
Gewandte Sprache verleiht einem Text den richtigen Schliff. Wer kommerzielle Thesauri meiden will, findet in der freien Software-Welt erstklassige Alternativen.
Sicher kennen Sie die Situation, in der Sie erst verzweifeln, und dann doch wieder Bauklötze staunen: Die Internetrecherche nach einem Läufer liefert zunächst unzählige Treffer. Darunter nicht nur berühmte Sportler, sondern auch kleine Teppiche und Schachfiguren sowie laufende Boten, die eine Nachricht überbringen.
Erst wenn Sie die Suche um weitere Begriffe ergänzen, schwenkt die Ausgabe oft in die gewünschte Richtung um. Die Basis dafür bildet eine Analyse der Sprache, die in den Auswerteprozess der Suchmaschine integriert ist. Solche erläutern die Zusammenhänge zwischen den Wörtern einer Sprache anhand verschiedener Kriterien; diese fließen in das Ergebnis der Suche ein.
Von außen betrachte, wirkt es daher so, dass der Computer besser verstünde, wonach Sie stöbern, und liefert Ihnen daraufhin exakte und vielfältige Treffer – und das selbst dann, wenn Sie sich bei der Schreibweise des Begriffes vertippt haben.
Obwohl die Benutzerschnittstelle, also die Eingabemaske, oft recht profan daherkommt, hat der Vorgang dahinter kaum noch etwas mit einer einfachen Stichwort- oder Schlagwortsuche gemeinsam [1]. Früher glückte eine Recherche in Dateien oder Dokumenten vorrangig anhand der richtig ausgewählten Suchbegriffe, deren korrekter Schreibweise und etwas Intuition.
In den letzten 20 Jahren entwickelte sich dieser Vorgang hingegen Schritt für Schritt zu einem ausgefeilten Prozess, in dem viele weitere Kriterien eine Rolle spielen. Betreiber von Suchmaschinen nutzen mehr als 50 davon, darunter die Sprache des Dokuments, dessen Format und Struktur, Fachbegriffe in den Metadaten sowie den Grad der Vernetzung, das heißt, wie oft ein Dokument etwa referenziert oder selbst Ziel eines Links ist.
Das Ergebnis basiert auf Begriffen, die thematisch zusammengehören. Neben einer großen Portion Statistik spielt dabei insbesondere das Wissen um die sprachlichen Zusammenhänge der einzelnen Worte eine große Rolle. Dies stammt aus linguistischen Thesauri (siehe Kasten “Im Überblick”).
Im Überblick
Der Begriff Thesaurus stammt vom altgriechischen “thesauros” ab und bedeutet Schatz oder Schatzhaus. Das Analogon im Lateinischen ist das Wort “thesaurus”. Allgemein gesprochen, bezeichnet es eine nach bestimmten Kriterien geordnete Sammlung thematisch zusammenhängender Objekte, eine Art “Wissensspeicher”. Bezogen auf die Sprach- und Dokumentationswissenschaft war ein Thesaurus ein Wörterbuch und somit ein Sammelwerk mit dem gesamten Wortschatz einer Sprache.
In den 1950er-Jahren veränderte sich dieses hin zum spezialisierten Nachschlagewerk, das aus einem kontrollierten, begrenzten Vokabular und den Relationen der einzelnen Worte untereinander besteht. Grundlage für das Vokabular bilden inzwischen die Begriffe aus der Schlagwortnormdatei der Deutschen Nationalbibliothek [2] oder der Library of Congress Subject Headings (LCSH) [3]. Verwendet werden vorrangig Synonyme sowie Ober- und Unterbegriffe. Die Relationen zwischen den einzelnen Begriffen sind gemäß DIN 1463-1 beziehungsweise ISO 2788 genormt (siehe Tabelle “Relationen”) und als Assoziationen und Verweise bekannt.
Relationen
| DIN 1463-1 | ISO 2788 | ||
|---|---|---|---|
| BF | Benutzt für | UF | Used for |
| BS | Benutze Synonym | USE/SYN | Use synonym |
| OB | Oberbegriff | BT | Broader term |
| UB | Unterbegriff | NT | Narrower term |
| VB | Verwandter Begriff | RT | Related term |
| SB | Spitzenbegriff | TT | Top term |
Aktuelle Beispiele sind der Thesaurus Linguae Latinae (abgekürzt ThlL oder TLL) [4] für Latein, der Thesaurus Linguae Graecae (TLG) [5] für Griechisch, aber der UNESCO Thesaurus [6]. Letztgenannter ist eher ein Sammelwerk zu den Bereichen Bildung, Wissenschaft, Kultur, Sozial- und Humanwissenschaften, Information und Kommunikation, Politik, Recht und Wirtschaft. Alle Einträge stehen in Englisch, Französisch, Spanisch und Russisch bereit. Nützlich sind der Europäische Thesaurus Internationale Beziehungen und Länderkunde [7] sowie der Getty Thesaurus of Geographic Names (TGN) [8]. Dieser steht inzwischen als Open Data jedem Interessenten frei (Abbildung 1).
