61 numberOfTravels = np.zeros((travelRoutes.size, month.size), dtype = np.int32)
62
63 for entry in data[1:]:
64 # find list id for the travel route
65 route = np.array("%s->%s:%s" % (entry[2], entry[3], entry[4]))
66 travelRouteId = np.where(travelRoutes == route)[0][0]
67
68 # extract travel data
69 travelRouteDateFrom = entry[0]
70 travelRouteDateTo = entry[1]
71
72 monthId = 0
73 for entry in monthlyRanges[1:]:
74 # extract month data range
75 monthDateFrom = datetime.strptime(entry[1], '%Y-%m-%d %H:%M:%S')
76 monthDateTo = datetime.strptime(entry[2], '%Y-%m-%d %H:%M:%S')
77
78 # validate route for being in month range
79 if ((travelRouteDateFrom >= monthDateFrom) and (travelRouteDateFrom <= monthDateTo)):
80 if ((travelRouteDateTo >= monthDateFrom) and (travelRouteDateTo <= monthDateTo)):
81 numberOfTravels[travelRouteId][monthId] += 1
82 break
83 monthId += 1
84 # print (numberOfTravels)
85
86 # define distance per entry
87 distances = np.array([])
88 entryId = 0
89 travelDescription = []
90 for entry in travelRoutes:
91 columns = re.split(':', entry)
92 factor = int(columns[1])
93
94 distances = np.append(distances, [numberOfTravels[entryId] * factor])
95 entryId += 1
96
97 travelDescription.append(columns[0])
98
99 # re-arrange the distances array
100 distances = np.reshape(distances, (travelRoutes.size,month.size))
101 distances = distances.swapaxes(1,0)
102
103 # create data frame
104 df = pd.DataFrame(distances,
105 index=month,
106 columns=pd.Index(travelDescription))
107
108 # plot the data frame as stacked, horizontal bars
109 df.plot(kind='barh', stacked=True, colormap='Set1')
110
111 # display the data frame
112 plt.show()
Ein Feld namens numberOfTravels repräsentiert die Häufigkeit einer Route pro Zeitabschnitt. Alle Elemente darin initialisieren wir mithilfe der NumPy-Methode zeros() zunächst mit null (Listing 4, Zeile 61), da wir bislang noch nicht wissen, wie häufig eine Route bereist wurde, und wir zudem für das Berechnen einen definierten, nicht negativen Wert als Basis benötigen.
Um alle Möglichkeiten korrekt abzubilden, ergibt sich die Größe des Felds numberOfTravels aus der Anzahl der Monate mal der Anzahl der Routen. Die Namen der Monate extrahiert die Anweisung in Zeile 54, zur Menge verhilft die Methode size() (Listing 4, Zeile 61).
Im Feld numberOfTravels dürfen ausschließlich positive, ganzzahlige Werte stehen. Daher enthält die Methode zeros() beim Aufruf mit dtype = np.int32 eine explizite Angabe des Typs für Integer. Die folgende For-Schleife (Zeile 63 bis 83) ermittelt die jeweiligen Häufigkeiten der Routen.
Der Eintrag im Feld kommt über die Routen-ID und die ID des Monats zustande. Dabei nutzt das Skript in Zeile 66 die NumPy-Methode where(), die den korrekten Index des Eintrags in der Liste der Routen berechnet. Den richtigen Monat ermittelt es über einen Abgleich des Datums der Reise mit dem gerade betrachteten Intervall.
Die Zeilen 87 bis 97 dienen dazu, die Anzahl der Kilometer zu berechnen. Dazu multipliziert die Anweisung lediglich die Häufigkeit einer Route mit den Kilometern pro Strecke aus numberOfTravels sowie der Streckenlänge.
