

Grep gehört zu den elementaren Linux-Werkzeugen. Eine Reihe von Zusatztools hilft bei der Suche in Formaten, die dem kleinen Tool sonst versperrt bleiben.
Die Diskussion begann im Rahmen der OpenRheinRuhr 2011: Welche Tools eignen sich am besten für die Suche in den verschiedenen Dateiformaten? Das Hauptaugenmerk galt Programmen, die ähnlich wie Grep auf der Kommandozeile funktionieren. Es kam rasch eine größere Menge an Werkzeugen zusammen, wobei sich schnell herausstellte, dass viele davon kaum ein Nutzer kennt.
In der Folge entstand eine erste Übersicht solcher Tools, die Axel Beckert kurz darauf in seinem Blog [1] veröffentlichte. Die Liste beinhaltet neben dem Anwendungsbereich und Datenformat zusätzlich den Paketnamen für auf Debian oder Ubuntu basierende Linux-Distributionen.
Dieser Blog-Eintrag löste ein reges Experimentieren aus. Leser schickten weitere Hinweise, die eine erneute Recherche nach sich zogen, und in der Folge gelang es, die Liste weiter zu vervollständigen. Daraus entstanden bereits ein Artikel zur Suche in Postscript- und PDF-Dokumenten [2] sowie in Archiven und komprimierten Daten [3]. Nun steht eine Auswahl von Tools für Anwendungsformate im Mittelpunkt.
Exakte Position
Bei der Suche über viele Dateien ist es wichtig, den Dateinamen und die exakte Zeilennummer zu erfahren, in der ein Treffer auftritt. Grep leistet das über die Kombination der beiden Optionen -o und -n. Dabei sorgt -o als Kurzform für --only-matching dafür, dass Grep nur den exakten Treffer ohne den umgebenden Kontext ausgibt, -n (--line-number) stellt der Ausgabe die Zeilennummer voran.
Suchen Sie mit Grep über mehrere Dateien, so stellt das Programm der Ausgabe den Dateinamen voran. Dabei trennt es Dateiname, Zeilennummer und Treffer jeweils durch einen Doppelpunkt voneinander (Listing 1) und hebt, falls --color mit im Spiel ist, diese farblich unterschiedlich hervor.
Listing 1
$ cat -n datei1 1 Muster 2 muster $ cat -n datei2 1 muster 2 MusTer $ grep -on -E "Mus[tT]er" datei* datei1:1:Muster datei2:2:MusTer
Gnumeric
Zur Office-Suite des Gnome-Projekts zählt die Tabellenkalkulation Gnumeric. Das Paket enthält neben dem eigentlichen Programm die beiden nützlichen Werkzeuge Ssconvert und Ssgrep. Die ersten beiden Buchstaben stehen für “Spreadsheet”, also Tabellenblatt. Während Ssconvert Gnumeric-Rechenblätter in andere Formate umwandelt, sucht Ssgrep in diesen nach dem übergebenen Suchmuster.
Dabei unterstützt das Programm jedes Datenformat, für das Gnumeric einen Import-Filter besitzt. Neben dem nativen Gnumeric-Format (Gzip-komprimiertes XML) fallen unter anderem CSV-Daten, Microsoft Excel, Quattro Pro sowie das XML-Format von OpenOffice und LibreOffice Calc [4] in diese Kategorie.
Der Aufruf von Ssgrep ähnelt dem von Grep in vielerlei Hinsicht: Das Programm erwartet zwei Parameter – als erstes die Optionen mit dem Suchmuster, als zweites den Namen der Gnumeric-Datei, in der Sie suchen möchten. Es interpretiert das angegebene Muster als regulären Ausdruck [5] und ermöglicht somit volle Flexibilität beim Formulieren.
Als Treffer gibt es den gesamten Inhalt der Zelle aus. Mit der Option -H (Kurzform für --with-filename) gibt es zusätzlich den Dateinamen aus. Die Option -c zählt die Treffer (“count”). Mit -n (--print-locus) erhalten Sie zusätzlich den Namen des Rechenblattes sowie die Zellennummer. Listing 2 zeigt den Aufruf von Ssgrep zur Datei aus Abbildung 1.