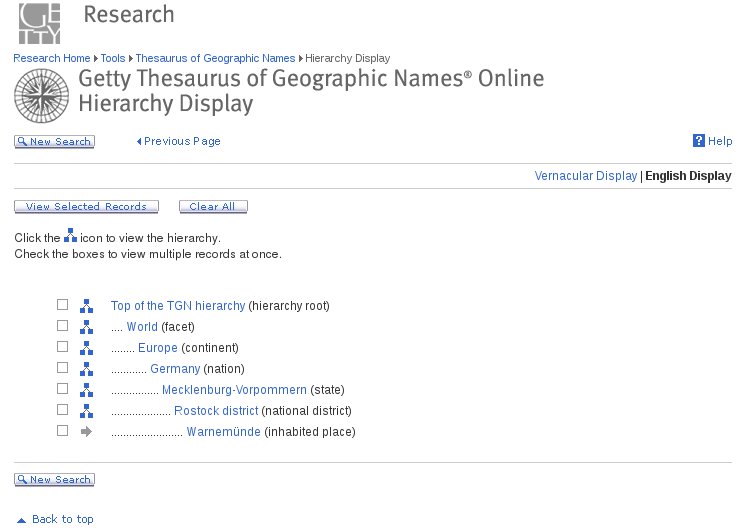
Abbildung 1: Detailliertes Suchergebnis und Hierarchie nach “Warnemünde” im TGN.
Linguistische Thesauri sind in der angewandten Sprachwissenschaft mit den beiden Begriffen Wortnetz und Sprachschatz verankert. Deren Ziel besteht einerseits darin, unsichtbare (semantische) Verbindungen zwischen Worten unterschiedlicher Herkunft und deren Bedeutung (Relationen und Assoziationen) anzuzeigen, andererseits die Ähnlichkeit zwischen den einzelnen Begriffen zu verdeutlichen.
Zudem dienen Thesauri dem Erforschen der Sprachgeschichte und zum Bestimmen von Bedeutungen und deren Historie. Im Alltag als Wörterbuch für Synonyme bekannt, verhelfen sie als Nachschlagewerk zu einem eleganteren Ausdruck und sorgen im optimalen Fall für eine größere Gewandtheit in der Sprache.
In der IT kommen Thesauri neben dem Einsatz bei Suchmaschinen oft als Zugabe zur Textverarbeitung daher und bilden häufig die Basis zur Rechtschreibprüfung und verstärkt als Hilfe für korrekte Grammatik. Beispiele aus der Praxis sind unter anderem der KThesaurus [9] und der OpenThesaurus für LibreOffice [10].
Projekte und Werkzeuge
Einen Einstieg zur Recherche im deutschen Sprachraum bietet die Schweizer Webseite Lexikon.ch [11]. Dieses Angebot versteht sich als spezielle Suchmaschine für Lexika, Thesauri, Wörterbücher, Zitatesammlungen, Abkürzungsverzeichnisse und Reimlexika. Sie listet sowohl kommerzielle als auch freie Projekte auf.
Als reine Online-Angebote stehen unter anderem Woxicon [12], Leo [13] und Beolingus/Dict [14]. Woxicon und Leo bieten Ergänzungen für slawische, romanische und skandinavische Sprachen an; Beolingus/Dict konzentriert sich hingegen auf Englisch, Spanisch und Portugiesisch.
Leo und Beolingus/Dict haben ihren Ursprung in der Wissenschaft – TU München und TU Chemnitz – und kooperieren für die Angabe der Thesauri unter anderem mit dem Centre National de Ressources Textuelles et Lexicales (CNRTL) [15] in Nancy (Lothringen) sowie den Projekten OpenThesaurus [16] und WordNet [17].
Kommerzielle Thesauri als Nachschlagewerk lagen traditionell in Buchform vor, so zum Beispiel als Bestandteil der Standardausgabe des Dudens, des Oxford English Dictionary oder des Dictionaire Robert. Die meisten Verlage integrieren ihren Thesaurus inzwischen aber mittlerweile direkt in ihr Online-Angebot und ermöglichen den Zugriff über den Webbrowser oder bieten alternativ eine passende App dafür an. Allerdings richten sich diese Angebote eher an Gelegenheitsnutzer mit 5000 bis 10?000 Abfragen pro Tag und Benutzer.