Die Streckenlänge steckt im Zahlenwert nach dem : im Eintrag einer Route. Mithilfe der Methode split() teilt das Skript zunächst den Eintrag auf und entnimmt zweite Spalte (Index 1). Mittels append() fügt es die in Listing 4 in Zeile 94 errechnete Wegstrecke ans Ende des Felds distances an. Gleiches geschieht mit der Beschreibung der Route in Zeile 97.
Danach folgen zwei kleine Tricks: das Skalieren des Felds mit dem Wert für die Distanz mittels reshape() sowie das Vertauschen der Koordinatenachsen mittels swapaxes(). Das sorgt für die korrekten Paare aus den gereisten Strecken pro Monat. Damit gelingt später das passende Plotten der aufsummierten Daten mit den Distanzen auf der x-Achse und den Monaten auf der y-Achse.
Die Zeilen 104 bis 106 erzeugen ein Objekt vom Typ pandas.DataFrame, das alle Daten für die Grafik enthält. Das umfasst die Entfernungswerte, die Indizes für Bezeichnungen der Monate sowie die Beschreibungen der Routen. Daraus entstehen die Beschriftungen für die beiden Achsen sowie die Legende mit den Routen samt der kleinen, farblich zum Balken passenden Box.
Die Methode plot() in Zeile 109 erzeugt zunächst die Grafik. Die Methode show() aus dem Matplotlib-Modul, die in Zeile 112 zum Einsatz kommt, zeigt diese dann in einem Fenster an. Ohne den Aufruf von show() sehen Sie nichts.
Die Funktion plot() benötigt zum Erstellen die gewünschte Form der Grafik – hier barh für horizontale Balken. Mit stacked=True weisen Sie die Software an, die Balken gestaffelt zu generieren. Für die individuellen Farben pro Route sorgt der Parameter colormap mit der Angabe eines bestehenden Farbsets. Zur Auswahl stehen diverse Spektren und Übergänge. Falls Ihnen die bestehenden Zusammenstellungen nicht zusagen, definieren Sie ein eigenes Schema [16].
Rufen Sie das Python-Skript nun auf. Im Beispiel aus Abbildung 2 ragt die Legende mit den Routen über die Grafik hinaus, da der Bereich mit den Staffelbalken für die hohe Anzahl der Routen zu klein ausfällt. Da gilt es dann, exzessiv an den Parametern für die Anzeige der Grafik und der Legende [17] zu drehen – etwa der Schriftgröße, den Abständen in der Box und deren Position [18].
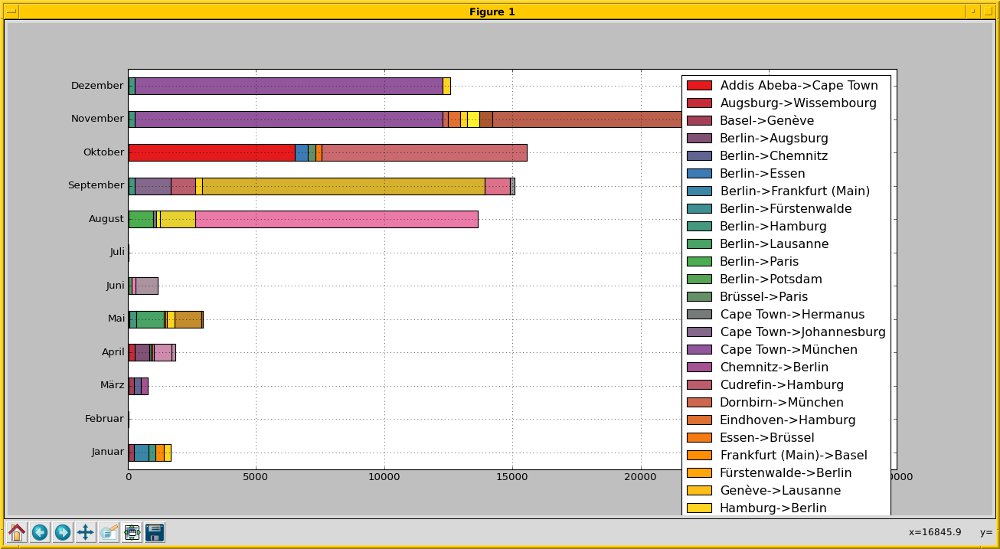
Abbildung 2: Um die Reisen zu vergleichen, bietet es sich an, diese nach Monaten aufgeschlüsselt als Balkengrafik zu erzeugen.
