

Mit einem kleinen Skript verarbeiten Sie große Mengen an Textscans zu PDF-Dateien, die Sie dank OCR mit typischen Unix-Werkzeugen im Volltext durchsuchen.
Wer gedruckte Schrift in digitaler Form richtig nutzen möchte, braucht Sie in einer Form, die ein Durchsuchen erlaubt. Ein reines Umwandeln in Bitmaps macht das nicht möglich. Darf das Layout der Informationen gegenüber dem Original abweichen, bietet sich ein Speichern als ASCII-Text an.
Möchten Sie das Original erhalten, ist das PDF die erste Wahl, das am Anfang oder Ende die per Texterkennung (OCR) gewonnene Information zusätzlich beinhaltet. Diese Datei durchsuchen Sie unter Linux dann mit gängigen Werkzeugen wie Grep.
Hinter vielen GUI-Anwendungen zum Scannen und zur Texterkennung arbeiten Werkzeuge im Hintergrund. Deren Möglichkeiten stehen alternativ direkt als Shell-Kommando bereit. Auf diese Weise schaffen Sie bei Bedarf eigene Tools, die genau Ihren Anforderungen entsprechen. Die Grundlagen bilden Scanimage und Cuneiform oder Tesseract.
Vom Papier zur Bild
Installieren Sie die Pakete libsane und sane-utils [1]. Es ist nicht zwingend notwendig, den Sane-Daemon zu starten. Im normalen Betrieb reicht der Aufruf des Programmes in einem Terminal. Bei der Installation über den Paketmanager legt das Setup einen Benutzer sane oder scanner in /etc/passwd zusammen mit einer entsprechenden Gruppe an. Fügen Sie in /etc/group in der zutreffenden Zeile jene Benutzer hinzu, die auf den Scanner zugreifen dürfen. Das sieht dann ähnlich dem folgenden Beispiel aus:
scanner:x:115:saned,harald,monika,kopierer
Die Anleitung von Sane gibt umfangreiche Hinweise darauf, wie und ob die Software einen Scanner unterstützt. In manchen Fällen setzt das voraus, dass Sie eine Datei aus dem Treiber für Windows extrahieren und auf dem Linux-Rechner ablegen. Viele neuere Scanner unterstützt die Software Sane jedoch direkt. Eine gute Beschreibung zum Installieren eines Scanners finden Sie im Web [2].
Suchen Sie nach dem angeschlossenen Scanner mit dem Aufruf sane-find-scanner (Abbildung 1). Das Programm schickt, mit Ausnahme bei den Stapeljobs, die Daten auf die Standardausgabe. In diesen Fällen lenken Sie die Ausgabe selbst in eine Datei um.
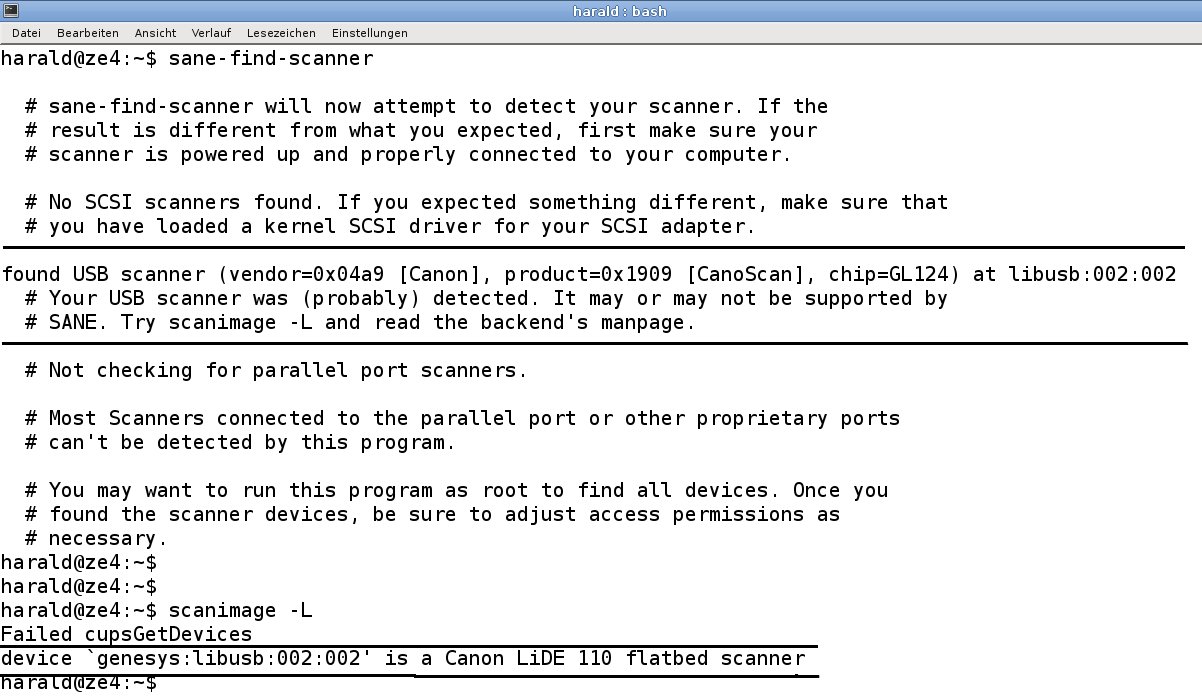
sane-find-scanner und scanimage -L.” width=”300″ height=”174″ />
sane-find-scanner und scanimage -L. Nach der Konfiguration testen Sie mit scanimage -T deren Funktionsfähigkeit: Beim Scanner sollte sich jetzt der Schlitten mit der Lesezeile in Bewegung setzen und im Terminal sollte eine entsprechende Ausgabe zu sehen sein (Abbildung 2).
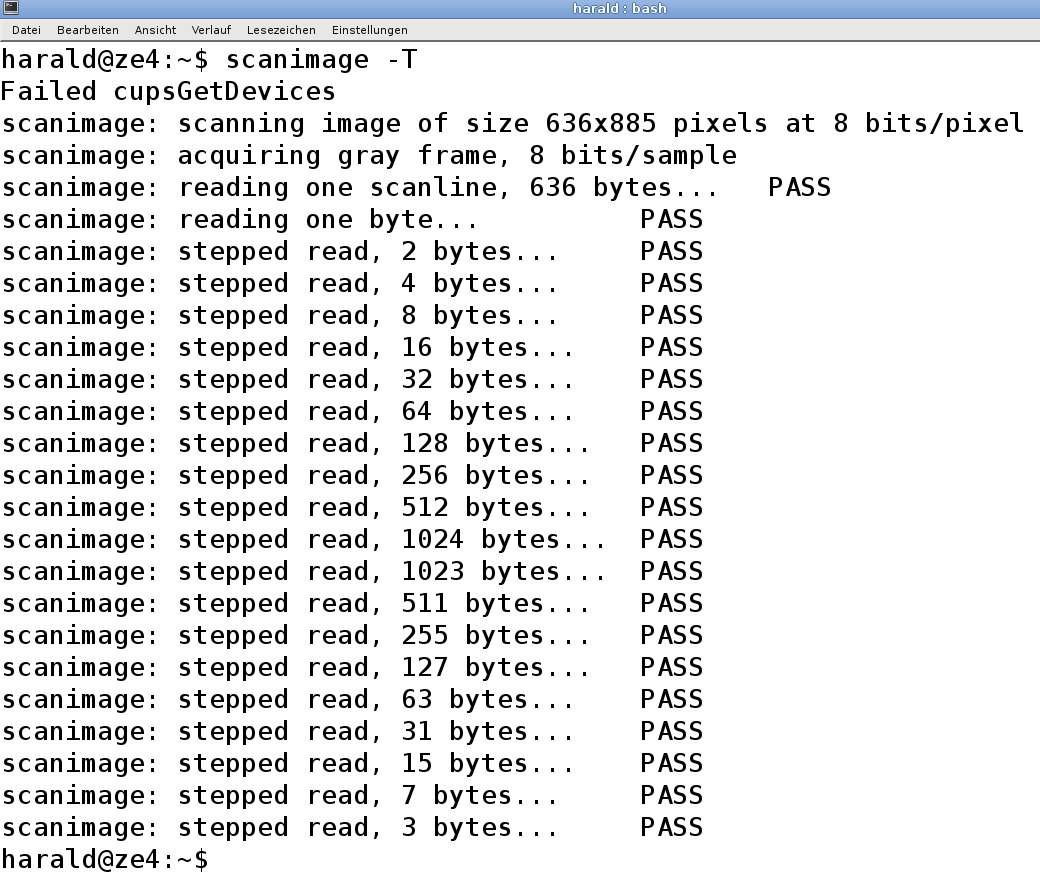
Abbildung 2: War die Konfiguration korrekt, erzeugt der Testlauf eine entsprechende Ausgabe.
Hat bis zu dieser Stelle alles funktioniert, ist damit das Einbinden der Hardware abgeschlossen. Die wichtigsten Optionen von Scanimage finden Sie in der Tabelle “Optimale Konfiguration”. Verfügen Sie über einen Scanner mit automatischen Dokumenteneinzug und Wendeeinheit (ADF), lohnt sich ein Blick auf das Tool Scanadf.