Für den unbegrenzten Einsatz sowie die Integration in eine eigene Applikation stellen die Verlage eine Schnittstelle (API) bereit. Die Arbeit mit dieser setzt voraus, dass Sie sich registrieren und einen API-Key erwerben. Diesen Key übermitteln Sie bei jedem Aufruf.
Macmillan Dictionary [18], Merriam-Webster [19] und Cambridge Dictionaries Online [20] geben die Ergebnisse als XML-Daten oder Javascript Object Notation (JSON) zurück und orientieren sich damit an den derzeit gängigen Standards im Web. Listing 1 zeigt eine Anfrage bei Merriam-Webster, Listing 2 die passende Antwort.
Listing 1
http://www.dictionaryapi.com/api/v1/references/thesaurus/xml/umpire?key=API-Key
Listing 2
<entry id="umpire"> <term> <hw>umpire</hw> </term> <fl>noun</fl> <sens> <mc>a person who impartially decides or resolves a dispute or controversy</mc> <vi>usually acts as <it>umpire</it> in the all-too-frequent squabbles between the two other roommates</vi> <syn>adjudicator, arbiter, arbitrator, referee, umpire</syn> <rel>jurist, justice, magistrate; intermediary, intermediate, mediator, mediatrix, moderator, negotiator; conciliator, go-between, peacemaker, reconciler, troubleshooter; decider</rel> </sens> </entry>
Pons, der Verlag für Wörterbücher, bietet die Anbindung an die hauseigene Datenbank als eigenständigen Service an [21], Mitbewerber Langenscheidt fokussiert auf das Angebot in Form von Büchern und spezifischen Apps für die unterschiedlichen mobilen Geräte.
Um sich die Facetten einzelner Worte als Graphen anzuschauen, bietet sich Visual Thesaurus [22] an. Dieser zeigt die Verbindungen zwischen den Worten bildhaft als einzelne Knoten und Kanten im Webbrowser an (Abbildung 2). Die Anzeige basiert auf Javascript und erlaubt es, die Grafik in jede gewünschte Richtung zu drehen. Das gelingt, indem Sie den gewünschten Knoten anklicken. Ohne einen API-Key dürfen Sie jedoch nur eine begrenzte Anzahl Aufrufe tätigen. Diese reichen in der Regel jedoch, um einen Eindruck zu erlangen.
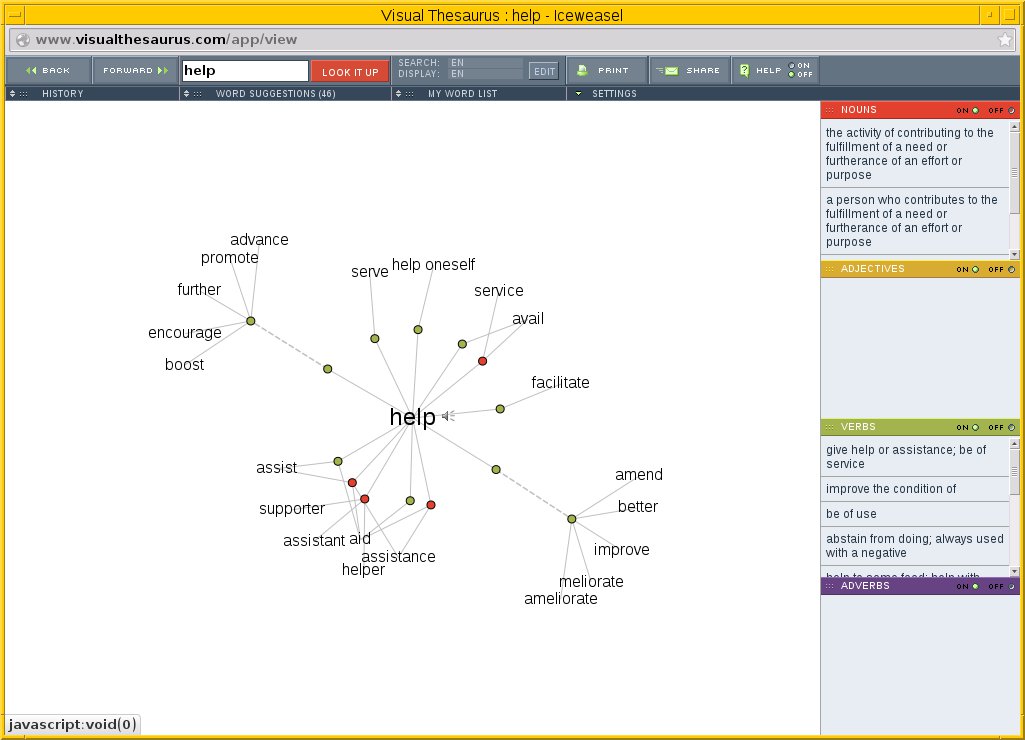
Abbildung 2: Die Webseite Visual Thesaurus zeigt die Verbindungen zwischen Worten als Baum, hier am Beispiel “help”.