Eigene Landkarte
Jetzt fehlt noch die Anzeige der Orte auf einer Landkarte. Das gelingt mithilfe des Projekts OpenLayers [8] und einer passenden Karte von OpenStreetMap.
Für jeden Ort benötigen Sie Zusatzinformationen, die im Beispiel zeilenweise in einer Datei lagern (Abbildung 3). Sie umfasst die vier Spalten Geo-Koordinaten (aus Breiten- und Längengrad), Ort, erweiterter Ort und Bild. Als Trennzeichen zwischen den vier Spalten fungiert jeweils ein Tabulator.

Abbildung 3: Eine Textdatei nimmt zusätzlich Informationen zu den Orten auf, wie etwa deren geografische Koordinaten. Dies dient dazu, diese mittels OpenLayers auf einer Karte von OpenStreetMap anzuzeigen.
Die Koordinaten erhalten Sie etwa über den entsprechenden Wikipedia-Eintrag oder alternativ über Online-Dienste wie Latlong.net [19], Find Latitude and Longitude [20], GeoHack [21], Nominatim [22] beziehungsweise die Mapquest Open Search (Nominatim) API [23]. Beachten Sie dabei die Reihenfolge der publizierten Angaben – während Wikipedia und GeoHack zuerst den Breitengrad und danach den Längengrad benennen, handhaben das andere Dienste und APIs umgekehrt. Das betrifft insbesondere die Methoden der Versionen 2 und 3 der OpenLayers-Bibliothek.
Das Erzeugen der Karte erfolgt mit einer Kombination aus HTML und Javascript. Der Einfachheit halber laden Sie zunächst das OpenLayers2-Framework von der Webseite herunter und entpacken das erhaltene Archiv im Arbeitsverzeichnis. Darin befindet sich ein Ordner namens examples, in dem Sie das Beispiel aus Listing 5 ergänzen. Das erfolgt in Form von zwei Dateien: die bereits angesprochene Datei mit den Koordinaten der Orte und die HTML-Datei für das Anzeigen der Karte.
Listing 5
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Reiseorte 2016</title>
<link rel="stylesheet" href="../theme/default/style.css" type="text/css">
<link rel="stylesheet" href="style.css" type="text/css">
<script src="../lib/OpenLayers.js"></script>
<script type="text/javascript">
function init(){
// map
map = new OpenLayers.Map('map');
layer = new OpenLayers.Layer.WMS("OpenLayers WMS",
"http://vmap0.tiles.osgeo.org/wms/vmap0",
{layers:'basic'} );
map.addLayer(layer);
// locations
var locations = new OpenLayers.Layer.Text( "Locations", {location:"./koordinaten.txt"} );
map.addLayer(locations);
// zoom to maximal size
map.zoomToMaxExtent();
}
</script>
</head>
<body onload="init()">
<h1 id="title">Reiseorte 2016</h1>
<div id="map" class="smallmap"></div>
</body>
</html>
Die Zeilen 1 bis 8 bilden den HTML-Header samt Referenz zu den Schnipseln des OpenLayers-Codes. Der Javascript-Teil ab Zeile 9 enthält eine Funktion namens init(), die der Browser beim Laden der HTML-Seite aufruft. Die Zeilen 12 bis 15 definieren zwei Variablen namens map und layer. Erstere enthält die gesamte Karte, die zweite die Ebene mit dem Kartenstil. Zeile 15 fügt die Ebene zur Karte hinzu.
