

In einem Bestand von Hunderten von LibreOffice-Dokumenten finden Sie mit Odtgrep im Handumdrehen die gewünschte Datei.
OpenOffice und LibreOffice speichern in der Standardeinstellung Daten im Open Document Format ODF ab [1]. Wer seine Dokumente nicht allein über Ordner oder Dateinamen organisieren möchte, dem ermöglicht das Format mittels Metadaten die Suche über etliche Zusatztools (siehe Kasten “Suchmaschinen für den Desktop”). Um dieses Feature voll auszureizen, gilt es sich mit dessen Feinheiten vertraut zu machen.
Suchmaschinen für den Desktop
Bei der Suche nach Dateien kommen zunehmend entsprechende Spezialprogramme zum Einsatz, die sogenannten Desktop-Suchmaschinen. Dazu zählen neben Google Desktop die Aufsteiger Metatracker [11], Imgseek [12], Strigi [13] und Terrier [14]. Beim bekannten Vorreiter Beagle stockt mittlerweile die Entwicklung. Für die Suche in einem umfangreicheren Datenbestand eignet sich die Kombination aus den beiden Apache-Projekten Lucene [15] und Solr [16].
Eine Suchmaschine verarbeitet die Daten in mehreren Phasen. Sie indexiert und klassifiziert vorab Dokumente, um später anhand dieser Informationen zu entscheiden, ob ein Dokument aus dem Datenbestand zu einer Suche passt. Falls ja, kommt es in die Liste der Treffer. Für die Klassifikation orientiert sich eine Suchmaschine an vier Faktoren: Dem Format des Dokuments, dessen Metadaten, der Struktur des Texts und am tatsächlichen Inhalt.
Die Metadaten helfen dabei, den Inhalt eines Dokuments thematisch zuzuordnen. Dazu beschreiben sie diesen beispielsweise anhand von Schlüsselworten. Liegen keine Metadaten vor, versuchen die Suchmaschinen über den Inhalt der Dokumente Informationen abzuleiten. Dabei kommen Methoden aus der Sprachwissenschaft sowie statistische Verfahren zum Einsatz.
Beim Strukturieren des Texts helfen Formatvorlagen (siehe Kasten “Struktur festlegen”), diese zusätzlich einen barrierefreien Zugriff ermöglichen. Über diesen greift auch die Suchmaschine auf die Daten zu und ermittelt so die einzelnen Bestandteile des Dokuments. Ohne diese zusätzliche Information besteht ein Dokument aus Sicht der Suchmaschine nur aus gleichwertigem, unstrukturiertem Text.
Struktur festlegen
LibreOffice bietet wie die meisten Office-Pakete die Möglichkeit, über Formatvorlagen die Optionen zum Darstellen (Formatieren) von Elementen separat zu definieren. Das bietet sich auch an, um wiederkehrende Inhalte zu konfigurieren – beispielsweise für Kopf- und Fußzeilen oder generell, um das Aussehen von Textteilen zu vereinheitlichen. Die Vorlagen unterscheiden sich je nach Einsatzgebiet: Absatz, Rahmen, Seite. Ausgenommen sind hier nur die Einstellungen für die Spaltenaufteilung. Weitere Informationen und Beispiele zu den Vorlagen finden sich in den Wikis von Open- und LibreOffice ([17],[18],[19]).
Metadaten eingeben
Die Offenheit und ausführliche Dokumentation von ODF vereinfacht die Suche in den Dateien erheblich. Allerdings speichern bislang nur wenige Anwender Metadaten in Dokumenten – entweder aus Unwissenheit oder schlicht, weil der Aufwand zu hoch erschien. Dabei ist die Arbeit oft flink erledigt und hilft später schnell zu erfassen, worum es im Dokument ging.
Unter Datei | Eigenschaften öffnen Sie den Reiter Beschreibung und füllen die vier Felder Titel, Thema, Schlüsselworte und Kommentar mit möglichst aussagekräftigen Begriffen aus. Als Kommentar bietet sich eine Zusammenfassung des Inhalts an. Ein Klick auf OK speichert die Daten (Abbildung 1).
