

Das Standard-Filesystem hat sich in den letzten zwei Jahrzehnten stetig weiterentwickelt. Heute dient es auf unzähligen Systemen als robuster Unterbau.
Als Linus Torvalds 1991 die ersten frühen Versionen von Linux entwickelte, verwendete er das Minix-Dateisystem von Andrew S. Tanenbaum. Dies gehörte zum Inventar des Unix-Klons Minix [1], das Tanenbaum eigens für Lehrzwecke erschaffen hatte. Einige Einschränkungen, wie etwa maximal 14 Zeichen lange Dateinamen oder die Grenze von 64 MByte für die Größe von Dateien, weckten den Bedarf nach einem eigens für Linux entwickelten Dateisystem – so schlug die Geburtsstunde des Extended File System oder kurz Ext.
1992 veröffentlichte der französische Software-Entwickler Rémy Card eine erste Version, die es ermöglichte, unter Linux erstmals Dateien mit einer Größe von bis zu 2 GByte abzuspeichern. Die zulässige Länge für Dateinamen stieg auf 255 Zeichen. Obwohl Ext in der ersten Version bereits vieles richtig machte, genügte es professionellen Ansprüchen kaum: Je nach Einsatz fragmentierte es stark; zudem war es nicht möglich, verschiedene Zeitstempel für den Zugriff sowie Modifikationen von Inode und Datei abzuspeichern.
Nachfolger Ext2
Beim Design von Ext2 übernahmen die Entwickler viele bewährte Methoden und Prinzipien vom damals unter Unix verbreiteten Berkeley Fast File System [2]: Demnach unterteilt ein Ext2-Dateisystem das Speichermedium aus logischer Sicht in Blöcke, die es aneinanderreiht. Deren Standardgröße beträgt 4 KByte.
Die Blöcke sollten in der Regel mindestens so groß ausfallen wie die Sektoren einer Festplatte. Seinerzeit waren das meist 512 Byte, womit ein Block aus logischer Sicht acht Sektoren beherbergte. Seit einigen Jahren gibt es jedoch Festplatten mit 4 KByte großen Sektoren, sodass ein entsprechender Block direkt einen Sektor abbildet.
Ext2 fügt zudem Blöcke zu Blockgruppen zusammen, wobei bei einer Blockgröße von 4 KByte typischerweise 32?768 Blöcke (entsprechend etwa 128 MByte) eine Gruppe bilden. Damit finden sich auf einer heutigen Festplatte mit einem Volumen von 2 TByte Abertausende an Blöcken und immerhin rund 16?000 Blockgruppen.
Das Unterteilen in Blöcke und Blockgruppen hilft bei der logischen Organisation des Speichers sowie beim Optimieren von Zugriffen beim Lesen und Schreiben. Dateien schreibt das System in der Regel innerhalb der gleichen Blockgruppe, um das Fragmentieren und die Zugriffszeiten auf das Speichermedium zu minimieren. Schreibt das System eine Datei, die größer ausfällt als die konfigurierte Blockgröße, umfasst sie dementsprechend mehrere Blöcke.
Das Unterteilen in feste Blockgrößen birgt aber einen entscheidenen Nachteil: Nutzt eine Datei die Blockgröße von 4096 Bytes (4 KByte) nicht aus, verschwendet das Speicherplatz. Eine 96 Byte große Datei belegt einen kompletten 4-KByte-Block, eine 5092 Byte große Datei bereits zwei. In beiden Fällen gehen 4000 Bytes quasi verloren.
Inodes
Ein Ext-Dateisystem speichert die Dateien ohne Metadaten auf der Festplatte – es benötigt also noch einen Weg, um die Größe der Files, deren Eigentümer und die Zugriffsrechte zu verwalten. Zusätzlich braucht es Platz für den genauen Speicherort auf der Festplatte, damit das System die Datei schnell wiederfindet.
Die Entwickler von Ext2 verwenden dafür sogenannte Inodes: Jede Datei und jedes Verzeichnis ist durch einen Inode repräsentiert, der die oben genannten Informationen enthält. Die Bezeichnung steht für den Begriff “index node” (Index-Knoten), weshalb in den frühen Jahren von Ext2 häufiger das Kürzel “I-Node” auftauchte. Ein Inode belegt unter Ext2 standardmäßig 128 Bytes.
Verzeichnisse
Aus der Sicht von Ext handelt es sich bei Ordnern um nichts anderes als um spezielle Dateien, die eine Liste der enthaltenen Files beherbergen. Jeder Eintrag verknüpft einen Dateinamen mit einer Inode-Nummer, der Länge und dem Inhalt des eigentlichen Dateinamens. Beim Zugriff auf eine Datei genügt dem System also ein Blick in den Inode, der das beherbergende Verzeichnis repräsentiert (Abbildung 1).