Optimale Konfiguration
| Option | Aktion |
|---|---|
-L |
Anzeige angeschlossener Scanner |
-A |
Anzeige aller Optionen, passend zum Modell |
-d Gerätedatei |
Angabe des Scanners |
--mode Modus |
Auswahl Schwarz/Weiß (lineart), Grau (gray) oder Farbe (color) |
--resolution DPI |
Auflösung in DPI, mögliche Werte siehe Ausgabe von -A |
--depth Wert |
Angabe Farbtiefe: 1 (Schwarz/Weiß)), sonst 8 oder 16 |
--brightness Wert |
Helligkeit (-100% bis +100% |
--batch |
Stapelbetrieb |
--batch-count Zahl |
Begrenzt den Stapelbetrieb |
--batch-start ZAHL |
Startwert für Seite |
--batch-increment ZAHL |
Schrittweite für Seitenzahl, 2 für doppelseitige Dokumente |
--batch-prompt |
Warten auf Eingabe beim Stapelbetrieb |
--format=FORMAT |
Format der Ausgabedatei (PNM/TIFF) |
-T |
Testlauf |
-p |
Fortschrittsanzeige |
Das Shell-Skript
Die Schritte beim Scannen von Dokumenten eignen sich hervoragend, um ein Skript daraus zu basteln. Listing 1 arbeitet die folgende Punkte ab: Einscannen der Dokumente, Ablage im TIFF-Format sowie Auslesen des Texts aus den TIFF-Dateien (OCR). Anschließend ruft das Skript einen Editor zur manuellen Korrektur des Ergebnisses auf.
Stimmt alles, bleibt nur noch das Konvertieren der TIFF-Datei ins PDF-Format. Zu guter Letzt erzeugt das Skript eine PDF-Datei aus der Datei mit dem Ergebnis aus dem OCR-Lauf und fügt die beiden PDF-Dateien zusammen. Als Ergebnis erhalten Sie eine PDF-Datei, die es erlaubt, diese mit Pdfgrep oder im Betrachter zu durchsuchen.