Wordnik
Das kommerzielle Produkt Wordnik [23], eine Art aufgebohrtes Wörterbuch ausschließlich für die englische Sprache, fokussiert in der Ausgabe insbesondere auf mobile Geräte. Vom Funktionsumfang her beinhaltet es Beschreibungen von Wörtern und Erläuterungen zu deren Bedeutungen sowie eine größere Menge an Beispielen. Dabei bindet es die Ergebnisse verschiedener Quellen mit ein, so vom Wiktionary und aus WordNet (Abbildung 3).
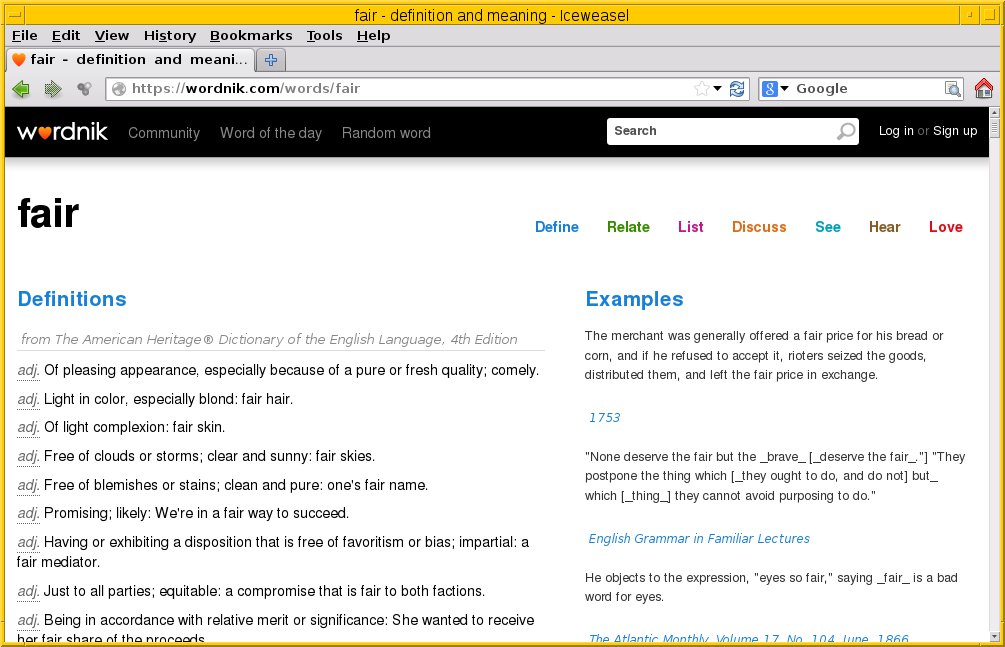
Abbildung 3: Das kommerzielle Produkt WordNik zeichnet sich durch ein übersichtliches und gut strukturiertes Suchergebnis aus.
Alle Module stehen unter der Apache Lizenz. Deren Quellcode finden Sie in einem Github-Repository. Die Anbindung gelingt über verschiedene Module und Schnittstellen, wie Python, Ruby, Javascript, Java und PHP. Der Einsatz setzt ein Registrieren beim Hersteller voraus, von dem Sie einen entsprechenden API-Key erhalten.
Freie Thesauri
Im Bereich der freien Software tummeln sich ebenfalls eine Reihe von Projekten, die sich mit der Thematik Thesaurus beschäftigen. Zu etlichen Programmen bestehen Schnittstellen, obwohl diese manchmal etwas versteckt sind.
Das bereits erwähnte WordNet ist das Ergebnis des gleichnamigen Forschungsprojekts der Princeton University, das inzwischen seit mehreren Jahrzehnten an einer lexikographischen Datenbank der englischen Sprache arbeitet. Es gruppiert dabei Substantive, Verben, Adjektive und Adverbien auf semantischer und lexikalischer Ebene.
Das Projekt bildet die Basis für vergleichende Sprachwissenschaft und das Verarbeiten der natürlichen Sprache und ist damit die Grundlage für mehrere der hier vorgestellten Programme.
