

Computer wurden ursprünglich als Rechenmaschinen entwickelt. Am Beispiel eines Fahrtenbuchs zeigen wir, wie Sie mit Bordmitteln das Maschinchen zu Ihren Gunsten werkeln lassen. Dabei stellen wir Ihnen sieben Varianten der Problemlösung vor.
Wer viel unterwegs ist, führt meist ein Fahrtenbuch, in dem er jede einzelne Tour vermerkt – sei es aus persönlichem Interesse, für die Steuererklärung oder für den Arbeitgeber. In vielen Fällen genügt am Ende lediglich die Angabe der Gesamtkilometerzahl. Doch wie errechnet man das am geschicktesten, also ohne viel Aufwand?
Dafür ein gesondertes Programm zu erwerben oder zu installieren erscheint zu viel des Guten. Die nachfolgend vorgestellten Lösungen demonstrieren, wie Sie das Problem(chen) mit Werkzeugen lösen, die meist sowieso auf dem System installiert sind, auch wenn Sie das vielleicht noch nicht unbedingt bewusst wahrgenommen haben.
Der Fokus der Lösungen liegt dabei auf Kompaktheit, Standardkonformität (also die Nutzung stets verfügbarer Standardmodule) und Verständlichkeit. Dabei haben wir die einzelnen Varianten nicht auf das letzte Bit optimiert, aber so zusammengestellt, dass Sie auch nach längerer Zeit noch verstehen, was vor sich geht.
In die hier umgesetzten Varianten fließen Ideen mit ein, die Teilnehmer der vom Autor durchgeführten LPIC-1/Unix/Linux-Kurse [1] fabriziert haben. Dabei handelt es sich zum Teil um sehr kompakte, durchdachte Lösungen – Vielfalt als Anregung sozusagen. Alle Lösungen funktionieren und liefern das korrekte Ergebnis, bedürfen aber unterschiedlich langer Erklärungen und (Vor-)Wissen, um den mitunter recht kryptisch wirkenden Programmcode zu verstehen.
Das hier gezeigte Beispiel und die Lösungen lassen sich auch gut auf andere Themen übertragen, etwa auf Rechnungen (Kassenzettel beziehungsweise den Warenkorb eines Internetshops) oder Download-Statistiken (Häufigkeit des Zugriffs für bereitgestellte Inhalte einer Webseite).
Ausgangsbasis Text
Den Ausgangspunkt für die Berechnungen bildet eine schlichte Textdatei, die über fünf Spalten verfügt: die Häufigkeit der Strecke (Anzahl), den Startpunkt (Von), das Fahrtziel (Nach), die Einzeldistanz (Distanz) und den Grund für die Fahrt. Die erste Zeile beinhaltet eine Kopfzeile, danach folgen zeilenweise die Daten für die gefahrene Strecke.
Die Textdatei heißt hier schlicht und einfach fahrtenbuch.txt. Damit das Fahrtenbuch hübsch aussieht, wenn Sie es ausdrucken, erlaubt das verwendete Format eine variable Anzahl von Tabulatoren zwischen den Spalten. Auf diese Weise erscheinen bei Anzeige und Druck alle erfassten Inhalte ordentlich neben- und untereinander (Abbildung 1).
Abbildung 1: Eine variable Anzahl von Tabulatoren sorgt bei Anzeige und Ausdruck für ein manierliches Erscheinungsbild des Fahrtenbuchs.
Shell
Der erste Gedanke führt zu einem beherzten Griff in den Werkzeugkasten Ihres Linux-Systems. Listing 1 flanscht daraus die Werkzeuge Cat, Tail, Awk, Tr, Sed und Bc aneinander. Jedes davon wirkt als Filter für den übergebenen Datenstrom und verändert diesen, jedoch nicht die Originaldatei.
Cat liest die Datei mit dem Fahrtenbuch und gibt deren Inhalt auf STDOUT aus. Über eine Pipe (|) leiten Sie die Ausgabe an Tr weiter. Dieses ersetzt im Datenstrom alle mehrfach vorkommenden Tabulatoren (-s '\t') durch einen Doppelpunkt – ein Trennzeichen, das im Fahrtenbuch ansonsten nicht vorkommt.