Listing 1
#! /bin/sh SCANNER="genesys:libusb:002:002" TXTLANG="deu" EDITOR="kwrite" echo -n "Projektname: "; read PROJEKT if [ -z $PROJEKT ]; then exit fi scanimage -d $SCANNER --batch --batch-start 10000 --batch-prompt --resolution 600 --mode lineart --format=tiff for TIF in out*.tif; do echo "Reading $TIF" TXT=$TIF.tif.txt tesseract $TIF $TXT -l $TXTLANG done cat *.txt >> $PROJEKT.txt $EDITOR $PROJEKT.txt PAGES=$(ls -l out*.tif | wc -l) for TIF in out*.tif; do echo "Converting $TIF" PDF=$TIF.tif.pdf if [ "$TIF" = "out10000.tif" ]; then convert $TIF vorlage.pdf else convert $TIF $PDF pdftk A=vorlage.pdf B=$PDF CAT A B output vorlage-1.pdf mv vorlage-1.pdf vorlage.pdf fi done recode UTF8..ISO-8859-15 $PROJEKT.txt a2ps -o $PROJEKT.ps $PROJEKT.txt ps2pdf14 $PROJEKT.ps $PROJEKT-text.pdf pdftk A=vorlage.pdf B=$PROJEKT-text.pdf CAT A B output $PROJEKT.pdf okular $PROJEKT.pdf echo -n "Hilfsdaten löschen ? (j) "; read loesch if [ "$loesch" = "j" ]; then rm $projekt.ps rm out*.tif rm out*.pdf rm out*.txt rm vorlage.pdf rm $projekt-text.pdf rm *~ fi
Zeile 12 mit dem Aufruf von Scanimage zeigt das Einbinden des Stapelbetriebes. Die Zahl der zu scannenden Seiten bleibt dabei offen. Sie fordern mit [Eingabe] jede Seite einzeln an; für den Abbruch des Vorgangs nutzen Sie [Strg]+[D]. Im Beispiel war dies nach zwei Seiten der Fall. Die Ziffer im Dateinamen beginnt mit 10000. Auf diese Weise umgehen Sie Fehler beim Sortieren der Dateien, die sich nachfolgend auf das Erzeugen der Textdateien auswirken.
Ferner erstellen Sie die Scans mit einer Auflösung von 600 DPI. Das bietet sich an, wenn die Vorlage kleine Schrift enthält. Die Scans sollen in schwarz-weiß erfolgen. Die Bilddateien legt das Skript im TIF-Format ab (Abbildung 3).
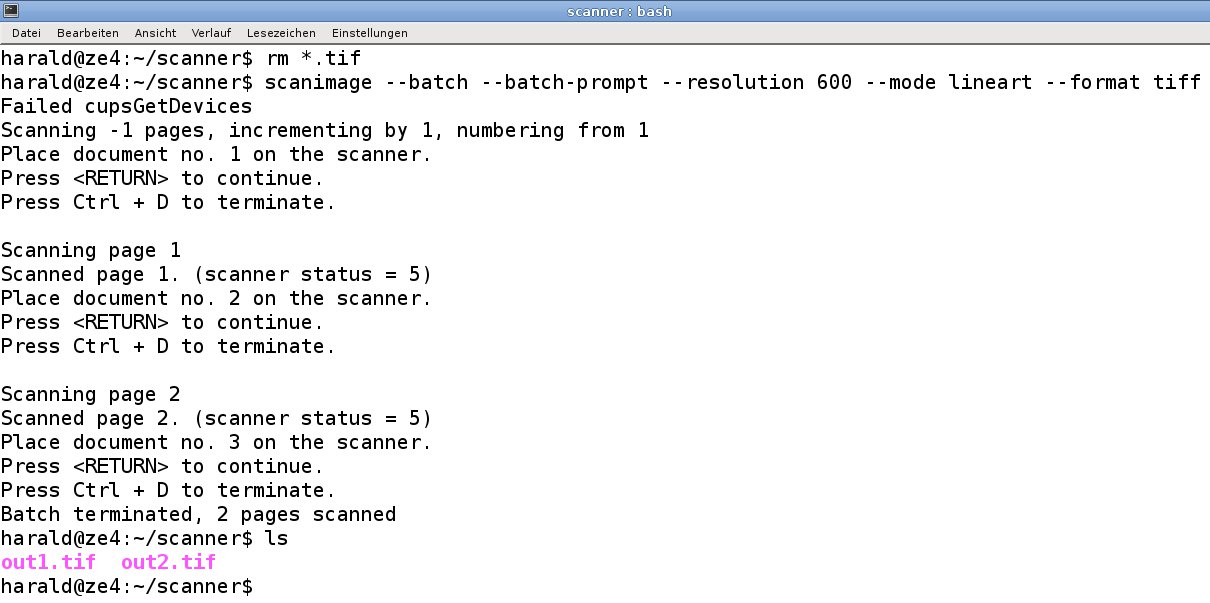
Abbildung 3: Die Ausgabe der Scans erfolgt im Beispiel im TIF-Format.