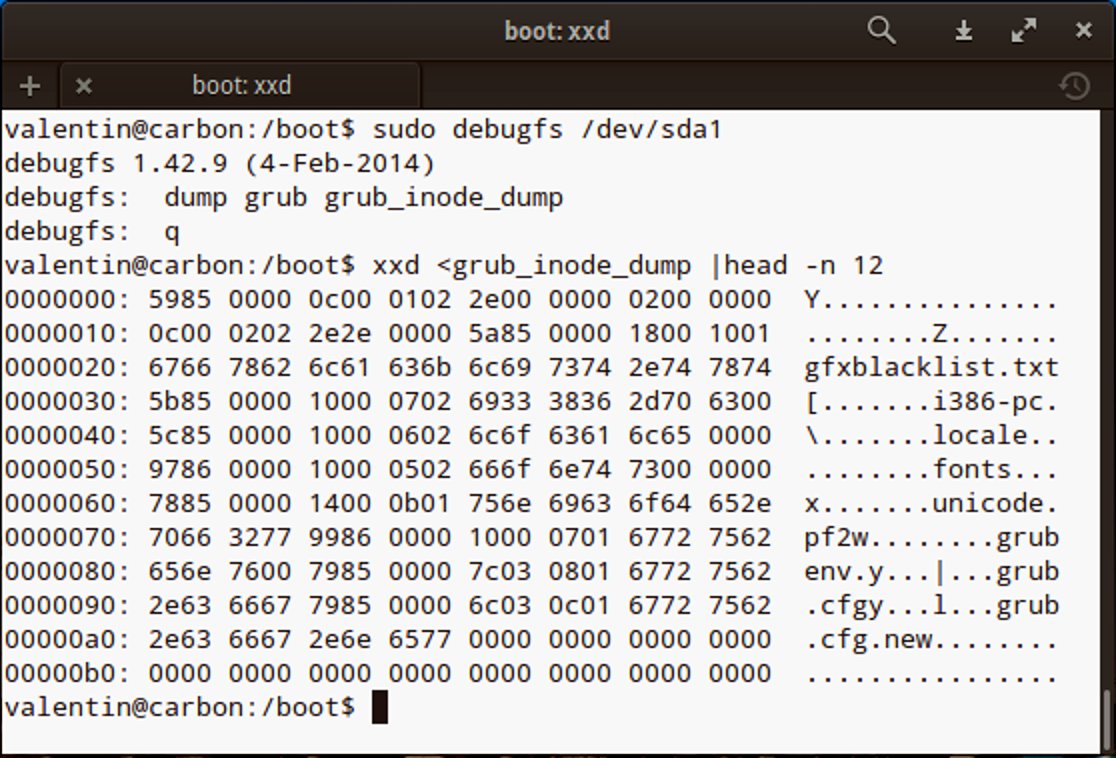
Abbildung 1: Der Blick in den für den Benutzer lesbaren Inhalt eines Verzeichnis-Inodes mittels DebugFS und des Hex-Viewers Xxd.
Das Zuordnen von Dateiname und Inode-Nummer muss dabei nicht singulär ausfallen: Verweist ein gänzlich anderer Dateiname auf eine bereits referenzierte Inode-Nummer, dann handelt es sich um einen sogenannten Hardlink. Ein solcher ist für Anwendungen und Benutzer in der Regel nicht ohne Weiteres zu erkennen und darf sich nur auf Objekte im eigenen Dateisystem beziehen. Für Unterverzeichnisse gilt übrigens dasselbe Prinzip: Dabei handelt es sich ebenfalls um spezielle Dateien, die der Inode des darüberliegenden Verzeichnisses mit deren Inode-Nummer als Datei referenziert.
Wenn Sie via ls -a den Inhalt eines Ordners auflisten, fallen die beiden Einträgen . und .. auf. Bei ihnen handelt es sich um Verzeichnisse mit besonderen Eigenschaften: Das System erzeugt sie beim Anlegen eines neuen Ordners automatisch, löschen lassen sie sich nicht. Die Einträge . und .. führt Ext2 im jeweiligen Verzeichnis mit der Inode-Nummer des aktuellen beziehungsweise darüber liegenden Verzeichnisses. Das Wurzelverzeichnis liegt übrigens immer im Inode Nummer 2 – so findet das System es schneller.
Superkräfte
Damit ein Ext-Dateisystem sich selbst organisieren kann, führt es Buch über einige wichtige Konfigurationsparameter sowie aktuelle Zustände. Diese Informationen liegen im sogenannten Superblock, der sich stets hinter den ersten 1024 Bytes eines Speichermediums befindet (Abbildung 2).