Danach übergibt eine weitere Pipe den so modifizierten Datenstrom an Tail. Mit dem Schalter --lines=+2 sorgen Sie dafür, dass Tail erst ab der zweiten Zeile zu lesen beginnt und damit die für die Berechnung der Gesamtdistanz überflüssige Kopfzeile entsorgt.
Der verkürzte Datenstrom fließt wiederum über eine Pipe weiter an Awk [2], das sich jetzt auf die einzelnen Spalten stürzt. Mit dem Schalter -F : interpretiert es den Doppelpunkt als Trennzeichen zwischen den einzelnen Spalten. Über den Ausdruck '{print $1 * $4}' entnimmt Awk jeder Zeile die erste und die vierte Spalte, multipliziert die dort enthaltenen Werte und gibt das errechnete Produkt wieder auf STDOUT aus.
Jetzt liegen alle Zwischenergebnisse für die einzelnen Touren vor – jedes auf einer einzigen Zeile, die mit einem Zeilenumbruch (\n) abschließt. Um die Werte zu addieren, wollen wir am Ende Bc nutzen. Dieses Tool muss aber noch wissen, was es mit den Einzelwerten machen soll – es benötigt also jeweils einen Operator zwischen den Einzelwerten.
Mithilfe von Tr ersetzen Sie daher nun im Datenstrom alle vorkommenden Zeilenumbrüche (\n) durch ein schlichtes Plus (+). Auf diese Weise erhalten wir eine einzige Zeile mit einem mathematischen Ausdruck, den Bc später verarbeiten kann.
Mit der vorherigen Operation haben wir allerdings auch den letzten Zeilenumbruch eliminiert. Das bügeln wir mithilfe des Stream-Editors Sed [3] wieder aus, da Bc sonst ein Operand zur Berechnung fehlt. Der reguläre Ausdruck [4]'s/+$/+0\n/' sucht nach einem Plus-Zeichen direkt vor einem Zeilenende und ersetzt diese beiden Zeichen durch ein +, gefolgt von einer Null und einem Zeilenumbruch.
Das verändert die Gesamtdistanz nicht und sorgt gleichzeitig für korrekten Ausdruck sowie einen Zeilenumbruch am Ende. Letzteren benötigt Bc als Zeilenabschluss, um die ganze Zeile aufzusummieren. Das Gesamtergebnis gibt es schlussendlich wieder auf STDOUT aus.
Listing 1
$ cat fahrtenbuch.txt \
> | tr -s '\t' ':' \
> | tail --lines=+2 \
> | awk -F : '{print $1 * $4}' \
> | tr '\n' '+' \
> | sed 's/+$/+0\n/' \
> | bc
1740
TIPP
In Listing 1 haben wir der Übersichtlichkeit halber auf der Konsole alle Einzelbefehle der Fahrtenbuch-Toolchain in einer eigenen Zeile eingegeben und jeweils durch [Eingabe] bestätigt. Dabei dient der Backslash (\) in jeder Zeile quasi als Fortsetzungszeichen und weist die Shell an, die folgende Eingabe als Teil der vorigen Zeile zu behandeln. Sie können stattdessen auch die Backslashes weglassen und alle Kommandos in einer einzigen Zeile angeben.
Awk
Das Verketten der vielen Einzelbefehle verursacht einige Tipparbeit. Die lässt sich jedoch reduzieren, indem man Awk sozusagen pur benutzt. Dazu definieren Sie wie in Listing 2 gezeigt drei Blöcke mit Anweisungen, jeweils eingerahmt von geschweiften Klammern.
Listing 2
BEGIN { FS="\t+" }
{ gesamt += $1 * $4 }
END {printf "Gesamt: %d km\n", gesamt}
Im ersten Block legen Sie nach dem Schlüsselwort BEGIN das zu verwendende Trennzeichen fest. Dazu setzen Sie die Awk-Variable FS (“file separator”) auf \t+, also eine Zeichenfolge aus einem oder mehreren Tabulatoren.