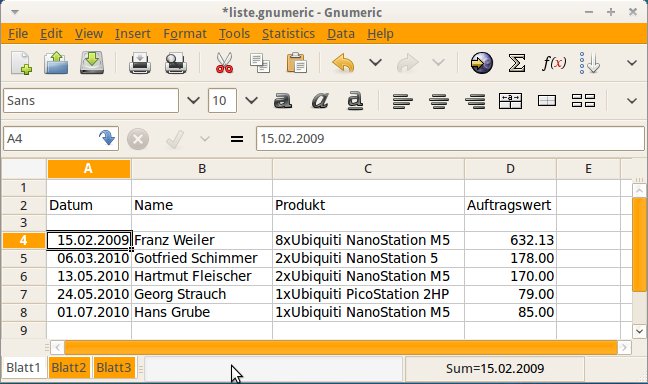
Abbildung 1: Ein Rechenblatt mit einer umfangreichen Produktliste in Gnumeric.
Listing 2
$ ssgrep -cH "Nano[Ss]tation" datei datei:4 $ ssgrep -Hn "Nano[Ss]tation" datei datei:Blatt1!C4:8xUbiquiti NanoStation M5 datei:Blatt1!C5:2xUbiquiti NanoStation 5 datei:Blatt1!C6:2xUbiquiti Nanostation M5 datei:Blatt1!C8:1xUbiquiti NanoStation M5
Die beiden Optionen -l und -L erweisen sich als nützlich, wenn Sie mehrere Dateien durchsuchen und nur den Namen der Datei benötigen, in der das Programm eine Übereinstimmung mit dem Muster findet. Mit der Option -l erhalten Sie eine Positivliste, mit -L hingegen eine Negativliste, also alle Dateien ohne Treffer. Diese beiden Optionen helfen dabei, den Suchraum einzugrenzen.
TIPP
Ssgrep kennt keine Option --color. Möchten Sie trotzdem etwas Farbe ins Ergebnis bringen, filtern Sie die Ausgabe durch ein nachfolgendes grep --color.
Für die Tabellenkalkulation Calc von OpenOffice und LibreOffice existiert kein Kommandozeilenwerkzeug, das ähnlich wie Ssgrep funktioniert. Allerdings hat Klaus Becker auf der Mailingliste der deutschen Debian-Anwender ein Skript gepostet [6], das Unzip und Grep kombiniert, um dennoch eine Suche im Terminal zu ermöglichen.
Die graphische Alternative Loook [7], ein Python-Skript mit Tk-Oberfläche, beherrscht die Suche in allen Dokumenten von Open- und LibreOffice (Abbildung 2). Es steht bisher allerdings nicht als Paket für Debian oder Ubuntu bereit, sondern nur als ZIP-Datei zum freien Download.
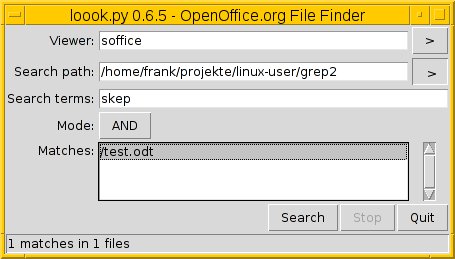
Abbildung 2: Loook hilft bei der Suche in Open- und LibreOffice-Dateien.
Im mittleren Eingabefeld (Search Path) des Fensters legen Sie fest, in welchem Verzeichnis die Software nach passenden Dateien sucht. Das dritte Eingabefeld (Search terms) nimmt das Suchkriterium auf. Allerdings verarbeitet Loook keine regulären Ausdrücke, sondern nur exakte Zeichenketten.
Sie haben die Möglichkeit, einen oder mehrere Suchbegriffe einzugeben und diese logisch miteinander zu verknüpfen. Dazu wählen Sie im Schalter Mode den entsprechenden Eintrag aus. Alle Treffer erscheinen in der unteren Box, ein Klick auf den Dateinamen öffnet die Datei. Welches Programm Sie dazu verwenden, bestimmen Sie über das oberste Eingabefeld (Viewer).