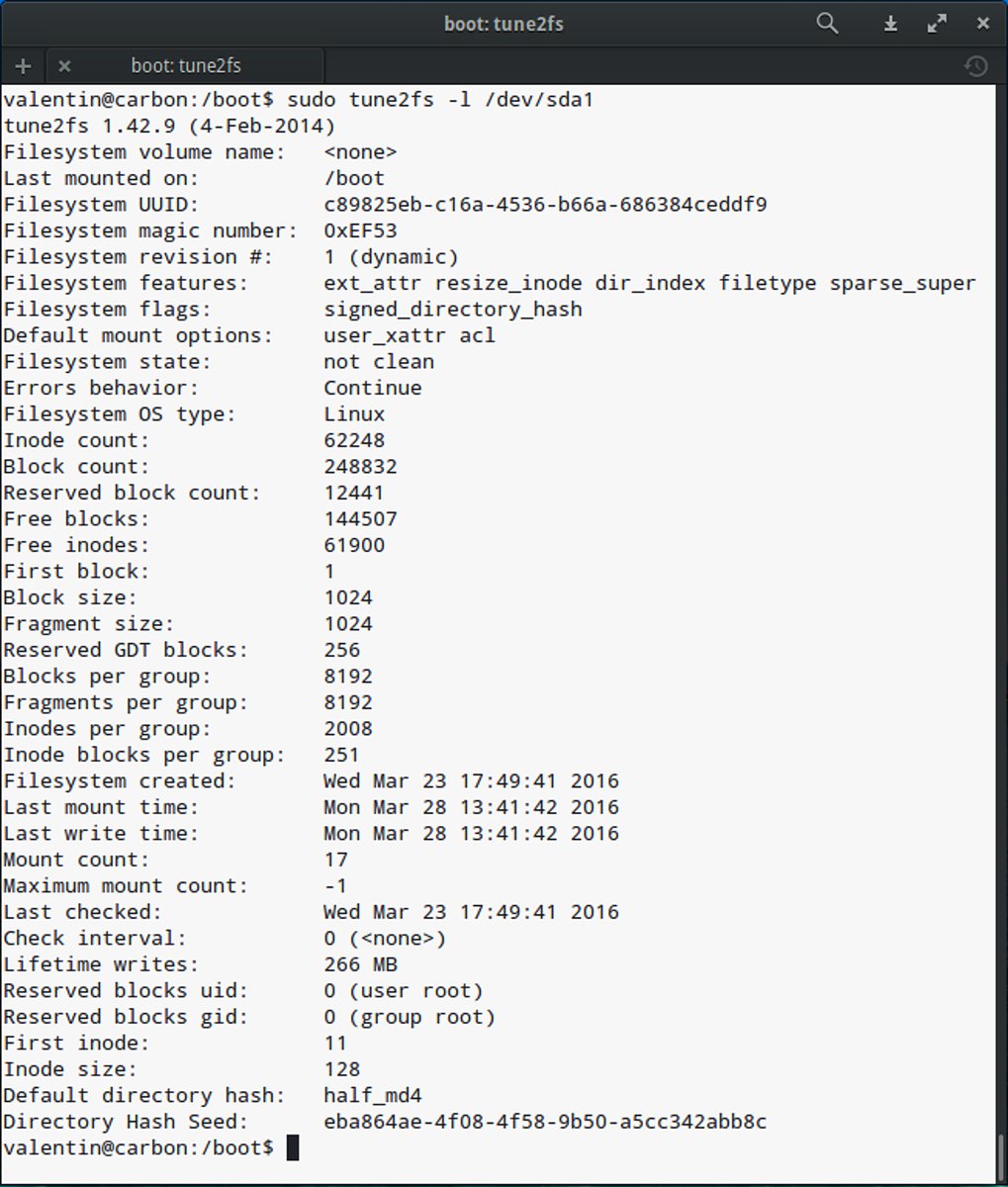
Abbildung 2: Das Tool Tune2fs liest für diese Ausgabe den Superblock eines Ext2-Dateisystems aus.
Diese feste Position ist zum Beispiel für den Mount-Vorgang oder einen Check des Dateisystems wichtig. Im Superblock finden sich unter anderem folgende Angaben:
- die genaue Blockgröße,
- die Anzahl der Blöcke und Blockgruppen,
- die Anzahl der freien und belegten Inodes,
- der Zeitpunkt des letzten erfolgreichen Einhängens,
- der Zeitpunkt der letzten Änderung,
- der Name des Betriebssystems, das das Dateisystem erstellt hat, sowie
- der aktuelle Zustand des Dateisystems.
Der Superblock bildet quasi das Herz des Ext-Dateisystems. Damit ein möglicher Schaden das Dateisystem nicht zerstört, legt Ext2 über die Blockgruppen verteilt mehrere Kopien des Superblocks an. Bei einer möglichen Reparatur greifen entsprechende Tools auf diese Sicherheitskopien zurück.
Für jede Blockgruppe existiert zudem ein Group Descriptor, der einige Informationen zu der eigenen Blockgruppe vorhält. Aus Gründen der Sicherheit enthalten alle Blockgruppen alle Group Descriptors des Ext-Dateisystems.
Darüber hinaus enthält jede Blockgruppe sogenannte Inode- und Block-Bitmaps. Sie dienen quasi als Karten, die alle Inodes und Blöcke der jeweiligen Blockgruppe verzeichnen. Ein Bit mit dem Wert 0 markiert ein Inode oder Block als frei, ein Wert von 1 signalisiert einen belegten Inode oder Block. Eine Bitmap muss stets in einen Block passen, was auch die Größe einer Blockgruppe begrenzt.
Speichervorgang im Detail
Legen Sie unter Ext2 neue Dateien oder Ordner an, trifft das Dateisystem zunächst eine Entscheidung über deren genauen Ablageort. Für ein noch leeres Dateisystem gilt: In der Theorie dürfen die Daten überall landen. Tatsächlich ist es aber aus Gründen der Performance sinnvoll, zusammenhängende Daten auch möglichst nahe beieinander abzulegen.
Ext2 versucht daher, Unterordner und Dateien in derjenigen Blockgruppe abzulegen, in der sich auch das Verzeichnis befindet, in dem diese liegen. Das Dateisystem geht dabei davon aus, dass diese Daten zusammenhängen und das System sie gegebenenfalls kurz hintereinander abruft.