Im zweiten Block definieren Sie eine Variable gesamt, wobei Sie Awk anweisen, aus jeder gelesenen Zeile die erste und vierte Spalte zu entnehmen und deren Werte miteinander zu multiplizieren. Den ermittelten Einzelwert addieren Sie über den Operator += zur Variablen hinzu. Beinhaltet eine gelesene Spalte einen Text, ergibt dessen Umwandlung zur Zahl den Wert null. Daher bedarf es hier keiner gesonderten Behandlung der Kopfzeile.
Vor dem dritten Block steht das Schlüsselwort END und markiert das Ende der Aktionen pro gelesener Zeile. Anschließend erfolgt die Ausgabe mithilfe der Funktion printf(). Die Zeichenkette %d steht für “digit”, also einen Zahlenwert. Awk ersetzt sie im Aufruf durch den errechneten Zahlenwert von gesamt.
Am besten speichern Sie das Awk-Skript als Datei distanz.awk, sodass es sich wiederholt benutzen lässt. Dann starten Sie die Berechnung mit dem Aufruf aus Listing 3. Dabei weist der Schalter -f Awk an, zur Verarbeitung das Skript aus der angegebenen Datei zu entnehmen. Der Aufruf geht davon aus, dass sich Daten und Awk-Skript im aktuellen Verzeichnis befinden. Liegen sie an anderen Stellen des Dateisystems, müssen Sie die entsprechenden Pfade mit angeben.
Listing 3
$ awk -f distanz.awk fahrtenbuch.txt Gesamt: 1740 km
Perl
Auch mithilfe diverser verbreiteter Skriptsprachen lässt sich die Gesamtdistanz recht unkompliziert errechnen. Wir demonstrieren das im Folgenden für die drei Vertreter Perl [5], Python [6] und Tcl [7].
Das Perl-Skript aus Listing 4 überprüft in Zeile 2 zuerst, ob Sie beim Aufruf Parameter angegeben haben – falls nicht, bricht es kommentarlos ab. Zeile 3 definiert die Variable gesamt für die Gesamtsumme und initialisiert sie mit dem Wert null.
Listing 4
#!/usr/bin/perl
exit unless @ARGV;
my $gesamt = 0;
while(<>) {
my @felder = split(/\t+/);
$gesamt += $felder[0] * $felder[3];
}
print "Gesamt: $gesamt km\n"
Die While-Schleife in den Zeilen 4 bis 7 verarbeitet den Eingabestrom, der entweder aus einer angegebenen Datei oder aus dem Kanal STDIN kommen darf. Jede empfangene Zeile zerlegt das Skript mittels split() anhand der Tabulatoren in einzelne Spalten und speichert diese in der Liste @felder (Zeile 5). Dazu nutzt split() den bereits bekannten regulären Ausdruck \t+, der wieder eine Zeichenfolge aus mindestens einem Tabulator repräsentiert.
Die Distanz pro Fahrt errechnet sich dann aus dem Inhalt des ersten und vierten Feldes (Zeile 6). Beachten Sie hier, dass die Zählung der Indizes für die Felder mit null beginnt – bei den obigen Lösungen begann sie mit eins. Zeile 6 addiert die Distanz pro Fahrt zur bestehenden Gesamtdistanz hinzu, Zeile 8 gibt dann die gefahrene Gesamtstrecke aus.
Für den Aufruf des Skripts ergeben sich die vier Möglichkeiten aus Listing 5, sodass Sie das Skript flexibel in einen weiteren Ablauf integrieren können. Lassen Sie jedoch im Skript die Zeile 3 weg, die auf Eingabeparameter prüft, entfallen die beiden Aufrufvarianten via Cat. Entscheiden Sie selbst, was Sie benötigen.
Listing 5
$ ./distanz.pl fahrtenbuch.txt Gesamt: 1740 km $ perl distanz.pl fahrtenbuch.txt Gesamt: 1740 km $ cat fahrtenbuch.txt | perl distanz.pl Gesamt: 1740 km $ cat fahrtenbuch.txt | ./distanz.pl Gesamt: 1740 km
Python
Mögen Sie Python mehr als Perl, soll auch diese Neigung nicht zu kurz kommen. Listing 6 ähnelt Listing 4, nutzt aber dabei ein paar Kniffe in Form von Modulen.