Manche ältere Modelle arbeiten bei einer Auflösung über 600 DPI besonders langsam. Solche Geräte lesen die Seite oft stückweise ein und bleiben dann stehen, bis die Daten auf dem Rechner abgelegt sind. Erst danach bewegt sich der Schlitten wieder ein Stück weiter. Das verführt zu der Annahme, dass Scanimage hängt und nur noch der Ausweg bleibt, den Prozess mit Gewalt zu beenden.
Mit der Fortschrittsanzeige (-p) haben Sie den Verlauf im Blick. Erst wenn sich die Anzeige (Abbildung 4) über mehrere Minuten nicht verändert, sollten Sie das Programm abbrechen. Des Weiteren war im Test die Angabe des Gerätes (-d Gerät) notwendig, weil sonst durch das Umlenken der Ausgabe die Fehlermeldung über nicht gefundene Cups-Geräte in der Zieldatei gelandet wäre.
Abbildung 4: Die Fortschrittsanzeige hilft bei älteren Scanner-Modellen, dem Verlauf der Arbeit von Scanimage zu folgen.
Qual der Wahl
Einen eindeutigen Favoriten unter den OCR-Programmen gibt es nicht. Mit Cuneiform [3] und Tesseract [4] stehen aber zwei alltagstaugliche Programme bereit. Im Test kam ein kleiner Mustertext zum Einsatz (Abbildung 5), der von beiden Programmen die Stärken und Schwächen aufzeigt. Die eingescannte Datei lag im TIF-Format mit einer Auflösung von 600 DPI vor.

Abbildung 5: Ein Mustertext deckt die Stärken und Schwächen der Texterkennungsprogramme Cuneiform und Tesseract auf.
TIPP
Bei Scans von Zeitschriftenartikeln, Gebrauchsanleitungen und Buchseiten fällt das Ergebnis weniger unterschiedlich aus. Daher erweist es sich für ein Shellskript als gute Taktik, beide OCR-Programme einzusetzen.
Cuneiform
Im Test wurde das Programm auf einem Debian-System aus den Quellen installiert, was nach dem Auflösen einiger Abhängigkeiten klappte. Die Software erwartet Eingabedateien im TIF-Format. Der Aufruf des Programm folgt der folgende Syntax:
cuneiform -l Sprache -f text -o Ausgabedatei Bilddatei
Die Option -l Sprache ermöglicht die Texterkennung in der angegebenen Sprache. Die zur Zeit unterstützten Sprachen finden Sie in der Tabelle “Sprachen in Cuneiform”.