Läuft die Blockgruppe allerdings voll, weicht Ext2 zwangsläufig auf einen anderen Speicherort aus. Um festzustellen, welche Blöcke und Inodes genau für das Abspeichern infrage kommen, sieht Ext2 in den jeweiligen Inode- und Block-Bitmaps nach.
Gute Referenzen
Ext2 führte auch die Unterstützung für symbolische Links oder kurz Symlinks ein. Dabei handelt es sich um eine spezielle Art von Datei, die anstelle von Daten lediglich eine Referenz auf eine andere Datei oder ein Verzeichnis enthält. Symlinks können anders als Hardlinks grundsätzlich auf Ziele von allen Dateisystemen verweisen, nicht nur auf das eigene.
Anders als Hardlinks erkennen Sie Symlinks jederzeit als solche. Anwendungen, die auf Dateien beziehungsweise Ordner hinter Symlinks zugreifen, behandeln diese wie gewöhnliche Dateien. Wenn es aber darauf ankommt, wie etwa beim Erstellen von Backups, muss ein Programm Symlink gesondert behandeln.
Symlinks existieren unabhängig vom Ziel. Löschen Sie die Datei, auf die ein Symlink verweist, bleibt der Link bestehen – es handelt sich ja um eine eigene Datei mit eigenem Inode. Der potenzielle Nachteil: Ändern Sie den Namen oder Ablageort einer Datei, müssen Sie auch den Symlink entsprechend anpassen.
Alle Symlinks, die aufgrund des Namens oder Verweises auf ein Ziel weniger als 60 Bytes groß ausfallen, speichert das Dateisystem direkt im zugehörigen Inode. Das vermeidet die Zuordnung eines eigenen Blocks im Ext2-Dateisystem. Diese Vorgehensweise kommt bei normalen Dateien ebenfalls zum Einsatz. Sofern der Inhalt einer Datei weniger als 60 Byte umfasst, schreibt das Dateisystem ihn direkt in den zugehörigen Inode (“inline data”).
Erweiterte Attribute
Version 2 des Ext-Dateisystems bot erstmals die Möglichkeit, erweiterte Attribute zu verwenden. Zu den bekanntesten davon gehört das Immutable-Bit: Mit dem Kommando chattr +i schützen Sie als Administrator eine Datei vor dem Verändern und Löschen.
Darüber hinaus verwaltet das Dateisystem erweiterte Zugriffsrechte (“Access Control Lists”, kurz ACLs). Diese erlauben es, verschiedenen Benutzern und Gruppen Zugriffe auf Dateien und Verzeichnisse zu gewähren oder zu entziehen. Erwartungsgemäß liegen die erweiterten Attribute direkt im Inode.
Eine weitere Neuerung von Ext2 sind die unterschiedlichen Zeitstempel: Das Dateisystem verwaltet drei verschiedene Zeitstempel für Dateien und Ordner (Abbildung 3). Diese erlauben es, dass Anwendungen wie ls anzeigen, wann das System auf ein Objekt zuletzt zugegriffen hat oder sich etwas auf der Ebene des Inodes beziehungsweise der Daten geändert hat.
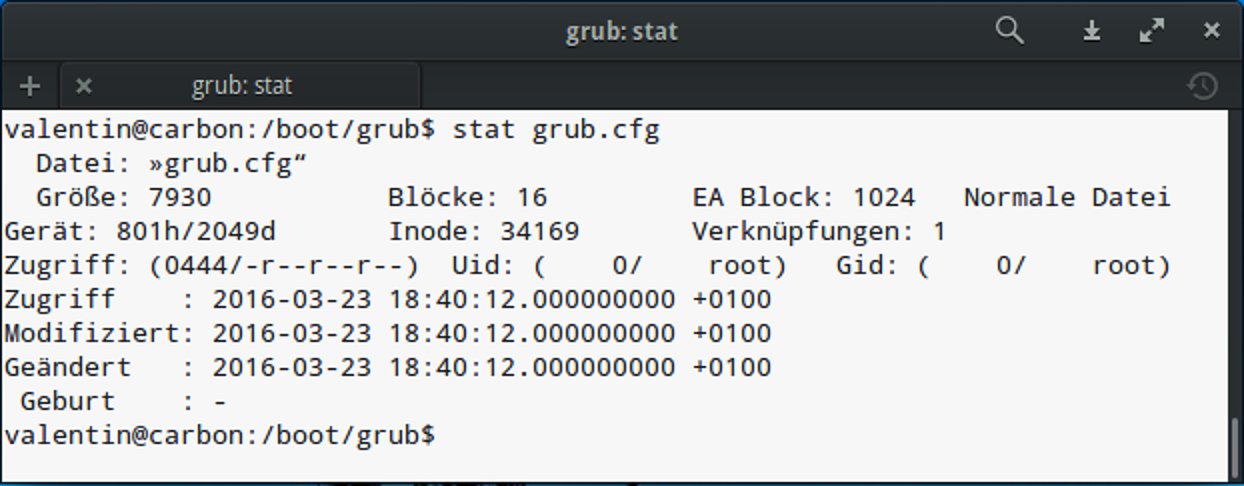
stat zeigt die drei Zeitstempel recht komfortabel.” width=”300″ height=”117″ />
Abbildung 3: Das Kommandostat zeigt die drei Zeitstempel recht komfortabel.Komprimiert
Einige Jahre nach der Veröffentlichung von Ext2 tauchte im Netz der Patch E2compr auf, der den Ext2-Treiber im Linux-Kernel um die Unterstützung für Kompression erweitert [3]. Diese greift nur bei Dateien – Verzeichnisse, Inodes, Superblöcke und andere auf das System bezogene Daten hingegen bleiben davon unberührt.