Listing 6
#!/usr/bin/python
import fileinput
import re
gesamt = 0
for zeile in fileinput.input():
if re.match('\d+\t+.*\t+.*\t*\d+', zeile):
spalten = re.split('\t+', zeile)
gesamt += int(spalten[0]) * int(spalten[3])
print("Gesamt: %i km" % (gesamt))
Die Zeilen 2 und 3 deklarieren die Verwendung der Module fileinput [8] und re [9], die für eine vereinfachte Verarbeitung der Ein- und Ausgabe sorgen sowie das Verwenden regulärer Ausdrücke ermöglichen.
In Zeile 4 definieren Sie die Variable gesamt für die Gesamtsumme und initialisieren diese mit dem Wert null. Die For-Schleife in den Zeilen 5 bis 8 verarbeitet das Fahrtenbuch und iteriert zeilenweise durch den übergebenen Datenstrom.
Der liegt, bereitgestellt durch die Funktion fileinput.input(), als Liste vor. Der Inhalt der Liste kommt hierbei entweder via STDIN oder entstammt der Datei, die Sie dem Skript als Aufrufparameter mitgegeben haben.
Zeile 6 überprüft jede gelesene Zeile zuerst mithilfe eines regulären Ausdrucks daraufhin, ob sie eine bestimmte Struktur aufweist. In Betracht kommen nur solche Zeilen, die aus mindestens einer Ziffer bestehen, gefolgt von mindestens einem Tabulator, mehreren beliebigen Zeichen, mindestens einem Tabulator, noch einmal beliebigen Zeichen, mindestens einem Tabulator und mindestens einer Ziffer. Das überspringt die Kopfzeile des Fahrtenbuchs.
In Zeile 7 zerlegt das Skript die gelesene Zeile anhand des regulären Ausdrucks mit Tabulatoren in einzelne Spalten, die im weiteren Verlauf zum Berechnen der Distanz pro Tour dienen. Zeile 8 addiert die Distanz pro Tour zur Gesamtdistanz, wobei eine explizite Typkonvertierung des gelesenen Spalteninhalts via int() erfolgt.
Zu guter Letzt sorgt Zeile 9 für die Ausgabe der Gesamtdistanz. Um das Skript aufzurufen, bestehen die gleichen Möglichkeiten wie für die bereits oben gezeigte Perl-Variante (Listing 7).
Listing 7
$ python distanz.py fahrtenbuch.txt Gesamt: 1740 km $ ./distanz.py fahrtenbuch.txt Gesamt: 1740 km $ cat fahrtenbuch.txt | python distanz.py Gesamt: 1740 km $ cat fahrtenbuch.txt | ./distanz.py Gesamt: 1740 km
Tcl
Die Tool Command Language Tcl mag vielleicht eher den älteren Semestern unter den Lesern vertraut sein, hat aber auch heute nichts von ihrer Fähigkeit verloren, auf clevere Weise Textdaten zu verarbeiten. Das entsprechende Skript finden Sie in Listing 8. Es greift ebenfalls wieder auf das Lesen von STDIN und auf reguläre Ausdrücke zurück.
Listing 8
set gesamtdistanz 0
while {1} {
set zeile [gets stdin]
if {[eof stdin]} {
close stdin
break
}
set felder [regexp -all -inline \[^\t\]+ $zeile]
if {[string is integer -strict [lindex $felder 0]]} {
incr gesamtdistanz [expr [lindex $felder 0] * [lindex $felder 3]]
}
}
puts "Gesamt: $gesamtdistanz km"
Nach der Definition und Initialisierung der Variable gesamtdistanz mit null (Zeile 1) folgt eine While-Schleife (Zeile 2 bis 12). Diese liest solange von STDIN (Zeile 3), wie Daten anliegen. Bei dem Auftreten eines Dateiendes (“End of File”, EOF) bricht die Schleife ab (Zeile 4 bis 7).