ID3-Tags
Wer über ein Archiv von Audio-Daten verfügt, kennt das Problem, flink den richtige Sound-Schnipsel wiederzufinden. Eine Struktur der Dateien nach Genre oder Künstler und das entsprechende Einsortieren in passend benannte Verzeichnisse sorgt für eine erste Orientierung. Viele Programme sortieren anhand der Tags, die Sie in den Musikdateien hinterlegt haben. Bei MP3 sind das unter anderem Titel, Interpret, Album, Jahr, Genre, Kommentar, Nummer des Titels, Komponist, Originalinterpret, Copyright und URL.
Für die Recherche auf der Kommandozeile steht Taggrepper [8] bereit. Es unterstützt bislang die Formate MP3, Ogg Vorbis und FLAC. Taggrepper akzeptiert ein oder mehrere Suchwörter, die Sie über eine Option dem entsprechenden Tag in der Datei zuordnen. Die Optionen gibt es jeweils in einer Kurz- und einer Langvariante: So dient -a als Äquivalent für --artist und führt zu einem Vergleich mit dem Interpreten. Eine Ausnahme bildet --any-tag, welches das Suchwort mit jedem Tag in der Datei vergleicht.
Alle Suchwörter behandelt Taggrepper als Perl-kompatible reguläre Ausdrücke (PCRE, [9]) und gestattet somit maximale Flexibilität in der Anfrage. Die Ausgabe des Programms beinhaltet normalerweise nur die Namen der Musikdateien, bei denen es einen Treffer gab. Worauf der Treffer beruht, erfahren Sie, indem Sie den Aufruf um weitere Parameter ergänzen, beispielsweise um --display-artist für den Interpreten (Listing 3). Diese Option lässt sich für alle oben genannten Tags nutzen.
Listing 3
$ taggrepper --display-artist -a NDR *20*.mp3
stenkelfeld200.mp3
Artist: NDR 2 - Neues aus Stenkelfeld
tenkelfeld204.mp3
Artist: NDR 2 - Neues aus Stenkelfeld
Für die rekursive Suche über mehrere Verzeichnisebenen hinweg bietet Taggrepper die Option -r an (Listing 4). Kombinieren Sie die verschiedenen Optionen miteinander, finden Sie schnell die gewünschte Musikdatei – vorausgesetzt natürlich, dass die Tags in den Audio-Daten vollständig eingetragen sind.
Listing 4
$ taggrepper -r --any-tag "Redaktion" --display-artist --display-title .
./hr2/derTag_20101125.mp3
Title: Der Papst im Beichtstuhl - Aus dem Inneren des Vatikans
Artist: Redaktion Der Tag
./hr2/derTag_20101209.mp3
Title: Das Empire schlägt zurück - Assange und die verratene Freiheit
Artist: Redaktion Der Tag
./hr2/derTag_20110902.mp3
Title: Wo der Bodden blubbert... Unbekanntes Mecklenburg-Vorpommern
Artist: Redaktion Der Tag
Genügt der Funktionsumfang von Taggrepper Ihren Ansprüchen nicht, stehen etliche grafische Alternativen bereit, beispielsweise Easytag [10] und Ex falso [11]. Diese bieten nicht nur die Möglichkeit, die Inhalte der Tags zu verändern, sondern ermitteln bei Bedarf auch die Details zu Bitrate, Länge des Audio-Stücks und dessen MPEG-Stufe (Abbildung 3).