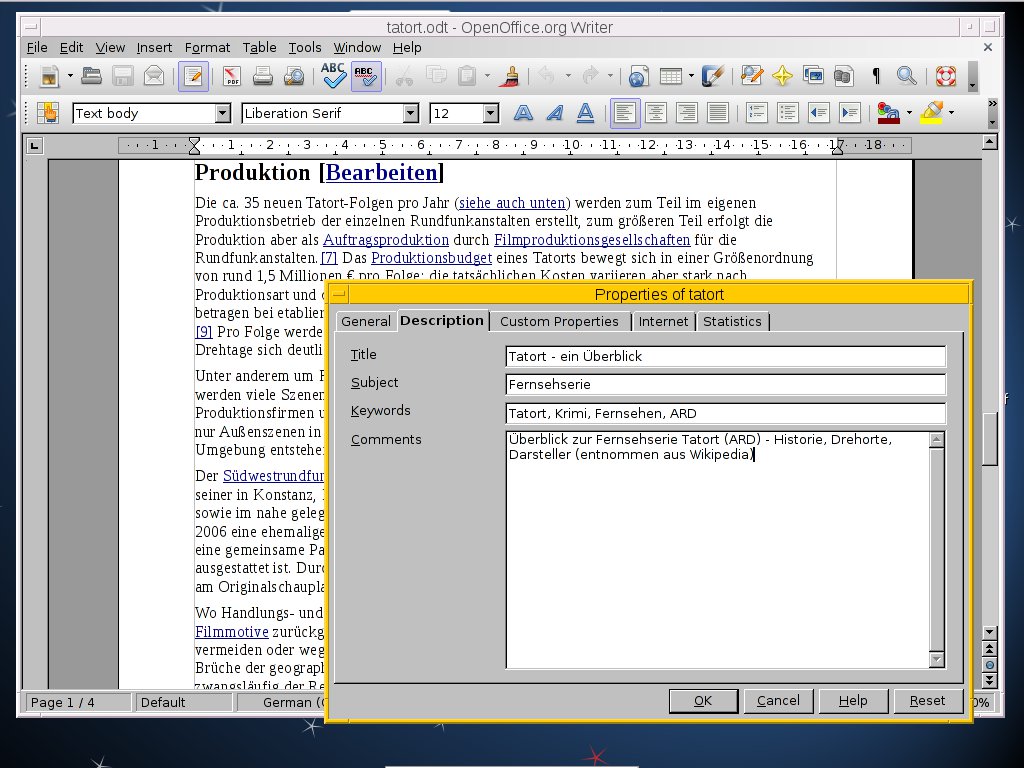
Abbildung 1: Mit nur wenigen Angaben in den Eigenschaften eines Dokuments erhöhen Sie die Chance, später schnell das richtige Dokument wiederzufinden.
Metadaten auslesen
Ein ODF-Dokument besteht aus einer Reihe von XML-Dateien mit fest vorgegebenen Dateinamen, die in einem Zip-Archiv lagern. Wenden Sie hingegen das Kommando file auf eine Datei aus OpenOffice oder LibreOffice an, erhalten Sie als Rückgabewert OpenDocument Text, für eine Calc-Tabelle hingegen OpenDocument Spreadsheet (Abbildung 2).
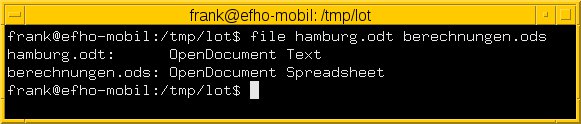
Abbildung 2: File erkennt den Typ des Dokuments – Text oder Tabelle.
Gemäß der Definition des Formats findet sich die Beschreibung für den Dateityp in der im Archiv enthaltene Datei mimetype, die explizit unkomprimiert an erster Stelle im Archiv liegt, sodass das Auslesen ohne Entpacken gelingt. Packen Sie ein entsprechendes Dokument mit dem Kommando unzip Datei aus, erhalten Sie die in der Tabelle “ODF-Dokumente: Bestandteile” erwähnten Dateien.