Das Skript trennt dann in Zeile 8 zunächst die gelesene Zeile in einzelne Spalten auf. Das erfolgt mithilfe eines regulären Ausdrucks anhand der Tabulatoren, die mehrfach vorkommen dürfen. Die Variable felder umfasst dann eine Liste, wobei jedes Listenelement eine Spalte des Fahrtenbuchs repräsentiert.
In Zeile 9 erfolgt eine Prüfung, ob die Zeichenkette in Feld 0 einer Integer-Zahl entspricht. Falls ja, handelt es sich nicht um die Kopfzeile. Dann multipliziert der Ausdruck aus Zeile 10 die Felder 0 und 3 miteinander und addiert das Ergebnis zur Gesamtsumme. Das incr()-Statement akzeptiert dazu einen zweiten Parameter mit der Zwischensumme.
Nach dem Durchlaufen aller Zeilen erfolgt in Zeile 14 die Ausgabe der Gesamtdistanz. Das Tcl-Skript erwartet das Fahrtenbuch über STDIN, sodass Sie den Aufruf aus Listing 9 zum Ausführen der Auswertung verwenden.
Listing 9
$ cat fahrtenbuch.txt | /usr/bin/tclsh distanz.tcl Gesamt: 1740 km
Datenbank
Auch mit einem DBMS klappt die Berechnung – die Software ist ja dafür gedacht, uns als Benutzer in dieser Form zu unterstützen. Beispielhaft kommt hier PostgreSQL [10] zum Einsatz, prinzipiell können Sie aber auch jede andere (SQL-fähige) Datenbank nutzen.
Zum Einsatz kommen hier Datenbankfunktionen, die man auch Aggregatfunktionen nennt [11]. Neben der Summenfunktion zählen dazu beispielsweise die Ermittlung des Minimums, des Maximums und des Durchschnittswerts einer Spalte. In unserem Fall sieht der Aufruf wie folgt aus:
SELECT SUM(anzahl*distanz) FROM fahrtenbuch;
Bei fahrtenbuch handelt es sich diesmal nicht um eine Datei, sondern um eine Tabelle in unserer Datenbank. anzahl und distanz sind Spalten der Tabelle fahrtenbuch. Listing 10 zeigt die Tabelle samt den (bisherigen) Einträgen sowie den Aufruf zum Ermitteln der Gesamtdistanz. PostgreSQL erzeugt auf unsere SQL-Anfrage hin eine Ergebnisspalte namens sum, die die Gesamtdistanz als einzige Zeile enthält.
Listing 10
datenbank=> select * from fahrtenbuch;
anzahl | von | nach | distanz
--------+------------------+---------+---------
1 | Berlin | Potsdam | 30
2 | Berlin | Hamburg | 280
2 | Frankfurt (Main) | Paris | 575
(3 Zeilen)
datenbank=> select sum(anzahl*distanz) from fahrtenbuch;
sum
------
1740
(1 Zeile)
Tabellenkalkulation
Wer eher herumklicken als programmieren möchte, greift zu einer Tabellenkalkulation. Dazu bieten sich beispielsweise Calc aus Open/LibreOffice [12] an, Gnumeric [13] aus dem Gnome-Fundus oder die Einzelkämpfer Pyspread [14] beziehungsweise Sc [15]. Für Calc existiert sogar eine passende, frei verfügbare Vorlage [16].
Egal, welches Programm Sie benutzen: Es bedarf kleiner Formeln zur Berechnung, die Sie in Ihr Tabellenblatt eintragen müssen. Damit berechnen Sie einerseits die Anzahl mal Einzeldistanz sowie nachfolgend die Summe über alle Zwischenwerte. In unserem Beispiel aus Abbildung 2 lautet der entsprechende Ausdruck sum(A2*D2;A3*D3;A4*D4).
Die Funktion sum() interpretiert die Werte in Klammern als Liste der Einzelwerte. Der Eintrag A2 referenziert die zweite Zeile in der Spalte A des aktuellen Rechenblatts.