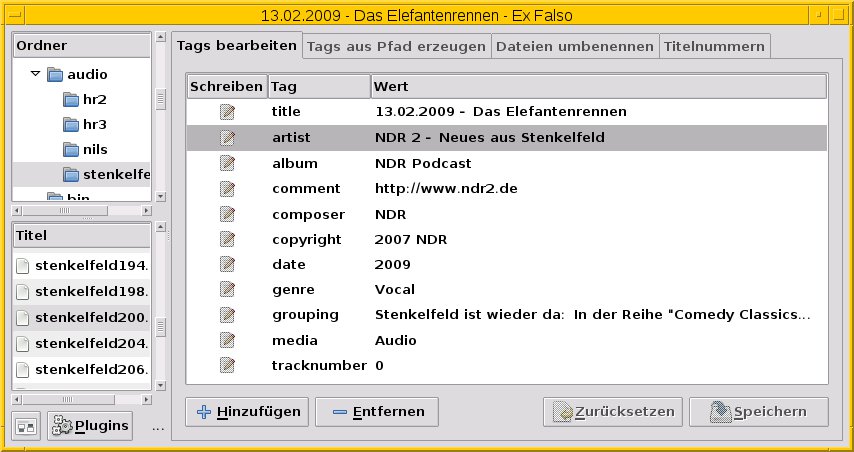
Abbildung 3: Ex Falso kitzelt aus einer MP3-Datei neben den Tags auch noch weitere Informationen heraus.
XML-Daten
Bei XML-Dateien handelt es sich um Textdateien mit einer definierten Struktur, am einfachsten zu vergleichen mit HTML. Der Unterschied besteht darin, dass Sie bei der Vergabe der Tags mehr Möglichkeiten haben. Im hierarchischen XML-Baum bezeichnet jedes Element einen Knoten. Wenden Sie Grep auf eine XML-Datei an, findet es alle Zeilen im Dokument, die das Suchwort enthalten. Die Suche mittels Grep ist kontextunabhängig, sofern Sie diese nicht mit Hilfe eines regulären Ausdrucks an eine bestimmten Zeichenfolge binden.
Um aber eine Anfrage der Form “Finde alle Unterknoten mit dem Namen Name von Knoten und gebe deren Inhalt aus” zu beantworten, bedarf es anderer Werkzeuge. Das Formulieren einer solchen auf Knoten oder die Hierarchie bezogenen, kontextabhängigen Suche gelingt nur in Kombination mit Sed und Awk oder in Form einer Folge von XSLT-Anweisungen.
Das World Wide Web-Konsortium W3C [12] hat die Positionsangabe eines Knotens im XML-Strukturbaum seit längerem unter dem Begriff XPath standardisiert. Die Pfadangabe ähnelt der von Linux-Verzeichnissen, die Hierarchie-Ebenen trennt jeweils ein Schrägstrich.
Im Laufe der Zeit gab es mehrfach den Versuch, unter dem Namen Xmlgrep ein Grep-Analogon für die Suche in XML-Daten zu etablieren. Es existieren verschiedene Pakete, die ein solches oder ähnliches Kommando beinhalten. Dazu zählen das Perl-Modul XML::Twig [13], das Paket XMLStar [14], die XML-coreutils [15] und XMLclitools [16]. Xgrep [17] steht für Ubuntu bereit, XML_grep2 [18] hingegen nur im Quellcode.
Das Perl-Modul XML::Twig bietet unter anderem die Werkzeuge XML_grep und XML_spellcheck (bei Debian und Ubuntu im Paket xml-twig-tools) an. XML_grep verwendet zur Suche von Mustern in XML-Dateien eine Untermenge von XPath. Als Aufrufparameter akzeptiert XML_grep verschiedene Optionen, eine XPath-Angabe und die XML-Datei.
Listing 5 zeigt ein Beispiel für ein kurzes XML-Format zum Speichern von Buchtiteln. Die Option --text_only bei der Abfrage in Listing 6 sorgt dafür, dass das Tool nur der Inhalt der Knoten ausgibt. Die XPath-Angabe benennt einen Knoten in der dritten Ebene der Hierarchie, der mit <isbn> bezeichnet ist.
Listing 5
<?xml version="1.0" encoding="UTF-8"?> <sortiment> <buch> <titel>XML</titel> <autor>Elizabeth Castro</autor> <isbn>3-8272-5994-0</isbn> </buch> <buch> <titel>Reif für die Insel. England für Anfänger und Fortgeschrittene</titel> <autor>Bill Bryson</autor> <isbn>9-783442-46596-5</isbn> </buch> </sortiment>
Listing 6
$ xml_grep --text_only "//sortiment/buch/isbn" buch.xml 3-8272-5994-0 9-783442-46596-5 $
Das Paket XMLStar bezeichnet sich als XML-Werkzeugsatz für die Kommandozeile und ermöglicht das Transformieren, Abfragen, Validieren und Modifizieren von XML-Dateien in der Shell. Es steht als Debian/Ubuntu-Paket bereit (xmlstarlet), welches das gleichnamige Tool mitbringt.