Sofern Sie den Patch integriert haben, besteht die Möglichkeit, mit $ chattr +c Datei ein erweitertes Attribut auf eine Datei zu setzen. Wenn Sie ein Verzeichnis für die Kompression markieren, komprimiert das System automatisch jede darin neu abgelegte Datei.
Noch nicht ganz fertig
Trotz vieler Vorteile gegenüber der ersten Ext-Version kämpft Ext2 mit einigen Limitierungen. So darf ein Verzeichnis aufgrund eines internen Limits maximal 31?998 Verzeichnisse enthalten, wobei diese Zahl in der Praxis vermutlich nur selten eine Rolle spielt. Aufgrund der Art, wie Ext2 Dateien verwaltet, kommt das Dateisystem bei mehr als 10?000 Dateien in einem Ordner aus dem Tritt.
Zumindest besser als in Ext verhält es sich unter Ext2 mit den maximalen Datei- und Dateisystemgrößen: Mit Kernel-Versionen 2.4 oder später darf ein Ext2-Dateisystem immerhin bis zu 16 TByte umfassen und Dateien mit Größen von bis zu 2 TByte verwalten (vorausgesetzt, die Blockgröße beträgt 4 KByte).
Mit einem Linux-Kernel 2.4 oder älteren Versionen war noch die Größe von Block-Devices auf 2 TByte beschränkt, was folglich ein Ext2-Dateisystem ebenfalls auf diese Größe limitierte.
Sprung zu Ext3
Ext2 hatte sich zur Jahrtausendwende zu einem stabilen und weitverbreiteten Dateisystem entwickelt. Mit der Zeit erwies es sich für das Dateisystem jedoch immer schwieriger, die wachsenden Datenmengen auf stetig wachsenden Festplatten sinnvoll und effizient zu verwalten. Einige Entwickler, darunter der Schotte Dr. Stephen Tweedie, versuchten sich daher an Performance-Verbesserungen und nützlichen Änderungen im Code.
Die Architektur von Ext2 setzt jedoch bestimmte Grenzen, womit es irgendwann sinnvoll erschien, zu einer neuen Version des Dateisystems überzuleiten. Tweedie wagte daher mit anderen Entwicklern zusammen den Sprung und startete ein zu Ext2 abwärtskompatibles Ext3.
Eine große Neuerung in Ext3 war ein Feature, das Tweedie schon im Jahr 2000 als Erweiterung für Ext2 entwickelt hatte: das Journal. Diese Funktion sichert ein Dateisystem im Falle eines plötzlichen Crashes gegen Inkonsistenzen ab (siehe Kasten “Journal des Ext-Dateisystems”). Ext3 startete demnach im Wesentlichen als ein leicht verbessertes Ext2 mit Journal.
Journal des Ext-Dateisystems
Eine Änderung im Ext-Dateisystem wirkt sich an vielen Stellen aus: Kommt eine neue Datei hinzu, reserviert das Filesystem Blöcke sowie eine Inode-Position. Weiterhin legt Ext einen Inode an, schreibt die Daten, ändert die letzte Zugriffszeit im Inode des entsprechenden Verzeichnisses und aktualisiert die Statistiken im Superblock. Zudem schreibt der Kernel die Daten nicht direkt auf die Festplatte. Er behält sie zunächst im Arbeitsspeicher, signalisiert der Software aber, dass der Vorgang abgeschlossen sei. Erst nach einem festgelegten Intervall schreibt der Kernel optimiert mehrere Änderungen in einem Schwung auf die Platte.
Tritt jedoch vorher ein unvorhergesehenes Ereignis wie ein Systemabsturz auf, macht dies das Dateisystem mit hoher Wahrscheinlichkeit inkonsistent: Beispielsweise ist nicht klar, welche Daten der Kernel nun auf die Festplatte geschrieben hat und welche sich nur im flüchtigen Arbeitsspeicher befanden. Beim Booten oder beim Einhängen prüft das System daher das Dateisystem. Je nach Größe des Dateisystems und Geschwindigkeit des Mediums dauert dieser Test in etwa so lange wie ein bis zwei Folgen Ihrer Lieblingsfernsehserie. Im schlimmsten Fall fällt anschließend noch eine manuelle Reparatur an.
Ein Journal macht Tests dieser Art überflüssig: Das Dateisystem spannt eine Art Sicherheitsnetz. Unter Ext3 erfolgen Änderungen nicht direkt, stattdessen schreibt der Kernel diese erst ins Journal (eine Art Logbuch). Je nach Konfiguration enthält das Journal nur die Metadaten (also zum Beispiel die Nummern der reservierten Blöcke sowie alle anderen Nicht-Nutzdaten) oder Meta- und Nutzdaten. Als Standard speichern viele Distributionen aus Leistungsgründen meist nur die Metadaten.