Die Zeilen 17 bis 19 ergänzen die Orte zur Karte. Die Variable locations enthält eine Ebene für Text, wobei diese die Namen der Orte aus der Datei koordinaten.txt bezieht. Der Befehl in Zeile 22 sorgt dafür, dass der Browser die Karte maximiert.
Zeile 26 bis 29 beschreiben den Inhalt der HTML-Seite. Zeile 26 ruft die zuvor deklarierte Javascript-Funktion namens init() auf, sobald der Webbrowser die Seite lädt. Zeile 27 enthält die Überschrift der Seite, Zeile 28 definiert ein Div-Element mit einem Stil namens smallmap (definiert in einer der CSS-Dateien des OpenLayers-Frameworks). Das sorgt dafür, dass die Seite die Landkarte anzeigt, sobald Sie die HTML-Datei im Webbrowser laden (Abbildung 4).
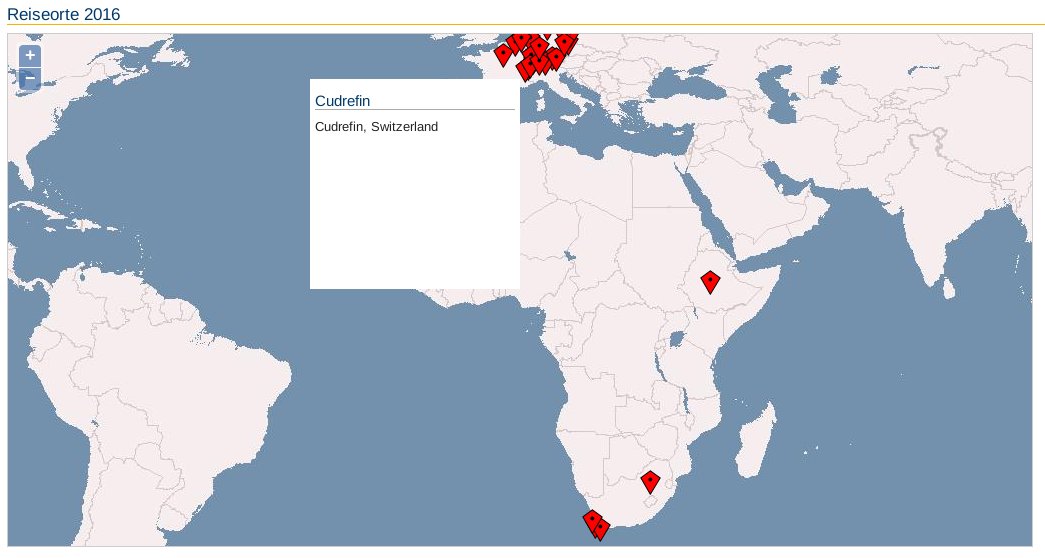
Abbildung 4: Haben Sie alle Daten korrekt hinterlegt, genügen etwas Programmcode sowie eine Bibliothek von OpenLayers, um die Reiseorte samt Detailinformationen auf einer Landkarte anzuzeigen.
Klicken Sie auf einen der roten Marker, öffnet sich ein weißes Fenster für Zusatzinformationen; in Abbildung 4 jene zu Cudrefin unweit von Bern. Das Fenster zeigt die Informationen an, die Sie in der dritten Spalte der zusätzlichen Datei zu den Reiseorten hinterlegt haben.
Fazit
Das Auswerten und Anzeigen der erfassten Daten erfolgt mit vergleichsweise wenig Skript-Logik. Dabei hilft der große Funktionsumfang der Python-Bibliotheken. Wie so oft ließe sich auch hier am Code noch vieles vereinfachen oder verändern. Auch das Erzeugen der grafischen Elemente auf einer OSM-Karte lässt sich einfach stemmen: Dass hier OpenLayers in der Version 2 zum Einsatz kam, liegt daran, dass sich trotz erheblichem Aufwands mit der aktuelleren Version 3 nicht das erwartete Ergebnis erzielen ließ [24]. Anregungen und Verbesserungen zum vorgestellten Beispiel nimmt der Autor gern entgegen.