Die Tests für diesen Artikel erfolgten auf der Basis der von den Entwicklern zuletzt freigegebenen Version 1.3.1 aus dem Januar 2012, da dieses Release stark fehlerbereinigt ist und stabiler als die bislang in Debian 6.0 “Squeeze” oder Ubuntu 11.10 “Oneiric” verfügbaren Pakete läuft. Die Programmaufrufe in den Beispielen erfolgten mit der lokal aus dem Quellcode übersetzten Version.
Der Aufruf zur Suche nach Unterknoten ähnelt dem von XML_grep, es kommen nur noch einige Parameter dazu (Abbildung 4). Der Parameter sel steht für “select” und bewirkt das Auswählen der Knoten, -t für die Einsatz eines (zur Laufzeit erzeugten) XSLT-Templates und -v als Kurzform für --value-of, auf den der XPath-Ausdruck für den gewünschten Knoten folgt. Am Schluss des Aufrufs steht die zu verarbeitende XML-Datei. Abbildung 4 zeigt den Inhalt der verwendeten XML-Datei und das Suchergebnis – die Inhalte der beiden Knoten <isbn> mit den ISBN-Nummern.
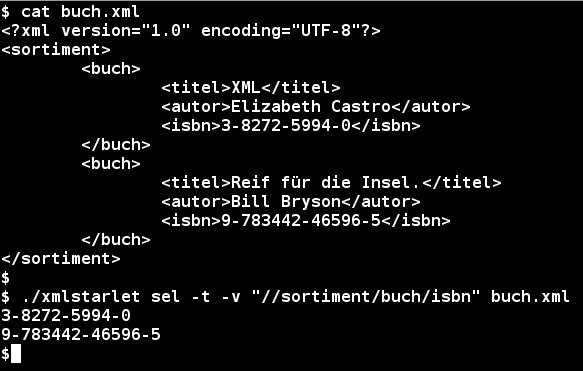
Abbildung 4: XMLStarlet gibt zeilenweise den Inhalt eines Knotens aus.
Falls Sie sich für das zur Laufzeit erzeugte XSLT-Template interessieren, machen Sie es mit dem Parameter -C sichtbar. Dabei zeigt die Applikation nur das Template an, sucht jedoch nicht (Abbildung 5). Das hilft einerseits, zu verstehen, wie das Programm funktioniert und wie das Suchergebnis zustande kommt. Andererseits erleichtert es die Suche nach möglichen Fehler. Nebenbei erhöht es das Verständnis für das Verarbeiten von XML-Formaten mit XSLT und XPath, was sich sicherlich auch an anderer Stelle als nützlich erweist.
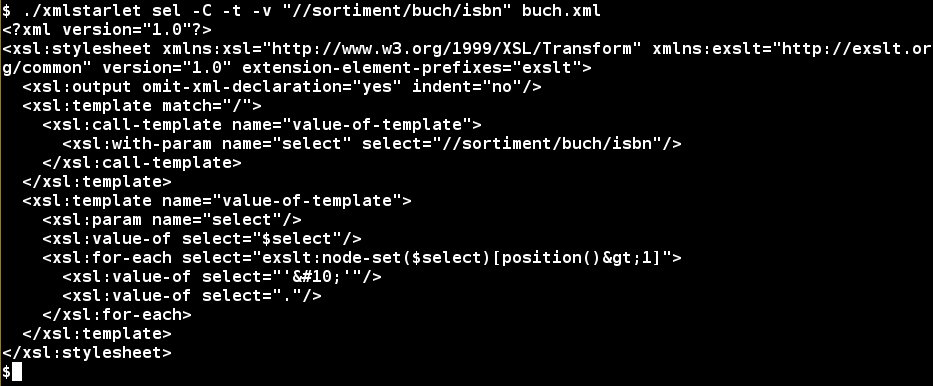
Abbildung 5: Ausgabe des on-the-fly erzeugten XSLT-Templates.