ODF-Dokumente: Bestandteile
| Dateiname | Bedeutung |
|---|---|
mimetype |
MIME-Type-Information |
content.xml |
Inhalte des Dokuments als XML-Datei |
meta.xml |
Meta-Informationen zum Dokument |
settings.xml |
Dokumentspezifische Einstellungen |
styles.xml |
Dokumentspezifische Formatierungen |
Configurations2 |
Bestandteile des Dokuments |
META-INF/manifest.xml |
Liste aller weiteren Dateien mit MIME-Typ |
Thumbnails/thumbnail.png |
Vorschau der ersten Dokumentenseite |
Aus diesen Dateien ist für Sie zunächst nur die XML-Datei meta.xml interessant, da sie die Meta-Informationen zum Dokument beinhaltet. Dazu zählen der Titel, das Thema, die Beschreibung sowie die Schlüsselwörter. Weiterhin merkt sich die Office-Suite das Erstellungsdatum, die Dauer des Bearbeitens und die Anzahl der Editiervorgänge (editing cycles). Zusätzlich finden sich statistische Angaben wie Wort-, Satz- und Seitenanzahl sowie die Programmversion, mit der Sie das Dokument bearbeitet haben.
Für die Suche in der XML-Datei über die Kommandozeile bietet sich das Tool xml_grep aus den XML-Twig-Tools [2] an. Der Knoten dc:description aus dem XML-Baum enthält die Beschreibung. Listing 1 zeigt, wie Sie dessen Inhalt auslesen. Als Ergebnis erzeugt das Tool zunächst ein valides XML-Dokument mit dem gewünschten Knoten (oben), mit dem Parameter --text_only gibt es nur den Inhalt des Knotens aus (unten). Die Ausgabe eignet sich zum Weiterverarbeiten mit anderen Werkzeugen.
Listing 1
$ xml_grep "dc:description" meta.xml <?xml version="1.0" ?> <xml_grep version="0.7" date="Tue Aug 28 11:29:27 2012"> <file filename="meta.xml"> <dc:description>irgendwas</dc:description> </file> </xml_grep> $ xml_grep --text_only "dc:description" meta.xml irgendwas
Möchten Sie alle Meta-Informationen zum Dokument anzeigen, hilft Ihnen das Shell-Skript odtinfo.sh (Listing 2). Es funktioniert ähnlich wie pdfinfo, welches die Metadaten zu PDF-Dokumenten anzeigt. Sie rufen es über die Kommandozeile mit der Datei als Parameter auf (Listing 3). Das Skript entpackt aus dem Archiv zunächst nur die Datei mit den Meta-Informationen (meta.xml). Danach liest es die Informationen zu den gewünschten Knoten ein und gibt diese formatiert auf der Standardausgabe aus.
Listing 2
#!/bin/bash
if [ $# -ne 1 ]; then
echo "usage: odtinfo filename"
exit 1
fi
filename="$1"
which xml_grep > /dev/null
if [ $? -ne 0 ]; then
echo "cannot find xml_grep"
exit 1
fi
grep="xml_grep --text_only"
oometa="//office:document-meta/office:meta"
filecontent=$(unzip -p "$filename" meta.xml)
title=$(echo $filecontent | $grep "$oometa/dc:title")
subject=$(echo $filecontent | $grep "$oometa/dc:subject")
description=$(echo $filecontent | $grep "$oometa/dc:description")
keywords=$(echo $filecontent | $grep "$oometa/meta:keyword" | tr -s '\n' ' ')
creationdate=$(echo $filecontent | $grep "$oometa/meta:creation-date" | tr 'T' ' ')
editingcycles=$(echo $filecontent | $grep "$oometa/meta:editing-cycles")
editingduration=$(echo $filecontent | $grep "$oometa/meta:editing-duration")
generator=`echo $filecontent | $grep "$oometa/meta:generator"`
echo " file: $filename"
echo " title: $title"
echo " subject: $subject"
echo " description: $description"
echo " keywords: $keywords"
echo " creation date: $creationdate"
echo " editing cycles: $editingcycles"
echo "edition duration: $editingduration"
echo " generator: $generator"
Listing 3
$ ./odtinfo.sh tatort.odt
file: tatort.odt
title: Tatort - ein Überblick
subject: Fernsehserie
description: Überblick zur Fernsehserie Tatort (ARD) - Historie, Drehorte, Darsteller (entnommen aus Wikipedia)
keywords: Tatort, Krimi, Fernsehen, ARD
creation date: 2012-08-27 21:51:05
editing cycles: 1
edition duration: PT00H02M17S
generator: OpenOffice.org/3.2$LinuxOpenOffice.org_project/320m19$Build-9505
Mehrere Dokumente durchsuchen
Neben dem Auswerten der Meta-Informationen steht häufig die Frage im Vordergrund, welches Dokument den oder die Suchbegriffe enthält. Einige wenige Dokumente durchstöbern Sie vielleicht noch per Hand über die grafische Oberfläche, bei einer größeren Menge an Dateien hilft oft nur ein Automatismus, um zum Ziel zu kommen. Ein Stöbern im Web fördert zwei Lösungen dafür zutage: Loook [3] und Odtgrep [4].