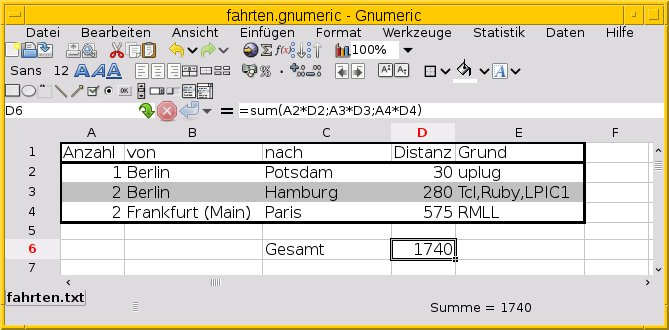
Abbildung 2: So führen Sie das Fahrtenbuch in der Tabellenkalkulation Gnumeric.
Fazit
Wie unsere Beispiele deutlich zeigen, benötigen Sie für das Abwickeln vieler Alltagsaufgaben keineswegs ein eigens dafür ausgelegtes Extraprogramm. In vielen Fällen genügen stattdessen eine schlichte Textdatei für die Datenerfassung sowie das Wissen um die Verwendung der richtigen Werkzeuge, die Linux sowieso an Bord hat. Welche Skriptsprache, welches Werkzeug oder welche Methode Sie dabei wählen, bleibt ganz Ihren eigenen Vorlieben überlassen. Wie fast immer bei unixoiden Betriebssystemen führen auch hier viele Wege zum Ziel.
Danksagung
Der Autor bedankt sich bei Axel Beckert (Perl), Thomas Partzsch (Awk) und Uwe Berger (Tcl) für ihre Kritik und Anregungen im Vorfeld dieses Artikels.
Autoreninfo
Frank Hofmann arbeitet in Berlin im Büro 2.0, einem Experten-Netzwerk für Open-Source, als Dienstleister mit Spezialisierung auf Druck und Satz (http://www.efho.de). Seit 2008 koordiniert er das Regionaltreffen der Linux User Groups aus der Region Berlin-Brandenburg. Er ist zudem Koautor des Debian-Paketmanagement-Buchs (http://www.dpmb.org/).
Glossar
-
STDOUT
-
Standardausgabe-Datenstrom auf unixoiden Betriebssystemen. Übliche Ausgabemethode von Programmen. Normalerweise ist
STDOUTmit dem Monitor verbunden, sodass Ausgabetexte dort erscheinen. -
Pipe
-
Datenstrom zwischen zwei Prozessen durch einen FIFO-Puffer. Die Ausgabe eines Programms an
STDOUTfließt so als Eingabe an ein zweites Programm weiter. -
STDIN
-
Über die Standardeingabe lesen Programme Daten ein. Normalerweise ist
STDINmit der Tastatur verbunden.
Infos
[1] Linux Professional Institute: https://www.lpi.org
[2] Awk (Wikipedia): https://de.wikipedia.org/wiki/Awk
[3] Sed (Wikipedia): https://de.wikipedia.org/wiki/Sed_(Unix)
[4] Reguläre Ausdrücke: Frank Hofmann, “Schnitzeljagd”, RPG 04/2014, S. 12, http://www.raspi-geek.de/32867
[5] Perl: https://www.perl.org/
[6] Python: https://www.python.org/
[7] Tcl Developer Exchange: https://www.tcl.tk/
[8] Python-Modul fileinput: https://docs.python.org/3/library/fileinput.html#module-fileinput
[9] Python-Modul re: https://docs.python.org/3/library/re.html#module-re
[10] PostgreSQL: http://www.postgresql.org/
[11] Aggregatfunktionen bei PostgreSQL: http://www.postgresql.org/docs/current/static/functions-aggregate.html
[12] LibreOffice Calc: https://de.libreoffice.org/discover/calc/
[13] Gnumeric: http://www.gnumeric.org/
[14] Pyspread: http://manns.github.io/pyspread/
[15] Sc: https://packages.debian.org/jessie/sc
[16] Vorlage zur Fahrtkostenberechnung für Open/LibreOffice Calc: http://opentemplate.org/content/show.php/Fahrtenbuch?content=47089