Sprachen in Cuneiform
| Sprache | Kürzel |
|---|---|
| Bulgarisch | bul |
| Dänisch | dan |
| Deutsch | ger |
| Englisch | eng |
| Estländisch | est |
| Französisch | fra |
| Italienisch | ita |
| Kroatisch | hrv |
| Lettländisch | lav |
| Litauisch | lit |
| Niederländisch | dut |
| Polnisch | pol |
| Portugiesisch | por |
| Rumänisch | rum |
| Russisch | rus |
| Schwedisch | swe |
| Serbisch | srp |
| Slowenisch | slo |
| Spanisch | spa |
| Tschechisch | cze |
| Türkisch | tur |
| Ukrainisch | ukr |
| Ungarisch | hun |
Die Option -f bestimmt das Format der Ausgabe: text für reinen Text, smarttext für Text mit Zeilen und Absätzen entsprechend der Vorlage, rtf für eine Rich-Text-Format-Datei und html für eine HTML-Datei. Weitere Optionen fügen Sie bei Bedarf nach der Angabe der Ausgabedatei ein. Dazu gehört unter anderem --dotmatrix, was das Auswerten von Ausdrucken von Nadeldruckern verbessert, mit --singlecolumn fassen Sie mehrere Spalten zu einer zusammen und --fax verbessert das Auswerten von gefaxten Dokumenten.
In Abbildung 6 finden Sie einen Auswertungslauf mit anschließendem Ergebnis. Versuche mit Vorlagen, welche weniger als 200 DPI aufwiesen, brachten keine brauchbaren Ergebnisse. Ab 300 DPI funktioniert das Auswerten. Kommen in der Vorlage verschiedene Schriftgrößen und sehr kleine Schriftarten vor, brauchen Sie beim Scannen eine Auflösung von 600 DPI.
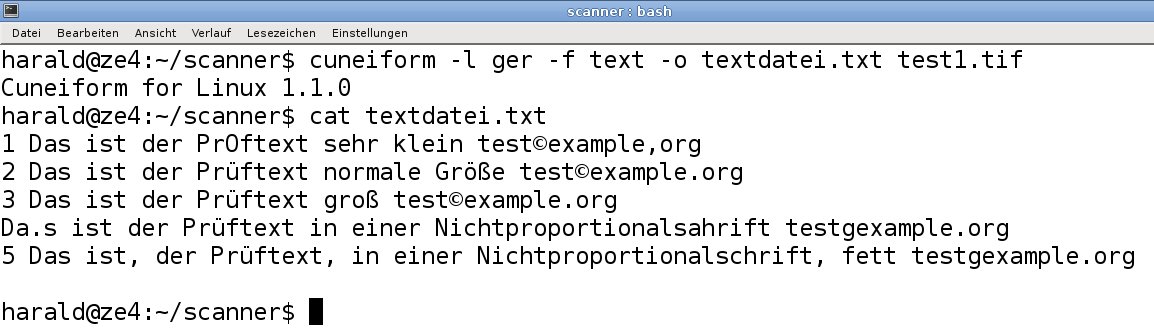
Abbildung 6: Nach dem Auswerten einer Seite mit Cuneiform zeigt das Ergebnis.
Tesseract
Die Entwicklung von Tesseract begann 1985. Im Gegensatz zu Cuneiform gibt die Software reine Textdateien aus. Dem Paket liegen Hilfsprogramme bei, mit denen Sie dem Programm neue Schriften beibringen (cntraining, mftraining). Ein OCR-Lauf mit Tesseract folgt der Syntax in Listing 1, Zeile 17.
Derzeit verarbeitet Tesseract folgende Sprachen: Deutsch (deu), Frakturschriften, Deutsch (deu-f), Englisch (eng), Französisch (fra), Niederländisch (nld), Italienisch (ita), Portugiesisch (por), Spanisch (spa) und Vietnamesisch (vie). Das Auswerten setzt die Daten in Form einer Bilddatei im TIF-Format voraus. Abbildung 7 zeigt einen Durchlauf. Im Vergleich zu Cuneiform erkennt Tesseract Sonderzeichen und Zahlen besser.

Abbildung 7: Tesseract wertet Sonderzeichen und Zahlen in vielen Fällen besser aus, als der Mitbewerber.