Wurden alle zusammengehörigen Änderungen ins Journal geschrieben, gilt der Vorgang (Transaktion) als vollständig, ein sogenannter Commit schließt ihn ab. Bei nächster Gelegenheit schreibt der Kernel nun die Änderungen auf die Festplatte, womit nun ein neuer, konsistenter Zustand sichergestellt ist. Die eigentlichen Daten sind bei der Standardeinstellung schon auf der Festplatte gelandet, aber erst nach dem Journal-Commit referenziert das System sie im Dateisystem.
Tritt zwischen dem Journal-Commit und dem Schreiben der Änderungen ein Systemabsturz auf, braucht das System beim nächsten Booten während des Dateisystem-Checks lediglich die Transaktionen aus dem Journal ins Dateisystem zu überführen.
Ein vollständiges Maß an Sicherheit gibt es allerdings nur, wenn Sie dafür sorgen, dass das System die geänderten Inhalte im Journal vorhält. Wie das Journal arbeitet, legen Sie beim Mounten des Dateisystems fest (mit mount -o data=Modus, also zum Beispiel mount -o data=journal). Der Journal-Modus beeinträchtigt allerdings die Performance des Dateisystems, weshalb er nicht standardmäßig aktiv ist, obwohl er die bestmögliche Sicherheit bietet.
Der wohl am meisten genutzte Modus des Journals lautet ordered (häufig der Standard), wonach zunächst die Inhalte ins Dateisystem geschrieben und erst danach die Metadaten im Journal aktualisiert werden (Abbildung 4). Der dritte Modus, writeback, schreibt nur die Metadaten ins Journal und überlässt es dem Kernel, wann dieser die eigentlichen Inhalte auf die Festplatte schreibt.
Ein Dateisystem-Journal bietet je nach Konfiguration eine recht gute Versicherung gegen Systemabstürze. Das Journal lässt sich zudem bei Bedarf auf ein anderes Speichermedium auslagern, damit es die Performance des Ext-Dateisystems nicht beeinträchtigt. Es sorgt aber auch für wesentlich mehr Schreibzugriffe auf das darunterliegende Speichermedium. Bei Speichermedien mit einer limitierten Anzahl an Schreibzyklen, wie etwa Flash-Speicher, verkürzt das Journaling daher die Lebensdauer drastisch. Für diese Medien greift man daher in der Regel zu Ext2.
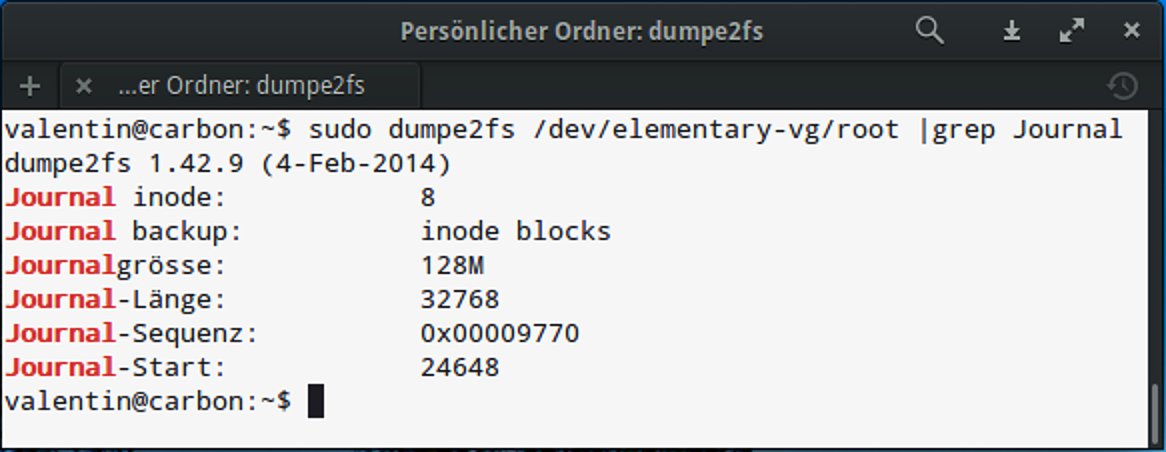
dumpe2fs lassen sich Informationen zum Journal anzeigen. Der hier dargestellte Modus inode blocks entspricht dem Modus ordered.” width=”300″ height=”116″ />
dumpe2fs lassen sich Informationen zum Journal anzeigen. Der hier dargestellte Modus inode blocks entspricht dem Modus ordered.Wie schon erwähnt skaliert Ext2 aufgrund einiger Designentscheidungen nicht gut, wenn es viele Tausend Dateien in Unterverzeichnissen beherbergt. Sobald das System in so einem Verzeichnis nach einer bestimmten Datei sucht, muss es aufwendig alle Einträge im Verzeichnis-Inode durchforsten, um das Ergebnis zu präsentieren.
Um für die Zukunft besser gewappnet zu sein, spendierten die Entwickler dem Dateisystem die sogenannte HTree-Indexstruktur. Diese baumartige Struktur ermöglicht es Ext3, Inhalte von Verzeichnissen effektiv zu organisieren, was die Suche nach Dateien erheblich beschleunigt.