In die gleiche Kategorie sortiert sich Sgrep [19] ein. Es sucht nach ineinander verschachtelten Strukturen und Mustern, benutzt dabei aber eine eigene Abfragesprache, die deutlich von Format der regulären Ausdrücke abweicht. Listing 7 zeigt eine Suche nach allen Knoten <isbn> im Dokument.
Listing 7
$ sgrep '"<isbn>" .. "</isbn>"' buch.xml <isbn>3-8272-5994-0</isbn><isbn>9-783442-46596-5</isbn>
Fazit
Das Wissen über den Einsatz des Werkzeugs Grep gehört zu den Grundlagen bei der Suche nach Textstellen. In bestimmten Fällen fällt die Suche aber eher umständlich aus. Die vorgestellten Werkzeuge decken Spezialfälle für ausgewählte Formate ab und helfen Ihnen damit, Zeit zu sparen und Fehler zu vermeiden.
Glossar
-
XSLT
-
Abkürzung für Extensible Stylesheet Language Transformation. Bezeichnet das Anwenden von Funktionen auf die Knoten des XML-Strukturbaums.
Infos
[1] Axel Beckert: Blog-Eintrag “grep everything”, http://noone.org/blog/English/Computer/Shell/grep%20everything.futile
[2] Suche in PS- und PDF-Dokumenten: Frank Hofmann “Gesucht, gefunden”, LU 02/2012, S. 82, https://www.linux-community.de/25255
[3] Suche in Archiven: Axel Beckert, Frank Hofmann, “Nadel im Datenhaufen”, LU 04/2012, https://www.linux-community.de/25403
[4] Im- und Exportformate in Gnumeric: http://projects.gnome.org/gnumeric/features.shtml
[5] Reguläre Ausdrücke: Frank Hofmann, “Schnipseljagd”, LU 09/2011, S. 84, https://www.linux-community.de/24091
[6] Desktopsuche für ODF-Dokumente: http://lists.debian.org/debian-user-german/2012/02/msg00316.html
[7] Loook: http://www.danielnaber.de/loook/
[8] Taggrepper: http://gitorious.org/taggrepper/pages/Home
[9] Perl Compatible Regular Expressions: http://www.pcre.org
[10] Easytag: http://easytag.sourceforge.net
[11] Ex Falso: http://code.google.com/p/quodlibet/
[12] World Wide Web Consortium (W3C), http://www.w3.org/
[13] XML::Twig: http://search.cpan.org/~mirod/XML-Twig/
[14] XMLStar: http://xmlstar.sourceforge.net
[15] XML-coreutils: http://xml-coreutils.sourceforge.net
[16] XMLclitools: http://robur.slu.se/jensl/xmlclitools/
[17] Xgrep: http://packages.ubuntu.com/natty/utils/xgrep
[18] XML_grep2: http://www.mirod.org/module/xml_grep2/xml_grep2.html
[19] Sgrep: http://www.cs.helsinki.fi/u/jjaakkol/sgrep.html
[] Die Autoren bedanken sich bei Thomas Osterried, Julius Plenz und Michael Stehmann für deren kritische Anmerkungen, Kommentare und Ergänzungen im Vorfeld dieses Artikels.
[] Axel Beckert (http://noone.org/abe/) hat Informatik an der Universität des Saarlandes in Saarbrücken studiert. Er arbeitet als Systemadministrator an der ETH Zürich am Departement für Physik. Nebenher engagiert er sich ehrenamtlich beim Debian-Projekt, in der Linux User Group Switzerland (LUGS), beim Hackerfunk sowie weiteren Open-Source-Projekten.
[] Frank Hofmann (http://www.efho.de) hat Informatik an der Technischen Universität Chemnitz studiert. Derzeit arbeitet er in Berlin im Büro 2.0, einem Open-Source-Expertennetzwerk, als Dienstleister mit Spezialisierung auf Druck und Satz. Er ist Mitgründer des Schulungsunternehmens Wizards of FOSS. Seit 2008 koordiniert er das Regionaltreffen der Linux User Groups aus der Region Berlin-Brandenburg.