Neben einer webbasierten Schnittstelle steht der aktuelle Forschungsstand für verschiedene Plattformen bereit – unter anderem als Debian-Paket [24]. Dieses beinhaltet sowohl ein Kommandozeilenprogramm wn, als auch eine grafische Applikation namens WordNet Browser.
Mit dem Aufruf aus Listing 3 erhalten Sie einen Überblick zu den Synonymen samt deren Bedeutung zum Substantiv “fair”. Der Parameter -synsn setzt sich aus -syns zur Auswahl der Synonyme und n zum Einschränken auf Substantive (engl. nouns) zusammen.
Listing 3
$ wn fair -synsn
Synonyms/Hypernyms (Ordered by Estimated Frequency) of noun fair
4 senses of fair
Sense 1
carnival, fair, funfair
=> show
Sense 2
fair
=> gathering, assemblage
Sense 3
fair
=> exhibition, exposition, expo
Sense 4
bazaar, fair
=> sale, cut-rate sale, sales event
Über das Kommando wnb starten Sie das GUI-Programm und geben im Eingabefeld oben links den Suchbegriff ein. Unter dem Eingabefeld erscheinen bis zu vier Knöpfe, die die jeweilige verfügbare Wortform anzeigen. Um die Übersicht auf Synonyme zu Substantiven einzuschränken, klicken Sie auf die Schaltfläche “Noun” und wählen aus der Liste “Synonyms, ordered by estimated frequency” aus. Das Ergebnis in Abbildung 4 ist identisch zu der Ausgabe auf der Kommandozeile.
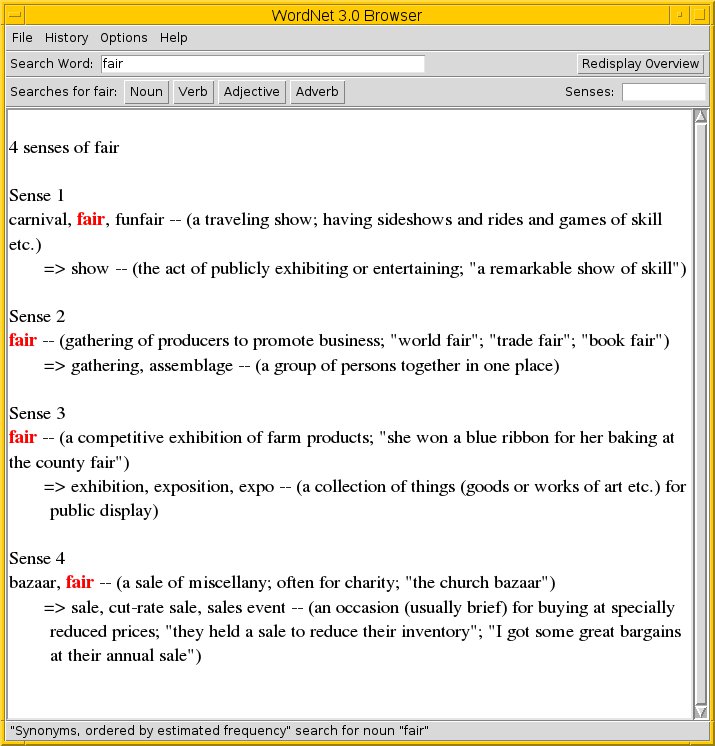
Abbildung 4: Anfrage zum Suchbegriff “fair” im WordNet Browser.
Für WordNet existieren eine Reihe von Implementationen; die Projektseite listet diese auf. Für den Einsatz mittels Perl nutzen Sie am besten das Modul WordNet-QueryData [25], das in Form des Debian-Pakets libwordnet-querydata-perl bereitsteht. Für Python hilft Ihnen das Python Natural Language Toolkit (NLTK) weiter [26]. Letzteres verfügt über eine passende Klasse für WordNet.
OpenThesaurus
Das Projekt OpenThesaurus startete 2002 zunächst als Ergänzung zu OpenOffice, heute ist es ebenso fester Bestandteil von LibreOffice und Papyrus [27]. Es beschreibt sich selbst als ein freies deutsches Wörterbuch für Synonyme”. Es steht jedem frei, sich an dem Projekt zu beteiligen. Es ist spezialisiert auf Wörter in unterschiedlicher Schreibweise, aber identischer Bedeutung. Derzeit stehen Sammlungen für Deutsch, Schweizerdeutsch, Niederländisch, Norwegisch, Polnisch, Portugiesisch, Slowakisch, Slowenisch und Spanisch bereit. Alle Inhalte stehen unter der GNU Lesser General Public License (LGPL).