Das Feature wurde ursprünglich schon für Ext2 entwickelt, schaffte es aber damals noch nicht in den offiziellen Quellcode. Während es unter Ext4 standardmäßig aktiviert ist, setzt Ext3 noch voraus, dass Sie das Directory-Indexing manuell anschalten. Außerdem erlaubt es Ext3, die Größe des Dateisystems zu ändern, während es noch eingehängt ist.
Darüber hinaus dürfen Sie definieren, wie sich der Kernel verhält, wenn er einige Metadaten des Dateisystems nicht versteht – zum Beispiel bei Schäden. Je nach Konfiguration kann der Kernel trotzdem das Dateisystem einhängen, wobei ein Schreibzugriff nur eingeschränkt möglich ist (und aus Gründen der Datensicherheit besser nicht geschehen sollte).
Ähnlich wie Windows-Dateisysteme zeigt sich Ext3 bei längerem Einsatz anfällig für Fragmentierung. Je nachdem, wie sich die freien Blöcke über das Dateisystem verteilen, kann das System vermutlich nicht immer zusammenhängende Daten auch hintereinanderschreiben. Abhilfe schafft die sogenannte Block-Preallokierung, mit der Ext3 Blöcke reserviert, bevor es sie wirklich benötigt. So gelingt es dem Dateisystem, die Daten möglichst nahe beieinander zu lagern.
Ein Online-Tool zur Defragmentierung gibt es für Ext3 übrigens nicht. Allerdings haben verschiedene Entwickler Werkzeuge veröffentlicht, die die Verteilung der Daten zumindest etwas optimieren. Durch das Hinzufügen eines Journals verwandeln Sie ein Ext2-Dateisystem in ein Ext3-Dateisystem, umgekehrt wird ebenfalls ein Schuh daraus.
Die Nähe zu seinem Vorgänger stellt übrigens den größten Nachteil von Ext3 dar: Da sich viele Strukturen ähneln, fehlten Ext3 anfangs einige Features, die konkurrierende Dateisysteme schon zu bieten hatten. Ein Ext3-Dateisystem mit einer Blockgröße von 4 KByte darf maximal 2 TByte große Dateien beherbergen und kann lediglich auf bis zu 16 TByte wachsen.
Einige Jahre nach Veröffentlichung von Ext3 galt das Dateisystem zwar als stabil, mehrere Firmen und Entwickler arbeiteten jedoch nach wie vor an Erweiterungen und Verbesserungen (besonders in Hinblick auf Performance und Stabilität). Auf der Kernel-Mailingliste entwickelte sich jedoch eine lebhafte Diskussion um die Frage, ob weitere Änderungen wirklich Verbesserungen an den fundamentalen Problemen bringen könnten oder den bisherigen Anwendern nicht sogar mehr Nachteile bescheren würden.
Schließlich einigten sich die Entwickler 2006 darauf, die Arbeit an Ext3 weitgehend einzustellen. Stattdessen entschieden sie sich, den Code des Dateisystems einmalig in einen neuen Zweig namens ext4 zu kopieren und neue Features sowie substanzielle Änderungen nur noch dort einzuspielen. Mehr als zwei Jahre später schaffte es Ext4 in Kernel 2.6.28, wodurch es nach und nach zum Standard für viele Distributionen avancierte.
Ext4
Ext4 unterstützt 64-Bit-Prozessoren, was es ermöglicht, bei einer Blockgröße von 4 KByte erstmals 16 TByte große Dateien zu erstellen. Das Dateisystem selbst darf auf 1 Exabyte (entspricht etwa 1 Million TByte) wachsen, wobei dieser Wert für die meisten Systeme eher theoretischer Natur ist. Für die meisten Fälle empfiehlt es sich, das Dateisystem auf rund 16 TByte zu beschränken und gegebenenfalls mehrere Dateisysteme nebeneinander anzulegen.
Ext2 und Ext3 organisieren die Ablage der Daten über Block-Bitmaps, die den physikalischen Speicherplatz abbilden. Unter Ext4 übernehmen “Extents” diese Funktion, die zusammenhängenden Blöcke auf dem Speichermedium zusammenzufügen. Ein einzelner Extent umfasst unter Ext4 bis zu 128 MByte an zusammenhängenden Speicherplatz, wobei ein Inode bis zu vier Extents enthält. Umfasst eine Datei mehr als vier Extents, indexiert das Dateisystem die übrigen Extents in einer Baumstruktur. Durch den Einsatz von Extents bietet das Ext-Dateisystem in einigen Fällen eine stark verbesserte Performance für große Dateien und eine bessere Defragmentierung.
Ein unter Ext3 schmerzlich vermisstes Feature hielt unter Ext4 ebenfalls Einzug: Eine neue Kernel-Funktion bringt Ext4 dazu, vorab schon Speicherplatz für eine Datei zu reservieren (“pre-allocation”). Ext4 füllt den fraglichen Bereich schon einmal mit Nullen und versucht zu garantieren, dass der Speicherplatz wirklich nicht bereitsteht und möglichst zusammenhängt.
Durch weitere Umbauten unterstützt Ext4 nun mehr als 32?000 Unterverzeichnisse pro Ordner – theoretisch nahezu unendlich viele, da der HTree-Mechanismus nun grundsätzlich greift. Benötigen Sie mehr als die standardmäßig 64?000 erlaubten Unterverzeichnisse, aktivieren Sie das Feature dir_nlink.