Hinter Loook verbirgt sich ein Python-Skript mit einer TK-Oberfläche (Abbildung 3). Nach der Angabe des Verzeichnisses und der Suchbegriffe listet es alle passenden Dateien auf. Bei Odtgrep handelt es sich um ein einfach gehaltenes Shell-Skript, das zunächst im Verzeichnis rekursiv nach ODT-Dateien sucht und aus diesen die gewünschte Information filtert.
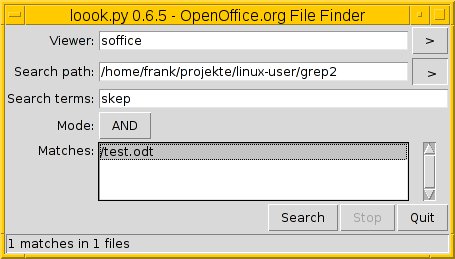
Abbildung 3: Loook hilft bei der Suche in ODF-Dokumenten.
Das Verzeichnis übergeben Sie beim Aufruf als ersten Parameter. Danach extrahiert Odtgrep aus jeder Datei den Dokumentinhalt (content.xml) und stöbert darin mittels Grep nach dem Suchbegriff, den Sie als zweiten Parameter übergeben. Treffer schreibt das Skript auf die Standardausgabe, dann setzt es die Suche bei der nächsten Datei fort. Listing 4 zeigt eine Suche nach dem Muster Hamburg im aktuellen Verzeichnis, repräsentiert durch den einzelnen Punkt.
Listing 4
$ ./odtgrep.sh . Hamburg Suchbegriff gefunden in dresden.odt Suchbegriff gefunden in hamburg.odt Suchbegriff gefunden in praxis.odt Suchbegriff gefunden in tatort.odt
Aufgrund der Einfachheit unterscheidet das Skript nicht zwischen Knotenbezeichnern und tatsächlichem Inhalt: Es meldet also unter Umständen unzutreffende Fundstellen, sogenannte “false positives”. Mit einem Aufruf des Stream-Editors Sed filtern Sie die XML-Knoten heraus (Listing 5). Dazu bekommt Sed als Parameter einen regulären Ausdruck, mit dessen Hilfe es alle überflüssigen Zeichen im Textstrom durch ein Leerzeichen ersetzt.
Listing 5
#!/bin/bash
if [ $# -ne 2 ]; then
echo "Benutzung: odtgrep-sed Pfad Ausdruck"
exit 1
fi
find $1 -name "*.odt" | while read datei
do
unzip -ca "$datei" content.xml | sed 's/<[^>]*>/ /g' | grep -qli "$2"
if [ $? -eq 0 ]; then
echo "Suchbegriff gefunden in " $datei
fi
done
Knoten im XML entsprechen der Form Name</Name>. Das macht sich das Skript zunutze: Zunächst sucht es nach einem Kleiner-als-Zeichen, auf das eine beliebigen Menge von Zeichen folgt, die aber kein Größer-als-Zeichen enthält. Den Abschluss bildet ein Größer-als-Zeichen. Dieser Trick sowie weitere Details zum Umgang mit Sed (und Awk) finden Sie im gleichnamigen Buch [5].