Der Thesaurus gehört nicht zu den Standardmodulen, Sie installieren ihn über die Paketverwaltung nach. Unter Debian heißt das Paket mythes-de (für Deutsch) und mythes-de-ch in der schweizer Variante. Das Werkzeug steht dann unter Extras | Language | Thesaurus zur Verfügung. Rufen Sie diesen Eintrag auf, öffnet sich ein neues Fenster (Abbildung 5).
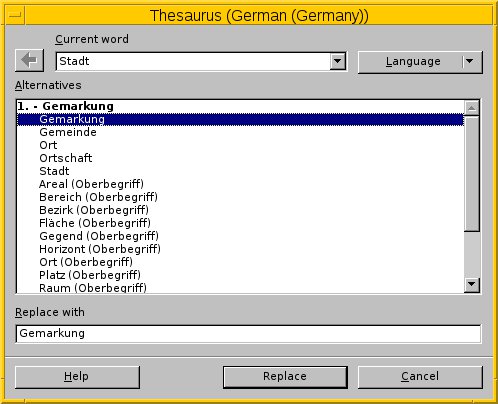
Abbildung 5: Vollständige Auswahl über den Thesaurus-Dialog.
Aus der Liste darunter wählen Sie die gewünschte Alternative aus und übertragen sie in den Text. Haben Sie zuvor ein Wort im Text markiert, gelingt Gleiches über das Kontextmenü. Mit einem Rechtsklick öffnen Sie dieses und wählen neben dem Eintrag Synonyme das Entsprechende aus.
Selbst ohne LibreOffice besteht die Möglichkeit, OpenThesaurus zu benutzen – und zwar über die Webseite des Projekts. In das Eingabefeld tragen Sie das gewünschte Wort ein und erhalten nach dem Klick auf den Pfeil eine ausführliche Information zu dem betreffenden Wort.
Kthesaurus
Kthesaurus (Abbildung 6) leistet Ähnliches für die Calligra-Suite (vormals KOffice) wie OpenThesaurus für LibreOfffice. Es setzt nicht auf Letzteres auf, sondern bezieht die lexikalischen Informationen zu den Wörtern aus der WordNet-Datenbank. Daher steht Kthesaurus nur für Englisch bereit. Um die Software zu verwenden, installieren Sie das gleichnamige Paket.
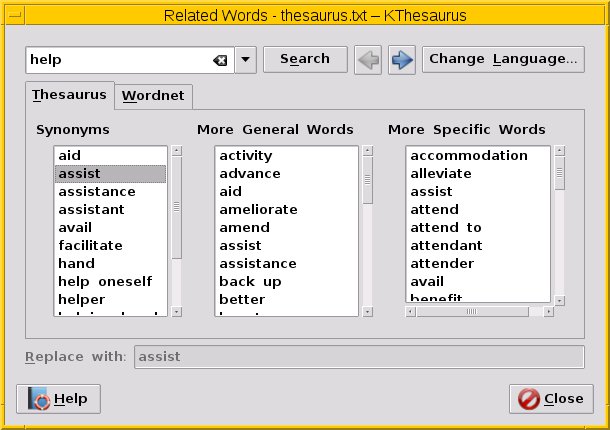
Abbildung 6: Kthesaurus bezieht seine Daten aus der WordNet-Datenbank und versteht sich aus diesem Grund natürlich nur auf Englisch als Sprache.
Im Eingabefeld oben links tragen Sie zuerst das gewünschte Wort ein und lösen über den Knopf Search eine Suche in der Datenbank aus. Daraufhin füllen sich in der Karteikarte Thesaurus die drei Spalten jeweils mit passenden Synonymen (Spalte 1), Oberbegriffen (Spalte 2) und Unterbegriffen (Spalte 3).
Mit dem Knopf Replace ersetzen Sie das Wort im Text durch die Auswahl (nur zu sehen, wenn Sie Kthesaurus innerhalb von Calligra-Office aufgerufen haben). Sie verändern die Suche im Wortschatz, indem Sie einen der Einträge aus den Spalten mit einem Doppelklick auswählen.
Über Karteireiter wechseln Sie zwischen der reinen Suche und dem Eintrag aus der WordNet-Datenbank. Abbildung 7 zeigt einen Überblick zum Wort “help”, gemäß nach der durchschnittlichen Häufigkeit sortiert. Über das Auswahlfeld erhalten Sie weitere Informationen, sofern diese in der WordNet-Datenbank abgespeichert sind, so bspw. Verbundworte (Worte im Zusammenhang), Synonyme, Antonyme und auch Beispiele aus dem Alltag.