Danksagung
Der Autor bedankt sich bei Mandy Neumeyer, Lars Lingner und Axel Beckert für ihre Kritik und Anregungen im Vorfeld dieses Artikels.
Über den Autor
Frank Hofmann arbeitet von unterwegs, bevorzugt von Berlin, Genf und Kapstadt aus, als Entwickler, Trainer und Autor. Er ist zudem Koautor des Debian-Paketmanagement-Buchs [30].
Infos
-
Digitale Nomaden: F.Hofmann, M.Neumeyer, “Geeks on Tour”, LU 05/2017, S. 16, https://www.linux-community.de/38125
-
Digitale Nomaden (Wikipedia): https://de.wikipedia.org/wiki/Digitaler_Nomade
-
DebConf 2017: http://www.debconf.org
-
Frank Hofmann – Strecken bei Gpsies: http://www.gpsies.com/mapUser.do?username=FrankHofmann
-
NumPy: http://www.numpy.org
-
Pandas: http://pandas.pydata.org
-
Matplotlib: http://matplotlib.org
-
OpenLayers: http://openlayers.org
-
Epoch Unix Time Stamp Converter: http://www.unixtimestamp.com
-
Python-Modul Datetime: https://docs.python.org/3.6/library/datetime.html
-
Perl-Datetime-Modul: http://search.cpan.org/~drolsky/DateTime-1.42/lib/DateTime.pm
-
“Unix Date Format Examples”: http://www.adminschoice.com/unix-date-format-examples
-
Python-Modul Fileinput: https://docs.python.org/3.6/library/fileinput.html
-
Python-Modul Re: https://docs.python.org/3.6/library/re.html
-
Regular Expressions: Frank Hofmann, “Schnipseljagd”, LU 09/2011, S. 84, https://www.linux-community.de/24091
-
“How to give a pandas/matplotlib bar graph custom colors”: http://stackoverflow.com/questions/11927715/how-to-give-a-pandas-matplotlib-bar-graph-custom-colors
-
Matplotlib Legend Guide: http://matplotlib.org/users/legend_guide.html
-
“How to adjust the size of matplotlib legend box?”: http://stackoverflow.com/questions/20048352/how-to-adjust-the-size-of-matplotlib-legend-box
-
Latlong.net: http://www.latlong.net
-
“Find Latitude and Longitude”: http://www.findlatitudeandlongitude.com
-
GeoHack: https://tools.wmflabs.org/geohack
-
Nominatim: http://nominatim.openstreetmap.org
-
Mapquest Open Search (Nominatim) API: https://developer.mapquest.com/documentation/open/nominatim-search
-
“OpenLayers 3 Beginner’s Guide”: http://openlayersbook.github.io
-
Distanzen berechnen (Luftlinie): https://www.luftlinie.org
-
Fahrtenbuch auswerten: Frank Hofmann, “Sieben Brücken”, LU 05/2016, S. 62: https://www.linux-community.de/36800
-
Fahrtenbuch mit Skripten auslesen: H.König, F.Hofmann, Vortrag auf dem Linux-Day Dornbirn 2016: https://www.linuxday.at/sieben-bruecken-fahrtenbuch-mit-skripten-auslesen
-
“Sieben Brücken” (Video): H.König, F.Hofmann, “Fahrtenbuch mit Skripten auslesen”, Linux-Day Dornbirn, 2016: https://www.youtube.com/watch?v=C77nn6eLsPc
-
Datenvisualisierung: Frank Hofmann, “Punktgenau”, LU 11/2016, S. 82: https://www.linux-community.de/37664
-
Debian-Paketmanagement-Buch: http://www.dpmb.org