Als Alternative bietet sich das Werkzeug Deepgrep an. Das Kommandozeilenwerkzeug, das zum Paket strigi-utils [6] gehört, kommt bei der Desktop-Suchmaschine Strigi als Backend zum Einsatz. Das Programm bringt weder Dokumentation noch Manpage mit, was den Einsatz nicht unbedingt erleichtert.
Deepgrep durchsucht rekursiv komprimierte Archive (Tar.gz, Zip, DEB, RPM) sowie MP3-Dateien, Microsoft-Office-Dateien und PDF-Dokumente. Axel Beckerts Blog liefert eine ausführliche Evaluation der Software [7]. Binden Sie sie ins Skript aus Listing 5 ein, erhalten sie eine Version analog zu Listing 6. Beide Skripte sind gleichwertig und liefern ein identisches Ergebnis, wobei Listing 6 etwa um den Faktor 5 bis 10 schneller läuft.
Listing 6
#!/bin/bash
if [ $# -ne 2 ]; then
echo "Benutzung: odtgrep2 Pfad Ausdruck"
exit 1
fi
find $1 -name "*.odt" | while read datei
do
treffer=$(deepgrep "$2" "$datei" | wc -l)
if [ $treffer -ne 0 ]; then
echo "Suchbegriff gefunden in " $datei
fi
done
Fazit
Es erstaunt, dass es bisher für den hier beschriebenen Anwendungsfall noch keine fertigen Pakete gibt – weder in Debian, noch in anderen Distributionen. Dies wäre mit wenig Aufwand zu bewerkstelligen und hätte für viele Benutzer einen praktischen Nutzen im Alltag, um schnell und unkompliziert Daten in ODF-Dokumenten ausfindig zu machen.
Bei Bedarf passen Sie oben beschriebene Shell-Skripte flink an andere Office-Formate an. Um Dokumente aus Microsoft Office zu verarbeiten, stehen beispielsweise die Pakete Catdoc [8], WV [9] und Docx2txt [10] mit den gleichnamigen Werkzeugen für die Kommandozeile bereit.
Infos
[] Der Autor bedankt sich bei Thomas Osterried, Michael Stehmann und Axel Beckert für deren Anregungen und Kritik im Vorfeld dieses Artikels.
[1] ODF: http://de.wikipedia.org/wiki/OpenDocument
[2] Formatspezifisch suchen: Axel Beckert, Frank Hofmann, “Mit Struktur”, LU 06/2012, S. 82, https://www.linux-community.de/2540
[3] Webseite zu Loook: http://www.danielnaber.de/loook/
[4] Desktop-Suche für OpenOffice-Dokumente: http://lists.debian.org/debian-user-german/2012/02/msg00316.html
[5] Handbuch Sed & Awk: Dale Dougherty, Arnold Robbins, “Sed & Awk”, O’Reilly-Verlag, 2. Auflage 1997, ISBN 978-1-56592-225-5
[6] Strigi-Utils: http://packages.debian.org/squeeze/strigi-utils
[7] Evaluation von Deepgrep: http://noone.org/blog/English/Computer/Debian/CoolTools/deepgrep.futile
[8] Catdoc: http://packages.debian.org/squeeze/catdoc
[9] WV: http://packages.debian.org/squeeze/wv
[10] Docx2txt: http://packages.debian.org/wheezy/docx2txt
[11] Metatracker: http://projects.gnome.org/tracker/
[12] Imgseek: http://www.imgseek.net
[13] Strigi: http://sourceforge.net/projects/strigi/
[14] Terrier Search Engine: http://www.terrier.org
[15] Apache Lucene: http://lucene.apache.org/core/
[16] Apache Solr: http://lucene.apache.org/solr/
[17] Formatvorlagen: http://www.ooowiki.de/FormatVorlagen
[18] LibreOffice-Hilfe: http://help.libreoffice.org/Writer/Templates_and_Styles/de
[19] Formatvorlagen für LibreOffice: http://borumat.de/libreoffice-writer-tipps#fulltoc-anliegen-formatvorlagen