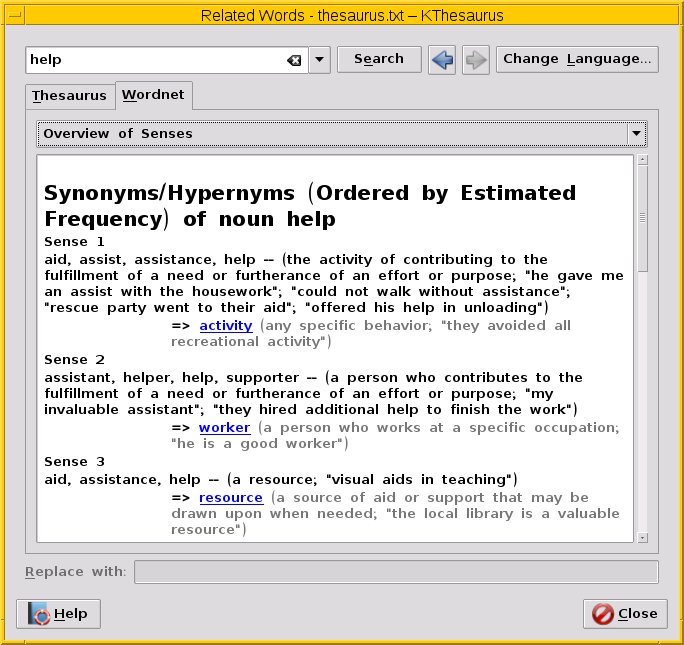
Abbildung 7: Rechercheergebnis mittels Kthesaurus in der WordNet-Datenbank zu “help”.
GoldenDict
Das Projekt GoldenDict [28] vereint verschiedene Quellen unter einer einheitlichen Benutzeroberfläche. Die Desktop-Anwendung setzt auf Qt und das Webkit-Framework [29] auf. In Debian finden Sie das Programm im Paket goldendict.
Das Programm dient als Schnittstelle zu verschiedenen Wörterbüchern und Datenquellen, unter anderem Wikipedia, dem Wiktionary und WordNet, um daraus die Informationen zusammenzustellen. Als Benutzer legen Sie in den Einstellungen fest, welche der Kanäle das Programm auswertet. Im Eingabefeld oben links tragen Sie zunächst den Suchbegriff ein, daraufhin erscheinen in der linken Spalte ähnliche Begriffe, aus denen Sie bei Bedarf wählen. In der mittleren Spalte sehen Sie das Suchergebnis, in der rechten Spalte die dafür verwendeten Quellen (Abbildung 8).
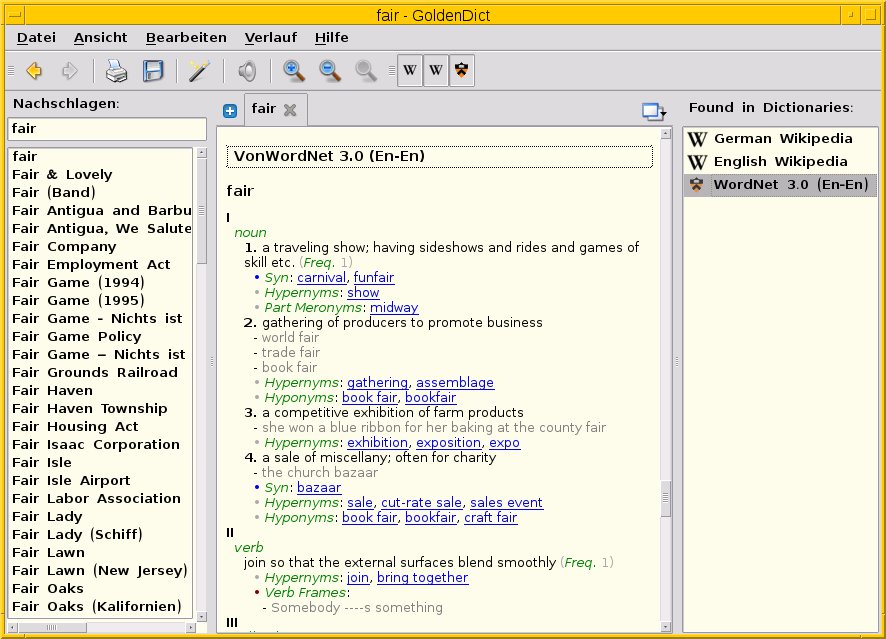
Abbildung 8: Goldendict vereint unter einer Oberfläche die Ergebnisse aus verschiedenen Quellen zum Begriff “fair”.