Das mit Ext3 hinzugekommene Journal erhielt eine sinnvolle Verbesserung: Mithilfe von Prüfsummen für Metadaten beugt es nun möglichen Risiken für defekte Metadaten vor, die im schlimmsten Fall das Dateisystem schreddern könnten. Der unbeliebte Dateisystem-Check läuft unter Ext4 deutlich schneller ab, da unbenutzte Speicherbereiche im Dateisystem als solche markiert sind. Beim Überprüfen überspringt die Software diese, wovon besonders fast leere Dateisysteme profitieren. Fans von möglichst genauen Zeitstempeln kommen nun ebenfalls auf ihre Kosten, da Ext4 auf Nanosekunden genaue Zeitstempel ermöglicht. Ext4 beherbergt nun zudem Optionen, mit denen das System SSD-Speicher optimaler nutzt.
Mit Kernel 4.1 hielt Mitte 2015 übrigens experimentell eine transparente Verschlüsselung Einzug ins Ext4-Dateisystem [4], wobei die Benutzer Daten mit jeweils verschiedenen Schlüsseln absichern können. Seit Kernel 4.4 erfüllt dieses Feature alle Voraussetzungen für einen künftigen Einsatz. Als treibende Kraft hinter der Ext4-Verschlüsselung agiert übrigens Google. Vermutlich will der Konzern damit bessere Sicherheits-Features für Android und ChromeOS anbieten. Experimentieren Sie derzeit mit einem aktuellen Kernel und neueren Userspace-Tools (wie Tune2fs), dann lohnt es sich, einen Blick auf einen entsprechenden Blog-Post [5] zu werfen.
Ext4 bietet Rückwärtskompatibilität zu Ext3 und Ext2, was es ermöglicht, die Vorläufer als Ext4 zu mounten. Ein Ext4-Dateisystem hingegen können Sie nicht direkt als Ext3-Dateisysteme einhängen. Dazu müssten Sie erst einige Features beim Erstellen des Dateisystems deaktivieren, zum Beispiel die Limits für das Dateisystem denen von Ext3 anpassen.
Ext4 beherrscht seit Kernel 3.6 Quota, mit denen Sie bei Bedarf den Speicherplatz der Benutzer und Benutzergruppen begrenzen. Mit der jüngst veröffentlichten Kernel-Version 4.5 hielten zudem Projekt-Quota Einzug. Damit limitieren Sie den Speicher entweder für Verzeichnishierarchien oder über mehrere Ordner hinweg verstreute Dateien. Die Patches dafür wurden bereits Ende 2014 eingereicht und in einem Post auf der Ext4-Mailingliste beschrieben [6].
Ausblick
Ext4 war über die letzten Jahre hinweg in vielen Distributionen Dateisystemstandard, da es sich für die meisten Zwecke gut eignet und als stabil gilt. Mittlerweile schwenken einige Distributoren auf XFS (Red Hat) oder Btrfs (OpenSuse) um. Besonders Btrfs gilt als aussichtsreichster Kandidat, um mittelfristig Ext4 abzulösen: Es enthält viele Features, die auf absehbare Zeit wohl nicht in Ext4 auftauchen dürften. Darunter fallen beispielsweise Dateisystem-Snapshots, Unterstützung für richtige Online-Defragmentierung und Copy-on-write-Vorgänge.
Ob es eine fünfte Version des Ext-Dateisystems gibt, ist derzeit ungewiss. In der Vergangenheit entstand die nächste Version des Dateisystems stets, sobald sich genug Änderungen fanden, die eine nächsthöhere Version rechtfertigten, während die Entwickler die bisherige Ext-Version möglichst stabil halten wollten.
In der Ext4-Mailingliste findet sich für Mai 2014 eine Patch-Beschreibung des Oracle-Entwicklers Darrick J. Wong, der zumindest einige Flags unter der Bezeichnung Ext5 einführen möchte [7]. Im Laufe der Diskussion stellten andere Entwickler jedoch heraus, dass die fraglichen Änderungen nicht ausreichen, um gleich ein neues Dateisystem zu begründen. Wahrscheinlicher ist, dass die Entwickler noch länger aktiv an Ext4 arbeiten. Mittelfristig aber wechseln vermutlich viele Nutzer zu Btrfs.
Der Autor
Valentin Höbel arbeitet als Cloud Architect für den VoIP-Spezialisten NFON AG in München. Wenn er in seiner Freizeit nicht gerade am Kicker-Tisch steht, wirft er einen Blick auf aktuelle Open-Source-Technologien.
Infos
[1] Minix: http://www.minix3.org
[2] Unix File System: https://en.wikipedia.org/wiki/Unix_File_System
[3] E2compr: http://e2compr.sourceforge.net
[4] Ext4-Verschlüsselung: https://lwn.net/Articles/639427/
[5] Blogeintrag zur Ext4-Verschlüsselung: http://blog.quarkslab.com/a-glimpse-of-ext4-filesystem-level-encryption.html
[6] Ext4-Quota-Patches: https://lwn.net/Articles/623835/
[7] “Ext5”: https://www.marc.info/?l=linux-ext4&m=139898619610519&w=1