Helferlein
Das mächtige Programm Convert aus dem ImageMagick-Paket [5] hilft beim Erstellen der PDF-Datei aus der TIFF-Datei. Mit diesem haben Sie nicht nur die Möglichkeit, andere Formate zu verarbeiten, sondern auch weitere Eigenschaften von Bilddateien per Shell-Befehl ändern. Zum Erzeugen einer PDF-Datei reicht der Aufruf aus Listing 1, Zeile 31.
Mit Pdftk [6] fügen Sie PDF-Dateien zusammen. Zeile 32 in Listing 1 zeigt, wie sie die Software einsetzen. Weitere Funktionen des Programmes sind das Zerlegen, Rotieren, Ver- und Entschlüsseln und Verändern von PDF-Dateien.
Zum Erzeugen einer PDF-Datei aus einer Textdatei braucht es mehrere Schritte: Die allermeisten Distributionen setzen auf UTF-8 als Zeichensatz in der Shell. Nachdem viele Werkzeuge zum Konvertieren auf die Zeichensätze aus der ISO-8859-Familie getrimmt sind, setzen Sie als ersten Schritt mit Recode [7] die Textdatei um (Listing 1, Zeile 37). Das Programm setzt selbst uralte Zeichensätze aus den Siebziger Jahren des letzten Jahrhunderts um.
Mit Enscript [8] oder A2ps [9] erzeugen Sie als Zwischenschritt eine Postscript-Datei. Die beiden Programme unterscheiden sich vor allem in der Form der Ausgabe. Sie funktionieren aktuell nur mit den ISO-Zeichensätzen. Den Aufruf von A2ps sehen Sie in Listing , Zeile 38; der von Enscript funktioniert analog. Im letzten Schritt erzeugt das Skript ein PDF-File aus der Postscript-Datei. Hierfür bietet sich Ps2pdf14 aus dem Ghostscipt-Paket [10] an (Listing 1, Zeile 39).
Im letzten Schritt setzt das Skript die eingescannten Dokumente und den extrahierten Text zusammen. Damit erhalten Sie ein Dokument, dass Ihnen den Inhalt liefert und die Möglichkeit bietet, diesen mit üblichen Unix-Tools zu durchsuchen.
Fazit:
Das Einscannen von Dokumenten und das Extrahieren von Text aus diesen gelingt mit den Werkzeugen der Shell ohne großen Aufwand. Das Muster-Skript liefert bereits ein funktionsfähiges Ergebnis. Mit ein wenig Shell-Know-how erweitern Sie es und passen es auf Ihre Bedürfnisse leicht erweitern, zum Beispiel mit dem Tool Unpaper [11].
Glossar
-
OCR
-
Optical Character Recognition (engl.). Ein Verfahren zum automatisierten Erkennen von Textstellen durch optische Lesegeräte sowie das anschließende Umwandeln in Textzeichen inklusive Fehlerkorrektur.
Infos
[1] Sane: http://www.sane-project.org/
[2] Scanner installieren: http://wiki.ubuntuusers.de/Scanner
[3] Cuneiform: Erik Bärwaldt, “Alphabetisierung”, LU 04/2011, S. 48, https://www.linux-community.de/22836
[4] Tesseract: Erik Bärwaldt, “Buchstabensalat”, LU 05/2011, S. 84, https://www.linux-community.de/22905
[5] ImageMagick: Thomas Drilling, “Zauberkasten”, LU 08/2012, S. 68, https://www.linux-community.de/26395
[6] Pdftk: http://www.pdflabs.com/tools/pdftk-the-pdf-toolkit
[7] Recode: http://recode.progiciels-bpi.ca/index.html
[8] Enscript: http://www.markkurossi.com/genscript/
[9] A2ps: http://www.inf.enst.fr/~demaille/a2ps/
[10] Ghostscript: http://www.ghostscript.com/
[11] Unpaper: http://unpaper.berlios.de