Im Beispiel erfolgte die Recherche nach dem Begriff “fair” – jeweils in der deutschen und englischsprachigen Wikipedia sowie über die WordNet-Datenbank. Letzteres ist hier als aufbereitetes Suchergebnis dargestellt. Um als Thesaurus auf der Basis von WordNet zu dienen, benötigen Sie noch das zusätzliche Paket goldendict-wordnet aus den Paketquellen, welches die Anbindung der beiden Projekte aneinander ermöglicht.
Wiktionary
Das Wiktionary-Projekt [30] gehört mit seinen mittlerweile über 370?000 Einträgen in mehr als 200 Sprachen zu den imposanteren Wikimedia-Ablegern. Es dient zwar in erster Linie als Wörterbuch, erfasst aber zu jedem Eintrag neben der Worttrennung, Aussprache, Bedeutung und Herkunft auch Synonyme und Antonyme (Abbildung 9). Das Wiktionary nutzen Sie über den Webbrowser, eine API zur Einbindung in eigene Projekte existiert online [31].
Abbildung 9: Suchergebnis zum Begriff “fair”.
Fazit
Dieser Beitrag gibt einen Überblick zu den verschiedenen Thesauri, die derzeit als kommerzielle oder freie Varianten verfügbar sind. Ob zum flinken Nachschlagen im Webbrowser oder über die Kommandozeile – kein Benutzer geht dabei leer aus.
Nur angerissen wurde bislang, wie Sie Thesauri und damit verbundene Technologien in Ihren eigenen Programmen nutzen können. Darauf gehen wir in einem Folgeartikel anhand der Programmiersprache Python ein und beleuchten dabei die Bibliotheken NLTK und AdvaS [32] genauer.
Infos
[1] Frank Hofmann: Cluster-basierte Websuche, Linux Intern 01/2013, Data Becker Verlag, 2013
[2] Schlagwortnormdatei (SWD): http://deposit.d-nb.de/ep/netpub/76/22/36/991362276/_data_dyna/snap_stand_2007_07_13/standardisierung/normdateien/swd.htm
[3] Library of Congress Subject Headings (LCSH): http://id.loc.gov/authorities/subjects.html
[4] Thesaurus Linguae Latinae: http://www.thesaurus.badw.de
[5] Thesaurus Linguae Graecae: http://www.tlg.uci.edu
[6] UNESCO Thesaurus: http://databases.unesco.org/thesaurus/
[7] Europäischer Thesaurus Internationale Beziehungen und Länderkunde: http://www.fiv-iblk.de/ip/ip_thesaurus.htm
[8] Getty Thesaurus of Geographic Names: http://www.getty.edu/research/tools/vocabularies/tgn/index.html
[9] KThesaurus (Debian-Paket): https://packages.debian.org/wheezy/kthesaurus
[10] OpenThesaurus für LibreOffice (Debian-Paket): https://packages.debian.org/wheezy/mythes-de
[11] Lexikon.ch: http://www.lexikon.ch
[12] Synonyme im Woxicon: http://synonyme.woxikon.de
[13] Leo: http://www.leo.org
[14] Beolingus/Dict: http://dict.tu-chemnitz.de
[15] Centre National de Ressources Textuelles et Lexicales: http://www.cnrtl.fr
[16] OpenThesaurus: http://www.openthesaurus.de
[17] WordNet: http://wordnet.princeton.edu/wordnet/
[18] Macmillan Dictionary: http://www.macmillandictionary.com/tools/aboutapi.html
[19] Merriam-Webster’s Collegiate Thesaurus: http://www.dictionaryapi.com/products/api-collegiate-thesaurus.html
[20] Cambridge Dictionaries Online: http://dictionary-api.cambridge.org/
[21] Pons: http://www.pons.com/specials/api
[22] Visual Thesaurus: http://www.visualthesaurus.com
[23] Wordnik, http://developer.wordnik.com
[24] WordNet (Debian-Paket): https://packages.debian.org/wheezy/wordnet
[25] Perl-Modul WordNet-QueryData: http://search.cpan.org/~jrennie/WordNet-QueryData/
[26] Python Natural Language Toolkit (NLTK): http://www.nltk.org
[27] Papyrus: http://www.papyrus.de
[28] Goldendict: http://goldendict.org
[29] WebKit-Framework: http://www.webkit.org
[30] Wiktionary: https://de.wiktionary.org/wiki/Wiktionary:Hauptseite
[31] Wiktionary-API: http://en.wiktionary.org/w/api.php
[32] AdvaS Advanced Search: http://sourceforge.net/projects/advas/




